|
||||
|
|
 Архитектура PowerPC Архитектура PowerPC  Расширения архитектуры PowerPC Расширения архитектуры PowerPC  65-разрядный процессор? 65-разрядный процессор?  Система команд Amazon Система команд Amazon  Процессоры Muskie первого поколения Процессоры Muskie первого поколения  Процессоры Cobra первого и второго поколения Процессоры Cobra первого и второго поколения  О Процессоры четвертого и следующих поколений О Процессоры четвертого и следующих поколений  О Подсистема памяти О Подсистема памяти  Организация памяти Организация памяти  Перекрестные переключатели Перекрестные переключатели Глава 2 Технология PowerPC «По сути своей, IBM s компания технологий», — сказал Лу Герстнер (Lou Gerstner) вскоре после того, как возглавил корпорацию в 1993 году. И действительно, чуть ли не все основные технологии компьютерной индустрии s от RISC до реляционных баз данных s вышли из IBM. В прошлом IBM не всегда удавалось коммерчески использовать свои изобретения, и Герстнер собирается это изменить. По его мнению, главное s продвижение нескольких ключевых технологий, одна из которых — RISC-микропроцессор PowerPC в AS/400 Advanced Series. Микросхемы сжимаются на глазах Статистика говорит, что сегодня в мире от 300 до 400 миллиардов микросхем, в том числе около 15 миллиардов кристаллов микропроцессоров. В основном, это микросхемы памяти. Произвести их в таком количестве за последние несколько лет позволил быстрый прогресс в технологии кремниевых микросхем. Подавляющее большинство микропроцессоров используются не в компьютерах, а в наручных часах, телевизорах, кухонных приборах и автомобилях. Например, в новом автомобиле обычно от 10 до 12 микропроцессоров, а в некоторых моделях sзначительно больше. С каждым новым поколением микросхем производителям удается разместить на одном кристалле все больше транзисторов, примерно удваивая это число каждые 18 месяцев. Данная закономерность известна как закон Мура, названный так в честь Гордона Мура (Gordon Moore), председателя и одного из основателей Intel. В 1971 году Intel выпустила свой первый микропроцессор 4004, содержавший 2300 транзисторов на одной микросхеме. Современный кристалл микропроцессора содержит миллионы транзисторов. Предсказание Мура сбывается уже более четверти столетия1. Постоянное сокращение размера транзисторов позволяет увеличивать плотность их упаковки на кристалле. По мнению многих экспертов, вскоре после 2000 года появятся транзисторы размером всего лишь около 0,18 микрона; а еще менее чем через десять лет s 0,08 микрон. Для сравнения, толщина человеческого волоса примерно 80 микрон. Представьте себе тысячу транзисторов, размещенных на его срезе! Судя по такой стремительности прогресса, закон Мура продержится еще не один десяток лет. Не пройдет и десятилетия, и мы, вероятно, увидим микросхемы с более чем 100 миллионами транзисторов; а размещение на одной микросхеме миллиарда транзисторов может стать возможным уже лет через 15 лет. Все это обеспечит та же самая кремниевая технология, которая применяется для современных микросхем. Необходимость ее замены возникнет, по-видимому, не раньше чем через 20 лет. Однако у микросхем с высокой плотностью упаковки есть и минусы. Они невероятно сложны, и их разработка и производство становятся все дороже. В будущем экономические проблемы, вероятно, приведут к прекращению производства микросхем несколькими известными сегодня фирмами. Уже сейчас завод, производящий кристаллы для современных микросхем стоит более 2 миллиардов долларов, а стоимость производства микросхем с размером транзисторов менее 0,1 микрон, вероятно, «перевалит» за 10 миллиардов. С учетом продолжающегося падения цен на полупроводниковые микросхемы, можно предположить, что через 10 лет производителей микросхем останется не более десятка. Никто не знает, кто выдержит эту гонку, и сегодняшние удачи ничего не гарантируют в будущем. Возьмем, например, Intel. Многие считают, что благодаря популярности ПК, Intel s крупнейший производитель микропроцессоров. Но это не так! Intel производит только около 1,5 процента всех микропроцессоров. Motorola, Hitachi и даже Zilog (помнит ли кто-нибудь Z80?) продают гораздо больше микропроцессоров, чем Intel. Своим успехом Intel обязан, главным образом, высоким ценам, которые он устанавливает на свои микросхемы для ПК. Другие производители продают микросхемы равной производительности дешевле. Но пока существуют ПК, Intel может запрашивать высокие цены. IBM твердо намерена оказаться в числе тех производителей микросхем, которые выживут в следующем десятилетии. Свои надежды мы возлагаем на процессоры PowerPC, чья технология будет фундаментом AS/400 и другой продукции IBM в течение следующих нескольких лет. Итак, давайте более подробно рассмотрим эволюцию архитектуры PowerPC и использование ее в AS/400, а затем поговорим о процессорах, используемых в различных RISC-моделях AS/400. Альянс PowerPC В начале 1991 года Apple Computer подыскивала новый процессор для своих компьютеров. Ее специалисты полагали, что будущее процессоров ПК — в RISC-архитектуре. В то время процессоры ПК, производимые Motorola, Intel и другими фирмами, имели архитектуру CISC. Apple тогда использовала процессоры Motorola, и хотя последняя уже создала RISC-процессор, он не имел большого коммерческого успеха. У технологии RISC фундаментальные преимущества над CISC. RISC-процессор более производителен, он упакован на кристалле меньшего размера и потребляет меньшую мощность. В Apple поняли, что вычислительная техника, в конце концов, будет двигаться в этом направлении, но в 1991 году подавляющее большинство доступных микропроцессоров по-прежнему имели архитектуру CISC. В то время IBM производила одни из лучших RISC-процессоров. Они применялись в компьютерах RISC System/6000 (RS/6000). Все эти процессоры имели многокристальную 32-разрядную архитектуру, но IBM планировала выпустить в начале 1992 года однокристальную версию RCS (RISC Single Chip). Узнав, что Apple ищет новый RISC-микропроцессор, в IBM решили узнать, не подойдет ли им продукция IBM. Оправившись от шока, вызванного тем, что их прямой конкурент на рынке ПК — IBM — пытается продать им процессоры, в Apple решили, что в этом что-то есть. Зная, что Motorola также работает над новым RISC-процессором, Apple предложила объединить усилия трех фирм. После переговоров IBM согласилась, и в сентябре 1991 года три фирмы официально объявили о совместной разработке некоторых новых технологий, включая большое семейство микропроцессоров. В основе дизайна микропроцессоров должен был лежать RSC. Новое семейство получило название PowerPC. Три партнера понимали, что успех на рынке зависит от объема продаж новых микросхем и возможностей выбора программного обеспечения. Для этого они стали привлекать к использованию PowerPC производителей аппаратного и программного обеспечения, включая Toshiba, Canon, Zenith Data Systems, Harris Computer и Groupe Bull. Чтобы еще больше повысить объем продаж процессоров, члены альянса привлекли и фирмы, работающие вне области вычислительной техники. Хороший пример такого сотрудничества s компания Ford Motor. В будущих автомобилях Ford микропроцессоры PowerPC будут применяться для управления важнейшими узлами — от двигателя до системы торможения. Эволюция PowerPC Концепция RISC была разработана Джоном Коком (John Cocke) из IBM Research. Кок установил, что прогресс в области компиляторов достиг той точки, когда можно упростить набор команд процессора, и возложить на компилятор значительную часть работы, ранее выполнявшейся аппаратурой. Впервые идеи Кока были воплощены в миникомпьютере IBM 801. Процессоры PowerPC s прямые наследники 801. Основным мотивом создания архитектур CISC было желание сократить семантический разрыв между двоичным машинным языком процессора и ЯВУ, используемыми программистами. В двоичный машинный язык вводились команды, соответствующие инструкциям языка высокого уровня. Идея заключалась в том, чтобы процессор исполнял меньшее количество сложных команд, что позволило бы сэкономить память. К несчастью, машинные команды стали настолько сложны, что при создании практически любого процессора приходилось применять микропрограммирование. Накладные расходы микропрограммируемого эмулятора замедляли выполнение часто встречающихся простых команд. Кок доказывал, что при использовании только простых команд, необходимость в микропрограммировании отпадет, а все команды будут выполняться аппаратурой непосредственно. Более того, если бы стоимость памяти не была столь существенна, то компиляторы могли бы напрямую подставлять код для выполнения более сложных функций. Потребности в памяти увеличились бы, но возросла бы и производительность. Дизайн процессора 801 был заимствован у суперкомпьютеров s самых быстродействующих ЭВМ. Хотя сам термин «суперкомпьютер» до середины 70-х годов не использовался, но конструкторы, стремившиеся раздвинуть пределы возможностей аппаратных технологий, были всегда. Невозможно говорить о суперкомпьютерах, не вспомнив о Сеймуре Крее (Seymour Cray). Если хотите, Крей и суперкомпьютер — это синонимы. Современные архитектуры RISC-процессоров многим обязаны этому первопроходцу[ 10 ]. Значительно повысить производительность процессоров позволил метод конвейерной обработки (pipelining). На протяжении уже многих лет эта технология используется при создании всех компьютеров, от ПК до больших ЭВМ. Суть ее — в параллельном исполнении фрагментов последовательных команд на разных этапах аппаратного конвейера. Первый компьютер общего назначения, использовавший конвейерную обработку, появился еще в 1961 году. Это был IBM 7030, известный также под названием Stretch.
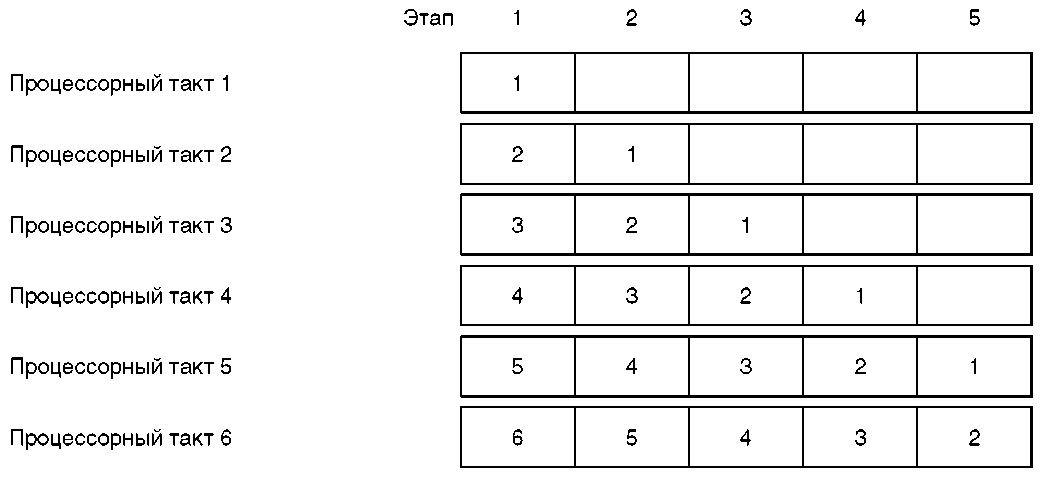
Рисунок 2.1а Конвейерный скалярный процессор — пятиэтапный конвейер команд. Пример пятиэтапного конвейера команд показан на рисунке 2.1а. Время, необходимое для выполнения каждого этапа выполнения команды, называется временем цикла процессора (processor cycle time). На рисунке 2.1б показана временная диаграмма пятиэтапного конвейера. В течение первого цикла процессора команда № 1 выбирается из буфера команд аппаратурой первого этапа конвейера. В течение второго цикла команда № 1 декодируется, и содержимое необходимых регистров считывается аппаратурой второго этапа. В то же самое время, аппаратура первого этапа считывает из буфера команд команду № 2. Теперь аппаратура разных стадий конвейера параллельно обрабатывает разные части двух разных команд. Благодаря такому параллелизму и достигается повышенная производительность процессоров с конвейерной обработкой. Обратите внимание: предполагается, что некоторая другая часть аппаратуры процессора обеспечивает заполнение буфера команд.
