|
||||
|
|
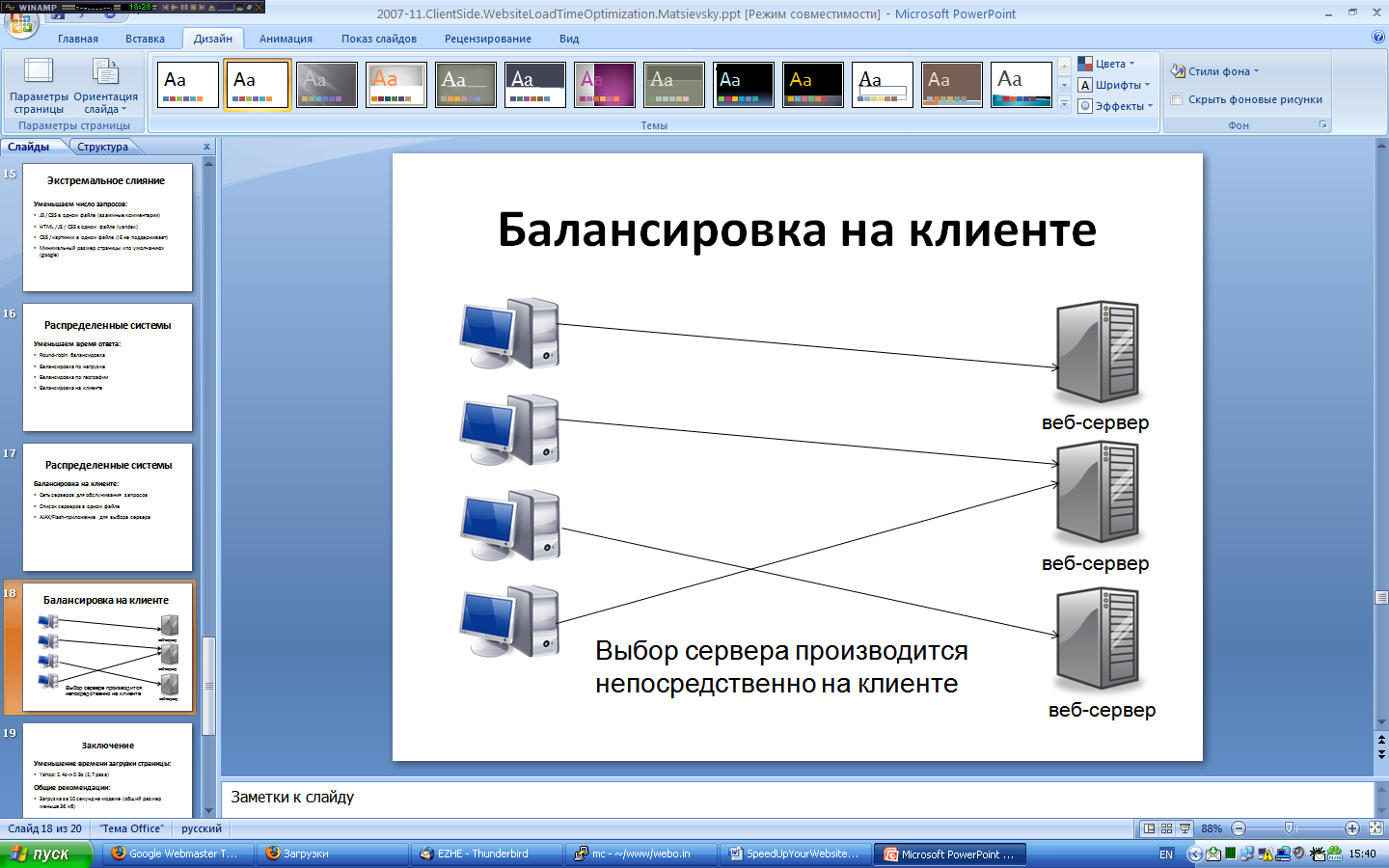
Глава 5. Параллельные соединения 5.1. Обходим ограничения браузера на число соединений Активное (англ. keep-alive) соединение стало настоящим прорывом в спецификации HTTP 1.1: оно позволяло использовать уже установленный канал для повторной передачи информации от клиента к серверу и обратно (в HTTP 1.0 соединение закрывалось сразу же после передачи информации от сервера, что добавляло задержки, связанные с трехступенчатой передачей пакетов). В том случае, если проблема свободных ресурсов стоит довольно остро, можно рассмотреть выставление небольшого таймаута для таких соединений (5-10 секунд).Однако HTTP 1.1 добавил веб-разработчикам головной боли по другому поводу. Давайте будем разбираться, как нам устранить и эту проблему.Издержки на доставку объектов Средняя веб-страница содержит более 50 объектов, и издержки на число объектов доминируют над всеми остальными задержками при загрузке большинства веб-страниц. Браузеры, следуя рекомендациям спецификации HTTP 1.1, обычно устанавливают не более 2 одновременных соединений с одним хостом. При увеличении числа HTTP-запросов, требуемых для отображения страницы, с 3 до 23 — время, затрачиваемое именно на «чистую» загрузку объектов, от общего времени загрузки падает с 50% до всего 14%.Если число объектов на странице превышает 4, то издержки на ожидание доступных потоков и разбор чанков для присланных объектов превалируют над общим временем загрузки страницы (от 80% до 86% для 20 и 23+ объектов соответственно) по сравнению со временем, которое уходит на действительную загрузку данных. Время инициализации плюс время ожидания, вызванное ограничением на параллельные соединения, занимают 50–86% от общего времени загрузки страницы. При увеличении числа подключаемых объектов сверх 10 время, затрачиваемое на инициализацию соединения, возрастает до 80% и более от общего времени, уходящего на получение объектов. Стоит отметить, что можно существенно уменьшить издержки на доставку большого числа объектов (более чем 12 на страницу) включением для сервера keep-alive режима и распределением запросов по нескольким хостам.Ограничения спецификации HTTP/1.1 Браузеры создавались в ту эпоху, когда громадное множество пользователей пользовались коммутируемым доступом с невысокой пропускной способностью канала, поэтому тогда было важно ограничить пользователей небольшим числом одновременных соединений. Накладные издержки на переключение между множеством соединений при коммутируемом доступе создавали большие сложности для обработки и загрузки каждого отдельного запроса. К тому же в ту эпоху веб- и прокси-серверы были недостаточно мощными, чтобы поддерживать множество соединений, поэтому такое жесткое ограничение числа одновременных соединений у браузера существенно снижало риск падения сетевой инфраструктуры в целом. Спецификация HTTP, приблизительно 1999 года, рекомендует, чтобы браузеры и серверы ограничивали число параллельных запросов к одному хосту двумя. Эта спецификация была написана задолго до существенного расширения каналов загрузки и была рассчитана на соединения с маленькой скоростью загрузки. Большинство браузеров поддерживают это ограничение на число потоков в спецификации, хотя переход на HTTP 1.0 увеличивает число параллельных загрузок до 4. Поэтому большинство браузеров серьезно ограничено этим параметром, если им приходится загружать большое число объектов с одного хоста (по словам Алекса Могилевского, в IE8 это число будет равно 6 из-за определенных издержек на установление нового соединения). Существует два основных пути для обхода этого ограничения (не считая, конечно, тонкой настройки используемого клиентами браузера, о которой рассказывается в восьмой главе):Отдавать ваши объекты с нескольких серверов. Создать несколько поддоменов для нескольких хостов. Чтобы найти подходящий баланс, IE до версии 7 включительно ограничивают пользователей всего восемью одновременными соединениями или двумя соединениями на хост для протокола HTTP 1.1. HTTP 1.0 немного отличается в этом плане, но это уже совсем другая история, потому что все выгоды от постоянных соединений доступны только, если мы будем использовать HTTP 1.1 (или уже так делаем). Времена меняются Естественно, в реальном мире все эти утилитарные решения имеют особенность устаревать, вместе со своим временем и средой. Сегодня у большинства пользователей широкополосный доступ в Интернет, поэтому наиболее узким местом является уже не клиентская сторона (клиентская сторона была, есть и будет наиболее узким местом в производительности наших веб-приложений — просто нужно понимать, как именно можно ее оптимизировать в каждом конкретном случае), а пропускная способность каналов в большинстве случаев. Обычно задержки при получении отдельных объектов значительно больше, чем время на установление нового соединения и отправку запроса. Увеличивая число одновременных соединений, мы можем распараллелить это место и гораздо быстрее пробиться через множество объектов, которые находятся