|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
ЧАСТЬ II. Язык программирования C# ГЛАВА 3. Основы языка C# Воспринимайте эту главу как коллекцию тем, посвященных основным вопросам применения языка C# и использования платформы .NET. В отличие от следующих глав, здесь нет одной ведущей темы, а предлагается иллюстрации целого ряда узких тем, которые вы должны освоить. Это, в частности, типы данных, характеризуемые значениями, и ссылочные типы данных, конструкции условного: выбора и цикла, механизмы приведения к объектному типу и восстановления из "объектного образа", роль System.Object и базовая техника построения классов. По ходу дела вы также узнаете, как в рамках синтаксиса C# обрабатываются строки, массивы, перечни и структуры. Чтобы иллюстрировать базовые принципы применения языка, мы рассмотрим библиотеки базовых классов .NET и построим ряд примеров приложений, используя различные типы из пространства имен System. В этой главе также рассматривается такая новая возможность языка C# 2005, как тип данных с разрешением принимать значение null. Наконец, вы узнаете, как в C# с помощью ключевого слова namespace объединить типы в отдельное пространство имен. Структура простой программы на C# Язык C# требует, чтобы вся логика программы содержалась в рамках определения некоторого типа (вспомните из главы 1, что термин тип используется для обозначения любого элемента множества {класс, интерфейс, структура, перечень, делегат}). В отличие от C(++), в C# не позволяется создавать глобальные функций и глобальные элементы данных. В простейшей своей форме программа на C# может быть записана в следующем виде. // По соглашению C#-файлы имеют расширение *.cs. using System; class HelloClass { public static int Main(string[] args) { Console.WriteLine("Hello World!"); Console.ReadLine(); return 0; } } Здесь определяется тип класса (HelloClass), поддерживающий единственный метод, которому назначено имя Main(). Каждое выполняемое C#-приложение должно содержать класс, определяющий метод Main(), который используется для обозначения точки входа приложения. Как видите, здесь с методом Main() связаны ключевые слова public и static. Позже будут представлены их формальные определения, а пока что вам достаточно знать, что открытые члены (public) доступны дли других типов, а статические члены (static) рассматриваются на уровне класса (а не на уровне объекта) и поэтому могут вызываться без создания нового экземпляра класса. Замечание. Язык C# является языком, чувствительным к регистру символов. Например, Main здесь отличается от main, а Readlinе – от ReadLine. Поэтому следует подчеркнуть, что все ключевые слова в C# состоят из букв нижнего регистра (public, lock, global и т.д.), а пространства имен, типы, имена членов, а также все интегрированные а них слова начинаются (по соглашению) с прописных букв (например, Console.WriteLine, System.Windows.Forms.MessageBox, System.Data.SqlClient и т.д). Вдобавок к ключевым словам public и static, этот метод Main() имеет один параметр, который в данном случае является массивом строк (String[] args). В настоящий момент вопрос обработки этого массива мы обсуждать не будем, но следует заметить, что этот параметр может принять любое число аргументов командной строки (вскоре вы узнаете как получить к ним доступ). Вся программная логика HelloClass содержится в рамках Main(). Здесь используется класс Console, который определен в пространстве имен System. Среди множества других членов там имеется статический элемент WriteLine(), который как вы можете догадаться, посылает текстовую строку на стандартное устройство вывода. Здесь же вызывается Console.ReadLine(), чтобы информация командной строки была видимой в ходе сеанса отладки Visual Studio 2005, пока вы не нажмете клавишу ‹Enter›. Ввиду того, что здесь метод Main() определен, как метод, возвращающий данные типа integer (целочисленные данные), перед выходом из метода возвращается нуль (означающий успешное завершение). Наконец, как вы можете понять из определения типа HelloClass, в языке C# используется тот вид комментариев, который был принят в C и C++. Вариации метода Main() Предыдущий вариант Main() был определен с одним параметром (массивом строк) и возвращал данные типа int. Однако это не единственно возможная форма Main(). Для построения точки входа приложения можно использовать любую из следующих сигнатур (в предположении, что она содержится в рамках C#-класса или определения структуры). // Возвращаемого типа нет, массив строк в качестве аргумента public static void Main(string[] args) { } // Возвращаемого типа нет, аргументов нет. public static void Main() { } // Возвращаемый тип int (целое), аргументов нет. public static int Main() { } Замечание. Метод Main() можно также определить, как private (частный, приватный), а не public (открытый, общедоступный). Это будет означать, что другие компоновочные блоки не смогут непосредственно вызвать точку входа приложения. В Visual Studio 2005 метод Main() программы автоматически определяется, как приватный. Очевидно, что при выборе варианта определения Main() нужно учитывать ответы на следующие два вопроса. Bo-первых предполагается ли при выполнении программы обрабатывать предоставленные пользователем параметры командной строки? Если да, то значения параметров должны запоминаться в массиве строк. Во-вторых, нужно ли будет по завершении работы Main() предоставить системе возвращаемое значение? Если да, то возвращаемым типом данных должно быть int, а не void. Обработка аргументов командной строки Давайте изменим класс HelloClass так. чтобы он мог обрабатывать параметры командной строки. // Проверить, передавались ли аргументы командной строки. using System; class HelloClass { public static int Main(string[] args) { Console.WriteLine("*** Аргументы командной строки ***"); for (int i = 0; i ‹ args.Length; i++) Console.WriteLine("Apгyмeнт: {0} ", args[i]); … } } Здесь с помощью свойства Length объект System.Array проверяется, содержит ли массив строк какие-либо элементы (как вы убедитесь в дальнейшем, все массивы в C# на самом деле имеют тип System.Array и таким образом имеют общее множество членов). В результате прохода по всем элементам массива их значения выводятся в окно консоли. Аргументы в командной строке указываются так, как показано на рис. 3.1. 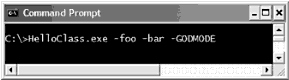 Рис. 3.1. Аргументы вызова приложения в командной строке Вместо стандартного цикла for для итераций над массивами входных строк можно использовать ключевое слово C# foreach. Этот элемент синтаксиса будет подробно рассматриваться позже, но вот вам пример его использования: // Обратите внимание на то, что при использовании'foreach' // нет необходимости проверять длину массива. public static int Main(string[] args) { … foreach (string s in args) Console.WriteLine("Аргумент: {0} ", s); … } Наконец, доступ к аргументам командной строки обеспечивает также статический метод GetCommandLineArgs() типа System.Environment. Возвращаемым значением этого метода является массив строк. Его первый элемент идентифицирует каталог, содержащий приложение, а остальные элементы в массиве содержат по отдельности аргументы командной строки (при этом нет необходимости определять для метода Main() параметр в виде массива строк). public static int Main(string[] args) { ... // Получение аргументов с помощью System.Environment. string[] theArgs = Environment.GetCommandLineArgs(); Console.WriteLine("Путь к приложению: {0}", theArgs[0]); … } Использование аргументов командной строки в Visual Studio 2005 Конечный пользователь указывает аргументы командной строки при запуске программы. В процессе разработки приложения вы можете указать флаги командной строки с целью тестирования программы. Чтобы сделать это в Visual Studio 2005, выполните двойной щелчок на пиктограмме Properties (Свойства) в окне Solution Explorer (Обзор решений) и выберите вкладку Debug (Отладка). После этого укажите нужные значения аргументов в поле текста Command line arguments (Аргументы командной строки), рис. 3.2. 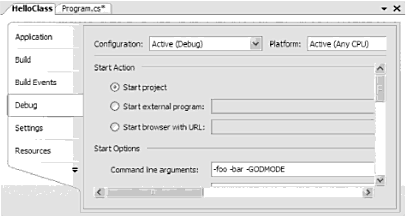 Рис. 3.2. Установка аргументов командной строки в Visual Studio 2005 Несколько слов о классе System.Environment Давайте рассмотрим класс System.Environment подробнее. Этот класс содержит ряд статических членов, позволяющих получить информацию относительно операционной системы, в которой выполняется .NET-приложение. Чтобы иллюстрировать возможности этого класса, измените метод Mаin() в соответствии со следующей логикой. public static int Main(string[] args) { ... // Информация об операционной системе. Console.WriteLine("Используемая ОС: {0} ", Environment.OSVersion); // Каталог, в котором находится приложение. Console.WriteLine("Текущий каталог: {0}: ", Environment.CurrentDirectory); // Список дисководов на данной машине. string[] drives = Environment.GetLogicalDrives(); for (int i = 0; i ‹ drives.Length; i++) Console.WriteLine("Диск {0}: {1} ", i, drives[i]); // Версия .NET-платформы, выполняемая на машине. Console.WriteLine("Выполняемая версия .NET: {0} ", Environment.Version); … } Возможный вариант вывода показан на рис. 3.3. 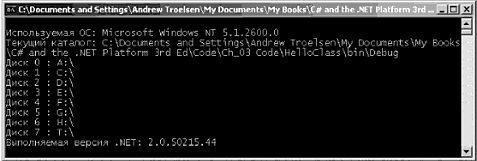 Рис. 3.3. Переменные окружения за работой Тип System.Envirоnmеnt содержит определения и других членов, а не только представленных в данном примере. В табл. 3.1 показаны некоторые интересные свойства, но непременно загляните в документацию .NET Framework 2.0 SDK, чтобы узнать подробности. Таблица 3.1. Некоторые свойства System.Environment
Определение классов и создание объектов Теперь, когда вы знаете о роли Main(), перейдем в задаче построения объектов. Во всех объектно-ориентированных языках делается четкое различие между классами и объектами. Термин класс используется для определения пользовательского типа (User-Defined Type – UDT), или, если хотите, шаблона. А термин объект применяется для обозначения экземпляра конкретного класса в памяти. Ключевое слово new в C# обеспечивает способ создания объектов. В отличие от других объектно-ориентированных языков (таких как, например, C++), в C# невозможно разместить тип класса в стеке, поэтому если вы попытаетесь использовать переменную класса, которая не была создана с помощью new, вы получите ошибку компиляции. Таким образом, следующий программный код C# оказывается недопустимым. using System; class HelloClass { public static int Main(string[] args) { // Ошибка! Используется неинициализированная локальная // переменная. Следует использовать 'new'. HelloClass c1; с1.SomeMethod(); … } } Чтобы использовать правильные процедуры для создания объектов, внесите следующие изменения. using System; class HelloClass { public static int Main(string[] args) { // Можно объявить и создать объект в одной строке… HelloClass с1 = new HelloClass(); //…или указать объявление и создание в разных строках. HelloClass c2; с2 = new HelloClass(); … } } Ключевое слово new отвечает за вычисление числа байтов, необходимых для заданного объекта, и выделение достаточного объема управляемой динамической памяти (managed heap). В данном случае вы размещаете два объекта типа класса HelloClass. Следует понимать, что объектные переменные C# на самом деле являются ссылками на объект в памяти, а не фактическими объектами. Так что c1 и с2 ссылаются на уникальный объект HelloClass, размещенный а управляемой динамической памяти. Роль конструкторов До сих пор объекты HelloClass строились с помощью конструктора, заданного по умолчанию, который, по определению, не имеет аргументов. Каждый класс C# автоматически снабжается типовым конструктором, который вы можете при необходимости переопределить. Этот типовой конструктор используется по умолчанию и гарантирует, что все члены-данные по умолчанию получат подходящие типовые значения (такое поведение характерно для всем конструкторов). Сравните это с ситуацией в C++. где неинициализированные данные указывают на "мусор" (иногда мелочи оказываются очень важными). Обычно кроме конструктора, заданного по умолчанию, классы предлагают и другие конструкторы. Тем самым вы обеспечиваете возможность инициализации состояния объекта во время его создания, Подобно Java и C++, конструкторы в C# имеют имя, соответствующее имени класса, который они конструируют, и они никогда не возвращают значения (даже значения void). Ниже снова рассматривается тип HelloClass, но с пользовательским конструктором, переопределенным заданным по умолчанию конструктором, и элементом открытых строковых данных. // HelloClass c конструкторами. class HelloClass { // Элемент открытых данных. public string userMessage; // Конструктор, заданный по умолчанию. public HelloClass() { Console.WriteLine("Вызван конструктор, заданный по умолчанию!"); } // Пользовательский конструктор, связывающий данные состояния // с данными пользователя. public HelloClass(string msg) { Console.WriteLine("Вызван пользовательский конструктор!"); userMessage = msg; } // точка входа программы. public static int Main(string[] args) { // Вызов конструктора, заданного по умолчанию HelloClass c1 = new HelloClass(); Console.WriteLine("Значение userMessage: {0}\n", c1.userMessage); // Вызов параметризованного конструктора HelloClass c2; c2 = new HelloClass("Проверка. 1, 2, 3"); Console.WriteLine("Значение userMessage: {0}\n ", c2.userMessage); Console.ReadLine(); return 0; } } Замечание. Если тип определяет члены (включая и конструкторы) с одинаковыми именами, которые отличаются только числом (или типом) параметров, то соответствующий член называют перегруженным. В главе 4 перегрузка будет рассмотрена подробно. При анализе вывода этой (программы можно заметить что конструктор, заданный по умолчанию, присваивает строковому полю значение (пустое), предусмотренное по умолчанию, в то время как специальный конструктор определяет для члена значение, предоставленное пользователем (pиc. 3.4). 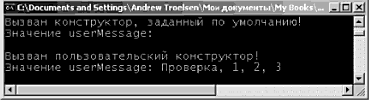 Рис. 3.4. Простая логика конструктора Замечание. После определения пользовательского конструктора для типа класса конструктор, заданный по умолчанию, будет удален. Чтобы в этом случае у пользователей объекта осталась возможность создавать экземпляры типа с помощью конструктора, заданного по умолчанию такой конструктор нужно явно переопределить, как это сделано в предыдущем примере. Утечка памяти Если вы имеете опыт программирования на языке C++, то у вас в связи с предыдущими примерами программного кода могут возникать вопросы. В частности, следует обратить внимание на то, что метод Main() типа HelloClass не имеет явных операторов уничтожений ссылок c1 и с2. Это не ужасное упущение, а правило .NET. Как и программистам Visual Basic и Java, программистам C# не требуется уничтожать управляемые объекты явно. Механизм сборки мусора .NET освобождает память автоматически, поэтому в C# не поддерживается ключевое слово delete. В главе 5 процесс сборки мусора будет рассмотрен подробно. До того времени вам достаточно знать лишь о том, что среда выполнения .NET автоматически уничтожит размещенные вами управляемые объекты. Определение "объекта приложения" В настоящее время тип HelloClass решает две задачи. Во-первых, этот класс определяет точку входа в приложение (метод Main()). Во-вторых, HelloClass поддерживает элемент данных и несколько конструкторов. Все это хорошо и синтаксически правильно, но немного странным может показаться то, что статический метод Main() создает экземпляр того же класса, в котором этот метод определен. class HelloClass { … public static int Main(string[] args) { HelloClass c1 = new HelloClass(); … } } Такой подход здесь и в других примерах используется только для того, чтобы сосредоточиться на иллюстрации решения соответствующей задачи. Более естественным подходом была бы факторизация типа HelloClass с разделением его на два отдельных класса: HelloClass и HelloApp. При компоновке C#-приложения обычно один тип используется в качестве "объекта приложения" (это тип, определяющий метод Main()), в то время как остальные типы и составляют собственно приложение. В терминах ООП это называется разграничение обязанностей. В сущности, этот принцип проектирования программ требует, чтобы класс отвечал за наименьший объем работы. Поэтому мы можем изменить нашу программу следующим образом (обратите внимание на то, что здесь в класс HelloClass добавляется новый член PrintMessage()). class HelloClass { public string userMessage; public HelloClass() {Console.WriteLine("Вызван конструктор, заданный по умолчанию!");} public HelloClass(string msg) { Console.WriteLine("Вызван пользовательский конструктор!"); userMessage = msg; } public void PrintMessage() { Console.WriteLine("Значение userMessage: {0}\n", userMessage); } } class HelloApp { public static int Main(string[] args) { HelloClass c1 = new HelloClass("Эй, вы, там…"); c1.PrintMessage(); } } Исходный код. Проект HelloClass размещен в подкаталоге, соответствующем главе 3. Класс System.Console Многие примеры приложений, созданные для первых глав этой книги, используют класс System.Console. Конечно, интерфейс CUI (Console User Interface – консольный интерфейс пользователя) не так "соблазнителен", как интерфейс Windows или WebUI, но, ограничившись в первых примерах интерфейсом CUI, мы можем сосредоточиться на иллюстрируемых базовых понятиях, не отвлекаясь на сложности построения GUI (Graphical User Interface – графический интерфейс пользователя). Как следует из его имени, класс Console инкапсулирует элементы обработки потоков ввода, вывода и сообщений об ошибках для консольных приложений. С выходом .NET 2.0 тип Console получил новые функциональные возможности. В табл. 3.2 представлен список некоторых наиболее интересных из них (но, конечно же, не всех). Таблица 3.2. Подборка членов System.Console, новых для .NET 2.0
Ввод и вывод в классе Console Вдобавок к членам, указанным в табл. 3.2, тип Console определяет множество методов, обрабатывающих ввод и вывод, причем все эти методы определены как статические (static), поэтому они вызываются на уровне класса. Вы уже видели, что WriteLine() вставляет текстовую строку (включая символ возврата каретки) в выходной поток. Метод Write() вставляет текст в выходной поток без возврата каретки. Метод ReadLine() позволяет получить информацию из входного потока до символа возврата каретки, a Read() используется дли захвата одного символа из входного потока. Чтобы проиллюстрировать основные возможности ввода-вывода класса Console, рассмотрим следующий метод Main(), который запрашивает у пользователя некоторую информацию и повторяет каждый элемент в потоке стандартного вывода. На рис 3.5 показан пример выполнения такой программы. // Использование класса Console для ввода и вывода. static void Main(string[] args) { // Эхо для некоторых строк. Console.Write("Введите свое имя: "); string s = Console.ReadLine(); Console.WriteLine("Привет {0} ", s); Console.Write("Укажите возpаст: "); s = Console.ReadLine(); Console.WriteLine("Вам {0} год(а)/лет", s); } 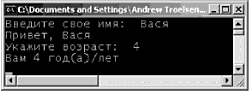 Рис. 3.5. Ввод и вывод с помощью System.Console Форматирование консольного вывода В этих первых главах вы много раз видели в строковых литералах символы {0}, {1} и др. В .NET вводится новый стиль форматирования строк, немного напоминающий стиль функции printf() в C, но без загадочных флагов %d, %s и %с. Вот простой пример (соответствующий вывод показан на рис. 3.6). static void Main(string[] args) { ... int theInt = 90; double theDouble = 9.99; bool theBool = true; // Код '\n' в строковых литералах выполняет вставку // символа перехода на новую строку. Console.WriteLine("Int равно {0}\nDouble равно {1}\nВооl равно {2}", theInt, theDouble, theBool); } 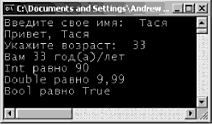 Рис. 3.6. Множество "пустышек" в строковых литералах Первый параметр метода WriteLine() представляет собой строковый литерал, который содержит опции-заполнители, обозначенные {0}, {1}, {2} и т.д. (нумерация в фигурных скобках всегда начинается с нуля). Остальные параметры WriteLine() являются значениями, которые должны быть вставлены на место соответствующих заполнителей (в данном случае это theInt, theDouble и theBool). Также следует знать о том, что метод WriteLine() перегружен, чтобы можно было указывать в качестве значения заполнителя массив объектов. Так, строкой формата следующего вида можно представить любое число элементов. // Замена заполнителей элементами массива объектов. object[] stuff = {"Эй", 20.9, 1, "Там", "83", 99.99933); Console.WriteLine("Мусор: {0}, {1}, {2}, {3}, {4}, {5}", stuff); Можно также повторять заполнитель в строке. Например, если вы являетесь поклонником Beatles и хотите построить строку "9, Number 9, Number 9", то можете написать следующее. // Джон говорит,… Console.WriteLine ("{0}, Number {0}, Number {0}", 9); Замечание. Если имеется несоответствие между числом различных заполнителей в фигурных скобках и числом заполняющих их аргументов, то в среде выполнения генерируется исключение FormatException. Флаги форматирования строк .NET Если требуется более сложное форматирование, каждый заполнитель может дополнительно содержать различные символы форматирования (в верхнем или в нижнем регистре), как показано в табл. 3.3. Таблица 3.3. Символы форматирования строк .NET
Символы форматирования добавляются в виде суффикса к соответствующему заполнителю через двоеточие (например, {0:C}, {1:d}, {2:X} и т.д.). Предположим, что вы добавили в Main() следующий программный код. // Используем некоторые дескрипторы формата. static void Main(string[] args) { … Console.WriteLine("Формат C: {0:C}", 99989.987); Console.WriteLine("Формат D9: {0:D9}", 99999); Console.WriteLine("Формат E: {0:E}", 99999.76543); Console.WriteLine("Формат F3: {0:F3}", 99999.9999); Console.WriteLine("Формат N: {0:N}", 99999); Console.WriteLine("Формат X: {0:X}", 99999); Console.WriteLine("Фopмaт x: {0:x}", 99999); } Использование символов форматирования в .NET не ограничивается консольными приложениями. Те же флаги можно использовать в контексте статического метода String.Format(). Это может быть полезно тогда, когда в памяти нужно построить строку с числовыми значениями, подходящую для использования в приложениях любого типа (Windows Forms, ASP.NET, Web-сервисы XML и т.д.). static void Main(string[] args) { // Использование статического метода String.Format() // для построения новой строки. string formatStr; formatStr = String.Format("Хотите получить {0:C} на свой счет?", 99989.987); Console.WriteLine(formatStr); } На рис. 3.7 показан пример вывода данной программы. 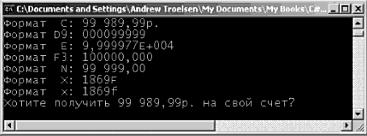 Рис. 3.7. Флаги форматирования строк в действии Исходный код. Проект BasicConsoleIO размещен в подкаталоге, соответствующем главе 3. Доступность членов Прежде чем двигаться дальше, мы должны обсудить вопрос доступности, или "видимости" членов. Члены (методы, поля, конструкторы и т.д.) данного класса или структуры должны указать свой уровень доступности. Если член определяется без указания ключевого слова, характеризующего доступность, этот член по умолчанию определяется как private. В C# используются модификаторы доступности методов, перечисленные в табл. 3.4. Вы, наверное, уже знаете, что доступ к открытым членам можно получить с помощью объектной ссылки, используя операцию, обозначаемую точкой (.). Приватные члены недоступны извне по объектной ссылке, но могут вызываться объектами внутри, чтобы экземпляр мог выполнить свою работу (т.е. это частные вспомогательные функции). Таблица 3.4. Ключевые слова C#, указывающие уровень доступности
Защищенные члены оказываются полезными только при создании иерархии классов, что будет темой обсуждения главы 4. Что касается внутренних, и защищённых членов, то они обычно используются при создании библиотек программного кода .NET (например, управляемых библиотек *.dll, что будет обсуждаться в главе 11). Чтобы проиллюстрировать применение указанных ключевых слов, создадим класс (SomeClass), в котором используются все указанные модификаторы доступности членов. // Опции доступности членов. class SomeClass { // Доступен везде. public void PublicMethod() {} // Доступен только из типов SomeClass. private void PrivateMethod() {} // Доступен из SomeClass и потомков. protected void ProtectedMethod() {} // Доступен только в рамках данного компоновочного блока. internal void InternalMethod() {} // Защищенный доступ внутри компоновочного блока. protected internal void ProtectedInternalMethod() {} // В C# при отсутствии явных указаний // члены по умолчанию считаются приватными. void SomeMethod(){} } Теперь, создав экземпляр класса SomeClass, попытаемся вызвать каждый из его методов, используя операцию, обозначаемую точкой. static void Main(string[] args) { // Создается объект и выполняется попытка вызова членов. SomeClass с = new SomeClass(); c.PublicMethod(); с.InternalMethod(); с.ProtectedInternalMethod(); с.PrivateMethod(); // Ошибка! с.ProtectedMethod(); //Ошибка! с.SomeMethod(); // Ошибка! } Если скомпилировать эту программу, вы обнаружите, что защищенные и частные члены вне объекта не доступны. Исходный код. Проект MemberAccess размещен в подкаталоге, соответствующем главе 3. Доступность типов Типы (классы, интерфейсы, структуры, перечни и делегаты) также могут использовать модификаторы доступности, но только public или internal. Когда вы создаете общедоступный тип (public), то гарантируете, что он будет доступным для других типов как в текущем компоновочном блоке, так и во внешних компоновочных блоках. Это может оказаться полезным только тогда, когда вы создаете библиотеку программного кода (см. главу 11), но здесь мы можем привести пример использования этого модификатора доступности,
public class MyClass() Внутренний (internal) тип, с другой стороны, может использоваться только компоновочным блоком, в котором этот тип определен. Если создать библиотеку программного кода .NET, в которой будут определены внутренние типы, то компоновочные блоки, ссылающиеся на эту библиотеку (файл *.dll), не смогут увидеть эти типы, создать их экземпляры или как-то иначе взаимодействовать с ними. Характеристикой доступности, принимаемой по умолчанию для типов в C#, является internal, поэтому если вы не укажете явно ключевое слово public, то в результате будет создан внутренний тип. // Эти классы могут использоваться только внутри // текущего компоновочного блока. internal class MyHelperClass{} class FinalHelperClass{} //По умолчанию тип будет внутренним. Замечание. В главе 4 будет говориться о вложенных типах. Вы узнаете, что вложенные типы тоже могут быть объявлены, как приватные. Значения, назначаемые переменным по умолчанию Членам-переменным классов автоматически присваиваются подходящие значения, предусмотренные по умолчанию. Эти значения для каждого типа данных, свои, но правила их выбора достаточно просты: • для типа bool устанавливается значение false; • числовым данным присваивается значение 0 (или 0.0, если это данные с плавающим разделителем); • для типа string устанавливается значение null; • для типа char устанавливается значение '\0'; • для ссылочных типов устанавливается значение null. С учетом этих правил проанализируйте следующий программный код. // Поля типа класса получают значения по умолчанию. class Test { public int myInt; // Устанавливается равным 0. public string myString; // Устанавливается равным null. public bool myBool; // Устанавливается равным false. public object myObj; // Устанавливается равным null. } Значения, назначаемые по умолчанию, и локальные переменные Совсем по-другому обстоит дело тогда, когда объявляются локальные переменные, видимые в пределах данного члена. При определении локальной переменной вы должны назначить ей начальное значение, прежде чем начать ее использование, поскольку такая перемен наяне не получает начального значения по умолчанию. Например, следующий программный код приведет к ошибке компиляции, // Ошибка компиляции! Переменная 'localInt' должна получить // начальное значение до ее использования. static void Main(string[] args) { int localInt; Console.WriteLine(localInt); } Исправить проблему очень просто. Следует присвоить переменной начальное значение. // Так лучше: теперь все довольны. static void Main(string[] args) { int localInt = 0; Console.WriteLine(localInt); } Замечание. Правило обязательного присваивания начальных значений локальным переменным имеет одно исключение: если переменная используется в качестве выходного параметра (это понятие будет рассмотрено немного позже), то устанавливать начальное значение такой переменной не требуется. Синтаксис инициализации членов-переменных Типы класса обычно имеют множество членов-переменных (также называемых полями). Если в классе можно определять множество конструкторов, то может возникнуть не слишком радующая программиста необходимость многократной записи одного и того же программного кода инициализации для каждой новой реализации конструктора. Это вполне реально, например, в том случае, когда вы не хотите принимать значение члена, предусмотренное по умолчанию. Так, чтобы член-переменная (myInt) целочисленного типа всегда инициализировался значением 9, вы можете записать следующее. // Все это хорошо, но такая избыточность… class Test { public int myInt; public string myString; public Test() {myInt = 9;} public Test(string s) { myInt = 9; myString = s; } } Альтернативой может быть определение вспомогательной функции, вызываемой всеми конструкторами. При этом уменьшается общее число повторений для операции присваивания, но теперь возникает следующая избыточность, // Все равно остается избыточность… class Test { public int myInt; public string myString; public Test() {InitData();} public Test(string s) { myString = s; InitData(); } private void InitData() {myInt = 9;} } Оба эта подхода вполне легитимны, но в C# позволяется назначать членам типа начальные значения в рамках деклараций (вы, наверное, знаете, что другие объектно-ориентированные языки [например, C++], не позволяют такую инициализацию членов). В следующем фрагменте программного кода обратите внимание на то, что инициализация может выполняться и для внутренних объектных ссылок, а не только для числовых типов данных. // Если нужно отказаться от значений, предусмотренных по умолчанию, // эта техника позволяет избежать повторной записи программного // хода инициализации в каждом конструкторе. class Test { public int myInt = 9; public string myStr = "Мое начальное значение. "; public SportsCar viper = new SportsCar(Color.Red); ... } Замечание. Инициализация членов выполняется до выполнения программной логики конструктора. Если присвоить значение полю в самом конструкторе, это сведет на нет инициализацию члена. Определение констант Итак, вы знаете, как объявить переменные класса. Теперь давайте выясним, как определить данные, изменить которые не предполагается. Для определения переменных с фиксированным, неизменяемым значением в C# предлагается ключевое слово const. После определения значения константы любая попытка изменить это значение приводит к ошибке компиляции. В отличие От C++, в C# ключевое слово const нельзя указывать для параметров и возвращаемых значений – оно предназначено для создания локальных данных и данных уровня экземпляра. Важно понимать, что значение, присвоенное константе, во время компиляции уже должно быть известно, поэтому константу нельзя инициализировать объектной ссылкой (значение последней вычисляется в среде выполнения). Чтобы проиллюстрировать использование ключевого слова const, рассмотрим следующий тип класса. class ConstData { // Значение, присваиваемое константе, должно быть известно во время компиляции. public const string BestNbaTeam = "Timberwolves"; public const double SimplePI = 3.14; public const bool Truth = true; public const bool Falsity = !Truth; } Обратите внимание на то, что значения всех констант известны во время компиляции. И действительно, если просмотреть эти константы с помощью ildasm.exe, то вы обнаружите, что их значения будут "жестко" вписаны в компоновочный блок, как показано на рис. 3.8. (Ничего более постоянного получить невозможно!)  Рис. 3.8. Ключевое слово const вписывает "свое" значение прямо в метаданные компоновочного блока Ссылки на константы Если нужно сослаться на константу, определенную внешним типом, вы должны добавить префикс имени типа (например, ConstData.Truth), поскольку поля-константы являются неявно статическими. Однако при ссылке на константу, определенную в рамках текущего типа (или в рамках текущего члена), указывать префикс имени типа не требуется. Чтобы пояснить это, рассмотрим следующий класс. class Program { public const string BestNhlTeam = "Wild"; static void Main(string[] args) { // Печать значений констант, определенных другими типами. Console.WriteLine("Константа Nba: {0}", ConstData.BestNbaTeam); Console.WriteLine("Константа SimplePI: {0}", ConstData.SimplePI); Console.WriteLine("Константа Truth: {0}", ConstData.Truth); Console.WriteLine("Константа Falsity: {0}", ConstData.Falsity); // Печать значений констант члена. Console.WriteLine("Константа Nhl: {0}", BestNhlTeam); // Печать значений констант локального уровня. const int LocalFixedValue = 4; Console.WriteLine("Константа Local: {0}", LocalFixedValue); Console.ReadLine(); } } Обратите внимание на то, что для доступа к константам класса ConstData необходимо указать имя типа. Однако класс Program имеет прямой доступ к константе BestNhlTeam, поскольку она была определена в пределах собственной области видимости класса. Константа LocalFixedValue, определенная в Main(), конечно же, должна быть доступной только из метода Main(). Исходный код. Проект Constants размещен в подкаталоге, соответствующем главе 3. Определение полей только для чтения Как упоминалось выше, значение, присваиваемое константе, должно быть известно во время компиляции. Но что делать, если нужно создать неизменяемое поле, начальное значение которого будет известно только в среде выполнения? Предположим, что вы создали класс Tire (покрышка), в котором обрабатывается значение ID (идентификатор) производителя. Кроме того, предположим, что вы хотите сконфигурировать этот тип класса так, чтобы в нем поддерживалась пара известных экземпляров Tire, чьи значения не должны изменяться. Если использовать ключевое слово const, вы получите ошибку компиляции, поскольку адрес объекта в памяти становится известным только в среде выполнения. class Tire { // Поскольку адреса объектов определяются в среде выполнения, // здесь нельзя использовать ключевое слово 'const.'! public const Tire Goodstone = new Tire(90); // Ошибка! public const Tire FireYear = new Tire(100); // Ошибка! public int manufactureID; public Tire() {} public Tire(int ID) { manufactureID = ID;} } Поля, доступные только для чтения, позволяют создавать элементы данных, значения которых остаются неизвестными в процессе трансляции, но о которых известно, что они никогда не будут изменяться после их создания. Чтобы определить поле, доступное только для чтения, используйте ключевое слово C# readonly. class Tire { public readonly Tire GoodStone = new Tire(90); public readonly Tire FireYear = new Tire(100); public int manufactureID; public Tire() {} public Tire (int ID) {manufactureID = ID;} } С такой модификацией вы сможете не только выполнить компиляцию, но и гарантировать, что при изменении значений полей GoodStone и FireYear в программе вы получите сообщение об ошибке. static void Main(string[] args) { // Ошибка! // Нельзя изменять значение поля, доступного только для чтения. Tire t = new Tire(); t.FireYear = new Tire(33); } Поля, доступные только для чтения, отличаются от констант еще и тем, что таким полям можно присваивать значения в контексте конструктора. Это может оказаться очень полезным тогда, когда значение, которое нужно присвоить доступному только для чтения полю, считывается из внешнего источника (например, из текстового файла или из базы данных). Рассмотрим другой класс, Employee (служащие), который определяет доступную только для чтения строку, изображающую SSN (Social Security Number – номер социальной страховки в США). Чтобы обеспечить пользователю объекта возможность указать это значение, можно использовать следующий вариант программного кода. class Employee { public readonly string SSN; public Employee(string empSSN) { SSN = empSSN; } } Здесь SSN является значением readonly (только для чтения), поэтому любая попытка изменить это значение вне конструктора приведет к ошибке компиляции. static void Main(string[] args) { Employee e = new Employee("111-22-1111"); e.SSN = "222-22-2222"; // Ошибка! } Статические поля только для чтения В отличие от данных-констант, доступные только для чтения поля не причисляются автоматически к группе статических. Если вы хотите использовать значения доступных только для чтения полей на уровне классов, используйте ключевое слово static. class Tire { public static readonly Tire GoodStone = new Tire(90); public static readonly Tire FireYear = new Tire(100); ... } Вот пример использования нового типа Tire. static void Main(string[] args) { Tire myTire = Tire.FireYear; Console.WriteLine("Код ID моих шин: {0}", myTire.manufactureID); } Исходный код. Проект ReadOnlyFields размещен в подкаталоге, соответствующем главе 3. Ключевое слово static Как уже говорилось в этой главе, члены классов (и структур) в C# могут определяться с ключевым cловом static В этом случае соответствующий член должен вызываться непосредственно на уровне класса, а не экземпляра типа. Для иллюстрации рассмотрим "знакомый" тип System.Console. Вы уже могли убедиться, что метод WriteLine() вызывается не с объектного уровня. // Ошибка! WriteLine() – это не метод уровня экземпляра! Console с = new Console(); c.WriteLine ("Так печатать я не могу…"); Вместо этого нужно просто добавить префикс имени типа к имени статического члена WriteLine(). // Правильно! WriteLine() – это статический метод. Console.WriteLine("Спасибо…"); Можно сказать, что статические члены являются элементами, которые (до мнению разработчика типа) оказываются "слишком банальными", чтобы создавать для них экземпляры типа. При создании типа класса вы можете определить любое число статических членов и/или членов уровня экземпляра. Статические методы Рассмотрим следующий класс Teenager (подросток), который определяет статический метод Complain(), возвращающий случайную строку, полученную с помощью вызова частной вспомогательной функции GetRandomNumber(). class Teenager { private static Random r = new Random(); private static int GetRandomNumber(short upperLimit) { return r.Next(upperLimit);} public static string Complain() { string[] messages = new string [5] {"А почему я?", "Он первый начал!", "Я так устал…", "Ненавижу школу!", "Это нечестно!"}; return messages[GetRandomNumber(5)]; } } Обратите внимание на то, что член-переменная System.Random и метод GetRandomNumber(), определяющий вспомогательную функцию, также o6ъявлeны как статические члены класса Teenager, согласно правилу, по которому статические члены могут оперировать только статическими членами. Замечание. Позвольте мне повториться. Статические члены могут воздействовать только на статические члены. Если в статическом методе вы попытаетесь использовать нестатические члены (также называемые данными уровня экземпляра), вы получите ошибку компиляции. Как и в случае любого другого статического члена, чтобы вызвать Complain(), следует добавить префикс имени класса. // Вызов статического метода Complain класса Teenager static void Main(string[] args) { for (int i = 0; i ‹ 10; i++) Console.WriteLine("-› {0}", Teenager.Complain()); } И, как и в случае любого нестатического метода, если бы метод Complain() не был обозначен, как static, нужно было бы создать экземпляр класса Teenager, чтобы вы могли узнать о проблеме дня. // Нестатические данные должна вызываться на объектном уровне. Teenager joe = new Teenager(); joe.Complain(); Исходный код. Проект StaticMethods размещен в подкаталоге, соответствующем главе 3. Статические данные Вдобавок к статическим методам, тип может также определять статические данные (например, член-переменная Random в предыдущем классе Teenager). Следует понимать, что когда класс определяет нестатические данные, каждый объект данного типа поддерживает приватную копию соответствующего поля, Рассмотрим, например, класс, который моделирует депозитный счет, // Этот класс имеет элемент нестатических данных. class SavingsAccount { public double сurrBalance; public SavingsAccount(double balance) {сurrBalance = balance;} } При создании объектов SavingsAccount память для поля сurrBalance выделяется для каждого экземпляра. Статические данные, напротив, размещаются один раз и совместно используются всеми экземплярами объекта данного типа. Чтобы привести пример применения статических данных, добавим в класс SavingsAccount элемент currInterestRate. class SavingsAccount { public double currBalance; public static double currInterestRate = 0.04; public SavingsAccount(double balance) { currBalance = balance; } } Если теперь создать три экземпляра SavingsAccount, как показано ниже static void Main(string[] args) { // Каждый объект SavingsAccount имеет свою копию поля currBalance. SavingsAccount s1 = new SavingsAccount (50); SavingsAccount s2 = new SavingsAccount(100); SavingsAccount s3 = new SavingsAccount(10000.75); } то размещение данных в памяти должно быть примерно таким, как показано на рис. 3.9. 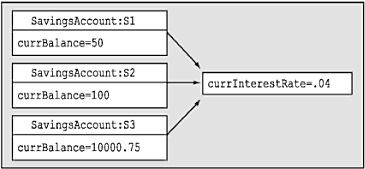 Рис. 3.9. Статические данные совместно используются всеми экземплярами определяющего их класса Давайте обновим класс SavingsAccount, определив два статических метода для получения и установки значений процентной ставки. Как была замечено выше, статические методы могут работать только со статическими данными. Однако нестатический метод может использовать как статические, так и нестатические данные. Это имеет смысл, поскольку статические данные доступны всем экземплярам типа. С учетом этого давайте добавим еще два метода уровня экземпляра, которые будут использовать переменную процентной ставки. class SavingsAccount { public double currBalance; public static double currInterestRate = 0.04; public SavingsAccount(double balance) { currBalance balance;} // Статические методы получения/установки процентной ставки. public static void SetInterestRate(double newRate) { currInterestRate = newRate; } public static double GetInterestRate() { return currInterestRate; } // Методы экземпляра получения/установки текущей процентной ставки. public void SetInterestRateObj(double newRate) { currInterestRate = newRate; } public double GetInterestRateObj() { return currInterestRate; } } Теперь рассмотрим следующий вариант использования этого класса и соответствующий вывод, показанный на рис. 3.10. static void Main(string [] args) { Console.WriteLine("*** Забавы со статическими данными ***"); SavingsAccount s1 = new SavingsAccount(50); SavingsAccount s2 = new SavingsAccount(100); // Получение и установка процентной ставки. Console.WriteLine("Процентная ставка: {0}", s1.GetInterestRateObj()); s2.SetInterestRateObj(0.08); // Создание нового объекта. // Это НЕ 'переустанавливает' процентную ставку. SavingsAccount s3 = new SavingsAccount(10000.75); Console.WriteLine("Процентная ставка: {0}", SavingsAccount.GetlnterestRate()); Console.ReadLine(); } 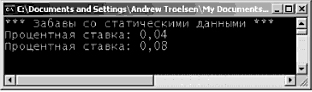 Рис. 3.10. Статические данные размещаются один раз Статические конструкторы Вы уже знаете о том, что конструкторы используются для установки значения данных типа во время его создания, Если указать присваивание значения элементу статических данных в рамках конструктора уровня экземпляра, вы обнаружите, что это значение переустанавливается каждый раз при создании нового объекта! Например, изменим класс SavingsAccount так. class SavingsAccount { public double currBalance; public static double currInterestRate; public SavingsAccount(double balance) { currBalance = balance; currInterestRate = 0.04; } } Если теперь выполнить предыдущий метод Main(), вы увидите совсем другой вывод (рис. 3.11). Обратите внимание на то, что в данном случае переменная currInterestRate переустанавливается каждый раз при создании нового объекта SavingsAccount. 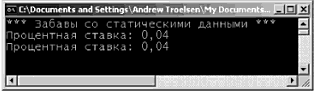 Рис. 3.11. Присваивание значений статическим данным в конструкторе "переустанавливает" эти значения Вы всегда можете установить начальное значение статических данных, используя синтаксис инициализации члена, но что делать, если значение для статических данных нужно получить из базы данных или внешнего файла? Для решения таких задач требуется, чтобы в контексте метода можно было использовать соответствующие операторы программного кода. По этой причине в C# допускается определение статического конструктора. class SavingsAccount { … // Статический конструктор. static SavingsAccount() { Console.WriteLine("В статическом конструкторе."); currInterestRate = 0.04; } } Вот несколько интересных замечаний, касающихся статических конструкторов. • Любой класс (или структура) может определять только один статический конструктор. • Статический конструктор выполняется только один раз, независимо от того, сколько создается объектов данного типа. • Статический конструктор не может иметь модификаторов доступности и параметров. • Среда выполнения вызывает статический конструктор, когда создается экземпляр класса, или перед тем, как получить доступ к первому вызываемому статическому члену. • Статический конструктор выполняется до выполнения любого конструктора уровня экземпляра. Теперь значение статических данных при создании новых объектов SavingsAccount сохраняется, и соответствующий вывод будет идентичен показанному на рис. 3.10. Статические классы Язык C# 2005 расширил область применения ключевого слова static путем введения в рассмотрение статических классов. Когда класс определен, как статический, он не допускает создания экземпляров с помощью ключевого слова new и может содержать только статические члены или поля (если это условие не будет выполнено, вы получите ошибку компиляции). На первый взгляд может показаться, что класс, для которого нельзя создать экземпляр, должен быть совершенно бесполезным. Однако если вы создаете класс, не содержащий ничего, кроме статических членов и/или констант, то нет никакой необходимости и в локализации такого класса. Рассмотрим следующий тип. // Статические классы могут содержать только // статические члены и поля-константы. static class UtilityClass { public static void PrintTime() { Console.WriteLine(DateTime.Now.ToShortTimeString());} public static void PrintDate() {Console.WriteLine(DateTime.Today.ToShortDateString());} } При наличии модификатора static пользователи объекта не смогут создавать экземпляры UtilityClass. static void Main(string[] args) { UtilityClass.PrintDate(); // Ошибка компиляции! // Нельзя создавать экземпляры статических классов. UtilityClass u = new UtilityClass(); … } До появления C# 2005 единственной возможностью для запрета на создание таких типов пользователями объекта было или переопределение конструктора, заданного по умолчанию, как приватного, или обозначение класса, как абстрактного типа, с помощью ключевого слова C# abstract (подробно абстрактные типы обсуждаются в главе 4). class UtilityClass { private UtilityClass(){} … } abstract class UtilityClass { … } Эти конструкции по-прежнему доступны, но с точки зрения типовой безопасности использование статических классов является более выгодным решением, поскольку указанные выше варианты не исключают присутствия нестатических членов в определении класса. Исходный код. Проект StaticData размещен в подкаталоге, соответствующем главе 3. Модификаторы параметров методов Методы (и статические, и уровня экземпляра) могут использовать параметры, передаваемые вызывающей стороной. Однако, в отличие от некоторых других языков программировании, в C# предлагается множество модификаторов параметров, которые контролируют способ передачи (и, возможно, возврата) аргументов для данного метода, как показано в табл. 3.5, Таблица 3.5. Модификаторы параметров C#
Способ передачи параметров, используемый по умолчанию По умолчанию параметр передается в функцию по значению. Попросту говоря, если не определить для аргумента модификатор, то в функцию передаётся копия переменной. // По умолчанию аргументы передаются по значению. public static int Add(int x, int y) { int ans = x + y; // Вызывающая сторона не увидит этих изменений, // поскольку модифицируется копия оригинальных данных. x = 10000; у = 88888; return ans; } Здесь входные целочисленные параметры передаются по значению. Поэтому, если изменить значения параметров внутри данного метода, то вызывающая сторона об этом не узнает, поскольку изменяются значения копий целочисленных данных вызывающего объекта. static void Main(string[] args) { int x = 9, y = 10; Console.WriteLine ("До вызова: X: {0}, Y: {1}", x, y); Console.WriteLine("Ответ: {0}", Add(x, y)); Console.WriteLine("После вызова: X: {0}, Y: {1}", x, у); } Как вы и должны ожидать, значения х и у остаются теми же и после вызова Add(). Модификатор out Теперь рассмотрим использование параметров out (от output – выходной). Если метод определен с выходными параметрами, то необходимо назначить этим параметрам подходящие значения до выхода из метода (если этого не сделать, будет сгенерирована ошибка компиляции). Ниже для иллюстрации предлагается альтернативный вариант метода Add(), использующий C#-модификатор out и возвращающий сумму двух целых чисел в виде выходного параметра (обратите внимание на то, что возвращаемым значением самого метода теперь будет void). // Выходные параметры задаются членом. public static void Add(int x, int y, out int ans) { ans = x + y; } При вызове метода с выходными параметрами тоже требуется указать модификатор out. Локальным переменным, используемым в качестве выходного параметра, не требуется присваивать значения до их использования (эти значения после вызова все равно будут потеряны), Например: static void Main(string[] args) { // Нет необходимости задавать значения // локальным выходным переменным. int ans; Add(90, 90, out ans); Console.WriteLine("90 + 90 = {0} ", ans); } Этот пример предлагается здесь только для иллюстрации: нет никакой необходимости возвращать значение суммы с помощью выходного параметра. Но сам модификатор out играет очень важную роль: он позволяет вызывающей стороне получить множество возвращаемых значений от одного вызова метода. // Возвращение множества выходных параметров. public static void FillTheseVals(out int a, out string b, out bool c) { а = 9; b = "Радуйтесь своей строке."; с = true; } Вызывающая сторона может вызвать этот метод следующим образом. static void Main(string[] args) { int i; string str; bool b; FillTheseVals(out i, out str, out b); Console.WriteLine("Int равно: {0}", i); Console.WriteLine("String равно: (0}", str); Console.WriteLine("Boolean равно: {0}", b); } Модификатор ref Теперь рассмотрим, использование в C# модификатора ref (от reference – ссылочный). Ссылочные параметры нужны тогда, когда требуется позволить методу изменять данные, объявленные в контексте вызова (например, в функциях сортировки или обмена данными). Обратите внимание на различие между выходными и ссылочными параметрами. • Выходные параметры не требуется инициализировать перед передачей их методу. Причина в том, что сам метод должен присвоить значения выходным параметрам. • Ссылочные параметры необходимо инициализировать до того, как они будут переданы методу. Причина в том, что передается ссылка на существующую переменную. Если не присвоить переменной начальное значение, это будет означать использование неинициализированной переменной. Давайте продемонстрируем использование ключевого слова ref с помощью метода, в котором осуществляется обмен значениями двух строк. // Ссылочные параметры. public static void SwapStrings(ref string s1, ref string s2) { string tempStr = s1; s1 = s2; s2 = tempStr; } Этот метод можно вызвать так. static void Main(string[] args) { string s = "Первая строка"; string s2 = "Вторая строка"; Console.WriteLine("До: {0}, {1} ", s, s2); SwapStrings(ref s, ref s2); Console.WriteLine("После: {0}, {1} ", s, s2); } Здесь вызывающая сторона присваивает начальное значение локальным строковым данным (s и s2). По завершении вызова SwapStrings() строка s содержит значение "Вторая строка", a s2 – значение "Первая строка". Модификатор params Нам осталось рассмотреть модификатор params, позволяющий создавать методы, которым можно направить множество однотипных аргументов в виде одного параметра. Чтобы прояснить суть дела, рассмотрим метод, возвращающий среднее для любого числа значений, // Возвращение среднего для 'некоторого числа' значений. static double CalculateAverage(params double[] values) { double sum = 0; for (int i = 0; i ‹ values.Length; i++) sum += values[i]; return (sum / values.Length); } Этот метод принимает массив параметров, состоящий из значений с двойной точностью. Метод фактически говорит следующее: "Дайте мне любой набор значений с двойной точностью, и я вычислю для них среднюю величину". Зная это, вы можете вызвать CalculateAverage() одним из следующих способов (если не использовать модификатор params в определении CalculateAverage(), то первый из указанных ниже вариантов вызова этого метода должен привести к ошибке компиляции). static void Main(string[] args) { // Передача в виде списка значений, разделенных запятыми,.… double average; average = CalculateAverage(4.0, 3.2, 5.7); Console.WriteLine("Среднее 4.0, 3.2, 5.7 равно: {0}", average); //… или передача в виде массива значений. double[] data = {4.0, 3.2, 5.7}; average = CalculateAverage(data); Console.WriteLine ("Среднее равно: {0}", average); Console.ReadLine(); } Это завершает наше вводное обсуждение модификаторов параметров. Мы снова обратимся к этой теме немного позже (в этой же главе), когда будем обсуждать различия между типами значений и ссылочными типами. А пока что давайте рассмотрим итерационные и условные конструкции языка программирования C#. Исходный код. Проект SimpleParams размещен в подкаталоге, соответствующем главе 3. Итерационные конструкции Все языки программирования предлагают конструкции обеспечивающие возможность повторения блоков программного кода, пока не выполнено условие завершения повторений. Если у вас есть опыт программирования, то операторы цикла в C# будут для вас понятными и не должны требовать пространных объяснений. В C# обеспечиваются следующие четыре итерационные конструкции: • цикл for; • цикл foreach/in; • цикл while; • цикл do/while. Давайте рассмотрим все указанные конструкции по очереди. Цикл for Когда требуется повторить блок программного кода определенное число раз, оператор for подходит для этого лучше всего. Вы можете указать, сколько раз должен повториться блок программного кода, а также условие окончания цикла. Без лишних объяснений, вот вам соответствующий образец синтаксиса. // База для цикла. static void Main(string[] args) { // Переменная 'i' доступна только в контексте этого цикла for. for(int i = 0; i ‹ 10; i++) { Console.WriteLine("Значение переменной: {0} ", i); } // Здесь переменная 'i' недоступна. } Все ваши привычные приемы использования циклов C, C++ и Java применимы и при построении операторов for в C#. Вы можете создавать сложные условия окончания цикла, строить бесконечные циклы, а также использовать ключевые слова goto, continue и break. Я думаю, что эта итерационная конструкция будет вам понятна. Если же вам требуются дальнейшие объяснения по поводу ключевого слова fоr в C#, используйте документацию .NET Framework 2.0 SDK. Цикл foreach Ключевое слово C# foreach позволяет повторить определенные действия для всех элементов массива без необходимости выяснения размеров массива. Вот два примера использования foreach, один для массива строк, а другой – для массива целых, чисел. // Прохождение массива с помощью foreach. static void Main(string[] args) { string[] books = {"Сложные алгоритмы", "Классическая технология COM", "Язык C# и платформа .NET"}; foreach(string s in books) Console.WriteLine(s); int[] myInts = {10, 20, 30, 40}; foreach(int i in myInts) Console.Writeline(i); } В дополнение к случаю простых массивов, foreach можно использовать и для просмотра системных и пользовательских коллекций. Обсуждение соответствующих подробностей предполагается в главе 7, поскольку этот вариант применения ключевого слова foreach предполагает понимание интерфейсного программирования и роли интерфейсов IEnumerator и IEnumerable. Конструкции while и do/while Цикл while оказывается полезным тогда, когда блок операторов должен выполняться до тех пор, пока не будет достигнуто заданное условие. Конечно, при этом требуется, чтобы в области видимости цикла while было определено условие окончания цикла, иначе вы получите бесконечный цикл. В следующем примере сообщение "в цикле while" будет печататься до тех пор, пока пользователь не введет значение "да" в командной строке. static void Main(string[] args) { string userIsDone = "нет"; // Проверка на соответствие строке в нижнем регистре. while(userIsDone.ToLower() != "да") { Console.Write("Вы удовлетворены? [да] [нет]: "); userIsDone = Console.ReadLine(); Console.WriteLine{"В цикле while"); } } Цикл do/while подобен циклу while. Как и цикл while, цикл do/while используется для выполнения последовательности действий неопределенное число раз. Разница в том, что цикл do/while гарантирует выполнение соответствующего блока программного кода как минимум один раз (простой цикл while может не выполниться ни разу, если условие его окончания окажется неверным с самого начала). static void Main(string[] args) { string userlsDone = ""; do { Console.WriteLine("В цикле do/while"); Console.Write("Вы удовлетворены? [да] [нет]: "); userIsDone = Console.ReadLine(); } while(userIsDone.ToLower() != "да"); // Обратите внимание на точку с запятой! } Конструкции выбора решений и операции сравнения В C# определяются две простые конструкции, позволяющие изменить поток выполнения программы по набору условий: • оператор if/else; • оператор switch. Оператор if/else В отличие от C и C++, оператор if/else в C# может работать только с булевыми выражениями, а не с произвольными значениями -1, 0. Поэтому в операторах if/else обычно используются операции C#, показанные в табл. 3.6. чтобы получить буквальные булевы значения. Таблица 3.6. Операции сравнения в C#
Программистам, использующим C и C++, следует обратить внимание на то, что их привычные приемы по проверке условий "на равенство нулю" в C# работать не будут. Например, вы хотите выяснить, будет ли данная строка длиннее пустой строки. Может возникнуть искушение написать следующее. // В C# это недопустимо, поскольку Length возвращает int, а не bool. string thoughtOfThеDay = "Старую coбaку новым трюкам научить МОЖНО"; if (thoughtOfTheDay.Length) { … } В данном случае для использования cвойства String.Length нужно изменить условие так, как показано ниже.
if (0 != thoughtOfTheDay.Length) Чтобы обеспечить более сложную проверку, оператор if может содержать сложные выражения и другие операторы, Синтаксис C# в данном случае идентичен C(++) и Java (и не слишком отличается от Visual Basic). Для построения сложных выражений C# имеет вполне отвечающий ожиданиям набор условных операций, описания которых предлагаются в табл. 3.7. Таблица 3.7. Условные операции в C#
Оператор switch Другой простой конструкцией выбора, предлагаемой в C#, является оператор switch. Как и в других языках типа C, оператор switch позволяет обработать поток выполнения программы на основе заданного набора вариантов. Например, следующий метод Main() позволяет печатать строку, зависящую от выбранного варианта (случай default предназначен для обработки непредусмотренных вариантов выбора). // Переключение по числовому значению. static void Main(string[] args) { Console.WriteLine("1 [C#], 2 [VB]"); Console.Write("Выберите язык, который вы предпочитаете: "); string langChoice = Console.ReadLine(); int n = int.Parse(langChoice); switch (n) { case 1: Console.WriteLine("Отлично! C# – это прекрасный язык."); break; case 2: Console.WriteLine("VB .NET: ООП, многозадачность и т.д.!"); break; default: Console.WriteLine("Хорошо… удачи вам с таким выбором!"); break; } } Замечание. В C# требуется, чтобы каждый вариант выбора (включая default), содержащий выполняемые операторы, завершался оператором break или goto, во избежание прохода сквозь структуру при невыполнении условия. Приятной особенностью оператора switch в C# является то, что в рамках этого оператора вы можете оценивать не только числовые, но и строковые данные. Именно это используется в следующем операторе switch (при таком подходе нет необходимости переводить пользовательские данные в числовые значения). static void Main(string[] args) { Console.WriteLine("C# или VB"); Console.Write("Выберите язык, который вы предпочитаете: "); string langChoice = Console.ReadLine(); switch (langChoice) { case "C#": Console.WriteLine("Отлично! C# – это прекрасный язык. "); break; case "VB": Console.WriteLine("VB .NET: ООП, многозадачность и т.д.!"); break; default: Console.WriteLine("Хорошо… удачи вам с таким выбором!"); break; } } Исходный код. Проект IterationsAndDeсisions размещен в подкаталоге, соответствующем главе 3. Типы, характеризуемые значениями, и ссылочные типы Подобно любому другому языку программирования, язык C# определяет ряд ключевых слов, представляющих базовые типы данных, такие как целые числа, символьные данные, числа с плавающим десятичным разделителем и логические (булевы) значения. Если вы работали с языком C++, то будете рады узнать, что здесь эти внутренние типы являются "фиксированными константами", т.е., например, после создания элемента целочисленных данных все языки .NET будут понимать природу этого типа и диапазон его значений, Тип данных .NET может либо характеризоваться значением, либо быть ссылочным типом (т.е. характеризоваться ссылкой). К типам, характеризуемым значением, относятся все числовые типы данных (int, float и т.д.), а также перечни и структуры, размещаемые в стеке. Поэтому типы, характеризуемые значениями, можно сразу же удалить из памяти, как только они оказываются вне контекста их определений. // Целочисленные данные характеризуются значением! public void SomeMethod() { int i = 0; Console.WriteLine(i); } // здесь 'i' удаляется из стека. Когда вы присваиваете один характеризуемый значением тип другому, по умолчанию выполняется "почленное" копирование. Для числовых и булевых типов данных единственным "членом", подлежащим копированию, является непосредственное значение переменной, // Для типов, характеризуемых значениями, в результате такого // присваивания в стек помещаются две независимые переменные. public void SomeMethod() { int i = 99; int j = i; // После следующего присваивания значением 'i' останется 99. j = 8732; } Этот пример может не содержать для вас ничего нового, но важно понять, что .NET-структуры (как и перечни, которые будут рассмотрены в этой главе позже) тоже являются типами, характеризуемыми значением. Структуры, в частности, дают возможность использовать основные преимущества объектно-ориентированного подхода (инкапсуляции) при сохранении эффективности размещения данных в стеке. Подобно классам, структуры могут использовать конструкторы (с аргументами) и определять любое число членов. Все структуры неявно получаются из класса System.ValueType. С точки зрения функциональности, единственной целью System.ValueType является "переопределение" виртуальных методов System.Object (этот объект будет описан чуть позже) с целью учета особенностей семантики типов, заданных значениями, в противоположность ссылочным типам. Методы экземпляра, определенные с помощью System.ValueType, будут идентичны соответствующим методам System.Object. // Структуры и перечни являются расширениями System.ValueType. public abstract class ValueType: object { public virtual bool Equals(object obj); public virtual int GetHashCode(); public Type GetType(); public virtual string ToString(); } Предположим, что вы создали C#-структуру с именем MyPoint, используя ключевое слово C# struct.
