|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
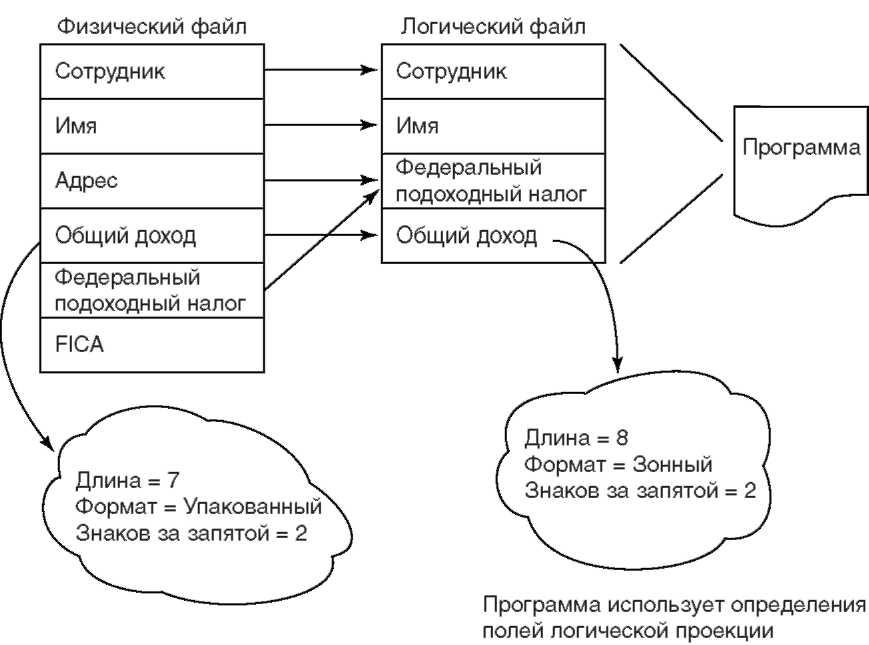
 Объекты базы данных Объекты базы данных  Области данных Области данных  Курсоры Курсоры Глава 6 Интегрированная база данных В сегодняшнем бизнесе конкуренция постоянно усиливается. Чтобы достичь успеха приходится производить больше продукции за меньшую стоимость и быстрее, чем раньше. В нашем стремительном мире остановиться — значит проиграть. Как сказал, однажды американский философ Йоги Берра (Yogi Berra), «рано быстро становится поздно». Очень часто выжить в условиях острой конкуренции помогают оперативные данные. Многие бизнесмены понимают теперь, что информация — возможно, самое ценное, что у них есть. Часто выборка, обновление и сохранение данных повседневной деятельности выполняются некоторой прикладной программой, например, бухгалтерской или приема заказов. Мы, специалисты, обычно, называем программы такого типа приложениями оперативной обработки транзакций OLTP (online transaction processing). Приложение OLTP часто интерактивно, то есть обновление данных происходит в процессе оперативных транзакций. Для легкого и быстрого доступа к оперативной информации сегодня ее обычно хранят в реляционной базе данных. Компьютерная революция позволила легко собирать и дешево хранить большие объемы оперативных данных. Многие компании хранят свои данные за многие годы, веря, что это может когда-нибудь пригодиться. Но у большинства из них остается вопрос: «Мы знаем, что внутри этих данных скрыта бесценная информация о наших рынках сбыта, товарах, услугах и клиентах. Но как извлечь эту информацию?» Традиционно, анализ данных в поисках необходимой информации выполнялся вручную. Но в последние несколько лет стало очевидно, что автоматизация анализа данных не только значительно облегчает этот процесс, но и экономически выгодна. Часто ПО анализа данных называют системами поддержки принятия решений (decision-support), и говорят о преобразовании данных сначала в информацию, а затем в знания. Словосочетания складирование данных (data warehousing) и разработка данных[ 46 ] (datamining), еще несколько лет назад известные лишь узким специалистам, стали частью повседневного словаря делового человека. Рассказы в прессе о компаниях, которым с помощью этих технологий удалось выйти на передовые позиции в своей отрасли, побудили многие фирмы следовать тем же путем. Хранилища данных, где накапливается информация из собранных оперативных данных, — возможно, одна из наиболее быстро распространяющихся информационных технологий для бизнеса. Некоторые консультанты предсказывают, что в следующие несколько лет примерно треть всех расходов на информационные технологии будет связана с ней. Какое отношение все это имеет к AS/400? Вероятно, в ближайшие несколько лет с помощью AS/400 будет реализовано больше хранилищ данных, чем с помощью какой-либо другой системы. Причина проста: именно DB2/400 — база данных AS/400 — наиболее широко используемая многопользовательская база данных во всем мире, и именно под ее управлением сосредоточен наибольший объем оперативных данных. Обычно, этот факт удивляет даже в заказчиков AS/400. IBM не продает DB2/400 как отдельный продукт, поэтому многие просто не знают о ее позициях на рынке и часто считают наиболее широко распространенными базы данных от Oracle, Sybase или Microsoft. Очень немногие знают о DB2/400. Учитывая объем данных, хранящихся в базах DB2/400, можно представить, сколь много хранилищ данных будет создано на AS/400. По оценке IBM более 60 процентов заказчиков AS/400 в следующие несколько лет станут использовать те или иные системы поддержки принятия решений. В этой главе мы рассмотрим все возрастающую роль баз данных и то, как AS/400 удается держать первенство в этой области. Мы остановимся также на истории DB2/400 и на том, как она интегрирована в AS/ 400. Но сначала, давайте разберемся, что такое DB2/400? База данных без имени Много лет назад мы решили интегрировать мощную реляционную базу данных в каждую System/38. Затем эта идея перекочевала и в AS/400. Мы считали, что способность полнофункциональной системы управления базой данных (СУБД) эффективно и надежно обрабатывать большие объемы информации, станет хорошей основой всех приложений для бизнеса. Вместо того, чтобы делать базу данных отдельным продуктом, мы просто встроили ее, даже не побеспокоившись об отдельном имени. Незаметно для глаз многие годы безымянная база данных тихо делала свое дело. В результате, даже не все наши заказчики (40 процентов, как показали проведенные несколько лет назад исследования) знают, что на них ежедневно работает такая мощная база данных. Это и хорошо, и плохо. Хорошо, что многие заказчики не предпринимали никаких специальных усилий для управления своей базой данных, а просто пользовались, не испытывая при этом никакой потребности в помощи администратора базы данных. (Этим база данных AS/400 отличается от некоторых других, для управления которыми требуется персонал). Плохо же то, что некоторые пользователи в один прекрасный день решили добавить на свои AS/400 базу данных, не зная, что она там уже есть. Действительно, пользователи почти всех современных компьютерах, включая ПК, отдельно покупают и интегрируют в систему реляционные базы данных. Поэтому, решили такие заказчики, несомненно, стоит потратиться и установить реляционную базу данных и на AS/400[ 47 ]. Кроме того, нам, сотрудникам IBM, было трудно объяснить, где собственно находится база данных AS/400, так как она не сосредоточена в одном месте. Интегрированная природа системы ведет к тому, что база распределена по всей системе. С другой стороны, обычные базы данных — это отдельные программные компоненты, работающие поверх ОС. Чтобы добраться до обычной базы данных, программе необходимо пройти через ОС или использовать совершенно отдельный интерфейс. Между тем, интегрированная частично над MI, и частично в SLIC, база данных AS/ 400 более эффективна, чем базы, построенные поверх существующих систем. База данных AS/400 тесно связана с другими компонентами системы и взаимодействует с ними способами, недоступными обычным базам. В 1994 году мы решили дать своей базе данных имя, выбрав «DB2 для OS/400» в отражение того, что наша база данных — часть семейства реляционных баз данных IBM DB2[ 48 ]. Фамильное сходство заключается, в основном, во внешних утилитах и поддержке распределенных баз данных. Внутренне каждый продукт реализован по-своему. Но имя DB2 все помогает устранить впечатление, что у AS/400 нет современной, надежной базы данных. Интегрированная база данных AS/400 решает проблемы бизнеса с помощью новейших информационных технологий. Рост популярности хранилищ данных и средств их обработки среди заказчиков AS/400 — доказательство мощности этой системы. Не приходится удивляться, что среди прочих новых технологий многие пользователи предпочитают именно ее. Давайте рассмотрим, как AS/400 поддерживает хранилища и обработку данных, а затем разберем некоторые фундаментальные концепции DB2/400. Хранилища данных Итак, мы убедились в важности для современного бизнеса оперативного хранения и использования данных и обсудили, чем в этом случае может помочь реляционная база данных. Оперативные данные динамичны, часто обновляются, оптимизированы для транзакций. Информационные данные — обобщают оперативные, обновляются редко (может быть даже никогда), и хранятся в форме, оптимизированной для принятия решений, отдельно от оперативных, зачастую даже на другой машине. Именно информационные данные и составляют хранилище данных. Следует ясно понимать, что хранилище данных — это концепция, а не конкретный продукт. Это набор средств для систематизации информационных данных, их хранения и анализа для принятия решений. Хранилище данных AS/400 состоит из четырех основных компонентов, а именно: средств трансформации и преобразования данных для заполнения хранилища; сервера базы данных; аналитических средств и программы пользовательского интерфейса; средств управления информацией о самом хранилище. Преобразование оперативных данных в информационные Создание хранилища данных требует преобразования оперативных данных в информационные. Для этого используются так называемые средства трансформации (transformation tools) или средства преобразования (propagation tools). Их задача — не просто извлечь данные из одной или нескольких оперативных баз, но и преобразовать их в форму, подходящую для хранения. Возьмем, например, оперативные данные оптового дистрибьютора по продажам. Каждая запись содержит информацию о размере партии проданного товара, форме оплаты и о покупателе. Так как данные находятся в формате, удобном для регистрации каждой транзакции, то их анализ посредством запросов может требовать слишком много времени, поскольку большинству аналитических программ не нужна информация по отдельным транзакциям. Программа может проанализировать собранные данные для прогноза потребностей в товарах, или для оценки доходов по сравнению с прошлым годом. Для анализа такого типа — быстрого выявления тенденций и потенциальных проблем — данные должны быть преобразованы. Аналитической программе нужна сводка информации из оперативной базы. Средства преобразования периодически собирают с компьютеров оперативные данные, трансформируют их в сводный формат и помещают в хранилище данных. Обратите внимание, что большинству аналитических программ не требуется постоянная синхронизация данных в хранилище и оперативных. Автоматическое обновление хранилища данных осуществляется с разной периодичностью: раз в неделю, раз в день или каждые 10 минут. Есть много программ как IBM, так и других производителей, позволяющих выбирать данные из баз (DB2 или других) и импортировать их непосредственно в склад данных AS/400. Серверы баз данных Несколько лет назад IBM представила специальные модели AS/400, названные серверными. Они созданы для работы в качестве серверов баз данных, серверов коммуникаций и пакетной обработки. В эти модели внесены улучшения, специально предназначенные для приложений хранилищ данных. Мы еще вернемся к серверным моделям, а сейчас давайте, подробней поговорим об улучшениях в DB2/400. Итак, два важнейших аспекта поддержки хранилищ данных — параллельная обработка и многомерные базы данных (MDD). Параллельная обработка Различные приемы параллельной обработки позволяют базе данных полностью задействовать все аппаратные возможности. Выборка и анализ больших объемов информации может требовать очень больших ресурсов. По счастью, при обработке базы данных доступ к ней может осуществляться параллельно, после чего собранные данные можно анализировать независимо и также параллельно. Обработка баз данных — один из примеров практического использования массового параллелизма, который мы вкратце затронули в главе 2. IBM несколько модифицировала AS/400 и DB2/400, что позволило применить массовый параллелизм при работе с базой данных. Впервые поддержка параллельной обработки ввода-вывода появилась в V3R1, что позволило воспользоваться возможностями аппаратной архитектуры AS/400, имеющей как основные процессоры, так и вспомогательные, и ввести параллельную обработку на уровне процессора ввода-вывода (IOP) для одного задания. Мы подробно рассмотрим IOP в главе 10, а сейчас, забегая вперед, скажу, что в мощной AS/400 их может быть установлено несколько сотен, причем к разным IOP подключают множество дисковых накопителей. Параллельный ввод-вывод позволяет обрабатывать пользовательский запрос к базе данных несколькими IOP одновременно. Таким образом, устраняется одна из самых серьезных проблем, мешающих многим системам достичь высокой производительности: задержки при выполнении ввода-вывода. В главе 2 мы говорили о поддержке SMP в AS/400, когда все основные процессоры работают параллельно с общей памятью. При большинстве видов обработки отдельные задания выполняются на разных процессорах, при необходимости используя общие области памяти. При обработке запросов к базе данных каждый основной процессор может обрабатывать часть задачи. Именно так работает средство параллельной обработки DB2/400. Запрос разбивается на отдельные, независимые подзапросы, которые выполняются параллельно несколькими основными процессорами, что позволяет значительно сократить время обработки. Задать использование нескольких процессоров при обработке запроса можно с помощью соответствующей опции команды «CHGQRYA» (Change Query Attribute). Данный метод повышает производительность таких запросов, как поиск в таблице, группирование (group-by), поиск в индексе и соединение (join). Поддержкой параллельной обработки базы данных на системах SMP пользуются также некоторые внутренние функции SLIC, например, построение индекса (подробно об этом мы поговорим в разделе «Машинный индекс»). Параллелизм присутствует на всех системах версий 3 и 4, но параллельное построение индекса — только на RISC-системах. AS/400 также поддерживает конфигурации MPP. При этом несколько систем AS/ 400 с помощью высокоскоростных линий соединяются друг с другом в кластер. Один из способов такого соединения — через волоконно-оптический кабель с помощью продукта OptiConnect. Для объединения машин серии AS/400е подходит также соединение SAN, позволяющее достичь еще больших скоростей. Распределение базы данных по дискам всех систем кластера позволяет создавать очень большие базы, с которыми параллельно работают несколько сотен процессоров. IBM называет такую конфигурацию MPP слабо связанной параллельной системой базы данных, в связи с отсутствием разделения памяти за пределами отдельной системы в кластере. Здесь используется подробно обсуждавшийся в главе 2 подход shared-nothing, похожий на тот, что применяется в SP2. Различие в том, что узлы кластера AS/400 находятся в разных физических корпусах, но, несмотря на это, для пользователя кластер выглядит как единая база данных. Технология слабо связанной параллельной базы данных позволяет разбивать запросы на части, с которыми может справиться отдельный узел. В отличии от SMP-па-раллельной базы данных, у каждого узла — собственные память и дисковое пространство. Каждый узел кластера