в списке ожидаемых к загрузке, что приведет, в итоге, к увеличению ощущаемой скорости загрузки у пользователя «до скорости молнии» К несчастью, полагаться на то, что пользователи сами будут изменять настройки своего браузера (а о том, как это можно сделать, пойдет речь в восьмой главе) — это будет не лучшей стратегией по оптимизации. Так что же делать разработчику, чтобы добиться того же эффекта со своей стороны? «Режем» соединения Большинство сайтов обладают всего одним хостом, поэтому все запросы вынуждены бороться за 2 доступных соединения к этому хосту. Одним из наиболее эффективных методов для увеличения числа параллельных потоков будет распределение содержания по нескольким хостам. Это не так сложно сделать, потому что браузеры обращают внимание только на название хоста, а не на IP-адрес. Таким образом, к каждому из хостов images1.yoursite.ru и images2.yoursite.ru браузеры смогут установить по два соединения. Небольшие изображения (например, товаров в магазине или фотографий к новостям) по умолчанию загружаются с родительского хоста, поэтому они также вынуждены использовать те же два доступных соединения. Ниже представлена примерная диаграмма загрузки объектов на странице. Рис. 5.1. Загрузка изображений при двух соединениях. Источник: www.ajaxperformance.com На этом графике хорошо видно, что для musicstore.ajaxperformance.com открыто только 2 соединения (данная диаграмма является модельной и справедлива только для IE; во всех остальных браузерах по умолчанию открывается большие соединений): C0 и C2. Мы используем протокол HTTP 1.1, поэтому нам не нужно открывать отдельное соединение для каждой картинки, но мы по-прежнему теряем кучу времени на обслуживание индивидуальных запросов к объектам. Время на установление соединения (время до получения первого байта, голубая полоска на диаграмме) явно доминирует над временем загрузки данных, которое не так велико (красная полоска на диаграмме). Вы можете, естественно, настроить несколько серверов для обслуживания выдачи картинок или других объектов, чтобы увеличить число параллельных загрузок. Например:images1.yoursite.ru images2.yoursite.ru images3.yoursite.ru Однако каждый из этих поддоменов не обязан находиться на отдельном сервере.Лучше, больше, быстрее Чтобы улучшить производительность, можно создать CNAME-записи в DNS-таблице для images1.yoursite.ru, images2.yoursite.ru и images3.yoursite.ru, каждая из которых указывает обратно на основной хост. Стоит обратить внимание, что при проектировании масштабируемых приложений, которые будут распределять объекты по различным хостам, нужно использовать хэш-функцию. Она установит однозначное соответствие между названием изображения и хостом, с которого оно должно загружаться. В качестве простых примеров можно привести остаток от деления md5-суммы или длины строки адреса изображения на число хостов. Также можно рассмотреть использование контрольной суммы CRC32, которую проще посчитать на JavaScript. При первой загрузке производительность будет значительно лучше. Как можно видеть из нижеприведенного графика, сейчас используется уже 6 соединений для загрузки наших картинок (рис. 5.2). Рис. 5.2. Загрузка при шести соединениях. Источник: www.ajaxperformance.com Реальный выигрыш Время загрузки страницы при использовании уменьшилось больше чем на 40%. И эта техника будет работать во всех случаях, когда у вас большой пул запросов к объектам, которые расположены на одном сервере. Существует масса примеров применения этого метода в реальных AJAX-приложениях. Чтобы утилизировать параллельность соединений, на Google Maps ( http://maps.google.com/ ) картинки поставляются с нескольких хостов, начиная с mt0.google.com и заканчивая mt3.google.com. На Virtual Earth ( http://local.live.com/ ) также используется эта техника. Этот подход можно также применить, чтобы изолировать отдельные части вашего приложения друг от друга. Если некоторые его элементы требуют доступа к базе данных и их загрузка задерживается больше, чем для статичных объектов, стоит устранить их из числа тех двух соединений, которые будут использоваться для загрузки картинок на вашем сайте, например, разместив их на поддомене. В данном случае, наверное, наиболее практичным решением будет размещение всей статики (кроме, пожалуй, CSS- и JavaScript-файлов, которые влияют на стадию предзагрузки — чтобы максимально избежать на этой стадии задержек на дополнительные DNS-запросы) на отдельном домене, например, static.example.com, а загрузка HTML-страниц, которые требовательны к базе, будет вестись с основного хоста. При этом static.example.com может иметь даже другой IP-адрес и обслуживаться любым «легким» сервером. Этот прием может быть и не сильно ускорит загрузку нашей страницы, но определенно улучшит ощущаемую производительность, позволяя пользователю загружать все статические файлы без дополнительных задержек. Подводим итоги Сейчас средняя веб-страница состоит более чем из 50 объектов (для Рунета, по статистическим данным webo.in, ситуация весьма похожа: число объектов колеблется в пределах 40–50), поэтому минимизация издержек на доставку объектов является весьма критичной для клиентской производительности. Также можно уменьшить число объектов на странице, если использовать технику CSS Sprites (или data:URI) и объединение текстовых файлов на сервере. Так как в данный момент у пользователей достаточно быстрый канал, то можно достигнуть уменьшения времени загрузки до 40-60% (зависит от общего числа объектов). Можно использовать 2 или 3 хоста для обслуживания объектов с одного сервера, чтобы «обмануть» браузеры в их ограничениях на загрузку нескольких объектов параллельно.