struct MyPoint { public int x, у; } Чтобы разместить в памяти тип структуры, можно использовать ключевое слово new, что, кажется, противоречит интуиции, поскольку обычно подразумевается, что new всегда размещает данные в динамически распределяемой памяти. Это частица общего "тумана", сопровождающего CLR. Мы можем полагать, что вообще все в программе является объектами и значениями, создаваемыми с помощью new. Однако в том случае, когда среда выполнения обнаруживает тип. полученный из System.ValueType, выполняется обращение к стеку. // Все равно используется стек! MyPoint р = new MyPoint(); Структуры могут создаваться и без использования ключевою слова new. MyPoint p1; p1.x = 100; p1.y = 100; Но при использовании этого подхода вы должны выполнить инициализацию всех полей данных до их использования. Если этого не сделать, возникнет ошибка компиляции. Типы, характеризуемые значениями, ссылочные типы и оператор присваивания Теперь изучите следующий метод Main() и рассмотрите его вывод, показанный на рис. 3.12. static void Main(string[] args) { Console.WriteLine("*** Типы, характеризуемые значением / Ссылочные типы ***"); Console.WriteLine(''-› Создание p1"); MyPoint p1 = new MyPoint(); p1.x = 100; p1.у = 100; Console.WriteLine("-› Приcваивание p1 типу p2\n"); MyPoint p2 = p1; // Это p1. Console.WriteLine"p1.x = {0}", p1.x); Console.WriteLine"p1.y = {0}", p1.y); // Это р2. Console.WriteLine("p2.x = {0}", p2.x); Console.WriteLine("p2.у = {0}", p2.y); // Изменение p2.x. Это НЕ влияет на p1.x. Console.WriteLine("-› Замена значения p2.x на 900"); р2.х = 900; // Новая печать. Console.WriteLine("-› Это снова значения х… "); Console.WriteLine("p1.x = {0}", p1.x); Console.WriteLine("p2.x = {0}", р2.х); Console ReadLine(); } 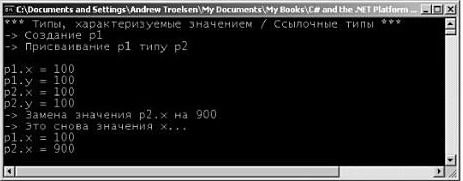 Рис. 3.12. Для типов, характеризуемых значениями, присваивание означает буквальное копирование каждого поля Здесь создается переменная типа MyPoint (с именем p1), которая затем присваивается другой переменной типа MyPoint (р2). Ввиду того, что MyPoint является типом, характеризуемым значением, в результате в стеке будет две копии типа MyPoint, каждая из которых может обрабатываться независимо одна от другой. Поэтому, когда изменяется значение р2.х, значение p1.x остается прежним (точно так же, как в предыдущем примере с целочисленными данными). Ссылочные типы (классы], наоборот, размещаются в управляемой динамически распределяемой памяти (managed heap). Эти объекты остаются в памяти до тех пор, пока сборщик мусора .NET не уничтожит их. По умолчанию в результате присваивания ссылочных типов создается новая ссылка на тот же объект в динамической памяти. Для иллюстрации давайте изменим определение типа MyPoint со структуры на класс. // Классы всегда оказываются ссылочными типами, class MyPoint { // ‹= Теперь это класс! public int х, у; } Если выполнить программу теперь, то можно заметить изменения в ее поведении (рис. 3.13). 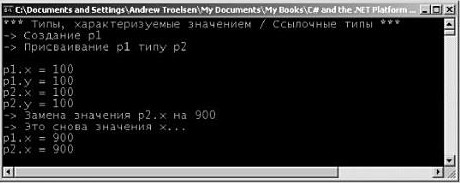 Рис. 3.13. Для ссылочных типов присваивание означает копирование ссылки В данном случае имеется две ссылки на один и тот же объект в управляемой динамической памяти. Поэтому, если изменить значение x с помощью ссылки р2, то мы увидим, что p1.х укажет на измененное значение. Типы, характеризуемые значениями и содержащие ссылочные типы Теперь, когда вы чувствуете разницу между типами, характеризуемыми значением, и ссылочными типами, давайте рассмотрим более сложный пример. Предположим, что имеется следующий ссылочный тип (класс), обрабатывающий информационную строку, которую можно установить с помощью пользовательского конструктора. class ShapeInfo { public string infoString; public ShapeInfo(string info) { infoString = info; } } Предположим также, что вы хотите поместить переменную этого типа класса в тип с именем MyReсtangle (прямоугольник), характеризуемый значением. Чтобы позволить внешним объектам устанавливать значение внутреннего поля ShapeInfо, вы должны создать новый конструктор (при этом конструктор структуры, заданный по умолчанию, является зарезервированным и не допускает переопределения). struct MyRectangle { // Структура MyRectangle содержит член ссылочного типа. public ShapeInfo reсtInfo; public int top, left, bottom, right; public MyRactangle(string info) { rectInfo = new ShapeInfo(info); top = left = 10; bottom = right = 100; } } Теперь вы имеете ссылочный тип. внутри типа, характеризуемого значением. И здесь возникает вопрос на миллион долларов: что случится, если присвоить одну переменную типа MyRectangle другой такой же переменной? С учетом того, что вы уже знаете о типах, характеризуемых значениями, вы можете сделать правильное предположение о том, что целые данные (которые на самом деле и формируют эту структуру) для каждой переменной MyRectangle должны быть независимыми элементами. Но что можно сказать о внутреннем ссылочном типе? Будет скопировано полное состояние этого объекта или будет скопирована ссылка на этот объект? Проанализируйте следующий программный код и рассмотрите рис. 3.14, который может подсказать правильный ответ. static void Main(string[] args) { // Создание первого объекта MyRectangle. Console.WriteLine("-› Создание r1"); MyRectangle r1 = new MyRectangle("Это мой первый прямоугольник"); // Присваивание новому MyRectangle значений r1. Console.WriteLine("-› Присваивание r1 типу r2"); MyRectangle r2; r2 = r1; // Изменение значений r2. Console.WriteLine("-› Изменение значений r2"); r2.rectInfo.InfoString = "Это новая информация!"); r2.bottom = 4444; // Print values Console.WriteLine("-› Значения после изменений:"); Console.WriteLine("-› r1.rectInfo.infoString: {0}", r1.rectInfo.infoString); Console.WriteLine("-› r2.rectInfo.infoString: {0}", r2.rectInfo.infoString); Console.WriteLine("-› r1.bottom: {0}", r1.bottom); Console.WriteLine("-› r2.bottom: {0}", r2.bottom); } 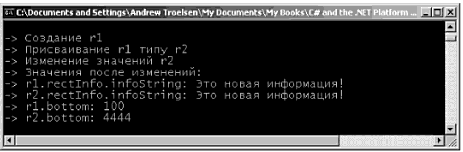 Рис. 3.14. Внутренние ссылки указывают на один и тот же объект Как видите, при изменении значения информирующей строки с помощью ссылки r2 ссылка r1 отображает точно такое же значение. По умолчанию, когда тип, характеризуемый значением, содержит ссылочные типы, присваивание приводит к копированию ссылок. В результате вы получаете две независимые структуры, каждая из которых содержит ссылки, указывающие на один и тот же объект в памяти (т.е. "поверхностную копию"). Если вы хотите иметь "детальную копию", когда состояние внутренних ссылок полностью Копируется в новый объект, необходимо реализовать интерфейс ICloneable (это будет обсуждаться в главе 7). Исходный код. Проект ValAndRef размещен в подкаталоге, соответствующем главе 3. Передача ссылочных типов по значению Очевидно, что ссылочные типы могут передаваться членам типов, как параметры. Но передача объекта по ссылке отличается от его передачи по значению. Чтобы понять суть различий, предположим, что у нас есть класс Person (персона), определенный следующим образом. class Person { public string fullName; public byte age; public Person(string n, byte a) { fullName = n; age = a; } public Person() {} public void PrintInfo() { Console.WriteLine("{0}, {1} года (лет)", fullName, age); } } Теперь создадим метод, который позволяет вызывающей стороне переслать тип Person по значению (обратите внимание на отcутcтвие модификаторов параметра). public static void SendAPersonByValue(Person p) { // Изменяет ли это возраст 'р'? p.age = 92; // Увидит ли вызывающая сторона такие изменения? p = new Person ("Никки", 192); } Обратите внимание на то, что метод SendAPersonByValue() пытается изменить получаемую ссылку Person на новый объект, а также изменить некоторые данные состояния. Давайте проверим работу этого метода, используя следующий метод Main(). static void Main(string[] args) { // Передача ссылочных типов по значению. Console.WriteLine("*** Передача объекта Person по значению ***"); Person fred = new Persоn("Фред", 2); Console.WriteLine("Person до вызова по значению"); fred.PrintInfo(); SendAPersonByValue(fred); Console.WriteLine("Persоn после вызова по значению"); fred.PrintInfо(); } На рис. 3.15 показан соответствующий вывод. 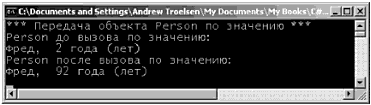 Рис. 3.15. Передача ссылочных типов по значению блокирует соответствующую ссылку Как видите, значение возраста (age) изменяется. Кажется, такое поведение при передаче параметра противоречит самому термину "по значению". Если вы способны изменить состояние получаемого объекта Person, что же все-таки копируется? Ответ здесь следующий: в объект вызывающей стороны копируется ссылка. Поэтому, поскольку метод SendAPersonByValue() и объект вызывающей стороны указывают на один и тот же объект, можно изменить состояние данных объекта. Что здесь невозможно, так это изменить саму ссылку так, чтобы она указывала на другой объект (это напоминает ситуацию с постоянными указателями в C++). Передача ссылочных типов по ссылке Теперь предположим, что у нас есть метод SendAPersonByReference(), который передает ссылочный тип по ссылке (обратите внимание на то, что здесь присутствует модификатор параметра ref). public static void SendAPersonByReference(ref Person p) { // Изменение некоторых данных 'р'. p.age = 122; // Теперь 'р' указывает на новый объект в динамической памяти! р = new Person("Никки", 222); } Как вы можете догадаться сами, это обеспечивает вызывающей стороне полную гибкость в управлении входными параметрами. Вызывающая сторона не только может изменить состояние объекта, но и переопределить ссылку так, чтобы она указывала на новый тип Person. Рассмотрите следующий вариант. static void Main(string[] args) { // Передача ссылочных типов по ссылке. Console.WriteLine("\n*** Передача объекта Person по ссылке ***"); Person mel = new Person("Мэл", 23); Console.WriteLine("Person до вызова по ссылке:"); mel.PrintInfo(); SendAPersonByReference(ref mel); Console.WriteLine("Person после вызова по ссылке:"); mel.PrintInfо(); } Из рис. 3.16 видно, что тип с именем Мэл возвращается после вызова как тип с именем Никки. 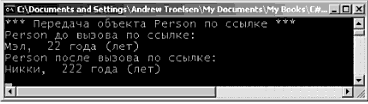 Рис. 3.16. Передача ссылочных типов по ссылке позволяет перенаправить ссылку Золотым правилом при передаче ссылочных типов по ссылке является следующее. • Если ссылочный тип передается по ссылке, то вызывающая сторона может изменить не только состояние данных соответствующего объекта, но сам объект ссылки. Исходный код. Проект RefTypeValTypeParams размещен в подкаталоге, соответствующем главе 3. Типы, характеризуемые значениями, и ссылочные типы: заключительные замечания Чтобы завершить обсуждение данной темы, изучите информацию табл. 3.8, в которой приводится краткая сводка основных отличий между типами, характеризуемыми значением, и ссылочными типами. Таблица 3.8. Сравнение типов, характеризуемых значением, и ссылочных типов
Несмотря на указанные отличия, и типы, характеризуемые значением, и ссылочные типы могут реализовывать интерфейсы и поддерживать любое число полей, методов, перегруженных операций, констант, свойств и событий. Операции создания объектного образа и восстановления из объектного образа Ввиду того, что в .NET определяются две главные категории типов (характеризуемые значением или ссылкой), может понадобиться представление переменной одной категории в виде переменной другой категории. В C# предлагается очень простой механизм, называемый операцией создания объектного образа (boxing), позволяющий превратить тип, характеризуемый значением, в ссылочный тип. Предположим, что вы создали переменную типа short. // Создание значения типа short. short s =25; Если в приложении потребуется конвертировать этот тип значения в ссылочный тип, вы должны "упаковать" это значение так, как показано ниже. // "Упаковка" значения в объектную ссылку. object objShort = s; Операцию создания объектного образа можно формально определить, как процесс явного преобразования типа, характеризуемого значением, в соответствующий ссылочный тип с помощью сохранения переменной в System.Object. Когда значение преобразуется в объектный тип, среда CLR размещает новый объект в динамической памяти и копирует значение соответствующего типа (в данном случае это значение 25) в созданный экземпляр. Вам возвращается ссылка на новый размещенный в памяти объект. При использований такого подхода у разработчика .NET не возникает необходимости использовать интерфейсные классы, чтобы временно обращаться с данными стека как с объектами, размещенными в динамической памяти. Обратная операция тоже предусмотрена, и называется она восстановлением из объектного образа (unboxing). Восстановление из объектного образа является процессом обратного преобразования значения, содержащегося в объектной ссылке, в значение соответствующего типа, размещаемое в стеке. Операция восстановления из объектного образа начинается с проверки того, что тип данных, в который выполняется восстановление, эквивалентен типу, который был приведён к объекту. Если это так, то выполняется обратное копирование соответствующего значения в локальную переменную в стеке. Например, следующая операция восстановления из объектного образа будет выполнена успешно, поскольку соответствующий тип objShort действительно имеет тип short (операцию преобразования типов в C# мы рассмотрим подробно в следующей главе, а пока что не слишком беспокойтесь о деталях). // Обратное преобразование ссылки в соответствующее значение short. short anotherShort = (short)objShort; Снова обратим ваше внимание на то, что восстановление следует выполнять в соответствующий тип данных. Так, следующая программная логика восстановления из объектного образа генерирует исключение InvalidCastException (обсуждение вопросов обработки исключений содержится в главе 6). // Некорректное восстановление из объектного образа. static void Main(string[] args) { … try { // Тип в "yпаковке" - это HE int, a shоrt! int i = (int)objShort; } catch(InvalidCastExceptien e) { Console.WriteLine("ОЙ!\n{0} ", e.ToString()); } } Примеры создания объектных образов и восстановления значений Вы, наверное, спросите, когда действительно бывает необходимо вручную выполнять преобразование в объектный тип (или восстановление из объектного образа)? Предыдущий пример был исключительно иллюстративным, поскольку в нем для данных short не было никакой реальной необходимости приведении к объектному типу (с последующим восстановлением данных из объектного образа). Реальность такова, что необходимость вручную приводить данные к объектному типу возникает очень редко – если возникает вообще. В большинстве случаев компилятор C# выполняет такие преобразования автоматически. Например, при передаче типа, характеризуемого значением, методу, предполагающему получение объектного параметра, автоматически "в фоновом режиме" происходит приведение к объектному типу. class Program { static void Main(string[] args) { // Создание значения int (тип, характеризуемый значением). int myInt = 99; // myInt передается методу, предполагающему // получение объекта, поэтому myInt приводится // к объектному типу автоматически. UseThisObject(myInt); Console.ReadLine(); } static void UseThisObject(object o) { Console.WriteLine("Значением о является: {0}", о);} } Автоматическое преобразование в объектный тип происходит и при работе c типами библиотек базовых классов .NET. Например, пространство имен System.Collections (формально оно будет обсуждаться в главе 7) определяет тип класса с именем ArrayList. Подобно большинству других типов коллекций, ArrayList имеет члены, позволяющие вставлять, получать и удалять элементы. public class System.Collections.ArrayList: object, System.Collections.IList, System.Collections.ICollection, System.Collections.IEnumerable, ICloneable { … public virtual int Add(object value); public virtual void Insert(int index, object value); public virtual void Remove(object obj); public virtual object this[int index] {get; set;} } Как видите, эти члены действуют на типы System.Object. Поскольку все, в конечном счете, получается из этого общего базового класса, следующий программный код оказывается вполне корректным. static void Main(string [] args) { … ArrayList myInts = new ArrayList(); myInts.Add(88); myInts.Add(3.33); myInts.Add(false); } Но теперь с учетом вашего понимания ссылочных типов и типов, характеризуемые значением, вы можете спросить: что же на самом деле размещается в ArrayList? (Ссылки? Копии ссылок? Копии структур?) Как и в случае, с рассмотренным выше методом UseThisObject(), должно быть ясно, что каждый из типов данных System.Int32 перед размещением в ArrayList в действительности приводится к объектному типу. Чтобы восстановить элемент из типа ArrayList, требуется выполнить соответствующую операцию восстановления. static void BoxAndUnboxInts() { // "Упаковка" данных int в ArrayList. ArrayList myInts = new ArrayList(); myInts.Add(88); myInts.Add(3.33); myInts.Add(false); // Извлечение первого элемента из ArrayList. int firstItem = (int)myInts[0]; Console.WriteLine("Первым элементом является {0}", firstItem); } Без сомнения, операции приведения к объектному типу и восстановления из объектного образа требуют времени и, если эти операций использовать без ограничений, это может влиять на производительность приложения. Но с использованием такого подхода .NET вы можете симметрично работать с типами характеризуемыми значением, и со ссылочными типами. Замечание. В C# 2.0 потери производительности из-за приведения к ссылочному типу и восстановления из объектного образа можно нивелировать путем использования обобщений (generics), которые будут рассмотрены в главе 10. Восстановление из объектного образа для пользовательских типов Когда методу, предполагающему получение экземпляров System.Object, передаются пользовательские структуры или перечни, тоже происходит их приведение к объектному типу, Однако после получения входного параметра вызванным методом вы не сможете получить доступ к каким бы то ни было членам структуры (или перечня), пока не выполните операцию восстановлений из объектного образа для данного типа. Вспомним структуру МуРoint, определенную в этой главе выше. Struct MyPoint { public int x, у; } Предположим, что вы посылаете переменную MyPoint новому методу с именем UseBoxedMyPoint(). static void Main(string[] args) { … MyPoint p; p.x = 10; p.y = 20; UseBoxedMyPoint(p); } При попытке получить доступ к полю данных MyPoint возникнет ошибка компиляции, поскольку метод предполагает, что вы действуете на строго типизованный System.Object. static void UseBoxedMyPoint(object o) { // Ошибка! System.Object не имеет членов-переменных // с именами 'х' и 'у' . Console.WriteLine ("{0}, {1}", о.х, о.у); } Чтобы получить доступ к полю данных MyPoint, вы должны сначала восстановить параметр из объектного образа. Сначала можно использовать ключевое слово C# is для проверки того, что этот параметр на самом деле является переменной MyPoint. Ключевое слово is рассматривается в главе 4, здесь мы только предлагаем пример его использования. static void UseBoxedMyPoint(object о) { if (о is MyPoint) { MyPoint p = (MyPoint)o; Console.WriteLine ("{0}, {1}", p.x, p.y); } else Console.WriteLine("Вы прислали не MyPoint."); } Исходный код. Проект Boxing размещен в подкаталоге, соответствующем главе 3. Работа с перечнями .NET Вдобавок к структурам в .NET имеется еще один тип из категории характеризуемых значением – это перечни. При создании программы часто бывает удобно создать набор символьных имен для представления некоторых числовых значений. Например, при создании системы учета оплаты труда работников предприятия вы предпочтете использовать константы Manager (менеджер), Grunt (рабочий), Contractor (подрядчик) и VP (вице-президент) вместо простых числовых значений {0, 1, 2, 3}. Именно по этой причине в C# поддерживаются пользовательские перечни. Например, вот перечень EmpType. // Пользовательский перечень. enum EmpType { Manager, // = 0 Grunt, // = 1 Contractor, // = 2 VP // = 3 } Перечень EmpType определяет четыре именованные константы, соответствующие конкретным числовым значениям. В C# схема нумерации по умолчанию предполагает начало с нулевого элемента (0) и нумерацию последующих элементов по правилам арифметической прогрессии n + 1. При необходимости вы имеете возможность изменить такое поведение на более удобное. // начало нумерации со значения 102. enum EmpType { Manager = 102, Grunt, // = 103 Contractor, // =104 VP // = 105 } Перечни не обязаны следовать строгому последовательному порядку нумерации элементов. Если (по некоторой причине) вы сочтете разумным создать EmpType так, как показано ниже, компилятор примет это без возражений. // Элементы перечня не обязаны следовать в строгой последовательности! enum EmpType { Manager = 10, Grunt = 1, Contractor = 100, VP = 9 } Тип, используемый для каждого элемента в перечне, по умолчанию отображается в System.Int32. Такое поведение при необходимости тоже можно изменить. Например, если вы хотите, чтобы соответствующее хранимое значение EmpTyре было byte, а не int, вы должны написать следующее. // Теперь EmpType отображается в byte. enum EmpType: byte { Manager = 30, Grunt = 1, Contractor = 100, VP = 9 } Замечание. Перечни в C# могут определяться в унифицированной форме для любого из числовых типов (byte, sbyte, short, ushort, int, uint, long или ulong). Это может быть полезно при создании программ для устройств с малыми объемами памяти, таких как КПК или сотовые телефоны, совместимые с .NET. Установив диапазон и тип хранения для перечня, вы можете использовать его вместо так называемых "магических чисел". Предположим, что у вас есть класс, определяющий статическую функцию с единственным параметром EmpType. static void AskForBonus(EmpType e) { switch(e) { case EmpType.Contractor: Console.WriteLine("Вам заплатили достаточно…"); break; case EmpType.Grunt: Console.WriteLine("Вы должны кирпичи укладывать…"); break; case EmpType.Manager: Console.WriteLine("Лучше скажите, что там с опционами!"); break; case EmpType.VP: Console.WriteLine("ХОРОШО, сэр!"); break; default: break; } } Этот метод можно вызвать так. static void Main(string[] args) { // Создание типа contractor. EmpType fred; fred = EmpType.Contractor; AskForBonus(fred); } Замечание. При ссылке на значение перечня всегда следует добавлять префикс имени перечня (например, использовать EmpType.Grunt, а не просто Grunt). Базовый класс System.Enum Особенностью перечней .NET является то, что все они неявно получаются из System.Enum. Этот базовый класс определяет ряд методов, которые позволяют опросить и трансформировать перечень. В табл. 3.9 описаны некоторые из таких методов, и все они являются статическими. Таблица 3.9. Ряд статических членов System.Enum
Статический метод Enum.Format() можно использовать с флагами форматирования, которые рассматривались выше при обсуждении System.Console. Например, можно извлечь строку c именем (указав G), шестнадцатиричное (X) или числовое значение (D, F и т.д.). В System.Enum также определяется статический метод GetValues(). Этот метод возвращает экземпляр System.Array (мы обсудим этот объект немного позже), в котором каждый элемент соответствует паре "имя-значение" данного перечня. Для Примера рассмотрите следующий фрагмент программного кода. static void Main (string[] args) { // Печать информации для перечня EmpType. Array obj = Enum.GetValues(typeof(EmpType)); Console.WriteLine("В этом перечне {0} членов.", obj.Length); foreach(EmpType e in obj) { Console.Write("Строка с именем: {0},", e.ToString()); Console.Write("int: ({0}), ", Enum.Format(typeof(EmpType), e, "D")); Console.Write("hex: ({0})\n", Enum.Format(typeof(EmpType), e, "X")); } } Как вы сами можете догадаться, этот блок программного кода для перечня EmpType печатает пары "имя-значение" (в десятичном и шестнадцатиричном формате). Теперь исследуем свойство IsDefined. Это свойство позволяет выяснить, является ли данная строка членом данного перечня. Предположим, что нужно выяснить, является ли значение SalesPerson (продавец) частью перечня EmpType. Для этого вы должны послать указанной функции информацию о типе перечня и строку, которую требуется проверить (информацию о типе можно получить с помощью операции typeof, которая подробно рассматривается в главе 12). static void Main(string[] args) { … // Есть ли значение SalesPerson в EmpType? if (Enum.IsDefined(typeof(EmpType), "SalesPerson")) Console.WriteLine("Да, у нас есть продавцы."); else Console.WriteLine("Нет, мы работаем без прибыли…"); } С помощью статического метода Enum.Parse() можно генерировать значения перечня, соответствующие заданному строковому литералу. Поскольку Parse() возвращает общий System.Object, нужно преобразовать возвращаемое значение в нужный тип. // Печатает "Sally is a Manager". EmpType sally = (EmpType)Enum.Parse(typeof(EmpType), "Manager"); Console.WriteLine("Sally is a {0}", sally.ToString()); И последнее, но не менее важное замечание: перечни в C# поддерживают различные операции, которые позволяют выполнять сравнения с заданными значениями, например: static void Main(string[] args) { … // Какая из этих переменных EmpType // имеет большее числовое значение? EmpType Joe = EmpType.VP; EmpType Fran = EmpType.Grunt; if (Joe ‹ Fran) Console.WriteLine("Значение Джо меньше значения Фрэн."); else Console.WriteLine("Значение Фрэн меньше значения Джо."); } Исходный код. Проект Enums размещен в подкаталоге, соответствующем главе 3. Мастер-класс: System.Object Совет. Следующий обзор System.Object предполагает, что вы знакомы с понятиями виртуального метода и переопределения методов. Если мир ООП для вас является новым, вы можете вернуться к этому разделу после изучения материала главы 4. В .NET каждый тип в конечном итоге оказывается производным от общего базового класса System.Object. Класс Object определяет общий набор членов, поддерживаемых каждым типом во вселенной .NET. При создании класса, для которого не указан явно базовый класс, вы неявно получаете этот класс из System.Object. // Неявное получение класса из System.Object. class.HelloClass {…} Если вы желаете уточнить свои намерения, операция C#, обозначаемая двоеточием (:), позволяет явно указать базовый класс типа (например. System.Object). // В обоих случаях класс явно получается из System.Object. class ShapeInfo: System.Object {…} class ShapeInfo: object {…} Тип System.Object определяет набор членов экземпляра и членов класса (статических членов). Заметим, что некоторые из членов экземпляра объявляются с использованием ключевого слова virtual и поэтому могут переопределяться порождаемым классом. // Класс, занимающий наивысшую позицию в .NET: // System.Object namespace System { public class Object { public Object(); public virtual Boolean Equals(Object obj); public virtual Int32 GetHashCode(); public Type GetType(); public virtual String ToString(); protected virtual void Finalize(); protected Object MemberwiseClone(); public static bool Equals(object objA, object objB); public static bool ReferenceEquals(object objA, object objB); } } В табл. 3.10 предлагаются описания функциональных возможностей методов экземпляра для указанного объекта. Таблица 3.10. Наиболее важные члены System.Object
Поведение System.Object, заданное по умолчанию Чтобы продемонстрировать некоторые особенности принятого по умолчанию поведения базового класса System.Object, рассмотрим класс Person (персона), определенный в пользовательском пространстве имен ObjectMethods. // Ключевое слово 'namespace' обсуждается в конце этой славы. namespace ObjectMethods { class Person { public Person(string fname, string lname, string s, byte a) { firstName = fname; lastName = lname; SSN = s; age = a; } public Person() {} // Персональные данные (данные состояния). public string firstMame; public string lastName; public string SSN; public byte age; } } Теперь используем тип Person в рамках метода Main(). static void Main(string[] args) { Console.WriteLine("***** Работа с классом Object *****\n"); Person fred = new Person("Фред", "Кларк", "111-11-1111", 20); Console.WriteLine("-› fred.ToString: {0}", fred.ToString()); Console.WriteLine("-› fred.GetHashCode: {0}", fred.GetHashCode()); Console.WriteLine("-› базовый класс для 'fred': {0}", fred.GetType().BaseType); // Создание дополнительных ссылок на 'fred'. Person p2 = fred; object о = p2; // Указывали ли все 3 экземпляра на один объект в памяти? if (о.Equals(fred) && p2.EqualS(o)) Console.WriteLine("fred, p2 и о ссылаются на один объект!"); Console.ReadLine(); } На риc. 3.17 показан вариант вывода, полученного при тестовом запуске программы. 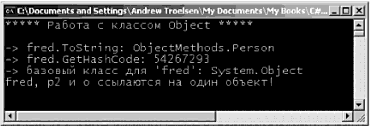 Рис. 3.17. Реализация членов System.Object, заданная по умолчанию Обратите внимание на то, что заданная по умолчанию реализация ToString() просто возвращает полное имя типа (например, в виде пространствоИмён.ИмяТипа). Метод GetType() возвращает объект System.Type, который определяет свойство BaseType (как вы можете догадаться сами, оно идентифицирует полное имя базового класса данного типа). Теперь рассмотрим программный код, использующий метод Equals(). Здесь в управляемой динамической памяти размещается новый объект Person, и ссылка на этот объект запоминается в ссылочной переменной fred. Переменная р2 тоже имеет тип Person, однако здесь не создается новый экземпляр класса Person, a присваивается fred переменной р2. Таким образом, и fred, и р2, а также переменная о (типа object, которая была добавлена для полноты картины) указывают на один и тот же объект в памяти. По этой причине тест на тождественность будет успешным. Переопределение элементов System.Object, заданных по умолчанию Хотя заданное по умолчанию поведение System.Object может оказаться вполне приемлемым в большинстве случаев, вполне обычным для создаваемых вами типов будет переопределение некоторых из унаследованных методов. В главе 4 предлагается подробный анализ возможностей ООП в рамках C#, но, по сути, переопределение - это изменение поведения наследуемого виртуального члена в производном классе. Как вы только что убедились, System.Object определяет ряд виртуальных методов (например, ToString() и Equals()), задающих предусмотренную реализацию. Чтобы иметь другую реализацию этих виртуальных членов для производного типа, вы должны использовать ключевое слово C# override (букв. подменять). Переопределение System.Object.ToString() Переопределение метода ToString() дает возможность получить "снимок" текущего состояния объекта. Это может оказаться полезным в процессе отладки. Для примера давайте переопределим System.Object.ToString() так, чтобы возвращалось текстовое представление состояния объекта (обратите внимание на то, что здесь используется новое пространство имен System.Text). // Нужно сослаться на System.Text для доступа к StringBuilder. using System; using System.Text; class Person { // Переопределение System.Object.ToString(). public override string ToString() { StringBuilder sb = new StringBuilder(); sb.AppendFormat("[FirstName={0}; ", this.firstName); sb.AppendFormat(" Lastname={0}; ", this, lastName); sb.AppendFormat(" SSN={0};", this.SSN); sb.AppendFormat(" Age={0}]", this.age); return sb.ToString(); } … } To, как вы форматируете строку, возвращающуюся из System.Object.ToString(), не очень важно. В данном примере пары имен и значений помещены в квадратные скобки и разделены точками с запятой (этот формат используется в библиотеках базовых классов .NET). В этом примере используется новый тип System.Text.StringBuilder, который будет подробно описан позже. Здесь следует только подчеркнуть, что StringBuilder обеспечивает более эффективную альтернативу конкатенации строк в C#. Переопределение System.Object. Equals() Давайте переопределим и поведение System.Object.Equals(), чтобы иметь возможность работать с семантикой, основанной на значениях. Напомним, что по умолчанию Equals() возвращает true (истина), когда обе сравниваемые ссылки указывают на один и тот же объект в динамической памяти. Однако часто бывает нужно не то, чтобы две ссылки указывали на один объект в памяти, а чтобы два объекта имели одинаковые состояния (в случае Person это означает равенство значений name, SSN и age). public override bool Equals(object о) { // Убедимся, что вызывающая сторона посылает // действительный объект Person. if (о!= null && о is Person) { // Теперь проверим, что данный объект Person // и текущий объект (this) несут одинаковую информацию. Person temp = (Person)о; if (temp.firstName == this.firstName && temp.lastName == this.lastName && temp.SSN == this.SSN && temp.age == this.age) return true; } return falsе; // He одинаковую! } Здесь с помощью ключевого слова is языка C# вы сначала проверяете, что вызывающая сторона действительно передает методу Equals() объект Person. После этого нужно сравнить значение поступающего параметра со значениями полей данных текущего объекта (обратите внимание на использование ключевого слова this, которое ссылается на текущий объект). Прототип System.Object.Equals() предполагает получение единственного аргумента типа object. Поэтому вы должны выполнить явный вызов метода Equals(), чтобы получить доступ к членам типа Person. Если значения name, SSN и age двух объектов будут идентичны, вы имеете два объекта с одинаковыми данными состояния, поэтому возвратится true (истина). Если какие-то данные будут различаться, вы получите false (ложь). Переопределив System.Object.ToString() для данного класса, вы получаете очень простую возможность переопределения System.Object.Equals(). Если возвращаемое из ToString() значение учитывает все члены текущего класса (и данные базовых классов), то метод Equals() может просто сравнить значения соответствующих строковых типов. public override bool Equals(object o) { if (o != null && о is Person) { Person temp = (Person)o; if (this.ToString() == о.ToString()) return true; else return false; } return false; } Теперь предположим, что у нас есть тип Car (автомобиль), экземпляр которого мы попытаемся передать методу Person.Equals(). // Автомобили – это не люди! Car с = new Car(); Person p = new Person(); p.Equals(c); Из-за проверки в среде выполнения на "истинность" объекта Person (с помощью оператора is) метод Equals() возвратит false. Теперь рассмотрим следующий вызов. // Ой! Person р = new Person(); p.Equals(null); Это тоже не представляет опасности, поскольку наша проверка предусматривает возможность поступления пустой ссылки. Переопределение System.Object.GetHashCode() Если класс переопределяет метод Equals(), следует переопределить и метод System.Object.GetHashCode(). Не сделав этого, вы получите предупреждение компилятора. Роль GetHashCode() – возвратить числовое значение, которое идентифицирует объект в зависимости от его состояния. И если у вас есть два объекта Person, имеющие идентичные значения name, SSN и age, то вы должны получить для них одинаковый хеш-код. Вообще говоря, переопределение этого метода может понадобиться только тогда, когда вы собираетесь сохранить пользовательский тип в коллекции, использующей хеш-коды, например, в System.Collections.Hashtable. В фоновом режиме тип Hashtable вызывает Equals() и GetHashCode() содержащихся в нем типов, чтобы определить правильность объекта, возвращаемого вызывающей стороне. Поскольку System.Object не имеет информации о данных состояния для производных типов, вы должны переопределить GetHashCode() для всех типов, которые вы собираетесь хранить в Hashtable. Есть много алгоритмов, которые можно использовать для создания хеш-кода, как "изощренных", так и достаточно "простых". Еще раз подчеркнем, что значение хеш-кода объекта зависит от состояния этого объекта. Класс System.String имеет довольно солидную реализацию GetHashCode(), основанную на значении символьных данных. Поэтому, если можно найти строковое поле, которое будет уникальным для всех рассматриваемых объектов (например, поле SSN для объектов Person), то можно вызвать GetHashCode() для строкового представлении такого поля. // Возвращает хеш-код на основе SSN. public override int GetHashCode() { return SSN.GetHashCode(); } Если вы не сможете указать подходящий элемент данных, но переопределите ToString(), то можно просто возвратить хеш-код строки, возвращенной вашей реализацией ToString(). // Возвращает хеш-код на основе пользовательского ToString(). public override int GetHashCode() { return ToString().GetHashCode(); } Тестирование переопределенных членов Теперь можно проверить обновленный класс Person. Добавьте следующий программный код в метод Main() и сравните результат его выполнения с тем, что показано на рис. 3.18. static void Main (string[] args) { // ВНИМАНИЕ: эти объекты должны быть идентичными. Person р3 = new Person("Fred", "Jones", "222-22-2222", 98); Person p4 = new Person("Fred", "Jones", "222-22-2222", 98); // Тогда эти хеш-коды и строки будут одинаковыми. Console.WriteLine("-› Хеш-код для р3 = {0}", р3.getHashCode()); Console.WriteLine("-› Хеш-код для р4 = {0}", p4.GetHashCode()); Console.WriteLine("-› Строка для р3 = {0}", p3.ToString()); Console.WriteLine("-› Cтрока для р4 = {0}", p4.ToString()); // Здесь состояния должны быть одинаковыми. if (р3.Equals(p4)) Console.WriteLine("-› Состояния р3 и р4 одинаковы!"); else Console.WriteLine("-› Состояния р3 и р4 различны!"); // Изменим age для р4. Console.WriteLine("\n-› Изменение age для р4\n"); р4.age = 2; // Теперь состояния неодинаковы: хеш-коды и строки будут разными. Console.WriteLine("-› Строка для р3 = {0}", p3.ToString()); Console.WriteLine("-› Строка для р4 = {0}", p4.ToString()); Console.WriteLine("-› Хеш-код для р3 = {0}", р3.GetHashCode()); Console.WriteLine("-› Хеш-код для р4 = {0}", p4.GetHashCode()); if (р3.Equals(p4)) Console.WriteLine("-› Состояния р3 и р4 одинаковы!") else Console.WriteLine("-› Состояния р3 и р4 различны!"); } 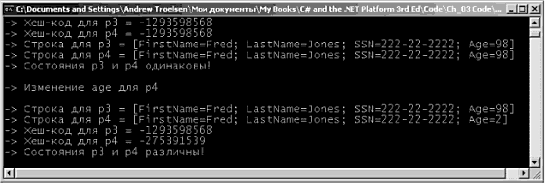 Рис. 3.18. Результаты переопределения членов System.Object Статические члены System.Object В завершение нашего обсуждения базового класса .NET, находящегося на вершине иерархии классов, следует отметить, что System.Object определяет два статических члена (Object.Equals() и Object.ReferenceEquals()), обеспечивающих проверку на равенство значений и ссылок соответственно. Рассмотрим следующий программный код. static void Main(string[] args) { // Два объекта с идентичной конфигурацией. Person р3 = new Person("Fred", "Jones", "222-22-2222", 98); Person p4 = new Person("Fred", "Jones", "222-22-2222", 98); // Одинаковы ли состояния р3 и р4? ИСТИНА! Console.WriteLine("Одинаковы ли состояния: р3 и р4: {0} ", object.Equals(р3, р4)); // Являются ли они одним объектом в памяти? ЛОЖЬ! Console.WriteLine ("Указывают ли р3 и р4 на один объект: {0} ", object.ReferenceEquals(р3, р4)); } Исходный код. Проект ObjectMethods размещен в подкаталоге, соответствующем главе 3. Типы данных System (и их обозначения в C#) Вы, наверное, уже догадались, что каждый внутренний тип данных C# – это на самом деле сокращенное обозначение некоторого типа, определенного в пространстве имен System. В табл. 3.11 предлагается список типов данных System, указаны их диапазоны изменения, соответствующие им псевдонимы C# и информация о согласованности типа со спецификациями CLS. Таблица 3.11. Типы System и их обозначения в C#
Замечание. По умолчанию действительный числовой литерал справа от операции присваивания интерпретируется, как double. Поэтому, чтобы инициализировать переменную типа float, используйте суффикс f или F (например 5.3F). Интересно отметить, что и примитивные типы данных .NET организованы в иерархии классов. Отношения между этими базовыми типами (как и некоторыми другими типами, с которыми мы познакомимся чуть позже) можно представить так, как показано на рис. 3.19. 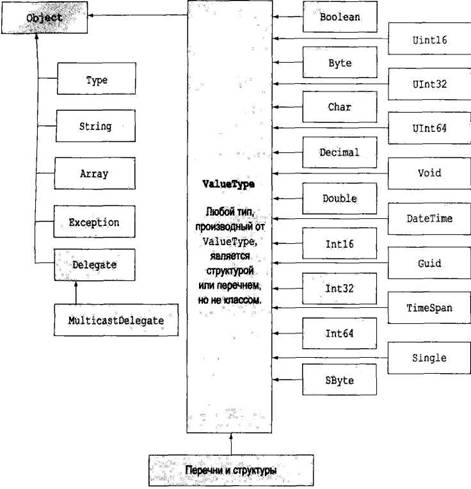 Рис. 3.19. Иерархия типов System Как видите, каждый из этих типов, в конечном счете, получается из System.Object. Ввиду того, что такие типы данных, как, например, int являются просто сокращенными обозначениями соответствующего системного типа (в данном случае типа System.Int32), следующий вариант синтаксиса оказывается вполне допустимым. // Помните! В C# int - это просто сокращение для System. Int32. Console.WriteLine(12.GetHashCode()); Console.WriteLine(12.Equals(23)); Console.WriteLine(12.ToString()); Console.WriteLine(12); // ToString() вызывается автоматически. Console.WriteLine(12.GetType().BaseType); К тому же, поскольку все типы значений имеют конструктор, заданный по умолчанию, можно создавать системные типы с помощью ключевого слова new, в результате чего переменной, к тому же, будет присвоено значение по умолчанию. Хотя использование ключевого слова new при создании типов данных System выглядит несколько "неуклюжим", следующая конструкция оказывается в C# синтаксически правильной. // Следующие операторы эквивалентны. bool b1 = new bool(); // b1= false. bool b2 = false; Кстати, заметим, что можно создавать системные типы данных, используя абсолютные имена. // Следующие операторы также семантически эквивалентны. System.Вoоl b1 = new System.Bool(); // b1 = false. System.Bool sb2 = false; Эксперименты с числовыми типами данных Числовые типы .NET поддерживают свойства MaxValue и МinValue, сообщающие информацию о диапазоне данных, которые может хранить данный тип. Предположим, что мы создали несколько переменных типа System.UInt16 (unsigned short – короткое целое без знака), как показано ниже. static void Main(string[] args) { System.Uint16.myUInt16 = 300000; Console.WriteLine("Максимум для UInt16: {0} ", UInt16.MaxValue); Console.WriteLine("Минимум для UInt16: {0} ", UInt16.MinValue); Console.WriteLine("Значение равно: {0} ", myUInt16); Console.WriteLine("Я есть: {0} ", myUInt16.GetType()); // Теперь для сокращения System.UInt16 (т.e для ushort). ushort myOtherUInt16 = 12000; Console.WriteLine("Максимум для UInt16: {0} ", ushort.MaxValue); Console.WriteLine("Минимум для UInt16: {0} ", ushort.MinValue); Console.WriteLine("Знaчение равно: {0} ", myOtherUInt16); Console.WriteLine("Я есть: {0} ", myotherUInt16.GetType()); Console.ReadLine(); } Вдобавок к свойствам MinValue/MaxValue системные типы могут определять другие полезные члены. Например, тип System.Double позволяет получить значения Epsilon и Infinity. Console.WriteLine("-› double.Epsilon: {0}", double.Epsilon); Console.WriteLine("-› double.РositiveInfinitу: {0} ", double.PositiveInfinity); Console.WriteLine("-› double.NegativeInfinity: {0}", double.NegativeInfinity); Console.WriteLine("-› double.MaxValue: {0}", double.MaxValue); Console.WriteLine("-› double.MinValue: {0}", double.MinValue); Члены System.Boolean Теперь рассмотрим тип данных System.Boolean. В отличие от C(++), в C# единственными возможными значениями для bool являются {true | false}. В C# вы не можете назначать типу bool импровизированные значения (например, -1, 0, 1), что считается (большинством программистов) правильным нововведением. С учетом этого должно быть понятно, почему System.Boolean не поддерживает свойства MinValue/MaxValue, а поддерживает TrueString/FalseString. // В C# нет произвольных типов Boolean! bool b = 0; // Недопустимо! bool b2 = -1; // Также недопустимо! bool b3 = true; // Без проблем. bool b4 = false; // Без проблем. Console.WriteLine("-› bool.FalseString: {0}", bool.FalseString); Console.WriteLine("-› bool.TrueString: {0}", bool.TrueString); Члены System.Char Текстовые данные в C# представляются встроенными типами данных string и char. Все .NET-языки отображают текстовые типы в соответствующие базовые типы (System.String и System.Char). Оба эти типа в своей основе используют Unicode. Тип System.Char обеспечивает широкие функциональные возможности, далеко выходящие за рамки простого хранения символьных данных (которые, кстати, должны помещаться в одиночные кавычки). Используя статические методы System.Char, вы можете определить, является ли данный символ цифрой, буквой, знаком пунктуации или чем-то иным. Для иллюстрации рассмотрим следующий фрагмент программного кода. static void Main(string[] args) { … // Проверьте работу следующих операторов… Console.WriteLine("-› char.IsDigit('К'): {0}", char.IsDigit('К')); Console.WriteLine("-› char.IsDigit('9'): {0}", char.IsDigit('9')); Console.WriteLine("-› char.IsLetter('10', 1): {0}", char.IsLetter("10", 1)); Console.WriteLine("-› char.IsLetter('p'): {0}", char.IsLetter('p')); Console.WriteLine("-› char.IsWhiteSpace('Эй, там!', 3): {0}", char.IsWhiteSpace("Эй, там!", 3)); Console.WriteLine("-› char.IsWhiteSpace('Эй, там!', 4): {0}", char.IsWhiteSpace("Эй, там!", 4)); Console.WriteLine("-› char.IsLettetOrDigit('?'): {0}", char.IsLetterOrDigit('?')); Console.WriteLine("-› char.IsPunctuation('!'): {0}", char.IsPunctuation('!')); Console.WriteLine("-›char.IsPunctuation('›'): {0}", char.IsPunctuation('›')); Console.WriteLine("-› char.IsPunctuation(','): {0}", char.IsPunctuation(',')); … } Как видите, для всех этих статических членов System.Char при вызове используется следующее соглашение: следует указать либо единственный символ, либо строку с числовым индексом, который указывает местоположение проверяемого символа. Анализ значений строковых данных Типы данных .NET обеспечивают возможность генерировать переменную того типа, который задается данным текстовом эквивалентом (т.е. выполнять синтаксический анализ). Эта возможность может оказаться чрезвычайно полезной тогда, когда требуется преобразовать вводимые пользователем данные (например, выделенные в раскрывающемся списке) в числовые значения. Рассмотрите следующий фрагмент программного кода. static void Main(string[] args) { … bool myBool = bool.Parse("True"); Console.WriteLine("-› Значение myBool: {0}", myBool); double myDbl = double.Parse("99,884"); Console.WriteLine("-› Значение myDbl: {0}", myDbl); int myInt = int.Parse("8"); Console.WriteLine("-› Значение myInt: {0}", myInt); Char myChar = char.Раrsе("w"); Console.WriteLine(''-› Значение myChar: {0}\n", myChar); … } System.DateTime и System.TimeSpan В завершение нашего обзора базовых типов данных позволите обратить ваше внимание на то, что пространство имен System определяет несколько полезных типов данных, для которых в C# не предусмотрено ключевых слов. Это, в частности, типы DateTime и TimeSpan (задачу исследования типов System.Guid и System.Void, которые среди прочих показаны на рис. 3.19, мы оставляем на усмотрение заинтересованных читателей). Тип DateTime содержит данные, представляющие конкретные дату (месяц, день, год) и время, которые можно отформатировать различными способами с помощью соответствующих членов. В качестве простого примера рассмотрите следующий набор операторов. static void Main (string[] args) { … // Этот конструктор использует (год, месяц, день) DateTime dt = new DateTime(2004, 10, 17); // Какой это день недели? Console.WriteLine("День {0} – это (1}", dt.Date, dt.DayOfWeek); dt.AddMonths(2); // Теперь это декабрь. Console.WriteLine ("Учет летнего времени: {0}", dt.IsDaylightSavingTime()); … } Структура TimeSpan позволяет с легкостью определять и преобразовывать единицы времени с помощью различных ее членов, например: static void Main(string[] args) { … // Этот конструктор использует (часы, минуты, секунды) TimeSpan ts = new TimeSpan(4, 30, 0); Console.WriteLine(ts); // Вычтем 15 минут из текущего значения TimeSpan и распечатаем результат. Console.WriteLine(ts.Subtract(new TimeSpan (0, 15, 0))); … } На рис. 3.20 показан вывод операторов DateTime и TimeSpan.  Рис. 3.20. Использование типов DateTime и TimeSpan Исходный код. Проект DataTypes размещен в подкаталоге, соответствующем главе 3. Тип данных System.String Ключевое слово string в C# является сокращенным обозначением типа System.String, предлагающего ряд членов, вполне ожидаемых от этого класса. В табл. 3.12 предлагаются описания некоторых (но, конечно же, не всех) таких членов. Таблица 3.12. Некоторые члены System.String
Базовые операции со строками Для иллюстрации некоторых базовых операций со строками рассмотрим следующий метод Main(). static void Main(string[] args) { Console.WriteLine("***** Забавы со строками *****"); string s = "Boy, this is taking a long time."; Console.WriteLine("-› Содержит ли s 'oy'?: {0}", s.Contains("oy")); Console.WriteLine("-› Содержит ли s 'Boy'?: {0}", s.Contains("Boy")); Console.WriteLine(s.Replace('.', '!')); Console.WriteLine.(s.Insert(0, "Boy O' ")); Console.ReadLine(); } Здесь мы создаем тип string, вызывающий методы Contains(), Replace() и Insert(). Cоответствующий вывод показан на рис. 3.21.  Рис. 3.21. Базовые операции во строками Вы должны учесть то, что хотя string и является ссылочным типом, операции равенства и неравенства (== и !=) предполагают сравнение значений со строковыми объектами, а не областей памяти, на которые они ссылаются. Поэтому следующее сравнение в результате дает true: string s1 = "Hello"; string s2 = "Hello"; Console.WriteLine("s1 == s2: {0}", s1 == s2); тогда как следующее сравнение возвратит false: string s1 = "Hello"; string s2 = "World!"; Console.WriteLine("s1 == s2: {0}", s1 == s2); Для конкатенации существующих строк в новую строку, которая является объединением исходных, в C# предлагается операция +, как статический метод String.Concat(). С учетом этого следующие операторы оказываются функционально эквивалентными. // Конкатенация строк. string newString = s + s1 + s2; Console.WriteLine ("s + s1 + s2 = {0}", newString); Console.WriteLine("string.Concat(s, s1, s2) = {0}", string.Concat(s, s1, s2)); Другой полезной возможностью, присущей типу string, является возможность выполнения цикла по всем отдельным символам строки с использованием синтаксиса, аналогичного синтаксису массивов. Формально говоря, объекты, поддерживающие доступ к своему содержимому, подобный по форме доступу к массивам, используют метод индексатора. О том, как строить индексаторы, вы узнаете из главы 9, но здесь для иллюстрации соответствующего понятия предлагается рассмотреть следующий фрагмент программного кода, в котором каждый символ строкового объекта s1 выводится на консоль. // System.String определяет индексатор для доступа // каждому символу в строке. for (int k = 0; k ‹ s1.Length; k++) Console.WriteLine("Char {0} is {1}", k, s1[k]); В качестве альтернативы взаимодействию с индексатором типа можно использовать строковый класс в конструкции foreach. Ввиду того, что System.String поддерживает массив индивидуальных типов System.Char, следующий программный тоже выводит каждый символ si на консоль. foreach (char c in s1) Console.WriteLine(с); Управляющие последовательности Как и в других языках, подобных C, строковые литералы в C# могут содержать различные управляющие последовательности, которые интерпретируются как определенный набор данных, предназначенных для отправки в выходной поток. Каждая управляющая последовательность начинается с обратной косой черты, за которой следует интерпретируемый знак. На тот случай, если вы подзабыли значения управляющих последовательностей, в табл. 3.13 предлагаются описания тех из них, которые используются чаще всего. Таблица 3.13. Управляющие последовательности строковых литералов
Так, чтобы напечатать строку, в которой между любыми двумя словами имеется знак табуляции, можно использовать управляющую последовательность \t. // Строковые литералы могут содержать любое число // управляющих последовательностей. string s3 = "Эй, \tвы,\tтам,\tопять!"; Console.WriteLine(s3); Для другого примера предположим, что вам нужно создать строковый литерал, который содержит кавычки, литерал, указывающий путь к каталогу, и, наконец, литерал, который вставляет три пустые строки после вывода всех символьных данных. Чтобы не допустить появления сообщений об ошибках компиляции, используйте управляющие символы \", \\ и \n. Consolе.WriteLine("Все любят \"Hello World\"); Console. WriteLine("C:\\MyApp\\bin\\debug"); Console.WriteLine("Все завершено.\n\n\n"); Буквальное воспроизведение строк в C# В C# вводится использование префикса @ для строк, которые требуется воспроизвести буквально. Используя буквальное воспроизведение строк, вы отключаете обработку управляющих символов строк. Это может быть полезным при работе со строками, представляющими каталоги и сетевые пути. Тогда вместо использования управляющих символов \\ можно использовать следующее. // Следующая строка должна воспроизводиться буквально, // поэтому все 'управляющее символы' будут отображены. Console.WriteLine(@"C:\MyАрр\bin\debug"); Отметьте также и то, что буквально воспроизводимые строки могут использоваться для представления пропусков пространства в строковых значениях, "растянутых" на несколько строк. // В буквально воспроизводимых строках // пропуски пространства сохраняются. string myLongString = @"Это очень очень очень длинная строка"; Console.WriteLine(myLongString); Двойную кавычку в такой строковый литерал можно вставить с помощью дублирования знака ", например: Console.WriteLine(@"Cerebus said ""Darrr! Pret-ty sun-sets"""); Роль System.Text.StringBuilder Тип string прекрасно подходит для того, чтобы представлять базовые строковые переменные (имя, SSN и т.п.), но этого может оказаться недостаточно, если вы создаете программу, в которой активно используются текстовые данные. Причина кроется в одной очень важной особенности строк в .NET: значение строки после ее определения изменить нельзя. Строки в C# неизменяемы. На первый взгляд, это кажется невероятным, поскольку мы привыкли присваивать новые значения строковым переменным. Однако, если проанализировать методы System.String, вы заметите, что методы, которые, как кажется, внутренне изменяют строку, на самом деле возвращают измененную копию оригинальной строки. Например, при вызове ToUpper() для строкового объекта вы не изменяете буфер существующего строкового объекта, а получаете новый строковый объект в форме символов верхнего регистра. static void Main(string[] args) { … // Думаете, что изменяете strFixed? А вот и нет! System.String strFixed = "Так я начинал свою жизнь"; Console.WriteLine(strFixed); string upperVersion = strFixed.ToUpper(); Console.WriteLine(strFixed); Console.WriteLine("{0}\n\n", upperVersion); … } Подобным образом, присваивая существующему строковому объекту новое значение, вы фактически размещаете в процессе новую строку (оригинальный строковый объект в конечном итоге будет удален сборщиком мусора). Аналогичные действия выполняются и при конкатенации строк. Чтобы уменьшить число копирований строк, в пространстве имен System.Text определяется класс StringBuilder (он уже упоминался нами выше при рассмотрении System.Object). В отличие от System.String, тип StringBuilder обеспечивает прямой доступ к буферу строки. Подобно System.String, тип StringBuilder предлагает множество членов, позволяющих добавлять, форматировать, вставлять и удалять данные (подробности вы найдете в документации .NET Framework 2.0 SDK). При создании объекта StringBuilder можно указать (через аргумент конструктора) начальное число символов, которое может содержать объект. Если этого не сделать, то будет использоваться "стандартная емкость" StringBuilder, по умолчанию равная 16. Но в любом случае, если вы увеличите StringBuilder больше заданного числа символов, то размеры буфера будут переопределены динамически. Вот пример использования этого типа класса. using System; using System.Text; // Здесь 'живет' StringBuilder. class StringApp { static void Main(string[] args) { StringBuilder myBuffer = new StringBuilder("Моя строка"); Console.WriteLine("Емкость этого StringBuilder: {0}", myBuffer.Capacity); myBuffer.Append(" содержит также числа:"); myBuffer.AppendFormat("{0}, {1}.", 44, 99); Console.WriteLine("Емкость этого StringBuilder: {0}", myBuffer.Сарасitу); Console.WriteLine(myBuffer); } } Во многих случаях наиболее подходящим для вас текстовым объектом будет System.String. Для большинства приложений потери, связанные с возвращением измененных копий символьных данных, будут незначительными. Однако при построении приложений, интенсивно использующих текстовые данные (например, текстовых процессоров), вы, скорее всего, обнаружите, что использование System.Text.StringBuilder повышает производительность. Исходный код. Проект Strings размешен в подкаталоге, соответствующем главе 3. Типы массивов .NET Формально говоря, массив - это коллекция указателей на данные одного и того же вполне определенного типа, доступ к которым осуществляется по числовому индексу. Массивы являются ссылочными типами и получаются из общего базового класса System.Array. По умолчанию для .NET-мaccивов начальный индекс равен нулю, но с помощью статического метода System.Array.CreateInstance() для любого массива можно задать любую нижнюю границу для его индексов. Массивы в C# можно объявлять по-разному. Во-первых, если вы хотите создать массив, значения которого будут определены позже (возможно после ввода соответствующих данных пользователем), то, используя квадратные скобки ([]), укажите размеры массива во время его создания. Например: // Создание массива строк, содержащего 3 элемента (0-2) string[] booksOnCOM; booksOnCOM = new string[3]; // Инициализация 100-элементного массива с нумерацией (0 - 99) string[] booksOnDotNet = new string[100]; Объявив массив, вы можете использовать синтаксис индексатора, чтобы присвоить значения его элементам. // Создание, заполнение и печать массива из трех строк. string[] booksOnCOM; booksOnCOM = new string[3]; booksOnCOM[0] = "Developer's Workshop to COM and ATL 3.0"; booksOnCOM[1] = "Inside COM"; booksOnCOM[2] = "Inside ATL"; foreach (string s in booksOnCOM) Console.WriteLine(s); Если значения массива во время его объявления известны, вы можете использовать "сокращенный" вариант объявления массива, просто указав эти значения в фигурных скобках. Указывать размер массива в этом случае не обязательно (он вычисляется динамически), как и при использовании ключевого слова new. Так, следующие варианты объявления массива эквивалентны. // 'Краткий' вариант объявления массива // (значения во время объявления должны быть известны). int[] n = new int[] {20, 22, 23, 0}; int[] n3 = {20, 22, 23, 0}; И наконец, еще один вариант создания типа массива. int[] n2 = new int[4] {20, 22, 23, 0}; // 4 элемента, {0 - 3} В данном случае указанное числовое значение задает число элементов в массиве, а не граничное сверху значение для индексов. При несоответствии между объявленным размером и числом инициализируемых элементов вы получите сообщение об ошибке компиляции. Независимо от того, как вы объявите массив, элементам в .NET-массиве автоматически будут присвоены значения, предусмотренные по умолчанию, сохраняющиеся до тех пор, пока вы укажете иные значения. Так, в случае массива числовых типов, каждому его элементу присваивается значение 0 (или 0.0 в случае чисел с плавающим разделителем), объектам присваивается null (пустое значение), а типам Boolean – значение false (ложь). Массивы в качестве параметров (и возвращаемых значений) После создания массива вы можете передавать его, как параметр, или получать его в виде возвращаемого значения. Например, следующий метод PrintArray() получает входной массив строк и выводит каждый элемент на консоль, а метод GetStringArray() "наполняет" массив значениями и возвращает его вызывающей стороне. static void PrintArray(int[] myInts) { for (int i = 0; i ‹ myInts.Length; i++) Console.WriteLine("Элемент {0} равен {1}", i, myInts[i]); } static string[] GetStringArray() { string theStrings = { "Привет", "от", "GetStringArray"}; return theStrings; } Эти методы можно вызвать из метода Main(), как показано ниже. static void Main(string[] args) { int[] ages={20, 22, 23, 0}; PrintArray(ages); string[] strs = GetStringArray(); foreach(string s in strs) Console.WriteLine(s); Console.ReadLine(); } Работа с многомерными массивами Вдобавок к одномерным массивам, которые мы рассматривали до сих пор, в C# поддерживаются два варианта многомерных массивов. Первый из них – это прямоугольный массив, т.е. многомерный массив, в котором каждая строка оказывается одной и той же длины. Чтобы объявить и заполнить многомерный прямоугольный массив, действуйте так, как показано ниже. static void Main(string[] args) { … // Прямоугольный массив MD . int[,] myMatrix; myMatrix = new int[6,6]; // Заполнение массива (6 * 6). for (int i = 0; i ‹ 6; i++) for (int j = 0; j ‹ 6; j++) myMatrix[i, j] = i * j; // Печать массива (6 * 6). for (int i = 0; i ‹ 6; i++) { for(int j = 0; j ‹ 6; j++) Console.Write(myMatrix[i, j] + "\t"); Console.WriteLine(); } … } На рис. 3.22 показан соответствующий вывод (обратите внимание на прямоугольный вид массива). 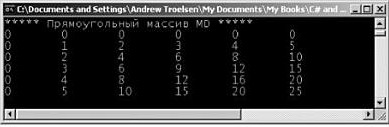 Рис. 3.22. Многомерный массив Второй тип многомерных массивов – это невыровненный массив. Как следует из самого названия, такой массив содержит некоторый набор массивов, каждый из которых может иметь свой верхний предел для индексов. Например: static void Main(string[] args) { … // Невыровненный массив MD (т.е. массив массивов). // Здесь мы имеем массив из 5 разных массивов. int[][] myJagArray = new int[5][]; // Создание невыровненного массива. for (int i = 0; i ‹ myJagArray.Length; i++) myJagArray[i] = new int[i +7]; // Печать каждой строки (не забывайте о том, что // по умолчанию все элементы будут равны нулю!) for (int i = 0; i ‹ 5; i++) { Console.Write("Длина строки {0} равна {1}:\t", i, myJagArray[i].Length); for (int j = 0; j ‹ myJagArray[i].Length; j++) Console.Write(myJagArray[i][j] + " "); Console.WriteLine(); } } На рис. 3.23 показан соответствующий вывод (обратите, что здесь массив имеет "неровный край"). 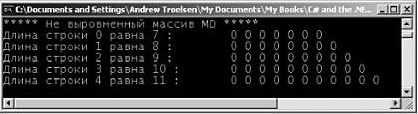 Рис. 3.23. Невыровненный массив Теперь когда вы знаете, как строить и заполнять массивы в C#, обратим внимание на базовый класс любого массива: System.Array. Базовый класс System.Array Каждый создаваемый вами массив в .NET автоматически получается из System.Array. Этот класс определяет рад полезных методов для упрощения работы с массивами. В табл. 3.14 предлагаются описания некоторых из наиболее интересных членов указанного класса. Таблица 3.14. Некоторые члены System.Array
Рассмотрим примеры использовании некоторых из этих членов. В следующем программном коде используются статические методы Reverse() и Clear() (а также свойство Length) для вывода некоторой информации о массиве строк firstNames на консоль. // Создание строковых массивов и проверка // некоторых членов System.Array. static void Main(string[] args) { // Массив строк. string[] firstNames = {"Steve", "Dominic", "Swallow", "Baldy"}; // Печать имен в объявленном виде. Console.WriteLine("Вот вам массив:"); for(int i = 0; i ‹ firstNames.Length; i++) Console.Write("Имя: {0}\t", firstNames[i]); Console.WriteLine("\n"); // Инвертирование порядка в массиве и печать. Array.Reverse(firstNames); Console.WriteLine("Вот вам инвертированный массив:"); for (int i = 0; i ‹ firstNames.Length; i++) Console.Write("Имя: (0}\t", firstNames[i]); Console.WriteLine("\n"); // Очистка всех данных, хроме Baldy. Console.WriteLine("Очистка всех данных, кроме Baldy…"); Array.Clear(firstNames, 1, 3); for (int i = 0; i ‹ firstNames.Length; i++) Console.Write ("Имя: {0}\t", firstNames[i]); Console.ReadLine(); } Обратите особое внимание на то, что при вызове метода Clear() для массива оставшиеся элементы массива не сжимаются в меньший массив. Для подвергшихся очистке элементов просто устанавливаются значения по умолчанию. Если вам нужен контейнер динамического типа, поищите подходящий тип в пространстве имен System.Collections. Исходный код. Проект Arrays размещен в подкаталоге, соответствующем главе 3. Типы с разрешением принимать значение null Вы уже видели, что типы данных CLR имеют фиксированный диапазон изменения. Например, тип данных System.Boolean может принимать значения из множества {true, false}. В .NET 2.0 можно создавать типы с разрешением принимать значение null (типы nullable). Тип с разрешением принимать значение null может представлять любое значение, допустимое для данного типа, и, кроме того, значение null. Так, если объявить тип System.Boolean с разрешением принимать значение null, то такой тип сможет принимать значения из множества {true, false, null}. Очень важно понимать, что тип, характеризуемый значением, без разрешения принимать значение null это значение принимать не может. static void Main(string[] args) { // Ошибка компиляции! // Типы, характеризуемые значением, не допускают значений null! bool myBool = null; int myInt = null; } Чтобы определить переменную типа nullable, к обозначению типа данных в виде суффикса добавляется знак вопроса (?). Такой синтаксис оказывается допустимым только тогда, когда речь идет о типах, характеризуемых значениями, или массивах таких типов. При попытке создать ссылочный тип (включая строковый) с разрешением значения null вы получите ошибку компиляции. Подобно переменным без разрешения принимать значение null, локальным переменным с таким разрешением тоже должны присваиваться начальные значения. static void Main(string [] args) { // Несколько определений локальных типов // с разрешенными значениями null. int? nullableInt = 10; double? nullableDouble = 3.14; bool? nullableBool = null; char? nullableChar = 'a'; int?[] arrayOfNullableInts = new int?[10]; // Ошибка! Строки являются ссылочными типами! string? s = "ой!"; } Суффикс ? в C# является сокращенной записью для указания создать переменную структуры обобщённого типа System.Nullable‹T›. Мы рассмотрим обобщений в главе 10, а сейчас важно понять то, что тип System.Nullablе‹Т› предлагает ряд членов, которые могут использовать все типы с разрешением значения null. Например, используя свойство HasValue или операцию !=, вы можете программным путем выяснить, содержит ли соответствующая переменная значение null. Значение, присвоенное типу с разрешением значения null, можно получить непосредственно или с помощью свойства Value. Работа с типами, для которых допустимы значения null Типы с разрешением принимать значение null могут оказаться исключительно полезными при взаимодействии с базами данных, где столбцы в таблице могут оказаться пустыми (т.е., неопределенными). Для примера рассмотрим следующий класс, моделирующий доступ к базе данных с таблицей, два столбца которой могут оставаться неопределенными. Обратите внимание на то, что здесь метод GetIntFromDatabase() не присваивает значение члену-переменной целочисленного типа с разрешенным значением null, в то время как GetBoolFromDatabase() назначает подходящее значение члену bool?. Class DatabaseReader { // Поле данных с разрешением значения null. public int? numbericValue; public bool? boolValue = true; // Обратите внимание на разрешение null для возвращаемого типа. public int? GetIntFromDatabase() {return numberiсVаlue;} // Обратите внимание на разрешение null для возвращаемого типа. public bool? GetBoolFromDatabase() {return boolValue;} } Теперь рассмотрим следующий метод Main(), вызывающий члены класса DatabaseReader и демонстрирующий присвоенные им значения с помощью HasValue и Value в соответствии с синтаксисом C#. static void Main(string[] args) { Console.WriteLine("***** Забавы с разрешением null *****\n") DatabaseReader dr = new DatabaseReader(); // Получение int из 'базы данных'. int? i = dr.GetIntFromDatabase(); if (i.HasValue) Console.WriteLine("Значение 'i' равно: {0}", i); else Console.WriteLine("Значение 'i' не определено."); // Получение bool из 'базы данных'. bool? b = dr.GetBoolFromDatabase(); if (b != null) Console.WriteLine("Значение 'b' равно: {0}", b); else Console.WriteLine("Значение 'b' не определено."); Console.ReadLine(); } Операция ?? Еще одной особенностью типов с разрешением принимать значения null, о которой вам следует знать, является то, что с такими типами можно использовать появившуюся в C# 2005 специальную операцию, обозначаемую знаком ??. Эта операция позволяет присвоить типу значение, если его текущим значением оказывается null. Для примера предположим, что в том случае, когда значение, возвращенное методом GetIntFromDatabase(), оказывается равным null, соответствующему локальному типу int с разрешением значения null нужно присвоить числовое значение 100 (конечно, упомянутый метод всегда возвращает null, но я думаю, вы поймете идею, которую иллюстрирует данный пример). static void Main(string[] args) { Console.WriteLine("***** Забавы с разрешением null *****\n"); DatabaseReader dr = new DatabaseReader(); // Если GetIntFromDatabase() возвращает null, // то локальной переменной присваивается значение 100. int? myData = dr.GetIntFromDatabase() ?? 100; Console.WriteLine("Значение myData: {0}", myData); Console.ReadLine(); } Исходный код. Проект NullableType размещен в подкаталоге, соответствующем главе 3. Пользовательские пространства имен До этого момента мы создавали небольшие тестовые программы, используя пространства имен, существующие в среде .NET (в частности, пространство имен System). Но иногда при создании приложения бывает удобно объединить связанные типы в одном пользовательском пространстве имён. В C# это делается с помощью ключевого слова namespace. Предположим, что вы создаете коллекцию геометрических классов с названиями Square (квадрат), Circle (круг) и Hexagon (шестиугольник). Учитывая их родство, вы хотите сгруппировать их в общее пространство имен. Здесь вам предлагаются два основных подхода. С одной стороны, можно определить все классы в одном файле (shapeslib.cs), как показано ниже. // shapeslib.cs using System; namespace MyShapes { // Класс Circle. class Circle {/* Интересные методы… */} // Класс Hexagon. class Hexagon {/* Более интересные методы… */} // Класс Square. class Square {/* Еще более интересные методы… */} } Заметим, что пространство имен MyShapes играет роль абстрактного "контейнера" указанных типов. Альтернативным вариантом является размещение единого пространства имен в нескольких C#-файлах. Для этого достаточно "завернуть" определения различных классов в одно пространство имен. // circle.cs using System; namespace MyShapes { // Клаcc Circle. class Circle{ } } // hexagon.cs using System; namespace MyShapes { // Класс Hexagon. class Hexagon{} } // square.cs using System; namespace MyShapes { // Класс Square. class Square{} } Вы уже знаете, что в том случае, когда одному пространству имен требуются объекты из другого пространства имен, следует использовать ключевое слово using. // Использование типов из пространства имен MyShapes. using System; using MyShapes; namespace MyApp { class ShapeTester { static void Main(string[] args) { Hexagon h = new Hexagon(); Circle с = new Circle(); Square s = new Square(); } } } Абсолютные имена типов Строго говоря, при объявлении типа, определенного во внешнем пространстве имен, в C# не обязательно использовать ключевое слово using. Можно использовать полное, или абсолютное имя типа, которое, как следует из главы 1, состоит из имени типа с добавленным префиксом пространства имен, определяющего данный тип. // Заметьте, что здесь не используется 'using MyShapes'. using System; namespace MyApp { class ShapeTester { static void Main(string[] args) { MyShapes.Hexagon h = new MyShapes.Hexagon(); MyShapes.Circle с = new MyShapes.Circle(); MyShapes.Square s = new MyShapes.Square(); } } } Обычно нет необходимости использовать полное имя. Это только увеличивает объем ввода с клавиатуры, но не дает никаких преимуществ ни с точки зрения размеров программного кода, ни с точки зрения производительности программы. На самом деле в программном коде CIL типы всегда указываются с полным именем. С этой точки зрения ключевое слово using в C# просто экономит время при наборе программного кода. Однако абсолютные имена могут быть весьма полезны (а иногда и необходимы) тогда, когда возникают конфликты при использовании пространств имен, содержащих типы с одинаковыми именами. Предположим, что есть еще одно пространство имен My3DShapes, в котором определяются три класса для визуализации пространственных форм. // Другое пространство форм… using System; namespace My3DShapes { // Трехмерный класс Circle. class circle{} // Трехмерный класс Hexagon. class Hexagon{} // Трехмерный класс Square. class Square{} } Если обновить ShapeTester, как показано ниже, вы получите целый ряд сообщений об ошибках компиляции, поскольку два пространства имен определяют типы с одинаковыми названиями. // Множество неоднозначностей! using System; using MyShapes; using My3DShapes; namespace MyApp { class ShapeTester { static void Main(string[] args) { // На какое пространство имен ссылаются? Hexagon b = new Hexagon(); // Ошибка компиляции! Circle с = new Circle(); // Ошибка компиляции! Square s = new Square(); // Ошибка компиляции! } } } Неоднозначность разрешится, если использовать абсолютное имя типа // Теперь неоднозначность ликвидирована. static void Main(string[] args) { Му3DShapes.Hexagon h = new My3DShapes.Hexagon(); My3DShapes.Circle с = new My3DShrapes.Circle(); MyShapes.Square s = new MyShapes.Square(); } Использование псевдонимов Ключевое слово C# using можно также использовать для создания псевдонимов абсолютных имен типов. После создания псевдонима вы получаете возможность использовать его как ярлык, который будет заменен полным именем типа во время компиляции. Например: using System; using MyShapes; using My3DShapes; // Ликвидация неоднозначности с помощью псевдонима. using The3DHexagon = My3DShapes.Hexagon; namespace MyApp { class ShapeTester { static void Main(string[] args) { // На самом деле здесь создается тип My3DShapes.Hexagon. The3DHexagon h2 = new The3DHexagon(); … } } } Этот альтернативный синтаксис using можно использовать и при создании псевдонимов для длинных названий пространств имен. Одним из длинных названий в библиотеке базовых классов является System.Runtime.Serialization.Formatters.Binary. Это пространство имен содержит член с именем BinaryFormatter. Используя синтаксис using, экземпляр BinaryFormatter можно создать так, как показано ниже: using MyAlias = System.Runtime.Serialization.Formatters.Binary; namespace MyApp { class ShapeTester { static void Main(string[] args) { MyAlias.BinaryFormatter b = new MyAlias.BinaryFormatter(); } } } или же с помощью традиционного варианта использования директивы using. using System.Runtime.Serialization.Formatters.Binary; namespace MyApp { class ShapeTester { static void Main(string [] args) { BinaryFormatter b = new BinaryFormatter(); } } } Замечание. Теперь в C# предлагается и механизм разрешения конфликтов для одинаково названных пространств имен, основанный на использовании спецификатора псевдонима пространства имен (::) и "глобальной" метки. К счастью, указанный тип коллизий возникает исключительно редко. Если вам требуется дополнительная информация по этой теме, прочитайте мою статью "Working with the C# 2.0 Command Line Compiler" (Работа с компилятором командной строки C# 2.0), которую можно найти на страницах http://msdn.microsoft.com. Вложенные пространства имен Совершенствуя организацию своих типов, вы имеете возможность определить пространства имен в рамках других пространств имен. Библиотеки базовых классов .NET часто используют такие вложений, чтобы обеспечить более высокий уровень организации типа. Например, пространство имен Collections вложено в System, чтобы в результате получилась System.Collections. Чтобы создать корневое пространство имен, содержащее уже существующее пространство имен My3DShapes, можно изменить наш программный код так, как показано ниже. // Вложение пространства имен. namespace Chapter3 { namespace My3DShapes { // Трехмерный класс Circle. class Circle{} // Трехмерный класс Hexagon. class Hexagon{} // Трехмерный класс Square. class Square{} } } Во многих случаях единственной задачей корневого пространства имен является расширение области видимости, поэтому непосредственно в рамках такого пространства имен может вообще не определяться никаких типов (как в случае пространства имей Chapter3). В таких случаях вложенное пространство имен можно определить, используя следующую компактную форму. // Вложение пространства имен (вариант 2). namespace Chapters.My3DShapes { // Трехмерный класс Circle. class Circle{} // Трехмерный класс Hexagon. class Hexagon{} // Трехмерный класс Square. class Square{} } С учетом того, что теперь пространство имен My3DShapes вложено в рамки корневого пространства имен Chapter3, вы должны изменить вид всех соответствующих операторов, использующих директиву using и псевдонимы типов. using Chapter3.My3DShapes; using The3DHexagon = Chapter3.My3DShapes.Hexagon; Пространство имен по умолчанию в Visual Studio 2005 В заключение нашего обсуждения пространств имен следует отметить, что при создании нового C#-проекта в Visual Studio 2005 имя пространства имен вашего приложения по умолчанию будет совпадать с именем проекта. При вставке новых элементов с помощью меню Project>Add New Item создаваемые типы будут автоматически помещаться в пространство имен, используемое по умолчанию. Если вы хотите изменить имя пространства имен, используемого по умолчанию (например, так, чтобы оно соответствовало названию вашей компании), используйте опцию Default namespace (Пространство имен по умолчанию) на вкладке Application (Приложения) окна свойств проекта (рис. 3.24).  