работает с порцией физического файла или таблицы, и запрос к нему выполняется для соответствующей порции файла. Каждый узел может содержать один или несколько процессоров, ведь узел — это просто AS/400. Приложение, выполняющееся на любом компьютере кластера, может работать с базой так, как если бы она полностью размещалась на этом компьютере. Распределенность базы по узлам кластера делает DB2/400 прозрачной как для приложений, так и для конечного пользователя. Для задания имен системам в группе узлов в CL были введены новые команды, к некоторым командам были добавлены новые параметры для поддержки распределения файлов базы по узлам. После рассредоточения по узлам, файл при выполнении операций вставки, обновления и удаления выглядит как локальный. Главное преимущество слабо связанных параллельных систем — отсутствие верхнего предела количества узлов, что означает практически неограниченный рост производительности и емкости. Возможности расширения концепции кластеров AS/400 в будущем мы рассмотрим в главе 12. Многомерные базы данных (MDD) Реляционные базы данных организованы в виде двумерных таблиц. В MDD имеется одно или несколько дополнительных измерений. Например, Вам надо оценить свои доходы от продаж, рассмотрев в отдельности сводки по товарам, по регионам и по времени. В этом случае лучшую наглядность Вам обеспечит трехмерная структура данных со шкалой измерения по товарам на одной оси; временем в днях, неделях или месяцах — на второй; и географическими данными — на третьей. В результате получится куб, очень похожий на трехмерную электронную таблицу, в каждой ячейке которой — величина доходов от продажи. Далее можно использовать различные средства анализа продаж товаров в регионах в течение некоторого периода времени. AS/400 поддерживает многомерные структуры данных непосредственно в самой базе данных DB2/400 или с помощью продуктов, разработанных бизнес-партнерами. Преимущество многомерных структур данных состоит в возможности быстро получить ответ на поставленный вопрос в виде среза данных по любому измерению или прохода сквозь структуру для получения данных новых уровней. Поскольку время ответа на запросы обычно очень мало, такой многомерный анализ часто называют оперативной аналитической обработкой OLAP (on-line analytical processing). Иногда различным подразделениям одной организации требуются информационные данные в разных формах. Внутри MDD можно создавать специализированные хранилища данных (data mart), которые содержат информационные данные, соответствующие потребностям конкретного отдела или рабочей группы. В этом случае хранилище данных всей организации состоит из набора таких специализированных хранилищ для отдельных структурных единиц[ 49 ]. Анализ данных и инструментарий конечных пользователей Термином «интеллектуальный бизнес» (business intelligence) обозначают методы обработки информации, применяемые для принятия решений в бизнесе. Средства интеллектуального ведения бизнеса — это программные пакеты, используемые для анализа данных в хранилище данных на AS/400. Обычно, эти программы работают на ПК и способны обращаться к хранилищу данных на AS/400 напрямую. Есть три основных категории бизнес-информационных средств: программы поддержки принятия решений DSS (decision support system); управленческие информационные системы EIS (executive information system); средства разработки данных. Программы DSS позволяют конечному пользователю строить гипотезу и затем генерировать запросы для ее проверки. При этом предполагается, что у пользователя есть некое общее представление о том, что нужно найти в хранилище данных, и это позволяет ему выдавать произвольные запросы и генерировать отчеты. Это средства простейшего типа, так как они просто возвращают информацию по запросу пользователя. EIS объединяют средства поддержки принятия решений с некоторыми расширенными возможностями анализа. Обычно, они имеют доступ к средствам за пределами хранилища данных, например, могут использовать оперативные новости из Интернета для получения информации с мировых рынков. Как и DSS, EIS предполагает наличие у спрашивающего некоторого представления о том, что именно следует искать. И EIS, и DSS обеспечивают поиск нужной пользователю информации путем проверок. Но как быть, если Вы не можете четко сформулировать вопрос? Вы знаете, что в базе данных скрыта важная информация, но не можете придумать, как до нее добраться. Тогда Вам нужна разработка данных — средство принятия решений на основе открытий. Разработка данных позволяет отыскивать информацию при незначительном объеме указаний от пользователя или вовсе без таковых. Система выполняет поиск шаблонов и связей. На практике существует бесконечное множество вариантов такого способа поиска. Например, розничный торговец может использовать разработку данных для того, чтобы определить, какие товары покупаются вместе. Анализ и оценка привычек покупателей очень полезны при оценке спроса на товар, или выявлении групп покупателей с наивысшим потенциалом. Разработка данных используется также в банковском деле для выявления подделок кредитных карт: путем «просеивания» больших объемов информации можно выявлять отклонения от нормы. Технология разработки данных пришла из мира искусственного интеллекта. Средства IBM для поиска шаблонов и взаимосвязей данных комбинируют нейронные сети и статистические алгоритмы. Нейронная сеть поддерживает основной шаг разработки данных в процессе открытия знаний. Соответствующая технология была разработана в Рочестере в период проекта Fort Knox (подробнее об этом — в Приложении) и впервые появилась на рынке в начале 90-х годов в виде утилиты для AS/400. Теперь же она — основа всей разработки данных в IBM. Управление хранилищем данных Метаданные — это данные о данных. Они используются для управления хранилищем данных. Существуют две формы метаданных — технические и бизнес-данные. Первые содержат описания оперативной базы данных и хранилища данных, что позволяет перемещать данные из оперативной базы в хранилище. Бизнес-данные необходимы конечному пользователю для поиска информации в хранилище данных. Легче всего представить их себе как каталог информации о хранилище, в том числе об актуальности и источниках поступления этой информации. Бизнес-данные пользователь видит в терминах, принятых в его отрасли деятельности, и может позволить себе забыть о сложности нижележащей базы данных. Теперь, после рассмотрения способов использования новых технологий баз данных AS/400, мы можем перейти к фундаментальным концепциям DB2/400. Сначала рассмотрим историю этой замечательной базы данных. Эволюция реляционной базы данных Первая коммерческая база данных с реляционными возможностями появилась в System/38. Эта уникальная технология опережала другие реляционные базы примерно на три года, что позволило System/38 выйти на передовые позиции на рынке. Разработчики System/38 искали более эффективный способ обработки записей, по сравнению с System/3. Первая System/3 была разработана как машина единичных записей. Она поддерживала только пакетную обработку, то есть приложение должно было обработать все записи в файле одну за другой. Первые записи размещались на перфокартах, колода перфокарт составляла файл. Позднее, появилась возможность хранения файлов на диске, хотя обрабатывались они по-прежнему с помощью перфокарт. Типичное приложение единичных записей сначала сортировало записи в файле. Записи могли иметь несколько полей, содержащих такую информацию, как имя клиента, номер счета, номер детали и так далее. Выбиралось одно из этих полей, называемое ключом, и все записи сортировались по значению ключевого поля в определенном порядке. Механический сортировщик перфокарт в большинстве машин единичных записей использовался очень интенсивно. После сортировки файл обрабатывался последовательно, запись за записью, до конца. Позднее в System/3 была добавлена интерактивная обработка. Применение дисков позволило обращаться к записям в произвольном порядке. Поиск нужной записи осуществлялся с помощью индекса — небольшого файла, в котором каждой записи основного файла соответствуют лишь два поля. Первое содержит значение ключа, а второе — дисковый адрес записи с совпадающим значением. Для сортировки записей индекса по значениям ключа использовалась особая программа. Затем индекс сохранялся на диске вместе с основным файлом. Для поиска записи с заданным значением ключа система вначале просматривала индекс. После этого для выборки полной записи использовался дисковый адрес, хранящийся вместе с этим значением. Так как размер памяти System/3 был очень небольшим, хранить в памяти объемные индексы целиком было невозможно. Это снижало эффективность поиска из-за необходимости нескольких обращений к диску. System/34 была первой моделью семейства System/3, предназначенной для работы в интерактивном, а не в пакетном режиме. Размеры памяти в System/34 были также невелики, так что IBM решила ускорить поиск нужной записи в индексе, а для этого — устранить необходимость считывать индекс с диска. Часть дорожек диска была зарезервирована для индекса, для контроллера диска была разработана специальная аппаратура. Желаемое значение ключа процессор передавал дисковому контроллеру. Затем контроллер начинал считывать информацию дорожки, отыскивая значение ключа. Обнаружив искомое, аппаратура контроллера считывала следующее поле адреса и возвращала его процессору. Процессор использовал полученный адрес для считывания целой записи из некоторой другой части диска. Эта операция была названа сканированием. Функция сканирования значительно повысила эффективность интерактивной обработки, благодаря полному устранению этапа обращения к диску для считывания индекса. Но при этом потребовалось встроить в памяти еще один небольшой индекс. Индекс в памяти указывал, на какой индексной дорожке диска следует выполнять поиск. Позднее аналогичная операция сканирования была реализована в System/36 для обработки файлов. Для System/38 также была важна очень высокая эффективность интерактивной обработки. Недостатком описанной процедуры сканирования была ее слишком тесная привязка к аппаратуре. Были также и другие ограничения: максимально возможное число индексов, ограничение способов их обработки и др. Так как System/38 должна была иметь одноуровневую память, разработчики решили поместить все файлы и индексы в эту большую память. Если вернуться назад к только что описанной файловой структуре, то мы увидим двумерную таблицу, где строки —это записи, а столбцы — поля записей. Разработчики посчитали, что наиболее эффективным будет организовать файл System/38 просто как двумерную таблицу в памяти. Они также полагали, что производительность обработки повысится, если таблицу обрабатывать «на месте» без сортировки записей. Чтобы добиться этого, они встроили индекс в таблицу так, что сортировка просто не требуется (подробнее об этом — далее, в разделе «Машинные индексы»). По сути, предполагалось, что в System/38 никогда не будет программы сортировки. Однако, такая программа была и есть. Ее написал Дик Бэйнс, назвав «Conversion Reformat Utility», вероятно, чтобы скрыть ее сущность и предотвратить использование прикладными программистами в новых проектах[ 50 ]. Эта программа, тем не менее, была — а, может быть, есть и по сей день — самым быстрым способом сортировки и выборки записей из больших файлов. Джим Слоан (Jim Sloan), бывший разработчик и проектировщик, участвовавший в создании компилятора CL, разработал в составе своего набора QUSRTOOL утилиту для пользователей, интерфейс которой к этой программе сортировки позволял использовать внешние имена полей. В процессе разработки базы данных Перри Тейлор (Perry Taylor) случайно наткнулся на технический отчет Е. Ф. Кодда (E. F. Codd). Кодд, который считается создателем реляционной базы данных, работал над проектом System/R (R — реляционная) в исследовательском центре IBM в Калифорнии. Базой в определении Кодда была двумерная таблица, над которой можно было выполнять четыре элементарных операции. Первая операция — упорядочение (order) — позволяла обрабатывать строки или столбцы в определенном порядке по ключевому полю; вторая — выборка (selection) — выбирать записи по значению ключевого поля; третья — проекция (projection) — осуществлять выборку из таблицы заданных полей; и наконец, четвертая — соединение (join) —рассматривать несколько таблиц как одну большую. Таким образом, реляционная база данных представляла собой просто двумерную таблицу с операциями упорядочения, выборки, проекции и соединения. Перри сразу же понял, что разработчики System/38 строят очень похожую базу данных, за исключением того, что в ней нет соединения. Он позвонил Кодду, чтобы сообщить о работах в Рочестере и предложить свою поддержку. Но Кодд ответил, что, по его мнению, реляционные базы данных предназначены только для больших систем; а малым нужны только функции сортировки и слияния. По словам Перри, разговор не был сердечным. Тон Кодда он сравнил с тоном полицейских во время перекрестного допроса их защитниками на процессе О. Дж. Симпсона (O. J. Simpson) — вежливый, но холодный. Кодд и Тейлор больше никогда не разговаривали. Через три года после объявления System/38 база данных System/R была объявлена как DB2 и признана в качестве первой реляционной базы данных[ 51 ]. Так как первоначально System/38 не поддерживала операции соединения, то она считается первой коммерческой базой данных с реляционными возможностями. Двуликая база данных Говоря о базе данных, мы имеем в виду не просто некоторое место для размещения данных. Мы говорим о системе управления базой данных. СУБД — среда для хранения и выборки данных, включающая определения данных, правила обеспечения их целостности и механизмы поддержания, а также операции сохранения и выборки данных. СУБД должна иметь интерфейс, чтобы пользователи могли работать с ней. В этом разделе мы представим два интерфейса СУБД AS/400: DDS (Data Description Specifications) и SQL (Structured Query Language), в следующих разделах — детально рассмотрим саму СУБД. Когда IBM начинала проект System/38, стандартных интерфейсов к реляционной базе