Рисунок 2.1b Пример временной диаграммы В течение третьего процессорного цикла команда № 1 поступает на стадию выполнения и вычисления эффективного адреса (стадия 3), команда № 2 поступает на стадию 2, а команда № 3 s на стадию 1. Процесс продолжается вплоть до завершения пятого цикла процессора, когда выполнение команды: № 1 заканчивается и она покидает конвейер. Таким образом, выполнение каждой отдельной команды занимает полные пять циклов, но после того, как конвейер заполнен, на каждом цикле процессора завершается выполнение одной команды. Когда говорят, что для выполнения одной команды необходим один цикл процессора, подразумевается, что конвейер заполнен, что, понятно, близко к идеалу[ 11 ]. В начале 60-х годов Сеймур Крей в Control Data Corporation разрабатывал первый в мире суперкомпьютер — CDC 6600. Он планировал использовать конвейерную обработку и добивался, чтобы время выполнения всех команд было одинаковым. Ведь, как видно из приведенного примера, общее время выполнения команд определяется командой, имеющей самое большое время выполнения. Команды, выбирающие операнды из памяти или записывающие их в память, обычно выполняются дольше остальных. Если эти, работающие с памятью, команды выполняют также и логические или арифметические действия над данными, то время выполнения может стать очень большим. Чтобы максимально сократить общее время выполнения команд, Крей решил, что в его процессоре единственными операциями с памятью будут загрузка в регистр содержимого памяти по некоторому адресу и сохранение содержимого регистра по некоторому адресу в памяти. Любые действия над данными должны производиться только в регистрах. Тогда это было очень непривычно: ведь большинство других компьютеров позволяли выполнять операции над данными в памяти без использования регистров. Например, команды S/360 позволяют сложить два находящихся в памяти операнда и записать сумму обратно в память. Эта операция занимает очень много времени, но выполняется одной машинной командой. Команды данного типа называются командами память-память. Для выполнения той же самой операции на машине Крея потребовалось бы пять команд. Сначала две команды загрузки поместили бы данные в два регистра. Затем команда сложения просуммировала бы содержимое этих регистров и поместила бы результат обратно в регистр. И, наконец, команда сохранения переписала бы сумму из регистра в память[ 12 ]. Но если эффективно поместить все эти пять команд на конвейер и выполнять их параллельно, то общее необходимое для этого время будет меньше времени, необходимого для выполнения эквивалентной операции на машине с командами типа память-память. И все же большее число команд, требуемых для выполнения операции, было недостатком машины Крея. В 1964 году появилась CDC 6600 s первая машина общего назначения с архитектурой загрузка/сохранение (load/store). Крей осознал связь между конвейерной обработкой и архитектурой набора команд, и это привело его к выводу о необходимости упрощения этой архитектуры для повышения эффективности конвейера. Современные RISC-процессоры используют подход Сеймура Крея — в них команды, работающие с памятью, выполняют только загрузку и сохранение. Вот почему RISC-машины быстрее CISC-машин с полным набором команд для работы с памятью. По той же причине и программы, скомпилированные для RISC, больше по размеру. Вклад Сеймура Крея в разработку высокопроизводительных конвейеров не ограничивается только архитектурой набора команд. В CDC 6600 он применил аппаратуру, которая обеспечивала максимум производительности путем максимально возможной загрузки конвейера, то есть ситуацию, при которой на каждой его стадии выполняется часть некоторой команды. В реальности, между командами в программах существуют зависимости. Если команда на конвейере использует данные, которые сохраняются командой, идущей по конвейеру непосредственно впереди нее, то в определенный момент эти данные могут быть еще недоступны, что не только вызывает простой конвейера, но и останавливает выполнение всех последующих команд. Тем самым уменьшается производительность процессора. В CDC 6600 было впервые реализовано оборудование, позволяющее процессору просматривать команды, расположенные далее в потоке команд, и определять, могут ли они быть запущены перед той, что ожидает сохранения результата. Идея аппаратного переупорядочивания команд на конвейере, известная как динамическое планирование (dynamic scheduling), служила поддержанию максимально возможной его загрузки и значительно повысила производительность CDC 6600. В суперкомпьютерах 60-х была реализована и идея предсказания переходов. Команда перехода может разрушить конвейер. Вызванный ею простой затянется до тех пор, пока система не будет в состоянии решить, какая команда должна выполняться следующей. Идея предсказания переходов состоит в том, чтобы на основе опыта угадать, откуда следует выбирать команду, следующую после команды перехода. Использованное в IBM 360/91 сложное аппаратное обеспечение предсказания переходов позволило достичь отличных результатов. 360/91 обладала еще одной интересной аппаратной особенностью. Опираясь на ее опыт, Боб Томасуло (Bob Tomasulo), инженер IBM, усовершенствовал алгоритм Крея, созданный несколькими годами ранее, и создал новый алгоритм динамического планирования. Реализованный аппаратно, алгоритм Томасуло устранил многие случаи простоя конвейера путем выполнения команд не по порядку их следования. Команда, которая должна ожидать получения некоторого результата, более не останавливает команды, следующие за ней. Алгоритм Томасуло требовал невероятно сложной по тем временам аппаратуры, но на деле позволял достичь желаемого роста производительности. Специализированное оборудование для повышения производительности конвейера повышало не только сложность, но и цену аппаратуры. Для суперкомпьютеров цена не играет особой роли, чего не скажешь об обычных системах. В конце 60-х годов Джон Кок работал над проектом быстрого компьютера для научных расчетов в IBM Research Laboratory в Сан-Хосе (San Jose), штат Калифорния, и вплотную столкнулся со сложностью оборудования, необходимого для поддержания загрузки конвейера. Кок полагал, что если переложить большую часть ответственности за это на компиляторы, то оборудование значительно упростится и подешевеет. И тогда высокопроизводительная обработка перестанет быть прерогативой суперкомпьютеров. Так родилась идея RISC. К сожалению, этот исследовательский проект был прерван прежде, чем Кок смог реализовать свои идеи. Еще один шанс сделать это представился ему в 1976 году, в исследовательской лаборатории IBM Yorktown в Нью-Йорке. Коку было поручено спроектировать и построить высокопроизводительный контроллер телекоммуникаций. Именно этот контроллер, получивший кодовое наименование 801 (по номеру здания, в котором работал Кок) обычно считается первым RISC-компьютером. 801 доказал, что планирование загрузки конвейерного процессора может быть возложено на компилятор. Сочетание компилятора, генерировавшего поток команд, оптимизированный для конкретного конвейерного процессора, и упрощенного процессора типа загрузка/сохранение, аналогичного машине Сеймура Крея, до сих пор остается непревзойденным. Современные RISC-процессоры используют идею Джона Кока s оптимизирующий компилятор, соответствующий аппаратуре процессора. Их производительность обеспечивается технологическими достижениями как аппаратуры, так и компиляторов. Поскольку за последние несколько лет компиляторы очень быстро прогрессируют, то есть даже предложения переименовать RISC в «Relegate Interesting Stuff to Compilers»[ 13 ]. Первым продуктом IBM, в котором использовались идеи 801, был PC RT. Подразделению по созданию продукции для офисов в Остине понадобился новый процессор. В качестве отправной точки для разработки был взят 801. Новый микропроцессор, названный ROMP (Research/Office Products Microprocessor), включал в себя подмножество 801, что обеспечивало низкую себестоимость. Главным архитектором и менеджером разработки PC RT выступал Гленн Хенри. Ранее он был программным менеджером нашего проекта в Рочестере, а после выхода на рынок System/38 перебрался в Остин, где возглавил первый проект IBM по созданию RISC-компьютера. 801 использовался также и другими организациями в качестве базы для создания RISC-процессоров. В начале 80-х исследования по этой теме велись группой Дэвида Паттерсона (David Patterson) в Калифорнийском университете в Беркли (Berkeley) и группой Джона Хеннеси (John Hennessy) в Станфордском университете. Именно Паттерсон и придумал термин «RISC». Выпускники обоих упомянутых университетов работали в IBM Research и знали 801. Проект Паттерсона лег в основу микропроцессора SPARC, использовавшегося компанией SUN, а проект Хеннеси s микропроцессора MIPS. Тем временем, в расположенной по соседству компании HP разработкой архитектуры PA-RISC занимался Джоел Бирнбаум (Joel Birnbaum), ранее возглавлявший группу 801 в IBM Research. Таким образом, PA-RISC также s прямой потомок проекта 801. Ранние процессоры RISC, как и 801, использовали один конвейер. Кок и другие сотрудники IBM полагали, что повысить производительность можно путем распределения на каждом цикле нескольких команд из обычного линейного потока по нескольким конвейерам. Такой компьютер был создан и назван суперскалярным. Первый суперскалярный RISC-процессор появился в 1990 году в RS/6000. В основе его архитектуры также лежал 801. Чтобы отметить суперскалярное расширение RISC-процессора, IBM назвала эту архитектуру POWER (Performance Optimization With Enhanced RISC). Архитектура POWER стала стартовой площадкой объединенного проекта Apple, IBM и Motorola.
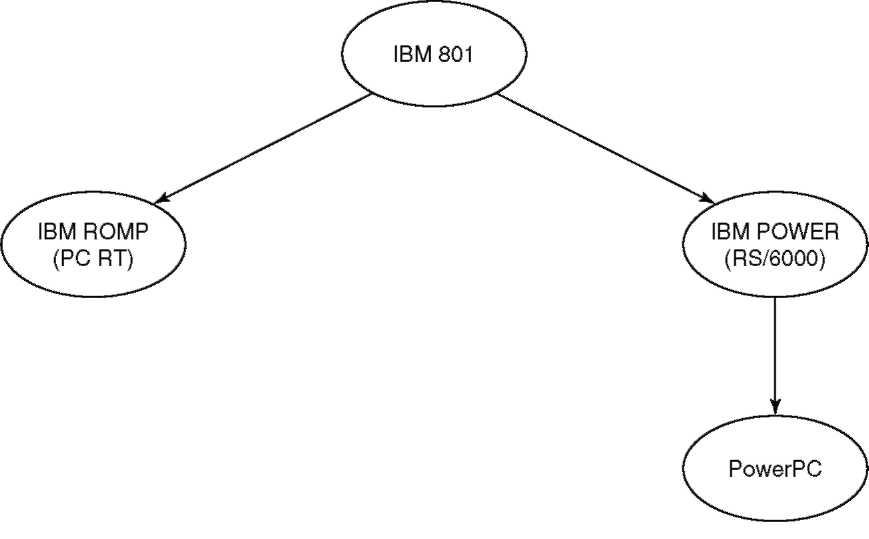
Рисунок 2.2. Эволюция PowerPC Чтобы удовлетворить будущие потребности всех трех корпораций, архитектуру POWER требовалось несколько изменить. Большинство процессоров POWER были многокристальными. Некоторое упрощение архитектуры сделало возможным создание дешевых однокристальных вариантов (иначе говоря, микропроцессоров). Кроме того, архитектура POWER не поддерживала многопроцессорные системы, так что и здесь понадобились соответствующие добавления. Были также увеличены возможности поддержки предполагаемых будущих приложений. Наконец, 32-разрядная архитектура POWER была расширена путем включения 64-разрядных адресов и операций. В результате всех этих изменений на свет появилась новая архитектура s PowerPC. Ее эволюция, начиная с 801, показана на рисунке 2.2. Усилиями инженеров Apple, IBM и Motorola был создан новый проектный центр для разработки микропроцессоров PowerPC. Персонал Somerset[ 14 ] Design Center, расположенного в Остине, состоит, в основном, из инженеров IBM и Motorola. В конце 1995 года Somerset стал частью подразделения IBM Microelectronics. Сотрудничающие фирмы имеют право производить и продавать процессоры, разработанные в Сомерсете. Например, Apple покупает микросхемы PowerPC как у IBM, так и у Motorola. Процессоры PowerPC Motorola производятся на заводе этой фирмы в Остине. IBM производит свои микросхемы PowerPC в Барлингтоне (Burlington), штат Вермонт. Важно отметить, что RISC-процессоры в последние несколько лет неуклонно прогрессируют. Практически каждый их производитель, включая консорциум PowerPC, ныне поставляет на рынок 64-разрядный RISC-процессор, на кристалле которого установлена аппаратура динамического планирования, использующая описанный выше алгоритм Томасуло, а также предсказания переходов. Удивительно, но мы, кажется, совершили полный круг? В современные процессоры снова включена вся аппаратура, для устранения которой и была первоначально предложена RISC-архитектура. Сеймур Крей мог бы гордиться: ведь аппаратные решения, предложенные им впервые в 1964 году, взяли верх над более простыми архитектурами ранних RISC-процессоров. Это определенно не те RISC-процессоры, что раньше! RISC-процессор AS/400 для коммерческих расчетов В 1990 году была разработана новая архитектура RISC-процессора для будущих моделей AS/400. Первоначальная архитектура процессора, получившая неуклюжее название Internal Microprogrammed Interface (IMPI)[ 15 ] была разработана в середине 70-х для System/38 и предназначалась для поддержки интерактивных коммерческих систем обработки транзакций. IMPI была преимущественно архитектурой память-память. С помощью одной команды данные могли быть выбраны из памяти, изменены процессором и записаны обратно. Обычно, интерактивные приложения обработки транзакций перемещают много данных, но изменяют лишь их малую часть. Рассмотрим типичную операцию обновления инвентарной описи. Пользователь делает заказ по телефону. Наше приложение должно обновлять инвентарную запись для каждой проданной им единицы товара. Инвентарная запись выбирается из памяти, или, что вероятнее всего, с диска. Размер заказа сравнивается с полем количества в записи, и если это количество достаточно, то оно уменьшается на число проданных единиц товара. Наконец, обновленная запись помещается обратно в память, и к ней может обратиться другой пользователь системы. Описанная операция может считаться отдельной транзакцией, или быть частью более крупной транзакции. В любом случае, мы имеем дело с обработкой транзакций. Кроме того, данное приложение интерактивно, так как им управляет человек за терминалом (приемщик заказа). Этому человеку исключительно важно получить ответ быстро. Следовательно, для создания интерактивной системы обработки транзакций абсолютно необходим процессор, который в состоянии перемещать большие объемы данных и выполнять операции в короткое время. AS/400 отлично подходит для приложений такого типа. На протяжении многих лет мы исследовали тысячи коммерческих приложений, написанных для AS/400 и других многопользовательских систем Рочестера. Все они имеют ряд общих характеристик. Рассмотрим некоторые из них. Возможность поддерживать параллельную работу сотен и даже тысяч пользователей. Длинные последовательные цепочки команд, причем большая часть длины такой цепочки приходится на код операционной системы, а не приложения. Приложения выполняют множество обращений к операционной системе за различными видами обслуживания, например, для ввода-вывода. Адресация структур данных в AS/400 выполняется посредством указателей, что требует использования целочисленной арифметики для обновления адресов. При обработке данных используются, в основном, строковые или целочисленные сравнения, обновления и вставки. Арифметика с плавающей точкой используется редко. Циклы в приложениях для AS/400 встречаются реже, а нециклические переходы чаще, чем в приложениях для научных расчетов. Обрабатываемые данные разбросаны по большому объему дискового пространства. Объем данных, выбираемых за одно обращение к диску, относительно невелик, а последовательные обращения с большой вероятностью будут обращены к разным дискам. Сравним приложение данного типа с типичным приложением для инженерных или научных расчетов, выполняемом на специализированной рабочей станции. Последние часто называют вычислительными (compute-intensive), так как они выполняют большие объемы вычислений с относительно малыми объемами данных. Обычно, такие приложения имеют малые рабочие наборы команд с большим числом компактных циклов вычислений с плавающей точкой. Ввод-вывод в них чаще последовательный, а не прямой. Сеймур Крей показал, что для приложений такого типа наилучшим будет процессор, который обрабатывает данные только в регистрах, как RISC-процессоры. Коммерческие приложения по-прежнему преобладают, среди программ, написанных для AS/400. Но появляется все больше высокопроизводительных вычислительных приложений, что связано с переходом к модели клиент-сервер. В этой модели приложение разбивается между ПК или сетевым компьютером СК (клиент) и AS/ 400 (сервер). Серверные приложения ориентированы на увеличение числа операций, по сравнению с интерактивными приложениями. Приложения будущего, вероятно, потребуют еще большей вычислительной мощности. С момента своего появления архитектура IMPI неоднократно расширялась и модифицировалась. Но даже и с учетом этих изменений ее нельзя признать подходящей для выполнения большого объема вычислений. Большинству специалистов в Рочестере было ясно, что для удовлетворения будущих потребностей в вычислительной мощности необходимо введение характеристик RISC-процессора. Итак, в 1990 году мы начали проект по добавлению к IMPI свойств RISC. Сначала мы хотели использовать процессор от RS/6000, но быстро отказались от этой мысли. Архитектура POWER была разработана для технических расчетов. Ей недоставало ряда характеристик, необходимых для выполнения коммерческих вычислений. Кроме того, она не могла обрабатывать большие объемы данных с требуемой эффективностью. В то время RISC-процессоры были, как правило, 32-разрядными (то есть ширина трактов данных и регистров процессора равна всего лишь 32 битам). Большинство имело и 64-разрядные регистры с плавающей точкой, но целочисленные регистры — те, которые используются для коммерческих расчетов, — имели только 32 разряда. А так как RISC-процессор перед обработкой данных должен сначала загрузить их в свои регистры, то при больших объемах данных 32-разрядная ширина быстро становится недостатком. Архитектуры CISC, такие как IMPI, могут выполнять команды память-память, обрабатывая данные без загрузки их в регистры, таким образом, это узкое место здесь фактически обходится. Приняв во внимание эти соображения, мы решили, что для нашего будущего компьютера необходим полностью 64-разрядный процессор. Дополнительно на нас влияло то, что ширина адреса в AS/400 равна 48 битам, и этот адрес невозможно втиснуть в 32-разрядный регистр. 