Рис. 3.24. Изменение пространства имен, используемого по умолчанию После такой модификации любой новый элемент, вставляемый в проект, будет помещаться в пространство имен IntertechTraining (и, очевидно, чтобы использовать соответствующие типы в рамках другого пространства имен, потребуется указать подходящую по форме директиву using). Исходный код. Проект Namespaces размещен в подкаталоге, соответствующем главе 3. Резюме В этой (довольно длинной) главе обсуждались самые разные аспекты языка программирования C# и платформы .NET. В центре внимания были конструкция, которые наиболее часто используются в приложениях и которые могут понадобиться вам при создании таких приложений. Вы могли убедиться, что все внутренние типы данных в C# соответствуют определенным типам из пространства имён System. Каждый такой "системный" тип предлагает набор членов, с помощью которых программными средствами можно выяснить диапазон изменения типа. Были также рассмотрены особенности построения типов класса в C#, различные правила передачи параметров, изучены типы, характеризуемые значениями, и ссылочные типы, а также выяснена роль могущественного System.Object. Кроме того, в главе обсуждались возможности среды CLR, позволяющие использовать объектно-ориентированный подход с общими программными конструкциями, такими как массивы, строки, структуры и перечни. Здесь же были рассмотрены операции приведения к объектному типу и восстановления из объектного образа. Этот простой механизм позволяет с легкостью переходить от типов, характеризуемых значениями, к ссылочным типам и обратно. Наконец, была раскрыта роль типов данных с разрешением принимать значение null и показано, как строить пользовательские пространства имён. ГЛАВА 4. Язык C# 2.0 и объектно-ориентированный подход В предыдущей главе мы рассмотрели ряд базовых конструкций языка C# и платформы .NET, а также некоторые типы из пространства имен System. Здесь мы углубимся в детали процесса построения объектов. Сначала мы рассмотрим знаменитые принципы ООП, а затем выясним, как именно реализуются, инкапсуляция, наследование и полиморфизм в C#. Это обеспечит знания, необходимые для того, чтобы строить иерархии пользовательских классов. В ходе обсуждения мы рассмотрим некоторые новые конструкции, такие как свойства типов, члены типов для контроля версий, изолированные классы и синтаксис XML-кода документации. Представленная здесь информация будет базой для освоения более сложных приемов построения классов (с использованием, например, перегруженных операций, событий и пользовательских программ преобразования), рассматриваемых в следующих главах. Даже если вы чувствуете себя вполне комфортно в рамках объектно-ориентированного подхода с другими языками программирования, я настойчиво рекомендую вам внимательно рассмотреть примеры программного кода, предлагаемые в этой главе. Вы убедитесь, что C# предлагает новые решения для многих привычных конструкций объектно-ориентированного подхода. Тип класса в C# Если вы имеете опыт создания объектов в рамках какого-то другого языка программирования, то, несомненно, знаете о роли определений классов. Формально говоря, класс – это определенный пользователем тип (User-Defined Type - UDT), который скомпонован из полей данных (иногда называемых членами-переменными) и функций (часто вызываемых методами), воздействующих на эти данные. Множество полей данных в совокупности представляет "состояние" экземпляра класса. Мощь объектно-ориентированных языков заключается в том, что с помощью группировки данных и функциональных возможностей в едином пользовательском типе можно строить свои собственные программные типы по образу и подобию лучших образцов, созданных профессионалами. Предположим, что вы должны создать программный объект, моделирующий типичного работника для бухгалтерской программы. С минимумом требований вы можете создать класс Employee (работ-ник), поддерживающий поля для имени, текущего уровня зарплаты и ID (числового кода) работника. Дополнительно этот класс может определить метод GiveBonus(), который на некоторую величину увеличивает выплату для данного индивидуума, a также метод DisplayStats(), который печатает данные состояния. На рис. 4.1 показана структура типа Employee.  Pис. 4.1. Тип класса Employee Вспомните из главы 3 что классы в C# могут определять любое числоконструкторов - это специальные методы класса, обеспечивающие пользователю объекта простую возможность создания экземпляров данного класса с заданным поведением. Каждый класс в C# изначально обеспечивается конструктором, заданным по умолчанию, который по определению никогда не имеет аргументов. В дополнение к конструктору, заданному по умолчанию, можно определить любое число пользовательских конструкторов. Для начала мы определим вашу первую модификацию класса Employee (по мере изучения материала данной главы мы будем добавлять в этот класс новые функциональные возможности). // Исходное определение класса Employee. namespace Employees { public class Employee { // Поля данных. private string fullName; private int empID; private float currPay; // Конструкторы. public Employee(){} public Employee(string fullName, int empID, float currPay) { this.fullName = fullName; this.empIP = empID; this.currPay = currPay; } // Увеличение выплаты для данного работника. public void GiveBonus(float amount) { currPay += amount; } // Текущее состояние объекта. public void DisplayStats() { Console.WriteLine("Имя: {0} ", fullName); Console.WriteLine("З/п: {0} ", currPay); Console.WriteLine("Код: {0} ", empID); } } } Обратите внимание на реализацию конструктора по умолчанию (он оказывается пустым) для класса Employee. public class Employee { … public Employee(){} … } Подобно C++ и Java, если в определении C#-класса задаются пользовательские конструкторы, то конструктор, заданный по умолчанию, отключается без предупреждений. Если вы хотите позволить пользователю объекта создавать экземпляры вашего класса следующим образом: static void Main(string[] args) { // Вызов конструктора, заданного до умолчанию. Employee e = new Employee(); } то должны явно переопределить конструктор, заданный по умолчанию. Если этого не сделать, то при создании экземпляра вашего класса с помощью конструктора по умолчанию вы получите ошибку компиляции. Так или иначе, следующий метод Main() создает целый ряд объектов Employee, используя наш пользовательский конструктор с тремся аргументами. // Создание нескольких объектов Employee. static void Main(string[] args) { Employee e = new Employee("Джо", 80, 30000); Employee e2; e2 = new Employee("Бет", 81, 50000); Console.ReadLine(); } Перегрузка методов Подобно другим объектно-ориентированным языкам, язык C# позволяет типу перегружать его методы. Говоря простыми словами, когда класс имеет несколько членов с одинаковыми именами, отличающихся только числом (или типом) параметров, соответствующий член называют перегруженным. В классе Employee перегруженным является конструктор класса, поскольку предложены два определения, которые отличаются только наборами параметров. public class Employee { ... // Перегруженные конструкторы. public Employee(){} public Employee(string fullName, int empID, float currPay) {…} ... } Конструкторы, однако, не являются единственными членами, допускающими перегрузку. Продолжив рассмотрение текущего примера, предположим, что у нас есть класс Triangle (треугольник), который поддерживает перегруженный метод Draw(). С его помощью пользователю объекта позволяется выполнить визуализацию изображений, используя различные входные параметры. public class Triangle { // Перегруженный метод Draw() . public void Draw(int x, int y, int height, int width) {…} public void Draw(float x, float y, float height, float width) {…} public void Draw(Point upperLeft, Point bottomRight) {…} public void Draw(Rect r) {…} } Если бы в C# не поддерживалась перегрузка методов, вы были бы вынуждены создать четыре члена с уникальными именами, что, как можете убедиться, весьма далеко от идеала. public class Triangle { // Глупость… public void DrawWithInts(int x, int y, int height, int width) {…} public void DrawWithFloats(float x, float y, float height, float width) {…} public void DrawWithPoints(Point upperLeft, Point bottomRight) {…} public void DrawWithRect(Rect r) {…} } Но не забывайте о том, что при перегрузке члена возвращаемый тип не может быть независимым. Так, следующий вариант просто недопустим. public class Triangle { … // Ошибка! Нельзя перегружать методы // на основе возвращаемых значений! public float GetX(){…} public int GetX(){…} } Использование this для возвратных ссылок в C# Обратите внимание на то, что другой конструктор класса Employee использует ключевое слово C# this. // Явное использование "this" для разрешения конфликтов имен. publiс Employee(string fullName, int empID, float currPay) { // Присваивание входных параметров данным состояния. this.fullName = fullName; this.empID = empID; this.currPay = currPay; } Это ключевое слово C# используется тогда, когда требуется явно сослаться на поля и члены текущего объекта. Причиной использования ключевого слова this в этом пользовательском конструкторе является стремление избежать конфликта имен параметров и внутренних переменных состояния. Альтернативой могло бы быть изменение имен всех параметров. // В отсутствие конфликта имен "this" подразумевается. public Employee(string name, int id, float pay) { fullName = name; empID = id; currPay = pay; } В данном случае нет необходимости явно добавлять префикс this к именам членов-переменных Employee, потому что конфликт имен уже исключен. Компилятор может самостоятельно выяснить области видимости используемых членов-переменных, и в этой ситуации this называют неявным: если класс ссылается на свои собственные поля данных и члены-переменные (без каких бы то ни было неоднозначностей), то this подразумевается. Таким образом, предыдущая логика конструктора функционально идентична следующей. public Employee(string name, int Id, float pay) { this.fullName = name; this.empID = id; this.currPay = pay; } Замечание. Статические члены типа не могут использовать ключевое слово this в контексте метода. В этом есть смысл, поскольку статические члены-функции действуют на уровне класса (а не объекта). На уровне класса нет this! Передача вызовов конструктора с помощью this Другим вариантом использования ключевого слова this является такая реализация вызова одним конструктором другого, при которой не возникает избыточной логики инициализации члена. Рассмотрим следующую модификацию класса Employee. public class Employee { … public Employee(string fullName, int empID, float currPay) { this.fullName = fullName; this.empID = empID; this.currPay = currPay; } // Если пользователь вызовет этот конструктор, то // передать вызов версии с тремя аргументами. public Employee(string fullName) : this(fullName, IDGenerator.GetNewEmpID(), 0.0F) {} … } Эта итерация класса Employee определяет два пользовательских конструктора, и второй из них имеет единственный параметр (имя индивидуума). Однако для построения полноценного нового Employee вы хотите гарантировать наличие соответствующего ID и значения зарплаты. Предположим, что у вас есть пользовательский класс (IDGenerator) со статическим методом GetNewEmpID(), тем или иным образом генерирующим ID нового работника. Собрав множество начальных параметров, вы передаете запрос создания объекта конструктору с тремя аргументами. Если не передавать вызов, то придется добавить в каждый конструктор избыточный программный код. // currPay автоматически приравнивается к 0.0F через значения, // заданные по умолчанию. public Employee(string fullName) { this.fullName = fullName; this.empID = IDGenerator.GetNewEmpID(); } Следует понимать, что использование ключевого слова this для передачи вызовов конструктора не является обязательным. Однако при использовании этого подхода вы получаете более удобное и более краткое определение класса. Фактически, используя этот подход, вы можете упростить свои программистские задачи, поскольку реальная работа делегируется одному конструктору (обычно это конструктор, который имеет наибольшее число параметров), а остальные конструкторы просто перекладывают ответственность. Определение открытого интерфейса класса После создания данных внутреннего состояния класса и набора конструкторов следующим шагом должно быть определение деталей открытого интерфейса класса. Этим терминам обозначают множество членов, непосредственно доступных из объектной переменной через операцию, обозначаемую точкой. С точки зрения построения класса открытый интерфейс формируют те элементы, которые объявлены в классе с использованием ключевого слова public. Кроме далей данных и конструкторов, открытый интерфейс класса может иметь множество других членов, включая следующие. • Методы. Именованные единицы действия, моделирующие некоторые особенности поведения класса. • Свойства. Традиционные функции чтения и модификации данных. • Константы/поля только для чтения. Поля данных, которые не допускают изменения после присваивания им значений (см. главу 3). Замечание. Из последующего материала данной главы вам станет ясно, что вложенные определения типа тоже могут появляться в рамках открытого интерфейса типа. К тому же, как будет показано в главе 8, открытый интерфейс класса может поддерживать и события. С учетом того, что наш класс Employee определяет два открытых метода (GiveBonus() и DisplayStats()), мы имеем возможность взаимодействовать с открытым интерфейсом так, как показано ниже. // Взаимодействие с открытым интерфейсом класса Employee. static void Main(string[] args) { Console.WriteLine("*** Тип Employee в процессе работы ***\n"); Employee e = new Employee("Джо", 80, 30000); e.GiveBonus(20.0); e.DisplayStats(); Employee e2; e2 = new Employee("Бет", 81, 50000); e2.GiveBonus(1000); e2.DisplayStats(); Console.ReadLine(); } Если выполнить это приложение в том его состоянии, в котором оно находится сейчас, вы должны получить вывод, подобный показанному на рис. 4.2. На этот момент у нас имеется очень простой тип класса с минимальным открытым интерфейсом. Перед тем как двигаться дальше к более сложным примерам, давайте потратим некоторое время на обсуждение принципов объектно-ориентированного программирования (рассмотрение типа Emplоуее мы продолжим немного позже). 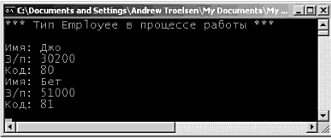 Рис. 4.2. Тип класса Employee в процессе работы Принципы объектно-ориентированного программирования Все объектно-ориентированные языки используют три базовых принципа объектно-ориентированного программирования. • Инкапсуляция. Как данный язык скрывает внутренние особенности реализации объекта? • Наследование. Как данный язык обеспечивает возможность многократного использования программного кода? • Полиморфизм. Как данный язык позволяет интерпретировать родственные объекты унифицированным образом? Перед тем как начать рассмотрение синтаксических особенностей реализации каждого из этих принципов, важно понять базовую роль каждого из них. Поэтому здесь предлагается краткая теоретическая информация по соответствующим вопросам, просто для того, чтобы исключить разночтения, которые могут возникать у людей, ощущающих постоянную нехватку времени на теорию из-за жестких сроков окончания их проектов. Инкапсуляция Первым принципом ООП является инкапсуляция. По сути, она означает возможность скрыть средствами языка несущественные детали реализации от пользователя объекта. Предположим, например, что мы используем класс DatabaseReader, который имеет два метода Open() и Close(). // DatabaseReader инкапсулирует средства работы с базой данных. DatabaseReader dbObj = new DatabaseReader(); dbObj.Open(@"C:\Employees.mdf"); // Работа с базой данных... dbObj.Close(); Вымышленный класс DatabaseReader инкапсулирует внутренние возможности размещения, загрузки, обработки и закрытия файла данных. Пользователи объекта приветствуют инкапсуляцию, поскольку этот принцип ООП позволяет упростить задачи программирования. Нет необходимости беспокоиться о многочисленных строках программного кода, который выполняет работу класса DatabaseReader "за кулисами". Bсe, что требуется от вас, – это создание экземпляра и отправка подходящих сообщений (например, "открыть файл Employees.mdf, размещенный на моем диске C"). Одним из аспектов инкапсуляции является защита данных. В идеале данные состояния объекта должны определяться, как приватные, a не открытые (как было в предыдущих главах). В этом случае "внешний мир" будет вынужден "смиренно просить" право на изменение или чтение соответствующих значений. Наследование Следующим принципом ООП является наследование, означающее способность языка обеспечить построение определений новых классов на основе определений существующих классов. В сущности, наследование позволяет расширить возможности поведения базового класса (называемого также родительским классом) с помощью построения подкласса (называемого производным классам или дочерним классом), наследующего функциональные возможности родительского класса. На рис. 4.3 иллюстрируется отношение подчиненности ("is-а") для родительских и дочерних классов. 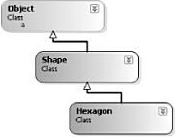 Рис. 4.3. Отношение подчиненности для родительских и дочерних классов Можно прочитать эту диаграмму так: "Шестиугольник (hexagon) является формой (shape), которая является объектом (object)". При создании классов, связанных этой формой наследования, вы создаете отношения подчиненности между типами. Отношение подчиненности часто называется классическим наследованием. Вспомните из главы 3, что System.Object является предельным базовым классом любой иерархии .NET. Здесь класс Shape (форма) расширяет Object (объект). Можно предположить, что Shape определяет некоторый набор свойств, полей, методов и событий, которые будут общими для всех форм. Класс Hexagon (шестиугольник) расширяет Shape и наследует функциональные возможности, определенные в рамках Shape и Object, вдобавок к определению своих собственных членов (какими бы они ни были). В мире ООП есть и другая форма многократного использования программного кода - это модель локализации/делегирования (также известная, как отношение локализации, "has-a"). Эта форма многократного использования программного кода не используется дли создания отношений "класс-подкласс". Скорее данный класс может определить член-переменную другого класса и открыть часть или все свои функциональные возможности для "внешнего мира". Например, если создается модель автомобиля, то вы можете отобразить тот факт, что автомобиль "имеет" ("has-a") радио. Было бы нелогично пытаться получить класс Car (автомобиль) из Radio (радио) или наоборот. (Радио является автомобилем? Я думаю, нет.) Скорее, есть два независимых класса, работающие вместе, где класс-контейнер создает и представляет функциональные возможности содержащегося в нем класса. public class Radio { public void Power(bool turnOn) { Console.WriteLine("Radio on: {0}", turnOn); } } public class Car { // Car содержит ("has-a") Radio. private Radio myRadio = new Radio(); public void TurnOnRadio(bool onOff) { // Делегат для внутреннего объекта. myRadio.Power(onOff); } } Здесь тип-контейнер (Car) несет ответственность за создание содержащегося объекта (Radio). Если объект Car "желает" сделать поведение Radio доступным для экземпляра Car, он должен пополнить свой собственный открытый интерфейс некоторым набором функций, Которые будут действовать на содержащийся тип. Заметим, что пользователь объекта не получит никакой информации о том, что класс Car использует внутренний объект Radio. static void Main(string[] args) { // Вызов внутренне передается Radio. Car viper = new Car(); viper.TurnOnRadio(true); } Полиморфизм Третьим принципом ООП является полиморфизм. Он характеризует способность языка одинаково интерпретировать родственные объекты. Эта особенность объектно-ориентированного языка позволяет базовому классу определить множество членов (формально называемых полиморфным интерфейсом) для всех производных классов. Полиморфный интерфейс типа класса строится с помощью определения произвольного числа виртуальных, или абстрактных членов. Виртуальный член можно изменить (или, говоря более формально, переопределить) в производном классе, тогда как абстрактный метод должен переопределяться. Когда производные типы переопределяют члены, определенные базовым классом, они, по существу, переопределяют свой ответ на соответствующий запрос. Чтобы проиллюстрировать понятие полиморфизма, снова используем иерархию форм. Предположим, что класс Shape определил метод Draw(), не имеющий параметров и не возвращающий ничего. С учетом того, что визуализация для каждой формы оказывается уникальной, подклассы (такие как Hexagon и Circle) могут переопределить соответствующий метод так, как это требуется для них (рис. 4.4). 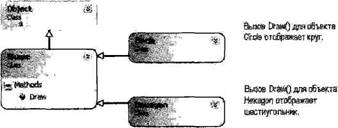 Рис. 4.4. Классический полиморфизм После создания полиморфного интерфейса можно использовать различные предположения, касающиеся программного кода. Например, если Hexagon и Circle являются производными от одного общего родителя (Shape), то некоторый массив типов Shape может содержать любой производный класс. Более того, если Shape определяет полиморфный интерфейс для всех производных типов {в данном примере это метод Draw(), то можно предположить, что каждый член в таком массиве имеет эти функциональные возможности. Проанализируйте следующий метод Main(), в котором массиву типов, производных от Shape, дается указание визуализировать себя с помощью метода Draw(). static void Main(string [] args) { // Создание массива элементов, производных от Shape. Shape[] myShapes = new Shape[3]; myShapes[0] = new Hexagon(); myShapes[1] = new Circle(); myShapes[2] = new Hexagon(); // Движение по массиву и отображение элементов. foreach (Shape s in myShapes) s.Draw(); Console.ReadLine(); } На этом наш краткий (и упрощенный) обзор принципов ООП завершается. Теперь, имея в запасе теорию, мы исследуем некоторые подробности и точный синтаксис C#, с помощью которого реализуются каждый из указанных принципов. Первый принцип: сервис инкапсуляции C# Понятие инкапсуляции отражает общее правило, согласно которому поля данных объекта не должны быть непосредственно доступны из открытого интерфейса. Если пользователь объекта желает изменить состояние объекта, то он должен делать это косвенно, с помощью методов чтения (get) и модификации (set). В C# инкапсуляция "навязывается" на уровне синтаксиса с помощью ключевых слов public, private, protected и protected internal, как было показано в главе 3. Чтобы проиллюстрировать необходимость инкапсуляции, предположим, что у нас есть следующее определение класса. // Класс с одним общедоступным полем. public class Book { public int numberOfPages; } Проблема общедоступных полей данных заключается в том, что такие элементы не имеют никакой возможности "понять", является ли их текущее значение действительным с точки зрения "бизнес-правил" данной системы. Вы знаете, что верхняя граница диапазона допустимых значений для int в C# очень велика (она равна 2147483647). Поэтому компилятор не запрещает следующий вариант присваивания. // М-м-м-да… static void Main(stting[] args) { Book miniNovel = new Book(); miniNovel.numberOfPages = 30000000; } Здесь нет перехода за границы допустимости для данных целочисленного типа, но должно быть ясно, что miniNovel ("мини-роман") со значением 30000000 для numberOfPages (число страниц) является просто невероятным с практической точки зрения. Как видите, открытые поля не обеспечивают проверку адекватности данных. Если система предполагает правило, по которому мини-роман должен содержать от 1 до 200 страниц, будет трудно реализовать это правило программными средствами. В этой связи открытые поля обычно не находят места на уровне определений классов, применяемых для решения реальных задач (исключением являются открытые поля, доступные только для чтения). Инкапсуляция обеспечивает возможность сохранения целостности данных для состояния объекта. Вместо определения открытых полей (с помощью которых очень просто прийти к нарушению целостности данных), вашей привычкой должно стать определение частных полей данных, которые обрабатываются вызывающей стороной косвенно, с использованием одного из двух главных подходов. • Определение пары традиционных методов чтения и модификации данных. • Определение именованного свойства. Суть любого их этих подходов заключается в том, что хорошо инкапсулированный класс должен скрыть от "любопытных глаз внешнего мира" необработанные данные и детали того, как выполняются соответствующие действия. Часто такой подход называют программированием "черного ящика". Красота этого подхода в том, что создатель класса имеет возможность изменить особенности реализации любого из своих методов, так сказать, "за кулисами", и нет никакой нужды отменять использование уже существующего программного кода (при условии, что имя метода остается прежним). Инкапсуляция на основе методов чтения и модификации Давайте снова вернемся к рассмотрению нашего класса Employee. Чтобы "внешний мир" мог взаимодействовать с частным полем данных fullName, традиции велят определить средства чтения (метод get) и модификации (метод set). Например: // Традиционные средства чтения и модификации для приватных данных. public class Employee { private string fullName; … // Чтение. public string GetFullName() {return fullName;} // Модификация. public void SetFullName(string n) { // Удаление недопустимых символов (!, @, #, $, %), // проверка максимальной длины (или регистра символов) // перед присваиванием. fullName = n; } } Конечно, компилятору "все равно", что вы будете вызывать методы чтения и модификации данных. Поскольку GetFullName() и SetFullName() инкапсулируют приватную строку с именем fullName, выбор таких имен кажется вполне подходящим. Логина вызова может быть следующей. // Использование средств чтения/модификации. static void Main(string[] args) { Employee p = new Employee(); p.SetFullName("Фред Флинстон"); Console.WriteLine("Имя работника: {0} ", p.GetFullName()); Console.ReadLine(); } Инкапсуляция на основе свойств класса В отличие от традиционных методов чтения и модификации, языки .NET тяготеют к реализации принципа инкапсуляции на основе использования свойств, которые представляют доступные для внешнего пользователя элементы данных. Вместо того, чтобы вызывать два разных метода (get и set) для чтения и установки данных состояния объекта, пользователь получает возможность вызвать нечто, похожее на общедоступное поле. Предположим, что мы имеем свойство с именем ID (код), представляющее внутренний член-переменную empID типа Employee. Синтаксис вызова в данном случае должен выглядеть примерно так. // Синтаксис установки/чтения значения ID работника. static void Main(string[] args) { Employee p = new Employee(); // Установка значения. p.ID = 81; // Чтение значения. Console.WriteLine ("ID работника: {0} ", p.ID); Console.ReadLine(); } Свойства типа "за кадром" всегда отображаются в "настоящие" методы чтения и модификации. Поэтому, как разработчик класса, вы имеете возможность реализовать любую внутреннюю логику, выполняемую перед присваиванием соответствующего значения (например, перевод символов в верхний регистр, очистку значения от недопустимых символов, проверку принадлежности числового значения диапазону допустимости и т.д.). Ниже демонстрируется синтаксис C#. использующий, кроме свойства ID, свойство Pay (оплата), которое инкапсулирует поле currPay, a также свойство Name (имя), которое инкапсулирует данные fullName. // Инкапсуляция с помощью свойств. public class Employee { ... private int empID; private float currPay; private string fullName; // Свойство для empID. public int ID { get {return empID;} set { // Вы можете проверить и, если требуется, модифицировать // поступившее значение перед присваиванием. empID = value; } } // Свойство для fullName. public string Name { get { return fullName; } set { fullName = value; } } // Свойство для currPay. public float Pay { get { return currPay; } set { currPay = value; } } } Свойство в C# компонуется из блока чтения и блока модификации (установки) значении. Ярлык value в C# представляет правую сторону оператора присваивания. Соответствующий ярлыку value тип данных зависит от того, какого сорта данные этот ярлык представляет. В данном примере свойство ID оперирует с типом данных int, который, как вы знаете, отображается в System.Int32. // 81 принадлежит System.Int32, // поэтому "значением" является System.Int32. Employee e = new Employee(); e.ID = 81; Чтобы это доказать, предположим, что вы добавили следующий программный код для установки свойства ID. // Свойство для empID. public int ID { get {return empID;} set { Console.WriteLine("value является экземпляром {0} ", value.GetType()); Console.WriteLine("Значение value: {0} ", value); empID = value; } } Выполнив приложение, вы должны увидеть вариант вывода, показанный на рис. 4.5. 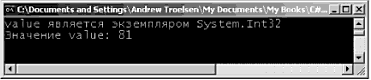 Рис. 4.5. Значение value после установки для ID значения 81 Замечание. Строго говоря, ярлык value в C# является не ключевым оловом, а, скорее, контекстным ключевым словом, представляющим неявный параметр, который используется в операторе присваивания в контексте метода, используемого для установки значения свойства. Поэтому вполне допустимо иметь члены-переменные и локальные элементы данных с именем value. Следует понимать, что свойства (в отличие от традиционных методов чтения и модификации) еще и упрощают работу с типами, поскольку свойства способны "реагировать" на внутренние операции в C#. Например, предположим, что тип класса Employee имеет внутренний приватный член, представляющий значение возраста работника. Вот соответствующая модификация класса. public class Employee { … // Текущий возраст работника. private int empAge; public Employee(string fullName, int age, int empID, float currPay) { … this.empAge = age; } public int Age { get { return empAge; } set { empAge = value; } } public void DisplayStats() { … Console.WriteLine("Возраст: {0} ", empAge); } } Теперь предположим, что вы создали объект Employee с именем joe. Вы хотите, чтобы в день рождения работника значение переменной возраста увеличивалось на единицу. Используя традиционные методы чтения и модификации, вы должны применить, например, следующий программный код. Employee joe = new Employee(); joe.SetAge(joe.GetAge() + 1); Но если инкапсулировать empAge, используя "правильный" синтаксис, вы сможете просто написать: Employee joe = new Employee(); joe.Age++; Внутреннее представление свойств в C# Многие программисты (особенно те, которые привыкли использовать C++) стремятся использовать традиционные префиксы get_ и set_ для методов чтения и модификации (например, get_FullName() и set_FullName()). Против самого соглашения возражений нет. Однако следует знать, что "за кадром" свойства в C# представляются программным кодом CIL, использующим такие же префиксы. Например, если открыть компоновочный блок Employees.exe с помощью ildasm.exe, вы увидите, что каждое свойство XXX на самом деле сводится к скрытым методам get_XXX()/set_XXX() (рис. 4.6).  Рис. 4.6. Отображение свойств XXX в скрытые методы get_XXX() и set_XXX() Предположим теперь, что тип Employee имеет частный член-переменную с именем empSSN для представления номера социальной страховки работника. Эта переменная устанавливается через параметр конструктора, а для управления этой переменной используется свойство SocialSecurityNumber. // Добавление поддержки нового поля, представляющего SSN-код. public class Employee { … // Номер социальной страховки (SSN). private string empSSN; public Employes (string fullName, int age, int empID, float currPay, string ssn) { … this.empSSN = ssn; } public string SocialSecurityNumber { get { return empSSN; } set { empSSN = value; } } public void DisplayStats() { … Console.WriteLine("SSN: {0} ", empSSN); } } Если бы вы также определили два метода get_SocialSecurityNumber() и set_SocialSecurityNumber(), то получили бы ошибки компиляции. // Свойство в C# отображается в пару методов get_/set_. public class Employee { // ОШИБКА! Уже определены самим свойством! public string get_SocialSecurityNumber() { return empSSN; } public void set_SocialSecurityNumber(string val) { empSSN = val; } } Замечание. В библиотеках базовых классов .NET всегда отдается предпочтение свойствам типа (в сравнении с традиционными методами чтения и модификации). Поэтому, чтобы строить пользовательские типы, которые хорошо интегрируются с платформой .NET, следует избегать использования традиционных методов get и set. Контекст операторов get и set для свойств До появления C# 2005 область видимости get и set задавалась исключительно модификаторами доступа в определении свойства. // Логика get и set здесь открыта, // в соответствии с определением свойства. public string SocialSecurityNumber { get {return empSSN;} set {empSSN = value;} } В некоторых случаях бывает нужно указать свои области видимости для методов get и set. Чтобы сделать это, просто добавьте префикс доступности (в виде соответствующего ключевого слова) к ключевому слову get или set (при этом область видимости без уточнения будет соответствовать области видимости из определения свойства). // Пользователи объекта могут только получить значение, // но производные типы могут также установить значение. public string SocialSecurityNumber { get { return empSSN;} protected set {empSSN = value;} } В данном случае логика set для SocialSecurityNumber может вызываться только данным классом и производными классами, а поэтому не может быть доступна на уровне экземпляра объекта. Свойства, доступные только для чтения, и свойства, доступные только для записи При создании типов класса можно создавать свойства, доступные только для чтения. Для этого просто создайте свойство без соответствующего блока set. Точно так же, если вы хотите иметь свойство, допускающее только запись, опустите блок get. Для нашего примера в этом нет необходимости, но вот как можно изменить свойство SocialSecurityNumber, чтобы оно было доступно только для чтения. public class Employee { … // Теперь это свойство, доступное только для чтения. public string SocialSecurityNumber {get {return empSSN;}} } При таком изменений единственным способом установки номера социальной страховки для работника оказывается установка этого номера через аргумент конструктора. Статические свойства В C# также поддерживаются статические свойства. Вспомните из главы 3, что статические члены доступны на уровне класса, а не экземпляра (объекта) этого класса. Например, предположим, что тип Employee определяет элемент статических данных, представляющий название организации, в которой трудоустроен работник. Можно определить статическое свойство (например, уровня класса) так, как показано ниже. // Статические свойства должны оперировать со статическими данными! public class Employee { private static string companyName; public static String Company { get { return companyName; } set { companyName = value; } } … } Статические свойства используются точно так же, как статические методы. // Установка и чтение названия компании, // в которой трудоустроены эти работники… public static int Main(string[] args) { Employee.Company = "Intertech training"; Console.WriteLine("Эти люди, работают в {0} ", Employee.Company); … } Также вспомните из главы 3, что в C# поддерживаются статические конструкторы. Поэтому, если вы хотите, чтобы статическое свойство companyName всегда устанавливалось равным Intertech Training, можете добавить в класс Employee член следующего вида. // Статический конструктор без модификаторов доступа и аргументов. public class Employee { … static Employee() { companyName = "Intertech Training"; } } В данном случае мы ничего не выиграли в результате добавления статического конструктора, если учесть, что тот же результат можно было бы достичь с помощью простого присваивания значения члену-переменной companyName, как показано ниже. // Статические свойства должны оперировать со статическими данными! public class Employee { private static string companyName = "Intertech Training"; } Однако следует вспомнить о том. что статические конструкторы оказываются очень полезными тогда, когда значения для статических данных становятся известны только в среде выполнения (например, при чтении из базы данных). В завершение нашего обзора возможностей инкапсуляции следует подчеркнуть, что свойства используются с той же целью, что и классическая пара методов чтения/модификации данных. Преимущество свойств заключается в том, что пользователи объекта получают возможность изменять внутренние данные, используя для этого один именованный элемент. Второй принцип: поддержка наследования в C# Теперь, после исследования различных подходов, позволяющих создавать классы с хорошей инкапсуляцией, пришло время заняться построением семейств связанных классов. Как уже упоминалось, наследование является принципом ООП, упрощающим многократное использование программного кода. Наследование бывает двух видов: классическое наследование (отношение подчиненности, "is-a") и модель локализации/делегирования (отношение локализации, "has-a"). Сначала мы рассмотрим классическую модель отношения подчиненности. При создании отношения подчиненности между классами вы строите зависимость между типами. Основной идеей классического наследования является то, что новые классы могут использовать (и, возможно, расширять) функциональные возможности исходных классов. Для примера предположим, что вы хотите использовать функциональные возможности класса Employee и создать два новых класса – Salesperson (продавец) и Manager (менеджер). Иерархия классов будет выглядеть примерно так, как показано на рис. 4.7.  Рис. 4.7. Иерархия классов служащих Из рис. 4.7 можно понять, что Salesperson (продавец) является ("is-a") Employee (работником), точно так же, как и Manager (менеджер). В классической модели наследования базовые классы (например. Employee) используются для определения общих характеристик, которые будут присущи всем потомкам. Подклассы (например, SalesPerson и Manager) расширяют общие функциональные возможности, добавляя специфические элементы поведения. Для нашего примера мы предположим, что класс Manager расширяет Employee, обеспечивал запись числа опционов, а класс SalesPerson поддерживает информацию о числе продаж. В C# расширение класса задается в определении класса операцией, обозначаемой двоеточием (:). Так получаются производные типы класса в следующем фрагменте программного кода. // Добавление двух подклассов в пространстве имен Employees. namespace Employees { public class Manager: Employee { // Менеджер должен знать число опционов. private ulong numberOfOptions; public ulong NumbOpts { get {return numberOfOptions;} set {numberOfOptions = value;} } } public class SalesPerson: Employee { // Продавец должен знать число продаж. private int numberOfSales; public int NumbSales { get {return numberOfSales;} set {numberOfSales = value;} } } } Теперь, когда создано отношение подчиненности, SalesPerson и Manager автоматически наследуют все открытие (и защищенные) члены базового класса Employee. Например: // Создание подкласса и доступ к функциональным возможностям // базового класса. static void Main (string[] args) { // Создание экземпляра SalesPerson. SalesPerson stan = new SalesPerson(); // Эти члены наследуют возможности базового класса Employee. stan.ID = 100; stan.Name = "Stan"; // Это определено классом SalesPerson. stan.NumbSales = 42; Console.ReadLine(); } Следует знать, что наследование сохраняет инкапсуляцию. Поэтому производный класс не может иметь непосредственный доступ к приватным членам, определенным базовым классом. Управление созданием базовых классов с помощью base В настоящий момент SalesPerson и Manager можно создать только с помощью конструктора, заданного по умолчанию. Поэтому предположим, что в тип Manager добавлен новый конструктор с шестью аргументами, который вызывается так, как показано ниже. static void Main(string[] args) { // Предположим, что есть следующий конструктор с параметрами // (имя, возраст, ID, плата, SSN, число опционов). Manager chucky = new Manager("Chucky", 35, 92, 100000, "333-23-2322", 9000); } Если взглянуть на список аргументов, можно сразу понять, что большинство из них должно запоминаться в членах-переменных, определенных базовым классом Employee. Для этого вы могли бы реализовать этот конструктор так, как предлагается ниже. // Если не указано иное, конструктор подкласса автоматически вызывает // конструктор базового класса, заданный по умолчанию. public Manager(string fullName, int age, int empID, float currPay, string ssn, ulong numbOfOpts) { // Это наш элемент данных. numberOfOptions = numbOfOpts; // Использование членов, наследуемых от Employee, // для установки данных состояния. ID = empID; Age = age; Name = fullName; SocialSecurityNumber = ssn; Pay = currPay; } Строго говоря, это допустимый, но не оптимальный вариант. В C#, если вы не укажете иное, конструктор базового класса, заданный по умолчанию, вызывается автоматически до выполнения логики любого пользовательского конструктора Manager. После этого текущая реализация получает доступ к множеству открытых свойств базового класса Employee, чтобы задать его состояние. Поэтому здесь при создании производного объекта вы на самом деле "убиваете семь зайцев" (пять наследуемых свойств и два вызова конструктора)! Чтобы оптимизировать создание производного класса, вы должны реализовать свои конструкторы подклассов так, чтобы явно вызвался подходящий пользовательский конструктор базового класса, а не конструктор, заданный по умолчанию. Таким образом можно уменьшить число вызовов инициализации наследуемых членов (что экономит время). Позвольте для этого модифицировать пользовательский конструктор. // На этот раз используем ключевое слово C# "base" для вызова // пользовательского конструктора с базовым классом. public Manager (string fullName, int age, int empID, float currPay, string ssn, ulong numbOfOpts): base(fullName, age, empID, currPay, ssn) { numberOfOptions = numbOfOpts; } Здесь конструктор был дополнен довольно запутанными элементами синтаксиса. Непосредственно после закрывающей скобки списка аргументов конcтруктора стоит двоеточие, за которым следует ключевое слово C# base. В этой ситуации вы явно вызываете конструктор с пятью аргументами, определенный классом Employees избавляясь от ненужных вызовов в процессе создания дочернего класса. Конструктор SalesPerson выглядит почти идентично. // Как правило, каждый подкласс должен явно вызывать // подходящий конструктор базового класса. public SalesPerson(string fullName, int age, int empID, float currPay, string ssn, int numbOfSales): base(fullName, age, empID, currPay, ssn) { numberOfSales = numbOfSales; } Вы должны также знать о том. что ключевое слово base можно использовать всегда, когда подклассу нужно обеспечить доступ к открытым или защищенным членам, определённым родительским классом. Использование этого ключевого слова не ограничено логикой конструктора. В нашем следующем обсуждении полиморфизма вы увидите примеры, в которых тоже используется ключевое слово base. Множественные базовые классы Говоря о базовых классах, важно не забывать, что в C# каждый класс должен иметь в точности один непосредственный базовый класс. Таким образом, нельзя иметь тип с двумя или большим числом базовых классов (это называется множественным наследованием). Вы увидите в главе 7, что в C# любому типу позволяется иметь любое число дискретных интерфейсов. Таким образом класс в C# может реализовывать различные варианты поведения, избегая проблем, присущих классическому подходу, связанному с множественным наследованием. Аналогично можно сконфигурировать обычный интерфейс, как производный от множественных интерфейсов (см. главу 7). Хранение семейных тайн: ключевое слово protected Вы уже знаете, что открытые элементы непосредственно доступны отовсюду, а приватные элементы недоступны для объектов вне класса, определяющего эти элементы. Язык C#, занимающий лидирующие позиции среда многих других современных объектных языков, обеспечивает еще один уровень доступа: защищенный. Если базовый класс определяет защищенные данные или защищенные члены, он может создать набор элементов, которые будут непосредственно доступны для любого дочернего класса. Например, чтобы позволить дочерним классам SalesPerson и Manager непосредственный доступ к сектору данных, определенному классом Employee, обновите оригинальное определение класса Employee так, как показано ниже. // Защищенные данные состояния. public class Employee { // Дочерние классы могут иметь непосредственный доступ // к этой информации, а пользователи объекта – нет. protected string fullName; protected int empID; protected float currPay; protected string empSSN; protected int empAge; … } Удобство определения защищенных членов в базовом классе заключается в том, что производные типы теперь могут иметь доступ к данным не только через открытые методы и свойства. Недостатком, конечно, является то, что при прямом доступе производного типа к внутренним данным родителя вполне вероятно случайное нарушение существующих правил, установленных в рамках общедоступных свойств (например, превышение допустимого числа страниц для "мини-романа"). Создавая защищенные члены, вы задаете определенный уровень доверия между родительским и дочерним классом, поскольку компилятор не сможет обнаружить нарушения правил, предусмотренных вами для данного типа. Наконец, следует понимать, что с точки зрения пользователя объекта защищенные данные воспринимаются, как приватные (поскольку пользователь находится "за пределами семейства"). Так, следующий вариант программного кода некорректен. static void Main(string[] args) { // Ошибка! Защищенные данные недоступны на уровне экземпляра. Employee emp = new Employee(); emp.empSSN = "111-11-1111"; } Запрет наследования: изолированные классы Создавая отношения базовых классов и подклассов, вы получаете возможность использовать поведение существующих типов. Но что делать, когда нужно определить класс, не позволяющий получение подклассов? Например, предположим, что в наше пространство имен добавлен еще один класс, расширяющий уже существующий тип SalesPerson. На рис. 4.8 показана соответствующая схема.  Рис. 4.8. Расширенная иерархия служащих Класс PTSalesPerson является классом, представляющим продавца, работающего на неполную ставку, и предположим, например, что вы хотите, чтобы никакой другой разработчик не мог создавать подклассы из PTSalesPerson. (В конце концов, какую еще неполную ставку можно получить на основе неполной ставки?) Чтобы не допустить возможности расширения класса, используйте ключевое слово C# sealed. // Класс PTSalesPerson не сможет быть базовым классом. public sealed class PTSalesPerson: SalesPerson { public PTSalesPerson(string fullName, int age, int empID, float currPay, string ssn, int numbOfSales): base (fullName, age, empID, currPay, ssn, numbOfSales) { // Логика конструктора… } // Другие члены… } Поскольку класс PTSalesPerson изолирован, он не может служить базовым Классам никакому другому типу. Поэтому при попытке расширить PTSalesPersоn вы получите сообщение об ошибке компиляции. // Ошибка компиляции! public class ReallyPTSalesPerson: PTSalesPerson {…} Наиболее полезным ключевое слово sealed оказывается при создании автономных классов утилит. Класс String, определённый в пространстве имен Sуstem, например, явно изолирован. public sealed class string: object, IComparable, ICloneable, IConvertible, IEnumerable {…} Поэтому вы не сможете создать новый класс, производный от System.String: // Снова ошибка! public class MyString: string Если вы хотите создать новый класс, использующий функциональные возможности изолированного класса, единственным вариантом будет отказ от классического наследования и использование модели локализации/делегирования (известной еще как отношение локализации, "has-a"). Модель локализации/делегирования Как уже отмечалось в этой главе, наследование можно реализовать двумя способами. Только что мы исследовали классическое отношение подчиненности ("is-a"). Чтобы завершить обсуждение второго принципа ООП, давайте рассмотрим отношение локализации (отношение "has-a", также известное под названием модели локализации/делегирования). Предположим, что мы создали новый класс, моделирующий пакет льгот работника. // Этот тип будет функционировать, как вложенный класс. public class BenefitPackage { // Другие члены, представляющие пакет страховок, // медицинского обслуживания и т.д. public double ComputePayDeduction() {return 125.0;} } Ясно, что отношение подчиненности ("is-a") между типами BenefitPackage (пакет льгот) и Employee (работник) выглядело бы достаточно странно. (Является ли менеджер пакетом льгот? Вряд ли.) Но должно быть ясно и то, что какая-то связь между этими типами необходима. Короче, вы должны выразить ту идею, что каждый работник имеет ("has-a") пакет льгот. Для этого определение класса Employee следует обновить так", как показано ниже. // Работники теперь имеют льготы. public class Employee { … // Содержит объект BenefitPackage. protected BenefitPackage empBenefits = new BenefitPackage(); } Здесь вы успешно создали вложенный объект. Но чтобы открыть функциональные возможности вложенного объекта внешнему миру, требуется делегирование. Делегирование означает добавление в класс-контейнер таких членов, которые будут использовать функциональные возможности содержащегося в классе объекта. Например, можно изменить класс Employee так, чтобы он открывал содержащийся в нем объект empBenefits с помощью некоторого свойства, а также позволял использовать функциональные возможности этого объекта с помощью нового метода GetBenefitCost(). public class Employee { protected BenefitPackage empBenefits = new BenefitPackage(); // Открытие некоторых функциональных возможностей объекта. public double GetBenefitCost() { return empBenefits.ComputePayDeduction(); } // Доступ к объекту через пользовательское свойство. public BenefitPackage Benefits { get {return empBenefits;} set {empBenefits = value;} } } В следующем обновленном методе Main() обратите внимание на то, как можно взаимодействовать с внутренним типом BenefitsPackage, определяемым типом Employee. static void Main(string[] args) { Manager mel; mel = new Manager(); Console.WriteLine (mel.Benefits.ComputerPayDeduction()); … Consolе.ReadLine(); } Вложенные определения типов Перед тем как рассмотреть заключительный принцип ООП (полиморфизм), давайте обсудим технику программирования, называемую вложением типов. В C# можно определить тип (перечень, класс, интерфейс, структуру или делегат) в пределах области видимости класса или структуры. При этом вложенный ("внутренний") тип считается членом содержащего его ("внешнего") класса, с точки зрения среды выполнения ничем не отличающимся от любого другого члена (поля, свойства, метода, события и т.п.). Синтаксис, используемый для вложения типа, исключительно прост. public class OuterClass { // Открытый вложенный тип могут использовать все. public class PublicInnerClass{} // Приватный вложенный тип могут использовать только члены // содержащего его класса. private class PrivateInnerClass{} } Синтаксис здесь ясен, но понять, почему вы можете это делать, не так просто. Чтобы прийти к пониманию этого подхода, подумайте над следующим. • Вложение типов подобно их композиции ("has-a"), за исключением того, что вы имеете полный контроль над доступом на уровне внутреннего типа, а не содержащегося объекта. • Ввиду того, что вложенный тип является членом класса-контейнера, этот тип может иметь доступ к приватным членам данного класса. • Часто вложенный тип играет роль вспомогательного элемента для класса-контейнера, и его использование "внешним миром" не предполагается. Когда некоторый тип содержит другой тип класса, он может создавать члены-переменные вложенного типа, точно так же, как для любого другого своего элемента данных. Но если вы пытаетесь использовать вложенный тип из-за границ внешнего типа, вы должны уточнить область видимости вложенного типа, указав его абсолютное имя. Изучите следующий пример программного кода. static void Main (string[] args) { // Создание и использование открытого внутреннего класса. Все ОК! OuterClass.PublicInnerClass inner; inner = new OuterClass.PublicInnerClass(); // Ошибка компиляции! Нет доступа к приватному классу. OuterClass.PrivateInnerClass inner2; inner2 = new OuterClass.PrivateInnerClass(); } Чтобы использовать этот подход в нашем примере, предположим, что мы вложили BenefitPackage непосредственно в тип класса Employee. // Вложение BenefitPackage. public class Employee { ... public class BenefitPackage { public double ComputePayDeduction() {return 125.0;} } } Глубина вложения может быть любой. Предположим, что мы хотим создать перечень BenefitPackageLevel, указывающий различные уровни льгот, которые может выбрать работник. Чтобы программно реализовать связь между Employee, BenefitPackage и BenefitPackageLevel, можно вложить перечень так, как показано ниже. // Employee содержит BenefitPackage. public class Employee { // BenefitPackage содержит BenefitPackageLevel. public class BenefitPackage { public double ComputePayDeduction() {return 125.0;} public enum BenefitPackageLevel { Standard, Gold, Platinum } } } С учетом отношений вложении обратите внимание на то, как приходится иcпользовать этот перечень. Static void Main(string[] args) { // Создание переменной BenefitPackageLevel. Employee.BenefitPackage.BenefitPackageLevel myBenefitLevel = Employee.BenefitPackage.BenefitPackageLevel.Platinum; … } Третий принцип: поддержка полиморфизма в C# Теперь давайте рассмотрим заключительный принцип ООП – полиморфизм. Напомним, что базовый класс Employee определил метод GiveBonus(), который был реализован так. // Предоставление премий работникам. public class Employee { … public void GiveBonus(float amount) { currPay += amount;} } Ввиду того, что этот метод является открытым, вы теперь имеете возможность выдать премии продавцам и менеджерам (а также продавцам, занятым неполный рабочий день). static void Main(string[] args) { // Премии работникам. Manager chucky = new Manager("Сhucky", 50, 92, 100000, "333-23-2322", 9000); chucky.GiveBonus(300); chucky.DisplayStats(); SalesPerson fran = new SalesPerson("Fran", 43, 93, 3000, "932-32- 3232 " , 31); fran.GiveBonus(200); fran.DisplayStats(); Console.ReadLine(); } Недостаток данного варианта в том, что наследуемый метод GiveBonus() действует одинаково для всех подклассов. В идеале премия продавца, как и продавца, работающего на неполную ставку, должна зависеть от числа продаж. Возможно, менеджеры должны получать льготы в дополнение к денежному вознаграждению, В связи с этим возникает интересный вопрос: "Каким образом родственные объекты могут по-разному реагировать на одинаковые запросы?" Ключевые слова virtual и override Полиморфизм обеспечивает подклассам возможность задать собственную реализацию методов, определенных базовым классом. Чтобы соответствующим образом изменить наш проект, мы должны рассмотреть применение ключевых слов C# virtual и override. Если в базовом классе нужно определить метод, допускающий переопределение подклассом, то этот метод должен быть виртуальным. public class Employee { // GiveBonus() имеет реализацию, заданную по умолчанию, // но дочерние классы могут переопределить это поведение. public virtual void GiveBonus(float amount) {currPay += amount;} … } Чтобы в подклассе переопределить виртуальный метод, используется ключевое слово override. Например, SalesPerson и Manager могут переопределить GiveBonus() так, как показано ниже (мы предполагаем, что PTSalesPerson переопределяет GiveBonus() примерно так же, как SalesPerson), public class SalesPerson: Employee { // Премия продавца зависит от числа продаж. public override void GiveBonus(float amount) { int salesBonus = 0; if (numberOfSales ›= 0 && numberOfSales ‹= 100) salesBonus = 10; else if (numberOfSales ›= 101&& numberOfSales ‹= 200) salesBonus = 15; else salesBonus = 20; // Вcе, что больше 200. base.GiveBonus(amount * salesBonus); } } public class Manager: Employee { // Менеджер в дополнение к денежному вознаграждению // получает некоторое число опционов. public override void GiveBonus(float amount) { // Прибавка к зарплате. base.GiveBonus(amount); // И получение опционов… Random r = new Random(); numberOfOptions += (ulong)r.Next(500); } … } Обратите внимание на то, что переопределенный метод будет использовать поведение, принятое по умолчанию, если указать ключевое слово base. При этом нет необходимости снова реализовывать логику GiveBonus(), а можно снова использовать (и, возможно, расширить) поведение родительского класса, принятое по умолчанию. Также предположим, что Employee.DisplayStats() был объявлен виртуально и переопределен каждым подклассом, чтобы учесть число продаж (для продавцов) и текущее состояние опционов (для менеджеров). Теперь, когда каждый подкласс может по-своему интерпретировать виртуальные методы, каждый экземпляр объекта ведет себя более независимо. static void Main (string[] args) { // Лучшая система премиальных! Manager chucky = new Manager("Chucky", 50, 92, 100000, "333-23-2322", 9000); chucky.GiveBonus(300); chucky.DisplayStats(); SalesPerson fran = new SalesPerson("Fran", 43, 93, 3000, "932-32-3232", 31); fran.GiveBonus(200); fran.DisplayStats(); } Снова о ключевом слове sealed Ключевое слово sealed может также применяться к членам типа, чтобы запретить переопределение таких виртуальных членив в производных типах. Это оказывается полезным тогда, когда нужно изолировать не весь класс, а только несколько его методов или свойств. Например, если (по некоторой причине) классу PTSalesPerson требуется разрешить расширение другими классами, но нужно гарантировать, чтобы эти классы не могли переопределять виртуальный метод GiveBonus(), можно использовать следующий вариант программного кода. // Этот класс можно расширить, // но GiveBonus() не может переопределяться производным классом. public class PTSalesPerson: SalesPerson { … public override sealed void GiveBonus(float amount) { … } } Абстрактные классы В данный момент базовый класс Employee скомпонован так, что он может поставлять своим потомкам защищенные члены-переменные, а также два виртуальных метода (GiveBonus() и DisplayStats()), которые могут переопределяться производным классом. Все это хорошо, но данный вариант программного кода имеет один недостаток: вы можете непосредственно создавать экземпляры базового класса Employee. // Что же это значит? Employee X = new Employee (); В данном примере единственной целью базового класса Employee является определение общих полей и членов для всех подклассов. Вероятно, вы не предполагали, что кто-то будет непосредственно создавать экземпляры класса, поскольку тип Employee (работник) является слишком общим. Например, если я приду к вам и скажу "Я работаю!", то в ответ я, скорее всего, услышу вопрос "Кем вы работаете?" (консультантом, инструктором, ассистентом администратора, редактором, представителем Белого Дома и т.п.). Ввиду того, что многие базовые классы оказываются чем-то вроде "небожителей", для нашего примера лучше всего запретить возможность непосредственного создания новых объектов Employee. В C# это можно сделать программными средствами, используя ключевое слово abstract. // Обозначение класса Employee, как абстрактного, // запрещает непосредственное создание его экземпляров. abstract public class Employee {…} Если вы теперь попытаетесь создать экземпляр класса Employee, то получите ошибку компиляции. // Ошибка! Нельзя создать экземпляр абстрактного класса. Employee X = new Employee(); Превосходно! К этому моменту мы построили очень интересную иерархию служащих. Мы добавим новые функциональные возможности в это приложение немного позже, когда будем рассматривать правила классификации в C#. Иерархия типов, определенных на данный момент, показана на рис. 4.9. Исходный код. Проект Employees размещен в подкаталоге, соответствующем главе 4. Принудительный полиморфизм: абстрактные методы Если класс является абстрактным базовым классом, он может определять любое число абстрактных членов (их аналогами в C++ являются "чистые" виртуальные функции). Абстрактные методы могут использоваться тогда, когда требуется определить метод без реализации, заданной по умолчанию. В результате производным классам придется использовать полиморфизм, поскольку им придется "уточнять" детали абстрактных методов. Здесь сразу же возникает вопрос, зачем это нужно. Чтобы понять роль абстрактных методов, давайте снова рассмотрим иерархию форм, уже упоминавшуюся в этой главе и расширенную так, как показано на рис. 4.10.  Рис. 4.9. Полная иерархии служащих 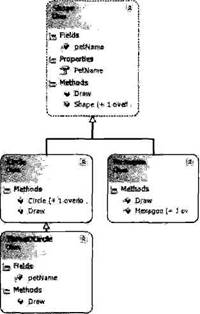 Рис. 4.10. Иерархия форм Как и в случае иерархии служащих, лучше запретить пользователю объекта создавать экземпляры Shape (форма) непосредственно, поскольку соответствующее понятие слишком абстрактно. Для этого необходимо определить тип Shape, как абстрактный класс. namespace Shapes { public abstract class Shape { // Форме можно назначить понятное имя. protected string petName; // Конструкторы. public Shape()(petName = "БезИмени";} public Shape(string s) (petName = s;} // Draw() виртуален и может быть переопределен. public virtual void Draw() { Console.WriteLine("Shape.Draw()"); } public string PetName { get { return petName; } set { petName = value; } } } // Circle не переопределяет Draw(). public class Circle: Shape { public Circle() {} public Circle(string name): base(name) {} } // Hexagon переопределяет Draw(). public class Hexagon: Shape { public Hexagon () {} public Hexagon (string name): base(name) {} public override void Draw() { Console.WriteLine("Отображение шестиугольника {0}", petName); } } } Обратите внимание на то, что класс Shape определил виртуальный метод с именем Draw(). Вы только что убедились, что подклассы могут переопределять поведение виртуального метода, используя ключевое слово override (как в случае класса Hexagon). Роль абстрактных методов становится совершенно ясной, если вспомнить, что подклассам не обязательно переопределять виртуальные методы (как в случае Circle). Таким образом, если вы создадите экземпляры типов Hexagon и Circle, то обнаружите, что Hexagon "знает", как правильно отобразить себя. Однако Circle в этом случае будет "не на шутку озадачен" (рис. 4.11). // Объект Circle не переопределяет реализацию Draw() базового класса. static void Main(string[] args) { Hexagon hex = new Hexagon("Beth"); hex.Draw(); Circle car = new Circle("Cindy"); // М-м-м-да. Используем реализацию базового класса. cir.Draw(); Console.ReadLine(); } 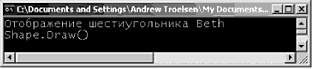 Рис. 4.11. Виртуальные методы переопределять не обязательно Ясно, что это не идеальный вариант иерархии форм. Чтобы заставить каждый производный класс иметь свой собственный метод Draw(), можно задать Draw(), как абстрактный метод класса Shape, т.е метод, который вообще не имеет реализации, заданной по умолчанию. Заметим, что абстрактные методы могут определяться только в абстрактных классах. Если вы попытаетесь сделать это в другом классе, то получите ошибку компиляции. // Заставим всех "деток" иметь cвоe представление. public abstract class Shape { ... // Теперь Draw() полностью абстрактный // (обратите внимание на точку с запятой). public abstract void Draw(); … } Учитывая это, вы обязаны реализовать Draw() в классе Circle. Иначе Circle тоже должен быть абстрактным типом, обозначенным ключевым словом abstract (что для данного примера не совсем логично). // Если не задать реализацию метода Draw(), то класс Circle должен // быть абстрактным и не допускать непосредcтвенную реализацию! public class Circle: Shape { public Circle() {} public Circle(string name): base (name) {} // Теперь Circle должен "понимать", как отобразить себя. public override void Draw() { Console.WriteLine("Отображение окружности {0}", petName); } } Для иллюстрации упомянутых здесь возможностей полиморфизма рассмотрим следующий программный код, // Создание массива различных объектов Shape. static void Main(string [] args) { Console.WriteLine("***** Забавы с полиморфизмом *****\n"); Shape[] myShapes = {new Hexagon(), new Circle(), new Hexagon("Mick"), new Circle("Beth"), new Hexagon("Linda")}; // Движение по массиву и отображение объектов. for (int i = 0; i ‹ myShapes.Length; i++) myShapes[i].Draw(); Console.ReadLine(); } Соответствующий вывод показан на рис. 4.12. 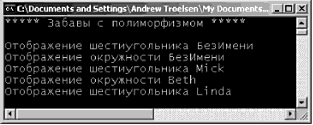 Рис. 4.12. Забавы с полиморфизмом Здесь метод Main() иллюстрирует полиморфизм в лучшем его проявлении. Напомним, что при обозначении класса, как абстрактного, вы теряете возможность непосредственного создания экземпляров соответствующего типа. Однако вы можете хранить ссылки на любой подкласс в абстрактной базовой переменной. При выполнении итераций по массиву ссылок Shape соответствующий тип будет определен в среде выполнения. После этого будет вызван соответствующий метод. Возможность скрывать члены В C# также обеспечивается логическая противоположность возможности переопределения методов; возможность скрывать члены. Формально говоря, если производный класс повторно объявляет член, идентичный унаследованному от базового класса, полученный класс скрывает (или затеняет) соответствующий член родительского класса. На практике эта возможность оказывается наиболее полезной тогда, когда приходится создавать подклассы, созданные другими разработчиками (например, при использовании купленного пакета программ .NET). Для иллюстрации предположим, что от своего коллеги (или одноклассника) вы получили класс ThreeDCircle, который получается из System.Object. public class ThreeDCircie { public void Draw() { Console.WriteLine ("Отображение трехмерной окружности"); } } Вы полагаете, что ThreeDCircle относится ("is-a") к типу Circle, поэтому пытаетесь получить производный класс из существующего типа Circle. public class ThreeDCircie: Circle { public void Draw() { Console.WriteLine("Отображение трехмерной окружности"); } } В процессе компиляции в Visual Studio 2005 вы увидите предупреждение, показанное на рис. 4.13. ('Shapes.ThreeDCircle.Draw()' скрывает наследуемый член 'Shapes.Circle.Draw()'. Чтобы переопределить соответствующую реализацию данным членом, используйте ключевое слово override, иначе используйте ключевое слово new)  Рис. 4.13. Ой! ThreeDCircle.Draw() скрывает Circle.Draw Есть два варианта решения этой проблемы. Можно просто изменить версию Draw() родителя, используя ключевое слово override. При таком подходе тип ThreeDCircie может расширить возможности поведения родителя так, как требуется. Альтернативой может быть использование ключевого слова new (с членом Draw() типа ThreeDCircle). Это явное указание того, что реализация производного типа должна скрывать версию родителя (это может понадобиться тогда, когда полученные извне программы .NET не согласуются с программами, уже имеющимися у вас). // Этот класс расширяет Circle и скрывает наследуемый метод Draw(). public class ThreeDCircle: Circle { // Скрыть любую внешнюю реализацию Draw(). public new void Draw() { Console.WriteLine("Отображение трехмерной окружности"); } } Вы можете использовать ключевое слово new с любыми членами, унаследованными от базового класса (с полями, константами, статическими членами, свойствами и т.д.). Например, предположим, что ThreeDCircle должен скрыть наследуемое поле petName. public class ThreeDCircle: Circle { new protected string petName; new public void Draw() { Console.WriteLine("Отображение трехмерной окружности"); } } Наконец, следует знать о том, что возможность использовать реализацию базового класса для скрытого члена тоже не исключается, но в этом случае следует использовать явное приведение типов (см. следующий раздел). Например: static void Main(string[] args) { ThreeDCircie о = new ThreeDCircle(); о.Draw(); // Вызывается ThreeDCircle.Draw() ((Circle)o).Draw(); // Вызывается Circle.Draw() } Исходный код. Иерархия Shapes размещается в подкаталоге, соответствующем главе 4. Правила приведения типов в C# Пришло время изучить правила выполнения операций приведения типов в C#. Вспомните иерархию Employees и тот факт, что наивысшим классом в системе является System.Object. Поэтому все в вашей программе является объектами и может рассматриваться, как объекты. С учетом этого вполне допустимо сохранять экземпляры любого типа в объектных переменных. // Manager – это System.Object. object frank = new Manager("Frank Zappa", 9, 40000, "111-11-1111", 5); В системе Employees типы Manager, Salesperson и PTSalesPerson расширяют Employee, поэтому можно запомнить любой из этих объектов в подходящей ссылке базового класса. Так что допустимыми будут и следующие операторы. // Manager - это Employee. Employee moonUnit = new Manager("MoonUnit Zappa", 2, 20000, "101-11-1321", 1); // PTSalesPerson - это Salesperson. Salesperson jill = new PTSalesPerson("Jill", 834, 100000, "111-12-1119", 90); Первым правилом преобразований для типов классов является то, что когда два класса связаны отношением подчиненности ("is-a"), всегда можно сохранить производный тип в ссылке базового класса. Формально его называют неявным (кон-текстуальным) приведением типов, поскольку оно "работает" только в рамках законов наследования. Такой подход позволяет строить очень мощные программные конструкции. Предположим, например, что у нас есть класс TheMachine (машина), который поддерживает следующий статический метод, соответствующий увольнению работника. public class TheMachine { public static void FireThisPerson(Employee e) { // Удалить из базы данных… // Забрать у работника ключи и точилку… } } Мы можем непосредственно передать этому методу любой производный класс класса Employee ввиду того, что эти классы связаны отношением подчиненности ("is-a"). // Сокращение штатов. TheMaсhine.FireThisPerson(moonUnit); // "moonUnit" - это Employee. TheMachine.FireThisFerson(jill); //"jill" - это SalesPerson. В дальнейшем программный код использует в производном типе неявное преобразование из базового класса (Employee). Но что делать, если вы хотите уволить служащего по имени Frank Zарра (информация о котором в настоящий момент хранится в ссылке System.Object общего вида)? Если передать объект frank непосредственно в TheMaсhine.FireThisPerson() так, как показано ниже: // Manager - это object, но… . object frank = new Manager("Frank Zappa", 9, 40000, "111-11-1111", 5); … TheMachine.FireThisPerson(frank); // Ошибка! то вы получите ошибку компиляции. Причина в том, что нельзя автоматически интерпретировать System.Object, как объект, являющийся производным непосредственно от Employee, поскольку Object не является Employee. Но вы можете заметить, что объектная ссылка указывает на объект, связанный с Employee. Поэтому компилятор будет "удовлетворен", если вы используете явное приведение типов. В C# явное приведение типов указывается с помощью скобок, размещаемых вокруг имени типа, к которому вы хотите прийти, с последующим указанием объекта, который вы пытаетесь использовать в качестве исходного. Например: // Приведение общего типа System.Object // к строго типизованному Manager. Manager mgr = (Manager)frank; Console.WriteLine("Опционы Фрэнка: {0}", mgr.NumbOpts); Если не объявлять специальную переменную для "целевого типа", то можно получить более компактный программный код.