При этом нужно помнить, что увеличение одновременных запросов повлечет задействование дополнительных ресурсов со стороны сервера (это может быть, например, как максимальное число открытых соединений или портов, так и дополнительные объемы оперативной памяти). Поэтому данный подход стоит активно использовать только при наличии «легкого» сервера, который способен одновременно поддерживать тысячи и десятки тысяч открытых соединений без особого ущерба для производительности (например, nginx или 0W).Стоит коснуться еще одного, весьма интересного момента в оптимизации времени загрузки путем увеличения числа параллельных потоков. Заключается он в выравнивании и увеличении размера одновременно загружаемых объектов, чтобы максимально использовать имеющиеся соединения. Например, если у вас есть 40 картинок по 5 Кб, то гораздо выгоднее будет отдавать 10 картинок по 20 Кб с двух хостов, чем 20 (по 10 Кб) с 4 хостов или 40 — с 8. Общие задержки в первом случае будут минимальными в силу максимизации эффективной скорости загрузки данных клиенту.Можно пойти и дальше и загружать, например, 4 картинки по 50 Кб в 4 потока, достигая просто феноменального ускорения. Однако тут играет роль психологический фактор: пользователю будет некомфортно, если он будет видеть страницу вообще без картинок все время, пока грузится 50 Кб, и он может просто уйти с сайта.Стоит подчеркнуть, что данный подход применим и к другим ресурсным (в том числе и HTML) файлам, однако стоит помнить о весьма жестких ограничениях браузеров на загрузку CSS- и JavaScript-файлов (как их обойти для CSS-файлов, было описано в четвертой главе, о JavaScript же более детально речь пойдет в седьмой).5.2. Content Delivery Network и Domain Name System Сети доставки содержания (англ. CDN) часто используются для уменьшения нагрузки на хостинг для веб-приложений и его каналов. В этом случае увеличение производительности достигается за счет распространения всех требуемых ресурсов по сети серверов. Близость к таким веб-серверам незамедлительно оборачивается увеличением скорости загрузки компонентов. Основной упор в таких сетях делают на максимальное уменьшение времени ping до сервера, что приводит к впечатляющим результатам с точки зрения производительности. Некоторые крупные интернет-компании владеют своими сетями CDN, однако, гораздо дешевле использовать уже готовые решения, такие как Akamai Technologies, Mirror Image Internet либо CDNetwork. Для стартапов или личных веб-сайтов стоимость услуг сетей CDN может оказаться непомерно высокой, но по мере того как аудитория увеличивается и становится все более удаленной от вас, CDN просто необходимы для достижения быстрого отклика веб-страницы. Ценовая структура Akamai основана на общем весе веб-страниц в килобайтах и числе пользовательских загрузок. Оптимизация самих веб-страниц может очень сильно сказаться на общей цене. Предположим, что один из клиентов такого сервиса платит приблизительно $8000 в месяц за домашнюю страницу в 320 Кб. Если бы над сайтом была проведена работа, которая бы уменьшила общий вес страницы на 25%, то ежемесячная оплата для клиента сократилась бы на $2000. В этом примере речь идет всего лишь о домашней странице. Уже для нее затраты на разработку окупятся с лихвой! Подключаем CDN CDN — это множество веб-серверов, распределенных географически для достижения максимальной скорости отдачи содержания клиенту. Сервер, который непосредственно будет отдавать файлы пользователю, выбирается на основании некоторых показателей. Например, выбирается сервер с наименьшим числом промежуточных запросов (англ. hop) до него либо с наименьшим временем отклика. Использование CDN потребует лишь незначительных изменений (либо вообще таковых не потребует) кода, но повлечет значительное увеличение скорости загрузки самих веб-приложений, потому что на нее сильно влияет и то, насколько далеко пользователь находится от нашего сервера. Размещение файлов на нескольких серверах, разнесенных географически, сделает загрузку сайта быстрее с точки зрения пользователя. Но с чего бы начать? В качестве первого шага к построению системы с географически распределенным содержанием не стоит пытаться изменить веб-приложение для работы с распределенной архитектурой. В зависимости от приложения изменение архитектуры может повлечь за собой сложные изменения, такие как синхронизация состояния сессий или репликация транзакций баз данных между географически разнесенными серверами. 