64-разрядный процессор позволял нам расширить адрес, используемый в IMPI, с 48 до 64 бит. Наши расчеты показывали, что в будущем, по мере того как системы AS/400 будут становиться все больше и больше, настанет момент, когда потребуется больший размер адреса. Нельзя было не брать во внимание и объем микрокода, который пришлось бы изменить. Начав с IMPI, мы смогли бы минимизировать эти изменения. Итак, было принято решение: взять IMPI, расширить его до 64 бит и добавить вычислительные операции, присущие RISC. Нам предстояло создать первый гибридный процессор CISC/RISC, предназначенный исключительно для коммерческих вычислений. Мы назвали его C-RISC — «Commercial-RISC». Технология PowerPC для AS/400 Президентом IBM в 1991 году был Джек Кюлер (Jack Kuehler). Он привел IBM к соглашению с Apple и Motorola о создании микропроцессоров PowerPC. Джек Кюлер считал, что к концу десятилетия все компьютеры, от самых маленьких, умещающихся на ладони, до суперЭВМ будут использовать RISC-процессоры. Он также полагал, что компании, создающие такие микропроцессоры, можно будет пересчитать по пальцам одной руки, и был твердо уверен, что альянс PowerPC станет одной из таких выживших фирм.
Кюлер не мог понять, почему обе его основные лаборатории одновременно занимаются разработкой новых RISC-процессоров. Лаборатория в Остине ра ботала над спецификацией PowerPC, а лаборатория в Рочестере s над C-RISC. I Кюлер был убежден в необходимости объединить усилия двух этих исследовательских центров, а также в том, что PowerPC подойдет и тем, и другим. Он стал выяснять, почему Рочестер не может использовать этот процессор. Мы покорно ездили в Армонк (Armonk), штат Нью-Йорк, где попытались объяснить различия между процессорами для коммерческих и научных расчетов. Кюлер не оспаривал успехи Рочестера, но и не принимал наши доводы. Он требовал дополнительные данные в обоснование нашей позиции. «Неужели RS/6000 не может выполнять и коммерческие вычисления?» — спрашивал он. Наконец, примерно после третьего визита в Армонк нам удалось его убедить. Специалисты Рочестера знали, о чем говорят. Они понимали как делать процессоры для коммерческих вычислений, и чем эти процессоры отличались от предназначенных для технических расчетов. И все же Кюлер настоял, чтобы через 90 дней мы вернулись к нему с ответами на два вопроса: «Как изменить архитектуру PowerPC, чтобы она стала подошла для AS/400?» и «Сколько будет стоить перевод AS/400 на эту новую архитектуру?». Тем самым Кюлер дал нам возможность влиять на проект PowerPC. Он также изъявил желание финансировать любые дополнительные расходы, связанные с переходом на новый процессор. В начале апреля 1991 года я возглавил группу из 10 человек, которая должна была дать ответ на оба эти вопроса. Кюлер также дал указание главе IBM Research, отвечавшему за согласование архитектуры PowerPC с Apple и Motorola, работать в тесном контакте с нами. Кроме того, наши инженеры тесно сотрудничали со своими коллегами из Остина. Успех проекта во многом зависел от из рочестерской команды:, чьи инженеры были в числе самых лучших. Задача была не из легких. Сначала казалось, что требования AS/400 прямо противоположны задачам PowerPC. Затем возникло ощущение, что в результате слияния этих двух архитектур Рочестер лишится возможности создавать процессоры, оптимизированные для коммерческих расчетов. Нечего и говорить, как горячи были споры! Было решено начать с архитектуры PowerPC в том виде, как она была определена на тот момент. К ней следовало добавить расширения, необходимые для AS/400. В результате должно было получиться нечто новое, заранее названное, в отличие от базовой архитектуры PowerPC, Amazon.
Хотя в Рочестере и были определенные сомнения в плодотворности идеи общей архитектуры RISC, тем не менее, ее разработка шла быстро. Основная роль здесь принадлежала Энди Уоттренгу (Andy Wottreng) и Майку Кор-ригану (Mike Corrigan). Они выполнили выдающуюся работу по интеграции технических требований AS/400 в новую архитектуру. В результате, впервые была создана архитектура RISC, которая одинаково хорошо подходила и для коммерческих, и для технических приложений. За координацию проекта отвечал Дэррил Соли (Darryl Solie). Он находился в тесном контакте с обеими группами разработчиков в Остине и Рочесте-ре и обеспечивал взаимодействие между ними. Проектировщики Рочестера многому научились у инженеров других подразделений IBM и Motorola. Уровни производительности процессоров, которые сперва казались недостижимыми, внезапно становились возможными. В результате, сейчас в Рочес-тере создаются одни из самых быстрых процессоров в мире. Наша лаборатория отвечает внутри IBM за разработку новых 64-разрядных процессоров для коммерческих вычислений. Всякий раз, когда возникали трения, разгорались споры, и кто-нибудь начинал утверждать, что порочна идея в целом, в дело вмешивался Билл Берг (Bill Berg). Спокойно, дипломатично и быстро убеждал нас в том, что мы s на правильном пути, и что только мы можем пройти его до конца. Позднее Билл способствовал тому, чтобы убедить разработчиков использовать при создании программного обеспечения новой операционной системы объектно-ориентированные технологии. Архитектура PowerPC должна была работать как в 32-разрядном, так и в 64-разрядном режимах. Все 64-разрядные версии PowerPC должны были иметь и 32-разрядное подмножество. Мы сосредоточились только на 64-разрядном режиме, практически не изменив 32-разрядное подмножество. По мере разработки новой архитектуры мы могли предварительно оценить ее стоимость. Работа велась напряженно и была завершена за 90 дней, но результаты не слишком впечатляли. Многие из необходимых нам архитектурных изменений было бы трудно внести в ранние версии процессоров PowerPC, разработанные в Сомерсете. Процессоры поздних моделей AS/400 должны были обрабатывать очень большие объемы данных, и для нужной производительности требовались очень широкие шины данных. Мы даже не пытались ничего добавлять в конструкции процессоров PowerPC 601, 603 или 604, так как они поддерживали только 32-разрядный режим. Было также крайне сомнительно, сможем ли мы усовершенствовать первый разработанный в Сомерсете 64-разрядный процессор (его окончательное название s 620), так как плотность упаковки элементов на этом кристалле была недостаточна для того, чтобы сделать его подходящим для наших моделей — пришлось бы разработать многокристальную версию архитектуры. Даже в отношении младших моделей AS/400 у нас не было полной ясности. Некоторое время мы предполагали применить усовершенствованный вариант 620, который мы назвали 621, но в конце концов решили, что проще всего разрабатывать процессоры для AS/400 внутри IBM. Одновременно с нами разработчики RS/6000 также пришли к заключению, что не смогут использовать ранние версии процессоров PowerPC в своих старших моделях. Для младших моделей подходил однокристальный процессор разработанный в Сомерсете, но для более высокопроизводительных моделей требовался многокристальный процессор. Кроме того, наши коллеги хотели включить в свой проект некоторые коммерчески выгодные возможности технических вычислений, а именно, NIC (numerically intensive computing), большинство из которых отсутствуют в обычном PowerPC. Также было добавлено больше конвейеров и новые вычислительные команды. Созданное в результате расширение первоначальной архитектуры POWER получило название POWER2. Впервые процессоры архитектуры POWER2 были применены в RS/6000 в 1993 году. Они также использовались в RS/6000 Scalable POWERparallel System (RS/6000 SP). Последняя система ознаменовала выход IBM на рынок компьютеров параллельных вычислений. В RS/6000 SP может работать параллельно много таких процессоров. Параллельные машины очень хороши для ряда научно-технических и некоторых коммерческих приложений, например, для просмотра больших баз данных. Первоначально архитекторы AS/400 и RS/6000 хотели добиться общей конструкции процессоров, решив включить в архитектуру Amazon все необходимые для них расширения. Мы планировали создать один процессор, который мог бы поддерживать специфические требования обеих систем. У первого общего процессора PowerPC, предназначенного как для AS/400, так и для RS/6000, было несколько названий. Разработчики RS/6000 часто называли его POWER3, или PowerPC 630. Мы дали ему внутреннее имя Belatrix. Беллатрикс s это звезда в созвездии Ориона. Немногие знают, что ее называют также звездой Амазонки (Amazon Star). Belatrix должен был стать звездой архитектуры Amazon. Как и многие предыдущие проекты, проект Belatrix был слишком амбициозным и всеохватывающим и не имел успеха. Мы решили, что целесообразнее иметь несколько версий процессоров PowerPC, оптимизированных для разных вычислительных сред. Каждый процессор PowerPC должен был реализовывать базовый набор команд и функций, а также поддерживать необязательные расширения. Рочестер должен был сделать первые процессоры PowerPC применимыми для коммерческих задач. Первоначально они предназначались исключительно для AS/400. Позже было принято решение: начиная с 1997 года использовать новое поколение 64-разрядных процессоров PowerPC, разработанных в Рочестере, и для RS/6000. После прекращения работ над Belatrix в Остине начали разработку новой версии 630 — 64-разрядного процессора PowerPC, который должен был обеспечить вычислительную производительность, необходимую для будущих систем. Мы в Рочестере также стали разрабатывать свою версию Belatrix, которая предназначалась для серии AS/400 1998 года. Так как Belatrix назван по имени звезды, а Миннесота известна как штат Серверной звезды (North Star), то мы назвали новый процессор Northstar[ 16 ]. В области программного обеспечения ситуация с PowerPC была гораздо хуже, по сравнению с тем, что мы обещали Кюлеру. Все прикладное и системное программное обеспечение, работавшее поверх MI, было защищено благодаря независимой от технологии архитектуре AS/400. Однако, поскольку PowerPC сильно отличается от IMPI, то микрокод, расположенный ниже MI, было необходимо переделать под новый процессор. Это нелегкая задача, несмотря на то, что часть ее можно было осуществить с помощью автоматизированных средств. Между тем наши программисты должны были заниматься выпуском новых версий AS/400. Мы подсчитали, что для работы с RISC-процессором потребуется нанять несколько сотен новых системных программистов. Наконец, мы были ограничены по времени. Первоначально планировалось выпустить новые процессоры C-RISC в середине 1994 года, мы уже мечтали о них для Advanced Series. При использовании PowerPC нам пришлось бы изменить планы и передвинуть выпуск RISC-процессоров на 1995 год s именно столько времени потребовалось бы для разработки нужных расширений и переписывания внутреннего кода. Пришлось бы оснащать Advanced Series процессорами IMPI и обеспечить возможность их модернизации процессорами PowerPC, когда последние будут готовы. В начале июля 1991 года мы вновь нанесли визит Джеку Кюлеру. Большинство из нас полагали, что он поблагодарит за проделанную работу, сделает вывод, что переход на процессор PowerPC будет слишком дорогим и отправит обратно заниматься созданием C-RISC. Но Кюлер ничего такого не сделал. Вместо этого он попросил нас ускорить работу и предоставил необходимые для этого ресурсы. Так, внезапно для нас, пришлось полностью изменить направление работ над Advanced Series как в области аппаратного, так и программного обеспечения. В конце июля мы завершили реорганизацию лаборатории для работы над новой системой. Ответственность за разработку новой модели процессора, названной Muskie, была возложена на Рочестер. Этот многокристальный процессор был предназначен для коммерческих вычислений на очень больших компьютерах. Разработка младших моделей серии AS/400 была переведена в лабораторию IBM в Эндикот-те. Эта линия получила наименование Cobra, и ее процессоры должны были быть однокристальными и полностью 64-разрядными. Как уже упоминалось, первоначально мы планировали только 64-разрядный режим процессора. В конце концов, AS/400 не использует 32-разрядный режим, да и никто более не собирался использовать ранние 32-разрядные процессоры, так что реализовывать эту архитектуру в полном объеме, как нам казалось, не имело смысла. Но примерно через год, когда стало ясно, что AS/400 необходимо поддерживать все прикладное программное обеспечение, написанное для процессоров PowerPC, это решение было изменено. Поскольку большая часть таких программ написана для 32-разрядных процессоров, то и нам пришлось включить во все свои процессоры 32-разрядное подмножество. Это также должно было обеспечить возможность использовать наши новые PowerPC на других системах IBM. Одновременно активизировалась работа по переносу микрокода AS/400 на новые процессоры. Это была возможность ревизии внутренностей операционной системы AS/400, чего не делалось с момента разработки System/38. Поскольку мы собирались перекраивать самые основы, то было решено идти до конца и использовать новейшие объектно-ориентированные методологии программирования. Мы планировали получить самую современную операционную систему.