данных не существовало. Поэтому проектировщикам пришлось разработать собственный уникальный интерфейс для этой системы. Не удивительно, что этот интерфейс DDS очень похож на файловую систему, которую должен был заменить. Создатели интерфейса ограничились несколькими системными командами и функциями управления базой данных, а также ввели в MI команды для таких операций как чтение, запись, обновление и удаление. Программисты могли непосредственно использовать эти команды из таких языков как RPG и Cobol. Например, многие используют DDS-RPG: DDS для определений данных, RPG для доступа к ним. Интерфейс DDS перешел из System/38 в AS/400, и многие по-прежнему предпочитают его. Бывшим пользователям мэйнфреймов, перешедшим на AS/400, он также нравится, поскольку очень похож на интерфейс базы данных для больших систем IBM — IMS (Information Management System). Примерно в то же время, когда разрабатывалась AS/400, в IBM и других фирмах выполнялись проекты по стандартизации SQL (из System/R) в качестве языка реляционных баз данных. Проект продвигался не слишком гладко, на создание стандарта потребовалось около десятилетия. Ingres многие годы использовала язык-соперник QUEL, пока, наконец, тоже не поддалась общей тенденции. Появившаяся в 1988 году AS/400 поддерживала и собственный интерфейс DDS, и SQL. Операторы SQL могут включаться непосредственно в программы на RPG, Cobol и С, заменяя «родные» команды, такие как чтение, запись и обновление. Для трансляции этих операторов SQL DB2/400 содержит прекомпиляторы. При более внимательном взгляде становится видно, что DB2/400 состоит из двух отдельных частей. Собственно СУБД и язык DDS входят в состав OS/400. Query Manager and SQL Development Kit — особый продукт, приобретаемый отдельно. Как следует из названия, этот продукт содержит Query Manager — ПО AS/400 для конечного пользователя, позволяющее выдавать запросы на SQL. В состав продукта входят кроме того интерактивный пользовательский интерфейс к SQL (Interactive SQL), а также прекомпиляторы для различных языков, используемые при вставке операторов SQL в ЯВУ. К несчастью сложилось так, что IBM требует от Вас платить за SQL отдельно, тогда как DDS входит в состав OS/400. Такая ситуация — основная причина непопулярности SQL у многих пользователей AS/400, считающих его внешним продуктом, каковым он на самом деле не является. Сегодня большинство разработчиков баз данных в Рочестере думают в терминах SQL, а не DDS. Интерфейс DDS будет поддерживаться и далее, но новые функции, скорее всего, будут в SQL. Хотя AS/400 и поддерживает два разных интерфейса к базе данных, крайне важно понимать, что сама база данных только одна. Доступ к данным, определение данных и манипуляции с ними на AS/400 возможны как посредством DDS, так и посредством SQL. Так как интерфейс SQL использует те же команды MI, что и DDS, каждый из интерфейсов может работать с объектами данных, созданных посредством другого интерфейса. Эта возможность смешения двух интерфейсов обеспечивает базе данных AS/400 дополнительные мощь и гибкость. Самая большая проблема двух интерфейсов состоит в путанице, вызываемой терминологическими различиями. Как и в случае различий имен между объектами OS/ 400 и системными объектами MI, имена для разных интерфейсов базы данных подбирались разными группами. Например, в интерфейсе DDS имеются физические файлы, содержащие данные. Как мы видели ранее, физический файл — это двумерная таблица. В интерфейсе SQL тот же самый физический файл называется таблицей, что больше подходит для этой структуры. Логический файл в интерфейсе DDS не содержит данные, а указывает на реальные данные и дает программе некоторую их проекцию. В SQL логический файл называется проекцией (view). Аналогично, то, что в терминологии DDS — запись и поле, в интерфейсе SQL — строка и столбец (чтобы отразить концепцию таблицы). Как функционирует база данных В этом разделе мы рассмотрим различные компоненты базы данных AS/400. Я не ставил здесь перед собой задачу проинструктировать Вас, как использовать эту базу данных. Уже есть целый ряд хороших книг, посвященных внешним аспектам базы данных и использованию двух ее интерфейсов в программах[ 52 ]. А я лишь хочу предложить Вам обзор характеристик СУБД и основ ее функционирования. Раздел состоит из двух частей. В первой содержится описание основных функций, которые должны присутствовать в каждой СУБД, и их реализации в AS/400. Во второй — обзор других характеристик базы данных, некоторые из которых имеют отношение к производительности, а другие обеспечивают поддержку использования AS/400 в качестве сервера базы данных. После этого мы поговорим о внутренней реализации некоторых фундаментальных функций базы данных. Функции СУБД Есть много способов реализации реляционной базы данных, но любая система управления ею должна предоставлять следующие семь функций: определение и описание таблиц базы данных; операции управления данными (вставка, выборка, обновление и удаление); возможность определить, что представляют собой данные независимо от программы; возможность создавать новые проекции данных для удовлетворения изменяющихся требований прикладных программ; множественные проекции данных для разных прикладных программ; защита данных; целостность данных. Теперь посмотрим, как эти функции реализованы в AS/400. Описание данных и создание файлов Для описания физических и логических файлов базы данных можно использовать «родной» язык СУБД AS/400 — DDS. Он содержит операторы, ключевые слова и параметры, позволяющие описывать как атрибуты самого файла, так и полей записей базы данных. DDS можно также применять для описания файлов устройств, используемых AS/400. Эти файлы устройств содержат информацию о формате и типах данных, используемых подключенными к системе физическими устройствами. DDS позволяет определить несколько атрибутов полей записей базы данных. Среди них имя поля, его длина и род данных (текстовые или числовые). В зависимости от типа данных поля можно задать некоторые другие специфические атрибуты. Например, если поле содержит десятичные данные, можно задать общее число десятичных цифр и число цифр справа от запятой. Операторы DDS помещаются в разделах исходных файлов, которые затем превращаются в файловые объекты с помощью команд OS/400 «CRTPF» («Create Physical File») и «CRTLF» («Create Logical File»). Для описания атрибутов файлов базы данных можно использовать и SQL. В отличие от DDS, представляющего собой только язык описания данных, один оператор SQL и описывает, и создает таблицы и проекции (view). В SQL определение файла неотделимо от команды создания. Например, оператор SQL «Create table» задает имя таблицы, имена столбцов (полей) и их атрибуты. Кроме того, при исполнении этого оператора создается и сама таблица. Создание физических файлов и таблиц Физические файлы или, в терминологии SQL, таблицы содержат собственно данные. Запись физического файла имеет фиксированный набор полей. Каждое поле может иметь (хотя и не часто) переменную длину. В терминологии SQL таблица содержит строки фиксированной длины со столбцами переменной длины[ 53 ]. Физический файл состоит из двух частей. В первой находятся атрибуты файла и описания полей. В набор атрибутов файла входят его имя, владелец, размер, число записей, ключевые поля и некоторые другие характеристики. Описания полей задают атрибуты для каждого поля записей. Вторая часть физического файла содержит собственно данные. Она может состоять из одного или нескольких разделов, позволяющих подразделять файл. Все записи во всех разделах обязательно имеют один и тот же формат. Это удобный способ разделения записей: например, информацию текущего месяца можно поместить в один раздел, а информацию прошлого — в другой. Каждый раздел имеет уникальное имя, которое можно использовать для доступа к записям. Таблицы SQL могут состоять только из одного раздела, что соответствует самой сути реляционной модели: все данные хранятся в двумерных таблицах. Файлы же имеющие несколько разделов — трехмерные. Для создания физического файла используется системная команда «CRTPF». Она создает физический файл по операторам из исходного файла. Вновь созданный физический файл не содержит записей данных, для их добавления необходимо использовать отдельную программу или утилиту. Как было отмечено ранее, оператор определения данных SQL также создает таблицу. Оператор «Create table» можно выполнить с помощью Query Manager, Interactive SQL, или вставив его в программу на ЯВУ. Таблица, созданная этим оператором, является физическим файлом, идентичным созданному с помощью «родного» интерфейса. Создание логических файлов и проекций Логические файлы дают возможность доступа к данным в формате, отличном от использующегося для их хранения в одном или нескольких физических файлах. Логические файлы обеспечивают независимость данных и программ, которая будет обсуждаться в следующем разделе. Они не содержат записей данных, а лишь относительный номер записи (индекс) данных в физическом файле. Часто говорят, что логический файл задает путь доступа к данным. Структура логического файла может быть как очень простой, так и очень сложной. Логические файлы и проекции можно подразделить на четыре категории. Перечислю их. Простые логические файлы и проекции, которые отображают данные из одного физического файла или таблицы на другое описание логических записей. Многоформатные логические файлы, обеспечивающие доступ к нескольким физическим файлам, каждый из которых имеет собственный формат записей. Данный тип логического файла может быть создан только с помощью «родного» интерфейса; с помощью SQL его создать нельзя. Логические файлы объединения (join), задающие одно определение логической записи, построенное из любой комбинации полей двух или более физических файлов, таблиц, логических файлов или проекций. При этом общее число физических файлов и таблиц не должно превышать 32. Проекции SQL (view), которые похожи на логические файлы объединения и дают те же результаты, но реализованы совершенно иначе. Файлы объединения хранят путь доступа для каждого объединения. Проекции же SQL определяют пути доступа во время исполнения, руководствуясь хранящимся внутри шаблоном определения запроса (Query Definition Template). Подобно физическому, логический файл состоит из двух частей. Первая — точно такая же, как и у физического файла. Она содержит атрибуты файла и описания полей. Вторая часть содержит относительные номера записей данных физического файла. Программе, использующей логический файл, видимы только те данные физического файла, которые соответствуют описанию полей логического файла. Для создания логического файла используется системная команда «CRTLF». Она использует операторы DDS в исходном файле для создания логического файла. Операторы DDS в исходном файле задают имена одного или нескольких физических файлов, служащих основой для логического. Созданный логический файл содержит относительные номера записей данных из одного или нескольких физических файлов. Оператор SQL «Create view» задает таблицу, представляемую проекцией, вместе с описанием столбцов проекции. Результат создания проекции — логический файл, идентичный создаваемому при использовании «родного» интерфейса. Логические файлы выполняют три операции: форматирование, включая проекцию, объединение и создание производных полей (field derivation); выборку записей; упорядочение. Логический файл, созданный с помощью DDS, может осуществлять все три операции. Файл, созданный с помощью SQL, может выполнять либо форматирование (проекция SQL), либо упорядочение (индекс SQL), но не обе сразу. На SQL нельзя создать проекций, выделяющих подмножество записей физического файла. Проекция SQL может быть создана с помощью DDS, но DDS обычно не используется для создания файлов, имеющих только возможности проекций SQL. Словарь данных и каталоги Описания компонентов всех физических и логических файлов содержатся на каждой AS/400 в одном месте. В терминах «родного» интерфейса это место называется словарем данных. Словарь данных — это специальный объект OS/400, который обслуживается менеджером базы данных и к которому могут обращаться пользователи для поиска информации о структуре и местах использования файлов. Менеджер базы данных автоматически обновляет информацию в словаре данных всякий раз при создании нового объекта СУБД. Словарь данных позволяет разработчикам приложений и пользователям получить представление о структуре базы данных на любой системе. «Каковы форматы записей?», «Каковы атрибуты данных?», «Где в системе используется некое имя?», — с помощью словаря данных можно найти ответы на эти и другие вопросы. В интерфейсе SQL словарь данных называется общесистемным каталогом. SQL также позволяет разработчикам создавать другие каталоги. Каждая коллекция (collection) SQL (библиотека в «нормальной» терминологии) может (хоть и необязательно) иметь собственный каталог. Независимость данных и программ Использование комбинации физических и логических файлов в AS/400 позволяет достичь независимости программ от используемых ими данных. Отделение описания данных от программ достигается тем, что прикладные программы рассматривают данные в формате, отличном от того в каком они хранятся физически. Концепция отделения программ и данных — одна из основ технологической независимости архитектуры System/38 и AS/400. Рассмотрим структуру физического файла, содержащего помимо самих данных их описание, часто называемое внешним описанием файла. Как System/38, так и AS/ 400 имеют внешне описанные данные, которые не надо помещать в программу. Это означает, что программа не определяет, как данные должны физически храниться. Кроме того, одна прикладная программа может работать с файлами, содержащими данные в разных форматах. Формат логического файла, так же как и формат физического — внешний, так что с помощью логических файлов можно переопределить формат записи программы. На рисунке 6.1 показан очень простой пример, иллюстрирующий некоторые функции логических файлов: использование программой логического файла для получения иного представления данных физического файла.