80–90% времени загрузки страницы уходит на загрузку ее компонентов: картинок, CSS, скриптов, Flash и т. д. Вместо того чтобы заниматься изменением архитектуры самого приложения, сначала стоит распределить статический контент. Это не только позволяет добиться значительного ускорения загрузки страницы, но также легко реализуется благодаря CDN. Yahoo! и Google Yahoo! обеспечивает выдачу YUI (Yahoo! User Interface) библиотек, используя распределенную систему серверов по всему миру бесплатно. Это сервис обеспечивает: gzip-сжатие (уменьшает размер файлов от 60% до 90%);; контроль за кэширующими заголовками; распределенный хостинг файлов, основанный на географическом расположении клиента. Предоставляется на основе передовых компьютерных систем. Аналогичный сервис сейчас предоставляет и Google для JavaScript-библиотек (в том числе, естественно, для всех дополнений от Google, таких как автоматическая страница «Ничего не найдено» (ошибка 404), AJAX API для поиска или Google Maps). Сети доставки содержания задумывались в качестве простого хостинга для картинок и больших (аудио-, видео-) файлов, но сейчас они обрабатывают и JavaScript с CSS. Использование кэширования и системы контроля версий в сочетании с распределением файлов по такой сети может привести к существенному приросту производительности. Количество DNS-запросов Система DNS устанавливает соответствие имен хостов их IP-адресам, точно так же как телефонный справочник позволяет узнать номер человека по его имени. Когда вы набираете «www.yahoo.com» в адресной строке браузера, преобразователь DNS, к которому обратился браузер, возвращает IP-адрес узла. DNS-запрос имеет свою цену. Обычно требуется 20–120 миллисекунд, чтобы его выполнить и получить ответ (в российских реалиях это время обычно больше). Браузер вынужден ожидать завершения DNS-запроса, т.к. до этого момента он еще не может ничего загружать. Для повышения быстродействия результаты DNS-запросов кэшируются. Это кэширование может происходить как на специальном сервере интернет-провайдера, так и на компьютере пользователя. Информация DNS сохраняется в системном кэше (в Windows за это отвечает служба «DNS Client Service»). Большинство браузеров имеет свой кэш, не зависящий от системного. Пока браузер хранит DNS-запись в своем кэше, он не обращается к операционной системе для DNS-преобразования. Internet Explorer по умолчанию кэширует результаты DNS-запросов на 30 минут, как указано в переменной реестра DnsCacheTimeout. Firefox кэширует DNS-ответы на 1 минуту, что видно из установки network.dnsCacheExpiration. Когда клиентский кэш очищается (как системный, так и у браузера), количество DNS-запросов возрастает до количества уникальных имен хостов на странице. А это включает в себя собственно адрес самой страницы, картинок, скриптов, CSS-, Flash-объектов и т. д. Уменьшение количества уникальных имен хостов уменьшает количество DNS-запросов. Однако уменьшение количества уникальных хостов потенциально уменьшает количество параллельных загрузок компонентов страницы. В свете этого обстоятельства наилучшим выходом будет распределение загружаемых компонентов между 2–4 (но не более) уникальными хостами. Это является компромиссом между уменьшением количества DNS-запросов и сохранением неплохой параллельности при загрузке компонентов страницы. 5.3. Балансировка на стороне клиента Балансировка нагрузки повышает надежность веб-сайта путем распределения запросов между несколькими (кластером) серверами, если один из них перегружен или отказал. Существует много методов по обеспечению такого поведения, но все они должны удовлетворять следующим требованиям:распределять нагрузку внутри кластера рабочих серверов; корректно обрабатывать отказ одного из рабочих серверов; весь кластер должен существовать для конечного пользователя как одна-единственная машина. Round-Robin DNS Популярным, хотя и очень простым подходом для балансировки запросов является циклический DNS. Он подразумевает создание нескольких записей в таблице DNS для одного домена. Например, мы хотим распределять нагрузку для сайта www.loadbalancedwebsite.ru, и у нас есть два сервера с IP-адресами 64.13.192.120 и 64.13.192.121 соответственно. Для того чтобы реализовать циклический DNS для распределения запросов, можно просто создать следующие записи в DNS:www.loadbalancedwebsite.ru 64.13.192.120 www.loadbalancedwebsite.ru 64.13.192.121 После каждого пользовательского запроса к таблице DNS для www.loadbalancedwebsite.ru, запись, стоящая первой, меняется. Ваш браузер будет использовать первую запись, поэтому все запросы будут распределяться случайным образом между этими двумя серверами. К несчастью, ключевым недостатком этого подхода является нарушение второго условия, обозначенного выше, а именно: при отказе одного из серверов сервер DNS все равно будет отправлять на него пользовательские запросы, и половина ваших пользователей окажется за бортом.Можно, конечно, перенести IP-адрес на соседний сервер, который может нести нагрузку. Однако данная процедура весьма хлопотная, чтобы проводить ее в условиях аврала.