За организацию работ по переделке основ операционной системы отвечал Майк Томашек (Mike Tomashek). Майк знал, что у него нет ни людей, ни W опыта для того, чтобы уложиться в отведенные сроки. Любой здравомыслящий человек подтвердил бы, что это невозможно. Вместе с ключевыми раз-1 работчиками, такими как Билл Берг и Крис Джонс (Chris Jones) Майк разработал план. Им было нужно нанять сотни новых людей, обучить их объектно-ориентированным технологиям и переписать важнейшие части операционной системы AS/400 за короткие сроки. Майк не потратил много времени на раздумья и дебаты. Он просто объявил, что план сработает, и на полной скорости двинулся вперед. В конце 1991 мы начали массовый найм программистов. В ряде крупнейших газет Америки стали появляться объявления о том, что в Рочестере требуются системные программисты с опытом работы на С++. Нам удалось быстро нанять несколько сотен новых программистов. Тогда многие обозреватели удивлялись, для чего нам это понадобилось, но теперь они знают. Прежде чем перейти к более подробному рассмотрению архитектуры PowerPC, хочу напомнить о нашей «перечной» системе рейтинга. Оставшаяся часть этой главы — лишь для тех, кому нужны дополнительные подробности. Обратите внимание, что когда мы начнем обсуждение реализации процессора, материал станет еще «острее». Если «попробовав этой информации Вы найдете ее «чересчур», просто пролистайте книгу, пока не дойдете до тех разделов, где меньше специй.
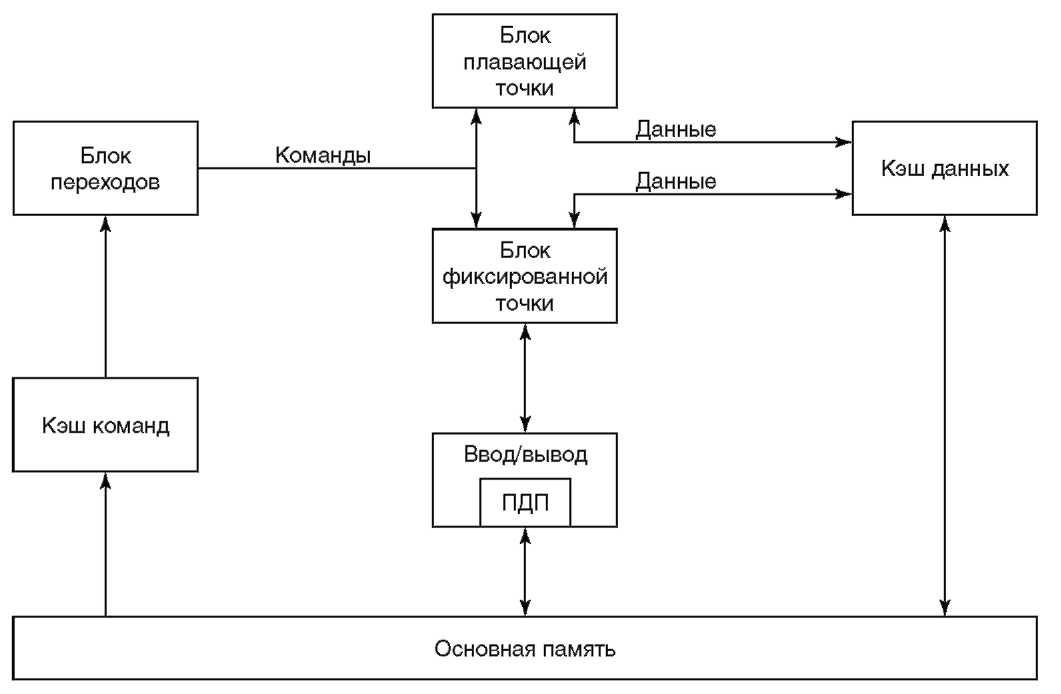
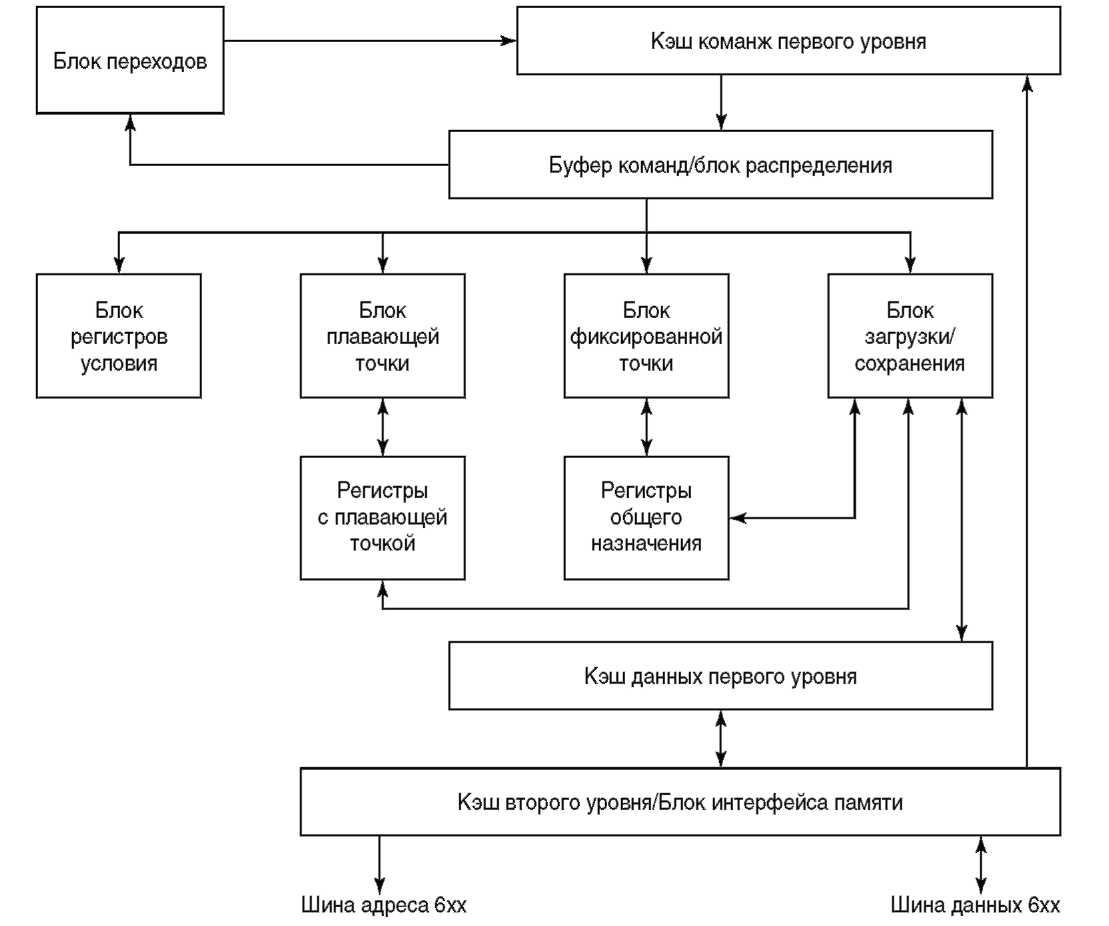
Архитектура PowerPC обладает всеми обычными характеристиками архитектуры RISC: команды фиксированной длины, операции регистр-регистр, простые режимы адресации и большой набор регистров. Но есть и характеристики, отличающие ее от других. Как уже упоминалось, архитектура PowerPC — полностью 64-разрядная с 32-разрядным подмножеством. Она допускает как 32-разрядные, так и 64-разрядные версии процессоров PowerPC, но все они должны поддерживать, как минимум, 32-разрядное подмножество. Архитектура определяет переключатель режима 32/64, которые может использоваться операционной системой, чтобы позволить 64-разрядному процессору выполнять 32-разрядные программы. В основе набора команд лежит идея суперскалярной реализации. В суперскалярном процессоре за один такт несколько команд могут быть распределены на несколько конвейеров. Аппаратура процессора просматривает поток команд и отправляет на выполнение максимально возможное число независимых команд (обычно от двух до четырех за цикл). Эти команды могут далее выполняться параллельно и даже завершиться в порядке, отличном от первоначального. Такой дополнительный параллелизм может значительно увеличить общую производительность процессора. Команды направляются одновременно в три независимых исполняющих блока. Общая структура PowerPC показана на рисунке 2.3: блок переходов, блок фиксированной точки и блок плавающей точки. Также показан кэш команд[ 17 ], кэш данных, память и пространство ввода-вывода, которое в данной архитектуре выглядит как часть памяти.