Console.WriteLine("Опционы Фрэнка: {0}", ((Manager)frank).NumbOpts); Проблему, связанную с передачей ссылки System.Object методу FireThisPerson(), можно решить так, как показано ниже. // Явное приведение типа System.Object к Employee. TheMachine.FireThisPerson((Employee)frank); Замечание. Попытка приведения объекта к несовместимому типу порождает в среде выполнения соответствующее исключение. Возможности структурированной обработки исключений будут рассмотрены в главе 6. Распознавание типов Статический метод TheMachine.FireThisPerson() строился так, чтобы он мог принимать любой тип, производный от Employee, но возникает один вопрос: как метод "узнает", какой именно производный тип передается методу. Кроме того, если поступивший параметр имеет тип Employee, то как получить доступ к специфическим членам типов SalesPerson и Manager? Язык C# обеспечивает три способа определения того, что ссылка базового класса действительно указывает на производный тип: явное приведение типа (рассмотренное выше), ключевое слово is и ключевое слово as. Ключевое слово is возвращает логическое значение, указывающее на совместимость ссылки базового класса с данным производным типом. Рассмотрим следующий обновленный метод FireThisPerson(). public class TheMachine { public static void FireThisPerson(Employee e) { if (e is SalesPerson) { Console.WriteLine("Имя уволенного продавца: {0}", e.GetFullName()); Console.WriteLine("{0} оформил(a) {1} операций…", e.GetFullName(), ((SalesPerson)e).NumbSales); } if (e is Manager) { Console.WriteLine("Имя уволенного клерка: {0}", e.GetFullName()); Console.WriteLine("{0} имел(а) (1} опцион(ов)…", e.GetFullName(), ((Manager)e).NumbOpts); } } } Здесь ключевое слово is используется для того, чтобы динамически определить тип работника. Чтобы получить доступ к свойствам NumbSales или NumbOpts, вы должны использовать явное приведение типов. Альтернативой место бы быть ис-пользование ключевого слова as для получения ссылки на производный тип (если типы при этом окажутся несовместимыми, ссылка получит значение null). SalesPerson p = е as SalesРеrson; if (p!= null) Console.WriteLinе("Число продаж: {0}", p.NumbSales); Замечание. Из Главы 7 вы узнаете, что такой же подход (явное приведение типов, is и as) может использоваться при получении интерфейсных ссылок из реализующего типа. Приведение числовых типов В завершение нашего обзора операций приведения типов в C# заметим, что преобразование числовых типов подчиняется примерно таким же правилам. Чтобы поместить "больший" числовой тип в "меньший" (например, целое число int в byte), следует использовать явное приведение типов, которое информирует компилятор о том, что вы готовы принять возможную потерю данных. // Если "х" больше предельного значения для byte, вероятна потеря // данных, но из главы 9 вы узнаете о "контролируемых исключениях", // с помощью которых можно управлять результатом. int х = 6; byte b = (byte)x; Когда вы сохраняете "меньший" числовой тип в "большем" (например, byte в int), тип для вас будет преобразован неявно и автоматически, так как здесь нет потерь данных. // Приведение типа не требуется, // int достаточно "велик" для хранения byte. byte b = 30; int x = b; Парциальные типы C# В C# 2005 вводится новый модификатор типа partial, который позволяет определять C#-тип в нескольких файлах *.cs. Предыдущие версии языка C# требовали, чтобы весь программный код определения типа содержался в пределах одного файла *.cs. С учетом того, что C#-класс производственного уровня может содержать сотни строк программного кода, соответствующий файл может оказаться достаточно объемным. В таких случаях было бы хорошо иметь возможность разделить реализацию типа на несколько файлов, чтобы отделить программный код, который в некотором смысле более важен, от других элементов. Например, используя для класса модификатор partial, можно поместить все открытые члены в файл с именем MyТуре_Public.cs, а приватные поля данных и вспомогательные функции – в файл MyType_Private.cs. // MyClass_Public.cs namespace PartialTypes { public partial class MyClass { // Конструкторы. public MyClass() {} // Открытые члены. public void MemberA() {} public void MemberB() {} } } // MyClass_Private.cs namespace PartialTypes { public partial class MyClass { // Приватные поля данных. private string someStringData; // Приватные вспомогательные члены. public static void SomeStaticHelper(){} } } Это, в частности, упростит задачу изучения открытого интерфейса типа для новых членов команды разработчиков. Вместо изучения единого (и большого) файла C# с целью поиска соответствующих членов, разработчики получают возможность рассмотреть только открытые члены. Конечно, после компиляции этих файлов с помощью csc.exe в результате все равно получается единый унифицированный тип (рис. 4.14). 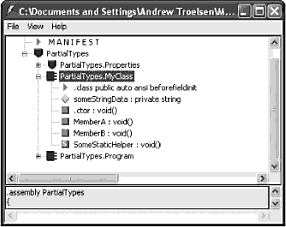 Рис. 4.14. После компиляции парциальные типы уже не будут парциальными Исходный код. Проект PartialTypes размещен в подкаталоге, соответствующем главе 4. Замечание. После рассмотрения Windows Forms и ASP.NET вы поймете, что в Visual Studio 2005 ключевое слово partial используется для разделения программного кода, генерируемого инструментами разработки. Используя этот подход, вы можете сосредоточиться на поиске подходящих решений и не заботиться об автоматически генерируемом программном коде. Документирование исходного кода в C# с помощью XML В завершение этой главы мы рассмотрим специфические для C# лексемы комментариев, которые порождают документацию программного кода на. базе XML. Если вы имеете опыт программирования на языке Java, то, скорее всего, знаете об утилите javadoc. Используя javadoc, можно превратить исходный вод Java в соответствующее HTML-представление. Модель документирования, принятая в C#, оказывается немного иной в том отношении, что процесс преобразования комментариев в XML является заботой компилятора (при использовании опции /doc), а не особой утилиты. Но почему для документирования определений типов используется XML, а не HTML? Главная причина в том, что XML обеспечивает очень широкие возможности. Поскольку XML отделяет определение данных от представления этих данных, к лежащему в основе XML-коду можно применить любое XML-преобразование, позволяющее отобразить документацию программного кода в одном из множества доступных форматов (MSDN, HTML и т.д.). При документировании C#-типов в формате XML первой задачей является выбор одного из двух вариантой нотации: тройной косой черты (///) или признака комментария, который начинается комбинацией косой черты и двух звездочек (/**), а заканчивается – комбинацией звездочки и косой черты (*/). В поле документирующего комментария можно использовать любые XML-элементы, включая элементы рекомендуемого набора, описанные в табл. 4.1. Таблица 4.1. Элементы XML рекомендуемые для использования в комментариях к программному коду
В качестве конкретного примера рассмотрим следующее определение типа Car (автомобиль), в котором следует обратить особое внимание на использование элементов ‹summary› и ‹param›. /// ‹summary› /// Это тип Car, иллюстрирующий /// возможности XML-документирования. /// ‹/summary› public class Car { /// ‹summary› /// Есть ли люк в крыше вашего автомобиля? /// ‹/summary› private bool hasSunroof = false; /// ‹summary› /// Этот конструктор позволяет установить наличие люка. /// ‹/summary› /// ‹param name="hasSunroof "› ‹/param› public Car(bool hasSunroof) { this.hasSunroof = hasSunroof; } /// ‹summary› /// Этот метод позволяет открыть люк. /// ‹/summary› /// ‹param name="state"› ‹/param› public void OpenSunroof (bool state) { if (state == true && hasSunroof == true) Console.WriteLine("Открываем люк!"); else Console.WriteLine("Извините, у вас нет люка."); } } Метод Main() программы также документируется с использованием XML-элементов. /// ‹summary› /// Точка входа приложения. /// ‹/summary› static void Main(string [] args) { Car с = new Car(true); с.OpenSunroof(true); } Чтобы на основе комментариев, задающих XML-код, сгенерировать соответствующий файл *.xml, при построении C#-программы с помощью csc.exe используется флаг /doc. csc /doc:XmlCarDoc.xml *.cs В Visual Studio 2005 можно указать имя файла с XML-документацией, используя вкладку Build окна свойств (рис. 4.15).  Pис. 4.15. Генерирование файла XML-документации в Visual Studio 2005 Символы форматирования в XML-коде комментариев Если открыть сгенерированный XML-файл, вы увидите, что элементы будут помечены такими символами, как "M", "T", "F" и т.п. Например: ‹member name = "Т:ХmlDоcCar.Car"› ‹summary› Это тип Car, иллюстрирующий возможности XML-документирования. ‹/summary› ‹/member› В табл. 4.2 описаны значения этих меток. Таблица 4.2. Символы форматирования XML
Трансформация XML-кода комментариев Предыдущие версии Visual Studio 2005 (в частности. Visual Studio .NET 2003) предлагали очень полезный инструмент, позволяющий преобразовать файлы с XML-кодом документации в систему HTML-справки. К сожалению, Visual Studio 2005 не предлагает такой утилиты, оставляя пользователя "один на один" с XML-документом. Если вы имеете опыт использования XML-трансформаций, то, конечно, способны вручную создать подходящие таблицы стилей. Более простым вариантом является использование инструментов сторонних производителей, которые позволяют переводить XML-код в самые разные форматы. Например, приложение NDoc, уже упоминавшееся в главе 2, позволяет генерировать документацию в нескольких различных форматах. Напомним, что информацию о приложении NDoc можно найти на страницах http://ndoc.sourceforge.net. Исходный код. Проект XmlDocCar размещен в подкаталоге, соответствующем главе 4. Резюме Если вы изучаете .NET, имея опыт работы с любым другим объектно-ориентированным языком программирования, то материал этой главы обеспечит сравнение возможностей используемого вами языка с возможностями языка C#. При отсутствии такого опыта многие представленные в этой главе понятия могут казаться непривычными. Но это не страшно, поскольку по мере освоения оставшегося материала книги вы будете иметь возможность закрепить представленные здесь понятия. Эта глава началась с обсуждения принципов ООП: инкапсуляции, наследования и полиморфизма. Сервис инкапсуляции можно обеспечить с помощью традиционных методов чтения/модификации, свойств типа или открытых полей, доступных только для чтения. Наследование в C# реализуется еще проще, поскольку этот язык не имеет для наследования специального ключевого слова, а предлагает использовать операцию, обозначаемую двоеточием. Наконец, для поддержки полиморфизма в C# предлагается использовать ключевые слова abstract, virtual, override и new. ГЛАВА 5. Цикл существования объектов В предыдущей главе мы потратили достаточно много времени на то, чтобы научиться строить пользовательские типы класса в C#. В этой главе мы выясним, как среда CLR управляет уже размешенными объектами с помощью процесса, который называется сборкой мусора. Программистам использующим C# не приходится удалять объекты из памяти "вручную" (напомним, что в C# вообще нет ключевого слова delete). Объекты .NET размещаются в области памяти, которая называется управляемой динамической памятью, где эти объекты "в некоторый подходящий момент" будут автоматически уничтожены сборщиком мусора. Выяснив основные детали процесса сборки мусора, вы узнаете, как взаимодействовать со сборщиком мусора, используя для этого тип класса System.GC, Наконец, мы рассмотрим виртуальный метод System.Object.Finalize() и интерфейс IDisposable, которые можно использовать для того, чтобы создавать типы самостоятельно освобождающие в нужный момент свои внутренние неуправляемые ресурсы. Изучив материал этой главы, вы сможете понять, как среда CLR управляет объектами .NET. Классы, объекты и ссылки Чтобы очертить контуры темы, рассматриваемой в данной главе, необходимо уточнить различия между класcами, объектами и ссылками. В предыдущей главе уже говорилось о том, что класс – это своеобразный "шаблон" с описанием того, как экземпляр данного типа должен выглядеть и вести себя в памяти. Классы определяются в файлах, которые по соглашению в C# имеют расширение *.cs. Рассмотрим простой класс Car (автомобиль), определённый в файле Car.cs. public class Car { private int currSp; private string petName; public Car(){} public Car(string name, int speed) { petName = name; currSp = speed; } public override string ToString() { return String.Format("{0} имеет скорость {1} км/ч", petName, currSp); } } Определив класс, вы можете разместить в памяти любое число соответствующих объектов, используя ключевое слово C# new. При этом, однако, следует понимать, что ключевое слово new возвращает ссылку на объект в динамической памяти, а не сам реальный объект. Эта переменная со ссылкой запоминается в стеке для использования в приложении в дальнейшем. Для вызова членов объекта следует применить к сохраненной ссылке операцию C#, обозначаемую точкой. class Program { static void Main(string[] args) { // Создается новый объект Car в динамической памяти. // Возвращается ссылка на этот объект ('refТоМуСаr'). Car refToMyCar = new Car("Zippy", 50); // Операция C#, обозначаемая точкой (.), используется // со ссылочной переменной для вызова членов этого объекта. Console.WriteLine(refToMyCar.ToString()); Console.ReadLine(); } } На рис. 5.1 изображена схема, иллюстрирующая взаимосвязь между классами, объектами и их ссылками. 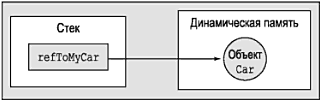 Рис. 5.1. Ссылки на объекты в управляемой динамической памяти Основные сведения о существовании объектов При построении C#-приложений вы вправе предполагать, что управляемая динамическая память будет обрабатываться без вашего прямого вмешательства. "Золотое правило" управления памятью .NET является очень простым. • Правило. Следует поместить объект в управляемую динамическую память с помощью ключевого слова new и забыть об этом. Сборщик мусора уничтожит созданный объект, когда этот объект будет больше не нужен. Cледующий очевидный вопрос: "Как сборщик мусора определяет, что объект больше не нужен?" Краткий (т.е. упрощенный) ответ заключается в том, что сборщик мусора удаляет объект из динамической памяти тогда, когда объект становится недоступным для всех частей программного кода. Предположим, что вы имеете метод, размещающий локальный объект Car. public static void MakeACar() { // Если myCar является единственной ссылкой на объект Car, // то объект может быть уничтожен после возвращения из метода. Car myCar = new Car(); … } Обратите внимание на то, что ссылка на объект (myCar) была создана непосредственно в методе MakeACar() и не передавалась за пределы области видимости определяющего эту ссылку объекта (ни в виде возвращаемого значения, ни в виде параметров ref/out). Поэтому после завершения работы вызванного метода ссылка myCar становится недоступной, и соответствующий объект Car оказывается кандидатом для удаления в "мусор". Однако следует понимать, что вы не можете гарантировать немедленное удаление этого объекта из памяти сразу же по завершении работы MakeACar(). В этот момент можно гарантировать только то, что при следующей сборке мусора в общеязыковой среде выполнения (CLR) объект myCar может быть без опасений уничтожен. Вы, несомненно, обнаружите, что программирование в окружении, обеспечивающем автоматическую сборку мусора, значительно упрощает задачу разработки приложений. Программисты, использующие C++, знают о том, что если в C++ забыть вручную удалить размещенные в динамической памяти объекты, может произойти "утечка памяти". На самом деле ликвидация утечек памяти является одним из самых трудоемких (и неинтересных) аспектов программирования на языках, которые не являются управляемыми. Поручив сборщику мусора уничтожение объектов, вы снимаете с себя груз ответственности за управление памятью и перекладываете его на CLR. Замечание. Если вы имеете опыт разработки программ в использованием COM, то знайте, что объекты .NET не поддерживают счетчик внутренних ссылок, поэтому управляемые объекты не предлагают такие методы, как AddRef() и Release(). CIL-код для new Когда компилятор C# обнаруживает ключевое слово new, он генерирует CIL-инструкцию newobj в рамках реализации соответствующего метода. Если выполнить компиляцию программного кода текущего примера и с помощью ildasm.exe рассмотреть полученный компоновочный блок, то в рамках метода MakeACar() вы увидите следующие CIL-операторы. .method public hidebysig static void MakeACar() cil managed { // Code size 7 (0x7) .maxstack 1 .locals init ([0] class SimpleFinalize.Car c) IL_0000: newobj instance void SimpleFinalize.Car::.ctor() IL_0005: stloc.0 IL_0006: ret} } // end of method Program::MakeACar Перед тем как обсудить точные правила, определяющие момент удаления объекта из управляемой динамической памяти, давайте выясним роль CIL-инструкции newobj. Сначала заметим, что управляемая динамическая память является не просто случайным фрагментом памяти, доступной для среды выполнения. Сборщик мусора .NET является исключительно аккуратным "дворником" в динамической памяти – он (при необходимости) даже сжимает пустые блоки памяти с целью оптимизации. Чтобы упростить задачу сборки мусора, управляемая динамическая память имеет указатель (обычно называемый указателем на следующий объект, или указателем на новый объект),который идентифицирует точное место размещения следующего объекта. Инструкция newobj информирует среду CLR о том, что необходимо выполнить следующие главные задачи. • Вычислить общий объем памяти, необходимой для размещения объекта (включая память, необходимую для членов-переменных и базовых классов типа). • Проверить управляемую динамическую память, чтобы гарантировать достаточный объем памяти для размещаемого объекта. Если памяти достаточно, вызывается конструктор типа, и вызывающей стороне, в конечном счете, возвращается ссылка на новый объект в памяти, причем адрес этого объекта будет соответствовать последней позиции указателя на следующий объект. • Наконец, перед возвращением ссылки вызывающей стороне необходимо изменить значение указателя на следующий объект, чтобы указатель соответствовал началу свободной области управляемой динамической памяти. Этот процесс схематически показан на риc. 5.2. 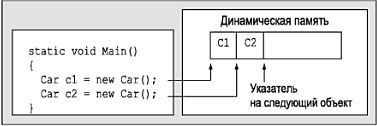 Рис. 5.2. Размещение объектов в управляемой динамической памяти При размещении объектов в приложении пространство управляемой динамической памяти может, в конечном счете, заполниться. Если при обработке инструкции newobj среда CLR обнаружит, что управляемой динамической памяти недостаточно для размещения очередного типа, с целью освобождения памяти будет выполнена сборка мусора. Поэтому следующее правило сборки мусора также оказывается очень простым. • Правило. Если управляемая динамическая память недостаточна дли размещения очередного объекта, выполняется сборка мусора. В процессе сборки мусора сборщик мусора временно приостанавливает все активные потоки в рамках текущего процесса, чтобы гарантировать, что приложение не получит доступа к динамической памяти в процессе сборки мусора. Тему потоков мы рассмотрим в главе 14, а пока что воспринимайте поток, как "нить" выполнения в пределах выполняющейся программы. После завершения цикла сборки мусора приостановленным потокам будет разрешено продолжить работу. К счастью, сборщик мусора .NET хорошо оптимизирован, и вы вряд ли заметите соответствующие короткие перерывы в работе вашего приложения. Роль корней приложения Теперь мы вернемся к вопросу о том, как сборщик мусора определяет, когда объект "больше не нужен". Чтобы понять это, необходимо рассмотреть понятие корней приложения. Упрощенно говоря, корень- это место в памяти со ссылкой на объект, размещенный в динамической памяти. Строго говоря, корень может относиться к любой из следующих категорий. • Ссылки на глобальные объекты (хотя они и не позволены в C#, программный код CIL допускает размещение глобальных объектов). • Ссылки на используемый в настоящий момент статические объекты и поля. • Ссылки на локальные объекты в пределах данного метода. • Ссылки на объектные параметры, предаваемые методу. • Ссылки на объекты, ожидающие финализации (соответствующее понятие будет описано в этой главе позже). • Любые регистры процессора, ссылающиеся на локальный объект. В процессе сборки мусора среда выполнения проверяет объекты в управляемой динамической памяти и определяет, остаются ли они доступными для приложения (иначе говоря, укорененными). Для этого среда CLR строит объектный граф, изображающий каждый объект в динамической памяти, достижимый для приложения. Объектные графы будут рассматриваться подробнее при обсуждении сериализации объектов (см. главу 17). На данный момент вам достаточно знать, что объектные графы используются для учета всех достижимых объектов. Следует знать и о том, что сборщик мусора никогда не учитывает один и тот же объект дважды, вследствие чего, в отличие от классического подхода COM. здесь не возникает опасности циклического учета ссылок,. Предположим, что управляемая динамическая память содержит множество объектов, имена которых A, B, C, D, E, F и G. В процессе сборки мусора эти объекты (а также все внутренние объектные ссылки, которые эти объекты могут содержать) проверяются на наличие у них активных корней, После построения графа недостижимые объекты (мы будем предполагать, что это объекты C и F) обозначаются, как мусор. На рис. 5.3 представлен возможный объектный граф для только что описанного сценария (направленные стрелки, связывающие объекты в таком графе, можно заменить словами "зависит от" или "требует", – например, "E зависит от G и косвенно от B", "A не зависит ни от чего" и т.д.).  Рис. 5.3. Объектные графы строятся для выявления объектов, достижимых из корней приложения Если объекты помечены для уничтожения (в данном случае это C и F – они не включены в объектный граф), эти объекты удаляются из памяти. В этот момент оставшееся пространство в динамической памяти уплотняется, что в свою очередь заставляет среду CLR модифицировать множество корней активного приложения, чтобы они обеспечивали правильные ссылки на точки размещения в памяти (это делается автоматически и незаметно). Наконец, соответствующим образом изменяется указатель на следующий объект. На рис. 5.4 показан результат преобразований. 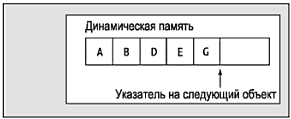 Рис. 5.4. "Чистая и компактная" динамическая память Замечание. Строго говоря, сборщик мусора использует два разных фрагмента динамической памяти, один из которых предназначен специально для хранения очень больших объектов. К этой динамической памяти при сборке мусора система обращается реже, поскольку при размещении больших объектов возможные потери производительности выше. Тем не менее, вполне допустимо считать "управляемую динамическую память" единым регионом в памяти. Генерации объектов Когда среда CLR пытается найти недоступные объекты, это не значит, что будет рассмотрен буквально каждый объект, размещенный в управляемой динамической памяти. Очевидно, что это требовало бы слишком много времени, особенно в реальных (т.е. больших) приложениях. Чтобы оптимизировать процесс, каждый объект в динамической памяти приписывается определенной "генерации". Идея достаточно проста: чем дольше объект существует в динамической памяти, тем более вероятно то, что он должен там и оставаться. Например, объект, реализующий Main() будет находиться в памяти до тех пор, пока программа не закончится. С другой стороны, объекты, которые недавно размещены в динамической памяти, вероятнее всего, станут вскоре недостижимыми (например, объекты, созданные в рамках области видимости метода). При этих предположениях каждый объект в динамической памяти можно отнести к одной из следующих категорий. • Генерация 0. Новые, только что размещенные объекты, которые еще никогда же предназначались для использования в процессе сборки мусора. • Генерация 1. Объекты, которые "пережили" одну сборку мусора (т.е. были обозначены для использования в процессе сборки мусора, но не были удалены по той причине, что в динамической памяти оказалось достаточно места). • Генерация 2. Объекты, ''пережившие" несколько сборок мусора. Сборщик мусора сначала рассматривает объекты генерации 0. Если в результате выявления ненужных объектов и соответствующей чистки свободной памяти оказывается достаточно, все оставшиеся объекты относятся к генерации 1. Чтобы понять, как генерации объектов влияют на процесс сборки мусора, рассмотрите рис. 5.5. где схематически показано, как некоторое множество "выживших" объектов (A, B и E) генерации 0 переводятся в следующую генерацию после обновления остальной части памяти. 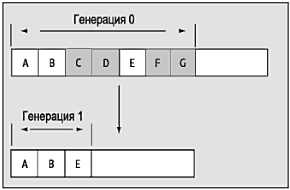 Рис 5.5. Объекты генерации 0, которые "пережили" сборку мусора, переходят к генерации 1 Если все объекты генерации 0 уже рассмотрены, но памяти все равно еще не достаточно, то рассматривается "достижимость" объектов генерации 1 и выполняется сборка мусора среди этих объектов. "Выжившие" объекты генерации 1 переходят к генерации 2. Если сборщик мусора все еще требует дополнительной памяти, тогда оцениваются объекты генерации 2. Здесь, если объект генерации 2 "выживает" в процессе сборки мусора, то такой объект сохраняет принадлежность к генерации 2, поскольку это предел для генераций объектов. Итак, с помощью назначения признака генерации объектам в динамической памяти более новые объекты (например, локальные переменные) будут удаляться быстрее, тогда как старые объекты (такие как, например, объект приложения программы) будут "беспокоиться" значительно реже. Тип System.GC Библиотеки базовых классов предлагают тип класса System.GC, который позволяет программно взаимодействовать со сборщиком мусора, используя множество статических членов указанного класса. Следует заметить, что непосредственно использовать этот тип в программном коде приходится очень редко (если приходится вообще). Чаще всего члены типа System.GC используется тогда, когда создаются типы, использующие неуправляемые ресурсы. В табл. 5.1 предлагаются описания некоторых членов этого класса (подробности можно найти в документации .NET Framework 2.0 SDK). Таблица 5.1. "Избранные" члены типа System.GC
Рассмотрите следующий метод Main(), в котором иллюстрируется использование указанных членов System.GC. static void Main(string[] args) { // Вывод оценки (в байтах) для динамической памяти. Console.WriteLine("Оценка объема памяти (в байтах): {0}", GC.GetTotalMemory(false)); // Отсчет для MaxGeneration начинается с нуля, // поэтому для удобства добавляем 1. Console.WriteLine("Число генераций для данной OC: {0}\n", (GC.МахGeneration + 1)); Car refToMyCar = new Car("Zippy", 100); Console.WriteLine(refToMyCar.ToString()); // Вывод информации о генерации для объекта refToMyCar. Console.WriteLine("Генерация refToMyCar: {0}", GC.SetGeneration(refToMyCar)); Console.ReadLine(); } Активизация сборки мусора Итак, сборщик мусора в .NET призван управлять памятью за вас. Однако в очень редких случаях, перечисленных ниже, бывает выгодно программно активизировать начало сборки мусора, используя дня этого GC.Collect(). • Перед входом приложения в блок программного кода, для которого нежелательно, чтобы его выполнение прерывалось возможной сборкой мусора. • После окончания размещения очень большого числа объектов, когда вы желаете освободить как можно больше памяти. Если вы сочтете, что будет выгодно выполнить сборку мусора, вы можете явно начать процесс сборки мусора так, как показано ниже. static void Main(string[] args) { … // Активизация сборки мусора и // ожидание завершения финализации объектов. GC.Collect(); GC.WaitForPendingFinalizers(); … } При непосредственной активизации сборки мусора вы должны вызвать GC.WaitForPendingFinalizers(). В рамках этого подхода вы можете быть уверены, что все лредуcматривающие финализацию объекты обязательно получат возможность выполнить все необходимые завершающие действия, прежде чем ваша программа продолжит свою работу. "За кулисами" GC.WaitForPendingFinalizers() приостановит выполнение вызывающего "потока" на время процесса сборки мусора. Это гарантирует, что ваш программный код не сможет вызвать метод объекта, уничтожаемого в данный момент. Методу GC.Collect() можно передать числовое значение, указывающее старейшую генерацию, для которой должна быть выполнена сборка мусора. Например, если вы желаете сообщить CLR, что следует рассмотреть только объекты генерации 0, вы должны напечатать следующее. static void Main(string[] args) { … // Рассмотреть только объекты генерации 0. GC.Collect(0); GC.WaitForPendingFinalizers(); … } Подобно любой сборке мусора, вызов GC.Collect() повысит статус выживших генераций. Предположим, например, что наш метод Main() обновлен так, как показано ниже. static void Main(string[] args) { Console.WriteLine ("***** Забавы с System.GC *****\n"); // Вывод информации об объеме динамической памяти. Console.WriteLine("Оценка объёма памяти (в байтах): {0}", GC.GetTotalMemory(false)); // Отсчет для MaxGeneration начинается с нуля. Console.WriteLine("Число генераций для данной ОС: {0}\n", (GC.MaxGeneration + 1)); Car refToMyCar = new Car("Zippy", 100); Console.WriteLine(refToMyCar.ToString()); // Вывод информации о генерации для объекта refToMyCar. Console.WriteLine("\nГенерация refToMyCar: {0}", GC.GetGeneration(refToMyCar)); // Создание тысяч объектов с целью тестирования. object[] tonsOfObjects = new object[50000]; for (int i = 0; i ‹ 50000; i++) tonsOfObjects [i] = new object(); // Сборка мусора только для объектов генерации 0. GC.Collect(0); GC.WaitForPendingFinalizers(); // Вывод информации о генерации для объекта refToMyCar. Console.WriteLine("Генерация refToMyCar: {0}", GC.GetGeneration(refToMyCar)); // Проверим, "жив" ли объект tonsOfObjects[9000]. if (tonsOfObjects[9000] != null) { Console.WriteLine("Генерация tonsOfObjects[9000]: {0}", GC.GetGeneration(tonsOfObjects[9000])); } else Console.WriteLine("Объекта tonsOfObjects[9000] ужe нет"); // Вывод числа процедур сборки мусора для генераций. Console.WriteLine("\nДля ген. 0 сборка выполнялась {0}: раз(a)", GC.CollectionCount(0)); Console.WriteLine("Для ген. 1 сборка выполнялась {0} раз(а)", GC.CollectionCount(1)); Console.WriteLine("Для ген. 2 сборка выполнялась {0} раз(a)", GC.CollectionCount(2)); Console.ReadLine(); } Здесь, мы намерений создали очень большой массив объектов с целью тестирования. Как следует из вывода, показанного на рис. 5.6, хотя метод Main() делает всего один явный запрос на сборку мусора, среда CLR выполняет целый ряд операций сборки мусора в фоновом режиме. 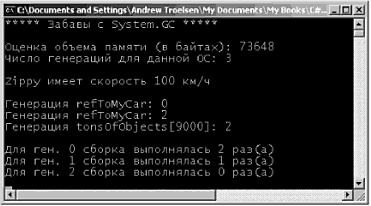 Рис. 5.6. Взаимодействие со сборщиком мусора CLR через System.GC К этому моменту, я надеюсь, вы уяснили себе некоторые детали, касающиеся цикла существования объектов. Остаток этой главы мы посвятим дальнейшему изучению процесса сборки мусора, выяснив, как можно строить объекты, предусматривающие финализацию, и объекты, предусматривающие освобождение ресурсов. Следует заметить, что обсуждающийся ниже подход может быть полезен только при построении управляемых классов с поддержкой внутренних неуправляемых ресурсов. Исходный код. Проект SimpleGC размещён в подкаталоге, соответствующем главе 5. Создание объектов, предусматривающих финализацию В главе 3 говорилось о том, что главный базовый класс .NET, System.Object, определяет виртуальный метод с именем Finalize() (метод деструктора). Реализация этого метода, заданная по умолчанию, не делает ничего. // System.Object public class Object { … protected virtual void Finalize(){} } Переопределяя Finalize() в своем пользовательском классе, вы создаете программную логику "уборки", необходимую для вашего типа. Поскольку этот член определяется, как protected, непосредственно вызвать метод Finalized объекта будет невозможно, Метод Finalize () объекта вызывается сборщиком мусора перед удалением объекта из памяти (если, конечно, этот метод объектом поддерживается). Ясно, что обращение к Finalize() происходит и в процессе "естественной" сборки мусора, и в случае программной активизации сборки мусора с помощью GC.Collect(). Кроме того, метод деструктора типа будет автоматически вызван тогда, когда выгружается из памяти домен приложения, содержащий выполняемое приложение. Вы, возможно, знаете, что домены приложений используются для размещения выполняемого компоновочного блока и необходимых для него внешних библиотек программного кода. Если вы еще не знакомы с этим понятием .NET, то всю необходимую информацию вам предоставит глава 13. Здесь главное то, что при выгрузке из памяти домена приложения среда CLR автоматически вызывает деструкторы для каждого из предусматривающих финализацию объектов, созданных в процессе выполнения программы. Теперь, независимо от того, что может говорить вам интуиция разработчика, следует подчеркнуть, что большинству классов в C# не требуется никакой явной "уборки". Причина проста: если ваши типы используют другие управляемые объекты, то все, в конечном счете, будет обработано сборщиком мусора. Создавать класс, который должен заниматься "уборкой", вам придется только тогда, когда этот класс будет использовать неуправляемые ресурсы (например, прямой доступ к дескрипторам файлов ОС, неуправляемым базам данных или другим неуправляемым ресурсам). Вы, наверное, знаете, что неуправляемые ресурсы создаются в результате прямого вызова API операционной системы с помощью PInvoke (Platform Invocation – обращение к платформе) или с помощью некоторых довольно сложных сценариев взаимодействия COM. С учетом этого возникает следующее правило сборки мусора. • Правило. Необходимость переопределения Finalize() может возникать только тогда, когда класс C# использует неуправляемые ресурсы посредством PInvoke или при решении сложных задач взаимодействия с COM-объектами (обычно с применением типа System.Runtime.InteropServices.Marshal). Замечание. В главе 3 уже отмечалось, что не допускается переопредешть Finalize() с типами структуры. Теперь это совершенно ясно, поскольку структуры являются типами, характеризуемыми значениями, и они не размещаются в динамической памяти. Переопределение System.Object.Finalize() В тех редких случаях, когда воздается C#-класс, использующий неуправляемые ресурсы, нужно гарантировать, что соответствующая память будет обрабатываться прогнозируемым образом. Предположим, что вы создали класс MyResourceWrapper, использующий неуправляемый ресурс (каким бы этот ресурс ни был), и вы хотите переопределить Finalize(). Немного странно, но в C# вы не можете для этого использовать ключевое слово override. public class MyResourceWrapper { // Ошибка компиляции! protected override void Finalize(){} } Чтобы в пользовательском типе класса переопределить метод Finalize(), вы должны использовать в C# другой синтаксис деструктора, напоминающий синтаксис деструктора в C++. Причина в том, что при обработке деструктора компилятором C# в метод Finalize() автоматически добавляются необходимые элементы инфраструктуры (что будет продемонстрировано чуть позже). Вот пример пользовательского деструктора для MyResourceWrapper, который при вызове генерирует системный сигнал. Ясно, что это сделано исключительно для примера. Настоящий деструктор должен только освобождать неуправляемые ресурсы, а не взаимодействовать с членами других управляемых o6ъeктов, поскольку вы не можете гарантировать, что эти объекты будут существовать в тот момент, когда сборщик мусора вызовет ваш метод Finalize().
// синтаксиса деструктора. class MyResourceWrapper { ~MyResourceWrapper() { // Освобождение неуправляемых ресурсов. // Завершающий сигнал (только для примера!) Console.Веер(); } } Если рассмотреть этот деструктор с помощью ildasm.exe, вы увидите, что компилятор добавляет программный код контроля ошибок. Программный код вашего метода Finаlize() помещается в рамки блока try. Это делается для выявления операторов, которые во время выполнения могут сгенерировать ошибку (что формально называется исключительной ситуацией или исключением). Соответствующий блок finally гарантирует, что метод Finalize() класса будет выполнен независимо от исключений, которые могут возникать в рамках try. Формальности структурированной обработки исключений будут рассмотрены в следующей главе, а пока что проанализируйте следующее CIL-представление деструктора для C#-класса MyResourceWrapper. .method family hidebysig virtual instance void Finalize() cil managed { // Code size 13 (0xd) .maxstack 1 .try { IL_0000: ldc.i4 0x4e20 IL_0005: ldc.i4 0x3e8 IL 000a: call void [mscorlib]System.Console::Beep(int32, int32) IL_000f: nop IL_0010: nop IL_0011: leave.s IL_001b } // end.try finally { IL_0013: ldarg.0 IL_0014: call instance void [mscorlib]System.Object::Finalize() IL_0019: nop IL_001a: endfinally } // end handler IL_001b: nop IL_001c: ret } // end of method MyResourceWrapper::Finalize При тестировании типа MyResourceWrapper вы обнаружите, что завершение работы приложения сопровождается системным звуковым сигналом, поскольку среда CLR автоматически вызывает деструкторы объектов при освобождении доменов приложений. static void Main(string[] args) { Console.WriteLine("***** Забавы с деструкторами *****\n"); Console.WriteLine("Нажмите клавишу ввода для завершения работы"); Console.WriteLine("и вызова Finalize() сборщиком мусора"); Console.WriteLine("для объектов, предусматривающих финализацию."); Console.ReadLine(); MyResourceWrapper rw = new MyResourceWrapper(); } Исходный код. Проект SimpleFinalize размещен в подкаталоге, соответствующем главе 5. Детали процесса финализации Чтобы не делать лишней работы, следует помнить о том, что целью метода Finalize() является гарантия освобождения неуправляемых ресурсов .NET-объекта при сборке мусора. Поэтому при cоздании типа, не использующего неуправляемые элементы (а такая ситуация оказывается вполне типичней), от финализации будет мало пользы. На самом деле, при разработке своих типов вы должны избегать использования метода Finalize() по той очень простой причине, что финализация требует времени. При размещений объекта в управляемой динамической памяти среда выполнения автоматически определяет, поддерживает ли этот объект пользовательский метод Finalize(). Если указанный метод поддерживается, то объект обозначается, как требующий финализации, а указатель на этот объект сохраняется во внутренней очереди, которую называют очередью финализации. Очередь финализации представляет собой таблицу, поддерживаемую сборщиком мусора и содержащую все объекты, для которых перед удалением из динамической памяти требуется финализация. Когда с точки зрения сборщика мусора приходит время удалить объект из памяти, проверяются элементы очереди финализации, и соответствующий объект копируется из динамической памяти в другую управляемую структуру, которую вызывают таблицей элементов, доступных для финализации. В этот момент создается отдельный поток, задачей которого является вызов метода Finalize() при следующей сборке мусора для каждого объекта из таблицы элементов, доступных для финализации. С учетом этого становится. ясно, что для окончательного уничтожения объекта потребуется как минимум две процедуры сборки мусора. Таким образом, хотя финализация объекта и гарантирует, что объект сможет освободить неуправляемые ресурсы, по своей природе эта процедура оказывается недетерминированной и, в связи с происходящими "за кулисами" дополнительными процессами, достаточно медленной. Создание объектов, предусматривающих освобождение ресурсов Поскольку многие неуправляемые ресурсы являются столь "драгоценными", что их нужно освободить как можно быстрее, предлагается рассмотреть еще один подход, используемый для "уборки" ресурсов объекта. В качестве альтернативы переопределению Finalize() класс может реализовать интерфейс IDisposable, который определяет единственный метод, имеющий имя Dispose(). public interface IDisposable { void Dispose(); } Если вы не имеете опыта программирования интерфейсов, то в главе 7 вы найдете все необходимые подробности. В сущности, интерфейс представляет собой набор абстрактных членов, которые могут поддерживаться классом или структурой. Если вы реализуете поддержку интерфейса IDisposable, то предполагается, что после завершения работы с объектом пользователь объекта должен вручную вызвать Dispose() до того, как объектная ссылка "уйдет" из области видимости. При таком подходе ваши объекты смогут выполнить всю необходимую "уборку" неуправляемых ресурсов без размещения в очереди финализации и без ожидания сборщика мусора, запускающего программную логику финализации класса. Замечание. Интерфейс IDisposable может поддерживаться и типами структуры, и типами класса (в отличие от переопределения Finalize(), которое годится только для типов класса). Ниже показан обновленный класс MyResourceWrapper, который теперь реализует IDisposable вместо переопределения System.Object.Finalize (). // Реализация IDisposable. public class MyResourceWrapper: IDisposable { // Пользователь объекта должен вызвать этот метод // перед завершением работы с объектом. public void Dispose() { // Освобождение неуправляемых ресурсов. // Освобождение других содержащихся объектов. } } Обратите внимание на то, что метод Dispose() отвечает не только за освобождение неуправляемых ресурсов типа, но и за вызов Dispose() для всех других содержащихся в его распоряжении объектов, предполагающих освобождение ресурсов. В отличие от Finalize(), обращаться из метода Dispose() к другим управляемым объектам вполне безопасно. Причина в том. что сборщик мусора не имеет никакого представления об интерфейсе IDisposable и никогда не вызывает Dispose(). Поэтому, когда пользователь объекта вызывает указанный метод, объект все еще существует в управляемой динамической памяти и имеет доступ ко всем другим объектам, размещенным в динамической памяти. Логика вызова проста. public class Program { static void Main() { MyResourceWrapper rw = new MyResourceWrapper(); rw.Dispose(); Console.ReadLine(); } } Конечно, перед попыткой вызвать Dispose() для объекта вы должны проверить, что соответствующий тип поддерживает интерфейс IDisposable. Обычно информацию об этом вы будете получать из документации .NET Framework 2.0 SDK, но это можно выяснить и программными средствами, используя ключевые слова is или as, применение которых обсуждалось в главе 4. public class Program { static void Main() { MyResourceWrapper rw = new MyResourceWrapper(); if (rw is IDisposable) rw.Dispose(); Console.ReadLine(); } } Этот пример заставляет вспомнить еще одно правило работы с типами, предполагающими сборку мусора. • Правило. Обязательно вызывайте Dispose() для любого возданного вами объекта, поддерживающего IDisposable. Если разработчик класса решил реализовать поддержку метода Dispose(), то типу, скорее всего, есть что "убирать". Снова о ключевом слове using в C# При обработке управляемых объектов, реализующих интерфейс IDisposable, вполне типичным будет использование методов структурированной обработки исключений (см. главу 6), чтобы гарантировать вызов метода Dispose() даже при возникновении исключительных ситуаций в среде выполнения. static void Main(string[] args) { MyResourceWrapper rw = new MyResourceWrapper(); try { // Использование членов rw. } finally { // Dispose () вызывается всегда, есть ошибки или нет. rw.Dispose(); } } Этот пример применения технологии "Безопасного программирования" прекрасен, но реальность такова, что лишь немногие разработчики готовы мириться с перспективой помещения каждого типа, предполагающего освобождение ресурсов, в рамки блока try/catch/finally только для того, чтобы гарантировать вызов метода Dispose(). Поэтому для достижения того же результата в C# предусмотрен намного более удобный синтаксис, реализуемый с помощью ключевого слова using. static void Main(string[] args) { // Dispose() вызывается автоматически при выходе за пределы // области видимости using. using(MyResourceWrapper rw = new MyResourceWrapper()) { // Использование объекта rw. } } Если с помощью ildasm.exe взглянуть на CIL-код метода Main(), то вы обнаружите, что синтаксис using на самом деле разворачивается в логику try/finally с ожидаемым вызовом Dispose(). .method private hidebysig static void Main(string [] args) cil managed { … .try { … } // end try finally { … IL_0012: callvirt instance void SimpleFinalize.MyResourceWrapper::Dispose() } // end handler } // end of method Program::Main Замечание. При попытке применить using к объекту, не реализующему интерфейс IDisposable, вы получите ошибку компиляции. Этот синтаксис исключает необходимость применения "ручной укладки" объектов в рамки программной логики try/finally, но, к сожалению, ключевое слово using в C# является двусмысленным (оно используется для указания пространств имен и для вызова метода Dispose()). Тем не менее, для типов .NET, предлагающих интерфейс IDisposable, синтаксическая конструкция using гарантирует автоматический вызов метода Dispose() при выходе из соответствующего блока. Исходный код. Проект SimpleDispose размещен в подкаталоге, соответствующем главе 5. Создание типов, предусматривающих освобождение ресурсов и финализацию К этому моменту мы с вами обсудили два различных подхода в построении классов, способных освобождать свои внутренние неуправляемые ресурсы. С одной стороны, можно переопределить System.Object.Finalize(), тогда вы будете уверены в том, что объект непременно освободит ресурсы при сборке мусора, без какого бы то ни было вмешательства пользователя. С другой стороны, можно реализовать IDisposable, что обеспечит пользователю возможность освободить ресурсы после завершения работы с объектом. Однако, если вызывающая сторона "забудет" вызвать Dispose(), неуправляемые ресурсы смогут оставаться в памяти неопределенно долгое время. Вы можете догадываться, что есть возможность комбинировать оба эти подхода в одном определении класса. Такая комбинации позволит использовать преимущества обеих моделей. Если пользователь объекта не забудет вызвать Dispose(), то с помощью вызова GC.SuppressFinalize() вы можете информировать сборщик мусора о том. что процесс финализации следует отменить. Еcли пользователь объекта забудет вызвать Dispose(), то объект, в конечном счете, подвергнется процедуре финализации при сборке мусора. Так или иначе, внутренние неуправляемые ресурсы объекта будут освобождены. Ниже предлагается очередной вариант MyResourceWrapper, в котором теперь предусмотрены и финализация, и освобождение ресурсов. // Сложный контейнер ресурсов. public class MyResourceWrapper: IDisposable { // Сборщик мусора вызывает этот метод в том случае, когда // пользователь объекта забывает вызвать Dispose(). ~MyResourceWrapper() { // Освобождение внутренних неуправляемых ресурсов. // НЕ следует вызывать Dispose() для управляемых объектов. } // Пользователь объекта вызывает этот метод для того, чтобы // как можно быстрее освободить ресурсы. public void Dispose() { // Освобождение неуправляемых ресурсов. // Вызов Dispose() для содержащихся объектов, // предусматривающих освобождение ресурсов. // Если пользователь вызвал Dispose(), то финализация не нужна. GC.SuppressFinalize(this); } } Обратите внимание на то, что в метод Dispose() здесь добавлен вызов GC.SuppressFinalize(), информирующий среду CLR о том, что теперь при сборке мусора не требуется вызывать деструктор, поскольку неуправляемые ресурсы уже освобождены с помощью программной логики Dispose(). Формализованный шаблон освобождения ресурсов Текущая реализация MyResourceWrapper работает вполне приемлемо, но некоторые недостатки она все же имеет. Во-первых, каждому из методов Finalize() и Dispose() приходится очищать одни и те же неуправляемые ресурсы. Это, конечно, ведет к дублированию программного кода, что усложняет задачу его поддержки. Лучше всего определить приватную вспомогательную функцию, которая вызывалась бы каждым из двух этих методов. Далее, следует убедиться в том, что метод Finalize() не пытается освободить управляемые объекты, которые должны обрабатываться методом Dispose(). Наконец, желательно гарантировать, что пользователь объекта сможет многократно вызывать метод Disposed без появления сообщений об ошибке. В настоящий момент наш метод Dispose() таких гарантий не дает. Для решения указанных проблемы Microsoft определила формализованный шаблон для освобождения ресурсов, устанавливающий баланс между устойчивостью к ошибкам, производительностью и простотой поддержки. Вот окончательная (и аннотированная) версия MyResourceWrapper, для которой используется этот "официальный" шаблон. public class MyResourceWrapper: IDisposable { // Используется для того, чтобы выяснить, // вызывался ли метод Dispose(). private bool disposed = false; public void Dispose() { // Вызов нашего вспомогательного метода. // Значение "true" указывает на то, что // очистку инициировал пользователь объекта. CleanUp(true); // Запрет финализации. GC.SuppressFinalize(this); } private void CleanUp(bool disposing) { // Убедимся, что ресурсы еще не освобождены. if (!this.disposed) { // Если disposing равно true, освободить // все управляемые ресурсы. if (disposing) { // Освобождение управляемых ресурсов. } // Освобождение неуправляемых ресурсов. } disposed = true; } ~MyResourceWrapper() { // Вызов нашего вспомогательного метода. // Значение "false" указывает на то, что // очистку инициировал сборщик мусора. CleanDp(false); } } Обратите внимание на то, что теперь MyResourceWrapper определяет приватный вспомогательный метод, с именем Cleanup(). Если для его аргумента указано true (истина), это значит, что сборку мусора инициировал пользователь объекта. И тогда мы должны освободить и управляемые, и неуправляемые ресурсы. Но если "уборка" инициирована сборщиком мусора, то при вызове CleanUp() следует указать false (ложь), чтобы внутренние объекты не освобождались (поскольку мы не можем гарантировать, что они все еще находятся в памяти). Наконец, перед выходом из CleanUp() член-переменная disposed логического типа устанавливается равной true, чтобы Dispose() можно было вызывать многократно без появления сообщений об ошибках. Исходный код. Проект FinalizableDisposableClass размещен в подкаталоге, соответствующем главе 5. На этом наше обсуждение того, как среда CLR управляет объектами с помощью сборки мусора, завершается. Остались нерассмотренными еще ряд вопросов, связанных с процессом сборки мусора (это, например, слабые ссылки и восстановление объектов), но вы теперь имеете достаточно знаний для того, чтобы продолжить исследование данной темы самостоятельно в удобное для вас время. Резюме Целью этой главы было обсуждение процесса сборки мусора. Вы могли убедиться, что сборщик мусора начинает работу только тогда, когда становится невозможным выделить необходимый объем управляемой динамической памяти (или когда из памяти выгружается домен данного приложения). Вы можете быть уверены в том, что сборка мусора будет выполнена в оптимальном режиме с помощью соответствующего алгоритма Microsoft, использующего генерации объектов, вторичные потоки для финализации, объектов и области управляемой динамической памяти, предназначенные для размещения больших объектов. В этой же главе объясняется, как с помощью типа класса System.GC взаимодействовать со сборщиком мусора. Это требуется при создании типов, предусматривающих финализацию или освобождение ресурсов. Типы, предусматривающие финализацию, представляют собой классы с переопределенным виртуальным методом System.Object.Finalize(), который (в будущем) должен обеспечить освобождение неуправляемых ресурсов. Объекты, предуcматриваюцие освобождение ресурсов, являются классами (или структурами), в которых реализуется интерфейс IDisposable. В рамках этого подхода пользователю объекта предлагается открытый метод, который должен быть вызван пользователем для выполнения внутренней ''уборки" сразу же, как только это потребуется. Наконец, вы узнали об "официальном" формализованном шаблоне освобождения ресурсов, в котором комбинируются оба указанных подхода. ГЛАВА 6. Структурированная обработка исключений Тема этой главы – устранение аномалий в среде выполнения вашего программного кода C# с помощью структурированной обработки исключений. Вы узнаете о ключевых словах C#, которые позволяют решать такие задачи (это ключевые слова try, catch, throw, finally), и выясните, в чем различие между исключениями системного уровня и уровня приложений. Данное обсуждение можно рассматривать, как введение в тему создания пользовательских исключений, а также как краткое описание средств отладки Visual Studio 2005, в основе которых, по сути, и лежит обработка исключений. Ода ошибкам и исключениям Вне зависимости от того, что говорит нам наша (часто преувеличенная) самооценка, абсолютно идеальных программистов не существует. Создание программного обеспечения является сложным делом и поэтому даже самые лучшие программы могут иметь проблемы. Иногда причиной проблем бывает несовершенный: программный код (например, выход за границы массива). В других случаях проблема возникает из-за неправильных данных, вводимых пользователем (например, ввод имени в поле телефонного номера), если возможность обработки таких данных не была предусмотрена в приложении. Независимо от причин возникающих проблем, результатом всегда оказывается непредусмотренное поведение приложения. Чтобы очертить рамки нашего обсуждения структурированной, обработки исключительных ситуаций, позвольте сформулировать определения трех терминов, часто используемых при изучении соответствующих аномалий. • Программные ошибки. Это, попросту говоря, ошибки программиста. Например, при использовании языка C++ без управляемых расширений, если вызвать указатель NULL или забыть очистить выделенную память (в результате чего происходит ''утечка" памяти), то возникает программная ошибка. • Пользовательские ошибки. В отличие от программных ошибок, пользовательские ошибки обычно возникают в результате действий объекта, использующего приложение, а не в результате действий разработчика. Например, действия пользователя, который вводит в текстовый блок строку "неправильного вида", могут привести к возникновению ошибки, если ваш программный код не в состоянии обработать такой ввод. • Исключения. Исключения, или исключительные ситуации, обычно проявляются в виде аномалий среды выполнения, и очень трудно, если вообще возможно, полностью учесть их все в процессе программирования приложения. К возможным исключительным ситуациям относятся попытки соединиться с базой данных, которой больше не существует, открыть поврежденный файл, контактировать с компьютером, который выключен. Программист, как и конечные пользователи, имеют очень ограниченные возможности управления в подобных "исключительных обстоятельствах". С учетом данных определений должно быть ясно, что структурированная обработка исключений в .NET предлагает подход, предназначенный для выявления исключительных ситуаций в среде выполнения. Однако и в случае программных и пользовательских ошибок, которые ускользнули от вашего внимания, среда CLR зачастую генерирует соответствующее исключение, идентифицирующее проблему. Для этого библиотеки базовых классов .NET определяют целый ряд исключений, таких как FormatException, IndexOutOfRangeException, FileNotFoundException, ArgumentOutOfRangeExсeption и т.д. Перед тем как углубиться в детали, давайте определим формальную роль структурированной обработки исключений и выясним, чем такая обработка отличается от традиционного подхода в деле исправления ошибок. Замечание. Чтобы сделать примеры программного кода, используемые в данной книге, как можно более конкретными, в них обрабатываются не асе возможные исключения, генерируемые соответствующими методами из библиотек базовых классов. Приемы, представленные в этой главе, вы можете использовать в своих реальных проектах по своему усмотрению. Роль обработки исключений в .NET До появления .NET обработка ошибок в операционной системе Windows представляла собой весьма запутанную смесь технологий. Многие программисты создавали свою собственную логику обработки ошибок, используемую в контексте приложения. Например, группа разработчиков могла определить набор числовых констант, представляющих известные сбойные ситуации, и использовать эти константы в качестве возвращаемых значений метода. Для примера взгляните на следующий фрагмент программного кода, созданного на языке C. /* Типичный механизм учета ошибок в C. */ #define E_FILENOTFOUND 1000 int SomeFunction() { // Предположим, что возникла ситуация, в результате // которой возвращается следующее значение. return E_FILENOTFOUND; } void Main() { int retVal = SomeFunction(); if (retVal == E_FILE_NOTFOUND) printf("Не найден файл…"); } Такой подход следует признать далеким от идеального, если учесть тот факт, что константа E_FILENOTFOUND является лишь числовым значением, а не информационным агентом, предлагающим решение возникшей проблемы. В идеале хотелось бы получать название ошибки, сообщение о ней и другую полезную информацию в одном пакете вполне определенного вида (и именно это предлагается в рамках структурированного подхода к обработке исключений). В дополнение к приемам самого разработчика, Windows API предлагает сотни кодов ошибок, которые поставляются в виде #define, HRESULT, а также в виде многочисленных вариаций булевых значений (bool, BOOL, VARIANT_BOOL и т.д.). Многие разработчики программ на языке C++ (а также VB6) в рамках модели COM явно или неявно применяют ограниченный набор стандартных COM-интерфейсов (например, ISupportErrorInfo, IErrorInfo, ICreateErrorInfo), чтобы предоставить COM-клиенту информацию об ошибках. Очевидной проблемой этой уже устаревшей схемы является отсутствие симметрии. Каждый из подходов более или менее укладывается в рамки своей конкретной технологии, конкретного языка и, возможно, даже в рамки конкретного проекта. Чтобы положить конец неуемному буйству разнообразия, платформа .NET предлагает стандартную технологию генерирования и выявления ошибок среды выполнения: структурированную обработку исключений – СОИ (Structured Exception Handling – SEH). Преимущество предлагаемой технологии заключается в том. что теперь разработчики могут использовать в области обработки ошибок унифицированный подход, общий для всех языков, обеспечивающих поддержку .NET. Таким образом, способ обработки ошибок в C# оказывается синтакcически аналогичным такой обработке и в VB .NET, и в C++ с управляемыми расширениями. При этом синтаксис, используемый для генерирования и выявления исключений между компоновочными блоками и границами систем, тоже оказывается одинаковым (и это является дополнительным преимуществом). Еще одним преимуществом обработки исключений в .NET является то, что вместо передачи простого "зашифрованного" числового значения, идентифицирующего проблему, исключения представляют собой объекты, содержащие понятное человеку описание ошибки, а также подробную "копию" содержимого стека вызовов в момент возникновений исключительной ситуации. К тому же вы имеете возможность предоставить конечному пользователю ссылку с адресом URL, по которой пользователь может получить подробную информацию о соответствующей проблеме. Атомы обработки исключений в .NET При создании программ с применением структурированной обработки исключений предполагается использовать следующие четыре взаимосвязанных элемента: • тип класса, который предоставляет подробную информацию о возникшей исключительной ситуации; • член, который генерирует, или направляет (throw) вызывающей стороне экземпляр класса, соответствующего исключительной ситуации: • блок программного кода вызывающей стороны, в котором был вызван генерирующий исключение член; • блок программного кода вызывающей стороны, в котором выполняется обработка, или захват (catch), данного исключения. В языке программирования C# предлагаются четыре ключевых слова (try, catch, throw и finally), с помощью которых генерируются и обрабатываются исключения. Тип, представляющий соответствующую проблему, является классом, производным от System.Exception (или его потомком). С учетом этого давайте выясним роль указанного базового класса. Базовый класс System.Exception Все исключения, определенные на уровне пользователя и системы, в конечном счете получаются из базового класса System.Exception (который, в свою очередь, получается из System.Object). Обратите внимание на то, что некоторые из указанных ниже членов виртуальны и поэтому могут переопределяться производными типами. public class Exception: ISerializable, _Exception { public virtual IDictionary Data { get; } protected Exception(SerializationInfo info, StreamingContext context); public Exception(string message, Exception innerException); public Exception(string message); public Exception(); public virtual Exception GetBaseException(); public virtual void GetObjectData(SerializationInfo info, StreamingContext context); public System.Type GetType(); protected int HResult { get; set; } public virtual string HelpLink { get; set; } public System.Exception InnerException { get; } public virtual string Message { get; } public virtual string Source { get; set; } public virtual string StackTrace { get; } public MethodBase TargetSite { get; } public override string ToString(); } Как видите, многие свойства, определенные в классе System.Exception, доступны только для чтения. Причиной этого является тот простой факт, что производные типы обычно предусматривают для каждого свойства значение по умолчанию (например, для типа IndexOutOfRangeException принятым по умолчанию сообщением является "Index was outside the bounds of the array", т.е. "Выход индекса за границы массива"). Замечание. В .NET 2.0 System.Exception реализует интерфейс _Exception, чтобы соответствующие функциональные возможности были доступны неуправляемому программному коду. В табл. 6.1 предлагаются описаний некоторых членов System.Exception. Таблица 6.1. Основные члены типа System.Exception