Балансировка на сервере Другим популярным подходом для балансировки запросов является создание одного выделенного сервера, который отвечает за распределение запросов. Примерами таких серверов могут быть специальное оборудование или программные решения, например F5-BIG-IP или Linux Virtual Server Project. Выделенный балансировщик принимает запросы и распределяет их уже внутри кластера веб-серверов. Балансировщик отвечает за обнаружение отказавшего сервера и распределение запросов по остальным. Для повышения надежности в эту схему может быть добавлен дополнительный балансировщик, который включается, когда отказывает основной.Минусы этого подхода: Существует предел запросов, которые могут быть приняты самим балансировщиком. Однако эта проблема решается введением в схему циклического DNS. Поддержка балансировщика может обходиться в круглую сумму, доходя до десятков тысяч долларов. К тому же запасной балансировщик большую часть времени простаивает в ожидании, когда откажет основной. Балансировка на стороне клиента Существует еще один подход для распределения нагрузки на серверы от современных веб-приложений, который не нуждается в дополнительном балансирующем оборудовании, и отказ одного из серверов происходит гораздо более незаметно для клиента, чем в случае циклического DNS. Прежде чем мы углубимся в детали, давайте представим себе настольное приложение, которому требуется установить связь с серверами в интернете для получения данных. Если наше приложение создает больше запросов к удаленному серверу, чем тот может поддерживать при помощи единственной машины, нам потребуется решение для балансировки нагрузки. Можем ли мы воспользоваться циклическим DNS или балансировщиком нагрузки, описанным выше? Конечно, но существует более дешевое и надежное решение.Вместо того чтобы сказать клиенту, что у нас единственный сервер, можно сообщить о нескольких серверах — s1.loadbalancedsite.ru, s2.loadbalancedsite.ru и так далее. При этом клиентское приложение может случайным образом выбирать сервер для подключения и пытаться получить данные с него. Если сервер недоступен или не отвечает длительное время, клиент сам выберет другой сервер, и так далее, пока не получит свои данные.В отличие от веб-приложений, которые хранят код (Javascript или Flash) на одном сервере, обеспечивающем доступ к этой информации, клиентское приложение не зависимо от сервера. Оно может само выбирать между серверами на стороне клиента для обеспечения масштабируемости приложения (рис. 5.3).
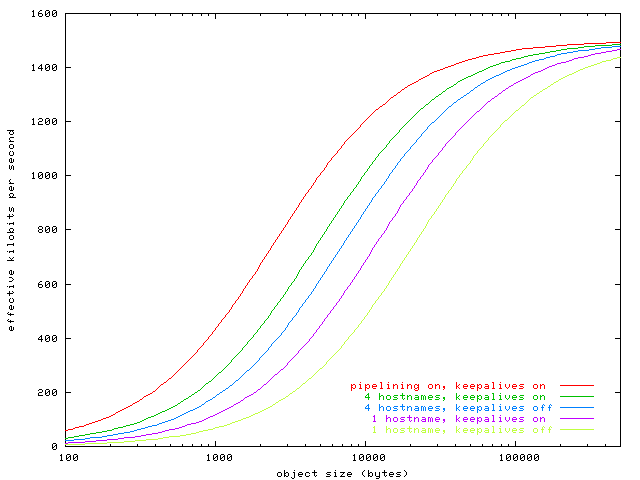
Клиентский код: JavaScript и(ли) SWF (для Flash-клиентов). Ресурсы: картинки, CSS (Каскадные Таблицы Стилей), аудио-, видео- и HTML-документы. Серверный код: внутренняя логика для обеспечения нужных клиентам данных. Заметно проще повысить доступность и масштабируемость HTML-кода страниц и других файлов, требуемых на клиенте, чем осуществить то же самое для серверных приложений: доставка статического содержания требует значительно меньше ресурсов. К тому же существует возможность выложить клиентский код через достаточно проверенные сервисы, например, S3 от Amazon Web Services. Как только у нас есть код и ресурсы, обслуживаемые высоконадежной системой доставки содержания, мы можем уже подумать над балансировкой нагрузки на серверные мощности.Мы можем включить список доступных серверов в клиентский код точно так же, как сделали бы это для настольного приложения. У веб-приложения доступен файл servers.xml, в котором находится список текущих серверов. Оно пытается связаться (используя AJAX или Flash) с каждым сервером в списке, пока не получит ответ. Таким образом, весь алгоритм на клиенте выглядит примерно так:Загружаем файл www.loadbalancedwebsite.ru/servers.xml, который выложен вместе с клиентским кодом и другими ресурсами и содержит список доступных серверов, например, в следующем виде: <servers> <server>s1.myloadbalancedwebsite.com</server> <server>s2.myloadbalancedwebsite.com</server> <server>s3.myloadbalancedwebsite.com</server> <server>s4.myloadbalancedwebsite.com</server> </servers> Выбираем случайным образом сервер из списка и пытаемся с ним соединиться. Во всех последующих запросах используем этот сервер. На клиенте существует заранее установленное время ожидания запроса; если оно превышено, то возвращаемся к шагу 2. Осуществляем кросс-доменные запросы Даже при небольшом опыте работы с AJAX уже должно было возникнуть закономерное возражение: «Это не будет работать из-за кроссдоменной безопасности» (для предотвращения XSS-атак). Давайте рассмотрим и этот вопрос.Для обеспечения безопасности пользователей веб-браузеры и Flash-клиенты блокируют пользовательские вызовы к другим доменам. Например, если клиентский код хочет обратиться к серверу s1.loadbalancedwebsite.ru, он должен быть загружен только с того же домена, s1.loadbalancedwebsite.ru. Запросы от клиентов на другие домены будут заблокированы. Для того чтобы обеспечить работоспособность описанной выше схемы балансировки, из клиентского кода на www.loadbalancedwebsite.ru требуется совершать обращения к серверам с другими доменами (например, к s1.loadbalancedwebsite.ru).