Рисунок 2-3 Модель архитектуры PowerPC Для каждого исполняющего блока архитектурой определен независимый набор регистров. Любая определенная архитектурой команда может выполняться только одним типом управляющих блоков. Таким образом, у каждого блока собственный набор регистров и собственный набор команд. Эти исполняющие блоки часто называют процессорами, так как им присущи все характеристики процессора. Можно считать, что процессор PowerPC содержит три отдельных процессора s исполняющих блока. При этом каждый исполняющий блок может иметь несколько конвейеров команд. Если, например, для модели, оптимизированной для вычислительных задач, важна производительность операций с плавающей точкой, то блок плавающей точки может содержать два и более конвейеров и, таким образом, выполнять более одной команды плавающей точки одновременно. То же самое верно и для двух других блоков. В принципе, возможно создать процессоры PowerPC, способные выполнять пять и более команд одновременно. Преимущество такой схемы не только в одновременном выполнении нескольких команд, но также и в минимальной необходимости взаимодействия и синхронизации между блоками, что достигается благодаря наличию у каждого блока отдельных ресурсов. Исполняющие блоки могут подстраиваться под изменяющийся поток команд, позволять командам обгонять друг друга и завершаться в ином порядке. Другая характеристика архитектуры PowerPC, отличающая ее от обычного RISC-процессора s использование нескольких составных команд. Самой большой недостаток RISC по сравнению с CISC — увеличение объема кода. Для выполнения одной и той же программы RISC требуется больше команд, чем CISC. Составные команды позволяют уменьшить это разрастание кода. Некоторые из них очень просты, например, обновление регистра базы при загрузке и сохранении, что позволяет исключить дополнительную команду прибавления. Другие более сложны, например, команды множественной загрузки и сохранения, позволяющие перемещать значения нескольких регистров одной командой. Есть также команды загрузки/сохранения цепочек, которые позволяют загружать и сохранять произвольно выровненную цепочку байтов. Фанатики CISC узнают в последней паре команд не слишком хорошо замаскированные команды пересылки символов. Ортодоксы RISC негодуют и обвиняют архитекторов PowerPC в том, что они «продались» сторонникам CISC. На самом же деле, надо просто понять, что в реальности некоторые операции, такие как пересылка невыравненных строк байтов, происходят достаточно часто и требуют определенной оптимизации. Если составная команда дает то, что нужно, даже нарушая при этом какое-то неписаное правило «чистого» RISC, то пусть так и будет. Составные команды не означают возврата к архитектуре CISC, однако их применение в RISC-процессорах лишний раз доказывает, что в мире нет ничего абсолютно белого или черного. Интенсивное применение суперскалярных возможностей и использование составных команд составляют философию проектирования архитектуры PowerPC. Эта философия используется также и другими архитектурами, такими как Sun SuperSPARC и Motorola 88110. Есть мнение, что такая сложность затрудняет достижение процессорами высоких тактовых частот, обычно измеряемых мегагерцами (МГц). Сторонники этой точки зрения полагают, что большая производительность может быть достигнута скорее за счет высокой тактовой частоты, а не интенсивного параллелизма на уровне команд. Что такое МГц? В последние годы стало популярным выражать производительность микросхемы процессора ЭВМ с помощью этой единицы измерения. Для простоты восприятия, ее можно соотнести с оборотами в минуту автомобильного двигателя: эта величина показывает, насколько быстро вращается двигатель автомобиля, или сколько оборотов в минуту совершает коленчатый вал. Скорость процессора можно рассматривать как число тактов, которое он может выполнить в секунду. За один такт процессор обычно может выполнить одну простую команду, так что иногда данная величина воспринимается как приблизительное число команд, выполняемое процессором в секунду. Физическая единица герц (Гц) получила свое название в честь немецкого физика и равна одному циклу в секунду. Один мегагерц (Mrii)s это миллион циклов в секунду. Философию высокой тактовой частоты можно проиллюстрировать и примерами архитектур Digital Alpha, HP PA-RISC и MIPS R4000. Возьмем, например, PA-RISC 1.1. Этот процессор обычно выполняет две команды за такт. Менее мощные модели PowerPC могут за такт исполнять три команды, тогда как старшие модели s четыре и более. Этот дополнительный параллелизм дает PowerPC выигрыш в производительности, хотя и за счет увеличения сложности, что может снизить тактовую частоту. Спор о том, какая из этих двух точек зрения лучше, продолжается. Противоборствующие лагеря условно можно назвать «Speed Daemons» (высокая тактовая частота) и «Brainiacs» (сложность). Суть вопроса в том, что тактовая частота, измеряемая мегагерцами, не всегда адекватно отражает общую производительность процессора. 150 МГц Brainiac может легко превзойти по производительности 300 МГц Speed Daemon. Все зависит от выполняемой программы и степени параллелизма команд, которой может достичь компилятор. Некоторые новости указывают на то, что чаша весов склоняется на сторону архитектур Brainiac, таких как PowerPC. Судя по описанию, новая архитектура HP, получившая название PA-RISC 2.0, выглядит так, словно ее создатели поддались зову сирены сложности. Так как архитектура PA-RISC 2.0 остается процессор- ориентированной, то как объявлено HP, 64-разрядные приложения для новой аппаратуры появятся примерно через 3-5 лет.
Так как первое поколение процессоров PowerPC создавалось специально под AS/400 и не было PowerPC в полном смысле, мы решили дать этим процессорам новое название s PowerPC Optimized for the AS/400 Advanced Series, но так как это труднопроизносимо, решено было остановиться на более кратком варианте s PowerPC AS. Большинство расшифровывают AS как Advanced Series, но многие из нас предпочитают считать, что это Amazon Series. Во втором поколении наших процессоров, представленном в 1997 году, мы реализовали и полную архитектуру PowerPC, и все расширения. Так как те же самые процессоры используются RS/6000, то обозначение AS более не имеет смысла. Самое существенное новшество архитектуры для AS/400 — использование тегов памяти (memory tags), которые будут подробно рассмотрены в главе 8. А вкратце мы поговорим об этом прямо сейчас. В System/38 была реализована концепция одноуровневой памяти. Проще говоря, вся память, включая дисковую, представляет собой большое единое адресное пространство. Нам был необходим эффективный механизм защиты памяти от пользователей, не имеющих права доступа к ним. В MI адресация выполнялась с помощью 16-байтовых указателей. Указатель содержит некоторый адрес, и пользователь может этот адрес изменить (подробнее об этом будет рассказано в главе 5). Поскольку адрес после изменения может указывать на любую область памяти, необходимо предотвратить неавторизованные изменения адресов пользователями. С каждым словом памяти System/38, имеющим 32 разряда данных, связан специальный бит защиты памяти, называемый битом тега (tag bit). Указатель MI занимает четыре таких слова. Всякий раз, когда операционная система сохраняет в четырех последовательных словах памяти указатель, аппаратура включает (устанавливает в 1) четыре бита тега, для индикации того, что указатель содержит адрес, допустимый для данного пользователя. Если пользователь изменяет в памяти любую часть указателя, то аппаратура выключает (устанавливает в 0) бит тега. Если хотя бы один из битов тега сброшен, то адрес в указателе неверен и не может быть использован для доступа к памяти. В целях безопасности бит тега не может быть одним из битов данных внутри слова, так как последние пользователь может видеть и изменять. Он должен быть скрытым, то есть храниться в недоступной пользователю области памяти, но где именно? System/38 использует для каждого слова памяти биты кода коррекции ошибок. Содержащая их часть памяти невидима программам, работающим поверх MI. Мы решили добавить к битам кода коррекции ошибок еще один и использовать его как бит тега. При изменении слова памяти какой-либо пользовательской программой, процессор должен автоматически сбрасывать скрытый бит тега. Ведь если данное слово станет частью указателя, то тот будет неверным. Только микрокод расположенный ниже MI имеет команды для включения битов тега. В памяти AS/400 также используются биты тега. Поскольку в архитектуре PowerPC таковые не предусмотрены, нам пришлось добавить к ней режим активных тегов (tags-active mode). В этом режиме процессор «знает» о битах тега и будет сбрасывать их всякий раз, когда пользователь изменяет слово в памяти. Все процессоры AS/400 работают в режиме активных тегов. Существующие процессоры PowerPC используют режим неактивных тегов.
В AS/400 ширина слова памяти возросла до 64 разрядов данных. С каждой восьмеркой байтов памяти AS/400 связан бит тега и указатель MI, занимающий два таких слова. В 1991 году нам виделись некоторые преимущества в том, чтобы хранить два теговых бита в регистрах новых RISC-процессоров, так же как и в памяти. Кроме того, мы хотели сократить размер указателей MI до 8 байтов. Внутри 16-байтовых указателей было неиспользуемое пространство, и казалось, что как раз настал подходящий момент сжать их. Для того чтобы хранить такие тегированные указатели в регистрах, размер целочисленных регистров нужно было увеличить до 65 разрядов. Мы разрабатывали описанную схему около года, но в 1992 году отказались от нее и вернулись к решению, хранить теги только в памяти. На то было три основных причины. Во-первых, изменение размера указателя влияло на OS/400 и требовало слишком многих модификаций ее кода. Во-вторых, такой подход ограничивал будущие расширения размера адреса 64 разрядами. И третье, самое важное — процессоры в режиме активных тегов оказались бы несовместимы с набором команд PowerPC. Первоначально мы не считали совместимость с PowerPC важной. Будущие процессоры, реализующие режим неактивных тегов, где 65-й разряд игнорируется, были бы полностью совместимы с PowerPC. А реализация 32-разрядных команд в режиме активных тегов и соответствующее программное обеспечение не планировалась даже в начале проекта. Ведь предполагалось, что этот режим будет использоваться только операционной системой AS/400, которая имеет дело с 64-разрядными командами. Затем, когда было решено поддерживать совместимость с набором команд PowerPC, мы избавились от 65-го разряда в процессоре. Тогда намечалось некое слияние операционных систем IBM (см. Приложение). В рамках этого проекта предполагалось и программное обеспечение, большая часть которого предназначалась для 32-разрядного процессора. Поэтому мы обеспечили поддержку 32-разрядного набора команд всеми процессорами даже в режиме активных тегов. Наши процессоры второго поколения имеют режимы как активных, так и неактивных тегов и могут исполнять все прикладное и системное ПО PowerPC. Хотя мы вернулись к 64-разрядным процессорам уже много лет назад, даже в IBM есть люди, по-прежнему упоминающие 65-разрядные, которые так никогда и не были созданы. Эта путаница возникает потому, что многие не знают, что собственно делает бит тега. Вероятно, если бы мы назвали его «битом защиты указателя в памяти» (pointer in memory protection), то не ввели бы в заблуждение столько народу. Но боюсь, тогда бы нам пришлось все время объяснять, зачем нам понадобился «бит pimp»[ 18 ].
Архитектура PowerPC определяет привилегированные операции и команды, используемые только операционной системой и не предназначенные для прикладных программ. В AS/400 после специальных расширений этим «ведает» режим активных тегов. Например, механизм трансляции адреса должен поддерживать и одноуровневую память с единым адресным пространством, и обычную память с отдельным адресным пространством для каждого процесса. Мы используем режим активных тегов для того, чтобы приказать процессору использовать одноуровневую память. В режиме неактивных тегов процессор использует обычную трансляцию адреса PowerPC. В состав других расширений AS/400 входят команды для работы с десятичными числами, некоторые новые команды загрузки и сохранения, а также расширения внутреннего регистра состояния процессора, предназначенные для оптимизации выполнения переходов. Мы не будем терять сейчас время на объяснение того, как эти команды используются в AS/400, а отложим это до следующих глав, где рассмотрим, как используется каждая из расширенных команд, более подробно. А сейчас хочу привести некоторые цифры. Они помогут подытожить разговор об изменениях в архитектуре AS/400 и связанных с ними перспективах развития архитектуры PowerPC. 32-разрядная архитектура PowerPC определяет 187 команд, причем 11 из них — необязательные. 64-разрядная архитектура PowerPC определяет 228 команд (187 из 32-разрядного набора + 41 дополнительная), из них 21 — необязательная. Архитектура Amazon определяет 253 команды (228 из 64-разрядного набора PowerPC + 25 дополнительных), из них 20 — необязательные. Заметьте, что 25 дополнительных команд доступны только в режиме активных тегов. Режим неактивных тегов поддерживает лишь 64-разрядный набор команд PowerPC. Но учтите, что определение любой архитектуры динамично и конкретные числа могут изменяться! Реализации процессора AS/400 Первые использовавшиеся в AS/400 RISC-процессоры поддерживали только режим активных тегов и только структуру ввода-вывода AS/400. Поэтому они выполняли приложения, но не операционные системы, написанные для стандартного процессора PowerPC. Любая другая операционная система на одном из этих процессоров для таких функций как ввод-вывод должна пользоваться средствами, предоставляемыми операционной системой AS/400. (Подробнее об этом — в следующих главах). Последнее поколение RISC-процессоров для AS/400е поддерживает и режим активных тегов, и режим неактивных тегов, а, кроме того, обе структуры ввода-вывода одновременно. Они способны исполнять любую ОС для PowerPC и используются как в серии AS/400е, так и в RS/6000. Процессоры будущего сохранят эти характеристики.
Процессор первого поколения, известный под названием Muskie[ 19 ], был разработан в Рочестере в 1995 году как старшая модель процессора для AS/400. На тот момент он был самым быстрым процессором PowerPC и самым быстрым микропроцессором IBM. Первоначально он имел время цикла 6,5 наносекунд, что соответствует тактовой частоте 154 МГц. В 1996 году мы представили еще более быстрые его версии со временем цикла 5,5 наносекунд (182 МГц). Muskie явно предназначен для использования в системах коммерческих расчетов, а не в технических рабочих станциях. И хотя это не самая последняя наша разработка PowerPC, его стоит рассмотреть подробнее, чтобы понять различия между процес сорами, предназначенными для коммерческих и научно-технических расчетов. Тогда станет ясно, почему было решено сконцентрировать усилия Рочестера на разработке процессоров для коммерческих вычислений (и для AS/400, и для RS/6000), тогда как Остин занимается процессорами для научно-технических расчетов. Процессор Muskie — одномодульный, многокристальный, конвейерный, суперскалярный и предназначен для старших RISC-моделей AS/400. Это единственный многокристальный процессор семейства PowerPC. Процессор построен по четырех-канальной (4-way) суперскалярной схеме, то есть может выбирать и исполнять до четырех команд за цикл. Кроме того, поддерживаются и многопроцессорные конфигурации.