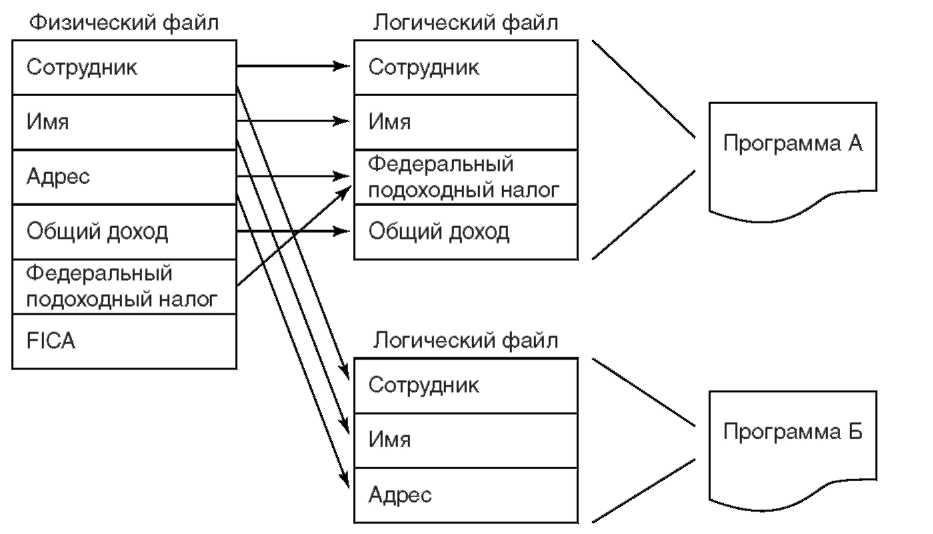
Рисунок 6.1. Независимость данных и программ Обратите внимание на выделенные поля. Каждая запись физического файла содержит шесть полей; в то же время программа, посредством логического файла, «видит» только четыре из них. Возможность исключения полей из логического файла позволяет реализовывать защиту на уровне полей. Пользователи имеют доступ только к тем полям, которые им позволено видеть. Это лишь один прием защиты в AS/400. Более подробно тема защиты рассматривается в главе 7. Другая функция, отображенная на рисунке — возможность переупорядочения полей записи. Порядок следования в логической записи полей общего дохода (gross) и федерального подоходного налога (FIT) изменен на обратный. Другими словами, программа независима от порядка следования полей. Кроме того, рисунок 6.1 иллюстрирует переопределение полей записи. В физическом файле поле общего дохода представляет собой упакованное десятичное число, содержащее 7 цифр, две из которых расположены справа от запятой. Однако программа написана так, что поле общего дохода должно иметь зонный десятичный формат с 8 цифрами, две из которых расположены справа от запятой. Логический файл обеспечивает нужное программе представление, а также осуществляет преобразование между упакованным и зонным десятичным форматами. Использование множественных логических файлов, построенных над одним и тем же физическим файлом, предоставляет альтернативные пути доступа к данным и обеспечивает разделение данных между программами. На рисунке 6.2 показан еще один логический файл для другой программы, который был добавлен к первому примеру. Теперь каждая программа имеет свое представление записей, хранящихся в физическом файле, и доступ только к тем полям, к которым он разрешен. Поля, присутствующие в обоих логических файлах, позволяют программам совместно использовать данные.
Рисунок 6.2. Совместное использование данных Очень важно подчеркнуть, что обе программы работают с теми же самыми физическими данными, — копирования данных нет. Обновление данных, выполненное одной программой, становится немедленно «видимо» другой. Эта возможность работы программ с текущими значениями данных, а не с копиями, используется в System/38 и AS/400 на протяжении уже почти 20 лет. Защита данных Итак, логические файлы позволяют защищать данные на уровне записей и полей. Мы увидели на примере, что поля можно защитить, просто не включая их в описание логического файла. Рассмотренные нами примеры просты, и в них не показана возможность выборки записей. Достичь защиты на уровне поля можно с помощью выборки и пропуска на уровне логического файла. В результате, пользователи получат доступ только к данным, удовлетворяющим критериям выборки. Если у пользователя нет доступа к какому-либо файлу, то данный файл защищен. Если пользователь, не имеющий прав на доступ, например, к общему доходу, попробует запустить программу, использующую данный путь, то программа не будет работать. Все логические и физические файлы AS/400 — это системные объекты, и для доступа к ним необходимы соответствующие права. Защита данных обеспечивается путем комбинации логических файлов и компонента управления доступом операционной системы. Мы можем предоставить конкретному пользователю следующие виды доступа к какому-либо физическому файлу: доступ ко всему файлу (с помощью средств управления доступом); разрешить некоторые типы операций с файлом, например, чтение, но не обновление (с помощью средств управления доступом); доступ к некоторым полям (с помощью логического файла); доступ к некоторым записям (с помощью логического файла). Целостность и восстановление данных Целостность данных, хранящихся в базе крайне важна. Между тем, при одновременном чтении и изменении данных многими пользователями существует вероятность их разрушения. База данных AS/400 предоставляет надежные средства обеспечения целостности данных. Средства восстановления данных необходимы на тот случай, если данные все же разрушатся или станут недоступными. Часто полагают, что такое может произойти лишь вследствие аппаратных сбоев. В AS/400 есть даже несколько средств предотвращения порчи данных при аппаратном сбое — это так называемые средства обеспечения доступности (availability). Но хотя аппаратный сбой — наиболее распространенная причина порчи данных, программы также могут содержать ошибки, после которых требуется восстановление данных. Подробное обсуждение целостности данных и их последующего восстановления потребовало бы отдельной книги. А мы сможем лишь кратко описать средства, предоставляемые базой данных AS/400, а также то, как некоторые из этих средств реализованы аппаратно. Журнал Журнал — это хронологическая запись изменений данных, предназначенная для восстановления предыдущей версии набора данных. В AS/400 поддерживаются журналы различных типов, в том числе журнал базы данных. При внесении изменения в запись журналируемого файла базы данных, в журнал помещается копия записи вместе с информацией, описывающей причину изменения. Ведение записей поддерживается двумя объектами OS/400: журналом и приемником журнала. Журнал идентифицирует журналируемые объекты, а приемник содержит записи журнала. Для гарантии сохранения информации приемники журнала могут немедленно записываться на диск. Помимо прочего, запись журнала содержит следующую информацию: имена файла, библиотеки и программы, относительный номер записи, дату и время изменения; а также идентификацию задания, пользователя и рабочей станции. Вместе с этой информацией в приемник журнала записывается копия измененной записи. AS/400 может также записать в журнал копию записи перед выполнением изменения. Журналы базы данных используются для восстановления, как при сбоях системы, так и в случаях ошибок в программах. При аварийной остановке системы из-за аппаратного или программного сбоя файлы базы данных, для которых велся журнал, автоматически восстанавливаются при перезагрузке и будут обновлены в соответствии с информацией, записанной в приемниках журнала. Если программа ввела в файл, для которого ведется журнал, ошибочные данные, то AS/400 может восстановить такой файл как прямым, так и обратным способом. В первом случае сначала восстанавливается резервная версия файла, затем к нему применяются записи журнала, сделанные до того момента времени, когда произошел сбой. При обратном восстановлении ошибочные изменения удаляются из файла, но для этого в журнале должны быть копии записей как до, так и после изменения. Системная защита пути доступа SMAPP В прошлом пользователи AS/400 были вынуждены мириться с долгим временем перезагрузки после аварийной остановки: пути доступа[ 54 ], открытые для обновления файла, должны были быть построены заново. Вспомните, что в главе 5 мы упомянули возможность отложенной коррекции логического файла. Вследствие этого целостность логического файла при аварийной остановке может нарушиться. В зависимости от числа и размера открытых путей доступа по ключу, временной промежуток, требуемый для их восстановления, может быть значительным, для больших систем — несколько часов. Как мы только что говорили, в AS/400 имеются средства журналирования, в том числе и для логических файлов. Если пользователь задействует ведение журнала для путей доступа, то время перезагрузки системы может быть значительно сокращено. Потенциальная трудность состоит в том, что пользователь должен сначала определить, для каких файлов следует вести журнал, оценить размер приемников журнала и дать команду активизации журналирования. Некоторые так и поступают, но, увы, таких пользователей меньшинство. Для автоматического ведения журнала IBM разработала SMAPP (System-Managed Access Path Protection). Система сама вычисляет максимальное время, требуемое на восстановление путей доступа после сбоя и соответственно определяет необходимый объем журналирования путей доступа. Пользователь всегда может увеличить или уменьшить вычисленное системой время. Чем время меньше, тем больше системных ресурсов потребуется для ведения журнала. Таким образом, ведение журнала предполагает выбор между системными ресурсами, предназначенными для нормальной работы, и мерами предосторожности на случай аварийной перезагрузки. После вычисления или задания пользователем максимально допустимого времени, система просматривает все пути доступа по ключу, существующие в базе данных; затем вычисляет общее время, требуемое для восстановления всех этих путей. Если время превышает максимально допустимое, то система автоматически начинает ведение журнала для отдельных путей доступа, чтобы гарантировать минимизацию времени на восстановление. SMAPP использует специальную область ведения журнала, не требующую действий со стороны пользователя. Эта область — циклическая, то есть по достижении конца запись продолжается с начала. Система всегда поддерживает в этой области достаточное число записей. Управление транзакциями Иногда целостность данных может быть нарушена, особенно, если с записями физического файла работают несколько пользователей. Предположим, что один пользователь считывает запись, собираясь обновить какое-то ее поле. Что произойдет, если то же самое поле записи одновременно обновляет и другой пользователь? Если второй пользователь изменит поле после того, как значение поля считано первым пользователем, нарушится ли целостность данных? К счастью, этого не произойдет, так как база данных обеспечивает защиту от параллельного обновления. Однако, при более сложных вариантах одновременного изменения нескольких записей, система не гарантирует автоматической защиты. Допустим, что необходимо одновременно изменить несколько взаимосвязанных записей. Часто, для описания такой ситуации используется пример с банкоматом. Пользователь банковского терминала запускает транзакцию: вставляет в машину кредитную карту, вводит идентификационный код и выбирает тип транзакции. В результате этого клиентская запись считывается из базы данных центрального компьютера, который может располагаться на другом конце города или земного шара. Если клиент запрашивает выдачу наличности, то по содержимому записи проверяется, достаточен ли остаток денег на счете. Затем остаток уменьшается на затребованную величину и банкомату посылается команда на выдачу денег. Что если случилась поломка, и банкомат не может выдать наличность? Прежде чем эта неудавшаяся транзакция завершится, следует отменить изменение остатка на счете клиента. Средство, используемое для этого в AS/400, — управление транзакциями (commitment control). Так как все изменения невозможно выполнить одновременно, система обязана защитить группу взаимосвязанных записей и не освобождать ее до тех пор, пока все изменения не будут внесены. Команда «Commit» позволяет изменить группу записей так, чтобы она выглядела как одна операция. Если нельзя выполнить какое-либо изменение, то вся группа изменений может быть отменена по команде «Rollback». Для этих операций управление транзакциями использует журналирование. Триггеры Триггер — действие, выполняемое автоматически всякий раз, когда содержимое физического файла изменяется — удобный способ связать одну операцию с другой. Триггеры — разновидность пользовательского средства обеспечения целостности базы данных, встроенная в определение файла. Часто изменение базы данных, например, добавление или удаление записи, требует некоторых дополнительных действий. В этих случаях триггер может запустить соответствующую программу. В других случаях, при изменении записи может требоваться запустить программу проверки нового значения поля записи: например, если при обновлении данных в файле инвентарной описи число учитываемых предметов упадет ниже допустимого уровня. Триггер для такого файла может при каждом обновлении запускать программу, проверяющую значение и отправляющее поставщику в случае необходимости дополнительный заказ. При добавлении к физическому файлу триггера необходимо определить три атрибута. Первый — событие, приводящее к запуску триггера: вставка, обновление или удаление записи из файла. Второй атрибут задает, когда следует запустить триггер — до или после события. Наконец, третий атрибут задает программу запуска триггера. Обычно это пользовательская программа, написанная на любом ЯВУ, поддерживаемом AS/400. Таким образом, для каждого физического файла можно назначить до шести триггеров: по два триггера для обновления, вставки и удаления записей, так чтобы один триггер запускался до события, второй — после. Триггеры добавляют командой «ADDPFTRG» (Add Physical File Trigger), а удаляют командой «RMVPFTRG» (Remove Physical File Trigger). Ссылочная целостность На практике данные одного физического файла часто зависят от данных другого. Если программа обновляет один файл независимо от другого, то целостность данных может быть нарушена. Часто ответственность за поддержку таких зависимостей ложится на прикладную программу. Ссылочная целостность — это средство, встроенное в базу данных AS/400 и позволяющее снять эту ответственность с прикладных программ. Ссылочная целостность обеспечивает непротиворечивость данных двух физических файлов. Она определяет правила или ограничения, гарантирующие, что каждой записи в одном файле будет соответствовать запись в другом. Программа не сможет изменить запись, если такое изменение нарушит заданные правила. В качестве простого примера предположим, что у нас имеется главный файл, содержащий запись для каждого клиента. В качестве ключа в этом файле используется ID клиента. Внутри базы данных