Простейший пример Чтобы продемонстрировать "пользу" структурированной обработки исключений, нужно создать тип, который в подходящем окружении может генерировать исключение. Предположим, что мы создали новое консольное приложение с именeм SimpleException, в котором определяются два типа класса Car (автомобиль) и Radio (радио), связанные отношением локализации ("has-a"). Тип Radio определяет один метод, включающий и выключающий радио. public class Radio { public void TurnOn(bool on) { if (on) Console.WriteLine("Радиопомехи…"); else Console.WriteLine ("И тишина…"); } } В дополнение к использованию типа Radio в рамках модели локализации/делегирования, тип Car определяет следующее поведение. Если пользователь объекта Car превысит предел для скорости (этот предел задается значением соответствующего члена-константы), то "двигатель взрывается" и объект Car становится непригодным для использования, что выражается в соответствующем изменении значения члена-переменной типа bool с именем carIsDead (автомобиль разрушен). Кроме того, тип Car имеет несколько членов-переменных, представляющих текущую скорость и "ласкательное имя", данное автомобилю пользователем, а также несколько конструкторов. Вот полное определение этого типа (с соответствующими примечаниями). public class Car { // Константа для максимума скорости. public const int maxSpeed = 100; // Данные внутреннего состояния. private int currSpeed; private string petName; // Работает ли этот автомобиль? private bool carIsDead; // В автомобиле есть радио. private Radio theMusicBox = new Radio(); // Конструкторы. public Car() {} public Car(string name, int currSp) { currSpeed = currSp; petName = name; } public void CrankTunes(bool state) { // Запрос делегата для внутреннего объекта. theMusicBox.TurnOn(state); } // He перегрелся ли автомобиль? public void Accelerate(int delta) { if (carIsDead) Console.WriteLine("{0} не работает…", petName); else { currSpeed += delta; if (currSpeed › maxSpeed) { Console.WriteLine("{0} перегрелся!", petName); currSpeed = 0; carIsDead = true; } else Console.WriteLine("=› currSpeed = {0}", currSpeed); } } } Теперь реализуем такой метод Main(), в котором объект Car превысит заданную максимальную скорость (представленную) константой maxSpeed). static void Main(string[] args) { Console.WriteLine("*** Создание и испытание автомобиля ***"); Car myCar = new Car("Zippy", 20); myCar.CrankTunes(true); for (int i = 0; i ‹ 10; i++) myCar.Accelerate(10); Console.ReadLine(); } Тогда мы увидим вывод, подобный показанному на рис. 6.1. 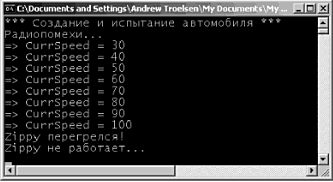 Рис. 6.1. Объект Car в действии Генерирование исключений Теперь, когда тип Car функционирует, продемонстрируем простейший способ генерирования исключений. Текущая реализация Accelerate() выводит сообщение об ошибке, когда значение скорости объекта Car становится выше заданного предела. Модифицируем этот метод так, чтобы он генерировал исключение при попытке пользователя увеличить скорость автомобиля выше предусмотренных его создателем пределов. Для этого нужно создать и сконфигурировать экземпляр класса System.Exception, установив значение доступного только для чтения свойства Message с помощью конструктора класса. Чтобы отправить соответствующий ошибке объект вызывающей стороне, используйте ключевое слово C# throw. Вот как может выглядеть соответствующая модификация метода Accelerate(). // Теперь, если пользователь увеличит скорость выше maxSpeed, // генерируется исключение. public void Accelerate(int delta) { if (carIsDead) Console.WriteLine("{0} не работает…", petName); else { currSpeed += delta; if (currSpeed ›= maxSpeed) { carIsDead = true; currSpeed = 0; // Используйте ключевое слово "throw", // чтобы генерировать исключение. throw new Exception(string.Format("{0} перегрелся!", petName)); } else Console.WriteLine("=› CurrSpeed = {0}', currSpeed); } } Прежде чем выяснить, как вызывающая сторона должна обрабатывать это исключение, отметим несколько интересных моментов. Во-первых, при генерировании исключения только от вас зависит, что следует считать исключительной ситуацией и когда должно быть сгенерировано соответствующее исключение. Здесь мы предполагаем, что при попытке в программе увеличить скорость автомобиля, который уже перестал функционировать, должен генерироваться тип System.Exception, сообщающий, что метод Accelerate() не может продолжить свою работу. В качестве альтернативы можно реализовать такой метод Accelerate(), который автоматически выполнит восстановление без генерирования исключения. Вообще говоря, исключения должны генерироваться только тогда, когда выявляются экстремальные ситуации (например, не найден необходимый файл, нет возможности соединиться с базой данных и т.п.). Решение о том, что именно должно вызывать появление исключений, должно приниматься разработчиком, и вы, как разработчик, должны всегда помнить об этом. Для наших примеров мы предполагаем, что увеличение скорости нашего обреченного автомобиля выше допустимого предела является вполне серьезной причиной для генерирования исключения. Обработка исключений Ввиду того, что теперь метод Accelerate() может генерировать исключение, вызывающая сторона должна быть готова обработать такое исключение. При вызове метода, способного генерировать исключение, вы должны использовать блок try/catch. Приняв исключение, вы можете вызвать члены типа System.Exception и прочитать подробную информацию о проблеме. Что вы будете делать с полученными данными, зависит, в основном, от вас. Вы можете поместить соответствующую информацию в файл отчета, записать ее в журнал регистрации событий Windows, отправить ее по электронной почте администратору системы или показать сообщение с описанием проблемы конечному пользователю. Здесь мы просто выводим информацию в окно консоли. // Обработка сгенерированного исключения. static void Main(string[] args) { Console.WriteLine("*** Создание и испытание автомобиля ***"); Car myCar = new Car("Zippy", 20); myCar.CrankTunes(true); // Превышение допустимого максимума для скорости, // чтобы генерировать исключение. try { for (int i = 0; i ‹ 10; i++) myCar.Accelerate(10); } catch(Exception e) { Console.WriteLine("\n*** Ошибка! ***"); Console.WriteLine("Метод: {0}", e.TargetSite); Console.WriteLine("Сообщение: {0}", e.Message); Console.WriteLine("Источник: {0}", е.Source); } // Ошибка обработана, выполняется следующий оператор. Console.WriteLine("\n*** Выход из обработчика исключений ***"); Console.ReadLine(); } Блок try представляет собой набор операторов, которые могут генерировать иcключения в ходе их выполнения. Если обнаруживается исключение, поток выполнения программы направляется подходящему блоку catch. С другой стороны, если программный код в рамках блока try не генерирует исключений, блок catch полностью пропускается, и все проходит "тихо и спокойно". На рис. 6.2 показан вывод этой программы. Как видите, после обработки исключения приложение может продолжать свою работу, начиная с оператора, следующего за блоком catch. В некоторых случаях исключение может оказаться достаточно серьезным для того, чтобы прекратить выполнение приложения. Но в большинстве случаев оказывается возможным исправить ситуацию в рамках программной логики обработчика исключений, чтобы приложение продолжило свою работу (хотя и с возможными ограничениями функциональности, если, например, не удается установить соединение с удаленным источником данных). 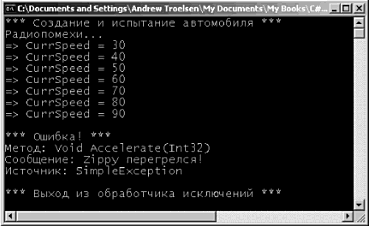 Рис. 6.2. Визуализация ошибок в рамках структурированной обработки исключений Конфигурация состояния исключений В настоящий момент конфигурация нашего объекта System.Exception задается в методе Accelerate(), где устанавливается значение, приписываемое свойству Message (через параметр конструктора). Но, как следует из табл. 6.1, класс Exception предлагает ряд дополнительных членов (TargetSite, StackTrace, HelpLink и Data), которые могут оказаться полезными в процессе дальнейшего анализа возникшей проблемы. Чтобы усовершенствовать наш пример, давайте рассмотрим содержимое указанных членов. Свойство TargetSite Свойство System.Exception.TargetSite позволяет выяснить дополнительную информацию о методе, генерирующем данное исключение. Как показано в предыдущем варианте метода Main(), при выводе значения TargetSite демонстрируется возвращаемое значение, имя и параметры метода, генерирующего данное исключение. Но TargetSite возвращает не просто строку, а строго типизированный объект System.Reflection.MethodBase. Этот тип содержит подробную информацию о методе, породившем проблему, и том классе, который определяет данный метод. Для иллюстрации обновим предыдущую логику catch так, как показано ниже. static void Main(string[] args) { … // В действительности TargetSite возвращает объект MethodBase. catch(Exception e) { Console.WriteLine("\n*** Ошибка! ***"); Console.WriteLine("Имя члена: {0}", е.TargetSite); Console.WriteLine("Класс, определяющий метод: {0}", е.TargetSite.DeclaringType); Console.WriteLine("Тип члена: {0}", е.TargetSite.MemberType); Console.WriteLine("Сообщение: {0}", e.Message); Console.WriteLine("Источник: {0}", e.Source); } Console.WriteLine("\n*** Выход из обработчика исключений ***"); myCar.Accelerate(10); // Это не ускорит автомобиль. Consolе.ReadLine(); } На этот раз вы используете свойство MethodBase.DeclaringType, чтобы определить абсолютное имя класса, сгенерировавшего ошибку (в данном случае это класс SimpleException.Car), и свойство MemberType объекта MethodBase, чтобы идентифицировать тип породившего исключение члена (в том смысле, свойство это или метод). На рис. 6.3 показан обновленный вывод. 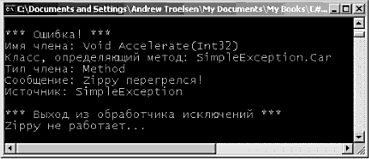 Рис 6.3. Получение информации о целевом объекте Свойство StackTrace Свойство System.Exception.StackTrace позволяет идентифицировать серию вызовов, которые привели к исключительной ситуации. Вы не должны устанавливать значение StackTrace, поскольку это делается автоматически в момент создания исключения. Для иллюстрации предположим, что мы снова обновили программный код catch. catch (Exception e) { … Console.WriteLine(''Стек {0}", e.StackTrace); } Если выполнить программу теперь, то вы обнаружите, что на консоль будет выведен след стека (для вашего приложения номера строк и названия папок, конечно же, могут быть другими). Стек: at SimpleException.Car.Accelerate(Int32 delta) in с:\myаррs\exceptions\car.cs: line 65 at Exceptions.App.Main() in с:\myapps\exceptions\app.cs: line 21 Строка, возвращаемая из StackTrace, сообщает последовательность вызовов, которые привели к генерированию данного исключения. Обратите внимание на то, что здесь последняя из возвращенных строк идентифицирует первый вызов в последовательности, а строка с наивысшим номером идентифицирует проблемный член. Эта информация может быть полезной при отладке приложения, поскольку вы получаете возможность "пройти" путь до источника ошибки. Свойство HelpLink Свойства Target Site и StackTrace позволяют получить информацию о данном исключении программисту, но конечному пользователю эта информация мало что дает. Вы уже видели, что для получения информации, понятной обычному пользователю, можно использовать свойство System.Exception.Message. В дополнение к этому свойство HelpLink может указать адрес URL или стандартный файл справки Windows, содержащий более подробную информацию. По умолчанию значением свойства HelpLink является пустая строка. Чтобы присвоить этому свойству некоторое значение, вы должны сделать это перед тем, как будет сгенерирован тип System.Exception. Вот как можно соответствующим образом изменить метод Car.Accelerate(). public void Accelerate(int delta) { if (carIsDead) Console.WriteLine("{0) не работает…", petName); else { currSpeed += delta; if (currSpeed ›= maxSpeed) { carIsDead = true; currSpeed = 0; // Чтобы вызвать свойство HelpLink, перед оператором, // генерирующим объект Exception, создается локальная переменная. Exception ex = new Exception(string.Format("{0} перегрелся!", petName)); ex.HelpLink = "http://www.CarsRUs.com"; throw ex; } else Console.WriteLine("=› CurrSpeed = {0}", currSpeed); } } Логику catch теперь можно изменить, чтобы информация ссылки выводилась так, как показано ниже. catch(Exception e) { … Console.WriteLine("Соответствующая справка: {0}", e.HelpLink); } Свойство Data Свойство Data объекта System.Exception является новым в .NET 2.0 и позволяет добавить в объект исключения дополнительную информацию для пользователя (например, штамп времени или что-то другое). Свойство Data возвращает объект, реализующий интерфейс с именем IDictionary, определенный в пространстве имен System.Collection. Роль программирования интерфейсов, как и пространство имен System.Collection, рассматриваются в следующей главе. Сейчас же будет достаточно заметить, что коллекции словарей позволяют создавать множества значений, возвращаемых по значению ключа. Рассмотрите, например, следующую модификацию метода Car.Accelerate(). public void Accelerate(int delta) { if (carIsDead) Console.WriteLine("{0} не работает…", petName); else { currSpeed += delta; if (currSpeed ›= maxSpeed) { carIsDead = true; currSpeed = 0; // Чтобы вызвать свойство HelpLink, перед оператором, // генерирующим объект Exception, создается локальная переменная. Exception ex = new Exception(string.Format("{0} перегрелся!", petName)); ex.HelpLink = "http://www.CarsRUs.com"; // Место для пользовательских данных с описанием ошибки. ex.Data.Add("Дата и время", string.Format("Автомобиль сломался {0}", DateTime.Now)); ex.Data.Add("Причина", " У вас тяжелая нога"); throw ex; } else Console.WriteLine("=› CurrSpeed = {0}", currSpeed); } } Чтобы не возникло проблем при определении пар "ключ-значение", с помощью директивы using следует указать пространство имен System.Collection, поскольку в файле, содержащем класс с реализацией метода Main(), мы собираемся использовать тип DictionaryEntry. using System.Collections; Затем нужно обновить программную логику catch для проверки того, что значение, возвращаемое свойством Data, не равно null (значение null задается по умолчанию). После этого мы используем свойства Key и Value типа DictionaryEntry, чтобы вывести пользовательские данные на консоль. catch (Exception e) { … // По умолчанию поле данных пусто, поэтому проверяем на null. Console.WriteLine("\n-› Пользовательские данные:"); if (e.Data != null) { foreach (DictionaryEntry de in e.Data) Console.WriteLine("-› {0}; {1}", de.Key, de.Value); } } С этими изменениями мы должны получить вывод, показанный на рис. 6.4. 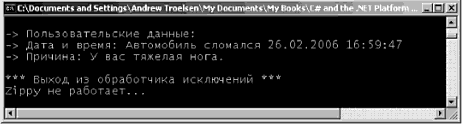 Рис. 6.4. Получение пользовательских данных Исходный код. Проект SimpleException размещен в подкаталоге, соответствующем главе 6. Исключения системного уровня (System.SystemException) Библиотеки базовых классов .NET определяют множество классов, производных от System.Exception. Пространство имен System определяет базовые объекты ошибок, например ArgumentOutOfRangeException, IndexOutOfRangeException, StackOverflowException и т.д. Другие пространства имен определяют исключения, отражающие поведение своих элементов (например, System.Drawing.Printing определяет исключения, возникающие при печати, System.IO – исключения ввода-вывода, System.Data – исключения, связанные с базами данных и т.д.). Исключения, генерируемые общеязыковой средой выполнения (CLR), называют исключениями системного уровня. Эти исключения считаются неустранимыми, фатальными ошибками. Исключения системного уровня получаются непосредственно из базового класса System.SystemException, являющегося производным от System.Exception (который, в свою очередь, получается из System.Object). public class SystemException: Exception { // Различные конструкторы. } С учетом того, что тип System.SystemException не добавляет ничего нового, кроме набора конструкторов, у вас может возникнуть вопрос, почему SystemException оказывается на первом месте. Главная причина в том, что если полученный тип исключения оказывается производным от System.SystemException, вы можете утверждать, что исключение сгенерировано средой выполнения .NET, а не программным кодом выполняемого приложения. Исключения уровня приложения (System.ApplicationException) Учитывая то, что все исключения .NET являются типами класса, можно создавать свои собственные исключения, учитывающие специфику приложения. Однако ввиду того, что базовый класс System.SystemException представляет исключения, генерируемые средой CLR, вполне естественно было бы предположить, что пользовательские исключений должны выводиться из типа System.Exception. Это действительно возможно, но практика диктует свой правила, по которым пользовательские исключения лучше выводить из типа System.ApplicationException. public class ApplicationException: Exception { // Различные конструкторы. } Подобно SystemException, тип ApplicationException не определяет никаких дополнительных членов, кроме набора конструкторов. С точки зрения функциональности единственной целью System.ApplicationException должна быть идентификация источника (устранимой) ошибки. При обработке исключения, полученного из System.ApplicationException, вы можете предполагать, что причиной появления исключения был программный код выполняемого приложения, а не библиотеки базовых классов .NET. Создание пользовательских исключений, раз… Всегда есть возможность генерировать экземпляр System.Exceptiоn, чтобы сигнализировать об ошибке времени выполнения (как показано в нашем первом примере), но часто бывает выгоднее построить строго типизированное исключение, которое предоставит уникальную информацию, характеризующую данную конкретную проблему. Предположим, например, что мы хотим создать пользовательское исключение (с именем CarIsDeadException), представляющее ошибку превышения скорости нашего обреченного автомобиля. Первым делом здесь должно быть создание нового класса из System.ApplicationException (по соглашению, классы исключений имеют суффикс "Exception", что в переводе означает "исключение"). // Это пользовательское исключение предлагает описание // автомобиля, вышедшего из строя. public class CarIsDeadException: ApplicationException {} Как и в случае любого другого класса, можно определить пользовательские члены, которые будут затем использоваться в блоке catch в рамках программной логики вызовов. Точно так же можно переопределить любые виртуальные члены, определенные родительскими классами. Например, можно реализовать CarIsDeadException, переопределив виртуальное свойство Message. public class CarIsDeadException: ApplicationException { private string messageDetails; public CarIsDeadException() {} public CarIsDeadException(string message) { messageDetails = message; } // Переопределение свойства Exception.Message. public override string Message { get { return string.Format("Сообщение об ошибке Car: {0}", messageDetails); } } } Здесь тип CarIsDeadException предлагает приватный член (messageDetails), представляющий информацию о текущем исключении, которая может быть задана с помощью пользовательского конструктора. Генерировать ошибку с помощью Accelerate() очень просто. Здесь следует разместить, сконфигурировать и сгенерировать тип CarIsDeadException, а не общий тип System.Exception. // Генерируем пользовательское исключение CarIsDeadException. public void Accelerate(int delta) { ... CarIsDeadException ex = new CarIsDeadException(string.Format("{0} перегрелся!", petName)); ex.HelpLink = "http://www.CarsRUs.com"; ex.Data.Add("Дата и время", string.Format("Автомобиль сломался {0}", DateTime.Now)); ex.Data.Add("Причина", "У вас тяжелая нога."); throw ex; } Чтобы выполнить явный захват поступившего исключения, блок catch следует изменить для захвата конкретного типа CarIsDeadException (однако, с учетом того, что System.CarIsDeadException является потомком System.Exception, можно также выполнить захват объекта System.Exception общего вида). static void Main (string[] args) { catch (CarIsDeadException e) { // Обработка поступившего исключения. } } Теперь, после рассмотрения основных этапов процесса создания пользовательских исключений, возникает вопрос: когда может потребоваться их создание? Как правило, пользовательские исключения требуется создавать только тогда, когда ошибка непосредственно связана с классом, генерирующим эту ошибку (например, пользовательский класс File может генерировать ряд исключений, связанных с доступом к файлам, класс Car может генерировать ряд исключений, связанных с работой автомобиля и т.д.). Тем самым вы обеспечиваете вызывающей стороне возможность обработки множества исключений на основе "индивидуального подхода". Создание пользовательских исключений, два… Тип CarIsDeadException переопределяет свойство System.Exception.Message, чтобы установить пользовательское сообщение об ошибке. Однако задачу можно упростить, установив родительское свойство Message через входной параметр конструктора. В результате нам не придется делать ничего, кроме следующего. public class CarIsDeadException: ApplicationException { public CarIsDeadException() {} public CarIsDeadException(string message) : base (message) {} } Обратите внимание на то, что теперь мы не определяем строковую переменную для представления сообщения и не переопределяем свойство Message. Вместо этого конструктору базового класса просто передается параметр. В рамках такого подхода пользовательский класс исключений представляет собой немногим большее, чем класс с уникальным именем, полученный из System.ApplicationException без каких бы то ни было членов-переменных (и переопределений базового класса). Не удивляйтесь, если большинство ваших пользовательских классов исключений (если не все они) будет иметь такой простой вид. Во многих случаях целью создания пользовательского исключения является не функциональные возможности, расширяющие возможности базовых классов, а получение строго именованного типа, идентифицирующего природу возникшей ошибки. Создание пользовательских исключений, три! Если вы хотите построить "педантично точный" пользовательский класс исключения, то созданный вами тип должен соответствовать лучшим образцам, использующим исключения .NET. В частности, ваше пользовательское исключение должно подчиняться следующим требованиям: • быть производным от Exception/ApplicationException; • обозначаться атрибутом [System.Serializable]; • определять конструктор, используемый по умолчанию; • определять конструктор, устанавливающий наследуемое свойство Message; • определять конструктор, обрабатывающий "внутренние исключения"; • определять конструктор, выполняющий сериализацию типа. Пока что глубина ваших знаний .NET не позволяет вам понять роль атрибутов и сериализации объектов, но сейчас это и не важно. Соответствующие вопросы будут рассмотрены позже. А в завершение обзора, посвященного вопросам создания пользовательских исключений, рассмотрите заключительный вариант CarIsDeadException. [Serializable] public class CarIsDeadException: ApplicationException { public CarIsDeadException() {} public CarIsDeadException(string message): base (message) {} public CarIsDeadException(string message, System.Exception inner): base (message, inner) {} protected CarIsDeadException(System.Runtime.Serialization.SerializationInfо info, System.Runtime.Serialization.StreamingContext context) : base(info, context) {} } Пользовательские исключения, соответствующие лучшим образцам программного кода .NET, на самом деле будут отличаться только именами, поэтому вам будет приятно узнать, что в Visual Studio 2005 предлагается шаблон программного кода под названием "Exception" (рис. 6.5), с помощью которого автоматически генерируется новый класс исключения в соответствии с лучшими рекомендациями .NET (шаблоны программного кода обсуждаются в главе 2). Обработка множеств исключений В простейшем варианте блок try имеет единственный блок catch. Но на практике часто возникает ситуация, когда операторы в рамках блока try способны создавать множество возможных исключений. Например, представьте себе, что метод Accelerate() дополнительно генерирует определенное библиотекой базовых классов исключение ArgumentOutOfRangeException, когда вы передаете методу недопустимый параметр (мы предполагаем, что недопустимым считается любое значение, меньшее нуля). // Прежде чем продолжить, проверим допустимость аргумента. public void Accelerate (int delta) { if (delta ‹ 0) throw new ArgumentOutOfRangeException("Скорость должна быть выше нуля!"); } 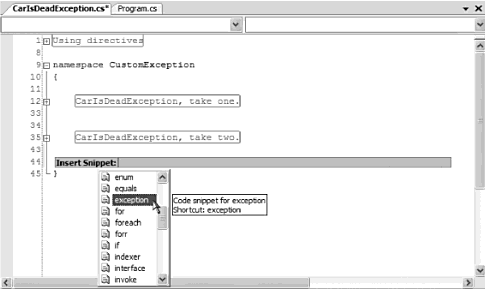 Рис. 6.5. Шаблон программного кода Exception Логика catch должна соответствовать каждому типу исключений. static void Main(string [] args) { … // Здесь учитывается множество исключений. try { for (int i = 0; i ‹ 10; i++) myCar.Accelerate(10); } catch(CarIsDeadExeeption e) { // Обработка CarIsDeadException. } catch (ArgumentOutOfRangeException e) { // Обработка ArgumentOutOfRangeException. } При создании множества блоков catch следует учитывать то, что сгенерированное исключение будет обработано "первым подходящим" бликом catch. Чтобы понять, что такое "первый подходящий" блок catch, добавьте в предыдущий фрагмент программного кода еще один блок catch, который будет обрабатывать все исключения после CarIsDeadException и ArgumentOutOfRangeException, выполняя захват System.Exception общего вида, как показано ниже. // Этот программный код не компилируется! static void Main(string[] args) { … try { for (int i = 0; i ‹ 10; i++) myCar.Accelerate(10); } catch(Exception e) { // Обработка всех остальных исключений? } catch(CarIsDeadException e) { // Обработка CarIsDeadException. } catch(ArgumentOutOfRangeException e) { // Обработка ArgumentOutOfRangeException. } … } Такая логика обработки исключений порождает ошибки компиляции. Проблема в том, что первый блок catch может обработать все, что оказывается производным от System.Exception, включая типы CarIsDeadException и ArgumentOutOfRangeException. Таким образом, оставшиеся два блока catch оказываются просто недостижимыми! Правило, которое следует использовать на практике, заключается в необходимости размещать блоки catch так, чтобы первый блок соответствовал самому "частному" исключению (т.е. самому младшему производному типу в цепочке наследования), а последний блок – самому "общему" (т.е. базовому классу данной цепочки, в данном случае это System.Exception). Поэтому если вы хотите определить оператор catch, который обработает все ошибки после CarIsDeadException и ArgumentOutOfRangeException, вы должны записать следующее. // Этот программный код будет скомпилирован. static void Main(string[] args) { … try { for (int i = 0; i ‹ 10; i++) myCar.Accelerate(10); } catch(CarIsDeadException e) { // Обработка CarIsDeadException. } catch(ArgumentOutOfRangeException) { // Обработка ArgumentOutOfRangeException. } catch (Exception e) { // Здесь будут обработаны все остальные возможные исключения, // генерируемые операторами в рамках try. } … } Общие операторы catch В C# также поддерживается "общий" блок catch, который не получает явно объект исключения, генерируемый данным членом. // Блок catch общего вида. static void Main(string[] args) { … try { for (int i = 0; i ‹ 10; i++) myCar.Accelerate(10); } catch { Console.WriteLine("Случилось что-то ужасное…"); } … } Очевидно, что это не самый информативный способ обработки исключения, поскольку здесь вы не имеете возможности получить содержательную информацию о произошедшей ошибке (например, имя метода, содержимое стека вызовов или пользовательское сообщение). Тем не менее, в C# такая конструкция возможна. Генерирование вторичных исключений Вы должны знать, что в рамках логики try имеется возможность генерировать исключение для вызывающей стороны, находящейся выше по цепочке вызовов в стеке вызовов. Для этого просто используйте ключевое слово throw в рамках блока сatch. Тем самым исключение будет направлено выше по цепочке логики вызовов, что может быть полезно тогда, когда данный блок catch не имеет возможности полностью обработать возникшую ошибку. // Перекладывание ответственности. static void Main (string[] args) { … try { // Логика ускорения автомобиля… } catch(CarIsDeadException e) { // Частичная обработка ошибки и перенаправление. // Здесь перенаправляется входной объект CarIsDeadException. // Но можно генерировать и другое исключение. throw e; } … } Вы должны понимать, что в данном примере программного кода конечным получателем CarIsDeadException является среда CLR, поскольку здесь вторичное исключение генерируется методом Main(). Поэтому вашему конечному пользователю будет представлено системное диалоговое окно с информацией об ошибке. Как правило, вторично сгенерированное и частично обработанное исключение предъявляется вызывающей стороне, которая имеет возможность обработать его более "грациозно". Внутренние исключения Вы можете догадываться, что вполне возможно генерировать исключения и во время обработки другого исключения. Например, предположим, что вы обрабатываете CarIsDeadException в рамках конкретного блока catch и в процессе обработки пытаетесь записать след стека в файл carErrors.txt на вашем диске C. catch(CarlsDeadException e) { // Попытка открыть файл carErrors.txt на диске C. FileStream fs = File.Open(@"C:\carErrors.txt", FileMode.Open); … } Если указанный файл на диске C не найден, попытка вызова File.Open() даст в результате FileNotFoundException. Позже мы рассмотрим пространство имен System.IO и выясним, как перед открытием файла можно программными средствами проверить наличие файла на жестком диске (и предотвратить возможность возникновения исключения). Однако здесь, чтобы сосредоточиться на теме исключений, мы предполагаем, что исключение возникло. Когда во время обработки одного исключения обнаруживается другое исключение, лучше всего записать новый объект исключения, как "внутреннее исключение" в рамках нового объекта того же типа, что и исходное исключение (язык сломаешь!). Причина, по которой мы должны создавать новый объект исключения, заключается в том, что единственным способом документирования внутреннего исключения оказывается использование параметров конструктора. Рассмотрите следующий фрагмент программного кода. catch (CarIsDeadException e) { try { FileStream fs = File.Open(@"C:\carErrors.txt", FileMode.Open); … } catch(Exception e2) { // Генерирование исключения, записывающего новое исключение // и сообщение первого исключения. throw new CarIsDeadException(e.Message, e2); } } Заметьте, что в данном случав мы передали объект FileNotFoundException конструктору CarIsDeadException в виде второго параметра. Сконфигурировав этот новый объект, мы направляем его по стеку вызовов следующему вызывающему объекту, в данном случае по отношению к методу Main(). С учетом того, что после Main() "следующих вызывающих объектов" для обработки исключений нет, мы снова должны увидеть диалоговое окно с сообщением об ошибке. Во многом подобно генерированию вторичных исключений, запись внутренних исключений обычно оказывается полезной только тогда, когда вызывающий объект имеет возможность красиво обработать такое исключение. В этом случае логика catch вызывающей стороны может использовать свойство InnerException для получения подробной информации об объекте внутреннего исключения. Блок finally В рамках try/catch можно также определить необязательный блок finally. Задача блока finally – обеспечить безусловное выполнение некоторого набора операторов программного кода, независимо от наличия или отсутствия исключения (любого типа). Для примера предположим, что вы хотите всегда выключать радио автомобиля перед выходом из Main(), независимо от исключений. static void Main(string[] args) { … Car myCar = new Car ('"Zippy", 20); myCar.CrankTunes(true); try { // Логика ускорения автомобиля. } catch (CarIsDeadException e) { // Обработка CarIsDeadException. } catch (ArgumentOutOfRangeException e) { // Обработка ArgumentOutOfRangeException. } catch(Exception e) { // Обработка всех остальных исключений. } finally { // Это выполняется всегда. Независимо от исключений. myCar.CrankTunes(false); } } Если вы не включите в конструкцию блок finally, то радио не будет выключаться, когда обнаруживается исключение (что может быть или не быть проблемой). В более реальном сценарии, когда приходится освобождать ресурсы объектов, закрывать файлы, отключаться от баз данных и т.д., блок finally может гарантировать соответствующую "уборку". Что и чем генерируется С учетом того, что методы в .NET Framework могут генерировать любое число исключений (в зависимости от обстоятельств), логичным кажется следующий вопрос: "Как узнать, какие именно исключения могут генерироваться тем или иным методом библиотеки базовых классов?" Ответ прост: это можно выяснить в документации .NET Framework 2.0 SDK. В системе справки для каждого метода указаны и исключения, которые может генерировать данный член. В Visual Studio 2005 вам предлагается альтернативный, более быстрый вариант: чтобы увидеть список всех исключений (если таковые имеются), генерируемых данным членом библиотеки базовых классов, достаточно просто задержать указатель мыши на имени члена в окне программного кода (рис. 6.6). 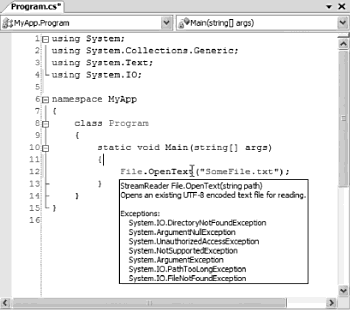 Рис. 6.6. Идентификация исключений, генерируемых данным методом Тем программистам, которые пришли к изучению .NET, имея опыт работы с Java, важно понять. что, члены типа не получают множество исключений из прототипа (другими словами, .NET не поддерживает типизацию исключений). Поэтому вам нет необходимости обрабатывать абсолютно все исключения, генерируемые данным членом. Во многих случаях можно обработать все ошибки путем захвата только System.Exception. static void Main(string[] args) { try { File.Open("IDontExist.txt", FileMode.Open); } catch(Exception ex) { Console.WriteLine(ex.Message); } } Однако если необходимо обработать конкретные исключения уникальным образом, то придется использовать множество блоков catch, как была показано в данной главе. Исключения, оставшиеся без обработки Здесь вы можете спросить, что произойдет в том случае, если не обработать исключение, направленное в ваш адрес? Предположим, что программная логика. Main() увеличивает скорость объекта Car выше максимальной скорости в отсутствие программной логики try/catch. Результат игнорирования исключения программой будет очень мешать конечному пользователю, поскольку перед его глазами появится диалоговое окно с информацией о "необработанном исключении". Если на машине установлены инструменты отладки .NET, появится нечто подобное тому, что показано на рис. 6.7 (машина без средств отладки должна отобразить аналогичное, не менее назойливое окно).  Рис 6.7. Результат игнорирования исключения Исходный код. Проект Custom Exception размещен в подкаталоге, соответствующем главе 6. Отладка необработанных исключений в Visual Studio 2005 В завершение нашего обсуждения следует заметить, что в Visual Studio 2005 предлагается целый ряд инструментов, которые помогают выполнить отладку программ с необработанными пользовательскими исключениями. Снова предположим, что мы увеличили скорость объекта Car выше максимума. Если в Visual Studio запустить сеанс отладки (используя Debug>Start из меню), то выполнение программы автоматически прервется в момент генерирования исключения, оставшегося без обработки. Более того, появится окно (рис. 6.8), в котором будет отображаться значение свойства Message. 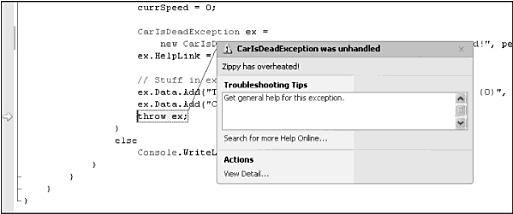 Рис. 6.8. Отладка необработанных пользовательских исключений в Visual Studio 2005 Если щелкнуть на ссылке View Detail (Показать подробности), появится дополнительная информация о состоянии объекта (рис. 6.9). 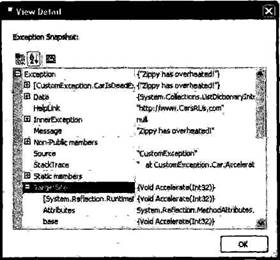 Рис. 6.9. Подробности отладки необработанных пользовательских исключений в Visual Studio 2005 Замечание. Если вы не обработаете исключение, сгенерированное методом из библиотеки базовых классов .NET, отладчик Visual Studio 2005 остановит выполнение программы на том операторе, который вызвал метод, создающий проблемы. Резюме В этой главе мы обсудили роль структурированной обработки исключений. Когда методу требуется отправить объект ошибки вызывающей стороне, этот метод создает, конфигурирует и посылает специальный тип System.Exception, используя для этого ключевое слово C# throw. Вызывающая сторона может обрабатывать поступающие исключения с помощью конструкций, в которых используются ключевое слово catch и необязательный блок finally. При создании пользовательских исключений вы создаете тип класса, производный от System.ApplicationException, что означает исключение, генерируемое выполняемым приложением. В противоположность этому объекты ошибок, получающиеся из System.SystemException представляют критические (и фатальные) ошибки, генерируемые средой CLR. Наконец, в этой главе были представлены различные инструменты Visual Studio 2005, которые можно использовать при отладке и при создании пользовательских исключений (в соответствии с лучшими образцами .NET). ГЛАВА 7. Интерфейсы и коллекции В этой главе предлагается рассмотреть тему программирования на основе интерфейсов, чтобы расширять ваши представления об объектно-ориентированном подходе в области разработки приложений. Здесь вы узнаете, как в рамках C# определяются и реализуются интерфейсы, и поймете, в чем заключаются преимущества типов, поддерживающих ''множественное поведение". В процессе обсуждения будет рассмотрен и ряд смежных вопросов – в частности, получение интерфейсных ссылок, явная реализация интерфейсов, а также иерархии интерфейсов. Часть главы будет посвящена рассмотрению целого ряда интерфейсов, определенных в рамках библиотек базовых классов .NET. Вы увидите, что определенные вами пользовательские типы тоже можно встраивать в эти предопределенные интерфейсы, чтобы обеспечить поддержку специальных функций, таких, как клонирование, перечисление и сортировка объектов. Чтобы продемонстрировать, как интерфейсы используются в библиотеках базовых классов .NET, в этой главе будут рассмотрено множество встроенных интерфейсов, реализуемых различными классами коллекций (ArrayList, Stack и т.п.), определенными в пространстве имен System.Collections. Информация, представленная здесь, будет необходима для понимания материала главы 10, в которой расcматриваются обобщения .NET и пространство имен Collections.Generiс. Определение интерфейсов в C# Изложение материала этой главы мы начнем с формального определения типа "интерфейс". Интерфейс – это просто именованная коллекция семантически связанных абстрактных членов. Эти члены определяются интерфейсом в зависимости от поведения, которое моделирует данный интерфейс. Интерфейс отражает поведение, которое может поддерживаться данным классом или структурой. В рамках синтаксиса C# интерфейс определяется с помощью ключевого слова interfасе. В отличие от других типов .NET, интерфейсы никогда не указывают базовый класс (включая System.Object) и для их членов никогда не указываются модификаторы доступа (поскольку все члены интерфейса неявно считаются открытыми). Вот пример пользовательского интерфейса, определенного на языке C#. // Этот интерфейс определяет наличие вершин. public interface IPointy { // Неявно открытый и абстрактный. byte GetNumberOfPoints(); } Замечание. По соглашению имена интерфейсов в библиотеках базовых классов .NET имеют префикс "I" (прописная буква "i" латинского алфавита). При создании пользовательского интерфейса рекомендуется придерживаться аналогичных правил. Как видите, интерфейс IPointy определяет единственный метод. Однако типы интерфейса в .NET могут также определять любое число свойств. Например, можно определить интерфейс IPointy, в котором используется доступное только для чтения свойство вместо традиционного метода чтения данных. // Реализация поведения в виде свойства, доступного только для чтения. public interface IPointy { byte Points {get;} } Вы должны понимать, что типы интерфейса сами по себе совершенно бесполезны, поскольку они представляют собой всего лишь именованные коллекции абстрактных членов. В этой связи вы не можете размещать типы интерфейса так, как это делается с классом или структурой. // Создавать типы интерфейса с помощью "new" не допускается. static void Main(string[] args) { IPointy p = new IPointy(); // Ошибка компиляции! } Интерфейсы не приносят пользы, если они не реализованы некоторым классом или структурой. Здесь IPointy является интерфейсом, отражающим "наличие вершин". Такое поведение может быть полезным в иерархии форм, построенной нами в главе 4. Идея очень проста: некоторые классы в иерархии форм имеют вершины (например, Hexagon – шестиугольник), а другие (например, Circle – круг) вершин не имеют. Реализовав интерфейс IPointy в Hexagon и Triangle, вы можете предполагать, что оба класса поддерживают общий тип поведения, а поэтому и общее множество членов. Реализация интерфейсов в C# Чтобы расширить функциональные возможности класса (или структуры) путем поддержки типов интерфейса, нужно просто указать в определении класса (или структуры) список соответствующих типов, разделив их запятыми. Непосредственный базовый класс должен быть первым элементом в списке, следующим после операции, обозначаемой двоеточием. Когда тип класса получается непосредственно из System.Object, можно указать только список интерфейсов, поддерживаемым классом, поскольку при отсутствии явного указании компилятор C# получает типы именно из System.Object. Точно так же, поскольку структуры всегда получаются из System.ValueType (см. главу 3), можно указать только интерфейсы в списке, следующем непосредственно после определения структуры. Рассмотрите следующие примеры. // Этот класс является производным System.Object. // и реализует один интерфейс. public сlаss SomeClass: ISomeInterface {…} // Этот класс является производным System.Object // и реализует один интерфейс. public class MyClass: object, ISomeInterface {…} // Этот класс является производным пользовательского базового класса // и реализует один интерфейс. public class AnotherClass: MyBaseClass, ISomeInterface {…} // Эта структура является производной System.ValueType // и реализует два интерфейса. public struct SomeStruct: ISomeInterface, IPointy Вы должны понимать, что реализация интерфейса подчиняется принципу "все или ничего". Тип, реализующий интерфейс, не может обеспечивать селективную поддержку членов этого интерфейса. Если интерфейс IPointy определяет единственное свойство, то для выбора вариантов нет. Однако если реализовать интерфейс, определяющий десять членов, то соответствующий тип будет обязан конкретизировать все десять абстрактных элементов. Так или иначе, вот вам пример реализации обновленной иерархии форм (и обратите внимание на новый тип класса Triangle – треугольник). // Hexagon теперь реализует IPointy. public class Hexagon: Shape, IPointy { public Hexagon() {} public Hexagon(string name): base (name) {} public override void Draw() { Console.WriteLine("Отображение шестиугольника {0} ", PetName); } // Реализация IPointy. public byte Points { get { return 6; } } } // Новый производный класс Triangle, полученный из Shape. public class Triangle: Shape, IPointy { public Triangle() {} public Triangle(string name): base(name) {} public override void Draw() { Console.WriteLine("Отображение треугольника {0} ", PetName); } // Реализация IPointy. public byte Points { get { return 3; } } } Теперь каждый класс при необходимости возвратит вызывающей стороне число вершин. Чтобы резюмировать сказанное, рассмотрите диаграмму на рис. 7.1, которая была получена в Visual Studio 2005 и иллюстрирует совместимые по интерфейсу IPointy классы, используя популярное обозначение интерфейса знаком "леденца на палочке". 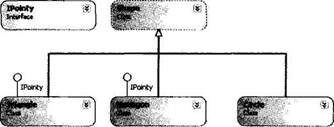 Рис. 7.1. Иерархия форм (теперь с интерфейсами) Интерфейсы в сравнении с абстрактными базовыми классами С учетом знаний, полученных в главе 4, вы можете спросить, какова причина выдвижения типов интерфейса на первое место. Ведь в C# позволяется строить абстрактные типы класса, содержащие абстрактные методы. И, подобно интерфейсу, при получении класса из абстрактного базового класса, класс тоже обязан определить детали абстрактных методов (если, конечно, производный класс не объявляется абстрактным). Однако возможности абстрактных базовых классов выходят далеко за рамки простого определения группы абстрактных методов. Они могут определять открытые, приватные и защищенные данные состояния, а также любое число конкретных методов, которые оказываются доступными через подклассы. Интерфейсы, с другой стороны, – это чистый протокол. Интерфейсы никогда не определяют данные состояния и никогда не обеспечивают реализацию методов (при попытке сделать это вы получите ошибку компиляции). public interface IAmABadInterface { // Ошибка! Интерфейс не может определять данные! int myInt = 0; // Ошибка! Допускается только абстрактные члены! void MyMethod() {Console.WriteLine("Фи!");} } Типы интерфейса оказываются полезными и в свете того, что в C# (и других языках .NET) не поддерживается множественное наследование, а основанный на интерфейсах протокол позволяет типу поддерживать множество вариантов поведения, избегая при этом проблем, возникающих при наследовании от множества базовых классов. Еще более важно то, что программирование на основе интерфейсов обеспечивает альтернативный способ реализаций полиморфного, поведения. Хотя множество классов (или структур) реализует один и тот же интерфейс своими собственными способами, вы имеете возможность обращаться со всеми типами по одной схеме. Чуть позже вы убедитесь, что интерфейсы исключительно полиморфны, потому что с их помощью возможность демонстрировать идентичное поведение получают типы, не связанные классическим наследованием. Вызов членов интерфейса на уровне объекта Теперь, когда у вас есть набор типов, поддерживающих интерфейс Pointy, следующей задачей оказывается доступ я новым функциональным возможностям. Самым простым способом обеспечения доступа к функциональным возможностям данного интерфейса является непосредственный вызов методов на уровне объектов. Например: static void Main(string[] args) { // вызов члена Points интерфейса IPointy. Hexagon hex = new Hexagon(); Console.WriteLine("Вершин: {0}", hex.Points); Console.ReadLine(); } Этот подход прекрасно работает в данном конкретном случае, поскольку вы знаете, что тип Hexagon реализует упомянутый интерфейс. Однако в других случаях во время компиляции вы не сможете определить, какие интерфейсы поддерживаются данным типом. Предположим, например, что у нас есть массив из 50 типов, соответствующих Shape, но только некоторые из них поддерживают IPointy. Очевидно, что если вы попытаетесь вызвать свойство Points для типа, в котором IPointy не реализован, вы получите ошибку компиляции. Возникает следующий вопрос: "Как динамически получить информацию о множестве интерфейсов, поддерживаемых данным типом?" Выяснить во время выполнения, поддерживает ли данный тип конкретный интерфейс можно, например, с помощью явного вызова. Если тип не поддерживает запрошенный интерфейс, вы получите исключение InvalidCastException. Чтобы "изящно" обработать эту возможность, используйте структурированную обработку исключений, например: static void Main(string[] args) { … // Возможный захват исключения InvalidCastException. Circle с = new Circle ("Lisa"); IPointу itfPt; try { itfPt = (IPointy)c; Console.WriteLine(itfPt.Points); } catch (InvalidCastException e) { Console.WriteLine(e.Message); } Console.ReadLine(); } Итак, можно использовать логику try/catch и надеяться на удачу, но лучше еще до вызова членов интерфейса определить, какие интерфейсы поддерживаются. Мы рассмотрим два варианта такой тактики. Получение интерфейсных ссылок: ключевое слово as Второй способ проверить поддержку интерфейса для данного типа предполагает использование ключевого слова as, о котором уже шла речь в главе 4. Если объект можно интерпретировать, как указанный интерфейс, будет возвращена ссылка на интерфейс. Если нет – вы получите null. static void Main(string[] args) { … // Можно ли интерпретировать hex2, как IPointy? Hexagon hex2 = new Hexagon("Peter"); IPointy itfPt2 = hex2 as IPointy; if (itfPt2 != null) Console.WriteLine("Вершин: {0}", itfPt2.Points); else Console.WriteLine("ОЙ! Вершин не видно…"); } Обратите внимание на то, что при использовании ключевого слова as не возникает необходимости использовать логику try/catch, поскольку в том случае, когда ссылка оказывается непустой, вы гарантированно будете иметь действительную ссылку на интерфейс. Получение интерфейсных ссылок: ключевое слово is Можно также проверить реализацию интерфейса с помощью ключевого слова is. Если соответствующий объект не совместим указанным интерфейсом, будет возвращено значение false. А если тип совместим с интерфейсом, вы можете смело вызвать его члены без использования логики try/catch. Для примера предположим, что мы изменили массив типов Shape так, что теперь некоторые его члены реализуют IPointy. Вот как с помощью ключевого слова is можно выяснить, какие из элементов в массиве поддерживают этот интерфейс. static void Main(string[] args) { … Shape[] s = {new Hexagon(), new Circle(), new Triangle("Joe"), new Circle("JoJo")}; for (int i = 0; i ‹ s.Length; i++) { // Напомним, что базовый класс Shape определяет абстрактный // член Draw(), поэтому все формы могут отображать себя. s[i].Draw() // Кто с вершинами? if (s[i] is IPointy) Console.WriteLine("-› Вершин: {0} ", ((IPointy)s[i]).Points); else Console.WriteLine("-› {0} без вершин!", s[i].PetName); } } Соответствующий вывод показан на рис. 7.2. 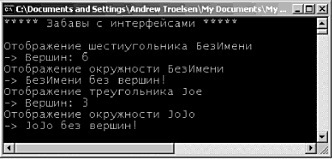 Рис 7.2. Динамическое обнаружение реализованных интерфейсов Интерфейсы в качестве параметров Поскольку интерфейсы являются полноценными типами .NET, вы можете конструировать методы, которые будут использовать интерфейсы, как параметры. Для примера предположим, что мы определили другой интерфейс с именем IDraw3D. // Моделируем возможность отображения типа в пространстве. public interface IDraw3D { void Draw3D(); } Предположим также, что две из наших трех форм (Circle и Hexagon) сконфигурированы для поддержки этого нового поведения. // Circle поддерживает IDraw3D. public class Circle: Shape, IDraw3D { … public void Draw3D() { Console.WriteLine("3D-отображение окружности!"); } } // Hexagon поддерживает IPointy и IDraw3D. public class Hexagon: Shape, IPointy, IDraw3D { … public void Draw3D() { Console.WriteLine ("3D-отображение шестиугольника!"); } } На рис. 7.3 показана соответствующая обновленная диаграмма классов, полученная в Visual Studio 2005. 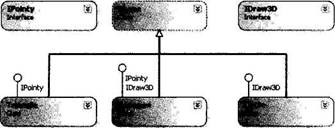 Рис. 7.3. Обновленная иерархия форм Если определить метод, использующий интерфейс IDraw3D в виде параметра, вы получите возможность передать любой объект, реализующий IDraw3D (но если вы попытаетесь передать тип, не поддерживающий нужный интерфейс, будет сгенерирована ошибка компиляции). Рассмотрим следующий фрагмент программного кода. // Создание нескольких форм. // Если это возможно, их отображение в трехмерном виде. public class Program { // Отображение форм, поддерживающих IDraw3D. public static void DrawIn3D(IDraw3D itf3d) { Console.WriteLine("-› Отображение IDraw3D-совместимого типа"); itf3d.Draw3D(); } static void Main() { Shape [] s = {new Hexagon(), new Circle(), new Triangle("Joe"), new Circle("JoJo")}; for (int i = 0; i ‹ s.Length; i++) { … // Можно ли отобразить в 3D-виде? if (s[i] is IDraw3D) DrawIn3D((IDraw3D)s[i]); } } } Обратите внимание на то, "что треугольник не отображается, поскольку он не является IDraw3D-совместимым (рис. 7.4). 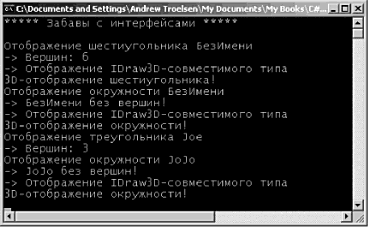 Рис.7.4. Интерфейсы в качестве параметров Интерфейсы в качестве возвращаемых значений Интерфейсы можно использовать и в качестве возвращаемых значений методов. Например, можно создать метод, который берет любой System.Object, проверяет на совместимость с IPointy и возвращает ссылку на извлеченный интерфейс. // Этот метод проверяет соответствие IPointy и, если это возможно, // возвращает ссылку на интерфейс. static IPointy ExtractPointyness(object o) { if (o is IPointy) return (IPointy)o; else return null; } С этим методом можно взаимодействовать так, как предлагается ниже. static void Main(string[] args) { // Попытка извлечь IPointy из объекта Car. Car myCar = new Car(); IPointy itfPt = ExtractPointyness(myCar); if (itfPt!= null) Console.WriteLine("Объект имеет {0} вершин.", itfPt.Points); else Console.WriteLine("Этот объект не реализует IPointy"); }; Массивы интерфейсных типов Следует понимать, что один и тот же интерфейс может реализовываться многими типами, даже если эти типы не находятся в рамках одной иерархии классов. В результате можно получать очень мощные программные конструкции, Предположим, например, что мы построили одну иерархию классов для описания кухонной посуды, а другую – для описания садового инвентаря. Эти иерархии абсолютно не связаны между собой с точки зрения классического наследования, но с ними можно обращаться полиморфно, используя программирование на основе интерфейсов. Для иллюстрации предположим, что у нас есть массив объектов, совместимых с IPointy. При условии, что все объекты этого массива поддерживают один интерфейс, вы можете обходиться с каждым объектом, как с IPointy-совместимым объектом, несмотря на абсолютную несовместимость иерархий классов. static void Main(string[] args) { // Этот массив может содержать только типы, // реализующие интерфейс IPointy. IPointy[] myPointyObjects = {new Hexagon(), new Knife(), new Triangle(), new Fork(), new PitchFork()}; for (int i = 0; i ‹ myPointyObjects.Length; i++) Console.WriteLine("Объект имеет {0} вершин", myPointyObjects[i].Points); } Замечание. С учетом общеязыковой природы .NET важно подчеркнуть, что можно определить интерфейс на одном языке (C#), а реализовать его на другом (VB .NET). Но чтобы выяснить, как это сделать, нам потребуется понимание структуры компоновочных блоков .NET, что является темой обсуждения главы 11. Явная реализация интерфейса В определении IDraw3D мы были вынуждены назвать наш единственный метод Draw3D(), чтобы избежать конфликта с абстрактным методом Draw(), определенным в базовом классе Shape. Такое определение интерфейса вполне допустимо, но более естественным именем для метода было бы Draw(). // Изменение имени с "Draw3D" на "Draw". public interface IDraw3D { void Draw(); } Если вносить такое изменение, то потребуется также обновить нашу реализацию DrawIn3D(). public static void DrawIn3D(IDraw3D itf3d) { Console.WriteLine("-› Отображение IDraw3D-совместимоuо типа"); itf3d.Draw(); } Теперь предположим, что мы определили новый класс Line (линия), который получается из абстрактного класса Shape и реализует iDraw3D (оба из них теперь определяют одинаково названные абстрактные методы Draw()). // Проблемы? Это зависит.… public class Line: Shape, IDraw3D { public override void Draw() { Console.WriteLine("Отображение линии…"); } } Класс Line компилируется беспрепятственно. Рассмотрим следующую логику Main(). static void Main(string[] args) { … // Вызов Draw(). Line myLine = new Line(); myLine.Draw(); // Вызов той же реализации Draw()! IDraw3D itfDraw3d = (IDraw3D)myLine; itfDraw3d.Draw(); } С учетом того, что вы уже знаете о базовом классе Shape и интерфейсе IDraw3D, это выглядит так как будто вы вызываете два варианта метода Draw() (один с объектного уровня, а другой – с помощью интерфейсной ссылки). Однако компилятор способен вызывать одну и ту же реализацию и с помощью интерфейса, и с помощью объектной ссылки, поскольку абстрактный базовый класс Shape и интерфейс IDraw3D имеют одинаково названные члены. Это может оказаться проблемой, когда вы хотите, чтобы метод IDraw3D.Draw() представлял тип во всей трехмерной (3D) "красе", а не в неказистом двухмерном представлении переопределённого метода Shape.Draw(). Теперь рассмотрим родственную проблему. Что делать, если вам нужно гарантировать, что методы, определенные данным интерфейсом, будут доступны только с помощью интерфейсных ссылок, а не объектных? В настоящий момент члены, определенные интерфейсом IPointy, доступны как с помощью объектных ссылок, так и по ссылке на IPointy. Ответ на оба вопроса дает явная реализация интерфейса. Используя этот подход, вы можете гарантировать, что пользователь объекта сможет получить доступ К методам, определенным данным интерфейсом, только с помощью правильной интерфейсной ссылки, не допуская при этом конфликта имен. Для примера рассмотрите следующий обновленный класс Line (предполагая, что вы соответствующим образом обновили Hexagon и Circle). // Используя явную реализацию метода, можно указать // другие реализации Draw() . public class Line: Shape, IDraw3D { // Этот метод можно вызвать только ссылкой на интерфейс IDraw3D. void IDraw3D.Draw() { Console.WriteLine("Отображение ЗD-линии…"); } // Это можно вызвать только на уровне объекта. public override void Draw() { Console.WriteLine("Отображение линии…"); } … } Как видите, при явной реализации члена интерфейса общий шаблон выглядит так: возвращаемоеЗначение ИмяИнтерфейса.ИмяМетода(аргументы). Здесь есть несколько "подводных камней", о которых следует знать. Прежде всего, не допускается определять явно реализуемые члены с модификаторами доступа. Например, следующий синтаксис недопустим. // Нет! Это недопустимо. public class Line: Shape, IDraw3D { public void IDraw3D.Draw() { // ‹= Ошибка! Console.WriteLine("Отображение 3D-линии…"); } … } Главной причиной использования явной реализации метода интерфейса является необходимость "привязки" соответствующего метода интерфейса к уровню интерфейса. Если добавить ключевое слово public, то это будет означать, что данный метод является членом открытого сектора класса, и "привязка" будет отменена. Тогда вызывающая сторона сможет вызывать только метод Draw(), определенный базовым классом Shape на объектном уровне. // Здесь вызывается переопределенный метод Shape.Draw(). Line myLine = new Line(); myLine.Draw(); Чтобы вызвать метод Draw(), определенный с помощью IDraw3D, мы должны явно получить интерфейсную ссылку, используя любой из ранее указанных подходов. Например: // Это обеспечит вызов метода IDraw3D.Draw(). Line myLine = new Line(); IDraw3D i3d = (IDraw3D) myLine; i3d.Draw(); Разрешение конфликтов имен Явная реализаций интерфейса может оказаться очень полезной тогда, когда реализуются несколько интерфейсов, содержащих идентичные члены, Предположим. например, что вы создали класс, реализующий следующие новые типы интерфейса.