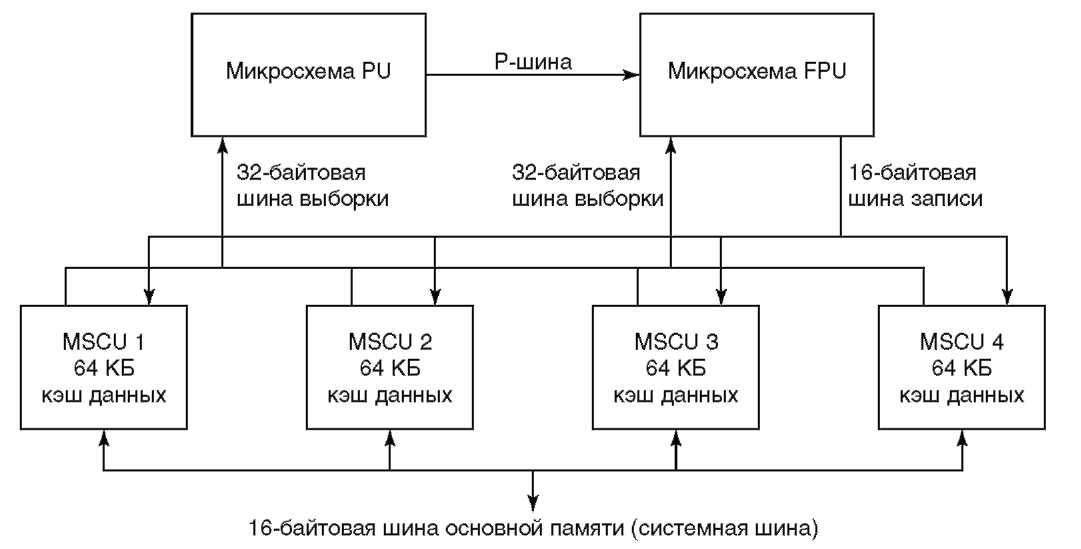
Рисунок 2.4 Структурная схема процессора Muskie Однокристальные процессоры обычно изготавливаются по технологии КМОП (комплиментарный метал-окисел-полупроводник). Микросхемы КМОП потребляют меньше мощности, чем микросхемы других технологий, то есть рассеивают меньше тепла. В результате, на одном кристалле может быть размещено больше транзисторов. Пока все схемы размещены на одном кристалле, маломощные цепи КМОП работают очень быстро. Иначе обстоит дело со связями между кристаллами. При использовании усилителей КМОП в многокристальном процессоре производительность уменьшается. Все шесть кристаллов Muskie используют технологию БиКМОП (Биполярный-КМОП). Биполярная технология имеет высокое быстродействие (в этом ее преимущество) и потребляет большую мощность. Недостаток БиКМОП — большое выделение тепла. Из-за объема рассеиваемого тепла биполярные кристаллы не могут использовать столь же высокую плотность упаковки, как кристаллы КМОП. Технология БиКМОП позволяет размещать на одном кристалле как биполярные цепи (для внешних усилителей), так и цепи КМОП (для схем внутри кристалла). Вместе со всеми вспомогательными схемами процессор Muskie занимает семь кристаллов. Последние упакованы в один многокристальный модуль, насчитывающий более 25 миллионов транзисторов. Один из кристаллов управляет вводом-выводом, то есть технически не является частью процессора. Прочие шесть кристаллов, составляющих процессор, вместе с соединениями между ними показаны на рисунке 2.4. БиКМОП отлично подходит для многокристального процессора. Например, известный Intel Pentium Pro выполнен в виде двухкристального модуля и использует технологию БиКМОП по тем же причинам, что и Muskie. Чтобы понять, почему для реализации данной технологии требуется так много транзисторов, рассмотрим микросхемы процессора подробнее. В состав шести основных кристаллов, составляющих процессор, входят кристалл процессорного блока PU (Processing Unit), кристалл блока плавающей точки FPU (Floating-Point Unit) и четыре одинаковых кристалла блоков управления основной памятью MSCU (Main Store Control Unit). На кристалле PU расположены кэш команд, блок переходов и блок фиксированной точки. Кэш команд размером 8 килобайт имеет ширину 32 байта. Он может выбирать из памяти за один такт 32 байта (8 команд[ 20 ]). Для передачи больших объемов данных за один такт имеются 32-байтовые тракты данных. Даже регистровый стек блока фиксированной точки рассчитан на загрузку или сохранение четырех 64-разрядных регистров за один такт. FPU размещается на отдельном кристалле и поддерживает стандарт IEEE для операций с плавающей точкой. Он спроектирован так, что способен выдавать результат в каждом такте, обеспечивая очень высокую производительность команд с плавающей точкой. Четыре команды за такт передаются от кристалла PU на кристалл FPU по 16-байтовой P-шине. Все данные, хранимые в памяти, также пересылаются из PU по P-шине в кэш данных. Данные для FPU выбираются из кэша данных со скоростью 32 байта за такт. Данные из FPU и PU пересылаются в кэш данных по 16-байтовой шине сохранения. MSCU содержит кэш данных, а также интерфейс памяти. Все четыре кристалла совместно реализуют 256-килобайтовый кэш данных и интерфейсы к шинам данных (см. рисунок 2.4). Обращения к кэшу данных выполняются конвейерно, так что за каждый такт считываются 32 и сохраняются 16 байт данных. MSCU поддерживает многопроцессорные конфигурации, обеспечивая когерентность кэшей разных процессоров. PU и FPU вместе насчитывают 5 конвейеров, однако в каждом цикле может быть распределено только 4 команды, а именно: команда перехода (включая операцию над содержимым регистра условия); команда загрузки/сохранения; команда арифметики с фиксированной точкой; команда фиксированной точки (логическая, сдвиг или циклический сдвиг; или команда плавающей точки). Команды плавающей точки исполняются в FPU, но не могут быть выбраны на выполнение одновременно с командами фиксированной точки для логических операций, сдвига или циклического сдвига, выполняемыми в PU. Обратите внимание, что конвейер загрузки/сохранения выполняет выборку и запись данных как с фиксированной, так и с плавающей точкой. Несколько конвейеров выполняют фрагменты нескольких команд одновременно. Процессор Muskie также может работать с разделяемой памятью, и таким образом поддерживает симметричное мультипроцессирование. Muskie первого поколения поддерживал конфигурации до 4 процессоров. Будучи самым быстрым RISC-процессором IBM своего времени, Muskie оптимизирован для нужд коммерческих вычислений. Для иллюстрации приведем некоторые характеристики. Системы и серверы для коммерческих расчетов должны обрабатывать огромные объемы данных. 16-байтовые (128 бит) и 32-байтовые (256 бит) шины позволяют Muskie справляться с этими задачами. Для сравнения: типичные 8-байтовые (64-разрядные) шины, используемые большинством высокопроизводительных RISC-процессоров, предназначены для рабочих станций, где объем обрабатываемых данных гораздо меньше. Кэш — обычно слабое место большинства RISC-процессоров, даже если система способна перемещать большие объемы данных. Для устранения этого недостатка в Muskie предусмотрен 256-килобайтовый кэш данных, работающий за один цикл. Поскольку команда перехода может вызвать простой конвейера, современные RISC-процессоры, подобно суперЭВМ, реализуют некоторую разновидность предсказания переходов. Для большинства RISC-процессоров точность предсказания переходов при выполнении технических задач составляет 80-90 процентов, благодаря тому, что в технических задачах процессор многократно повторяет последовательность команд тела цикла. Для программ подобного типа предсказание переходов работает отлично. В программах для коммерческих задач циклов гораздо меньше и точность предсказания переходов может быть ниже 50 процентов (это соответствует точности случайного выбора). Поэтому, вместо того чтобы пытаться угадать место перехода, Muskie выбирает команды из обоих мест перехода и начинает выполнять их. Данный метод, называемый спекулятивным выполнением (speculative execution), требует очень скоростного кэша (чем Muskie обладает), но зато позволяет достичь по сути стопроцентной точности на задачах любого типа. Еще один важный аспект коммерческих вычислений — высокие требования к целостности данных и коэффициенту готовности. Muskie реализует коды коррекции ошибок для всех связей за переделами кристаллов. Кроме того, большая часть логики управления и передачи данных на каждом кристалле также содержит различные схемы контроля. Типичный же RISC-процессор для рабочей станции вряд ли способен на что-либо подобное в области определения и исправления ошибок.
Как и Muskie, процессоры Cobra имеют расширенную 64-разрядную архитектуру PowerPC. Они суперскалярные, что позволяет использовать параллелизм на уровне команд. Функционально оба семейства процессоров исполняют один и тот же набор команд уровня приложений. Некоторые различия между ними заключаются в реализации необязательных команд. Так Cobra предназначается для средних и младших моделей AS/400, поэтому реализация команд, поддерживающих, например, мульти-процессирование, в нем не предусмотрена. Все четыре модели процессоров Cobra разработаны в Эндикотте. В системах AS/ 400, объявленных в 1995 году, используются Cobra-4 и Cobra-CR (CR расшифровывается как «cost reduced» — «цена уменьшена»). Cobra-CR — это Cobra-4, но с возможностью работать только на частоте 50 МГц, самой низкой для этого процессора[ 21 ]. Специально для тестирования нового программного обеспечения операционной системы команда проектировщиков в Эндикотте разработала вариант Cobra-0. Он никогда не применялся в AS/400. Существовала также версия Cobra-Lite, названная так, поскольку в ней отсутствуют 17 обязательных команд PowerPC[ 22 ]. Ее разработала небольшая группа из Рочестера для системы Advanced 36, анонсированной в 1994 году. При разработке процессоров Cobra ставилась задача объединить процессор и интерфейс памяти на одном кристалле, который, в результате, содержит 4,7 миллиона транзисторов. Интерфейс шины ввода-вывода располагается на отдельном кристалле, что позволяет использовать процессор с разными интерфейсами ввода-вывода. Cobra использует КМОП, а не БиКМОП, а точнее — технологию, названную IBM CMOS-5L. В результате, процессор рассеивает меньше тепла, чем Muskie, и меньше его нуждается в охлаждении. Только процессоры Cobra помещаются в корпуса небольшого размера, изготовленные для Advanced Series в 1994 году. Подобно Muskie, Cobra имеет 5 конвейеров, но за один цикл может распределять не более трех команд (то есть выполнен по трехканальной суперскалярной схеме). Это команды: перехода (включая команду регистра условия); загрузки/сохранения; арифметики с фиксированной точкой (включая логические команды, команды сдвига и циклического сдвига), или команда плавающей точки, или команда регистра условия. Три конвейера (фиксированной точки, плавающей точки и команд регистра условия) совместно используют третий слот диспетчирования команд. Первые процессоры Cobra работали на тактовых частотах 50 и 77 МГц, но их конструкция, как уже упоминалось, допускает и более высокие частоты. Для поддержания подобной скорости Cobra имеет 4-килобайтный внутренний (на кристалле) кэш команд и 8-килобайтный (также внутренний) кэш данных. По сравнению с Muskie, это не очень много. Большой кэш трудно разместить в однокристальном процессоре, поэтому процессоры, подобные Cobra, используют иерархию кэшей. Маленькие внутренние кэши (называемые кэшами первого уровня или кэшами L1) дополняются большим по размеру внешним кэшем (кэш второго уровня или L2). Cobra может работать с внешним (на отдельной микросхеме) кэшем L2 размером 1 мегабайт. Процессоры третьего поколения Apache Модели AS/400 1997 года используют новый дизайн процессора. Этот однокристальный процессор PowerPC, разработанный в Рочестере и названный Apache. Он предназначен для средних и старших моделей AS/400е. Младшие модели серии по-прежнему используют процессор Cobra. Apache можно считать процессором третьего поколения. В его основе — процессор Cobra, улучшенный и оснащенный новыми возможностями, например поддержки многопроцессорных систем. Apache — первый однокристальный процессор AS/ 400, которому по силам поддержка конфигурации SMP до 12 процессоров (даже Muskie поддерживал лишь четырехпроцессорные конфигурации). В отличие от Cobra или Muskie, Apache полностью реализует архитектуру PowerPC. Он использует режим активных тегов для поддержки одноуровневой памяти AS/400 и режим неактивных тегов — для поддержки стандартной модели адресации PowerPC; а также стандартные шины адреса и данных PowerPC 6хх — для соединений за пределами кристалла. Так что Apache можно использовать с любой вспомогательной микросхемой, разработанной для семейства процессоров PowerPC 6хх. (О том, как это позволило преобразовать структуру ввода-вывода компьютеров серии AS/400е мы поговорим подробней в главе 10). Apache — первый из когда-либо разработанных в Рочестере процессоров, который может использоваться вне рочес-терских систем. Процессоры Apache используются как в RS/6000, так и AS/400е.
Рисунок 2.5 Структурная схема процессора Apache Как и Cobra, Apache — однокристальный, 64-разрядный суперскалярный RISC-процессор (его структурная схема — на рисунке 2.5). Он реализован по новейшей технологии IBM CMOS-5S, что позволяет достичь большей плотности упаковки на кристалле, а также времени цикла в 8,0 наносекунд (125 МГц), хотя в некоторых моделях AS/400е используются более медленные версии. Технология КМОП значительно сокращает объем рассеиваемого тепла, который нужно отводить от процессора. В результате, на одной плате может быть установлено до четырех процессоров Apache. В новом процессоре наиболее значительны изменения в подсистеме памяти. О том, как системы с Apache используют совершенно новую подсистему памяти, предназначенную для пересылки больших объемов данных без замедления работы, читайте в следующем разделе. Несмотря на то, что время цикла у Apache не столь мало как в Muskie, новая подсистема памяти повышает масштабируемость Apache для конфигураций SMP, что позволяет создать еще более производительные модели AS/400е. Прежде чем продолжить сугубо технический разговор, хочу представить вам новые корпуса, появившиеся вместе с процессорами Apache. Три оригинальных черных корпуса AS/400 Advanced Series (известные как Apex, Cedar Key и Key Largo) были заменены на два новых, также черных, корпуса (Millennium и Mako). Корпус для Advanced Entry (Eiger) остался тем же. Мы изменили дизайн корпуса по нескольким причинам. Средние модели серии AS/400 поддерживают конфигурации SMP. Корпус Millennium допускает установку до четырех процессоров Apache, а корпус Mako для старших моделей — до 12 процессоров. (В прежний корпус для старших моделей (Key Largo) помещалось до четырех процессоров Muskie). Корпус Mako гораздо выше (около полутора метров, напоминает оригинальные белые стойки AS/400) и кроме дюжины процессоров в нем есть место для большего объема основной памяти и большего числа дисков. Новые корпуса, которые предполагается использовать в серии AS/400е до 2000 года, были разработаны совместно с подразделением RS/6000 для оптимизации общности компонентов этих систем.