имеются также другие файлы, использующие в качестве ключа ID клиента. В подобных случаях целесообразно, используя ссылочную целостность, ввести такое ограничение для каждого из зависимых файлов, которое не позволит прикладным программам добавлять в файлы ID клиента, если такого ID нет в главном файле. Очевидно, что могут быть и гораздо более сложные сценарии реализации ссылочной целостности. Дисковые системы высокой доступности Диски — это механические устройства, а механические устройства могут ломаться. Стандартная форма защиты для любой вычислительной системы — периодическое сохранение данных с дисков на другой носитель, обычно, ленту. Эта резервная копия содержит слепок базы данных или некоторой ее части на определенный момент времени. Если с данными на диске что-то произошло, то копия данных на ленте поможет восстановить потерянную информацию. Ранее мы рассматривали прямое восстановление базы данных с помощью журнала. Первым шагом этого процесса было восстановление резервной копии данных. Затем к этой копии применяются записи журнала, сделанные с момента ее создания, до тех пор, пока база данных не будет восстановлена. У AS/400 мощные средства сохранения/восстановления. Но иногда для восстановления данных при сбое диска требуется неприемлемо большое время. Обычно, в процессе восстановления система недоступна пользователям. Это может доставить большие затруднения, особенно, если необходимо физически заменить диск перед восстановлением данных. Альтернатива такой процедуры — дисковая подсистема, которая может так переносить сбои диска, чтобы система не становилась недоступной. AS/400 поддерживает два типа защиты дисков для обеспечения высокой доступности: зеркалирование дисков и дисковые массивы. Зеркалирование требует чтобы у каждого диска был «напарник». Всякий раз по команде записи на диск все данные дублируются на оба парных диска. Если один из дисков сломается, то доступ к данным со второго диска даст системе возможность продолжать работать. Для еще большей надежности диски в паре могут быть подключены к разным дисковым контроллерам, на разных процессорах ввода-вывода и на разных шинах. Путем подключения зеркальных дисков к оптической шине ввода-вывода их можно разместить даже в другом помещении (структура и взаимодействие компонентов ввода-вывода AS/400 описаны в главе 10). Зеркалирование обеспечивает наивысший уровень надежности, но дороговата, поскольку требует полного дублирования дисков. Другой подход — использование дисковых массивов. В этом случае диски объединяются в наборы, и данные записываются на все диски набора. Сектор — это фиксированный блок данных на диске. Страница памяти обычно хранится в нескольких екторах диска, и операция записи распределяет сектора по всем дискам набора. Добавление к массиву избыточного диска позволяет обнаруживать место сбоя и втоматически восстанавливать потерянную информацию. При этом используется перация <исключающего или> (XOR) над данными всех секторов набора . любой з операндов может быть восстановлен путем выполнения операции XOR над результатом и другим операндом. Данная технология известна как RAID (redundant arrays of nexpensive disks). Пример операции XOR показан на рисунке 6.3. Результат операции . <истина> то есть, 1) . достигается тогда и только тогда, когда один из операндов <истина> (1), другой . <ложь> (0). В противном случае, если оба операнда являются <истиной> ли оба <ложью>, значением операции является <ложь> (то есть 0).
Рисунок 6.3. Пример операции исключающее ИЛИ Операция XOR выполняется с данными соответствующих секторов на всех дисках, а ее результат операции сохраняется в секторе на избыточном диске. В случае сбоя диска, данные испорченного сектора восстанавливаются путем операции XOR над данными соответствующих секторов всех исправных дисков набора. Чтобы избежать перегрузки одного из дисков, контрольная информация (результаты операций XOR) распределяется на несколько дисков входящих в массив. Таким образом, любой диск содержит часть данных базы и часть результатов XOR. Целостность данных, восстановление и надежность — важнейшие характеристики любой вычислительной системы. В этом разделе мы рассмотрели лишь основные аспекты этой поддержки. Другие функции базы данных DB2/400 поддерживает и несколько дополнительных функций. Некоторые из них расширяют возможности применения AS/400 в клиент/серверных системах и средах распределенных баз данных, другие призваны повысить производительность базы данных. В этом разделе мы затронем только самые важные. Хранимые процедуры Один из самых действенных способов повысить производительность клиент/серверных приложений для AS/400 — хранимые процедуры. Оператор CALL в SQL позволяет приложению вызывать хранимую процедуру, которая исполняется на сервере AS/400. Таким образом, в результате одного обращения к серверу выполняется це лая транзакция. Без хранимых процедур для этого потребовалось бы множество таких обращений. В качестве хранимой процедуры может использоваться, за небольшими исключениями, любая программа AS/400, в том числе написанная на ЯВУ и даже содержащая операторы SQL. Доступ к хранимым процедурам возможен только через интерфейс SQL с использованием оператора CALL. Поддержка национальных языков Первый шаг в реализации Unicode на AS/400 был сделан в V3R1, где с его помощью кодировались имена объектов некоторых компонентов интегрированной файловой системы. Unicode поддерживает одновременное использование множества наборов символов (национальных алфавитов) в одной кодировке. В RISC-моделях эта поддержка была расширена, чтобы обеспечить хранение в файлах базы данных в Unicode (UCS2, уровень 1). Например, в одном файле базы данных может находиться информация на французском, немецком, английском, иврите, китайском, русском и других языках. SQL поддерживает преобразование в Unicode и обратно, что делает возможным работу старых приложений с данными в этой кодировке. Кроме того, имеется поддержка локализации (locale) — стандарт X/Open, дающий программистам возможность создавать приложения, самостоятельно адаптирующиеся к различным национальным особенностям (символ денежной единицы, формат даты и времени, формат чисел, порядок сортировки, преобразование регистров символов и др.). Предсказывающий регулятор запросов В большинстве реляционных баз данных присутствует регулятор запросов (query governor) гарантирующий, что единичный запрос не будет выполняться слишком долго. По истечении заданного времени такой регулятор останавливает выполнение запроса. DB2/400 же экономит системные ресурсы, используя предсказывающий регулятор запросов: если, выполнение запроса потребует столь много времени, что все равно будет прервано, то оно просто не начинается. Оптимизатор запросов предварительно анализирует способ, который будет применен при выполнении запроса для доступа к базе, и необходимое для этого время. Предсказанное время сравнивается с предельным временем запроса для данного пользователя. Если предсказанное время превосходит предельное, то пользователю посылается сообщение и тот может либо прекратить выполнение запроса, либо все-таки выдать запрос, отдавая себе отчет в том, что лимит будет исчерпан. Повышение производительности базы данных Для увеличения производительности различных операций в базе данных DB2/400 есть несколько механизмов. Например, команда «Explain» применяется для предсказания или просмотра характеристик исполнения запроса. Эта функция собирает информацию о том, как SQL используется в программе. Затем пользователь на основе полученной информации может вносить повышающие производительность изменения, как в базу данных, так и в сам запрос. Другие функции позволяют осуществлять операции выборки и вставки поблочно, то есть манипулировать массивами данных одной командой. Кроме того, существуют и расширенные механизмы кэширования. Пользователи могут активизировать экспертный кэш, размер которого в памяти автоматически увеличивается или уменьшается на основании текущей загрузки, предсказанной активности базы данных и выделенных ресурсов. Экспертный кэш использует этого алгоритмы искусственного интеллекта. Пользователь может также назначить статический кэш, чтобы поместить в резидентную область памяти целую таблицу или ее часть. Распределенные базы данных AS/400 позволяет прикладной программе работать с базой данных как на локальной, так и на удаленной системе; местоположение данных для приложения прозрачно. Это означает, что приложению доступна обработка файла базы данных без информации о том, где он находится. Кроме того, части базы данных могут быть перенесены на другую систему без изменения прикладных программ. Возможность доступа к базе данных на удаленной системе и доступа удаленных систем к данным AS/400 достигается благодаря реализации двух ключевых архитектур: DRDA (Distributed Relational Database Architecture) и DDM (Distributed Data Management). Для доступа к удаленным данным интерфейс SQL использует DRDA. Сначала устанавливается связь с удаленной базой при помощи оператора SQL CONNECT, в котором указывается имя базы. Для поиска имени удаленной базы данных и определения системы, на которой она расположена, используется справочник на локальной системе. После установки соединения между двумя системами возможна посылка запросов SQL к удаленной базе данных. Менеджер базы данных на удаленной системе отвечает на запрос и возвращает ответ на локальную систему. «Родной» интерфейс базы данных AS/400 использует архитектуру DDМ. Файл DDМ задает имя файла на удаленной системе и имя самой этой системы. Когда прикладной программе требуются удаленные данные, файл DDМ связывается с удаленной системой, после чего прикладная программа может работать с удаленным файлом. В отличие от DRDA, где обработка выполняется удаленной системой, использование DDМ означает, что обработка будет вестись на локальной системе. DDМ пересылает с удаленной системы на локальную все записи файла, тогда как DRDA — только результат уже выполненного запроса. Потенциально DRDA может обеспечить лучшую производительность приложений за счет меньших расходов на обслуживание коммуникаций. Шлюзы к другим базам данных AS/400 работает с базами данных, поддерживающими описанные архитектуры DRDA и DDМ, а также предоставляет интегрированный подход для доступа к другим базам данных. Это позволяет ей работать непосредственно с базой данных любого производителя на другом компьютере в сети. В дополнение к каталогу распределенной базы данных (Distributed Database Directory) в OS/400 присутствует менеджер драйверов (Distributed Database Driver Manager). Он работает с драйверами для других баз данных или файловых систем. Драйверы для баз данных Unix и ПК позволяют приложению AS/400 работать с этими базами так же, как и с любой базой DRDA. Трансформация данных с помощью DataPropagator Ранее, при обсуждении хранилищ данных мы упоминали о средствах трансформации данных, использующихся для их перемещения данных из оперативной базы в информационную. DataPropagator — одно из таких средств. Его можно использовать не только для хранилищ данных, но и для связи между любыми базами данных типа DB2. В распределенной среде на разных компьютерах могут существовать множественные копии одного и того же файла базы данных. Изменение одной копии не отражается на другой немедленно, поэтому один и тот же файл на разных системах может быть в разной степени актуален. DataPropagator предоставляет механизм репликации изменений файла на все системы через некоторый, определяемый пользователем, интервал времени. Так как при этом используется технология репликации IBM, то изменения могут реплицироваться в сети на любую базу данных семейства DB2. Соединение при помощи OptiConnect Если компьютер работает не в сети, и сами данные, и средства их обработки располагаются на нем самом. Одиночная система AS/400 поддерживает очень большие, в том числе многопроцессорные, конфигурации, что вполне удовлетворяет нужды большинства крупных заказчиков. Однако, среди наших заказчиков есть такие, чьи требования к производительности и объемам данных превосходят возможности одиночной AS/400. Даже при работе компьютеров в сети накладные расходы на передачу данных ограничивают прирост производительности, который достигается путем распределения приложения между несколькими компьютерами. В этом случае может помочь OptiConnect. В главах 10 и 11 мы рассмотрим новейшие высокоскоростное межсистемное соединение — SAN. Но SAN поддерживается только линией AS/400е, так что OptiConnect еще будет какое-то время использоваться для объединения AS/400. OptiConnect — это продукт, позволяющий соединять друг с другом компьютеры AS/400 с помощью волоконной оптики для большей скорости обработки транзакций. Часто, крупные заказчики AS/400 отделяют обработку баз данных от обработки приложений и размещают базу данных на серверной модели AS/400. В этом случае разные системы объединяются в кластер, в котором некоторые машины выделяются для обработки базы данных, а другие — для приложений. OptiConnect использует DDM, но здесь важно отметить следующее. DDM на сети применяет коммуникационные протоколы на линиях связи (ЛВС). При таком способе связи обычны сильные шумы, и коммуникационный протокол вставляет в передачу слои избыточности и проверок, что приводит к замедлению передачи. Оптическая шина обеспечивает соединение, достаточно чистое, чтобы устранить большую часть избыточности, в результате производительность существенно возрастает. При использовании OptiConnect время, необходимое для доступа к