public interface IDraw { void Draw(); } public interface IDrawToPrinter { void Draw(); } Если вы захотите построить класс с именем SuperImage (суперизображение), поддерживающий базовую визуализацию (IDraw), 3D-визуализацию (IDraw3D), а также сервис печати (IDrawToPrinter), то единственным способом обеспечить уникальную реализацию для каждого метода будет использование явной реализации интерфейса. // Не выводится из Shape, но вводит конфликт имен. public class SuperImage: IDraw, IDrawToPrinter, IDraw3D { void IDraw.Draw() {/* Логика базовой визуализации. */} void IDrawToPrinter.Draw() {/* Логика печати. */} void IDraw3D.Draw() {/* Логика 3D-визуализации. */} } Исходный код. Проект CustomInterface размешен в подкаталоге, соответствующем главе 7. Построение иерархии интерфейсов Продолжим наше обсуждение вопросов создания пользовательских интерфейсов и рассмотрим тему иерархии интерфейсов. Вы знаете, что класс может выступать в роли базового класса для других классов (которые, в свою очередь, тоже могут быть базовыми классами для других классов), но точно так же можно строить отношения наследования и среди интерфейсов. Как и следует ожидать, интерфейс на вершине иерархии определяет общее поведение, а интерфейсы, находящиеся на более низких уровнях, "уточняют" это поведение. Для примера рассмотрите следующую иерархию интерфейсов. // Базовый интерфейс. public interface IDrawable { void Draw(); } public interface IPrintable: IDrawable { void Print(); } public interface IMetaFileRender: IPrintable { void Render(); } Соответствующая цепочка наследования показана на рис. 7.5. 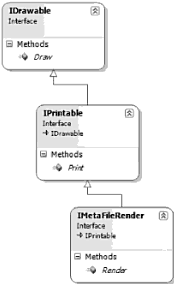 Рис. 7.5. Иерархия интерфейсов Теперь, если некоторый класс должен поддерживать все варианты поведения, заданные в рамках этой иерархии интерфейсов, то этот класс должен выводиться из интерфейса, лежащего в основе иерархии (в данном случае это IMetaFileRender). Все методы, определенные базовым интерфейсом (или интерфейсами), автоматически переносятся в определение. Например: // Этот класс поддерживает IDrawable, IPrintable и IMetaFileRender. public class SuperImage: IMetaFileRender { public void Draw() { Console.WriteLine("Базовая логика визуализации."); } public void Print() { Console.WriteLine("Вывод на принтер."); } public void Render() { Console WriteLine("Вывод в метафайл."); } } Вот пример вывода каждого интерфейса из экземпляра SuperImage. // Использование интерфейсов. static void Main(string[] args) { SuperImage si = new SuperImage(); // Получение IDrawable. IDrawable itfDraw = (IDrawable)si; itfDraw.Draw(); // Получение IMetaFileRender, который использует все методы, // определенные выше по цепочке интерфейсов. if (itfDraw is IMetaFileRender) { IMetaFileRender itfMF = (IMetaFileRender)itfDraw; itfMF.Render(); itfMF.Print(); } Console.ReadLine(); } Интерфейсы с множеством базовых интерфейсов При построении иерархии интерфейсов вполне допустимо создавать интерфейсы, которые оказываются производными от нескольких базовых интерфейсов. Однако напомним, что нельзя строить классы, которые будут производными от нескольких базовых классов. Для примера предположим, что вы строите набор интерфейсов, моделирующих поведение автомобиля. public interface ICar { void Drive(); } public interface IUnderwaterCar { void Dive(); } // Здесь интерфейс имеет ДВА базовых интерфейса. public interface IJamesBondCar: ICar, IUnderwaterCar { void TurboBoost(); } На рис. 7.6 показана соответствующая цепочка интерфейсов. 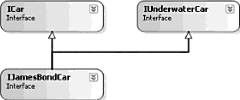 Рис. 7.6. Общая система типов (CTS) допускает множественное наследование интерфейсных типов При построении класса, реализующего IJamesBondCar (машина Джеймса Бонда), вы должны реализовать TurboBoost(), Dive() и Drive(). public class JamesBondCar: IJamesBondCar { public void Drive() { Console.WriteLine("Ускорение…"); } public void Dive() { Console.WriteLine("Погружение…"); } public void TurboBoost() { Console.WriteLine{"Взлет!"); } } Этот специализированный автомобиль можно использовать так, как и ожидается. static void Main(string[] args) { … JamesBоndCar j = new JamesBondCar(); j.Drive(); j.TurboBoost(); j.Dive(); } Реализация интерфейсов в Visual Studio 2005 Программирование на основе интерфейсов – это мощная техника программирования, но процесс реализации интерфейсов может предполагать ввод программного кода вручную в очень больших объемах. Поскольку интерфейсы представляют собой именованные наборы абстрактных членов, вам придется вводить программный код для каждого метода интерфейса и каждого класса, поддерживающего соответствующее поведение. Вы не ошибаетесь, если предполагаете, что в Visual Studio 2005 имеются различные средства автоматизации для решения задач реализации интерфейсов. Предположим, что нам нужно реализовать интерфейс ICar для нового класса с именем MiniVan. По завершении ввода имени интерфейса (или при помещении указателя мыши на имя интерфейса в окне программного кода) вы обнаружите, что под первой буквой имени появился так называемый "смарт-тег". При щелчке на нем раскрывается список, предлагающий реализовать интерфейс явно или неявно (рис. 7.7). 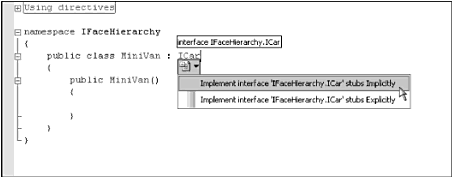 Рис. 7.7. Реализация интерфейсов в Visual Studio 2005 После выбора нужной вам опции Visual Studio 2005 сгенерирует программный код заглушки (в рамках соответствующей именованной области программного кода), который вы затем можете изменить (обратите внимание на то, что по умолчанию реализация предлагает исключение System.Exception). namespace IFaceHierarchy { public class MiniVan: ICar { public MiniVan() {} #region ICar Members public void Drive() { new Exception("The method or operation is not implemented."); } #endregion } } Теперь, после обсуждения специфики построения и реализации пользовательских интерфейсов, мы посвятим остаток главы рассмотрению встроенных интерфейсов, содержащихся в библиотеках базовых классов .NET. Исходный код. Проект IFaceHierarchy размещен в подкаталоге, соответствующем главе 7. Создание перечислимых типов (Enumerable и IEnumerator) Чтобы перейти к иллюстрации процесса реализации существующих интерфейсов .NET, нужно выяснить роль IEnumerable и IEnumerator. Предположим, что у нас есть класс Garage (гараж), содержащий некоторый набор типов Car (см. главу б), хранимых в виде System.Array. // Garage содержит набор объектов Car. public class Garage { private Car[] carArray; // Начальное наполнение объектами Car. public Garage() { carArray = new Car[4]; carArray[0] = new Car("Rusty", 30); carArray[1] = new Car("Clunker", 55); carArray[2] = new Car("Zippy", 30); carArray[3] = new Car("Fred", 30); } } Было бы удобно выполнить проход по элементам, содержащимся в объекте Garage, используя конструкцию C# foreach. // Это кажется разумным… public class Program { static void Main(string[] args) { Garage carLot = new Garage(); // Для каждого объекта Car в коллекции? foreach (Car c in carLot) { Console.WriteLine("{0} имеет скорость {1} км/ч", с.PetName, с.CurrSpeed);) } } Но, как это ни печально, компилятор сообщит вам, что класс Garage не реализует метод GetEnumerator(). Этот метод формально определен интерфейсом IEnumerable, находящимся в "недрах" пространства имен System.Collections. Объекты, поддерживающие соответствующий вариант поведения, декларируют, что они могут раскрыть содержащиеся в них элементы вызывающей стороне. // Этот интерфейс информирует вызывающую сторону о том, // что элементы объекта перечислимы. public interface IEnumerable { IEnumerator GetEnumerator(); } Как видите, метод GetEnumerator() должен возвращать ссылку на другой интерфейс – интерфейс c именем System.Collections.IEnumerator. Этот интерфейс предлагает инфраструктуру, которая позволяет вызывающей стороне выполнить цикл по объектам, содержащимся в IEnumerable-совместимом контейнере. // Этот интерфейс позволяет вызывающей стороне // получить внутренние элементы контейнера. public interface IEnumerator { bool MoveNext(); // Сдвинуть на позицию вперед. object Current { get;} // Прочитать (свойство только для чтения). void Reset(); // Сдвинуть в начальную позицию. } Чтобы обеспечить поддержку указанных интерфейсов типом Garage, можно пойти по длинному пути реализации каждого метода вручную. Конечно, ничто не запрещает указать свои версии GetEnumerator(), MoveNext(), Current и Reset(), но есть и более простой путь. Поскольку тип System.Array, как и многие другие типы, уже реализован в IEnumerable и IEnumerator, вы можете просто делегировать запрос к System.Array, как показано ниже. using System.Collections; public class Garage: IEnumerable { // В System.Array уже есть реализация IEnumerator! private Car[] carArray; public Cars() { carArray = new Car[4]; carArray[0] = new Car("FeeFee", 200, 0); carArray[l] = new Car("Clunker", 90, 0); carArray[2] = new Car("Zippy, 30, 0); carArray[3] = new Car("Fjred", 30, 0);} public IEnumerator GetEnumerator() { // Возвращает IEnumerator объекта массива. return carArray.GetEnumerator(); } } Теперь, после модификации типа Garage, вы можете использовать этот тип в конструкции foreach без опасений. К тому же, поскольку метод GetEnumerator() определен, как открытый, пользователь объекта тоже может взаимодействовать с типом IEnumerator. // Manually work with IEnumerator. IEnumerator I = carLot.GetEnumerator(); i.MoveNext(); Car myCar = (Car)i.Current; Console.WriteLine("{0} имеет скорость {1} км/ч", myCar.PetName, myCar.CurrSpeed); Если вы предпочтете скрыть функциональные возможности IEnumerable на объектном уровне, то следует использовать явную реализацию интерфейса. public IEnumerator IEnumerable.GetEnumerator() { // Возвращает IEnumerator объекта массива. return carArray.GetEnumerator(); } Исходный код. Проект CustomEnumerator размещен в подкаталоге, соответствующем главе 7. Методы итератора в C# В .NET 1.x для того, чтобы пользовательские коллекции (такие, как Garage) допускали применение конструкции foreach в операциях, подобных перечислению, реализация интерфейса IEnumerable (и, как правило, интерфейса IEnumerator) была обязательной. В C# 2005 предлагается альтернативный вариант построения типов, позволяющих применение цикла foreach, – с помощью итераторов. В упрощённой интерпретации итератор является членом, указывающим порядок возвращения внутренних элементов контейнера при их обработке с помощью foreach. И хотя метод итератора все равно должен называться GetEnumerator(), а возвращаемое значение все равно должно иметь тип IEnumerator, при таком подходе ваш пользовательский класс уже не обязан реализовывать все ожидаемые интерфейсы. public class Garage { // Без реализации IEnumerator! private Car[] carArray; … // Метод итератора. public IEnumerator GetEnumerator() { foreach (Car с in carArray) { yield return c; } } } Обратите внимание на то, что данная реализация GetEnumerator() осуществляет "проход" по вложенным элементам, используя внутреннюю логику foreach, и возвращает объекты Car вызывающей стороне, используя новую синтаксическую конструкцию yield return. Ключевое слово yield используется для того, чтобы указать значение (или значения), возвращаемые конструкции foreach вызывающей стороны. Когда в программе встречается оператор yield return, сохраняется текущая позиция, и именно с этой позиции выполнение будет продолжено при следующем вызове итератора. Когда компилятор C# обнаруживает метод итератора, в рамках области видимости соответствующего типа (в данном случае это Garage) динамически генерируется вложенный класс. Этот автоматически сгенерированный класс реализует интерфейсы IEnumerable и IEnumerator и указывает необходимые параметры членов GetEnumerator(), MoveNext(), Reset() и Current. Если теперь загрузить данное приложение в ildasm.exe, то будет видно, что внутренняя реализация GetEnumerator() в объекте Garage использует сгенерированный компилятором тип (который в данном примере получает имя ‹GetEnumerator›d__0). .method public hidebysig instance class [mscorlib] System.Collections.IEnumerator GetEnumerator() cil managed { … newobj instance void CustomEnumeratorWithYield.Garage/ '‹GetEnumerator›d__0'::.ctor(int32) … } // end of method Garage::GetEnumerator Явно, что от предложенного здесь определения метода итератора мы не получим большой пользы, поскольку наш тип Garage изначально реализовывал GetEnumerator(), ссылаясь на внутренний тип System.Array. Но синтаксис итератора C# может сэкономить немало времени при построении более "экзотических" пользовательских контейнеров (например, бинарных деревьев), где приходится вручную реализовать интерфейсы IEnumerator и IEnumerable. В любом случае программный код вызывающей стороны при взаимодействии с методом итератора с использованием foreach оказывается одинаковым. static void Main(string[] args) { Console.WriteLine("***** Забавы с методами итератора *****\n"); Garage carLot = new Garage(); foreach (Car с in carLot) { Console.WriteLine("{0} имеет скорость {1} км/ч", с.PetName, с.CurrrSpeed); } Console.ReadLine(); } Исходный код. Проект CustomEnumeratorWifhYield размещен в подкаталоге, соответствующем главе 7. Создание клонируемых объектов (ICloneable) Вы, должно быть, помните из главы 3, что System.Object определяет член с именем MemberwiseClone(). Указанный метод используется для получения поверхностной копии объекта. Пользователи объекта не могут вызвать этот метод непосредственно (поскольку он является защищенным), но сам объект может вызвать этот метод в процессе клонирования. Для примера предположим, что у нас есть класс с именем Point (точка). // Класс Point. public class Point { // Открыты для простоты. public int x, у; public Point(int x, int y) { this.x = x; this.у = у; } public Point(){} // Переопределение Object.ToString(). public override string ToString() { return string.Format("X = {0}; Y = {1}", x, у); } } С учетом того, что вы уже знаете о ссылочных типах и типах, характеризуемых значениями (см. главу 3), вы должны понимать, что в результате присваивания одной ссылочной переменной другой получаются две ссылки, указывающие на один и тот же объект в памяти. Поэтому следующее присваивание дает две ссылки на один и тот же объект Point в динамической памяти, и модификации любой из этих ссылок будут влиять на этот объект. static void Main(string[] args) { // Две ссылки на один и тот же объект! Point p1 = new Point(50, 50); Point p2 = p1; р2.х = 0; Console.WriteLine(p1); Console.WriteLine(p2); } Чтобы обеспечить пользовательскому типу возможность возвращать копию этого типа вызывающей стороне, можно реализовать стандартный интерфейс ICloneable. Этот интерфейс определяет единственный метод с именем Clone(). public interface ICloneable { object Clone(); } Очевидно, что реализация метода Clone() будет зависеть от объекта. Но базовые функциональные возможности оказываются одинаковыми: это копирование значений членов-переменных в новый экземпляр объекта и возвращение этого экземпляра пользователю. В качестве иллюстрации рассмотрите следующую модификацию класса Point. // Теперь Point поддерживает клонирование. public class Point: ICloneable { public int x, y; public Point(){} public Point (int x, int y) { this.x = x; this.у = у; } // Возвращение копии данного объекта. public object Clone() { return new Point(this.x, this.y); } public override string ToString() { return String.Format("X = {0}; Y = {1}", x, у); } } С помощью указанного подхода можно создавать точные и независимые копии типа Point, как показано в следующем фрагменте программного кода. static void Main (string[] args) { // Обратите внимание, Clone() возвращает объект общего типа. // Для получении производного типа используйте явное преобразование. Point р3 = new Point(100, 100); Point р4 = (Point)р3.Clone(); // Изменение p4.х (это не изменит р3.х). р4.х = 0; // Вывод объектов. Console.WriteLine(р3); Console.WriteLine(p4); } Текущая реализация Point решает все поставленные задачи, но вы можете немного усовершенствовать процесс. Введу того, что тип Point не содержит переменных ссылочного типа, можно упростить реализацию метода Clone(), как показано ниже. public object Clone() { // Скопировать все поля Point "почленно". return this.MemberwiseClone(); } При наличии в Point членов-переменных ссылочного типа метод MemberwiseClone() скопирует ссылки на соответствующие объекты (т.е. выполнит поверхностное копирование). Чтобы обеспечить поддержку полного копирования объектов, вы должны в процессе клонирования создать новый экземпляр для каждой переменной ссылочного типа. Соответствующий пример мы сейчас рассмотрим. Пример клонирования Предположим, что класс Point содержит член ссылочного типа с именем PointDescription, обеспечивающий поддержку "понятного" имени объекта Point и его идентификационного номера в виде System.Guid (еcли у вас нет опыта применения COM, знайте, что GUID – глобально уникальный идентификатор – это статистически уникальное 128-разрядное значение). Вот соответствующая реализация. // Этот класс описывает точку. public class PointDescription { // Открыты для простоты. public string petName; public Guid pointID; public PointDescription() { this.petName = "Без имени"; pointID = Guid.NewGuid(); } } При этом для учета новых элементов состояния в самом классе Point следует изменить метод ToString(), а также операторы определения и создания ссылочного типа PointDescription. Чтобы позволить "внешнему миру" указать имя для Point, можно также модифицировать аргументы, передаваемые перегруженному конструктору. public class Point: ICloneable { public int x, y; public PointDescription desc = new PointDescription(); public Point(){} public Point (int x, int y) { this.x = x; this.у = у; } public Point(int x, int y, string petname) { this.x = x; this.у = у; desc.petName = petname; } public object Clone() { return this.MemberwiseClone(); } public override string ToString() { return string.Format("X = {0}; Y = {1}; Имя = (2};\nID = {3}\n", x, y, desc.petName, desc.pointID); } } He забудьте о том. что вы еще не обновили метод Clone(). Поэтому при запросе клонирования объекта пользователем с помощью данной реализации все равно будет получена поверхностная ("почленная") копия. Для примера предположим, что мы обновили метод Main() так, как показано ниже. static void Main(string[] args) { Console.WriteLine("***** Забавы с ICloneable *****\n"); Console.WriteLine("Клонирован р3, новый Point сохранен в р4"); Point p3 = new Point(100, 100, "Jane"); Point p4 = (Point)p3.Clone(); Console.WriteLine("До модификации:"); Console.WriteLine("р3: {0}", р3); Console.WriteLine("p4: {0}", p4); p4.desc.petName = "Мистер X"; p4.x = 9; Console.WriteLine("Изменены p4.desc.petName и р4.х"); Console.WriteLine("После модификации: "); Console.WriteLine("p3: {0}", р3); Console.WriteLine("p4: {0}", p4); } На рис. 7.8 показан соответствующий вывод. 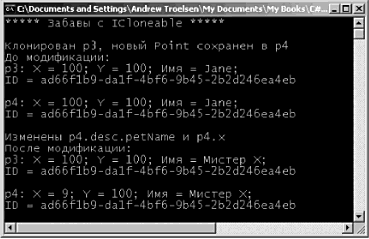 Рис. 7.8. Метод MemberwiseClone() возвращает поверхностную копию объекта Для того чтобы метод Clone() возвращал полные копии внутренних ссылочных типов, нужно "научить" возвращаемый методом MemberwiseClone() объект учитывать текущее имя объекта Point (тип System.Guid является структурой, так что на самом деле копируются числовые данные). Вот одна из возможных реализаций. // Мы должны учесть наличие члена PointDescription. public object Clone() { Point newPoint = (Point)this.MemberwiseClone(); PointDescription currentDesc = new PointDescription(); сurrentDesc.petName = this.desc.petName; newPoint.desc = currentDesc; return newPoint; } Если выполнить приложение теперь, то вы увидите (рис. 7.9), что возвращенный методом Clone() объект Point действительно копирует внутренние ссылочные члены-переменные типа (обратите внимание на то, что здесь p3 и p4 имеют свои уникальные имена). Итак, в том случае, когда класс или структура содержит только типы, характеризуемые значениями, лучше реализовать метод Clone(), использующий MemberwiseClone(). Однако в том случае, когда пользовательский тип содержит ссылочные типы, вы должны создать новый тип, принимающий во внимание все члены-переменные ссылочного типа. 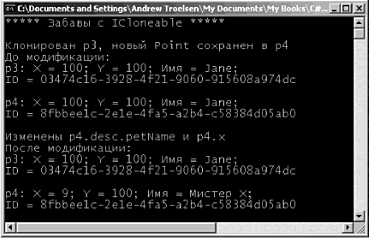 Рис. 7.9. Здесь получена полная копия объекта Исходный код. Проект CloneablePoint размещен в подкаталоге, соответствующем главе 7. Создание сравнимых объектов (IComparable) Интерфейс System.IComparable определяет поведение, позволяющее сортировать объекты по заданному ключу. Вот формальное определение. // Этот интерфейс позволяет объекту указать его связь // с другими подобными объектами. public interface IComparable { int CompareTo(object o); } Предположим теперь, что класс Car поддерживает некоторый внутренний идентификатор (представленный целым числом, хранимым в переменной carID), значение которого можно устанавливать с помощью параметра конструктора и изменять с помощью нового свойства ID. Ниже показана соответствующая модификация типа Car. public class Car { … private int carID; public int ID { get { return carID; } set { carID = value; } } public Car(string name, int currSp, int id) { currSpeed = currSp; petName = name; carID = id; } … } Пользователи объекта могут создать массив типов Car так. static void Main(string[] args) { // Создание массива типов Car. Car[] myAutos = new Car[5]; myAutos[0] = new Car("Rusty", 80, 1); myAutos[1] = new Car("Mary", 40, 234); myAutos[2] = new Car("Viper", 40, 34); myAutos[3] = new Car("Mel", 40, 4); myAutos[4] = new Car("Chucky", 40, 5); } Вспомним, что класс System.Array определяет статический метод Sort(). Вызвав этот метод для массива встроенных типов (int, short, string и т.д.), можно отсортировать элементы в массиве в числовом или алфавитном порядке, поскольку встроенные типы данных реализуют IComparable. Но что произойдет в том случае, когда методу Sort() будет передан массив типов Car, как показано ниже? // Будут ли отсортированы мои автомобили? Array.Sort(myAutos); Запустив этот пример, вы обнаружите, что среда выполнения сгенерирует исключение ArgumentException c сообщением следующего содержания: "Как минимум один объект должен реализовать IComparable". Чтобы позволить сортировку массивов ваших пользовательских типов, вы должны реализовать IComparable. При создании CompareTo() вы должны решить, что должно лежать в основе соответствующей операции упорядочения. Для типа Car самым подходящим "кандидатом" является carID. // Последовательность Car можно упорядочить на основе CarID. public class Car: IComparable { … // Реализация IComparable. int IComparable.CompareTo(object obj) { Car temp = (Car)obj; if (this.carID › temp.carID) return 1; if(this.carID ‹ temp.carID) return -1; else return 0; } } Как видите, в CompareTo() выполняется сравнение поступившего типа с текущим экземпляром на основе сравнения значений заданных элементов данных. Возвращаемое значение CompareTo() указывает, будет ли данный тип меньше, больше или равен объекту сравнения (см. табл. 7.1). Таблица 7.1. Возвращаемые значения CompareTo()
Теперь, когда тип Car "умеет" сравнивать себя с подобными объектами, вы можете записать пользовательский программный код следующего вида. // Проверка интерфейса IComparable. static void Main(string[] args) { // Создание массива типов Car. // Вывод исходного массива. Console.WriteLine("Несортированный набор машин:"); foreach(Car с in myAutos) Console.WriteLine("{0) (1}", с.ID, с.petName); // Теперь сортируем их с помощью IComparable. Array.Sort(myAutos); // Вывод отсортированного массива. Console.WriteLine("\nУпорядоченный набор машин:"); foreach(Car с in myAutos) Console.WriteLine("{0} {1}", с.ID, с.petName); Console.ReadLine(); } На рис. 7.10 показан соответствующий вывод. 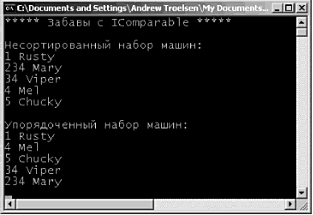 Рис. 7.10. Сравнение автомобилей на основе значений ID Сортировка по набору критериев (IComparer) В этой версии типа Car в качестве критерия упорядочения мы использовали ID автомобиля, В другом случае для сортировки можно использовать, например, petName (чтобы разместить автомобили в алфавитном порядке их названий). Но что делать, если нужно отсортировать автомобили и по значению ID, и по значению petName? В этом случае вы должны использовать другой стандартный интерфейс, определенный в рамках пространства имен System.Collections, – интерфейс IComparer. // Типичный способ сравнения двух объектов. interface IComparer { int Compare(object o1, object o2); } В отличие от IComparable, интерфейс IComparer обычно реализуют не с помощью типов, которые предполагается сортировать (в данном случае это типы Car), а с помощью некоторого набора вспомогательных классов, по одному для каждого порядка сортировки (petName, ID и т.д.). Тип Car (автомобиль) уже "знает", как сравнивать себя с другими автомобилями на основе внутреннего идентификатора ID. Чтобы позволить пользователю объекта отсортировать массив типов Car по значению petName, нам потребуется вспомогательный класс, реализующий IComparer. Вот подходящий для этого программный код. // Этот вспомогательный класс используется для сортировки // массива объектов Car по названию. using System.Collections; public class PetNameComparer : IComparer { public PetNameComparer() {} // Проверка названий объектов. int IComраrer.Compare(object o1, object o2) { Car t1 = (Car)о1; Car t2 = (Car)o2; return String.Compare (t1.petName, t2.petName); } } Этот вспомогательный класс можно использовать в программном коде пользователя объекта. Класс System.Array предлагает перегруженный метод Sort(), один из вариантов которого допускает использование объекта, реализующего интерфейс IComparer (рис. 7.11). static void Main (string[] args) { … // Теперь сортируем по имени. Array.Sort(myAutos, new РеtNameComparer()); // Вывод отсортированного массива. Consolе.WriteLine("\nУпорядочение по названию"); foreach(Car e in myAutos) Console.WriteLine("{0} {1}", c.ID, c.petName); … } 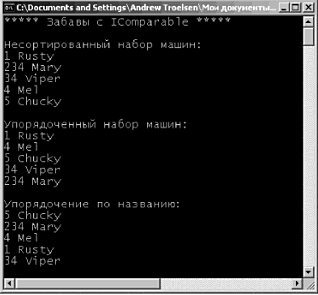 Рис. 7.11. Сортировка автомобилей по названию Типы, определяющие сортировку, и пользовательские свойства Следует отметить, что с помощью пользовательских статических свойств вы можете помочь пользователю объекта отсортировать типы Car по заданному элементу данных. Предположим, что в класс Car добавлено статическое свойство SortByPetName(), доступное только для чтения и возвращающее экземпляр объекта, реализующего интерфейс IComparer (в данном случае это PetNameComparer). // Здесь обеспечивается поддержка пользовательского свойства для // возвращения "правильного" интерфейса IComparer. public class Car: IComparable { … // Свойство, возвращающее компаратор SortByPetName. public static IComparer SortByPetName { get { return (IComparer)new PetNameComparer(); } } } В программном коде пользователя объекта теперь можно выполнить сортировку по названию, используя ассоциированное свойство без какого бы то ни было "упоминания" специального типа класса PetNameComparer:
Array.Sort(myAutos, Car.SortByPetName); Исходный код. Проект ComparableCar размещен в подкаталоге, соответствующем главе 7. Теперь вы должны понимать не только то, как определяются и реализуются типы интерфейса, но и то, в чем их польза. Будьте уверены, интерфейсы можно обнаружить в любом из главных пространств имен .NET и в завершение этой главы мы рассмотрим примеры интерфейсов (и базовых классов) из пространства имен System.Collections. Интерфейсы из пространства имен System.Collections В качестве самого примитивного контейнера может выступать тип System.Array. В главе 3 было показано, что класс System.Array предлагает целый ряд соответствующих возможностей (таких, как инвертирование, сортировка, очистка и перечисление). Но класс Array имеет свои ограничения, и наиболее важным из них является невозможность динамического переопределения размеров при добавлении и удалении элементов. Если для хранения типов необходим более "гибкий" контейнер, лучше использовать типы, определенные в пространстве имен System.Collections (или, в соответствии с рекомендациями главы 10, из пространства имен System.Collections.Generic). Пространство имен System.Collections определяет целый ряд интерфейсов (и некоторые из них уже использовались в примерах этой главы). Как правило, коллекции классов реализует эти интерфейсы для того, чтобы обеспечить доступ к своему содержимому. В табл. 7.2. приводятся описания основных интерфейсов, относящихся к коллекциям. Таблица 7.2. Интерфейсы System.Collections
Многие из этих интерфейсов связаны иерархией интерфейсов, в то время как другие являются автономными единицами. На рис. 7.12 показана схема взаимосвязей между указанными типами (напомним, что один интерфейс может быть производным от нескольких интерфейсов). 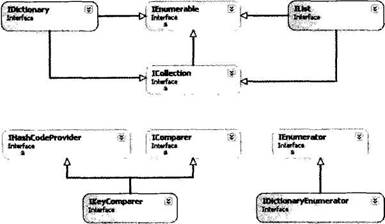 Рис. 7.12. Иерархия интерфейсов System.Collections Интерфейс ICollection Интерфейс ICollection является простейшим интерфейсом пространства имен System.Collections в том смысле, что этот интерфейс определяет поведение, поддерживаемое любым типом коллекции. По сути, этот интерфейс обеспечивает узкий набор свойств, которые позволяют определить: а) число элементов в контейнере; б) защищенность цепочки контейнера; в) возможность копирования содержимого в тип System.Array. Формально ICollection определяется так, как показано ниже (обратите внимание на то, что ICollection расширяет IEnumerable). public interface ICollection : IEnumerable { // Член IEnumerable.… int Count { get; } bool IsSynchronized { get; } object SyncRoot { get; } void CopyTo(Array array, int index); } Интерфейс IDictionary Вы, возможно, знаете, что словарь - это коллекция, обеспечивающая поддержку пар имен и их значений. Например, можно построить пользовательский тип, реализующий IDictionary, в котором вы сможете сохранить типы Car (значения) с возможностью их последующего восстановления по ID или petName (это примеры имен). Интерфейс IDictionary определяет свойства Keys и Values, а также методы Add(), Remove() и Contains(). Отдельные элементы можно получить c помощью индексатора типа. Вот формальное определение. public interface IDictionary : ICollection, IEnumerable { bool IsFixedSize { get; } bool IsReadOnly { get; } object this [object key] { get; set; } ICollection Keys { get; } ICollection Values { get; } void Add(object key, object value); void Clear(); bool Contains(Object key); IDictionaryEnumerator GetEnumerator(); void Remove(object key); } Интерфейс IDictionaryEnumerator При внимательном чтении вы могли заметить, что IDictionary.GetEnumerator() возвращает экземпляр IDictionaryEnumerator. Тип IDictionaryEnumerator – это строго типизованный нумератор, расширяющий IEnumerator путем добавления следующей функциональной возможности. public interface IDictionaryEnumerator : IEnumerator { // Методы IEnumerator… DictionaryEntry Entry { get; } object Key { get; } object Value { get; } } Обратите внимание на то, что IDictionaryEnumerator обеспечивает возможность перечисления элементов словаря с помощью общего свойства Entry, которое возвращает тип класса System.Collections.DictionaryEntry. Кроме того, вы можете выполнить цикл по парам имен и значений, используя свойства Key/Value. Интерфейс IList Последним из ключевых интерфейсов System.Collections является интерфейс IList, который обеспечивает возможность вставки, удаления и индексирования элементов контейнера. public interface IList : ICollection, IEnumerable { bool IsFixedSize { get; } bool IsReadOnly { get; } object this[int index] { get; set; } int Add(object value); void Clear(); bool Contains(object value); int IndexOf(object value); void Insert(int index, object value); void Remove(object value); void RemoveAt(int index); } Классы из пространства имен System.Collections Еще раз подчеркнем, что интерфейсы остаются бесполезными до тех пор, пока они не реализованы соответствующим классом или соответствующей структурой. В табл. 7.3 предлагаются описания основных классов из пространства имен System.Collections вместе с ключевыми интерфейсами, которые этими классами поддерживаются. Таблица 7.3. Классы System.Collections
Вдобавок к этим ключевым типам в System.Collections определяются некоторые менее значительные (в смысле частоты использования) "игроки", такие как BitArray, CaseInsensitiveComparer и CaseInsensitiveHashCodeProvider. Кроме того, это пространство имен определяет небольшой набор абстрактных базовых классов (CollectionBase, ReadOnlyCollectionBase и DictionaryBase), которые могут использоваться для построения строго типизованных контейнеров. Экспериментируя с типами System.Collections, вы обнаружите, что все они "стремятся" использовать общие функциональные возможности (в этом и заключается суть программирования на основе интерфейсов). Поэтому вместо описания всех членов каждого класса коллекции задачей нашего обсуждения будет демонстрация возможностей взаимодействия с тремя главными типами коллекций - ArrayList. Queue and Stack. Освоив функциональные возможности этих типов, вы без особого труда сможете прийти к пониманию и остальных классов коллекций (особенно если учесть что в файлах справки предлагается исчерпывающая документация для каждого из типов). Работа с типом ArrayList Тип ArrayList непременно станет для вас наиболее часто используемым типом пространства имей System.Collections, поскольку он позволяет динамически переопределять размеры содержимого. Для иллюстрации базовых возможностей этого типа предлагаем вам рассмотреть следующий программный код, в котором ArrayList используется для манипуляций с набором объектов Car. static void Main(string[] args) { // Создание ArrayList и заполнение исходными значениями. ArrayList carArList = new ArrayList(); carArList.AddRange(new Car[] {new Car("Fred", 90, 10), new Car("Mary", 100, 50), new Car("MB", 190, 11)}); Console.WriteLine("\nЭлементов в carArList: {0}", carArList.Count); // Печать текущих значений. foreach(Car с in carArList) Console.WriteLine("Имя автомобиля: {0}", c.petName); // Вставка нового элемента. Console.WriteLine("\n-›Добавление нового Car."); carArList.Insert(2, new Car("TheNewCar", 0, 12)); Console.WriteLine("Элементов в carArList: {0}", carArList.Count); // Получение массива объектов из ArrayList и снова печать. object[] arrayOfCars = carArList.ToArray(); for (int i = 0; i ‹ arrayOfCar.Length; i++) { Console.WriteLine("Имя автомобиля: {0}", ((Car) arrayOfCars[i]).petName); } } Здесь для добавления в коллекцию ArrayList набора типов Car используется метод AddRange() (который, по сути, заменяет n-кратный вызов метода Add()). После вывода информации о числе элементов в коллекции (и после цикла по всем элементам для получения имен) вызывается метод Insert(). Как видите, Insert() позволяет осуществить вставку нового элемента в заданную позицию ArrayList. Обратите внимание на вызов метода ToArray(), который возвращает общий массив типов System.Object на основе содержимого оригинального ArrayList. На рис. 7.13 показан соответствующий вывод. 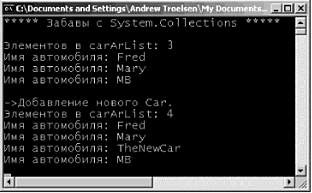 Рис. 7.13. Забавы с System.Collections.ArrayList Работа с типом Queue Тип Queue (очередь) – это контейнер, гарантирующий размещение элементов по правилу "первым прибыл – первым обслужен". К сожалению, люди сталкиваются с очередями повсеместно: очереди в банке, кинотеатре, по утрам к автомату, продающему кофе, и т.д. При моделировании сценариев, в которых элементы обрабатываются по правилу очереди, на помощь приходит System.Collections.Queue. Вдобавок к функциональным возможностям, обеспечиваемым поддерживаемыми интерфейсами, Queue определяет ряд членов, описанных в табл. 7.4. Таблица 7.4. Члены типа Queue
Чтобы проиллюстрировать возможности этих методов, снова используем нашу автомобильную тему и построим объект Queue, моделирующий очередь автомобилей перед въездом на мойку. Во-первых, предположим, что у нас есть следующий вспомогательный статический метод. public static void WashCar(Car с) { Console.WriteLine("Моется {0}", с.petName); } Теперь рассмотрим следующий программный код. static void Main(string[] args) { … // Создание очереди с тремя элементами. Queue carWashQ = new Queue(); carWashQ.Enqueue(new Car ("Первая", 0, 1)); carWashQ.Enqueue(new Car("Вторая", 0, 2)); carWashQ.Enqueue(new Car("Третья", 0, 3)); // Первая машина в очереди. Console.WriteLine("Первой в очереди является {0}", ((Сar)сarWashQ.Peek()).petName); // Удаление всех элементов из очереди. WashCar((Car)carWashQ.Dequeue()); WashCar((Car)carWashQ.Dequeue()); WashCar((Car)carWashQ.Dequeue()); // Попытаемся удалить снова? try {WashCar((Car)carWashQ.Dequeue());} catch(Exception е) { Console.WriteLine("Ошибка: {0}", e.Message);} } Здесь в тип Queue с помощью метода Enqueue() вставляются три элемента. Вызов Реек() позволяет проверить, (но не удалить) первый элемент в текущем состоянии Queue, и таким элементом в данном случае является машина с именем Первая. Наконец, с помощью Dequeue() элемент из очереди удаляется и посылается во вспомогательную функцию WashСar() для обработки. Обратите внимание на то, что при попытке удаления элемента из пустой очереди среда выполнения генерирует исключение. Работа с типом Stack Тип System.Collections.Stack представляет коллекцию, в которой элементы размещаются по правилу "последним прибыл – первым обслужен". Как и следует ожидать, Stack определяет члены с именами Push() и Pop() (для добавления элементов в стек и удаления их из стека). В следующем примере стека используется стандартный тип System.String. static void Main(string[] args) { … Stack stringStack = new Stack(); stringStack.Push("Первый"); stringStack.Push("Второй"); stringStack.Push("Третий"); // Смотрим на первый элемент, удаляем его и смотрим снова. Console.WriteLine("Первый элемент: {0}", stringStack.Peek()); Console.WriteLine("Удален {0}", stringStack.Pop()); Console.WriteLine("Первый элемент: {0}", stringStack.Peek()); Console.WriteLine("Удален {0}", stringStack.Pop()); Console.WriteLine("Первый элемент: {0}", stringStack.Peek()); Console.WriteLine("Удален {0}", stringStack.Pop()); try { Console.WriteLine("Первый элемент: {0}", stringStack.Peek()); Console.WriteLine ("Удален {0}", stringStack.Pop()); } catch(Exception e) {Console.WriteLine("Ошибка: {0}", e.Message);} } Здесь строится стек, содержащий три строковых типа (названных в соответствии с порядком их вставки). "Заглядывая" в стек, вы видите элемент, находящийся на вершине стека, поэтому первый вызов Peek() выявляет третью строку. После серии вызовов Pop() и Peek() стек, в конечном счете, опустошается, и тогда дополнительный вызов Peek()/Pop() приводит к генерированию системного исключения. Исходный код. Проект CollectionTypes размещен в подкаталоге, соответствующем главе 7. Пространство имен System.Collections.Specialized Кроме типов, определенных в пространстве имен System.Collections, библиотеки базовых классов .NET предлагают набор более специализированных типов, определенных в пространстве имен System.Collections.Specialized. Например, типы StringDictionary и ListDictionary обеспечивают "стилизованную" реализацию интерфейса IDictionary. Описания основных типов класса из этого пространства имен предлагаются в табл. 7.5. Таблица 7.5. Типы пространства имен System.Collections.Specialized.
Резюме Интерфейс можно определить, как именованную коллекцию абстрактных членов. Ввиду того, что интерфейс не предлагает деталей реализаций, он обычно рассматривается, как, вариант поведения, возможного для данного типа. При реализации одного и того же интерфейса в нескольких классах вы получаете возможность обращаться с соответствующими типами одинаково (это называется интерфейсным полиморфизмом). Для определения новых интерфейсов в C# предлагается ключевое слово interface. Любой тип может поддерживать столько интерфейсов, сколько необходимо, нужно только указать их в списке определения типа, разделяя запятыми. При этом можно создавать интерфейсы, которые оказываются производными нескольких базовых интерфейсов. Помимо возможности создания пользовательских интерфейсов, вы имеете возможность использовать ряд стандартных интерфейсов, определенных в библиотеках .NET (т.е. предлагаемых каркасом приложений). Вы можете строить пользовательские типы, реализующие эти встроенные интерфейсы, чтобы обеспечить выполнение ряда стандартных действий, таких как клонирование, сортировка или перечисление. Наконец, в этой главе вы узнали о классах коллекций, определенных в пространстве имен System.Collections, и изучили ряд общих интерфейсов, которые используются связанными с коллекциями типами. ГЛАВА 8. Интерфейсы обратного вызова, делегаты и события До этого момента в нашей книге в каждом примере приложении программный код Main() тем или иным способом направлял запросы соответствующим объектам. Но мы пока что не рассматривали возможность обратного обращения объекта к вызывающей стороне. В большинстве программ типичным для объектов системы оказывается двухсторонняя коммуникация, которая реализуется с помощью интерфейсов обратного вызова, событий и других программных конструкций. Эта глава начинается с рассмотрения того, как с помощью типов интерфейса реализовать функциональные возможности обратного вызова. Затем вы узнаете о типе делегата .NET, который является объектом, обеспечивающим типовую безопасность и "указывающим" на метод или методы, которые могут быть вызваны позднее. Но, в отличие от традиционного указателя на функцию в C++, делегаты .NET представляют собой объекты, которые имеют встроенную поддержку многоадресного и асинхронного вызова методов. Мы рассмотрим асинхронное поведение типов делегата позже, при изучении пространства имен System.Threading (см. главу 14). Выяснив, как создавать типы делегата и работать с ними, мы с вами рассмотрим ключевое слово C# event, которое призвано упростить и ускорить работу с типами делегата. Наконец, в этой главе будут рассмотрены новые возможности языка C#, связанные с использованием делегатов и событий, включая анонимные методы и групповые преобразования методов, Вы увидите, что указанный подход открывает более короткий путь к целевым объектам соответствующих событий. Интерфейсы обратного вызова При рассмотрении материала предыдущей главы вы имели возможность убедиться, что интерфейсы определяют доведение, которое может поддерживаться самыми разными типами. Кроме использований интерфейсов для поддержки полиморфизма, их можно использовать и в качестве механизма обратного вызова. Соответствующий подход дает объектам возможность осуществлять двухсторонний обмен, используя общее множество членов. Чтобы показать варианты использования интерфейсов обратного вызова, мы изменим уже знакомый нам тип Car так, чтобы он мог информировать вызывающую сторону о приближении поломки машины (т.е. о том, что текущая скорость на 10 км/ч ниже максимальной скорости) и о свершившейся поломке (когда текущая скорость равна или выше максимальной скорости). Способность посылать и принимать соответствующие события будет реализована с помощью интерфейса, носящего имя IEngineEvents. // Интерфейс обратного вызова. public interface IEngineEvents { void AboutToBlow(string msg); void Exploded (string msg); } Интерфейсы событий обычно реализуются не объектом, непосредственно "заинтересованным" в получении событий, а некоторым вспомогательным объектом, который называется объектом-приемником. Отправитель событий (в данном случае это тип Car) при определенных условиях выполняет для приемника соответствующие вызовы. Предположим, что класс приемника называется CarEventSink, и он просто выводит поступающие сообщения на консоль. Кроме того, наш приемник содержит строку, в которой указано его информативное имя. // Приемник событий Car. public class CarEventSink: IEngineEvents { private string name; public CarEventSink(){} public CarEventSink(string sinkName) { name = sinkName; } public void AboutToBlow(string msg) { Console.WriteLine("{0} сообщает: {1}", name, msg); } public void Exploded(string msg) { Console.WriteLine(" {0} сообщает: {1}", name, msg); } } Теперь, когда у нас есть объект-приемник, реализующий интерфейс событий, нашей следующей задачей является передача ссылки на этот приемник в тип Car. Тип Car будет хранить эту ссылку и при необходимости выполнять обратные вызовы приемника. Чтобы тип Car мог получить ссылку на приемник, нужно добавить в тип Car вспомогательный член, который мы назовем Advise(). Точно так же. если вызывающая сторона пожелает отменить привязку к источнику событий, она может вызвать другой вспомогательный метод типа Car – метод Unadvise(). Наконец, чтобы позволить вызывающей стороне регистрировать множество приемников событий (с целью групповой адресации), тип Car поддерживает ArrayList для представления исходящих соединений. // Тип Car и вызывающая сторона могут связываться // с помощью интерфейса IEngineEvents. public class Car { // Набор связанных приемников. ArrayList clientSinks = new ArrayList(); // Присоединение к источнику событий или отсоединение от него. public void Advise(IEngineEvents sink) {clientSinks.Add(sink);} public void Unadvise(IEngineEvents sink) {clientSinks.Remove(sink);} … } Чтобы на самом деде посылать события, мы обновим метод Car.Accelerate() так, чтобы он осуществлял "проход" по соединениям, указанным в ArrayList, и при необходимости выдавал подходящее сообщение (обратите внимание на то, что теперь в классе Car есть член-переменная carIsDead логического типа для представления состояния двигателя машины). // Протокол событий на базе интерфейса. class Car { … // Эта машина работает или нет? bool carIsDead; public void Accelerate(int delta) { // Если машина 'сломалась', отправить событие Exploded // каждому приемнику. if (carIsDead) { foreach(IEngineEvents e in clientSinks) e.Exploded("Извините, машина сломалась…"); } else { currSpeed += delta; // Отправка события AboutToBlow. if (10 == maxSpeed – currSpeed) { foreach(IEngineEvents e in clientSinks) е.AboutToBlow("Осторожно! Могу сломаться!"); } if (currSpeed ›= maxSpeed) carIsDead = true; else Console.WriteLine(" \tCurrSpeed = {0} ", currSpeed); } } } Вот подходящий программный код клиента, в котором используется интерфейс обратного вызова для отслеживания событий Car.
public class CarApp { static void Main(string[] args) { Console.WriteLine("*** Интерфейсы и контроль событий ***"); Car cl = new Car("SlugBug", 100, 10); // Создание объекта-приемника. CarEventSink sink = new CarEventSink(); // Передача Car ссылки на приемник. cl.Advise(sink); // Ускорение (вызывает наступление событий). for (int i = 0; i ‹ 10; i++) cl.Accelerate(20); // Разрыв связи с источником событий. cl.Unadvise(sink); Console.ReadLine(); } } На рис. 8.1 показан конечный результат работы этого основанного на интерфейсе протокола событий. 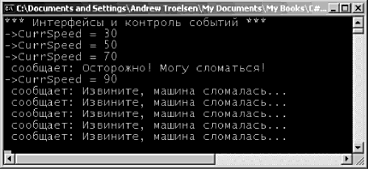 Рис. 8.1. Основанный на интерфейсе протокол событий Обратите внимание на то, что метод Unadvise() позволяет вызывающей стороне селективно отключаться от источника событий. Здесь перед выходом из Main() вызывается Unadvise(), хотя, строго говоря, это и не обязательно. Но предположим, что приложение должно зарегистрировать два приемника, динамически отключить их по очереди в процессе выполнения, а затем продолжить работу. static void Main(string[] args) { Console.WriteLine("***** Интерфейсы и контроль событий *****"); Car cl = new Car("SlugBug", 100, 10); // Создание двух объектов. Console.WriteLine("***** Создание приемников *****"); CarEventSink sink = new CarEventSink("Первый приемник"); CarEventSink myOtherSink = new CarEventSink("Второй приемник"); // Передача приемников объекту Car. Console.WriteLine("\n***** Отправка приемников в Car *****"); cl.Advise(sink); cl.Advise(myOtherSink); // Ускорение (при этом генерируются события). Console.WriteLine("\n***** Ускорение *****"); for (int i = 0; i ‹ 10; i++) cl.Accelerate(20); // Отключение первого приемника событий. Console.WriteLine("\n***** Отключение первого приемника *****"); cl.Unadvise(sink); // Новое ускорение (теперь вызывается только myOtherSink). Console.WriteLine("\n***** Снова ускорение *****); for(int i = 0; i ‹ 10; i++) cl.Accelerate(20); // Отключение второго приемника событий. Console.WriteLine("\n***** Отключение второго приемника *****"); Console.ReadLine(); } Интерфейсы событий могут быть полезны и тем, что они могут использоваться с любыми языками и любыми платформами (.NET, J2EE или какими-то иными), поддерживающими программирование на основе интерфейсов. Однако "официальный" протокол событий задает платформа .NET. Чтобы понять внутреннюю архитектуру обработки событий, мы начнем с обсуждения роли типа делегата. Исходный код. Проект EventInterface размещен в подкаталоге, соответствующем главе 8. Тип делегата .NET Перед тем как дать формальное определение делегата .NET, давайте обсудим соответствующие перспективы. В Windows API для создания объектов, называемых функциями обратного вызова, предполагается использовать указатели функций (подобные указателям C). Используя обратный вызов, программисты могут создавать функции, возвращающие информацию другим функциям в приложении в ответ на их вызов. Проблема стандартных функций обратного вызова, подобных C, заключается в том, что такие функции, по сути, мало отличаются от простой ссылки на адрес в памяти. В идеале функции обратного вызова могли бы содержать дополнительную обеспечивающую безопасность информацию о числе (и типах) параметров и возвращаемом значении для соответствующего метода. К сожалению, для традиционных функций обратного вызова это не так, и, как вы можете догадаться, (именно это часто оказывается причиной дефектов, которые проявляются в среде выполнения и которые трудно устранить. Тем не менее, возможность обратного вызова является полезной. В .NET Framework обратный вызов поддерживается» и соответствующие функциональные возможности реализуются с помощью более безопасных методов делегата, что обеспечивает более совершенный объектно-ориентированный подход. В сущности, делегат - это обеспечивающий типовую безопасность объект, указывающий на другой метод или, возможно, несколько методов в приложении, которые могут быть вызваны с помощью делегата позже. Точнее, тип делегата хранит три следующих элемента информации: • имя метода, к которому должен обращаться вызов; • аргументы метода (если таковые имеются); • возвращаемое значение метода (если таковое предполагается). Замечание. В отличие от указателей функций C(++), делегаты .NET могут указывать на статические методы и на методы экземпляра. После создания делегата и получения вышеуказанной информации делегат может динамически в среде выполнения вызывать методы, на которые он указывает. Вы убедитесь, что в .NET Framework каждый делегат .NET (в том числе и ваши пользовательские делегаты) автоматически наделяется способностью вызывать свои методы синхронно или асинхронно. Это очень упрощает задачи программирования, поскольку позволяет вызвать метод во вторичном потоке выполнения без явного создания объекта Thread и управления им вручную. Мы рассмотрим асинхронное поведение типов делегата в ходе нашего исследования пространства имен System.Threading в главе 14. Определение делегата в C# Чтобы создать делегат в C#, вы должны использовать ключевое слово delegate. Имя делегата может быть любым. Однако делегат должен соответствовать методу, на который этот делегат будет указывать. Предположим, например, что нам нужно создать делегат с именем BinaryOp, который сможет указывать на любой метод, возвращающий целое число и имеющий целочисленные входные параметры. // Этот делегат может указывать на любой метод, // принимающий два целых значения // и возвращающий целое значение. public delegate int BinaryOp(int x, int y); При обработке типов делегата компилятор C# автоматически генерирует изолированный класс, являющийся производным от System.MulticastDelegate. Этот класс (вместе с базовым классом System.Delegate) обеспечивает делегату необходимую инфраструктуру, позволяющую поддерживать список методов, которые должны быть вызваны позднее. Например, если рассмотреть содержимое делегата BinaryOp с помощью ildasm.exe, вы увидите элементы, показанные на рис. 8.2. 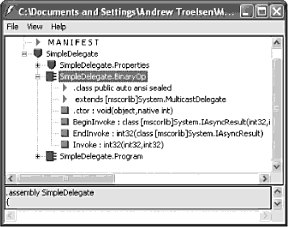 Рис. 8.2. Ключевое слово delegate в C# представляет изолированный тип, производный от System.MulticastDelegate Как видите, генерируемый здесь класс BinaryOp определяет три открытых метода. Метод Invoke() можно назвать главным, поскольку он используется для синхронного вызова методов, поддерживаемых типом делегата, и синхронность здесь означает то, что вызывающая сторона для продолжения работы должна ожидать завершения вызова. Весьма странным кажется тот факт, что синхронный метод Invoke() в C# нельзя вызвать непосредственно. Чуть позже будет продемонстрировано, как Invoke() вызывается опосредованно с помощью соответствующей синтаксической конструкции. Методы BeginInvoke() и EndInvoke() обеспечивает возможность асинхронного вызова текущего метода во вторичном потоке выполнения. Если у вас есть опыт работы с многопоточными приложениями, вы должны знать, что одной из главных причин, по которым разработчики создают вторичные потоки, является вызов методов, для выполнения которых требуется много времени. И хотя библиотеки базовых классов .NET предлагают целое пространство имен (System.Threading), специально предназначенное для решения задач многопоточного программирования, с помощью делегатов соответствующие функциональные возможности использовать проще. Но откуда компилятор "знает", как определять методы Invoke(), BeginInvoke() и EndInvoke()? Чтобы понять суть процесса, рассмотрим пример автоматически генерируемого типа класса BinаrуОр (полужирным шрифтом здесь обозначены элементы, заданные определяемым типом делегата). sealed class BinaryOp: System.MulticastDelegate { public BinaryOp(object target, uint functionAddress); public void Invoke(int x, int y); public IAsyncResult BeginInvoke(int x, int y, AsyncCallback cb, object state); public int EndInvoke(IAsyncResult result); } Во-первых, обратите внимание на то, что параметры и возвращаемое значение определяемого здесь метода Invoke() соответствуют определению делегата BinaryOp. Первые параметры членов BeginInvoke() (в данном случае это два целых числа) тоже соответствуют определению делегата BinaryOp, однако BeginInvoke() всегда имеет еще два параметра (типа AsyncCallback и object), которые используются для асинхронного вызова методов. Наконец, возвращаемое значение метода EndInvoke() тоже соответствует исходной декларации делегата, а единственным параметром метода является объект, реализующий интерфейс IAsyncResult. Рассмотрим еще один пример. Предположим, что мы определили тип делегата, который позволяет указать на любой метод, возвращающий строку и имеющий три входных параметра System.Boolean. public delegate string MyDelegate(bool a, bool b, bool c); На этот раз автоматически генерируемый класс выглядит так. sealed class MyDelegate : System.MulticastDelegate { public MyDelegate(object target, uint functionAddress); public string Invoke(bool a, bool b, bool c); public IAsyncResult BeginInvoke(bool a, bool b, bool c, AsyncCallback cb, object state); public string Endlnvoke(IAsyncResult result); } Делегаты могут также "указывать" на методы, содержащие любое число параметров out или ref. В качестве примера рассмотрим следующий тип делегата. public delegate string MyOtherDelegate(out bool a, ref bool b, int c); Сигнатуры методов Invoke() и BeginInvoke() выглядят так, как и ожидается, но обратите внимание на метод EndInvoke(), который теперь включает и все аргументы out/ref, определенные типом делегата. sealed class MyOtherDelegate : System.MulticastDelegate { public MyOtherDelegate (object target, uint functionAddress); public string Invoke(out bool a, ref bool b, int c); public IAsyncResult BeginInvoke(out bool a, ref bool b, int c, AsyncCallback cb, object state); public string EndInvoke(out bool a, ref bool b, IAsyncResult result); } Итак, в результате определения делегата в C# компилятор генерирует изолированный класс с тремя методами, для которых возвращаемые значения и типы параметров соответствуют декларации делегата. Следующий псевдокод приближенно описывает соответствующий базовый шаблон. // Это только псевдокод! public sealed class ИмяДелегата : System.MulticastDelegate { public ИмяДелегата(object target, uint functionAddress); public возвращаемоеЗначениеДелегата Invoke(всеПараметрыДелегата); public IAsyncResult BeginInvoke(всеПараметрыДелегата, AsyncCallback cb, object state); public возвращаемоеЗначениеДелегата EndInvoke(всеПараметрыRefOutДелегата, IAsyncResult result); } Базовые классы System.MulticastDelegate и System.Delegate Таким образом, при создании типов c помощью) ключевого слова delegate в C# вы неявно объявляете тип класса, являющегося производным от System.MulticastDelegate. Этот класс обеспечивает своим потомкам доступ к списку с адресами тех методов, которые поддерживаются типом делегата, а также предлагает несколько дополнительных методов (и ряд перегруженных операций), обеспечивающих взаимодействие со списком вызовов. Вот программный код некоторых членов System.MulticastDelegate. [Serializable] public abstract class MulticastDelegate: Delegate { // Методы public sealed override Delegate[] GetInvocationList(); public static bool operator==(MulticastDelegate d1, MulticastDelegate d2); public static bool operator!=(MulticastDelegate d1, MulticastDelegate d2); // Поля private IntPtr _invocationCount; private object _invocationList; } Дополнительные функциональные возможности System.MulticastDelegate получает от своего родительского класса System.Delegate. Вот часть определения этого класса. [Serializable, ClassInterface(ClassInterfaceType.AutoDual)] public abstract class Delegate: ICloneable, ISerializable { // Методы public static Delegate Combine(params Delegate[] delegates); public static Delegate Combine(Delegate a, Delegate b); public static Delegate Remove(Delegate source, Delegate value); public static Delegate RemoveAll(Delegate source, Delegate value); // Перегруженные операции public static bool operator==(Delegate d1, Delegate d2); public static bool operator!=(Delegate d1, Delegate d2); // Свойства public MethodInfo Method {get;} public object Target {get;} } Здесь следует подчеркнуть, что от вас никогда не потребуется непосредственно получать производные этих базовых классов, и вы можете ограничить себя использованием только членов, указанных в табл. 8.1. Таблица 8.1. Избранные члены System.MulticastDelegate и System.Delegate
Простейший пример делегата В начале освоения приемов работы с делегатами у программиста может возникать много вопросов. Поэтому мы начнем с рассмотрения очень простого примера, в котором используется созданный нами тип делегата BinaryOp. Вот программный код, который мы собираемся проанализировать. namespace SimpleDelegate { // Этот делегат может указывать на любой метод, // принимавший два целых значения // и возвращающий целое значение. public delegate int BinaryOp(int x, int y); // Этот класс содержит методы, на которые // будет указывать BinaryOp. public class SimpleMath { public static int Add(int x, int y) {return x + y;} public static int Subtract(int x, int y) {return x – у;} } class Program { static void Main(string[] args) { Console.WriteLine("***** пример делегата *****\n"); // Создание объекта BinaryOp, // "указывающего" на SimpleMath.Add(). BinaryOp b = new BinaryOp(SimpleMath.Add); // Вызов метода Add() с помощью делегата. Console.WriteLine(''10 + 10 равно {0}", b(10, 10)); Console.ReadLine(); } } } Снова обратите внимание на формат делегата BinaryOp, который может указывать на любой метод, принимающий два целых значения и возвращающий целое значение. Итак, мы создали класс с именем SimpleMath, определяющий два статических метода, которые (как неожиданно) соответствуют шаблону, определенному делегатом BinaryOp. Чтобы добавить целевой метод в делегат, нужно просто передать имя этою метода конструктору делегата. Тогда вы сможете вызвать указанный член с помощью синтаксической конструкции, подобной прямому вызову функции. // Здесь на самом деле вызывается Invoke()! Console.WriteLine("10 + 10 is {0}", b(10, 10)); "За кулисами" среда выполнения вызывает сгенерированный компилятором метод Invoke(). Вы можете проверить это сами, если откроете компоновочный блок с помощью ildasm.exe и посмотрите на программный код CIL метода Main(). .method private hidebysig static void Main(string[] args) cil managed { … .locals init ([0] class SimpleDelegate.BinaryOp b) ldftn int32 SimpleDelegate.SimpleMath::Add(int32, int32) … newobj instance void SimpleDelegate.BinaryOp::.ctor(object, native int) stloc.0 ldstr "10 + 10 is {0}" ldloc.0 ldc.i4.s 10 ldc.i4.s 10 callvirt instance int32 SimpleDelegate.BinaryOp::Invoke(int32, int32) … } Напомним, что делегаты .NET (в отличие от указателей функций в C) обеспечивают типовую безопасность. Поэтому, если вы попытаетесь передать делегату метод, "не соответствующий шаблону", вы получите сообщение об ошибке компиляции. Например, предположим, что класс SimpleMath определяет еще один метод, носящий имя SquareNumber(). public class SimpleMath { public static int SquareNumber(int a) { return a * a; } } С учетом того, что делегат BinaryOp может указывать только на методы, принимающие два целых значения и возвращающие целое значение, следующий программный метод оказывается некорректным и компилироваться не будет.