Для Flash-клиентов можно просто создать файл crossdomain.xml, который будет разрешать запросы на *.loadbalancedwebsite.ru:<cross-domain-policy> <allow-access-from domain="*.myloadbalancedwebsite.com"/> </cross-domain-policy> Для клиентского кода на AJAX существуют жесткие ограничения на передачу данных между доменами, которые зависят от методов, используемых для серверных вызовов. Применение динамической загрузки скриптов для осуществления запросов позволяет обойти ограничения по безопасности, ибо разрешает кроссдоменные вызовы. Однако в этом случае нужно будет обеспечить каким-то образом безопасность на уровне заголовков, чтобы убедиться, что именно ваш клиент осуществляет такие запросы.Но что, если на клиенте используется XMLHttpRequest? XHR попросту запрещает клиенту запрашивать отличный от исходного домена сервер. Однако существует небольшая лазейка: если клиент и сервер используют одинаковый домен верхнего уровня (для нашего примера это www.loadbalancedwebsite.ru и s1.loadbalancedsite.ru), то можно осуществлять AJAX-вызовы с использованием iframe и уже через него загружать документы с сервера. Браузеры позволяют скриптам обращаться к такому iframe как к «родному», — таким образом, становится возможным доставлять данные с помощью серверного вызова через iframe, если скрипты были загружены с того же домена верхнего уровня.А если все же AJAX? Применение динамической загрузки скриптов (она описана в начале седьмой главы) для осуществления запросов позволяет обойти ограничения по безопасности, ибо разрешает кроссдоменные вызовы. Однако эту проблему можно разрешить намного проще. Кроссдоменные запросы между доменами httр://a.site.ru, httр://b.site.ru на httр://site.ru допустимы через свойство document.domain, которое надо (в данном случае) установить в site.ru: // на странице a.site.ru ... document.domain='site.ru' ... // все, теперь можно делать XmlHttpRequest на site.ru req.open("post", 'http://site.ru/result.php') Проблема решена.Преимущества балансировки на стороне клиента Итак, как только мы обговорили технику, позволяющую осуществлять кроссдоменные вызовы, можно обсудить, собственно, как работает сам балансировщик и как он удовлетворяет требованиям, изложенным в начале раздела.Распределение нагрузки между кластером веб-серверов. Так как клиент выбирает сервер, с которого принимает запросы, случайным образом, загрузка будет распределена случайно (практически равномерно) между всеми имеющимися серверами. Незаметное выключение неработающего сервера из кластера. У клиента всегда есть возможность подключиться к другому серверу, если первый не отвечает дольше заранее определенного времени. Таким образом, подключение клиента «мягко» передается от одного сервера другому. Работающий кластер доступен для клиента как один сервер. В нашем примере пользователь просто открывает в браузере «http://www.loadbalancedwebsite.ru/», который и является для клиента единственным доступным сервером. Использование всех остальных «зеркал» происходит абсолютно незаметно. Подведем итог: каковы же преимущества балансировки на стороне клиента перед балансировкой на стороне сервера? Наиболее очевидное заключается в том, что не требуется специальное балансирующее оборудование (хотя сам клиентский код будет являться достаточно сложным, полноценным веб-приложением), и не будет никакой необходимости настраивать аппаратную часть или проверять зеркальность вторичного балансировщика для страховки основного. Если сервер недоступен, его можно просто исключить из файла servers.xml.Другим преимуществом является то, что все серверы не обязаны быть расположенными в одном месте. Клиент сам выбирает, к какому серверу ему лучше подключиться, в отличие от балансирующего сервера, который рассматривает его запрос и выбирает один из кластерных серверов для его обработки. Расположение серверов ничем не ограничено. Они могут находиться в различных дата-центрах на тот случай, если один из дата-центров окажется недоступен. Если приложению требуется база данных, расположенная в локальной сети, второй дата-центр может быть по-прежнему использован как запасной, если откажет основной. Переключение с одного дата-центра на другой заключается просто в обновлении файла servers.xml вместо того, чтобы ждать распространения изменений в таблице DNS.Используем Cloud Computing для балансировки на стороне клиента В качестве серверной основы приложения можно рассмотреть сервисы Simple Storage Service (S3) и Elastic Computing Cloud (EC2) от Amazon Web Services ( http://aws.amazon.com/ ).