базе на удаленной системе увеличивается лишь на 3 миллисекунды по сравнению с временем доступа к локальной базе данных, то есть удаленные диски работают почти со скоростью локальных. Рост производительности в результате разделения приложений и базы данных зависит от множества факторов, например, от степени использования базы данных. Однако то, что кластер OptiConnect может объединять до 32 машин, позволяет уверенно говорить, что с помощью этого соединения реально создание очень больших конфигураций. OptiConnect применяется не только для наращивания. Система на волоконно-оптических линиях может заменить существующие ЛВС, использующие DDM, что сделает сетевые соединения более быстрыми и надежными. Соединение с помощью OptiConnect дублированных систем позволяет создавать конфигурации с высоким уровнем доступности и возможностей восстановления важнейших приложений и данных. А теперь пришла пора спуститься на уровень ниже и рассмотреть, как функционирует база данных «изнутри». Затем мы поговорим об использовании машинного индекса для поддержки уже рассмотренных нами операций. Внутренняя реализация функций базы данных Как мы уже говорили в главе 3, функции базы данных AS/400 реализуются по разные стороны MI. В предыдущих разделах обсуждалась, в основном, база данных, реализованная как часть DB2/400 поверх MI. Давайте теперь рассмотрим некоторые системные объекты MI, используемые в DB2/400, а также то, как некоторые из операций над этими системными объектами реализованы в SLIC ниже MI. В этой книге нет места для детального описания всех средств и функций базы данных, и мы остановимся только на самых важных. Далее мы рассмотрим машинный индекс, используемый базой данных и другими компонентами AS/400. Особое внимание уделяется этой теме не только потому, что машинный индекс важен для многих функций AS/400, но и потому что он интересен сам по себе. SLIC поддерживает большие базы данных. Приведем некоторые предельные величины: до 240 ГБ на физический файл; более 2 миллиардов записей на физический файл; до 4 ГБ на индекс; до 2048 байтов на ключ. Следует отметить, что эти ограничения размеров связаны с текущей реализацией SLIC. Для MI нет какого-либо ограничения размеров системных объектов, так как он независим от технологии. SLIC же зависит от технологии, то есть размеры полей некоторых внутренних структур данных предопределены, что, в свою очередь, задает ограничения сверху. Мы обсудим некоторые из этих ограничений при рассмотрении внутренней реализации. Впрочем, как и в любой хорошей системе, здесь остается возможность модификаций, если таковые понадобятся, и об этом мы тоже поговорим. А сейчас, начнем с рассмотрения системных объектов MI, поддерживающих базу данных.
Ранее мы рассмотрели три основных системных объекта для поддержки базы данных: области данных, индексы областей данных и курсоры. Как и остальные системные объекты, они занимают несколько сегментов в одноуровневой памяти. Каждый из них имеет базовый сегмент, содержащий заголовок сегмента, заголовок ЕРА и специфический заголовок объекта; а кроме того — сегмент ассоциированного пространства.
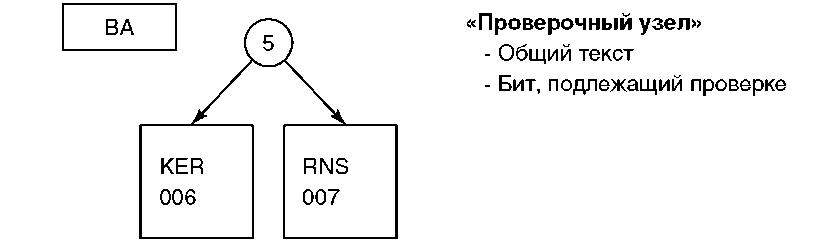
Области данных содержат записи базы данных. Все записи одной области данных схожи: однородны и имеют фиксированную длину. Записи хранятся в порядке их поступления, и все удаленные записи по-прежнему занимают место. Объект «область данных» состоит из сегментов трех типов. Кроме базового сегмента и сегмента ассоциированного пространства, в его состав может входить до 120 сегментов записей области данных. Каждый элемент сегмента содержит байты состояния и записи базы данных. Байт состояния содержит информацию о нынешнем состоянии записи, или о том, была ли она удалена. Каждая запись в сегменте области данных записей имеет номер, называемый порядковым номером. Порядковый номер задает положение записи в сегменте. Не путайте порядковые номера, отсчет которых начинается в каждом сегменте заново, с относительным номером записи (возможно, последний Вам лучше знаком, так как находится на уровне OS/400). Относительные номера записей, хранящиеся в логическом файле или проекции, указывают местоположение данных в физическом файле или таблице. Те же самые номера иногда называются в MI номерами элементов области данных. Начинающийся с нуля порядковый номер указывает, является ли запись первой, второй или n-ной в сегменте. Так как длина всех записей одинакова, необходимости хранения в сегменте порядковых номеров нет. Зная порядковый номер и длину каждой записи можно найти стартовый байт любой записи сегмента. Далее будет рассказано, как порядковый номер используется для поиска записей в базе данных. Базовый сегмент не содержит информации об области данных, его основная роль — хранить адреса сегментов области данных. Базовый сегмент также содержит адреса индексов, используемых с этой областью данных. Ассоциированное пространство содержит таблицу описателей полей с описанием каждого поля записи. Там также размещается рабочая область, используемая компонентами базы данных OS/400. Например, в ассоциированном пространстве хранятся указатели на логические курсоры. Индексы области данных Индекс области данных задает альтернативный порядок записей в области данных. Для альтернативного упорядочения используется дерево с двоичным основанием. В разделе «Деревья с двоичным основанием» мы рассмотрим такое дерево и его использование для поддержки ряда функций AS/400, включая индекс области данных. Индекс области данных задействован во множестве операций. Так, он поддерживает ключи переменной длины. Значения ключей могут вычисляться с помощью различных операций, таких как конкатенация, сложение, вычитание и умножение. Один такой индекс может обслуживать до 32 областей данных. Есть несколько вариантов упорядочения индекса: по возрастанию, убыванию, числовому и абсолютному значениям. Существуют также варианты выполнения коррекции: обновления могут вноситься в индекс немедленно, либо быть отложены. Откладывание обновления индекса позволяет избежать накладных расходов, если изменение в области данных происходит, а индекс не используется. В главе 5 были приведены примеры объектов, включая индекс области данных. Мы видели, что последний состоит из сегментов трех типов: базового, ассоциированного пространства и отложенной коррекции. Последние два сегмента уже были подробно рассмотрены, теперь остановимся на базовом сегменте. Базовый сегмент содержит атрибуты альтернативной сортировки, обеспечиваемой индексом, а также таблицу, описывающую как индекс «видит» каждое поле записей в области данных. Это описание логического представления. Базовый сегмент также содержит до 32 адресов областей данных. Наконец, в базовом сегменте находится дерево с двоичным основанием. Дерево с двоичным основанием может не умещаться в базовый сегмент целиком. Для размещения очень больших деревьев можно подключать сегменты четвертого типа. На практике, к индексу области данных можно присоединить до 64 сегментов дерева. Каждый ключ, хранящийся в сегменте дерева, состоит из цепочки байтов, содержащих его фактическое значение, за которым следует пара полей суффикса ключа. Обычно, такая пара называется относительным адресом. Первое поле содержит номер области данных и идентификацию сегмента записей области, второе — порядковый номер записи в сегменте. Эти два числа уникально идентифицируют запись с ключом аналогично относительному номеру записи в логическом файле или проекции.
Курсоры — механизм просмотра данных в области данных; через них осуществляется весь доступ к данным. Курсор, о котором мы сейчас говорим, — системный объект MI. DB2/400 поддерживает позиционируемые (scrollable) и последовательные файловые курсоры в соответствии со стандартом SQL 1992. Курсор SQL — это не то же самое, что и системный объект MI «курсор», хотя последний и используется для реализации первого. Как уже упоминалось, записи физического файла хранятся внутри разделов. Физический файл может состоять из одного или нескольких разделов. Это удобный способ разделения на части данных внутри физического файла. Логические файлы используют ту же концепцию множества разделов. Мы также оговорили, что таблицы и проекции SQL ограничены одним разделом на таблицу или проекцию. Курсор связан с каждым разделом файла. Он может обеспечить доступ к записям области данных как в порядке их поступления, так и в порядке ключей индекса. Другими словами, курсор может указывать на область данных либо непосредственно, либо «сквозь» индекс области данных. Один курсор может использоваться для нескольких областей данных, а для одной области — несколько курсоров. Курсор отслеживает текущее положение в пути доступа, принадлежащем программе (или заданию, или группе активации). Кстати, это помогает понять, почему он так называется. С помощью курсора также происходит проецирование в область данных и оттуда, что позволяет рассматривать данные иначе, чем когда они хранятся в области данных. Примеры проецирования — переименование полей, арифметические и строковые выражения и преобразования типов данных. Курсор позволяет осуществлять выборку записей, используя для этого функции арифметического и строкового проецирования. Обычно, критерий выборки записей задается в предложении WHERE оператора SQL (в DDS использовать арифметические выражения нельзя). С помощью курсоров (то есть, путей доступа), которые выбирают лишь некоторые записи, можно предотвратить нежелательный просмотр пользователем остальных записей. Иными словами, курсор обеспечивает защиту базы данных. Курсор состоит из двух сегментов: базового и ассоциированного пространства. Базовый сегмент содержит два набора адресов для указания областей данных и индексов областей данных, которые могут использоваться курсором; и тех и других может быть по 32. Единственный случай, когда может потребоваться более одного индекса области данных — логический файл объединения (join-logical file, а не проекция SQL). Базовый сегмент также содержит код проецирования и код выборки, используемые курсором. Ассоциированное пространство курсора содержит текст описания раздела и его атрибуты. Связи на уровне раздела поддерживаются компонентом базы данных в OS/400. Теперь, изучив каждый из трех основных системных объектов поддержки базы данных, можно говорить о том, как пользователь обращается к файлам базы данных в AS/400. Доступ пользователя к данным Все пути доступа пользователя к базе данных идут через OS/400 и MI, прямой доступ к данным — только у SLIC. С точки зрения пользователя, доступ к файлу базы данных OS/400 осуществляется с помощью открытия файла. На уровне MI эта функция реализована командой «Activate cursor». Когда пользователь закрывает файл, аналогично используется команда MI «Deactivate cursor». При доступе к области данных пользователь может задать несколько опций команды открытия файла. В их состав входят тип операции (чтение, запись, обновление и удаление) и число записей. Если курсор оперирует с несколькими областями данных, пользователь может отобрать для работы подмножество этих областей. Определение этого подмножества задается при создании файла командой «CRTLF». В процессе работы это подмножество может быть переопределено командой «OVRDBF» (Override with Database File), выданной перед открытием файла. При создании файла пользователь также может задать время ожидания заблокированной записи, и также переопределить это время перед открытием файла. Пользователь осуществляет доступ к области данных в произвольном или последовательном режиме. В режиме последовательного доступа возможна пересылка нескольких страниц с диска в основную память операцией переноса (bring). Пользователь задает размер переноса с помощью опции «число записей» в команде «OVRDBF» или «OPNQRYF» (Open Query File). В режиме произвольного доступа обычно считы-вается одна страница. Произвольный режим возможен только в том случае, если у области данных есть индекс, тогда код базы в SLIC использует схему просмотра для переноса в память следующей логической страницы индекса. Для доступа к данным в области данных нужен курсор. Поэтому для начала работы можно использовать команду MI открытия курсора «Activate cursor», а по завершении закрыть курсор командой «Deactivate cursor». Эти функции работы с курсором на уровне MI эквивалентны открытию и закрытию файла в OS/400. Ассоциированное пространство активного курсора содержит информацию об открытом пути данных ODP (Open Data Path) для открытого раздела. Исполнение команды: MI «Activate cursor» присоединеняет курсор к активизировавшему его процессу (единица работы в системе), а точнее — к связанному с процессом блоку управления (этот объект MI будет подробно рассмотрен позднее). Если процесс активизирует более одного курсора, то к блоку управления процессом присоединяется двусвязный список курсоров. Теперь никакой другой процесс не сможет использовать эти курсоры. Если тот же самый курсор потребуется другим пользователям, то при активизации ими курсора будет создана его копия. Получается, что курсор может быть постоянным и временным. Постоянный курсор связан с каждым разделом файла, а каждый раздел файла имеет один и только один постоянный курсор. Если курсор активизируется для предоставления ODP к разделу файла, но он уже был активизирован другим процессом, то создается временный курсор-копия. В целях экономии места коды проецирования и выборки во временном курсоре не хранятся. Адреса во временном курсоре указывают на постоянный курсор, содержащий соответствующие коды.