Итак, мы рассмотрели процессор Muskie и то, каким образом он производит коммерческие вычисления, обрабатывая большие объемы данных. Четырехканальная суперскалярная архитектура, а также шины шириной 16 байт (128 бит) и 32 байта (256 бит) ясно свидетельствуют, что Muskie создан для обработки больших объемов данных и команд. А теперь представьте себе, процессор Muskie, упакованный вместе с набором 64-килобайтных кэшей для команд и данных в одну микросхему КМОП. Добавьте к этому полную архитектуру PowerPC процессора Apache и возможность поддерживать конфигурации с 12 или даже 16 процессорами. Что получилось? Конечно, это наш процессор четвертого поколения Northstar. Сегодня можно уверенно сказать, что через несколько лет на первый план выйдут однокристальные КМОП-процессоры, помещенные в новые черные корпуса. Мы также знаем, что они будут использовать преимущества новой подсистемы памяти, впервые появившейся в Apache. А впрочем, давайте отложим обсуждение процессоров будущего до главы 12. Там мы рассмотрим некоторые новейшие технологии, включая те, которые сегодня разрабатывает IBM для процессоров AS/400.
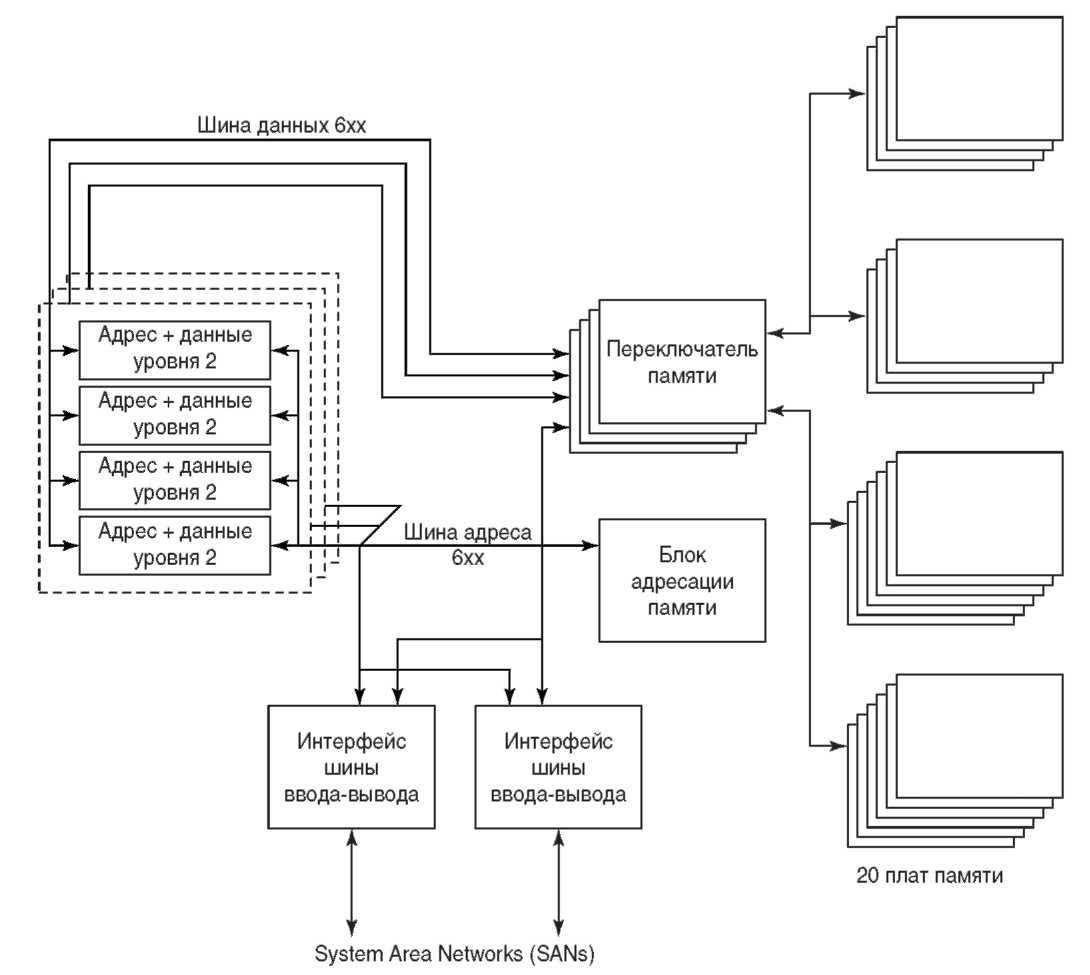
Одна из самых больших проблем любого процессора — обеспечение его загрузки. За последние несколько лет производительность процессоров необычайно выросла, в среднем удваиваясь каждые два года. Производительность памяти и ввода-вывода не успевает за этими темпами. В 1991 году я купил новую IBM PC для домашних нужд. В ней был установлен процессор Intel 386 20 МГц, 70-наносекундная память и жесткий диск с временем доступа 16 миллисекунд. Маломощный процессор 386 не долго меня устраивал; поэтому я, как и многие другие, начал бесконечную гонку за новейшей аппаратурой, приобретая последовательно системы с процессорами 486 и Pentium. В последнем купленном мною компьютере (который уже тоже устарел) установлены процессоры Pentium Pro 200 МГц, 60-наносекундная память и жесткие диски со временем доступа 8,5 миллисекунд. Да, за последние несколько лет разрыв в скорости между процессором и памятью-вводом/выводом вырос невероятно. Теперь вполне возможна ситуация, когда память и ввод-вывод не смогут поставлять достаточно информации для поддержания загрузки процессора, и последний будет проводить множество своих высокоскоростных циклов в ожидании выборки команд или данных. Универсальный прием для компенсации разницы в производительности между процессором и основной памятью — применение кэшей. Как мы уже говорили, кэш — это быстродействующая память, используемая для хранения блоков команд и данных, к которым процессор недавно обращался. При этом предполагается, что в ближайшем будущем процессор будет обращаться к тем же самым блокам. Кэши эффективны благодаря тому, что большинство программ обладают так называемыми пространственной и временной локализацией. Это означает, что программа, скорее всего, обратится к команде или элементу данных, расположенным в памяти недалеко от места последнего обращения (пространственная локализация); а также что такой доступ произойдет через короткий отрезок времени (временная локализация). Нетрудно предположить, некоторые программы обладают большей степенью локализации, чем другие. Программа, предполагающая выполнение многих циклов или большой объем повторной обработки одних и тех же данных, имеет очень высокую степень локализации. Приложения для коммерческих расчетов, наоборот, выполняют мало обработки такого сорта, и имеют несколько меньшую степень локализации. Большие кэши и иерархия кэшей могут обеспечить загрузку процессора данными и командами даже при низких уровнях локализации. При использовании иерархии кэшей происходит следующее: если нужная процессору информация отсутствует в кэше L1, процессор обращается к кэшу L2. Если информация не найдена и там, то происходит обращение к основной памяти. Пока идет поиск информации и выборка ее в регистр, процессор простаивает. Обычно это называют циклами простоя (stall cycles) процессора. В том случае, если информации нет даже в основной памяти и система должна обратиться к диску, процессор не ждет, а переключается на выполнение другой задачи в системе. Такую ситуацию обычно называют страничной ошибкой (page fault). Подробней мы поговорим об этом в главе 8. Высокая производительность Muskie достигается с помощью небольшого 8-кило-байтного кэша команд L1 и 256-килобайтного кэша данных L1. Большой кэш данных реализован на четырех отдельных 64-килобайтных микросхемах памяти высокого быстродействия. Будучи однокристальными процессорами, Cobra и Apache имеют гораздо меньшие внутренние кэши L1 (4К и 8К для команд и данных соответственно). Эти внутренние кэши дополняются кэшами L2 большего размера, выполненными в виде отдельных микросхем. Часть производительности Apache достигается за счет очень больших кэшей L2 объемом от 4 до 8 мегабайт. Несмотря на использование больших кэшей и иерархии кэшей, большинство процессоров все равно тратят много циклов простоя, ожидая выборки из памяти. Проблема заключается в шине между процессором и основной памятью. Большая часть систем, включая ранние AS/400, имеют одну такую шину, обычно высокоскоростную, но все равно работающую медленнее самого процессора. Например, мой Intel Pentium Pro 200 МГц работает с шиной памяти 66 МГц. Это означает, что при обращении к памяти процессор простаивает по три цикла на каждый цикл шины. Легко понять, что таких циклов простоя может быть много. В конфигурации SMP ситуация может значительно ухудшиться. Теперь одну шину памяти и одну основную память пытаются задействовать несколько процессоров. Так как в данный момент времени шина может использоваться только одним процессором, то все остальные процессоры, которым она понадобилась в этот момент, обречены ждать. А если та же шина памяти используется еще и для ввода-вывода, положение еще более усугубляется. Эта борьба за шину памяти приводит к уменьшению производительности при добавлении к системе SMP каждого нового процессора. Например, добавление второго процессора не позволит увеличить общую производительность на 100 процентов; фактическое увеличение будет несколько меньшим из-за борьбы за память. Добавление третьего и четвертого процессора еще сильнее сократит прирост производительности на один процессор. А когда дело дойдет до восьми и более процессоров, рост производительности системы SMP может и вовсе прекратиться.
Давайте проведем краткий обзор организаций памяти для многопроцессорных систем. Нас интересуют три схемы организации памяти: централизованная разделяемая память, распределенная память и распределенная разделяемая память. Машина с централизованной разделяемой памятью предоставляет центральную память для использования всеми процессорами. Обычно, к такой разделяемой памяти подключены посредством одной шины несколько десятков процессоров. Подобная организация называется SMP (ее мы рассматривали выше). Преимущества SMP в том, что все процессоры используют общую память, и время необходимое для доступа к любой части этой памяти, для них одинаково. Поэтому конфигурации SMP часто называют машинами с однородным доступом к памяти UMA (uniform memory access). Недостаток SMP — в ограниченности максимально поддерживаемого числа процессоров. В машинах с распределенной памятью последняя поделена между несколькими узлами, каждый из которых содержит несколько процессоров, соединенных с памятью узла как в SMP. Пример — кластер AS/400 OptiConnect (подробнее см. главу 6). Иногда машины с распределенной памятью называют архитектурами без разделения (shared-nothing), так как память не разделяется между узлами, а для связи между ними используется передача сообщений. Преимущество разделяемой памяти в том, что она может быть очень большой, если такое разделение памяти не требуется приложениям. Если каждый процессор в машине с распределенной памятью может выполнять одну и ту же операцию или одну и ту же программу над множеством независимых друг от друга наборов данных, то подобная конфигурация называется процессором с массовым параллелизмом MPP (massively parallel processor). Пример — система MPP в IBM SP2, использующая по одному процессору на узел[ 23 ]. У SP2 также очень хороший механизм передачи сообщений, позволяющий процессорам быстро обмениваться информацией друг с другом. Системы MPP могут насчитывать тысячи процессоров; их недостаток в том, что такая архитектура полезна только для некоторых типов приложений, таких как параллельная обработка баз данных или научных вычислений (то есть там, где совместное использование данных не требуется). Третья конфигурация — с распределенной разделяемой памятью, представляет собой вариант распределенной памяти. Здесь все узлы, состоящие из одного или нескольких процессоров, подключенных по схеме SMP, используют общее адресное пространство. Отличие этой конфигурации от машины с распределенной памятью в том, что здесь любой процессор может обратиться к любому участку памяти. Однако, время обращения к разным участкам памяти для каждого процессора различно в зависимости от того, где участок физически расположен в кластере. По этой причине такие конфигурации еще называют машинами с неоднородным доступом к памяти NUMA (non-uniform memory access). Мы рассмотрим NUMA в главе 12. Это отступление от основной линии повествования здесь для того, чтобы помочь Вам, читатель, понять новую подсистему памяти, используемую сейчас в серии AS/ 400е. Эта подсистема разработана для конфигурации SMP, так как последняя наилучшим образом подходит для решения коммерческих задач, когда процессорам требуется использовать память совместно. Но Вы увидите, что она может использоваться и с другими конфигурациями памяти.