Изначально сервис S3 предоставлял прекрасную возможность для хранения и доставки видеосообщений, а EC2 был спроектирован именно для работы с S3. Он позволяет расширять свои мощности для поддержки большого количества пользователей весьма просто. Мощности EC2 могут быть задействованы в любое время путем простого запуска образа виртуальной машины. Каждая такая машина стоит 10 центов в час или 72 доллара в месяц. Но что более всего привлекает в EC2, так это гибкость вычислительных ресурсов: виртуальные машины EC2 могут быть отключены, когда они не используются. Например, если у приложения больше трафика в дневное время, чем ночью, то можно подключать больше серверов днем, тем самым сильно повышая денежную эффективность решения в плане хостинга.Однако большим минусом для EC2 является невозможность проектирования балансировки нагрузки на стороне сервера, у которого не было бы уязвимых мест. Многие веб-приложения размещаются на EC2, используя только одну виртуальную машину с динамическим DNS для балансировки нагрузки запросов к отдельному домену. Если сервер, обеспечивающий балансировку, отказывает, то вся система становится недоступной, пока динамический DNS не подключит домен к другой виртуальной машине.Пример приложения При использовании описанной выше балансировки на стороне клиента становится возможным избежать этого неприятного момента и существенно повысить надежность всего решения на базе серверов EC2. При построении кластера виртуальных машин EC2 для поддержки балансировки на клиенте приложение использует код и другие веб-ресурсы, размещенные на S3 и отдаваемые с его помощью. Как только появляется виртуальная машина EC2 (т. е. она полностью настроена и готова принимать запросы от клиентов), тогда приложение использует следующий подход для составления списка доступных для клиента серверов.Чуть раньше указывалось на использование файла servers.xml для оповещения клиента о доступных серверах, но для S3 можно использовать более простой способ. При обращении к сегменту S3 (сегментом в S3 называют хранимую группу файлов; идея похожа на папки файлов) без каких-либо дополнительных аргументов сервис просто перечисляет все ключи, соответствующие заданному префиксу. Таким образом, для каждой из виртуальных машин приложения на базе EC2 запускается по cron-скрипту, который регистрирует сервер как часть общего кластера, просто создавая пустой файл с ключами servers/{AWS IP-адреса} в публично доступном сегменте S3.Например, по адресу http://s3.amazonaws.com/application/?actions=loadlist будет находиться следующий файл:<ListBucketResult> <Name>voxlite</Name> <Prefix>servers</Prefix> <Marker/> <MaxKeys>1000</MaxKeys> <IsTruncated>false</IsTruncated> <Contents> <Key>servers/216.255.255.1</Key> <LastModified>2007-07-18T02:01:25.000Z</LastModified> <ETag>"d41d8cd98f00b204e9800998ecf8427e"</ETag> <Size>0</Size> <StorageClass>STANDARD</StorageClass> </Contents> <Contents> <Key>servers/216.255.255.2</Key> <LastModified>2007-07-20T16:32:22.000Z</LastModified> <ETag>"d41d8cd98f00b204e9800998ecf8427e"</ETag> <Size>0</Size> <StorageClass>STANDARD</StorageClass> </Contents> </ListBucketResult> В этом примере присутствуют два EC2-сервера в кластере, с IP-адресами 216.255.255.1 и 216.255.255.2 соответственно.Логика для скрипта, запускающегося по расписанию Загрузить и разобрать http://s3.amazonaws.com/application/?actions=loadlist . Если текущий сервер отсутствует в списке, создать пустой файл в сегменте с ключом servers/{IP-адрес EC2-сервера}. Выяснить, доступны ли остальные серверы, записанные в сегменте, проверив связь с ними, используя внутренний AWS IP адрес. Если связь установить не удается, то ключ сервера из сегмента удаляется. Так как скрипт, запускающийся по cron, является частью виртуальной машины EC2, каждая такая машина автоматически регистрируется как доступный сервер в кластере. Клиентский код (AJAX или Flash) разбирает список ключей в сегменте, вычленяет внешнее имя AWS-сервера и добавляет его в массив для случайного выбора при соединении, как описано выше при рассмотрении файла servers.xml.Если виртуальная машина EC2 отказывает или выключается, то другие машины самостоятельно убирают ее запись из сегмента: в сегменте остаются только доступные серверы. Дополнительно — клиент сам выбирает другой сервер EC2 в сегменте, если ответ не был получен в течение определенного времени. Если трафик на веб-сайт увеличивается, достаточно просто запустить больше серверов EC2. Если нагрузка уменьшается, можно часть из них отключить. Использование балансировки на стороне клиента при помощи S3 и EC2 позволяет легко создать гибкое, расширяемое и весьма надежное веб-приложение.5.4. Редиректы, 404-ошибки и повторяющиеся файлы От вопросов распределения запросов и их балансировки давайте перейдем к оптимизации самой структуры веб-страницы и посмотрим, как в ряде случаев ее улучшение позволяет избежать существенных задержек и снизить издержки на доставку компонентов страницы конечному пользователю. Редиректы Редиректы осуществляются посредством отправки клиенту статус-кодов HTTP 301, 302 и 307. В качестве примера можно рассмотреть такой HTTP-заголовок со статус-кодом 301: HTTP/1.1 301 Moved Permanently Location: http://example.com/newuri Браузер автоматически перенаправляет пользователя на новый адрес, указанный в поле Location. Вся информация, необходимая