По принятому соглашению, OS/400 всегда создает временную копию постоянного курсора с помощью команды «CRTDUPOBJ» (Create Duplicate Object) и затем активизирует только временные курсоры. Благодаря этому, постоянный курсор может быть представлением раздела файла, так как помимо него объекта-раздела на уровне MI нет. Более того, все ODP — это временные курсоры, что также результат соглашений принятых в OS/400, а не ограничение MI. Журналы SLIC Ранее мы рассматривали ведение журналов базы данных. Базовые функции для протоколирования изменений базы данных реализованы ниже MI. Соответствующая поддержка предоставляется двумя системными объектами MI: порт журнала и область журнала. Порт журнала управляет определением журнала, а область журнала представляет собой контейнер для записей в него. Эти два объекта поддерживают объекты OS/400 журнал и приемник журнала соответственно. Обратите внимание, что на границе MI имена снова меняются. Порт журнала, как и почти все другие системные объекты, состоит из двух сегментов. Базовый сегмент содержит адреса объектов, для которых ведется журнал, а также адреса текущих журнальных пространств. Компонент базы данных, реализованный в OS/400, использует сегмент ассоциированного пространства. Область журнала — это специальный системный объект MI, состоящий из множества сегментов. Базовый сегмент содержит адреса порта журнала, а также адреса до 120 сегментов данных журнала. Сегмент данных журнала — это сегмент еще одного типа, который может быть частью системного объекта «область журнала». В сегментах данных журнала хранятся записи журнала. Записи журнала имеют переменную длину. Каждая запись содержит: поле длины, последовательный номер, поле типа, отметки времени и даты, идентификацию пользователя, программы и задания, а также информацию, заносимую в журнал. Важно отметить, что эти записи не могут обновляться или удаляться. Задачей журнала является просто хранение копий изменений базы данных на тот случай, если потребуется восстановление. Управление транзакциями в SLIC Ранее мы обсуждали базовые функции подтверждения и отката изменений. Эти функции поддерживаются и в MI, и в компоненте базы данных на уровне SLIC. В MI такую поддержку предоставляет системный объект блок транзакции (commit block). Он фиксирует изменения объекта, участвующего в транзакции. Блоки транзакции связаны с процессами. Объекты добавляются к блоку транзакции и удаляются из него. Блок транзакции также содержит информацию о блокировках записей. Эти блокировки освобождаются командой MI <<Cornrnrt>>. Команда <<Decornrnrt>>, которая практически во всех ЯВУ (включая набор команд OS/400) называется «Rollback», откатывает все изменения, сделанные в процессе транзакции, освобождает блокировки и устанавливает курсор в положение, нормальное на момент начала транзакции. Машинные индексы Перейдем к последней теме, связанной с нижним уровнем поддержки базы данных в AS/400 — к индексам. Мы уже обсуждали два вида индексов: независимый (в главе 5) и индекс области данных (в этой главе). Повторю, что оба этих системных объекта содержат дерево с двоичным основанием. Итак, что такое индекс? На мой взгляд, наиболее удачное определение таково: индекс — организованный набор информации для быстрого поиска в наборе элементов, например в большой таблице. Индексация играет важную роль в реализации многих компонентов AS/400 и любой другой системы. Поэтому еще при проектировании System/38 было принято решение встроить ниже MI максимально эффективный индекс таким образом, чтобы все системные компоненты могли при необходимости использовать его, а не создавать свои собственные. Этот встроенный индекс и называется машинным индексом. Машинный индекс полезен различным компонентам AS/400 при поиске в таблицах, адресации областей, сортировке и т. д. База данных применяет его при индексации области данных, работе со списком транзакций журнала и т. п.; компонент управление памятью — для многих своих справочников. Машинные индексы используются и в контекстах, и для поиска прав доступа. OS/400 использует объекты типа «независимый индекс» для нескольких целей, включая обработку сообщений, защиту и спулинг. Основные характеристики машинного индекса таковы: обеспечивает обобщенный поиск, позволяя находить группы связанных элементов; управляет используемым пространством; позволяет минимизировать случаи отсутствия нужной страницы в памяти (страничные ошибки); поддерживает ключи переменной длины до 2048 байтов; использует алгоритм двоичного поиска; хранит элементы в виде фрагментированного дерева с двоичным основанием (подробнее — в разделе «Внутренняя организация дерева с двоичным основанием» этой главы). Двоичный поиск Проще всего понять, что такое двоичный поиск, можно на примере игры в угадывание чисел. Смысл игры в том, что один игрок задумывает число внутри некоторого диапазона, например между 1 и 1000, а второй — пытается угадать это число за минимально возможное количество попыток. При каждой попытке второму игроку сообщается, является ли названное им число большим, меньшим или равным задуманному. Прием быстрого угадывания чисел в этой игре основан на двоичной системе счисления. Чтобы угадать число между 1 и 1000, при первой попытке следует назвать 512 (29 = 512). Если нам скажут, что это число слишком велико, то задуманное число больше нуля и меньше 512, поэтому далее мы называем 256 (28= 256) — следующую меньшую степень двойки. Если же сказано, что названное число меньше задуманного, то задумано число большее 512 и для следующей попытки нужно прибавить 256 к 512 и назвать 768, и при каждой следующей попытке прибавлять следующую меньшую степень двойки. Если названное число больше задуманного, мы вычитаем эту степень двойки и прибавляем следующую меньшую степень. Предположим, что первый игрок задумал 700. Отгадывающему следует называть такую последовательность чисел: 512, 768, 640, 704, 672, 688, 696 и, наконец, 700. При этом ему будет сообщаться, что первое число меньше, второе больше, третье меньше и т. д. На основании этой информации он будет вычислять следующее значение и, в конце концов, задуманное число будет отгадано за восемь попыток. Если мы посмотрим на последовательность ответов первого «больше/меньше» из приведенного примера, то заметим интересную закономерность. Эта последовательность выглядит так: «меньше», «больше», «меньше», «больше», «меньше», «меньше», «меньше» и «равно». Если на место каждого ответа «больше» подставить 0, а на место каждого ответа «меньше» — 1, то мы получим двоичное число. Учитывая, что для задания любого числа между 1 и 1000 требуется 10 разрядов, можно представить 700 как 1010111100. Мы угадали это число, двигаясь слева направо и используя ответы «больше/меньше» для определения двоичной цифры в текущей позиции. С использованием данного метода задуманное число всегда может быть найдено не более чем за 10 попыток. В нашем примере потребовалось только восемь попыток,так как число делится на 4 — степень двойки. Обратите внимание, что любое нечетное число потребует 10 попыток, по одной на разряд. Максимальное число попыток можно вычислить как логарифм 1000 по основанию 2. Иначе это значение можно определить, учитывая, что 2 = 1024. Для угадывания числа между единицей и миллионом по данному методу требуется лишь 20 или менее попыток. Приведенный пример иллюстрирует алгоритм двоичного поиска, который применяется для нахождения элемента индекса. Структура, в которой все записи заполнены, считается сбалансированной. При поиске по сбалансированному индексу с n элементами требуется выполнить сравнение лишь для log2 n элементов. Наш пример с угадыванием чисел был сбалансированным, так как в последовательности присутствуют все числа. Но даже для сильно несбалансированных структур среднее число попыток возрастает менее чем на 10 процентов. Алгоритм двоичного поиска отлично работает для большого числа элементов, но обычно не рекомендуется, если их число меньше 50. Деревья с двоичным основанием
Описанный выше метод двоичного поиска можно представить в виде древовидной структуры. Дерево будет содержать два типа узлов: тестовые и окончательные. Каждый тестовый узел дерева проверяет один разряд числа. По тому, равен разряд 1 или 0, в качестве следующего выбирается один из двух узлов следующего уровня. Начиная с вершины дерева[ 55 ], первый узел проверяет первый разряд числа (самый левый). Второй слой дерева содержит два текстовых узла, один из которых выбирается, если первый разряд был равен 0, а другой — если первый разряд был равен 1. На третьем уровне имеется четыре узла, на четвертом — восемь и так далее вплоть до десятого узла, на котором расположено 512 тестовых узлов. Одиннадцатый уровень — последний для данного дерева и содержит 1024 окончательных узла. Окончательный узел содержит точное значение искомого числа. Итак, для поиска числа мы начинаем с вершины дерева и проверяем разряды: слева направо. На каждом уровне дерева проверяется один из разрядов. После десяти проверок мы оказываемся в одном из окончательных узлов и можем точно назвать число. Мы только что описали двоичное дерево. Оно сбалансированное, так как присутствуют все узлы. При поиске по таблице могут присутствовать не все узлы, так как в таблице присутствуют не все возможные элементы. Следовательно, и проверяются не все разряды числа, некоторые уровни могут отсутствовать. Такое дерево в отличии от двоичного дерева, где присутствуют все узлы, называется деревом с двоичным основанием (binaryradix tree). Использование деревьев с двоичным основанием в AS/400 для реализации машинных индексов мы рассмотрим на примере рисунка 6.4. На нем показан простой файл из девяти записей, упорядоченных в порядке поступления. Каждая запись имеет несколько полей, на рисунке показаны лишь некоторые. Одно из полей — поле имени — предназначено для использования в качестве ключа. Для файла построен индекс, который также показан на рисунке. Каждая запись индекса имеет только два поля: поле ключа и логический адрес записи. Девять элементов индекса отсортированы по порядку значений ключа. В данном случае, ключи отсортированы по алфавиту, и первым элементом является Baker, а последним Wu. Поле логического адреса записи задает относительную позицию соответствующей записи в исходном файле, логическая адресация всегда начинается с 0 (для первой записи). Элемент для Baker указывает, что запись Baker является в файле седьмой.