BinaryOp b = new BinaryOp(SimpleMath.SquareNumber); Исследование объекта делегата Добавим в имеющийся пример вспомогательную функцию с именем DisplayDelegateInfo(). Она будет выводить имена методов, поддерживаемых поступающим типом, производным от System.Delegate, а также имя класса, определяющего метод. Для этого мы выполним цикл по элементам массива System.Delegate, возвращенного из GetInvocationList(), вызывая свойства Target и Method для каждого объекта. static void DisplayDelegateInfo(Delegate delObj) { // Вывод имен каждого из элементов // списка вызовов делегата. foreach (Delegate d in delQbj.GetInvocationList()) { Console.WriteLine("Имя метода: {0}", d.Method); Console.WriteLine("Имя типа: {0}", d.Target); } } Если изменить метод Main() так, чтобы он вызывал этот новый вспомогательный метод, то вы увидите вывод, показанный на рис. 8.3. 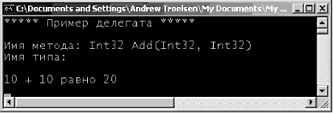 Рис. 8.3. Проверка списка вызовов делегата Обратите внимание на то, что здесь имя типа (SimpleMath) свойством Target не отображается. Причина в том, что наш делегат BinaryOp указывает на статические методы, следовательно, нет объекта, на который нужно ссылаться! Но если изменить методы Add() и Subtract() так, чтобы они перестали быть статическими, можно создать экземпляр типа SimpleMath и указать методы для вызова так, как показано ниже. static void Main(string[] args) { Console.WriteLine("***** Пример делегата *****\n"); // Делегаты .NET могут указывать на методы экземпляра. SimpleMath m = new SimpleMath(); BinaryOp b = new BinaryOp(m.Add); // Вывод информации об объекте. DisplayDelegateInfо(b); Console.WriteLine("\n10 + 10 равно {0}", b(10, 10)); Console.ReadLine(); } Теперь вы должны увидеть вывод, показанный на рис. 8.4. 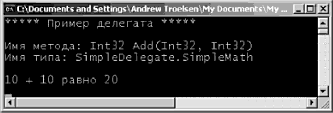 Рис. 8.4. Проверка списка вызовов делегата (новая попытка) Исходный код. Проект SimpleDelegate размещен в подкаталоге, соответствующем главе 8. Модификация типа Car с учетом делегатов Очевидно, что предыдущий пример SimpleDelegate был исключительно иллюстративным, поскольку нет никаких реальных причин строить делегаты для простого сложения двух чисел. Но этот пример раскрывает принципы работы с типами делегата. Для построения более реального примера мы модифицируем тип Car так, чтобы он посылал сообщения Exploded и AboutToBlow через делегаты .NET, a не через пользовательский интерфейс обратного вызова. Кроме отказа от реализации IEngineEvents, мы должны выполнить следующие шаги: • определить делегаты AboutToBlow и Exploded; • объявить члены-переменные всех типов делегата в классе Car; • создать вспомогательные функции Car, которые позволят вызывающей стороне указать методы, поддерживаемые членами-переменными делегатов; • обновить метод Accelerate(), чтобы иметь возможность в подходящей ситуации обратиться к списку вызовов делегата. Рассмотрите следующий обновленный класс Car, в котором решены первые три из указанных задач. public class Car { // Определение типов делегата. public delegate void AboutToBlow(string msg); public delegate void Exploded(string msg); // Определение членов-переменных для каждого из типов. private AboutToBlow almostDeadList; private Exploded explodedList; // Добавление элементов в список вызовов // с помощью вспомогательных методов. public void OnAboutToBlow(AboutToBlow clientMethod) {almostDeadList = clientMethod;} public void OnExploded(Exploded clientMethod) {explodedList = clientMethod;} … } Обратите внимание на то, что в этом примере мы определяем типы делегата непосредственно в рамках типа Car. Если исследовать библиотеки базовых классов, то станет ясно, что определение делегата в рамках типа, с которым он обычно работает, является вполне типичным. В связи с этим, поскольку компилятор преобразует делегат в полное определение класса, мы здесь фактически создаем вложенные классы. Далее обратите внимание на то, что здесь объявлены члены-переменные (по одному для каждого типа делегата) и вспомогательные функции (OnAboutToBlow() и OnExploded()), которые позволят клиенту добавлять методы в списки вызовов делегатов. В принципе эти методы подобны методам Advise() и Unadvise(), которые были нами созданы в примере с EventInterfасе. Но в данном случае входящим параметром оказывается размещаемый клиентом объект делегата, а не класс, реализующий конкретный интерфейс. Здесь мы должны обновить метод Accelerate(), чтобы вызывались делегаты, а не просматривались объекты ArrayList приемников клиента (как это было в примере с EventInterfасе). Подходящая модификация может выглядеть так. public void Accelerate(int delta) { // Если машина 'сломалась', генерируется событие Exploded. if (carIsDead) { if (explodedList != null) explodedList("Извините, машина сломалась…"); } elsе { currSpeed += delta; // Вот-вот сломается? if (10 == maxSpeed – currSpeed && almostDeadList != null) { almostDeadList("Осторожно! Могу сломаться!"); } // Пока все OK! if (currSpeed ›= maxSpeed) carIsDead = true; else Console.WriteLine("CurrSpeed = {0}", currSpeed); } } Обратите внимание на то, что перед вызовом методов, связанных с членами-переменными almostDeadList и explodedList, их значения проверяются на допустимость. Причина в том, что размещение соответствующих объектов с помощью вызова вспомогательных методов OnAboutToBlow() и OnExploded() будет задачей вызывающей стороны. Если вызывающая сторона не вызовет эти методы, а мы попытаемся получить список вызовов делегата, то будет сгенерировано исключение NullReferenseException и в среде выполнения возникнут проблемы (что, конечно же, нежелательно). Теперь, когда инфраструктура делегата имеет нужный нам вид, рассмотрим модификацию класса Program. class Program { static void Main(string[] args) { Console.WriteLine("***** Делегаты и контроль событий *****"); // Обычное создание класса Car. Car cl = new Car("SlugBug", 100, 10); // Регистрация обработчиков событий для типа Car. cl.OnAboutToBlow(new Car.AboutToBlow(CarAboutToBlow)); cl.OnExploded(new Car.Exploded(CarExploded)); // Ускоряемся (при этом генерируются события) . Console.WriteLine("\n***** Ускорение *****"); for(int i = 0; i ‹ 6; i++) cl.Accelerate(20); Console.ReadLine(); } // Car будет вызывать эти методы. public static void CarAboutToBlow(string msg) {Console.WriteLine(msg);} public static void CarExploded(string msg) {Console.WriteLine(msg);} } Здесь следует отметить только то, вызывающая сторона задает значения членам-переменным делегата с помощью вспомогательных методов регистрации. Кроме того, поскольку делегаты AboutToBlow и Exploded вложены в класс Car, при их размещении следует использовать полные имена (например, Car.AboutToBlow). Как любому конструктору, мы передаем конструктору делегата имя метода, который нужно добавить в список вызовов. В данном случае это два статических члена класса Program (если вложить указанные методы в новый класс, это будет очень похоже на тип CarEventSink из примера Event Interface). Реализация групповых вызовов Напомним, что делегаты .NET наделены возможностью группового вызова. Другими словами, объект делегата может поддерживать не один метод, а целый список доступных для вызова методов. Когда требуется добавить в объект делегата несколько методов, используется перегруженная операция +=, а не прямое присваивание. Чтобы разрешить групповой вызов для типа Car, можно обновить методы OnAboutToBlow() и OnExploded() так, как показано ниже. public class Car { // Добавление элемента в список вызовов. public void OnAboutToBlow(AboutToBlow clientMethod) {almostDeadList += clientMethod;} public void OnExploded(Exploded clientMethod) {explodedList += clientMethod;} … } Теперь вызывающая сторона может зарегистрировать несколько целевых объектов. class Program { static void Main(string[] args) { Car c1 = new Car("SlugBug", 100, 10); // Регистрация множества обработчиков событий. c1.OnAboutToBlow(new Car.AboutToBlow(CarAboutToBlow)); c1.OnAboutToBlow(new Car.AboutToBlow(CarlsAlmostDoomed)); c1.OnExploded(new Car.Exploded(CarExploded)); … } // Car будет вызывать эти методы. public static void CarAboutToBlow(string msg) {Console.WriteLine (msg);} public static void CarIsAlmostDoomed(string msg) {Console.WriteLine("Важное сообщение от Car: {0}", msg);} public static void CarExploded(string msg) {Console.WriteLine(msg);} } В программном воде CIL операция += преобразуется в вызов статического метода Delegate.Combine() (можно было бы вызвать Delegate.Combine() непосредственно, но операция += предлагает более простую альтернативу). Взгляните, например, на CIL-представление метода OnAboutToBlow(). .method public hidebysig instance void OnAboutToBlow (class CarDelegate.Car/AboutToBlow clientMethod) cil managed { .maxstack 8 ldarg.0 dup ldfld class CarDelegate.Car/AboutToBlow CarDelegate.Car::almostDeadList ldarg.1 call class [mscorlib]System.Delegate [mscorlib]System.Delegate::Combine(class [mscorlib]System.Delegate, class [mscorlib]System.Delegate) castclass CarDelegate.Car/AboutToBlow stfld class СarDelegate.Car/AboutToBlow CarDelegate.Car::almostDeadList ret } Класс Delegate определяет также статический метод Remove(), который позволит вызывающей стороне динамически удалять элементы из списка вызовов. Легко догадаться, что в C# разработчики могут для этого использовать перегруженную операцию -=. Чтобы предоставить вызывающей стороне возможность не привязываться к обозначениям AboutToBlow и Exploded, можно добавить в тип Car следующие вспомогательные методы (обратите внимание на операцию -=). public class Car { // Удаление элемента из списка вызовов. public void RemoveAboutToBlow(AboutToBlow clientMethod) {almostDeadList -= clientMethod;} public void RemoveExploded(Exploded clientMethod) {explodedList -= clientMethod;} ... } Здесь синтаксис -= тоже выступает в качестве простого сокращения для вызова статического метода Delegate.Remove(), что доказывается следующим программным кодом CIL для члена RemoveAboutToBlow() типа Car. .method public hidebysig instance void RemoveAboutToBlow(class CarDelegate.Car/AboutToBlow clientMethod) cil managed { .maxstack 8 ldarg.0 dup ldfld class CarDelegate.Car/AboutToBlow CarDelegate.Car::almostDeadList ldarg.1 call class [mscorlib]System.Delegate [mscorlib]System.Delegate::Remove(class [mscorlib]System.Delegate, class [mscorlib]System.Delegate) castclass CarDelegate.Car/AboutToBlow stfld class CarDelegate.Car/AboutToBlow CarDelegate.Car::almostDeadList ret } Если вызывающая сторона пожелает удалить элемент из списка вызовов делегата, мы должны предоставить тот же объект делегата, который был ранее добавлен. Поэтому мы можем прекратить выдачу сообщения Exploded, обновив Main() так, как показано ниже. static void Main(string[] args) { Car cl = new Car("SlugBug", 100, 10); // Сохранение объекта Car.Exploded делегата. Car.Exploded d = new Car.Exploded(CarExploded); cl.OnExploded(d); … // Удаление метода CarExploded из списка вызовов. cl.RemoveExploded(d); … } Вывод нашего приложения CarDelegate показан на рис. 8.5. 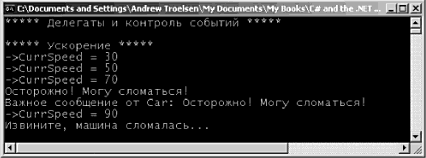 Рис. 8.5. Приложение CarDelegate за работой Исходный код. Проект CarDelegate размещен в подкаталоге, соответствующем главе 8. Более совершенный пример делегата Чтобы продемонстрировать более интересные варианты использования делегатов, мы добавим в класс Car пару членов-переменных логического типа. Первый из добавляемых членов предназначен для индикации того, что автомобиль необходимо помыть (isDirty), а второй будет сообщать о том, что автомобиль требует замены шин (shouldRotate). Чтобы позволить пользователю объекта взаимодействовать с этими новыми данными состояния, для Car определяются необходимые дополнительные свойства и обновляется конструктор. Вот как выглядит соответствующим образом модифицированный программный код. // Обновленный класс Car. public class Car { … // Не пора ли помыть? Не пора ли сменить шины? private bool isDirtу; private bool shouldRotate; // Дополнительные параметры для установки булевых значений. public Car(string name, int maxSp, int currSp, bool washCar, bool rotateTires) { … isDirty = washCar; shouldRotate = rotateTires; } public bool Dirty { get { return isDirty; } set { isDirty = value; } } public bool Rotate { get { return shouldRotate; } set { shouldRotate = value; } } } Также предположим, что в тип Car вложен новый делегат CarDelegate. // Для Car определяется еще один делегат. public class Car { … // Может вызывать любой метод, получающий Car в виде параметра // и не возвращающий ничего. public delegate void CarDelegate(Car с); … } Здесь создается делегат с именем CarDelegate. Тип CarDelegate представляет "некоторую функцию", принимающую Car в качестве параметра и возвращающую пустое значение. Делегаты в качестве параметров Теперь, когда у нас есть новый тип делегата, который указывает на методы, получающие Car в виде параметра и не возвращающие ничего, мы можем создавать функции, которые принимают этот делегат в виде параметра. Для примера предположим, что у нас есть новый класс, которому назначено имя Garage (гараж). Этот тип поддерживает коллекцию типов Car, содержащихся в System.Collections. ArrayList. При создании ArrayList наполняется типами Car. // Класс Garage хранит список типов Car. using System.Collections; … public class Garage { // Создание списка всех машин в гараже. ArrayList theCars = new ArrayList(); // Создание машин в гараже. public Garage() { // Напомним, что конструктор был обновлен, // и теперь можно установить значения isDirty и shouldRotate. theCars.Add(new Car("Viper", 100, 0, true, false)); theCars.Add(new Car("Fred", 100, 0, false, false)); theCars.Add(new Car("BillyBob", 100, 0, false, true)); } } Класс Garage будет определять общедоступный метод ProcessCars(), который в качестве единственного аргумента получит новый тип делегата (Car.CarDelegate). В ProcessCars() каждый объект Car из коллекции будет передаваться в виде параметра "той функции, на которую указывает" делегат. При этом ProcessCars() использует члены Target и Method из System.MulticastDelegate, чтобы определить, на какую из функций делегат указывает в настоящий момент. // Класс Garage имеет метод, использующий CarDelegate. using System.Collections; … public class Garage { … // Этот метод получает Car.CarDelegate в виде параметра. public void ProcessCars(Car.CarDelegate proc) { // Куда направить вызов? Console.WriteLine("***** Вызывается: {0} *****", proc.Method); // Вызывается метод экземпляра или статический метод? if (proc.Target != null) Console.WriteLine("-›Цель: {0} ", proc.Target); else Console.WriteLine("-›Целевым является статический метод"); // Вызов "указанного" метода всех машин по очереди. foreach (Car с in theCars) { Console.WriteLine("\n-› Обработка Car"); proc(c); } } } Как и в случае любого делегата, при вызове ProcessCars() мы должны указать имя метода, который обработает запрос. Напомним, что такой метод может быть или статическим, или методом экземпляра. Для примера предположим, что в качестве такого метода будут использоваться члены экземпляра нового класса ServiceDepartment (отдел технического обслуживании), которым назначены имела WashCar() и RotateTires(). Обратите внимание на то, что эти два метода используют новые свойства Rotate и Dirty типа Car. // Этот класс определяет методы, которые будут вызываться // типом Car.CarDelegate. public class ServiceDepartment { public void WashCar(Car c) { if (c.Dirty) Console.WriteLine("Моем машину"); else Console.WriteLine("Эта машина уже помыта…"); } public void RotateTires(Car с) { if (c.Rotate) Console.WriteLine("Меняем шины"); else Console.WriteLine("Менять шины не требуется…"); } } Теперь проиллюстрируем взаимодействие между новыми типами Car, CarDelegate, Garage и ServiceDepartment, рассмотрев их использование в следующем фрагменте программного кода. // Garage направляет все заказы в ServiceDepartment // (найти хорошего механика всегда проблема…) public class Program { static void Main(string[] args) { // Создание гаража. Garage g = new Garage(); // Создание отделения обслуживания, ServiceDepartment sd = new ServiceDepartment(); // Garage моет машины и меняет шины, // делегируя соответствующие полномочия ServiceDepartment. g.ProcessCars(new Car.CarDelegate(sd.WashCar)); g.ProcessCars(new Car.CarDelegate(sd.RotateTires)); Console.ReadLine(); } } На рис. 8.6 показан соответствующий вывод. 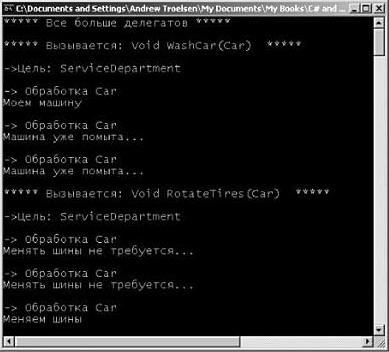 Рис. 8.6. Перекладывание ответственности Анализ программного кода делегирования Предложенный выше метод Main() начинается с создания экземпляров типов Garage и ServiceDepartment. Когда вы пишете
g.ProcessCars(new Car.CarDelegate(sd.WashCar)); это на самом деле означает: "Добавить указатель на метод ServiceDepartment.WashCar() к объекту Car.CarDelegate и передать этот объект в Garage.ProcessCars()". Подобно любому автомобильному предприятию в реальном мире, все заказы передаются в отдел технического обслуживания (что и объясняет, почему замена масла, обычно требующая 30 минут, занимает целых 2 часа). С учетом этого ProcessCars() можно интерпретировать так. // CarDelegate указывает на функцию ServiceDepartment.WashCar. public void ProсessCars(Car.CarDelegate proc) { foreach (Car с in theCars) proc(c); // proc(c) =› ServiceDepartment.WashCar(c) … } Точно так же, если вы говорите // Поменять шины. g.ProcessCars(new Car.CarDelegate(sd.RotateTires)); то ProcessCars() можно интерпретировать, как // CarDelegate указывает на функцию ServiceDepartment.RotateTires. public void ProcessCars(Car.CarDelegate proc) { … foreach(Car с in the Cars) proc(c); //proc(c) =› ServiceDepartment.RotateTires(e) … } Исходный код. Проект CarGarage размещен в подкаталоге, соответствующем главе 8. Ковариантность делегатов К этому моменту вы должны чувствовать себя более уверенно при создании и использовании типов делегата. Перед тем как перейти к изучению синтаксиса событий в C#, мы рассмотрим новую возможность .NET 2.0, связанную с делегатами и обозначенную термином ковариантность. Вы могли обратить внимание на то, что все делегаты, созданные нами до сих пор, указывали на методы, возвращающие простые числовые типы данных (или не возвращающие значений вообще). Но предположим, что нам нужен делегат, способный указывать на методы, возвращающие пользовательский тип класса. // Определение делегата, который позволит указывать на объекты, // возвращающие типы Car. public delegate Car ObtainCarDelegate(); Мы можем определить целевой объект для делегата так, как обычно. class Program { public delegate Car ObtainCarDelegate(); public static Car GetBasicCar() {return new Car();} static void Main(string[] args) { ObtainCarDelegate targetA = new ObtainCarDelegate(GetBasicCar); Car c = targetA(); Console.ReadLine(); } } Пока что все выглядит прекрасно. Но что делать, если мы получим новый класс SportsCar из типа Car и потребуется делегат, который сможет указывать на методы, возвращаемые этим новым типом класса? До появления .NET 2.0 в таком случае вам пришлось бы определить новый делегат. // Новый делегат, указывающий на целевые объекты, // возвращающие типы SportsCar. public delegate SportsCar ObtainSportsCarDelegate(); У нас теперь два типа делегата, и мы должны создать по экземпляру каждого из них, чтобы получить типы Car и SportsCar. class Program { public delegate Car ObtainCarDelegate(); public delegate SportsCar ObtainSportsCarDelegate(); public static Car GetBasicCar() {return new Car(); } public static SportsCar GetSportsCar() {return new SportsCar();} static void Main(string[] args) { ObtainCarDelegate targetA = new ObtainCarDelegate(GetBasicCar); Car с = targetA(); ObtainSportsCarDelegate targetB = new ObtainSportsCarDelegate(GetSportsCar); SportsCar sc = targetB(); Console.ReadLine(); } } По законам классического наследования в идеале лучше иметь один тип делегата, который мог бы указывать на методы, возвращающие либо тип Car, либо тип SportsCar (в конце концов, тип SportsCar связан с Car отношением наследования). Ковариантность позволяет реализовать именно такую возможность, т.е. построить один делегат, способный указывать на методы, возвращающие типы класса, связанные классическим отношением наследования. class Program { // Определение делегата, способного возвращать // как Car, так и SportsCar. public delegate Car ObtainVehicalDelegate(); public static Car GetBasicCar() {return new Car();} public static SportsCar GetSportsCar() { return new SportsCar();} static void Main(string[] args) { Console.WriteLine("***** Ковариантность делегатов *****\n"); ObtainVehicalDelegate targetA = new ObtainVehicalDelegate(GetBasicCar); Car c = targetA(); // Такое присваивание возможно вследствие ковариантности. ObtainVehicalDelegate targetB = new ObtainVehicalDelegate(GetSportsCar); SportsCar sc = (SportsCar)targetB(); Console.ReadLine(); } } Обратите внимание на то, что тип делегата ObtainVehicalDelegate был определен для того, чтобы указывать на методы, возвращающие строго типизованный Car. Однако в условиях ковариантности мы получаем возможность указывать и на методы, возвращающие производные типы. Чтобы получить производный тип, нужно просто выполнить явное преобразование. Замечание. Точно так же ковариантность обеспечивает возможность создания делегата, который позволит указать на множество методов, получающих объекты, связанные классическим отношением наследования. Более подробная информация имеется в документации .NET Framework 2.0 SDK. Исходный код. Проект DelegateCovariance размещен в подкаталоге, соответствующем главе 8. События в C# Делегаты оказываются очень интересными конструкциями с той точки зрения, что они предоставляют возможность реализовать двухстороннее взаимодействие между объектами в памяти. Однако, и вы с этим согласитесь, работа с делегата-ми напрямую предполагает ввод больших по объему шаблонных фрагментов программного кода (определение делегата, объявление членов-переменных, создание пользовательских методов регистрации и отмены регистрации). Поскольку возможность обратного вызови объектов другим объектом является очень полезной, в C# предлагается специальное ключевое слово event, позволяющее минимизировать неудобства программиста, связанные с непосредственным применением делегатов. При обработке ключевого слова event компилятор автоматически создает для вас методы регистрации и отмены регистрации, а также члены-переменные, необходимые для вашего типа делегата. Ключевое слово event Можно назвать синтаксической "конфеткой", позволяющей экономить время при вводе программного кода. Замечание. Даже при использовании в C# ключевого слова event вам все равно придется вручную определять связанные с делегатом типы. Процесс определения события состоит из двух шагов. Во-первых, вы должны определить делегат, который будет содержать методы, вызываемые при наступлении соответствующего события. Затем вы объявляете события (используя ключевое слово C# event) в терминах соответствующего делегата. Определение типа, способного посылать события, имеет следующий шаблон (записанный здесь в псевдокоде). public class SenderOfEvents { public delegate возврЗначение AssociatedDelegate(аргументы); public event AssociatedDelegate ИмяСобытия; … } События типа Car будут иметь те же имена, что и предыдущие делегаты (AboutToBlow и Exploded). Новому делегату, с которым будут ассоциироваться события, будет назначено имя CarEventHandler. Вот начальные изменения, вносимые в определение типа Car. public class Car { // Этот делегат работает в связке с событиями Car public delegate void CarEventHandler(string msg); // Объект Car может посылать эти события. public event CarEventHandler Exploded; public event CarEventHandler AboutToBlow; … } Отправка событий вызывающей стороне выполняется с помощью простого указания имени события и всех обязательных параметров, предусмотренных в определении соответствующего делегата. Вы должны проверить событие на значение null перед тем, как вызывать набор методов делегата, чтобы гарантировать регистрацию события вызывающей стороной. С учетом этого предлагается новый вариант метода Accelerate() для типа Car. public void Accelerate(int delta) { // Если машина сломана, генерируется событие Exploded. if (carIsDead) { if (Exploded!= null) Exploded("Извините, машина сломалась…"); } else { currSpeed += delta; // Вот-вот сломается? if (10 == maxSpeed – currSpeed && AboutToBlow != null) { AboutToBlow ("Осторожно! Могу сломаться!"); } // Пока все OK! if (currSpeed ›= maxSpeed) carIsDead = true; else Console.WriteLine("-›CurrSpeed = {0}", currSpeed); } } Мы наделили автомобиль способностью посылать два типа пользовательских событии, избавив себя от необходимости определять пользовательские функции регистрации. Немного позже мы приведем пример использования нашего нового автомобили, но сначала более подробно рассмотрим архитектуру событий. Глубинный механизм событий Событие в C# представляется двумя скрытыми общедоступными методами, один из которых имеет префикс add_, а другой – префикс remove_. За этими префиксами следует имя события. Например, событие Exploded транслируется в пару CIL-методов с именами add_Exploded() и remove_Exploded(). Кроме приведения к методам add_XXX() и remove_XXX(), определение события на уровне CIL связывает данное событие с соответствующим делегатом. Взгляните на CIL-инструкции для add_AboutToBlow(), и вы обнаружите программный код, почти идентичный программному коду вспомогательного метода OnAboutToBlow() из рассмотренного выше примера CarDelegate (обратите внимание на строку с вызовом Delegate.Combine()). .method public hidebysig specialname instance void add_AboutToBlow(class CarEvents.Car/CarEventHandler 'value') cil managed synchronized { .maxstack 8 ldarg.0 ldarg.0 ldfld class CarEvents.Car/CarEventHandler CarEvents.Car::AboutToBlow ldarg.1 call class [mscorlib]System.Delegate [mscorlib] System.Delegate::Combine(class [mscorlib]System.Delegate, class [mscorlib]System.Delegate) castclass CarEvents.Car/CarEventHandler stfld class CarEvents.Car/CarEventHandler CarEvents.Car::AboutToBlow ret } В соответствии с ожиданиями, метод remove_AboutToBlow() неявно (опосредованно) вызывает Delegate.Remove() и приблизительно соответствует определенному выше вспомогательному методу RemoveAboutToBlow(). .method public hidebysig specialname instance void remove_AboutToBlow(class CarEvents.Car/CarEventHandler 'value') cil managed synchronized { .maxstack 8 ldarg.0 ldarg.0 ldfld class CarEvents.Car/CarEventHandler CarEvents.Car::AboutToBlow ldarg.1 call class [mscorlib]System.Delegate [mscorlib]System.Delegate::Remove(class [mscorlib]System.Delegate, class [mscorlib]System.Delegate) castclass CarEvents.Car/CarEventHandler stfld class CarEvents.Car/CarEventHandler CarEvents.Car::AboutToBlow ret } Наконец, программный код CIL, представляющий само событие, использует директивы .addon и .removeon для отображения имен в соответствующие имена вызываемых методов add_XXX() и remove_XXX(). .event CarEvents.Car/EngineHandler AboutToBlow { .addon void CarEvents.Car::add_AboutToBlow(class CarEvents.Car/CarEngineHandler) .removeon void CarEvents.Car::remove_AboutToBlow(class CarEvents.Car/CarEngineHandler) } Теперь, когда вы знаете, как строить классы, способные посылать события в C# (и знаете о том, что соответствующая событиям синтаксическая конструкция – это просто сокращение, позволяющее уменьшить объем вводимых с клавиатуры данных), мы должны выяснить, как осуществляется "прием" поступающих событий с точки зрения вызывающей стороны. Прием поступающих событий Использование событий в C# позволяет также упростить регистрацию обработчиков событий вызывающей стороны. Вместо необходимости указывать пользовательские вспомогательные методы, вызывающая сторона просто использует операции += и -= (которые в фоновом режиме "подключают" add_XXX() или remove_XXX()). Если вы хотите регистрировать событие, то следуйте показанному ниже шаблону. // ОбъектнаяПеременная.ИмяСобытия += // new СоответствующийДелегат(вызываемаяФункция); Car.EngineHandler d = new Car.EngineHandler(CarExplodedEventHandler) myCar.Exploded += d; Чтобы отменить привязку к источнику событий, используйте операцию -=. // ОбъектнаяПеременная.ИмяСобытия -= объектДелегата; myCar.Exploded -= d; С учетом этих соответствующих ожиданиям шаблонов, вот как должен выглядеть модифицированный метод Main(), в котором используется синтаксис регистрации событий C#. class Program { statiс vоid Main(string[] args) { Console.WriteLine("***** События *****"); Car c1 = new Car("SlugBug", 100, 10); // Регистрация обработчиков событий. сl.AboutToBlow += new Car.CarEventHandler(CarIsAlmostDoomed); cl.AboutToBlow += new Car.CarEventHandler(CarAbautToBlow); Car.CarEventHandler d = new Car.CarEventHandler(CarExploded); cl.Exploded += d; Console.WriteLine("\n***** Ускорение *****); for(int i = 0; i ‹ 6; i++) cl.Accelerate(20); // Удаление метода CarExploded из списка вызовов. cl.Exploded -= d; Console.WriteLine("\n***** Ускорение *****"); for(int i = 0; i ‹ 6; i++) cl.Accelerate(20); Console.ReadLine(); } public static void CarAboutToBlow(string msg) { Console.WriteLine(msg); } public static void CarIsAlmostDoomed(string msg) { Console.WriteLine("Critical Message from Car: {0}", msg); } public static void CarExploded(string msg) { Console.WriteLine(msg); } } Исходный код. Проект CarEvents размещен в подкаталоге, соответствующем главе 8. Упрощенная регистрация событий в Visual Studio 2005 В Visual Studio .NET 2003 и Visual Studio 2005 предлагается помощь в процессе регистрации обработчиков событий. При вводе += в окне программного кода появляется окно IntelliSense, предлагающее назвать клавишу ‹Tab›, чтобы автоматически ввести соответствующий экземпляр делегата (рис. 8.7). 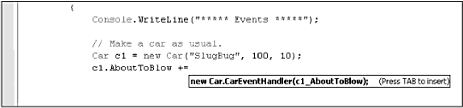 Рис. 8.7. Выбор делегата IntelliSense После нажатия клавиши ‹Tab› будет предложено ввести имя генерируемого обработчика события (или согласиться использовать имя, предлагаемое по умолчанию), как показано на рис. 8.8.  Рис. 8.8. Формат целевого объекта делегата IntelliSense Если снова нажать клавишу ‹Tab›, вы получите программный код "заглушки" в нужном формате целевого объекта делегата (обратите внимание на то, что соответствующий метод объявляется статическим, поскольку событие было зарегистрировано с помощью статического метода). static void cl_AboutToBlow(string msg) { // Add your code! } Эта возможность IntelliSense доступна для всех событий .NET из библиотек базовых классов. Данная особенность интегрированной среды разработки позволяет разработчику существенно экономить время, поскольку избавляет от необходимости искать по справке .NET подходящие делегаты (и выяснять их форматы) для использования их с конкретными событиями. "Разборчивые" события Есть еще одно усовершенствование, которое можно внести в наш пример с CarEvents и которое соответствует шаблону событий, рекомендуемому разработчиками из Microsoft. При исследовании событий, посылаемых данным типом из библиотек базовых классов, вы обнаружите, что первым параметром соответствующего делегата является System.Object, а вторым – тип, производный от System.EventArgs. Аргумент System.Object представляет ссылку на объект, посылающий событие (такой как, например, Car), а второй параметр представляет информацию о соответствующем событии. Базовый класс System.EventArgs представляет событие и не передает никакой пользовательской информации. public class EventArgs { public static readonly System.EventArgs Empty; public EventArgs(); } Для простых событий вы можете просто передать экземпляр EventArgs. Но если вы хотите передать и пользовательские данные, вы должны построить подходящий класс, производный от EventArgs. Для нашего примера мы предположим, что у нас есть класс CarEventArgs, который содержит строку с сообщением, отправляемым получателю. public class CarEventArgs: EventArgs { public readonly string msg; public CarEventArgs(string message) { msg = message; } } Теперь мы должны обновить делегат CarEventHandler так, как показано ниже (события должны остаться без изменений). public class Car { public delegate void CarEventHandler(object sender, CarEventArgs e); … } При генерировании событий из метода Accelerate() мы теперь должны предоставить ссылку на текущий объект Car (с помощью ключевого слова Car) и экземпляр нашего типа CarEventArgs. public void Accelerate(int delta) { // Если машина сломалась, генерируется событие Exploded. if (carIsDead) { if (Exploded != null) Exploded(this, new CarEventArgs("Извините, машина сломалась…")); else { … AboutToBlow(this, new CarEventArgs("Осторожно! Могу сломаться!")); } … } } С точки зрения вызывающей стороны, все, что нам требуется, так это обновление обработчиков событий, чтобы иметь возможность принять поступающие параметры и получить сообщение через доступное только для чтения поле. Например: public static void CarAboutToBlow(object sender, CarEventArgs e) { Console.WriteLine ("{0} сообщает: {1}", sender, e.msg); } Если получатель желает взаимодействовать с объектом, отправившим событие, следует выполнить явное преобразование System.Object. Так, если нужно выключить радио, когда объект Car уже на полпути к своему создателю, можно предложить обработчик событий, который будет выглядеть примерно так. public static void CarIsAlmostDoomed(object sender, CarEventArgs e) { // Просто для гарантии здесь перед вызовом предлагается // проверка среды выполнения. if (sender is Car) { Car с = (Car)sender; c.CrankTunes(false); } Console.WriteLine("Важное сообщение от {0}: {1}", sender, e.msg); } Исходный код. Проект PrimAndProperCarEvenfs размещен в подкаталоге, соответствующем главе 8. Анонимные методы в C# В завершение этой главы мы рассмотрим некоторые связанные с делегатами и событиями возможности .NET 2.0 через призму возможностей C#. Для начала обратим внимание на то, что в случае, когда вызывающей стороне требуется осуществлять прием поступающих событий, необходимо определить уникальный метод, отвечающий виду соответствующего делегата. class SomeCaller { static void Main(string[] args) { SomeType t = new SomeType(); t.SomeEvent += new SomeDelegate(MyEventHandler); } // Как правило, вызывается только объектом SomeDelegate. public static void MyEventHandler() {…} } Если немного подумать, то станет ясно, что такие методы, как MyEventHandler(), редко бывают предназначены для вызова вне вызываемого делегата. А с точки зрения продуктивности слишком непривлекательно (хотя и не запрещено) вручную определять специальные методы, которые вызываются объектом делегата. Чтобы разрешить эту проблему, теперь позволяется ассоциировать делегат непосредственно с блоком операторов программного кода при регистрации события. Формально такой программный код называется анонимным методом. В качестве иллюстрации базового синтаксиса рассмотрите следующий метод Main(), в кото-рам посылаемые типом Car события обрабатываются о помощью анонимных методов, а не специальных именованных программ обработки событий. class Program { static void Main(string[] args) { Console.WriteLine("***** Анонимные методы *****\n"); Car c1 = new Car("SlugBug", 100, 10); // Регистрация обработчиков событий с помощью // анонимных методов. c1.AboutToBlow += delegate { Console.WriteLine("Оx! Едем слишком быстро!"); }; c1.AboutToBlow += delegate(object sender, CarEventArgs e) { Console.WriteLine("Сообщение от Car: {0}", e.msg); }; c1.Exploded += delegate(object sender, CarEventArgs e) { Console.WriteLine("Фатальное сообщение от Car: {0}", e.msg); }; … } } Замечание. После завершающей фигурной скобки анонимного метода должна следовать точка с запятой. Если пропустить точку с запятой, будет получено сообщение об ошибке компиляции. Обратите вниманий на то, что тип Program уже не определяет конкретные статические программы обработки событий, такие как, например, CarAboutToBlow() и CarExploded(). Вместо этого здесь указаны безымянные (т.е. анонимные) методы, определяемые "внутристрочно" в тот момент, когда вызывающая сторона обрабатывает событие, используя синтаксис +=. Базовый синтаксис анонимного метода соответствует следующему представлению в псевдокоде. class SomeCaller { static void Main(string[] args) { SomeType t = new SomeType(); t.SomeEvent += delegate(необязательныеАргументыДелегата) { /* операторы */}; } } В предыдущем варианте метода Main() следует обратить внимание на то, что при обработке первого события AboutToBlow мы не определяем аргументы, передаваемые делегатом. c1.AboutToBlow += delegate { Console.WriteLine("Ox! Едем слишком быстро!"); }; Строго говоря, получать входные аргументы, посылаемые конкретным событием, не обязательно. Но если вы хотите использовать поступающие аргументы, вы должны указать параметры, прототипы которых заданы типом делегата (как это сделано во втором случае обработки событий AboutToBlow и Exploded). Например: c1.AboutToBlow += delegate(object sender, CarEventArgs e) { Console.WriteLine("Важное сообщение от Car: {0}", e.msg); }; Доступ к "внешним" переменным Анонимные методы интересны в том отношении, что они позволяют доступ к локальным переменным определяющего их метода. Формально говоря, такие переменные являются "внешними переменными" анонимного метода. Для примера предположим, что наш метод Main() определяет локальную целую переменную-счетчик с именем aboutToBlowCounter. В рамках анонимных методов, обрабатывающих событие AboutToBlow, мы будем увеличивать этот счетчик на 1 и печатать его значение в конце Main(). static void Main(string[] args) { … int aboutToBlowCounter = 0; // Создание машины. Car c1 = new Car("SlugBug", 100, 10); // Регистрация обработчиков событий в виде анонимных методов. c1.AboutToBlow += delegate { aboutToBlowCounter++; Console.WriteLine("Ox! Едем слишком быстро!"); }; c1.AboutToBlow += delegate(string msg) { aboutToBlowCounter++; Console.WriteLine("Важное сообщение от Car: {0}", msg); }; … Console.WriteLine("Событие AboutToBlow вызывалось {0} раз(а).", aboutToBlowCounter); Console.ReadLine(); } В результате выполнения этого обновленного метода Main() завершающий оператор Console.WriteLine() сообщит вам о том, что событие AboutToBlow генерировалось дважды. Замечание. Анонимный метод не имеет возможности получить доступ к параметрам ref и out определяющего метода. Групповое преобразование методов в C# Еще одной связанной с делегатами и событиями возможностью в C# является так называемое групповое преобразование методов. Эта возможность позволяет регистрировать "просто" имя обработчика событий. Чтобы пояснить это на примере, мы снова рассмотрим тип SimpleMath, уже рассматривавшийся в этой главе выше, но добавим в него новое событие, которому будет назначено имя ComputationFinished. public class SimpleMath { // Здесь мы не утруждаем себя созданием // производного типа System.EventArgs. public delegate void MathMessage(string msg); public event MathMessage ComputationFinished; public int Add(int x, int y) { ComputationFinished("Сложение выполнено."); return х + y; } public int Subtract(int x, int y) { ComputationFinished("Вычитание выполнено."); return x – у; } } Если не использовать синтаксис анонимных методов, то мы должны обработать событие ComputationComplete так, как показано ниже. class Program { static void Main(string[] args) { SimpleMath m = new SimpleMath(); m.ComputationFinished += new SimpleMath.MathMessage(ComputationFinishedHandler); Console.WriteLine("10 + 10 равно {0}", m.Add(10, 10)); Console.ReadLine(); } static void ComputationFinishedHandler(string msg) { Console.WriteLine(msg); } } Но можно зарегистрировать программу обработки событий для конкретного события и так, как показано ниже (в остальном программный код изменений не претерпевает). m.ComputationFinished += ComputationFinishedHandler; Обратите внимание на то, что мы не создаем непосредственно соответствующий тип делегата, а просто указываем метод, который соответствует ожидаемой сигнатуре делегата (в данном случае это метод, не возвращающий ничего и получающий один объект типа System.String). Ясно, что компилятор C# при этом должен обеспечить типовую безопасность. Если метод ComputationFinishedHandler() не получает System.String и не возвращает void, то вы получите сообщение об ошибке компиляции. Можно и явно конвертировать обработчик события в экземпляр соответствующего делегата. Это может оказаться полезным тогда, когда нужно получить соответствующий делегат, использующий заранее определенный метод. Например: // .NET 2.0 допускает преобразование обработчиков событий // в соответствующие делегаты. SimpleMath.MathMessage mmDelegate = (SimpleMath.MathMessage)ComputationFinishedHandler; Console.WriteLine(mmDelegate.Method); Если выполнить этот программный код, то заключительный оператор Console.WriteLine() напечатает сигнатуру ComputationFinishedHandler, как показано на рис. 8.9.  Рис. 8.9. Можно извлечь делегат из соответствующего обработчика события Исходный код. Проект AnonymousMethods размещен в подкаталоге, соответствующем главе 8. Резюме В этой главе был рассмотрен ряд подходов, позволяющих реализовать возможность двухстороннего взаимодействия объектов. Сначала было рассмотрено использование интерфейсов обратного вызова, которые обеспечивают возможность для объекта А вызывать объект В с помощью общего интерфейса. Этот подход не является специфическим для .NET, а может использоваться в любых языках и на любых платформах, допускающих программирование на основе интерфейсов. Затем было рассмотрено ключевое слово C# delegate, которое используется для непрямого построения классов, производных от System.MulticastDelegate. Как выяснилось, делегат представляет собой объект, хранящий список методов, доступных для вызова. При этом вызовы, могут быть синхронными (они выполняются с помощью метода Invoke()) или асинхронными (они выполняются с помощью методов BeginInvoke() и EndInvoke()). Асинхронная природа типов делегата .NET будет рассмотрена позже. Ключевое слово C# event при использовании с типом делегата позволяет упростить процесс отправки сообщений событий вызывающим объектам. Как показывает генерируемый CIL-код, модель событий .NET сводит ситуацию к скрытым вызовам типов System.Delegate/System.MulticastDelegate. В этой связи ключевое слово C# event оказывается необязательным и просто экономит время при наборе текста программы. Новая возможность, появившаяся в C# 2005 и получившая название анонимных методов, позволяет непосредственно ассоциировать с событием (неименованный) блок операторов программного кода. Анонимные методы могут игнорировать параметры, посылаемые событием, и получать доступ в "внешним переменным" определяющего метода. В завершение главы был рассмотрен упрощенный способ регистрации событий с помощью группового преобразования методов. ГЛАВА 9. Специальные приемы построения типов В этой главе вы расширите горизонты вашего понимания языка C#, рассмотрев ряд более сложных (но весьма полезных) синтаксических конструкций. Сначала мы с вами выясним, как использовать метод индексатора. Этот механизм в C# позволяет строить пользовательские типы, обеспечивающие доступ к внутренним подтипам на основе синтаксиса массивов. Научившись строить методы индексатора, вы затем узнаете, как перегружать различные операции (+, -, ‹, › и т.д.) и явно или неявно создавать пользовательские подпрограммы преобразования типов (а также узнаете, зачем это может понадобиться). Во второй половине главы будет рассмотрен небольшой набор ключевых слов C#, которые позволяют реализовать весьма интересные конструкции, хотя используются не очень часто. Вы узнаете о том, как с помощью ключевых слов checked и unchecked программно учитывать условия переполнения и потери значимости, а также о том, как создается "небезопасный" программный контекст, обеспечивающий возможность непосредственного управления ссылочными типами в C#. Завершается глава обсуждением роли директив препроцессора C#. Создание пользовательских индексаторов Как программисты, мы прекрасно знаем, что с помощью индексов можно получить доступ к отдельным элементам, содержащимся в стандартном массиве. // Объявление массива целых значений. int[] myInts = {10, 9, 100, 432, 9874}; // Использование операции [] для доступа к элементам. for (int j = 0; j ‹ myInts.Length; j++) Console.WriteLine("Индекс {0} = {1}", j, myInts[j]); Этот программный код ни в коем случае не претендует на новизну. Но язык C# дает возможность строить пользовательские классы и структуры, которые могут индексироваться подобно стандартным массивам. Поэтому совсем не удивительно, что метод, который обеспечивает такой доступ к элементам, называется индекса-mopoм. Перед тем как приступить к созданию соответствующей конструкции, мы рассмотрим один пример. Предположим, что поддержка метода индексатора уже добавлена в пользовательскую коллекцию Garage (гараж), уже рассматривавшуюся в главе 8. Проанализируйте следующий пример ее использования. // Индексаторы обеспечивают доступ к элементам подобно массивам. public class Program { static void Main(string[] args) { Console.WriteLine("***** Забавы с индексаторами *****\n"); // Предположим, что Garage имеет метод индексатора. Garage carLot = new Garage(); // Добавление в гараж машин с помощью индексатора. сarLot[0] = new Саr("FееFee", 200); carLot[1] = new Car("Clunker", 90); carLot[2] = new Car("Zippy", 30); // Чтение и отображение элементов с помощью индексатора. for (int i = 0; i ‹ 3; i++) { Console.WriteLine("Hомep машины: {0}", i); Console.WriteLite("Нaзвaниe: {0}", carLot[i].PetName); Console.WriteLine("Максимальная скорость: {0}", carLot[i].CurrSpeed); Console.WriteLine(); } Console.ReadLine(); } } Как видите, индексаторы ведут себя во многом подобно пользовательской коллекции, поддерживающей интерфейсы IEnumerator и IEnumerable. Основное различие в том, что вместо доступа к содержимому посредством типов интерфейса вы можете работать с внутренней коллекцией автомобилей, как с обычным массивом. Здесь возникает вопрос: "Как сконфигурировать класс (или структуру), чтобы обеспечить поддержку соответствующих функциональных возможностей?" Индексатор в C# представляет собой несколько "искаженное" свойство. Для создания индексатора в самой простой форме используется синтаксис this[]. Вот как может выглядеть подходящая модификации типа Garage. // Добавление индексатора в определение класса. public class Garage: IEnumerable { // для каждого элемента … // Использование ArrayList для типов Car. private ArrayList carArray = new ArrayList(); // Индексатор возвращает тип Car, соответствующий // Числовому индексу. public Car this[int pos] { // ArrayList тоже имеет индексатор! get { return (Car)carArray[pos]; } set { carArray.Add(value); } } } Если не обращать внимания на ключевое слово this, то объявление индексатора очень похоже на объявление свойства в C#. Но следует подчеркнуть, что индексаторы не обеспечивают иных функциональных возможностей массива, кроме возможности использования операции индексирования, Другими словами, пользователь объекта не может применить программный код, подобный следующему. // Используется свойство ArrayList.Count? Нет! Console.WriteLine("Машин в наличии: {0} ", carLot.Count); Для поддержки этой функциональной возможности вы должны добавить свое свойство Count в тип Garage и, соответственно, делегат. public class Garage: IEnumerable { … // Локализация/делегирование в действии снова. public int Count { get { return carArray.Count; } } } Итак, индексаторы – это еще одна синтаксическая "конфетка", поскольку соответствующих функциональных возможностей можно достичь и с помощью "обычных" методов. Например, если бы тип Garage не поддерживал индексатор, все равно можно было бы позволить "внешнему миру" взаимодействовать с внутренним массивом, используя для этого именованное свойство или традиционные методы чтения и модификации данных (accessor/mutator). Но при использовании индексаторов пользовательские типы коллекции лучше согласуются со структурой библиотек базовых классов .NET. Исходный код. Проект SimpleIndexer размещен в подкаталоге, соответствующем главе 9. Вариации индексатора для типа Garage В своем текущем виде тип Gаrage определяет индексатор, который позволяет вызывающей стороне идентифицировать внутренние элементы, используя число-вое значение. Но это не является непременным требованием метода индексатора. Предположим, что объекты Car содержатся в System.Collections.Specialized. ListDictionary, а не в ArrayList. Поскольку типы ListDictionary позволяют доступ к содержащимся типам с помощью ключевых маркеров (таких как, например, строки), можно создать новый индексатор Garage, подобный показанному ниже. public class Garage: IEnumerable { private ListDictionary carDictionary = new ListDictionarу(); // Этот индексатор возвращает соответствующий тип Car // на основе строкового индекса. public Car this[string name] { get { return (Car)carDictionary[name]; } set { carDictionary[name] = value; } } public int Length { get { return carDictionary.Count; } } public IEnumerator GetEnumerator() { return carDictionary.GetEnumerator(); } } Вызывающая сторона теперь может взаимодействовать с машинами внутри так, как показано ниже, public class Program { static void Main(string[] args) { Console:WriteLine("***** Забавы с индексаторами *****\n"); Garage carLot = new Garage(); // Добавление именованных машин в гараж. carLot["FeeFee"] = new Car("FeeFee", 200, 0); carLot["Clunker"] = new Car("Clunker", 90, 0); carLot["Zippy"] = new Car("Zippy", 30, 0); // Доступ к Zippy. Car zippy = carLot["Zippy"]; Console.WriteLine("{0} едет со скоростью {1} км/ч", zippy.PetName, zippy.CurrSpeed); Console.ReadLine(); } } Индексаторы могут быть и перегруженными. Так, чтобы позволить вызывающей стороне доступ к внутренним элементам посредством числового индекса или строковых значений, вы можете определить множество индексаторов для одного типа. Исходный код. Проект StringIndexer размещен в подкаталоге, соответствующем главе 9. Внутреннее представление индексаторов типов Мы рассмотрели примеры метода индексатора в C#, и пришло время выяснить, как представляются индексаторы в терминах CIL. Если открыть числовой индексатор типа Garage, то будет видно, что компилятор C# создает свойство Item, которое сводится к подходящей паре методов get/set. property instance class SimpleIndexer.Car Item(int32) { .get instance class SimpleIndexer.Car SimpleIndexer.Garage::get_Item(int32) .set instance void SimpleIndexer.Garage::set_Item(int32, class SimpleIndexer.Car) } // end of property Garage::Item Методы get_Item() и set_Item() будут реализованы аналогично любому другому свойству .NET, например: method public hidebysig specialname instance сlass SimpleIndexer.Car get_Item(int32 pos) cil managed { Code size 22 (0x16) .maxstack 2 .locals init ([0] class SimpleIndexer.Car CSS1$0000) IL_0000: ldarg.0 IL_0001: ldfld class [mscorlib] System.Collections.ArrayList SimpleIndexer.Garage::carArray IL_0006: ldarg.1 IL_0007: callvirt instance object [mscorlib] Sysftem.Collections.ArrayList::get_Item(int32) IL_000c: castclass SimpleIndexer.Car IL_0011: stloc.0 IL_0012: br.s IL_0014 IL_0014: ldloc.0 IL_0015: ret } // end of method Garage::get_Item Заключительные замечания об индексаторах Чтобы получить настоящую экзотику, вы можете создать индексатор, который имеет множество параметров. Предположим, что у нас есть пользовательская кол-лекция, которая хранит элементы в двумерном массиве. В этом случае вы можете создать метод индексатора, доказанный ниже. public class SameContainer { private int[,] my2DinArray = new int[10, 10]; public int this[int row, int column] {/* прочитать или установить значение 2D-массива * /} } В заключение следует заметить, что индексаторы могут определяться и для типа интерфейса .NET, что обеспечивает реализующим интерфейс типам возможность его настройки. Вот пример такого интерфейса. public interface IEstablishSubObjects { // Этот интерфейс определяет индексатор, возвращающий // строки на основе числового индекса. string this[int index] {get; set;} } Пожалуй, об индексаторах C# уже сказано достаточно. Перейдем к рассмотрению еще одного подхода, используемого в некоторых (но не во всех) языках программирования .NET: это перегрузка операций. Перегрузка операций В C#, как и в любом другом языке программирования, есть свой ограниченный набор лексем, используемых для выполнения базовых операций со встроенными типами. Так, вы знаете, что операция + применима к двум целым числам и в результате дает их сумму. // Операция + с целыми числами. int а = 100; int b = 240; int с = а + b; // с теперь равно 340 Снова заметим, что это не новость, но вы, наверное, заметили и то, что одна и та же операция + может применяться к большинству встроенных типов данных C#. Рассмотрите, например, следующий фрагмент программного кода. // Операция + со строками. string s1 = "Hello"; string s2 = " world!"; string s3 = s1 + s2; // s3 теперь равно "Hello world!" По сути, операция + функционирует уникальным образом в зависимости от поставляемых типов данных (в данном случае это строки или целые числа). Когда операция + применяется к числовым типам, результатом является сумма операндов, а когда операция + применяется к строковым типам, результатом будет конкатенация строк. Язык C# обеспечивает возможность построения пользовательских классов и структур, которые будут по-своему отвечать на один и тот же набор базовых лексем (таких, как операция +). При этом следует заметить, что можно "перегружать" не все встроенные операции C#. В табл. 9.1 указаны возможности перегрузки базовых операций. Таблица 9.1. Возможности перегрузки операций
Перегрузка бинарных операций Чтобы проиллюстрировать процесс перегрузки бинарных операций, расcмо-трим следующую простую структуру Point (точка). // Самая обычная структура C#. public struct Point { private int x, y; public Point(int xPos, int yPos) { x = xPos; у = yPos; } public override string ToString() { return string.Format("[{0}, {1}]", this.x, this.у); } } Можно, скажем, рассмотреть сложение типов Point. Можно также вычесть один тип Point из другого. Например, вы можете записать, следующий программный код. // Сложение и вычитание двух точек. static vоid Main(string [] args) { Console.WriteLine("*** Забавы с перегруженными операциями ***\n"); // Создание двух точек. Point ptOne = new Point(100, 100); Point ptTwo = new Point (40, 40); Console.WriteLine("ptOne = {0}", ptOne); Console.WriteLine("ptTwo = {0}", ptTwo); // Сложение точек в одну большую точку? Console.WriteLine("ptOne + ptTwo: {0} ", ptOne + ptTwo); // Вычитание одной точки из другой дает меньшую точку? Console.WriteLine("ptOne – ptTwo: {0} ", ptOne – ptTwo); Console.ReadLine(); } Чтобы позволить пользовательскому типу по-своему отвечать на встроенные операции, в C# предлагается ключевое слово operator, которое можно использовать только со статическими методами. Перегруженной бинарной операции (такой, как + или -) на вход подаются два аргумента, которые имеют тип определяющего класса (в данном примере это Point), как показывает следующий программный код. // Более 'интеллектуальный' тип Point. public struct Point { … // перегруженная операция + public static Point operator+(Point p1, Point p2) { return new Point(p1.x + p2.x, p1.y + p2.y); } // перегруженная операция - public static Point operator–(Point p1, Point p2) { return new Point(p1.x – p2.x, p1.y – p2.y); } } По логике операция + должна просто возвратить совершенно новый объект Point, полученный в результате суммирования соответствующих полей входных параметров Point. Поэтому, когда вы пишете pt1 + pt2, можете представлять себе следующий скрытый вызов статического метода операции +. // р3 = Point.операция+(p1, р2) р3 = p1 + р2; Точно так же p2 – p2 отображается в следующее. // р3 = Point.операция-(p1, р2) р3 = p1 – p2; Операции += и -= Если вы изучаете C#, уже имея опыт использования C++, то можете обратить внимание на отсутствие возможности перегрузки операторных сокращений, включающих операцию присваивания (+=, -= и т.д.). Не волнуйтесь, в C# операторные сокращения с присваиванием моделируются автоматически, если тип предполагает перегрузку соответствующей бинарной операции. Поэтому, поскольку структура Point уже использует перегрузку операций + и -, вы можете записать следующее. // Перегрузка бинарных операций автоматически влечет перегрузку // операторных сокращений с присваиванием. static void Main(string[] args) { // Автоматическая перегрузка += Point ptThree = new Point(90, 5); Console.WriteLine("ptThree = {0}", ptThree); Console.WriteLine("ptThree +=ptTwo: {0}", ptThree += ptTwo); // Автоматическая перегрузка -= Point ptFour = new Point(0, 500); Console.WriteLine("ptFour = {0}", ptFour); Console.WriteLine("ptFour -= ptThree: {0}", ptFour -= ptThree); } Перегрузка унарных операций В C# также позволяется перегрузка унарных операций, таких как, например, ++ и --. При перегрузке унарной операции вы тоже должны с помощью ключевого слова operator определить статический метод, но в данном случае передается только один параметр, который должен иметь тип, соответствующий определяющему классу или структуре. Например, если добавить в Point следующие перегруженные операции public struct Point { … // Добавление 1 к поступившему Point. public static Point operator++(Point p1) { return new Point(p1.x+1, p1.y+1); } // Вычитание 1 от поступившего Point. public static Point operator--(Point p1) { return new Point(p1.x-1, p1.y-1); } } то вы получите возможность увеличивать или уменьшать на единицу значения X и Y объекта Point, как показано ниже. static void Main(string[] args) { … // Применение унарных операций ++ и -- к Point. Console.WriteLine("++ptFive = {0}", ++ptFive); Console.WriteLine("--ptFive = {0}", --ptFive); } Перегрузка операций проверки на тождественность Вы можете помнить из материала главы 3, что System.Object.Equals() можно переопределить, чтобы сравнение типов выполнялось на основе значений (а не ссылок). Если вы переопределите Equals() (и связанный с Equals() метод System.Object.GetHashCode()), то будет очень просто задать перегрузку операций проверки на тождественность (== и !=). Для иллюстрации мы рассмотрим обновленный тип Point. // Такая 'инкарнация' Point задает также перегрузку операций == и !=. public struct Point { … public override bool Equals(object o) { if (o is Point) { if (((Point)o).x == this.x && ((Point)о). у == this.y) return true; } return false; } public override int GetHashCode() { return this.ToString().GetHashCode(); } // Здесь позволяется перегрузка операций == и !=. public static bool operator==(Point p1, Point p2) { return p1.Equals(p2); } public static bool operator!=(Point p1, Point p2) { return!p1.Equals(p2); } } Обратите внимание на то, что данная реализация операций == и != просто вызывает переопределенный метод Equals(), который и выполняет основную работу. С учетом этого вы можете теперь использовать свой класс Point так. // Использование перегруженных операций проверки на тождественность. static void Main(string[] args) { … Console.WriteLine("ptOne == ptTwo: {0}", ptOne == ptTwo); Console.WriteLine("ptOne != ptTwo: {0}", ptOne != ptTwo); } Как видите, здесь два объекта сравниваются с помощью операций == и !=, а не с помощью "менее естественного" вызова Object.Equals(). При использовании перегрузки операций проверки на тождественность для класса имейте в виду, что в C# требуется, чтобы при переопределении операции – обязательно переопределялась и операция != (если вы забудете это сделать, компилятор вам напомнит). Перегрузка операций сравнения Из материала главы 7 вы узнали о том, как реализовать интерфейс IComparable, чтобы иметь возможность сравнения подобных объектов. В дополнение к этому для того же класса вы можете использовать перегрузку операций сравнения (‹, ›, ‹= и ›=). Подобно операциям проверки на тождественность, в C# требуется, чтобы при перегрузке ‹ выполнялась и перегрузка ›. Это же касается и операций ‹= и ›=. Если тип Point использует перегрузку операций сравнения, пользователь объекта получает возможность сравнивать объекты Point так, как показано ниже. // Использование перегруженных операций ‹ и ›. static void Main(string[] args) { … Console.WriteLine("ptOne ‹ ptTwo: {0}", ptOne ‹ ptTwo); Console.WriteLine("ptOne › ptTwo: {0}", ptOne › ptTwo); } В предположении о том, что интерфейс IComparable реализован, перегрузка операций сравнения оказывается тривиальной. Вот как может выглядеть обновленное определение класса. // Можно сравнивать объекты Point с помощью операций сравнения. public struct Point: IComparable { … public int CompareTo(object obj) { if (obj is Point) { Point p = (Point)obj; if (this.x › p.x && this.y › p.y) return 1; if (this.x ‹ p.x && this.y ‹ p.y) return -1; else return 0; } else throw new ArgumentException(); } public static bool operator‹(Point p1, Point p2) { return(p1.CompareTo(р2) ‹ 0); } public static bool operator›(Point p1, Point p2) { return(p1.CompareTo(p2) › 0); } public static bool operator‹=(Point p1, Point p2) { return(p1.CompareTo(p2) ‹= 0); } public statiс bool operator›=(Point p1, Point p2) { return(p1.CompareTo(p2) ›= 0); } } Внутреннее представление перегруженных операций Подобно любому элементу программы C#, перегруженные операции представляются специальными элементами синтаксиса CIL. Откройте, например, компоновочный блок OverloadedOps.exe с помощью ildasm.exe. Как показано на рис. 9.1, перегруженные операции внутри блока представляются скрытыми методами (это, например, op_Addition(), oр_Subtraction(), op_Equality() и т.д.). Теперь, если рассмотреть CIL-инструкции для метода op_Addition, то вы обнаружите, что csc.exe добавляет в метод ключевое слово specialname. .method public hidebysig specialname static valuetype OverloadedOps.Point op_Addition(valuetype OverloadedsOps.Point p1, valuetype OverloadedOps.Point p2) cil managed { … }  Рис. 9.1. В терминах CIL перегруженные операции отображаются в скрытые методы Итак, любая операция, допускающая перегрузку, сводится в терминах CIL к специальному именованному методу. В табл. 9.2 раскрывается соответствие имен типичных операций C# и методов CIL. Таблица 9.2. Соответствие имен операций C# и методов CIL
Использование перегруженных операций в языках, не поддерживающих перегрузку операций Понимание того, как перегруженные операции представлены в программном коде CIL интересно не только с академической точки зрения. Чтобы осознать практическую пользу этих знаний, вспомните о том, что возможность перегрузки операций поддерживается не всеми языками, предназначенными для .NET. Как, например, добавить пару типов Point в программу, созданную на языке, не поддерживающем перегрузку операций? Одним из подходов является создание "нормальных" открытых членов, которые будут решать ту же задачу, что и перегруженные операции. Например, можно добавить в Point методы Add() в Subtract(), которые будут выполнять работу, соответствующую операциям + и -. // Экспозиция семантики перегруженных операций // с помощью простых членов-функций. public struct Point { // Представление операции + с помощью Add() public static Point Add(Point p1, Point p2) { return p1 + p2; } // Представление операции – с помощью Subtract() public static Point Subtract(Point p1, Paint p2) { return p1 – p2; } } С такими модификациями тип Point способен демонстрировать соответствующие функциональные возможности, используя любые подходы, предлагаемые в рамках данного языка. Пользователи C# могут применять операции + и – или же вызывать Add()/Subtract(). // Использование операции + или Add() , Console.WriteLine("ptOne + ptTwo: {0} ", ptOne + ptTwo); Console.WriteLine("Point.Add(ptOne, ptTwo): {0} ", Point.Add(ptOne, ptTwo)); // Использование операции – или Subtract(). Console.WriteLine("ptOne – ptTwo: {0} ", ptOne – ptTwo); Console.WriteLine("Point.Subtract(ptOne, ptTwo): {0} ", Point.Subtract(ptOne, ptTwo)); Языки, в которых не допускается перегрузка операций, могут использовать только открытые статические методы. В качестве альтернативы можно предложить непосредственный вызов специальных именованных методов, создаваемых компилятором. Рассмотрим исходный вариант языка программирования VB. NET. При построении консольного приложения VB .NET, ссыпающегося на тип Point, вы можете добавлять или вычитать типы Point, используя "специальные CIL-имена", например: ' Предполагается, что данное приложение VB.NET ' имеет доступ к типу Point. Module OverLoadedOpClient Sub Main() Dim p1 As Point p1.x = 200 p1.y= 9 Dim p2 As Point p2.x = 9 p2.y = 983 ' He так красиво, как вызов AddPoints(), ' но зато работает. Dim bigPoint = Point.op_Addition(p1, p2) Console.WriteLine("Большая точка {0}", bigPoint) End Sub End Module Как видите, языки программирования .NET, не предусматривающие перегрузку операций, способны непосредственно вызывать внутренние методы CIL, как "обычные" методы. Такое решение нельзя назвать слишком "изящным", но оно работает. Замечание. Текущая версия VB .NET (Visual Basic .NET 2005) перегрузку операций поддерживает. Однако для других (многочисленных) управляемых языков, не поддерживающих перегрузку операций, знание "специальных имен" соответствующих методов CIL может оказаться очень полезным. Заключительные замечания о перегрузке операций Вы могли убедиться в том, что C# обеспечивает возможность построения типов, по-своему отвечающих на встроенные всем известные операции. Перед тем как перейти к непосредственной модификации классов для поддержки такого поведения, вы должны убедиться в том, что для операций, которым вы хотите назначить перегрузку, такая перегрузка имеет смысл. Предположим, например, что вы хотите использовать перегрузку операции умножения для класса Engine (мотор). Что тогда должно означать умножение двух объектов Engine? He понятно. Перегрузка операций, в общем, оказывается полезной только тогда, когда строятся полезные типы. Строки, точки, прямоугольники и шестиугольники являются хорошими объектами для перегрузки операций. А люди, менеджеры, автомобили, наушники и бейсбольные кепки – нет. Если перегруженная операция делает более трудным понимание функциональных возможностей типа пользователем, то лучше перегрузку не использовать. Используйте указанную возможность с умом. Исходный код. Проект OverloadedOps размещен в подкаталоге, соответствующем главе 9. Пользовательские преобразования типов Рассмотрим тему, близко связанную с перегрузкой операций: это пользовательские правила преобразования типов. В начале вашего рассмотрения мы кратко обсудим явные и неявные преобразования числовых данных и соответствующих типов класса. Преобразования чисел В случае встроенных числовых типов (sbyte, int, float и т.д.) явное преобразование требуется тогда, когда вы пытаетесь сохранить большее значение в меньшем контейнере, поскольку при этом может происходить потеря данных. По сути, это способ сказать компилятору примерно следующее: "Не беспокойся, я знаю, что делаю!" С другой стороны, неявное преобразование происходит автоматически, когда вы пытаетесь разместить в типе-адресате тип меньших размеров, в результате чего потери данных не происходит. static void Main() { int a = 123; long b = a; // Неявное преобразование из int a long int с = (int)b; // Явное преобразование из long в int } Преобразования типов класса Как показано в главе 4, типы класса могут быть связаны классическим отношением наследования (отношение "is-a"). В этом случае в C# процесс преобразования позволяет сдвигаться вверх или вниз по иерархии классов. Например, производный класс всегда можно неявно преобразовать в базовый тип. Однако если вы захотите сохранить базовый тип класса в производной переменной, придется выполнить явное преобразование. // Два связанных типа класса. class Base{} class Derived: Base{} class Program { static void Main() { // Неявное преобразование из производного в базовый. Base myBaseType; myBaseType = new Derived(); // Для сохранения базовой ссылки в производном типе // следует выполнить явное преобразование. Derived myDerivedType = (Derived)myBaseType; } } Здесь явное преобразование работает благодаря тому, что классы Base и Derived связаны классическим отношением наследования. Но что делать в том случае, когда вы хотите связать преобразованием два типа класса, принадлежащие разным иерархиям? Если классы не связаны классическим наследованием, явное преобразование помочь ничем не сможет. В соответствующем ключе рассмотрим типы, характеризуемые значениями. Предположим, что у нас есть две .NET-структуры с именами Square (квадрат) и Rectangle (прямоугольник). Поскольку структуры не могут использовать классическое наследование, нет и естественного способа взаимного преобразования этих явно связанных типов (в предположении о том, что такое преобразование имеет смысл). Конечно, проблему можно решить с помощью создания в этих в структурах вспомогательных методов (например, Rectangle.ToSquare()), но в C# можно создавать пользовательские подпрограммы преобразования, позволяющие соответствующим типам по-своему отвечать на операцию (). Так, при правильной конфигурации типа Square вы получите возможность использовать следующий синтаксис для явного преобразования этих типов структуры. // Превращение прямоугольника в квадрат. Rectangle rect; rect.Width = 3; rect.Height = 10; Square sq = (Square)rect; Создание пользовательских подпрограмм преобразования В C# есть два ключевых слова, explicit и implicit, предназначенные для управления тем, как типы должны отвечать на попытки преобразования. Предположим, что у нас есть следующие определения структур. public struct Rectangle { // Открыты для простоты, // но ничто не мешает инкапсулировать их в виде свойств. public int Width, Height; public void Draw() { Console.WriteLine("Отображение прямоугольника."); } public override string ToString() { return string.Format("[Ширина = {0}; Высота = {1}]", Width, Height); } } public struct Square { public int Length; public void Draw() { Console.WriteLine("Отображение квадрата."); } public override string ToString() { return string.Format("[Сторона = {0}]", Length); } // Rectangle (прямоугольник) можно явно преобразовать // в Square (квадрат). public static explicit operator Square(Rectangle r) { Square s; s.Length = r.Width; return s; } } Обратите внимание на то, что на этот раз для типа Reсtangle определяется операция явного преобразования. Как и при перегрузке встроенных операций, в C# для подпрограмм преобразования используется ключевое слово operator (в совокупности с ключевым словом explicit или implicit) и эти подпрограммы должны определяться, как статические. Входным параметром является объект, который вы хотите преобразовать, а возвращаемое значение – это объект, в который поступающий объект превращается. public static explicit operator Square(Rectangle r) {…} Здесь предполагается, что квадрат (который является геометрической фигурой с равными сторонами) можно получить на основе ширины прямоугольника. Поэтому вы можете превратить Rectangle (прямоугольник) в Square (квадрат) так. static void Main(string args) { Console.WriteLine("***** Забавы с преобразованиями *****\n"); // Создание прямоугольника 10 х 5. Rectangle rect; reсt.Width = 10; rect.Height = 5; Console.WriteLine("rect = {0}", rect); // Преобразование прямоугольника в квадрат 10 х 10. Square sq = (Square)rect; Console.WriteLine("sq = {0}", sq); Console.ReadLine(); } Наверное, от превращения прямоугольников в квадраты в рамках одного контекста не слишком много пользы, но предположим, что у нас есть функция, которая предполагает использование типов Square. // Этот метод требует использования типа Square. private static void DrawSquare(Square sq) { sq.Draw(); } Используя нашу операцию явного преобразования, мы можем передавать этой функции типы Square. static void Main(string[] args) { … // Преобразование Rectangle в Square для вызова метода. DrawSquare((Square)rect); } Варианты явного преобразования для типа Square Теперь вы можете явно превращать прямоугольники в квадраты, но рассмотрим еще несколько вариантов явного преобразования. Поскольку у квадрата стороны равны, можно явно преобразовать System.Int32 в Square (длина стороны квадрата будет равна значению поступающего целого числа). Аналогично можно изменить определение Square, если требуется обеспечить преобразование из Square в System.Int32. Вот логика соответствующего вызова. static void Main(string[] args) { … // Преобразование System.Int32 в Square. Square sq2 = (Square)90; Console.WriteLine("sq2 = {0}", sq2); // Преобразование Square в System.Int32. int side = (int)sq2; Console.WriteLine("Длина стороны sq2 = {0}", side); } А вот как следует обновить определение типа Square. public struct Square { … public static explicit operator Square(int sideLength) { Square newSq; newSq.Length = sideLength; return newSq; } public static explicit operator int(Square s) { return s.Length; } } Выглядит немного странно, не так ли? Честно говоря, преобразование из Square в System.Int32 не является интуитивно очевидной (или полезной) операцией. Однако она демонстрирует одну очень важную особенность пользовательских подпрограмм преобразования; компилятору "все равно" из чего и во что вы преобразуете – важно, чтобы ваш программный код был синтаксически правильным. Так что, как в случае с перегрузкой операций, только из того, что вы можете создать операцию явного преобразования для данного типа, совсем не следует, что вы обязаны это делать. Как правило, этот подход оказывается наиболее полезным тогда, когда создаются типы структуры .NET, поскольку такие типы не могут использовать иерархии классического наследования (для которых соответствующие преобразования реализуются автоматически). Определение подпрограмм неявного преобразования До этого момента мы с вами создавали пользовательские операции явного преобразования. Но что можно сказать о следующем неявном преобразовании? static void Main(string[] args) { … // Попытка выполнить неявное преобразование? Square s3; s3.Length = 83; Rectangle rect2 = s3; } Как вы можете догадаться сами, этот программный код скомпилирован не будет, поскольку в нем не предлагается никакой подпрограммы неявного преобразования для типа Rectangle. Тут нас подстерегает "ловушка": в одном и том же типе нельзя определять явные и неявные функции преобразования, не отличающиеся по типу возвращаемого значения или по набору параметров. Может показаться, что это правило является слишком ограничивающим, но не следует забывать о том, что даже если тип определяет подпрограмму неявного преобразования, вызывающая сторона "имеет право" использовать синтаксис явного преобразования! Запутались? Чтобы прояснить ситуацию, добавим в структуру Rectangle подпрограмму неявного преобразования, используя ключевое слово C# implicit (в следующем программном коде предполагается, что ширина результирующего Rectangle получается с помощью умножения стороны Square на 2). public struct Rесtangle { … public static implicit operator Rectangle(Square s) { Rectangle r; r.Height = s.Length; // Ширина нового прямоугольника равна // удвоенной длине стороны квадрата. r.Width = s.Length * 2; } } С такими изменениями вы получаете возможность преобразовывать указанные типы так. static void Main(string[] args) { … // Неявное преобразование: все OK! Square s3; s3.Length = 83; Rectangle rect2 = s3; Console.WriteLine("rect2 = {0}", rect2); DrawSquare(s3); // Синтаксис явного преобразования: тоже OK! Square s4; S4.Length = 3; Rectangle rect3 = (Rectangle)s4; Console.WriteLine("rect3 = {0}", rect3); … } Снова подчеркнем, что допускается определение подпрограмм и явного, и неявного преобразования для одного и того же типа, но только если отличаются их сигнатуры. Поэтому мы можем обновить Square так, как показано ниже. public struct Square { … // Можно вызывать как Square sq2 = (Square)90; // или как Square sq2 = 90; public static implicit operator Square(int sideLength) { Square newSq; newSq.Length = sideLength; return newSq; // Должно вызываться как int side = (Square)mySquare; public static explicit operator int(Square s) { return s.Length; } } } Внутреннее представление пользовательских подпрограмм преобразования Как и в случае перегруженных операций, те методы, которые обозначены ключевыми словами implicit или explicit, получают "специальные имена" в терминах CIL: op_Implicit и op_Explicit соответственно (рис. 9.2).  Рис. 9.2. Представление пользовательских подпрограмм преобразования в терминах CIL. На этом мы завершаем обзор возможностей пользовательских подпрограмм преобразования. Как и в случае перегруженных операций, соответствующий синтаксис является лишь сокращённым вариантом определения "нормальных" членов-функций, и с этой точки зрения он не является обязательным. Исходный код. Проект CustomConversions размещен в подкаталоге, соответствующем главе 9. Ключевые слова C#, предназначенные для более сложных конструкций В завершение главы мы рассмотрим ряд ключевых слов C#, применение которых требует от разработчика несколько большего опыта в программировании: • checked/unchecked; • unsafe/stackalloc/fixed/sizeof. Сначала мы выясним, как с помощью ключевых слов checked и unchecked в C# обеспечивается автоматическое выявление условий переполнения и потери значимости при выполнении арифметических операций. Ключевое слово checked Вы, несомненно, прекрасно знаете, что любой числовой тип данных имеет свои строго заданные верхний и нижний пределы (значения которых можно выяснить программными средствами с помощью свойств MaxValue и MinValue). При выполнении арифметических операций с конкретным типом вполне возможно случайное переполнение блока хранения данного типа (попытка присвоения типу значения, которое оказывается больше максимально допустимого) или потеря значимости (попытка присвоения значения, которое оказывается меньше минимально допустимого). Чтобы "идти в ногу" с CLR, обе эти возможности будут обозначаться, как "переполнение". (И переполнение, и потеря значимости приводят к созданию типа System.OverflowException. Типа System.UnderflowException в библиотеках базовых классов нет.) Для примера предположим, что мы создали два экземпляра типа System.Byte (тип byte в C#), присвоив им значения, не превышающие максимального (255). При сложении значений этих типов (с условием преобразования результата в тип byte) хотелось бы предполагать, что результат будет точной суммой соответствующих членов. namespace CheckedUnchecked { class Program { static void Main(string[] args) { // Переполнение для System.Byte. Console.WriteLine("Макс, значение для byte равно {0}", byte.MaxValue); Console.WriteLine("Мин. значение для byte равно {0}", byte.MinValue); byte b1 = 100; byte b2 = 250; byte sum = (byte)(b1 + b2); // Значением sum должно быть 350, но.… Console.WriteLine("sum = {0}", sum); Console.ReadLine(); } } } Вывод этого приложения покажет, что sum содержит значение 94 (а не ожидаемое 350). Причина очень проста. Поскольку System.Byte может содержать только значения, находящиеся между 0 и 255 (что в итоге составляет 256 значений), sum будет содержать значение переполнения (350 – 256 = 94). Как видите, в отсутствие специальной коррекции переполнение происходит без генерирования исключений. Иногда скрытое переполнение не создает никаких проблем. В других случаях соответствующая потеря данных может быть совершенно неприемлемой. Для обработки переполнений или потери значимости в приложении имеются две возможности. Первой возможностью является использование программистского опыта и квалификации с тем, чтобы обработать все условия переполнения вручную. Предполагая, что вы можете найти все условия переполнения в программе, можно было бы решить проблему, связанную с переполнением в предыдущем программном коде, как показано ниже. // Использование int для sum, чтобы не допустить переполнения. byte b1 = 100; byte b2 = 250; int sum = b1 + b2; Конечно, проблемой этого подхода является то, что вы – человек, а значит, при всех ваших усилиях, могут остаться ошибки, ускользнувшие от вашего взгляда. Поэтому в C# предлагается ключевое слово checked. При помещении оператора (или блока операторов) в рамки контекста ключевого слова checked компилятор C# генерирует специальные CIL-инструкщии, с помощью которых проверяются условия переполнения, возможные при выполнении сложения, умножение, вычитания или деления числовых типов данных. Если происходит переполнение, среда выполнения генерирует тип System.OverflowException. Рассмотрите следующую модификацию программы. class Program { static void Main(string[] args) { // Переполнение для System.Byte. Console.WriteLine("Макс. значение для byte равно {0}.", byte.MaxValue); byte b1 = 100; byte b2 = 250; try { byte sum = checked((byte)(b1 + b2)); Console.WriteLine("sum = {0}", sum); } catch (OverflowException e) { Console.WriteLine(e.Message); } } } Здесь оператор сложения b1 и b2 помещается в контекст ключевого слова checked. Если вы хотите, чтобы проверка переполнения происходила для блока программного кода, можно взаимодействовать с ключевым словом checked так, как показано ниже. try { checked { byte sum = (byte)(b1 + b2); Console.WritaLine(sum = {0}", sum); } } catch (OverflowException e) { Console.WriteLine(e.Message); } В любом случае соответствующий программный код будет проверяться на возможное переполнение автоматически, и если переполнение будет обнаружено, то будет сгенерирована соответствующее переполнению исключение. Проверки переполнения для всего проектаЕсли вы создаете приложение, которое не должно позволять скрытое переполнение ни при каких условиях, будет слишком утомительно указывать ключевое слово checked для каждой строки программного кода. В качестве альтернативы компилятор C# предлагает использовать флаг /checked. Когда этот флаг активизирован, все арифметические операции будут проверяться на переполнение без указания ключевого слова checked. Если обнаружится переполнение, вы получите OverflowException среды выполнения. Чтобы активизировать этот флаг в Visual Studio 2005, откройте страницу свойств проекта и щелкните на кнопке Advanced на вкладке Build. В появившемся диалоговом окне отметьте флажок Check for arithmetic overflow/underflow (Проверять условия переполнения/потери значимости для арифметических операций), рис. 9.3.  Рис. 9.З. Активизация проверки переполнения в Visual Studio 2005 Ясно, что эта установка оказывается очень полезной при отладке. После того как все связанные с переполнением исключения будут из программного кода удалены, флаг /checked для последующей компоновки можно отключить. Ключевое слово unchecked В предположении, что вы активизировали проверку переполнения для всего проекта, как разрешить игнорирование переполнений для тех блоков программного кода, где "молчаливая реакция" на переполнение вполне приемлема? Поскольку флаг /checked предполагает проверку всей арифметической логики, в языке C# предлагается ключевое слово unchecked, которое позволяет отключить генерирование System.OverflowException для конкретных случаев, Правила использования этого ключевого слова аналогичны правилам использования ключевого слова checked, и вы можете указать для него один оператор или блок операторов, например: // Даже если флаг /checked активизирован, // этот блок не генерирует исключения в среде выполнения. unchecked { byte sum = (byte)(b1 + b2); Console.WriteLine(sum = {0}", sum); } Подводя итога обсуждения ключевых слов C# checked и unchecked, снова подчеркнем, что по умолчанию среда выполнения .NET игнорирует условии переполнения, возникающие при использовании арифметических операций. Если вы хотите селективно контролировать условия переполнения для отдельных операторов, используйте ключевое слово checked. Если нужно контролировать ошибки переполнения во всем приложении, укажите флаг /checked, Наконец, можно использовать ключевое слово unchecked, если у вас есть блок программного кода, для которого переполнение приемлемо (и поэтому оно не должно генерировать исключение в среде выполнения). Исходный код. Проект CheckedUnchecked размещен в подкаталоге, соответствующем главе 9. Работа с типами указателя Из главы 8 вы узнали, что платформа .NET определяет две главные категории данных: типы, характеризуемые значениями, и типы, характеризуемые ссылками (ссылочные типы). Однако, справедливости ради., следует сказать, что имеется и третья категория: это типы указателя. Для работы с типами указателя предлагаются специальные операции и ключевые слова, с помощью которых можно "обойти" схему управления памятью CLR и "взять управление в свои руки" (табл. 9.3). Таблица 9.3. Операции и ключевые слова C# для работы с указателями