В рамках начавшейся в 1995 году десятилетней программы ASCI (Accelerated Strategic Computing Initiative) министерство энергетики США DOE (Department of Energy) запросило у производителей компьютеров предложения по созданию самых мощных на сегодня ЭВМ. Задача ACSI — разработка «триллионных» компьютеров, которые могут быть использованы в том числе для моделирования ядерных испытаний. Предполагается, что триллионные (tera-scale) вычисления (таково официальное название для триллиона операций в секунду) будут широко применяться в коммерческих и научных приложениях в следующем столетии. Такие компьютеры создаются в трех национальных лабораториях DOE, связанных с проектом ASCI. На первом этапе проекта ASCI — ASCI Option Red — рассматривалась большая конфигурация MPP с процессорами, организованными по традиционной модели распределенной памяти. Intel получил контракт на разработку компьютера с 9 072 процессорами Pentium Pro, 283 гигабайтами памяти и двумя терабайтами дискового пространства. Эта система имеет архитектуру MPP без разделения. Испытания новой системы происходили в национальной лаборатории Сандиа (Sandia), штат Нью-Мехи-ко. Ставилась задача — Сандиа (Sandia), «выжать» из единственного в своем роде компьютера, стоимостью в 55 миллионов долларов, триллион операций с плавающей точкой в секунду (один терафлоп). В декабре 1996 компьютер Intel DOE достиг этой цели. DOE также хотело устранить ограничения двух распространенных многопроцессорных архитектур (SMP и MPP). Как мы уже говорили, системы SMP использующие шины, не масштабируются больше 32 процессоров, но отлично работают для большинства приложений. Схемы MPP сложнее в программировании и подходят только для некоторых классов приложений. Кроме того, их работа сильно замедляется при необходимости доступа к данным, разбросанным по системе. Поэтому DOE предложила новый проект масштабируемого SMP, названного ASCI Option Blue. Контракты на создание этих систем к концу 1998 года получили две компании, чьи предложения были самыми обещающими: IBM и Cray Research, которая была приобретена SGI (Silicon Graphics Incorporated). Машина IBM названная ASCI Blue Pacific будет установлена в национальной лаборатории имени. Лоуренса (Lawrence) в Ливер-море (Livermore), штат Калифорния, а машина SGI/Cray, получившая имя ASCI Blue Mountain — в национальной лаборатории в Лос-Аламосе (Los Alamos), штат Нью-Ме-хико. Задача обоих компьютеров Option Blue — достичь производительности более 3 терафлоп. В проекте IBM используются компактные узлы SMP с восемью процессорами; эти узлы соединяются с помощью переключателей передачи сообщений SP2. Проект SGI/ Cray более сложен и включает в себя комбинацию соединений и технологий операционных систем с целью создания образа единой SMP-подобной машины. И хотя физически данные будут распределены по системе, это будет архитектура NUMA. Компьютер IBM ASCI Blue Pacific будет содержать 512 8-процессорных узлов SMP, 4 096 сверхвысокопроизводительных процессоров PowerPC. Процессор, предназначенный для версии Belatrix Остина, назван 630. Он имеет высокую производительность для вычислений с плавающей точкой и в точности соответствует типу проблем, решать которые призван компьютер DOE. Для связи между узлами в ASCI Blue Pacific планируется новый высокоскоростной переключатель передачи сообщений типа SP2. Подсистема памяти, позволяющая процессорам внутри узла эффективно использовать память, будет использовать новый 128-разрядный перекрестный переключатель (cross-bar switch)[ 24 ]. Подсистема памяти на основе таких переключателей позволяет нескольким процессорам обращаться к памяти узла параллельно и обеспечивает конфигурацию UMA, где устранена проблема, присущая шине памяти в большинстве конфигураций SMP. Я упомянул о проекте DOE для того чтобы рассказать о новой подсистеме памяти, используемой в узлах SMP ASCI Blue Pacific. Первая подсистема UMA, использующая 128-разрядный перекрестный переключатель, была разработана в Рочестере. Аналогичная схема используется в настоящее время в компьютерах SMP Apache. Вместо одной шины между памятью и кэшем второго уровня, как в предыдущих системах SMP AS/400, в Apache применены перекрестные переключатели. Благодаря поддержке нескольких параллельных обращений к памяти за один цикл, возможна пересылка больших объемов данных между кэшем и разделяемой памятью, что позволяет поддерживать загрузку процессоров в больших конфигурациях SMP. Пример подобной конфигурации с двенадцатью процессорами Вы можете увидеть на рисунке 2.6. На одной плате — четыре процессора Apache вместе с четырьмя кэшами L2. В 12-процессорной конфигурации установлено три таких платы. Размещенные на платах кэши L2 размером 4 или 8 мегабайт обладают цикличностью в 8 наносекунд. Таким образом, за один цикл процессора между кэшем второго уровня и кэшем данных или команд первого уровня в микросхеме Apache может быть передано 16 байтов (см. рисунок 2.5). Основная память в данной конфигурации может достигать 20 гигабайт, каждая плата памяти — содержать до гигабайта, так что на рисунке 2.6 показаны 20 таких плат. Обратите внимание на наличие четырех банков памяти с одинаковым числом плат в каждом, что позволяет обеспечить прослоенную память (memory interleaving) — технический прием, при котором открывается доступ к последовательным блокам данных памяти через разные банки. Например, если каждая плата памяти имеет 8-байтовый интерфейс, то одновременно из четырех банков памяти может быть считано 32 последовательных байта (байты 0-7 из банка 1, байты 8-15 из банка 2 и т. д.). Четыре перекрестных переключателя подсистемы памяти UMA обеспечивают соединение между кэшами второго уровня и платами основной памяти. Три шины данных 6хх — по одной на каждую плату процессора — соединяют 12 процессоров с каждым из четырех переключателей. Эти 128-разрядные шины данных имеют время цикла 12 наносекунд (в полтора раза больше времени цикла процессора). Дополнительная шина данных 6хх соединяет с каждым из переключателей памяти подсистему ввода-вывода. У каждого переключателя — два независимых 128-разрядных интерфейса к платам памяти. В подобной конфигурации в каждом цикле памяти к ней может осуществляться несколько параллельных обращений, что фактически устраняет проблемы, связанные с использованием одной шины памяти на традиционных системах SMP. Имейте в виду, что здесь представлена лишь одна из возможных конфигураций соединения процессорных плат, переключателей и плат памяти. Другие модели линии AS/400 будут использовать иные комбинации этих компонентов. Например, в 4-процессорной конфигурации SMP может использоваться одна процессорная плата, два переключателя и четыре банка памяти. Также, обратите внимание, что переключатели используются только линиями данных. Линии адресах всех кэшей второго уровня (показанные на рисунке как адресные линии 6хх) общие, что позволяет обычное отслеживание адресов, иначе называемое снупингом кэша (cache snooping) — прием, при котором каждый контроллер кэша L2 постоянно отслеживает все адреса, передаваемые по общей адресной шине. Кроме того, контроллеры проверяют, содержится ли адрес на шине в их кэше. Если это так, то соответствующие данные кэша становятся недействительными. Таким образом достигается когерентность информации во всех кэшах, ведь общие данные могут быть изменены одновременно не более чем одним процессором. На рисунке 2.6 также показана общая подсистема ввода-вывода. Для подключения устройства расширения ввода-вывода к корпусу Mako, в котором размещается 12-процессорная конфигурация, используется SAN (System Area Network). Два таких интерфейса показаны на рисунке. В главе 10 мы рассмотрим использование SAN для поддержки разных интерфейсов ввода-вывода в AS/400е и соединения этих систем друг с другом.
Рисунок 2.6 12-конфигурация SMP Итак, причина использования перекрестных переключателей — стремление повысить эффективность, или, иначе говоря, процентный рост производительности SMP при добавлении нового процессора в конфигурацию. Во многих системах с разделяемой памятью эта эффективность равна примерно 70 процентам при использовании от четырех до восьми процессоров.[ 25 ] Благодаря новой подсистеме памяти, процессоры Apache должны поднять эффективность до 85—90 процентов. Будущее переключателей памяти Если используются иерархии кэшей, то почему бы не использовать иерархии переключателей? Фактически, именно это и произойдет в будущем. Мы рассмотрели пример, где каждый процессор был соединен посредством шины 6хх с каждым из четырех переключателей. А ведь вместо этого можно установить на каждый четырех процессорный узел один переключатель, который, логично назвать контроллером узла. Такие контроллеры могут быть подключены к набору переключателей, которые, в свою очередь, подключаются к банку плат памяти. Можно также подключить контроллеры узлов к нескольким наборам переключателей, а каждый из этих наборов — к отдельным банкам памяти. Таким образом будет получена очень большая конфигурация SMP. Вспомните этот разговор после выхода четвертого поколения процессоров Рочестера! Вы еще не забыли про компьютер IBM ASCI Blue Pacific? В нем будет 512 процессорных узлов по восемь процессоров в каждом и подсистема памяти UMA на переключателях. Не следует ожидать в скором времени появления столь мощной версии AS/400, но разве не приятно осознавать, что такая конфигурация возможна, даже если и не очень практична? В конце концов, кодовым названием System/38 было Pacific[ 26 ], и мы действительно собирались создать по-настоящему большую систему. Ну что ж, посмотрим, как будут выглядеть рочестерские процессоры PowerPC следующего поколения... Выводы Сегодня 64-разрядный процессор стал стандартом в компьютерной промышленности. Все RISC-процессоры AS/400 — современные, 64-разрядные, способные обеспечить функциональные возможности и производительность, необходимую для коммерческих систем и серверов. Мы считаем, что семейство RISC-процессоров PowerPC приведет AS/400 в следующее столетие. Примечания:1 Прекрасный вопрос для викторины: кто родился 8 января? Ответ: «Элвис и AS/400». Элвис Пресли родился в Тупело (Tupelo), штат Миссисипи, 8 января 1935 года, а AS/400 — в Рочестере, штат Миннесота, 8 января 1970. 2 Silverlake — название небольшого красивого озера в Миннесоте. — Прим. консультанта. 10 К несчастью, Сеймур Крей — отец суперкомпьютеров s умер в октябре 1996 года от ранений, полученных в автокатастрофе. Он начал разрабатывать компьютеры в 1950 году в миннесотской компании Engineering Research Associates, и создал там первый в мире коммерческий успешный компьютер для научных расчетов ERA 1103. В 1957 году Крей — среди основателей корпорации Control Data. Его проекты компьютеров 6600 и 7600 определили новые стандарты для всей промышленности. В 1972 году он основал первую из своих собственных фирм — Cray Research, в рамках которой создал самые быстрые в мире суперкомпьютеры общего назначения. Значение его наследия для всех нас, специалистов компьютерной индустрии, неоценимо. 11 Добиться полной загрузки конвейера на коммерческих задачах — весьма непросто из-за большого числа условных выражений и команд переходов. По этой причине RISC-системы неэффективны на коммерческих задачах. Как с этой проблемой справились разработчики AS/400 будет рассказано ниже. — Прим. консультанта. 12 Скорее всего Вы, читатель, насчитаете только 4 такта. Пятый (на самом деле — первый) — это выборка из памяти первой команды загрузки. Выборка остальных команд будет осуществляться уже параллельно с выполнением предыдущих команд и, следовательно, не приведет к увеличению времени выполнения всей последовательности. — Прим. консультанта. 13 Отдайте интересные моменты компиляторам. — Прим. переводчика. 14 Читатели, которые помнят короля Артура, знают, что Сомерсет (Somerset) — это мифическое место, куда враждующие стороны приходят для заключения мира. 15 Я дал это имя внутреннему интерфейсу System/38 в середине 70-х, предполагая, что оно будет изменено перед объявлением системы. Этого не случилось, и сразу же возникла терминологическая путаница: стали говорить об «интерфейсе IMPI». Между тем, понятие «интерфейс» в данном контексте, конечно же, избыточно. Кстати, и с MI s та же проблема. Затем однажды кто-то решил, что последнее «i» в IMPI должно расшифровываться как «instruction». Это тоже не корректно, поскольку мы говорим об инструкциях IMPI. Наконец, поступали предложения выбросить последнюю чтобы устранить дублирование. Тогда оказалось, что IMP не имеет смысла и вызывает в воображении картину маленького шаловливого демона внутри системы. Так могло продолжаться долго, но слава Богу, переход на PowerPC наконец-то решил проблему названия. 16 Это кодовое имя использовалось нами не впервые. Перед объявлением в 1975 году System/32 также называлась системой North Star. На этот раз, мы предпочли название, состоящее из одного слова. 17 Кэш — это быстродействующая память небольшого объема, выступающая в роли буфера для основной памяти. У большинства RISC-процессоров отдельные кэши команд и данных. Если процессор однокристальный кэши могут располагаться либо на кристалле, либо в отдельной микросхеме, тогда как основная память всегда реализуется в виде отдельных микросхем. 18 Буквальный перевод с английского — «сводник». — Прим. переводчика. 19 При объявлении этих процессоров им были присвоены номера, а не имена. Например, процессору Muskie был дан весьма незатейливый идентификатор А30. Но так как названия гораздо легче для восприятия, в разговоре о процессорах AS/400 мы будем пользоваться ими вместо цифр. 20 Все команды PowerPC как для 32- , так и для 64-разрядных процессоров имеют размер 32 разряда. 21 Cobra-4 может работать и на более высоких частотах. С характеристиками этого процессора мы скоро познакомимся. 22 Cobra-Lite является первым поколением процессоров RISC, которые использовались в AS/400.Последующие модели Cobra, реализующие полный набор команд PowerPC, рассматриваются как второе поколение Cobra-Lite. 23 Когда книга готовилась к печати, появилась возможность использовать до 8 процессоров SMP в каждом узле. Кстати, SP2 изменил название и теперь называется просто SP. — Прим. консультанта. 24 Перекрестные переключатели на протяжении десятков лет используются на телефонных станциях для подключения набора входящих линий к набору исходящих линий в произвольном порядке. Любая входящая линия может быть подключена к любой не занятой исходящей линии. Получается множество одновременных соединений. 25 Увы, кажется, в последнее время оно перестало сбываться. — Прим. консультанта. 26 В честь Тихого Океана — Прим. консультанта. |
|
||
|
Главная | Контакты | Нашёл ошибку | Прислать материал | Добавить в избранное |
||||
|
|
||||