Рисунок 6.4. Пример простого файла и индекса Точный формат логического адреса записи изменяется на AS/400 в зависимости от того, как используется индекс. Например, как уже говорилось, каждый элемент сегмента индекса области данных содержит ключ и относительный адрес, в свою очередь включающий в себя номер области данных, идентификацию сегмента области данных записей и порядковый номер записи. Данный относительный адрес уникальным образом идентифицирует запись, соответствующую ключу. В других случаях применения индекса используется иная форма относительных адресов. Давайте с помощью этого индекса создадим дерево с двоичным основанием. На рисунке 6.5 показан индекс с рисунка 6.4 с представлением поля ключа в коде EBCDIC. Индекс представлен в шестнадцатеричной и двоичной формах. Например, первая буква имени Baker имеет шестнадцатеричное значение С2. В двоичной системе счисления С2 будет 11000010. Вторая буква имени Baker имеет шестнадцатеричное значение С1 (11000001 двоичное). Каждый ключ располагается в памяти в виде цепочки нулей и единиц, как показано на рисунке.
Теперь с помощью двоичного представления ключей можно создать дерево с двоичным основанием. При построении дерева ключи добавляются по одному. Сначала последовательность битов каждого нового ключа просматривается слева направо в поисках первого, отличающего данный ключ от всех ключей, уже вставленных в дерево. Предположим, что единственным элементом дерева является Baker и мы хотим добавить элемент Barns. Взглянув на рисунок 6.5, можно увидеть, что первым отли чающимся битом (сканирование всегда идет слева направо) будет пятый в третьем байте. Если в дереве только два элемента Baker и Barns, то чтобы отличить один от другого, достаточно проверить пятый разряд третьего байта. Если разряд равен 0, то это элемент Baker, а если 1, то Barns. Допустим, теперь мы хотим добавить к дереву Carson. Тогда первым битом, отличающимся и от Baker, и от Barns, будет восьмой первого байта. Последовательность построения дерева показана на рисунке 6.6. На первом шаге в дереве есть единственный окончательный узел для Baker. Окончательный узел содержит некоторый текст (в данном случае «Baker») и логический адрес записи 006. На втором шаге к дереву добавляется Barns. Здесь к дереву непосредственно над Baker добавляется тестовый узел для проверки пятого разряда третьего байта. Тестовый узел содержит общий текст ключей (BA) и номер бита, который должен проверяться в следующем байте. В нашем примере с двумя байтами совпадающего текста (ВА) ясно, что бит, нуждающийся в проверке, находится в следующем (третьем) байте, задавать который явно не обязательно. При выборе следующего узла всегда берется левый, если проверяемый бит равен 0, и правый — в противоположном случае. Справа от первого окончательного узла добавлен второй окончательный узел для Barns с логическим адресом записи 007. Обратите внимание, что после удаления общего текста, терминальные узлы содержат только остатки имен (KER и RNS для Baker и Barns соответственно).
Шаг 1: В дереве только BAKER
Шаг 2: Добавляем BARNES
Шаг 3: Добавляем CARSON Рисунок 6.6. Построение дерева с двоичным основанием На шаге 3 к дереву добавляется Carson. Создается новый тестовый узел для проверки восьмого бита первого байта. В новом тестовом узле нет общего текста. Если при проверке восьмой бит первого байта равен 0, то далее следует проверить расположенный левее тестовый узел для Baker/Barns. Если же восьмой бит первого байта равен 1, то следующим будет окончательный узел справа для Carson. Данный узел содержит текст (CARSON) и логический адрес записи 008. На рисунке 6.7 дерево показано полностью, со всеми девятью элементами. Тестовый узел наверху дерева называется корневым узлом. Хотя в данном примере представлен относительно небольшой индекс, он иллюстрирует многие характеристики дерева с двоичным основанием.
Рисунок 6.7. Пример дерева с двоичным основанием Любое имя в дереве может быть найдено уже описанным методом. Но как быть с именами, которых в дереве нет? Предположим, что мы пытаемся найти там имя Soltis. Проверяем третий бит первого байта и видим, что он равен 1, затем — шестой бит первого байта, который равен 0. Это приводит нас к окончательному узлу для Smith. Теперь понятна причина хранения текста в окончательных узлах — на один и тот же окончательный узел может отображаться много имен. При достижении окончательного узла необходимо сравнить хранящийся там текст с остатком имени, поиск которого мы ведем. Если они совпали — мы нашли правильный окончательный узел, если нет — искомое имя отсутствует в дереве. Другая характеристика дерева связана со способом добавления к нему элементов. Мы всегда просматриваем строку битов для каждого нового элемента слева направо в поиске первого бита нового ключа, отличающего его от всех, уже находящихся в дереве. Таким образом, гарантируется, что при проходе по любому пути в дереве биты проверяются слева направо. В тестовом узле никогда не приходится возвращаться к началу имени: мы всегда движемся вперед. Метод, используемый для вставки элементов, также гарантирует, что дерево всегда будет иметь одну и ту же конфигурацию, независимо от порядка добавления элементов. Более того, окончательные узлы всегда упорядочены в соответствии со значениями ключей слева направо. В нашем примере, окончательные узлы расположены в алфавитном порядке имен в ключевом поле. Это не случайность, а свойство дерева. Дерево само по себе обеспечивает логическую последовательность ключей, так что сортировка физических записей не нужна. Элемент дерева можно также удалить. Это простая операция, так как на окончательный узел может указывать один и только один тестовый узел. Возьмите имя, подлежащее удалению, отыщите в дереве соответствующий ему окончательный узел, удалите его, вернитесь к расположенному выше тестовому узлу и объедините его со вторым окончательным узлом в новый окончательный узел. Внутренняя организация дерева с двоичным основанием Внутренняя форма хранения дерева с двоичным основанием оптимизирована как с точки зрения производительности, так и занимаемого пространства. Первая базовая структура для дерева с двоичным основанием была создана инженером Филом Хо-вардом (Phil Howard) в 70-х годах. В его схеме правый и левый потомки тестового узла вместе с возможным общим текстом объединены в кластер. Такие кластеры располагались в памяти один за другим, и для ссылки на кластер использовалось его положение в цепочке. Это устраняло необходимость учета адресов для ссылки на следующий узел. Фил изобрел очень элегантный механизм перемещения от одного узла дерева к другому. Кластер не содержал адресов следующего или предыдущего узла. Вместо этого, их положения определялись с помощью операции XOR, что позволяло перемещаться по дереву в обоих направлениях. Этим достигалась еще и экономия памяти, поскольку не нужно было хранить прямые и обратные ссылки на предыдущие и последующие узлы. Чтобы найти следующий узел дерева, операция XOR выполняется над значением, хранящимся в текущем узле, и позицией предыдущего узла. Ясно, что значение, хранящееся в текущем узле, — результат XOR над позициями следующего и предыдущего узлов. Таким образом, чтобы вычислить местоположение следующего узла, нужно знать лишь текущее значение и позицию предыдущего узла. Предположим, что мы хотим пройти по дереву в обратном направлении. Выполнив операцию XOR над значением в текущем узле и позицией следующего узла, мы получаем позицию предыдущего узла. Таким образом, из любой точки дерева, зная предыдущую, текущую и следующие позиции, а также содержимое текущего узла, можно перемещаться вверх и вниз без ссылок. Для хранения нужных нам трех позиций годится простой стек. Реализация дерева с двоичным основанием минимизирует число страничных ошибок путем разделения дерева на поддеревья. Формально, такую структуру следовало бы называть фрагментированным деревом с двоичным основанием. При переполнении страницы, выше по дереву выполняется разделение, и к индексу добавляются новые поддеревья. Предположим, мы решили разделить дерево из нашего примера на рисунке 6.7. Разумно поместить на одну страницу все терминальные узлы от Baker до Peters вместе с их тестовыми узлами, а на вторую — терминальные узлы от Smith до Wu, а также один указывающий на них тестовый узел. Однако, здесь нас подстерегает неприятность. В узлах нет адресов для связи с другими узлами — вместо этого используются относительные номера позиций. Чтобы попасть на другую страницу памяти, необходим адрес. Решение состоит в создании узла нового типа, который будет содержать адрес и позволит ссылаться на другую страницу дерева. Если верхний узел нашего примера — корневой узел — поместить на третью страницу и разместить в нем указатели на две другие, то мы получим фраг-ментированное дерево. Верхние узлы на всех трех страницах теперь являются корневым узлами для своих страниц, и мы значительно увеличили максимальный объем памяти, которая может использоваться для хранения данного дерева. Другое преимущество фрагментирования — то, что, попав в процессе поиска на некоторую страницу памяти, содержащую фрагмент дерева, мы остаемся на ней на всех уровнях тестирования. Перед переходом на следующую страницу все тестовые узлы данной страницы на пути поиска будут просмотрены. Кроме того, поскольку для поиска в очень больших индексах требуется относительно немного проверок (вспомните, что при поиске в индексе из миллиона записей требуется, в среднем, только 20 проверок), то лишь в редких случаях придется затронуть более одной-двух страниц. В результате, данная схема обеспечивает наивысшую производительность по сравнению со всеми иными известными схемами индексации. Выводы Интегрированная база данных дает AS/400 целый ряд преимуществ, обеспечивая недостижимый для других систем уровень эффективности и производительности. Многие из этих преимуществ были нами рассмотрены. Так как база данных AS/400 не «сидит» поверх ОС, ею могут пользоваться все компоненты системы. База данных AS/ 400 не изолирована от других компонентов, как на обычных системах. База данных AS/400 позволяет приложениям, написанным для различных интерфейсов, сосуществовать и работать с одними и теми же данными, обеспечивая непосредственную реализацию на AS/400 внешних интерфейсов и инструментария других баз данных. Следовательно, и приложения, написанные для иных баз данных, уже сейчас могут работать прямо на AS/400, используя данные совместно с остальными приложениями. В будущем эти возможности станут еще более значимы. Интегрированная защита AS/400 защищает базу данных и другие компоненты системы от несанкционированного доступа и предотвращает разрушение данных. В следующей главе, мы рассмотрим эту интегрированную защиту, а также управление доступом в SLIC. Примечания:4 В последующие годы, специалисты, посещавшие Рочестер, видели этот формат команд и объявляли, что System/38 создана на основе System/370. IBM даже финансировала проекты, которые должны были обеспечить выполнение программного обеспечения System/38 как операционной системы на аппаратуре System/370. Все эти проекты потерпели крах. 5 Husson S. S. Microprogramming Principles and Practices. Prentice-Hall: 1970. 46 Есть уже много русских терминов, аналогичных data mining, однако в данном случае по моему мнению, точнее всего отражает суть процесса прямой перевод — разработка данных (mining — буквально раскопки, добыча полезных ископаемых). Чисто технически, это действительно очень похоже на, например, обогащение руды и выплавку металла. — Прим. консультанта. 47 Опросы показали, что многие пользователи AS/400 собираются приобрести базу данных в ближайшем будущем. Здесь следует отметить, что результаты опросов не следует принимать безоговорочно; они могут больше говорить о самом опросе, чем реальном положении дел. 48 Я не видел нужды в особом названии для базы данных AS/400 до тех пор, пока не встретился с представителями одной крупной промышленной компании. Один из них спросил, какую базу данных я мог бы порекомендовать для AS/400. Я выпалил: «DB2/400», — так мы именовали базу данных в своих внутренних дискуссиях. Почти все присутствующие сразу же начали кивать: «О, это очень хорошая база данных!». И я понял, что раз даже эти люди — работники других подразделений IBM — не знают, что в AS/400 есть база данных, то мы действительно должны дать ей имя. 49 По сути дела все это напоминает овощебазу: здесь картошка, там капуста, за углом — морковь и т. д. Кстати, «сгниют» данные в хранилище или принесут ощутимую пользу — зависит только от хозяина. — Прим. консультанта. 50 Бессмыслица, что-то вроде «утилита переформатирования преобразования». — Прим. консультанта. 51 После ухода из Рочестера Том Фьюри стал генеральным менеджером группы разработки DB2. В то время DB2 собиралась отмечать свою десятую годовщину, пресс-релизы с гордостью называли ее первой реляционной базой данных. Тому пришлось напомнить, что первой была база данных System/38. 52 Моя любимая книга на эту тему—Paul Conte. Database Design and Programming for DB2/400. Duke Press .1997. Настоятельно рекомендую! 53 Чтобы избежать полной путаницы, я использую, где возможно, более привычную для пользователей AS/400 терминологию «родного» интерфейса, за исключением случаев, когда описывается реализация именно SQL. 54 Те читатели, у которых понятие «пути доступа» вызывает затруднения, могут (с известной натяжкой) считать, что это примерно то же самое, что и индекс. — Прим. консультанта. 55 В информатике деревья всегда растут вверх ногами. Где еще корень расположен наверху, а ветви тянутся вниз? |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Главная | Контакты | Нашёл ошибку | Прислать материал | Добавить в избранное |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||