Перед рассмотрением деталей позвольте заметить, что необходимость в использовании типов указателя возникает очень редко, если она возникает вообще. Хотя C# и позволяет "спуститься" на уровень манипуляций с указателями, следует понимать, что среда выполнения .NET не имеет никакого представления о ваших намерениях. Поэтому если вы ошибетесь в направлении указателя, то за последствия будете отвечать сами. Если учитывать это, то когда же на самом деле возникает необходимость использования типов указателя? Есть две стандартные ситуации. • Вы стремитесь оптимизировать работу определенных частей своего приложения путем непосредственной манипуляции памятью вне пределов управления CLR. • Вы хотите использовать методы C-библиотеки *.dll или COM-сервера, требующие ввода указателей в виде параметров. Если вы решите использовать указанную возможность языка C#, необходимо информировать csc.exe об этих намерениях, указав разрешение для проекта поддерживать "небезопасный программный код". Чтобы сделать это с командной строки компилятора C# (csc.exe), просто укажите в качестве аргумента флаг /unsafe. В Visual Studio 2005 вы должны перейти на страницу свойств проекта и активизировать опцию Allow Unsafe Code (Разрешать использование небезопасного программного кода) на вкладке Build (рис. 9.4).  Рис. 9.4. Разрешение небезопасного программного кода Visual Studio 2005 Ключевое слово unsafeВ следующих примерах предполагается, что вы имеете опыт работы с указателями в C(++). Если это не так, не слишком отчаивайтесь. Подчеркнем еще раз, что создание небезопасного программного кода не является типичной задачей в большинстве приложений .NET. Если вы хотите работать с указателями в C#, то должны специально объявить блок программного кода "небезопасным", используя для этого ключевое слово unsafe (как вы можете догадаться сами, весь программный код, не обозначенный ключевым unsafe, автоматически считается "безопасным"). unsafe { // Операторы для работы с указателями. } Кроме объявления контекста небезопасного программного кода, вы можете строить "небезопасные" структуры, классы, члены типов и параметры. Вот несколько примеров, на которые следует обратить внимание. // Вся эта структура является 'небезопасной' // и может использоваться только в небезопасном контексте. public unsafe struct Node { public int Value; public Node* Left; public Node* Right; } // Эта структура является безопасной, но члены Node* – нет. // Строго говоря, получить доступ к 'Value' извне небезопасного // контекста можно, а к 'Left' и 'Right' - нет. public struct Node { public int Value; // К этим элементам можно получить доступ только // в небезопасном контексте! public unsafe Node* Left; public unsafe Node* Right; } Методы (как статические, так и уровня экземпляра) тоже можно обозначать, как небезопасные. Предположим, например, вы знаете, что некоторый статический метод использует логику указателей. Чтобы гарантировать вызов данного метода только в небезопасном контексте, можно определить метод так, как показано ниже. unsafe public static void SomeUnsafeCode() { // Операторы для работы о указателями. } В такой конфигурации требуется, чтобы вызывающая сторона обращалась к SomeUnsafeCode() так. static void Main(string[] args) { unsafe { SomeUnsafeCode(); } } Если же не обязательно, чтобы вызывающая сторона делала вызов в небезопасном контексте, то можно не указывать ключевое слово unsafe в методе SomeUnsafeCode() и записать следующее: public static void SomeUnsafeCode() { unsafe { // Операторы для работы с указателями. } } что должно упростить вызов: static void Main(string[] args) { SomeUnsafeCode(); }Работа с операциями * и & После создания небезопасного контекста вы можете строить указатели на типы с помощью операции * и получать адреса заданных указателей с помощью операции &. В C# операция * применяется только к соответствующему типу, а не как префикс ко всем именам переменных указателя. Например, в следующем фрагменте программного кода объявляются две переменные типа int* (указатель на целое). // Нет! В C# это некорректно! int *pi, *pj; // Да! Это в C# правильно. int* pi, pj; Рассмотрим следующий пример. unsafe { int myInt; // Определения указателя типа int // и присваивание ему адреса myInt. int* ptrToMyInt = &myInt; // Присваивание значения myInt // с помощью разыменования указателя. *ptrToMyInt = 123; // Печать статистики. Console.WriteLine("Значение myInt {0}", myInt); Console.WriteLine("Адрес myInt {0:X}", (int)&ptrToMyInt); }Небезопасная (и безопасная) функция Swap Конечно, объявление указателей на локальные переменные с помощью просто-то присваивания им значений (как в предыдущем примере) никогда не требуется. Чтобы привести более полезный пример небезопасного программного кода, предположим, что вы хотите создать функцию обмена, используя арифметику указателей. unsafe public static void UnsafeSwap(int* i, int* j) { int temp = *i; *i = *j; *j = temp; } Очень похоже на C, не так ли? Однако с учетом знаний, полученных из главы 3, вы должны знать, что можно записать следующую безопасную версию алгоритма обмена, используя ключевое слово C# ref. public static void SafeSwap(ref int i, ref int j) int temp = i; i = j; j = temp; } Функциональные возможности каждого из этих методов идентичны, и это еще раз подтверждает, что работа напрямую с указателями в C# требуется редко. Ниже показана логика вызова, static void Main(string[] args) { Console.WriteLine(*** Вызов метода с небезопасным кодом ***"); // Значения для обмена. int i = 10, i = 20; // 'Безопасный' обмен значениями. Console.WriteLine("\n***** Безопасный обмен *****"); Cоnsоle.WriteLine("Значения до обмена: i = {0}, j = {1}", i, j); SafeSwap(ref 1, ref j); Console.WriteLine("Значения после обмена: i = {0}, j = {l}", i, j); // 'Небезопасный' обмен значениями. Console.WriteLine("\n***** Небезопасный обмен *****"); Console.WriteLine("Значения до обмена: i = {0}, j = {1}", i, j); unsafe { UnsafeSwap(&i, &j); } Console.WriteLine("Значения после обмена: i = {0}, j = {1}", i, j); Console.ReadLine(); }Доступ к полям через указатели (операция -›) Теперь предположим, что у нас определена структура Point и мы хотим объявить указатель на тип Point. Как и в C(++), для вызова методов или получения доступа к полям типа указателя необходимо использовать операцию доступа к полю указателя (-›). Как уже упоминалось в табл. 9.3, это небезопасная версия стандартной (безопасной) операции, обозначаемой точкой (.). Фактически, используя операцию разыменования указателя (*). можно снять косвенность указателя, чтобы (снова) вернуться к применению нотации, обозначаемой точкой. Рассмотрите следующий программный код. struct Point { public int x; public int y; public override string ToString() { return string.Format ("({0}, {1})", x, y); } } static void Main(string[] args) { // Доступ к членам через указатели. unsafe { Point point; Point* p =&point; p-›x = 100; p-›y = 200; Console.WriteLine(p-›ToString()); } // Доступ к членам через разыменование указателей. unsafe { Point point; Point* p =&point; (*p).x = 100; (*p).y = 200; Console.WriteLine((*p).ToString()); } }Ключевое слово stackalloc В небезопасном контексте может понадобиться объявление локальной переменной, размещаемой непосредственно в памяти стека вызовов (и таким образом не подлежащей "утилизации" при сборке мусора .NET). Чтобы сделать такое объявление, в C# предлагается ключевое слово stackalloc являющееся C#-эквивалентом функции alloca из библиотеки времени выполнения C. Вот простой пример. unsafe { char* p = stackalloc char[256]; for (int k = 0; k ‹ 256; k++) p[k] = (char)k; }Фиксация типа с помощью ключевого слова fixed Как показывает предыдущий пример, задачу размещения элемента в памяти в рамках небезопасного контекста можно упростить с помощью ключевого слова stackalloc. В силу самой природы этой операции соответствующая память очищается, как только происходит возврат из метода размещения (поскольку память выбирается из стека). Но рассмотрим более сложный пример. В процессе обсуждения операции -› вы создали характеризуемый значением тип Point. Подобно всем типам, характеризуемым значениями, выделенная для него память в стеке освобождается сразу же после исчезновения контекста выполнения. Теперь, для примера, предположим что тип Point был определен как ссылочный тип. class Point { //‹= Теперь это класс! public int x; public int у; public override string ToString() { return string.Format("({0}, {1})", x, y); } } Вы хорошо знаете о том, что если вызывающая сторона объявляет переменную типа Point, для нее выделяется динамическая память, являющаяся объектом для сборки мусора. Тогда возникает вопрос: что произойдет, если небезопасный контекст попытается взаимодействовать с соответствующим объектом (или любым другим объектом в динамической памяти)? Поскольку сборка мусора может начаться в любой момент, представьте себе всю болезненность доступа к членам Point, когда идет очистка динамической памяти. Теоретически возможно, что небезопасный контекст будет пытаться взаимодействовать с членом, который больше не доступен или занимает новое положение в динамической памяти, "пережив" очередную генерацию чистки (и это, очевидно, является проблемой). Чтобы блокировать переменную ссылочного типа в памяти из небезопасного контекста, в C# предлагается ключевое слово fixed. Оператор fixed устанавливает указатель на управляемый тип и "закрепляет" переменную на время выполнения оператора. Без ключевого слова fixed в применении указателей на управляемые переменные было бы мало смысла, поскольку в результате сборки мусора. такие переменные могут перемещаться непредсказуемым образом. (На самом деле компилятор C# вообще не позволит установить указатель на управляемую переменную, если в операторе не используется ключевое слово fixed.) Так что, если вы создадите тип Point (сейчас переопределенный, как класс) и захотите взаимодействовать с его членами, то должны записать следующий программный код (иначе возникнет ошибка компиляции). unsafe public static void Main() { point pt = new Point(); pt.x = 5; pt.y = 6; // Фиксация pt, чтобы не допустить перемещения // или удаления при сборке мусора. fixed (int* p =&pt.x) { // Переменная int* используется здесь. } // Теперь pt не зафиксирована и может быть убрана // сборщиком мусора. Console.WriteLine("Значение Point: {0}", pt); } В сущности, ключевое слово fixed позволяет строить операторы, закрепляющие ссылочную переменную в памяти, чтобы ее адрес оставался постоянным на время выполнения оператора. Для гарантии безопасности обязательно фиксируйте ссылки при взаимодействии со ссылочными типами из небезопасного контекста программного кода. Ключевое слово sizeof В заключение обсуждения вопросов, связанных с небезопасным контекстом в C#, рассмотрим ключевое слово sizeof. Как и в C(++), ключевое слово C# sizeof используется для того, чтобы выяснить размер в байтах типа, характеризуемого значениями (но не ссылочного типа), и это ключевое слово может использоваться только в рамках небезопасного контекста. Очевидно, что указанная возможность может оказаться полезной при взаимодействии с неуправляемыми API, созданными на базе C. Использовать ее очень просто. unsafe { Console.WriteLine("Длина short равна {0}.", sizeof(short)); Console.WriteLine("Длина int равна {0}.", sizeof(int)); Console.WriteLine("Длина long равна {0}.", sizeof(long)); } Поскольку sizeof может оценить число байтов для любого элемента, производного от System.ValueType, можно получать размеры пользовательских структур. Допустим, мы определили следующую структуру. struct MyValueType { public short s; public int i; public long l; } Тогда ее размеры можно выяснить так. unsafe { Console.WriteLine("Длина short равна {0}.", sizeof(short)); Console.WriteLine("Длина int равна {0}.", sizeof(int)); Console.WriteLine("Длина long равна {0}.", sizeof(long)); Console.WriteLine("Длина MyValueType равна {0}."/ sizeof(MyValueType)); } Исходный код. Проект UnsafeCode размещен в подкаталоге, соответствующем главе 9. Директивы препроцессора C# Подобно многим другим языкам из семейства C, в C# поддерживаются различные символы, позволяющие влиять на процесс компиляции. Перед рассмотрением директив препроцессора C# согласуем соответствующую терминологию. Термин "директива препроцессора C#" не вполне точен. Фактически этот термин используется только для согласованности с языками программирования C и C++. В C# нет отдельного шага препроцессора. Директивы препроцессора в C# являются составной частью процесса лексического анализа компилятора. Так или иначе, синтаксис директив препроцессора C# очень похож на синтаксис соответствующих директив остальных членов семейства C в том, что эти директивы всегда имеют префикс, обозначенный знаком "диез" (#). В табл. 9.4 описаны некоторые из наиболее часто используемых директив (подробности можно найти в документации .NET Framework 2.0 SDK). Таблица 9.4. Типичные директивы препроцессора C#
Разделы программного кода Возможно, одной из самых полезных директив препроцессора являются #region и #endregion. Используя эти признаки, вы указываете блок программного кода, который можно скрыть от просмотра и идентифицировать информирующим текстовым маркером. Использование разделов программного кода может упростить обслуживание больших файлов *.cs. Можно, например, создать один раздел для конструкторов типа, другой – для свойств и т.д. class Car { private string petName; private int currSp; #region Constructors public Car() {…} public Car Car(int currSp, string petName) {…} #endregion #region Properties public int Speed {…} public string Name {…} #endregion } При помещений указателя мыши на маркер свернутого раздела вы получите снимок программного кода, спрятанного за соответствующим названием (рис. 9.5).  Рис. 9.5. Разделы программного кода за работой Условная компиляция Другой пакет директив препроцессора (#if, #elif, #else, #endif) позволяет выполнить компиляцию блока программного кода по условию, базируясь на предварительно заданных символах. Классическим вариантом использования этих директив является идентификация блока программного кода, который компилируется только при отладке (а не при окончательной компоновке). class Program static void Main(string[] args) { // Этот программный код выполняется только при отладочной // компиляции проекта. #if DEBUG Console.WriteLine("Каталог приложения: {0}", Environment.CurrentDirectory); Console.WriteLine("Блок: {0}", Environment.MachineName); Console.WriteLine("ОС: {0}", Environment.OSVersion); Console.WriteLine("Версия .NET: {0}", Environment.Version); #endif } } Здесь выполняется проверка на символ DEBUG. Если он присутствует, выводится ряд данных состояния, для чего используются соответствующие статические члены класса System.Environment. Если символ DEBUG не обнаружен, то программный код, размещенный между #if и #endif, компилироваться не будет и в результирующий компоновочный блок не войдет, т.е. будет фактически проигнорирован. По умолчанию Visual Studio 2005 всегда определяет символ DEBUG, однако такое поведение можно отменить путем снятия отметки флажка Define DEBUG constant (Определить константу DEBUG) на вкладке Build (Сборка), размещенной на странице Properties (Свойства) вашего проекта. В предположении о том, что этот обычно генерируемый символ DEBUG отключен, можно определить этот символ для каждого файла в отдельности, используя директиву препроцессора #define. #define DEBUG using System; namespace Preprocessor { class ProcessMe { static void Main(string[] args) { // Программный код, подобный показанному выше… } } } Замечание. Директивы #define в файле с программным кодом C# должны быть указаны до всех остальных. Можно также определять свои собственные символы препроцессора. Предположим, например, что у нас есть класс C#, которой должен компилироваться немного иначе в рамках дистрибутива Mono.NET (см. главу 1). Используя #define, можно определить символ MONO_BUILD для каждого файла. #define DEBUG #define MONO_BUILD using System; namespace Preprocessor { class Program { static void Main (string[] args) { #if MONO_BUILD Console.WriteLine("Компиляция для Mono!"); #else Consоlе.WriteLine("Компиляция для Microsoft .NET"); #endif } } } Чтобы создать символ, применимый для всего проекта, используйте текстовый блок Conditional compilation symbols (Символы условной компиляции, размещенный на вкладке Build (Сборка) страницы свойств проекта (рис. 9.6).  Рис. 9.6. Определение символа препроцессора для применения в рамках всего проекта Резюме Целью этой главы является более глубокое изучение возможностей языка программирования C#. Глава началась с обсуждения ряда достаточно сложных конструкций программирования (методов индексатора, перегруженных операций и пользовательских подпрограмм преобразования). Затем был рассмотрен небольшой набор не слишком широко известных ключевых слов (таких, как sizeof, checked, unsafe и т.д.), обсуждение которых естественно привело к рассмотрению вопросов непосредственной работы с типами указателя. При исследовании типов указателя было показано, что в подавляющем большинстве приложений C# для использования типов указателя нет никакой необходимости. ГЛАВА 10. Обобщения С появлением .NET 2.0 язык программирования C# стал поддерживать новую возможность CTS (Common Type System – общая система типов), названную обобщениями (generics). Упрощенно говоря, обобщения обеспечивают программисту возможность определения "заполнителей" (формально называемых параметрами типа) для аргументов методов и определений типов, которые будут конкретизированы во время вызова обобщенного метода или при создании обобщенного типа. С целью иллюстрации этой новой возможности языка мы начнем главу с рассмотрения пространства имен System.Collections.Generic. Рассмотрев примеры поддержки обобщений в библиотеках базовых классов, в остальной части этой главы мы попытаемся выяснить, как строить свои собственные обобщения членов, классов, структур, интерфейсов и делегатов. Снова о создании объектных образов, восстановлении значений и System.Object Чтобы понять, в чем заключаются преимущества использования обобщений, следует выяснить, какие проблемы возникают у программиста без их использования. Вы должны помнить из главы 3, что платформа .NET поддерживает автоматическое преобразование объектов стека и динамической памяти с помощью операций создания объектного образа и восстановления из объектного образа. На первый взгляд, эта возможность кажется не слишком полезной и имеющей, скорее, теоретический, чем практический интерес. Но на самом деле возможность создания объектного образа и восстановления из объектного образа очень полезна тем, что она позволяет интерпретировать все, как System.Object, оставив все заботы о распределении памяти на усмотрение CLR. Чтобы рассмотреть особенности процесса создания объектного образа, предположим, что мы создали System.Collections.ArrayList для хранения числовых (т.е. размещаемых в стеке) данных. Напомним, что все члены ArrayList обладают прототипами для получения и возвращения типов System.Object. Но вместо того, чтобы заставлять программиста вручную вкладывать размещенное в стеке целое число в соответствующую объектную оболочку, среда выполнения делает это автоматически с помощью операции создания объектного образа. static void Main(string[] args) { // При передаче данных члену, требующему объект, для // характеризуемых значениями типов автоматически создается // объектный образ. ArrayList myInts = new ArrayList(); myInts.Add(10); Console.ReadLine(); } Чтобы восстановить значение из объекта ArrayList, используя индексатор типа, вы должны превратить размещенный в динамической памяти объект в размещенное в стеке целое число, используя операцию преобразования. static void Main(string[] args) { … // Значение восстанавливается… и снова становится объектом! Console.WriteLine("Значение вашего int: {0}", (int)myInts[0]); Console.ReadLine(); } Для представления операции создания объектного образа в терминах CIL компилятор C# использует блок box. Точно так же операция восстановления из объектного образа преобразуется в CIL-блок unbox. Вот соответствующий CIL-код для показанного выше метода Main() (этот код можно увидеть с помощью ildasm.exe). .method private hidebysig static void Main(string[] args) cil managed { … box [mscorlib]System.Int32 callvirt instance int32 [mscorlib] System.Collections.ArrayList::Add(object) pop ldstr "Значение вашего int: {0}" ldloc.0 ldc.i4.0 callvirt instance object [mscorlib] System.Collections.ArrayList::get_Item(int32) unbox [mscorlib]System.Int32 ldind.i4 box [mscorlib]System.Int32 call void [mscorlib]System.Console::WriteLine(string, object) … } Обратите внимание на то. что перед обращением к ArrayList.Add() размещенное в стеке значение System.Int32 преобразуется в объект, чтобы передать требуемый System.Object. Также заметьте, что при чтении из ArrayList с помощью индексатора типа (что отображается в скрытый метод get_Item()) объект System.Object восстанавливается в System.Int32 только для того, чтобы снова стать объектным образом при передаче методу Console.WriteLine(). Проблемы создания объектных образов и восстановления значений Операции создания объектных образов и восстановления из них значений очень удобны с точки зрении программиста, но такой упрощенный подход при обмене элементами стека и динамической памяти имеет свои специфические проблемы производительности и не гарантирует типовой безопасности. Чтобы понять проблемы производительности, рассмотрим следующие шаги, которые приходится выполнять при создании объектного образа и восстановлении значения обычного целого числа. 1. Новый объект нужно разместить в управляемой динамической памяти. 2. Значение размещенных в стеке данных нужно записать в соответствующее место в памяти. 3. При восстановлении значений, сохраненного в объекте, размещенном в динамической памяти, это значение нужно снова вернуть в стек. 4. Неиспользуемый объект в управляемой динамической памяти (в конце концов) должен быть уничтожен сборщиком мусора. В нашей ситуации метод Main() с точки зрения производительности не имеет никаких проблем, но соответствующие проблемы появятся, когда ArrayList будет содержать тысячи целых значений, если вашей программе придется регулярно их обрабатывать. Теперь рассмотрим проблему отсутствия: типовой безопасности в отношении операции восстановления значений из объектного образа. Вы знаете, что для восстановления значения в рамках синтаксиса C# используется оператор преобразования. Но каким будет это преобразование – успешным или неудачным, – выяснится только в среде выполнения, При попытке восстановить значение в неправильный тип данных вы получите InvalidCastException. static void Main(string[] args) { … // Ой! Исключение времени выполнения! Console.WriteLine("Значение вашего int: {0}", (short)myInts[0]); Console.ReadLine(); } В идеальной ситуации компилятор C# должен решать проблемы некорректных операций восстановления из объектного образа во время компиляции, а не в среде выполнения. В связи с этим, в действительно идеальной ситуации, можно было бы сохранить типы, характеризуемые значениями, в контейнере, который не требовал бы преобразования в объект. В .NET 2.0 обобщения дают решение именно этих проблем. Однако перед тем как углубиться в детали использования обобщений, давайте посмотрим, как программисты пытались бороться с этими проблемами в .NET 1.x. с помощью строго типизованных коллекций. Типовая безопасность и строго типизованные коллекции В мире .NET, существовавшем до появления версии 2.0, программисты попытались решить проблемы типовой безопасности с помощью построения пользовательских строго типизованных коллекций. Для примера предположим, что вы хотите создать пользовательскую коллекцию, которая сможет содержать только объекты типа Person (персона). public class Person { // Определены открытыми для простоты. public int currAge; public string fName, lName; public Person(){} public Person(string firstName, string lastName, int age) { currAge = age; fName = firstName; lName = lastName; } public override string ToString() { return string.Format("Возраст {0}, {1} равен (2}", lName, fName, currAge); } } Чтобы построить коллекцию персон, можно определить член-переменную System.Collections.ArrayList в рамках класса PeopleCollection и настроить все члены на работу со строго типизованными объектами Person, а не с общими объектами System.Object. public class PeopleCollection: IEnumerable { private ArrayList arPeople = new ArrayList(); public PeopleCollection(){} // Преобразование для вызывающей стороны. public Person GetPerson(int pos) { return (Person)arPeople[pos]; } // Вставка только типов Person. public void AddPerson(Person p) { arPeople.Add(p); } public void ClearPeople() { arPeople.Clear(); } public int Count { get { return arPeople.Count; } } // Поддержка foreach нумератора. IEnumerator IEnumerable.GetEnumerator() { return arPeople.GetEnumerator(); } } С такими определениями типов вы будете уверены в типовой безопасности, поскольку теперь компилятор C# сможет распознать любую попытку вставки неподходящего типа, static void Main (string[] args) { Console.WriteLine("***** Custom Person Collection *****\n"); PeopleCollection myPeople = new PeopleCollection(); myPeople.AddPerson(new Person("Homer", "Simpson", 40)); myPeople.AddPerson(new Person("Marge", "Simpson", 38)); myPeople.AddPerson(new Person("Lisa", "Simpson", 9)); myPeople.AddPerson(new Person("Bart", "Simpson", 7)); myPeople.AddPerson(new Person("Maggie", ''Simpson", 2)); // Это приведет к ошибке компиляции! myPeople.AddPerson(new Car()); foreach (Person p in myPeople) Console.WriteLine(p); Console.ReadLine(); } Хотя пользовательские коллекции и гарантируют типовую безопасность, при использовании этого подхода приходится создавать новые (и почти идентичные) пользовательские коллекции для каждого из соответствующих типов. Поэтому если вам понадобится пользовательская коллекция, которая должна работать только с классами, являющимися производными базового класса Car (автомобиль), вам придется построить очень похожий тип. public class CarCollection: IEnumerable { private ArrayList arCars = new ArrayList(); public CarCollection(){} // Преобразование для вызывающей стороны. public Car GetCar(int pos) { return (Car) arCars[pos]; } // Вставка только типов Car. public void AddCar(Car C) { arCars.Add(c); } public void ClearCars() { arCars.Clear(); } public int Count { get { return arCars.Count; } } // Поддержка foreach нумератора. IEnumerator IEnumerable.GetEnumerator() { return arCars.GetEnumerator(); } } Вы, наверное, знаете из своего собственного опыта, что процесс создания множества строго типизованных коллекций для учета различных типов является не только трудоемким, но просто кошмарным для последующего обслуживания. Обобщенные коллекции позволяют отложить указание спецификации содержащегося типа до времени создания. Пока что не слишком беспокойтесь о синтаксических деталях. Рассмотрите следующий программный код, в котором используется обобщенный класс с именем System.Collections.Generic.List‹› для создания двух контейнерных объектов, обеспечивающих типовую безопасность. static void Main(string [] args) { // Использование обобщенного типа List только для Person. List‹Person› morePeople = new List‹Person›(); morePeople.Add(new Person()); // Использование обобщенного типа List только для Car. List‹Car› moreCars = new List‹Car›(); // Ошибка компиляции! moreCars.Add(new Person()); } Проблемы создания объектных образов и строго типизованные коллекции Строго типизованные коллекции можно найти в библиотеках базовых классов .NET и это очень полезные программные конструкции. Однако эти пользовательские контейнеры мало помотают в решении проблем создания объектных образов. Даже если вы создадите пользовательскую коллекцию с именем IntCollection, предназначенную для работы только с типами данных System.Int32, вам придется создать объект некоторого типа для хранения самих данных (System.Array, System.Collections.ArrayList и т.п.). public class IntCollection: IEnumerable { private ArrayList arInts = new ArrayList(); public IntCollection() {} // Восстановление значения для вызывающей стороны. public int GetInt(int pos) { return (int)arInts[pos]; } // Операция создания объектного образа! public void AddInt(int i) { arInts.Add(i); } public void ClearInts() { arInts.Clear(); } public int Count { get { return arInts.Count; } } IEnumerator IEnumerable.GetEnumerator() { return arInts.GetEnumerator(); } } Вне зависимости от того, какой тип вы выберете для хранения целых чисел (System.Array, System.Collections.ArrayList и т.п.), вы не сможете избавиться от проблемы .NET 1.1, связанной с созданием объектных образов. Нетрудно догадаться, что здесь снова на помощь приходят обобщения. В следующем фрагменте программного кода тип System.Collections.Generic.List‹› используется для создания контейнера целых чисел, не имеющего проблем создания объектных образов и восстановлений значений при вставке и получении типов характеризуемых значений. static void Main (string [] args) { // Баз создания объектного образа! List‹int› myInts = new List‹int›(); myInts.Add.(5); // Без восстановления значения! int i = myInts[0]; } Просто в качестве подтверждения рассмотрите следующий CIL-код для этого метода Main() (обратите внимание да отсутствие в нем каких бы то ни было блоков box и unbox). .method private hidebysig static void Main(string[] args) cil managed { .entrypoint // Code size 24 (0x18) .maxstack 2 .locals init ([0] class [mscorlib] System.Collections.Generic.List`1‹int32› myInts, [1] int32 i) IL_0000: nop IL_0001: newobj instance void class [mscorlib] System.Collections.Generic.List`1‹int32›::.ctor() IL_0006: stloc.0 IL_0007: ldloc.0 IL_0008: ldc.i4.5 IL_0009: callvirt instance void class [mscorlib]System.Collections.Generic.List`1‹int32›::Add(!0) IL_000e: nop IL_000f: ldloc.0 IL_0010: ldc.i4.0 IL_0011: callvirt instance !0 class [mscorlib]System.Collections.Generic.List`1‹int32›::get_Item(int32) IL_0016: stloc.1 IL_0017: ret } // end of method Program::Main Теперь, когда вы имеете лучшее представление о роли обобщений в .NET2.0, мы с вами готовы углубиться в детали. Для начала мы формально рассмотрим пространство имен System.Collections.Generic. Исходный код. Проект CustomNonGenericCollection размещен в подкаталоге, соответствующем главе 10. Пространство имен System.Collections.Generic Обобщенные типы присутствуют во многих библиотеках базовых классов .NET 2.0, но пространство имен System.Collections.Generic буквально наполнено ими (что вполне соответствует его названию). Подобно своему "родственнику" без обобщений (System.Collections), пространство имен System.Collections. Generic содержит множество типов класса и интерфейса, что позволяет вкладывать элементы в самые разные контейнеры. Совсем не удивительно, что обобщенные интерфейсы имитируют соответствующие необобщенные типы из пространства имен System.Collections. • ICollection‹T› • IComparer‹T› • IDictionary‹K, V› • IEnumerable‹T› • IEnumerator‹T› • IList‹T› Замечание. По соглашению для обобщенных типов их замещаемые параметры обозначаются буквами верхнего регистра. И хотя здесь допустимо использовать любые буквы (или слова), обычно используют Т для обозначения типов, К – для ключей, а V – для значений. В пространстве имен System.Collections.Generic определяется и ряд классов, реализующих многие из этих ключевых интерфейсов. В табл. 10.1 представлены описания базовых типов класса из этого пространства имен, реализуемые ими интерфейсы и соответствующие типы из пространства имен System.Collections. В пространстве имен System.Collections.Generic также определяется целый ряд "вспомогательных" классов и структур для работы с конкретными контейнерами. Например, тип LinkedListNode‹T› представляет узел в обобщенном LinkedList‹T›, исключение KeyNotFoundException возникает при попытке доступа к элементу контейнера с несуществующим ключом и т.д. Как видно из табл. 10.1, многие обобщенные классы коллекции имеют необобщенные аналоги в пространстве имен System.Collections (иногда даже с одинаковыми именами). В главе 7 было показано, как работать с такими необобщенными типами, поэтому дальше не предполагается рассматривать все их обобщенные "дубликаты". Мы рассмотрим только List‹T›, чтобы проиллюстрировать приемы использования обобщений. Если вам нужны подробности о других элементах пространства имен System.Collections.Generic, обратитесь к документации .NET Framework 2.0. Таблица 10.1. Классы System.Collections.Generic
Тип List‹T› Подобно необобщенным классам, обобщенные классы являются объектами, размещаемыми в динамической памяти, поэтому для них следует использовать new со всеми необходимыми аргументами конструктора. Кроме того, вы должны указать типы, замещающие параметры, определенные обобщенным типом. Так, для System.Collections.Generic.List‹T› требуется указать одно значение, задающее вид элемента, с которым будет функционировать List‹T›. Например, чтобы создать три объекта List‹› для хранения целых чисел, объектов SportsCar и объектов Person, вы должны записать следующее static void Main(string[] args) { // Создается List для хранения целых чисел. List‹int› myInts = new List‹int›(); // Создается List для хранения объектов SportsCar. List‹SportsCar› myCars = new List‹SportsCar›(); // Создается List для хранения объектов Person. List‹Person› myPeople = new List‹Person›(); } В этот момент вы можете поинтересоваться, что же на самом деле становится значением заполнителя. Открыв окно определения программного кода в Visual Studio 2005 (см. главу 2), вы увидите, что везде в определении типа List‹T› используется заполнитель Т. Ниже показана часть соответствующего листинга (обратите внимание на элементы, выделенные полужирным шрифтом). // Часть листинга для типа List‹T›. namespace System.Collections.Generic { public class List‹T›: IList‹T›, ICollection‹T›, IEnumerable‹T›, IList, ICollection, IEnumerable { … public void Add(T item); public IList‹T› AsReadOnly(); public int BinarySearch(T item); public bool Contains(T item); public void CopyTo(T[] array); public int FindIndex(System.Predicate‹T› match); public T FindLast(System.Predicate‹T› match); public bool Remove(T item); public int RemoveAll(System.Predicate‹T› match); public T[] ToArray(); public bool TrueForAll(System.Predicate‹T› match); public T this[int index] { get; set; } … } } Когда вы создаете тип List‹T› и указываете для него SportsCar, это эквивалентно следующему определению типа List‹T›. namespace System.Collections.Generic { public class List‹SportsCar›: IList‹SportsCar›, ICollection‹SportsCar›, IEnumerable‹SportsCar›, IList, ICollection, IEnumerable { … public void Add(SportsCar item); public IList‹SportsCar› AsReadOnly(); public int BinarySearch(SportsCar item); public bool Contains(SportsCar item); public void CopyTo(SportsCar[] array); public int FindIndex(System.Predicate‹SportsCar› match); public SportsCar FindLast(System.Predicate‹SportsCar› match); public bool Remove(SportsCar item); public int RemoveAll(System.Predicate‹SportsCar› match); publiс SportsCar[] ToArray(); public bool TrueForAll(System.Predicate‹SportsCar› match); public SportsCar this[int index] { get; set; } … } } Конечно, когда вы создаете обобщенный List‹T›, нельзя сказать, что компилятор буквально создает совершенно новую реализацию типа List‹T›. Он обращается только к тем членам обобщенного типа, которые вы вызываете фактически. Чтобы пояснить это, предположим, что вы используете List‹T› для объектов SportsCar так. static void Main(string[] args) { // Проверка List, содержащего объекты SportsCars. List‹SportsCar› myCars = new List‹SportsCar›(); myCars.Add(new SportsCar()); Console.WriteLine("Your List contains {0}", myCars.Count); } Если с помощью ildasm.exe проверить генерируемый CIL-код, обнаружатся следующие подстановки. .method private hidebysig static void Main(string[] args) cil managed { .entrypoint .maxstack 2 .locals init ([0] class [mscorlib] System.Collections.Generic.'List`1'‹class SportsCar› myCars) newobj instance void class [mscorlib]System.Collections.Generic.'List`1'‹class SportsCar›::.ctor() stloc.0 ldloc.0 newobj instance void CollectionGenerics.SportsCar::.ctor() callvirt instance void class [mscorlib]System.Collections.Generic.'List`1'‹class SportsCar›::Add(!0) nop ldstr "Your List contains {0} item(s)." ldloc.0 callvirt instance int32 class [mscorlib] System.Collections.Generic.'List`1' ‹class SportsCar›::get_Count() box [mscorlib] System.Int32 call void [mscorlib]System.Console::WriteLine(string, object) nop ret } Теперь, после изучения процесса использования обобщенных типов из библиотек базовых классов, в оставшейся части главы мы рассмотрим вопросы создания обобщенных методов, типов и коллекций. Создание обобщенных методов Чтобы научиться интегрировать обобщения в проекты, мы начнем с простого примера обычной подпрограммы свопинга. Целью этого примера является построение метода обмена, который сможет работать c любыми типами данных (характеризуемыми значениями или ссылками), используя для этого один параметр типа. В силу самой природы алгоритмов свопинга входные параметры будут посылаться по ссылке (с помощью ключевого слова C# ref). Вот соответствующая полная реализация. // Этот метод переставляет любые два элемента, // определенные параметром типа ‹Т›. static void Swap‹T›(ref T a, ref Т b) { Console.WriteLine ("Методу Swap () передано {0}", typeof(T)); Т temp; temp = а; а = b; b = temp; } Обратите внимание на то, что обобщенный метод определяется с помощью указания параметра типа, размещаемого после имени метода, но перед списком параметров. Здесь вы заявляете, что метод Swap() может работать с любыми двумя параметрами типа ‹Т›. Просто для информации вы выводите имя типа соответствующего заменителя на консоль с помощью оператора C# typeof(). Теперь рассмотрите следующий метод Main(), в котором происходит обмен между целочисленными и строковыми типами. static void Main(string[] args) { Console.WriteLine("***** Забавы с обобщениями *****\n"); // Обмен между двумя целыми. int а = 10, b = 90; Console.WriteLine("До обмена: {0}, {l}", а, b); Swap‹int›(ref a, ref b); Console.WriteLine("После обмена: {0}, {1}", а, b); Console.WriteLine(); // Обмен между двумя строками. string s1 = "Hello", s2 = "There"; Console.WriteLine("До обмена: {0} {1}!", s1, s2); Swap‹string›(ref s1, ref s2); Console.WriteLine("После обмена: {0} {1}!", s1, s2); Console.ReadLine(); } Пропуск параметров типа При вызове обобщенных методов, подобных Swap‹T›, у ваc есть возможность не указывать параметр типа, но только в том случае, когда обобщенный метод требует указания аргументов, поскольку тогда компилятор может "выяснить" тип этих аргументов на основе вводимых параметров. Например, можно переставить два типа System.Boolean так. // Компилятор будет предполагать System.Boolean. bool b1 = true, b2 = false; Console.WriteLine("До обмена: {0}, {1}", b1, b2); Swap(ref b1, ref b2); Console.WriteLine("После обмена: {0}, {1}", b1, b2); Но если, например, у вас есть обобщённый метод с именем DisplayBaseClass‹T›, не имеющий входных параметров, как показано ниже: static void DisplayBaseClass‹T›() { Console.WriteLine("Базовым классом {0} является: {1}.", typeof(T), typeof(Т).BaseType); } то при вызове этого метода вы должны указать параметр типа. static void Main(string[] args) { … // Если метод не имеет параметров, // необходимо указать параметр типа. DisplayBaseClass‹int›(); DisplayBaseClass‹string›(); // Ошибка компиляции! // Нет параметров? Тогда должен быть заполнитель! DisplayBaseClass(); … } 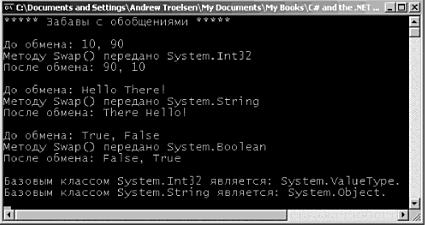 Рис. 10.1. Обобщенные методы в действии В данном случае обобщенные методы Swap‹T› и DisplayBaseClass‹T› были определены в рамках объекта приложения (т.е. в рамках типа, определяющего метод Main()). Если вы предпочтете определить эти члены в новом типе класса (MyHelperClass), то должны записать следующее. public class MyHelperClass { public static void Swap‹T›(ref T a, ref T b) { Console.WriteLine("Методу Swap() передано {0}", typeof(T)); T temp; temp = a; a = b; b = temp; } public static void DisplayBaseClass‹T›() { Console.WriteLine("Базовым классом {0} является: {1}.", typeof(T), typeof(T).BaseType); } } Обратите внимание на то, что тип MyHelperClass сам по себе не является обобщенным, но определяет два обобщенных метода. Так или иначе, теперь, когда методы Swap‹T› и DisplayBaseClass‹T› находятся в контексте нового типа класса, при вызове их членов придется указать имя типа. MyHelperClass.Swap‹int›(ref a, ref b); Наконец, обобщенные методы не обязаны быть статическими. Если бы Swap‹T› и DisplayBaseClass‹T› были методами уровня экземпляра, нужно было бы просто создать экземпляр MyHelperClass и вызвать их из объектной переменной. MyHelperClass с = new MyHelperClass(); c.Swap‹int›(ref a, ref b); Создание обобщенных структур (и классов) Теперь, когда вы понимаете, как определять и вызывать обобщенные методы, давайте рассмотрим построение обобщенных структур (процедура построения обобщенных классов оказывается аналогичной). Предположим, что мы построили гибкую структуру Point, поддерживающую один параметр типа, который представляет единицу хранения координат (х, у). Вызывающая сторона может создавать типы Point‹T› так. // Point с использованием int. Point‹int› p = new Point‹int›(10, 10); // Point с использованием double. Point‹double› p2 = new Point‹double›(5.4, 3.3); Вот полное определение Point‹T›, необходимое нам для дальнейшего анализа. // Обобщенная структура Point. public struct Point‹T› { // Обобщенные данные private T xPos; private T yPos; // Обобщенный конструктор. public Point (T xVal, T yVal) { xPos = xVal; yPos = yVal; } // Обобщенные свойства. public T X { get {return xPos;} set {xPos = value;} } public T Y { get { return yPos; } set { yPos = value; } } public override string ToString() { return string.Format("[{0}, {1}]", xPos, yPos); } // Переустановка полей со значениями параметра типа, // принятыми по умолчанию. public void ResetPoint() { xPos = default(T); yPos = default(T); } } Ключевое слово default в обобщенном программном коде Как ведите, Point‹T› использует параметр типа в определении полей данных, аргументов конструктора и в определениях свойств. Обратите внимание на то, что вдобавок к переопределению ToString() обобщенный тип Point‹T› определяет метод ResetPoint(), в котором используется новый синтаксис. // Ключевое слово 'default' в C# 2005 является перегруженным. // При использовании с обобщениями оно представляет значение // параметра типа, принимаемое по умолчанию. public void ResetPoint() { xPos = default(Т); yPos = default(T); } В C# 2005 ключевое слово default получило два значения. Кроме использования в конструкции switch, оно может использоваться для установки параметрам типа значений, принятых по умолчанию. И это, очевидно, полезно, поскольку обобщенный тип ничего заранее не знает о фактических замещающих значениях и поэтому не может с безопасностью предполагать о том. каким должно быть значение по умолчанию. Значения по умолчанию для параметра типа являются следующими. • Для числовых значений значением по умолчанию является 0. • Для ссылочных типов значением по умолчанию является null. • Поля структуры устанавливаются равными 0 (для типов, характеризуемых значениями) или null (для ссылочных типов). Для Point‹T› вы можете непосредственно установить xPos и yPos равными 0, поскольку вполне безопасно предполагать, что вызывающая сторона будет поставлять только числовые данные. Однако с помощью синтаксиса default(T) вы можете сделать обобщенный тип более гибким. В любом случае вы теперь можете использовать методы Point‹T› так. static void Main(string[] args) { Console.WriteLine("***** Забавы с обобщениями *****\n"); // Point с использованием int. Point‹int› p = new Point‹int›(10, 10); Console.WriteLine("p.ToString()={0}", p.ToString()); p.ResetPoint(); Console.WriteLine("p.ToString()={0}", p.ToString()); Console.WriteLine(); // Point с использованием double. Point‹double› p2 = new Point‹double›(5.4, 3.3); Console.WriteLine("p2.ToString()={0}", p2.ToString()); p2.ResetPoint(); Console.WriteLine("p2.ToString()={0}", p2.ToString()); Console.WriteLine(); // Обмен двух Point. Point‹int› pointA = new Point‹int›(50, 40); Point‹int› pointB = new Point‹int›(543, 1); Console.WriteLine("До обмена: {0}, {1}", pointA, pointB); Swap‹Point‹int> >(ref pointA, ref pointB); Console.WriteLine("После обмена: {0}, {1}", pointA, pointB); Console.ReadLine(); } Соответствующий вывод показан на рис. 10.2.  Рис. 10.2. Использование обобщённого типа Point Исходный код. Проект SimpleGenerics размещен в подкаталоге, соответствующем главе 10. Создание пользовательских обобщенных коллекций Итак, пространство имен System.Collections.Generic предлагает множество типов, позволяющих создавать эффективные контейнеры, удовлетворяющие требованиям типовой безопасности. С учетом множества доступных вариантов очень велика вероятность того, что в .NET 2.0 у вас вообще не возникнет необходимости в построении пользовательских типов коллекции. Тем не менее, чтобы показать, как строится обобщенный контейнер, нашей следующей задачей будет создание обобщенного класса коллекции, который мы назовем CarCollection‹Т›. Подобно созданному выше необобщенному типу CarCollection, наш новый вариант будет использовать уже существующий тип коллекции для хранения своих элементов (в данном случае это List‹›). Будет реализована и поддержка цикла foreach путем реализации обобщенного интерфейса IEnumerable‹›. Обратите внимание на то, что IEnumerable‹› расширяет необобщенный интерфейс IEnumerable, поэтому компилятор ожидает, что вы реализуете две версии метода GetEnumerator(). Вот как может выглядеть соответствующая модификация. public class CarCollection‹T›: IEnumerable‹T› { private List‹T› arCars = new List‹T›(); public T GetCar(int pos) { return arCars[pos]; } public void AddCar(T c) { arCars.Add(c); } public void ClearCars() { arCars.Clear(); } public int Count { get { return arCars.Count; } } // IEnumerable‹T› расширяет IEnumerable, поэтому // нужно реализовать обе версии GetEnumerator(). IEnumerator‹T› IEnumerable‹Т›.GetEnumerator() { return arCars.GetEnumerator(); } IEnumerator IEnumerable.GetEnumerator() { return arCars.GetEnumerator(); } } Этот обновленный тип CarCollection‹T› можно использовать так. static void Main(string[] args) { Console.WriteLine("* Пользовательская обобщенная коллекция *\n"); // Создание коллекции объектов Car. CarCollection‹Car› myCars = new CarColleetion‹Car›(); myCars.AddCar(new Car("Rusty", 20)); myCars.AddCar(new Car("Zippy", 90)); foreach(Car c in myCars) { Console.WriteLine("PetName: {0}, Speed: {1}", с.PetName, с.Speed); } Console.ReadLine(); } Здесь создается тип CarCollection‹T›, который должен содержать только типы Car. Снова заметим, что того же результата можно достичь и с помощью непосредственного использования типа List‹T›. Плавным преимуществом данного подхода является то, что теперь вы можете добавлять в CarCollection уникальные методы, делегирующие запросы к внутреннему типу List‹T›. Установка ограничений для параметров типа с помощью where В настоящий момент класс CarCollection‹T› привлекает нас только открытыми методами с уникальными именами. Кроме того, пользователь объекта может создать экземпляр CarCollection‹T› и указать практически любой параметр типа. // Это синтаксически корректно, но выглядит, // по крайней мере, странно… CarCollection‹int› myInts = new CarCollection‹int›(); myInts.AddCar(5); myInts.AddCar(11); Чтобы проиллюстрировать другую форму типичного непредусмотренного использования объекта, предположим, что вы создали два новых класса – SportsCar (спортивная машина) и MiniVan (минивэн), – которые являются производными от Car. public class SportsCar: Car { public SportsCar(string p, int s): base(p, s){} // Дополнительные методы для SportsCar. } public class MiniVan: Car { public MiniVan(string p, int a): base(p, s) {} // Дополнительные методы для MiniVan. } В соответствии с законами наследования, в коллекцию CarCollection‹T›, созданную с параметром типа Car, можно добавлять и типы MiniVan и SportsCar. // CarCollection‹Car› может хранить любой тип, производный от Car. CarCollection‹Car› myCars = new CarCollection‹Car›(); myInts.AddCar(new MiniVan("Family Truckster", 55); myInts.AddCar(new SportsCar("Crusher", 40)); Это синтаксически корректно, но что делать, если вдруг понадобится добавить в CarCollection‹T› новый открытый метод, например, с именем PrintPetName()? Такая задача кажется простой – достаточно получить доступ к подходящему элементу из List‹T› и вызвать свойство PetName. // Ошибка! // System.Объект не имеет свойства о именем PetName. public void PrintPetName(int pos) { Console.WriteLine(arCars[pos].PetName); } Однако в таком виде программный код скомпилирован не будет, поскольку истинная суть ‹Т› еще не известна, и вы не можете с уверенностью утверждать, что какой-то элемент типа List‹T› будет иметь свойство PetName. Когда параметр типа не имеет никаких ограничений (как в данном случае), обобщенный тип называется свободным (unbound). По идее параметры свободного типа должны иметь только члены System.Object (которые, очевидно, не имеют свойства PetName). Вы можете попытаться "обмануть" компилятор путем преобразования элемента, возвращенного из Метода индексатора List‹T›, в строго типизованный объект Car, чтобы затем вызвать petName возвращенного объекта. // Ошибка! // Нельзя превратить тип 'Т' в 'Car'! public void PrintPetName(int pos) { Console.WriteLine(((Car)arCars[pos]).PetName); } Но это тоже не компилируется, поскольку компилятор не знает значения параметра типа ‹Т› и не может гарантировать, что преобразование будет законным. Для решения именно таких проблем обобщения .NET могут опционально определяться с ограничениями, для чего используется ключевое слово where. В .NET 2.0 обобщения могут иметь ограничения, описанные в табл. 10.2. Таблица 10.2. Возможные ограничения обобщений для параметров типа
При наложении ограничений с помощью ключевого слова where список ограничений размещается после имени базового класса обобщенного типа и списка интерфейсов. В качестве конкретных примеров рассмотрите следующие ограничения обобщенного класса MyGenericClass. // Вложенные элементы должны иметь конструктор, // заданный по умолчанию. public class MyGenericClass‹T› where T: new() {…} // Вложенные элементы должны быть классами, реализующими IDrawable // и поддерживающими конструктор, заданный по умолчанию. public class MyGenericClass‹T› where T: class, IDrawable, new() {…} // MyGenericClass получается из МуВаsе и реализует ISomeInterface, // а вложенные элементы должны быть структурами. public class MyGenericClass‹T›: MyBase, ISomeInterface where T: struct {…} При построении обобщенного типа, в котором указано несколько параметров типа, вы можете указать уникальный набор ограничений для каждого из таких параметров. // ‹К› должен иметь конструктор, заданный по умолчанию, // а ‹Т› должен реализовывать открытый интерфейс IComparable. public class MyGenericClass‹K, T› where K: new() where T: IComparable‹T› {…} Если вы хотите изменить тип CarCollection‹T› так, чтобы в него можно было поместить только производные от Car, вы можете записать следующее. public' class CarCollection‹T›: IEnumerable‹T› where T: Car { public void PrintPetName(int роs) { // Поскольку теперь все элементы должны быть из семейства Car, // свойство PetName можно вызывать непосредственно. Console.WriteLine(arCars[pos].PetName); } } При таких ограничениях на CarCollection‹T› реализация PrintPetName() становится очень простой, поскольку теперь компилятор может предполагать, что ‹Т› является производным от Car. Более того, если указанный пользователем параметр типа не совместим с Car, будет сгенерирована ошибка компиляции. // Ошибка компиляции! CarCollection‹int› myInts = new CarCollection‹int›(); Вы должны понимать, что обобщенные методы тоже могут использовать ключевое слово where. Например, если нужно гарантировать, чтобы методу Swap(), созданному в этой главе выше, передавались только типы, производные от System. ValueType, измените свой программный код так. // Этот метод переставит любые типы, характеризуемые значениями. static void Swap‹T›(ref Т а, ref T b) where T: struct { … } Следует также понимать то, что при таком ограничении метод Swap() уже не сможет переставлять строковые типы (поскольку они являются ссылочными). Отсутствие поддержки ограничений при использовании операций При создании обобщенных методов для вас может оказаться сюрпризом появление ошибок компилятора, когда с параметрами типа используются операции C# (+, -, *, == и т.д.). Например, я уверен, вы сочли бы полезными классы Add(), Subtract(), Multiply() и Divide(), способные работать с обобщенными типами. // Ошибка компиляции! // Нельзя применять операции к параметрам типа! public class BasicMath‹T› { public T Add(T arg1, T arg2) { return arg1 + arg2; } public T Subtract(T arg1, T arg2) { return arg1 – arg2; } public T Multiply(T arg1, T arg2) { return arg1 * arg2; } public T Divide(T arg1, T arg2) { return arg1 / arg2; } } Как ни печально, этот класс BasicMath‹T› не компилируется. Это может показаться большим ограничением, но не следует забывать, что обобщения являются обобщениями. Конечно, тип System.Int32 может прекрасно работать с бинарными операциями C#. Однако, если, например, ‹T› будет пользовательским классом иди типом структуры, компилятор не сможет сделать никаких предположений о характере перегруженных операций +, -, * и /. В идеале C# должен был бы позволять обобщенному типу ограничения с использованием операций, например, так. // Только для иллюстрации! // Этот программный код не является допустимым в C# 2.0. public class BasicMath‹T› where T: operator +, operator -, operator *, operator / { public T Add(T arg1, T arg2) { return arg1 + arg2; } public T Subtract(T arg1, T arg2) { return arg1 – arg2; } public T Multiply(T arg1, T arg2) { return arg1 * arg2; } public T Divide(T arg1, T arg2) { return arg1 / arg2; } } Увы, ограничения обобщенных типов при использовании операций в C# 2005 не поддерживаются. Исходный код. Проект CustomGenericCollection размещен в подкаталоге, соответствующем главе 10. Создание обобщенных базовых классов Перед рассмотрением обобщенных интерфейсов следует указать на то, что обобщенные классы могут быть базовыми для других классов и могут таким образом определять любое число виртуальных и абстрактных методов. Однако производные типы должны подчиняться определенным правилам, вытекающим из природы обобщенной абстракции. Во-первых, если обобщенный класс расширяется необобщенным, то производный класс должен конкретизировать параметр типа, // Предположим, что создан пользовательский // обобщенный класс списка. public class MyList‹T› { private List‹T› listOfData = new List‹T›(); } // Конкретные типы должны указать параметр типа, // если они получаются из обобщенного базового класса. public class MyStringList: MyList‹string› {} Кроме того, если обобщенный базовый класс определяет обобщенные виртуальные или абстрактные методы, производный тип должен переопределить эти обобщенные методы, используя конкретизированный параметр типа. // Обобщенный класс с виртуальным методом. public class MyList‹T› { private List‹T› listOfData = new List‹T›(); public virtual void PrintList(T data) {} } public class MyStringList: MyList‹string› { // В производных методах нужно заменить параметр типа, // используемый а родительском классе. public override void PrintList(string data) {} } Если производный тип тоже является обобщенным, дочерний класс может (опционально) использовать заменитель типа в своем определении. Однако знайте, что любые ограничения, размещенные в базовом классе, должны "учитываться" и производным типом. Например: // Обратите внимание, теперь здесь имеется ограничение, // требующее конструктор по умолчанию. public class MyList‹T› where T: new() { private List‹T› listOfData = new List‹T›(); public virtual void PrintList(T data) {} // Производный тип должен учитывать ограничения базового. public class MyReadOnlyList‹T›: MyList‹T› where T: new() { public override void PrintList(T data) {} } Если вы только не планируете построить свою собственную библиотеку обобщений, вероятность того, что вам придется строить иерархии обобщенных классов, оказывается практически нулевой. Тем не менее, вы теперь знаете, что язык C# обеспечивает поддержку наследования обобщений. Создание обобщенных интерфейсов Вы уже видели при рассмотрении пространства имен System.Collections. Generiс, что обобщенные интерфейсы в C# также допустимы (например, IEnumerable‹Т›). Вы, конечно, можете определить свои собственные обобщенные интерфейсы (как с ограничениями, так и без ограничений). Предположим, что нужно определить интерфейс, который сможет выполнять бинарные операции с параметрами обобщенного типа. public interface IBinaryOperations‹T› { T Add(T arg1, T arg2); T Subtract(T arg1, T arg2); T Multiply(T arg1, T arg2); T Divide(T arg1, T arg2); } Известно, что интерфейсы остаются почти бесполезными, пока они не реализованы некоторым классом или структурой. При реализации обобщенного интерфейса поддерживающий его тип указывает тип заполнителя. public class BasicMath: IBinaryOperations‹int› { public int Add(int arg1, int arg2) { return arg1 + arg2; } public int Subtract(int arg1, int arg2) { return arg1 – arg2; } public int Multiply(int arg1, int arg2) { return arg1 * arg2; } public int Divide(int arg1, int arg2) { return arg1 / arg2; } } После этого вы можете использовать BasicMath, как и ожидали. static void Main(string[] args) { Console.WriteLine("***** Обобщенные интерфейсы *****\n"); BasicMath m = new BasicMath(); Console.WriteLine("1 + 1 = {0}", m.Add(1, 1)); Console.ReadLine(); } Если вместо этого требуется создать класс BasicMath, действующий на числа с плавающим десятичным разделителем, можно конкретизировать параметр типа так. public class BasicMath: IBinaryOperations‹double› { public double Add(double arg1, double arg2) { return arg1 + arg2; } … } Исходный код. Проект GenericInterface размещен в подкаталоге, соответствующем главе 10. Создание обобщенных делегатов Наконец, что не менее важно, .NET 2.0 позволяет определять обобщенные типы делегата. Предположим, например, что требуется определить делегат, который сможет вызывать любой метод, возвращающий void и принимающий один аргумент. Если аргумент может меняться, это можно учесть с помощью параметра типа. Для примера рассмотрим следующий программный код (обратите внимание на то, что целевые объекты делегата регистрируются как с помощью "традиционного" синтаксиса делегата, так и с помощью группового преобразования метода). namespace GenericDelegate { // Этот обобщенный делегат может вызвать любой метод, // возвращающий void и принимающий один параметр. public delegate void MyGenericDelegate‹T›(T arg); class Program { static void Main(string[] args) { Console.WriteLine("***** Обобщенные делегаты *****\n"); // Регистрация цели с помощью 'традиционного' // синтаксиса делегата. MyGenericDelegate‹string› strTarget = new MyGenericDelegate‹string›(StringTarget); strTarget("Некоторые строковые данные"); // Регистрация цели с помощью // группового преобразования метода. MyGenericDelegate‹int› intTarget = IntTarget; intTarget(9); Console.ReadLine(); } static void StringTarget(string arg) { Console.WriteLine("arg в верхнем регистре: {0}", arg.ToUpper()); } static void IntTarget(int arg) { Console.WriteLine("++arg: {0}", ++arg); } } } Обратите внимание на то. что MyGenericDelegate‹T› определяет один пара-метр типа, представляющий аргумент, отправляемый целевому объекту делегата. При создании экземпляра этого типа требуется конкретизировать значение параметра типа, а также имя метода, вызываемого делегатом. Так, если вы укажете строковый тип, то отправите целевому методу строковое значение. // Создание экземпляра MyGenericDelegate‹T› // со значением string для параметра типа. MyGenericDelegate‹string› strTarget = new MyGenericDelegate‹string›(StringTarget); strTarget("Некоторые строковые данные"); С учетом формата объекта strTarget метод StringTarget() должен теперь получить в качестве параметра одну строку. static void StringTarget(string arg) { Console.WriteLine("arg в верхнем регистре: {0}", arg.ToUpper()); } Имитация обобщенных делегатов в .NET 1.1 Как видите, обобщенные делегаты предлагают более гибкий подход для указания вызываемых методов. В рамках .NET 1.1 аналогичного результата можно достичь с помощью базового System.Object. public delegate void MyDelegate(object arg); Это позволяет посылать любой тип данных целевому объекту делегата, но при этом не гарантируется типовая безопасность, а кроме того, остаются нерешенными проблемы создания объектных образов. Предположим, например, что мы создали два экземпляра MyDelegate, которые указывают на один и тот же метод MyTarget. Обратите внимание на проблемы создания объектных образов и восстановления значений, а также на отсутствие гарантий типовой безопасности. class Program { static void Main(string[] args) { … // Регистрация цели с помощью // 'традиционного' синтаксиса делегата. MyDelegate d = new MyDelegate(MyTarget) d("Дополнительные строковые данные"); // Регистрация цели с помощью // группового преобразования метода. MyDelegate d2 = MyTarget; d2(9); // Проблема объектного образа. … } // Ввиду отсутствия типовой безопасности мы должны // определить соответствующий тип до преобразования. static void MyTarget(object arg) { if (arg is int) { int i = (int)arg; // Проблема восстановления значения. Console.WriteLine("++arg: {0}", ++i); } if (arg is string) { string s = (string) arg; Console.WriteLine("arg в верхнем регистре: {0}", s.ToUpper()); } } } Когда вы посылаете целевому объекту тип, характеризуемый значением, это значение (конечно же) "упаковывается" в объект и "распаковывается" после его получения целевым методом. Точно так же, поскольку поступающий параметр может быть всем чем угодно, вы должны динамически проверить соответствующий тип перед тем, как выполнить преобразование. С помощью обобщенных делегатов вы можете получить всю необходимую гибкость без "проблем". Несколько слов о вложенных делегатах Завершим эту главу рассмотрением еще одного аспекта обобщенных делегатов. Вы знаете, что делегаты могут быть вложены в тип класса, что должно означать тесную ассоциацию между этими двумя ссылочными типами. Если тип-контейнер при этом оказывается обобщенным, вложенный делегат может использовать в своем определении параметры типа. // Вложенные обобщающе делегаты могут иметь доступ к параметрам // обобщенного типа-контейнера. public class MyList‹T› { private List‹T› listOfData = new List‹T›(); public delegate void ListDelegate(T arg); } Исходный код. Проект GenericDetegate размещен в подкаталоге, соответствующем главе 10. Резюме Обобщения можно обоснованно считать главным из усовершенствований, предложенных в C# 2005. Как вы могли убедиться, обобщенный элемент позволяет указать "заполнители" (т.е. параметры типа), которые конкретизируются в момент создания типа (или вызова, в случае обобщенных методов). По сути, обобщения дают решение проблем объектных образов и типовой безопасности, усложняющих разработку программ в среде .NET 1.1. Чаще всего вы будете просто использовать обобщенные типы, предлагаемые библиотеками базовых классов .NET, но можно создавать и свои собственные обобщенные типы. При создании обобщенных типов можно указать любое число ограничений, чтобы повысить уровень типовой безопасности и гарантировать, что соответствующие операции будут выполняться с "известными величинами". |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Главная | Контакты | Нашёл ошибку | Прислать материал | Добавить в избранное |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||