для редиректа, есть в этих заголовках, тело ответа обычно остается пустым. Результаты редиректов (ни с кодом 301, ни с кодом 302) на практике не кэшируются, пока это явно не объявляется заголовком Expires либо Cache-Control. Также для перенаправления пользователя используется мета-тег refresh и JavaScript (location.href), однако, если все же необходимо сделать редирект, предпочтительней применение именно статус-кодов HTTP 301 и 302 со стороны сервера. В этом случае у пользователя будут правильно работать кнопки «Назад» и «Вперед». В случае JavaScript речь пойдет только о тех случаях, когда при загрузке первоначального HTML-файла пользователь сразу отправляется на новую страницу. Если же JavaScript используется только для динамической навигации, то это совершенно нормальная ситуация, и она не является ошибочной. Главное, что нужно помнить при использовании редиректов — это то, что они отнимают время на свое выполнение, а пользователь должен ждать его завершения. Страница даже не может начать отображаться из-за того, что пользователь еще не получил сам HTML-документ, и браузер не может начать загрузку остальных компонентов страницы. Одним из бесполезных редиректов, которые часто используются (и веб-разработчики не стремятся избегать этого), — когда пользователь забывает ввести завершающий слэш (/) в адресной строке в тех случаях, когда он там должен быть. Например, если попробовать открыть адрес http://webo.in/articles, то браузер получит ответ с кодом 301, содержащий редирект на http://webo.in/articles/ (в последнем случае содержится завершающий слэш). Это исправляется в Apache использованием Alias или mod_rewrite, или же DirectorySlash, если применяются Apache handlers. Объединение старого и нового сайтов также часто является причиной использования редиректов. Кое-кто объединяет часть старого и нового сайтов и перенаправляет (или не перенаправляет) пользователей, основываясь на ряде факторов: браузере, типе аккаунта пользователя и т. д. Применение редиректов для объединения двух сайтов является достаточно простым способом и требует минимального программирования, но усложняет поддержку проекта для разработчиков и ухудшает восприятие страницы пользователями. Альтернативой редиректу является использование модулей mod_alias и mod_rewrite в случае, если оба URI находятся в пределах одного сервера. Если же причиной появления редиректов является перенаправление пользователя между разными хостами, как альтернативу можно рассматривать создание DNS-записей типа CNAME (такие записи создают псевдонимы для доменов) в комбинации с Alias или mod_rewrite. Повторяющиеся файлы Включение одного скрипта дважды на одну страницу снижает производительность. Это не так редко встречается, как можно подумать. Два из десяти наиболее посещаемых сайтов содержат повторяющийся JavaScript-код (обращения к одинаковым JavaScript-файлам). Два основных фактора, которые могут повлиять на возникновение повторяющихся скриптов, — это количество скриптов на странице и количество разработчиков. Если происходит описанная ситуация, повторение скриптов замедляет работу сайта ненужными HTTP-запросами и вычислениями. Повторяющиеся запросы возникают в Internet Explorer (если версия IE меньше 7, то для загрузки одинаковых картинок на одной странице также может отправляться соответствующее число запросов). Internet Explorer дважды загружает один и тот же скрипт, если он включен в страницу два раза и не кэшируется. Но даже если скрипт закэширован, все равно возникает дополнительный HTTP-запрос, когда пользователь перезагружает страницу. В дополнение к ненужным HTTP-запросам тратится время на выполнение кода. Повторное исполнение кода происходит во всех браузерах, вне зависимости от того, был ли закэширован скрипт или нет. Единственным способом избежать повторного включения одного и того же скрипта является разработка системы управления скриптами в виде модуля системы шаблонов. Обычным способом включения скрипта в страницу является использование тега script: <script type="text/javascript" src="menu_1.0.17.js"></script> Альтернативой в PHP можно считать создание функции insertScript: <?php insertScript("menu.js") ?> Кроме простого предотвращения включения одного скрипта на страницу дважды, такая функция может выполнять и другие задачи, к примеру, отслеживать зависимости между скриптами, добавлять номер версии в название файла скрипта для поддержки HTTP-заголовков Expires и пр. 404-ошибки Если сервер не может удовлетворить запрос браузера по причине того, что ни один файл не соответствует запрошенному, то он отвечает со статус-кодом 404 (File Not Found). Таким образом, браузер понимает, что не может получить соответствующий ресурс, и стандартным образом обрабатывает эту ошибку. Вроде все хорошо: процесс уже давно описан в спецификации, и браузеры действуют строго согласно ей. Однако в данном случае проблема заключается в том, что если браузер получит 404-ответ от сервера при запросе какого-либо файла, который нужен для данной страницы, то этот запрос можно вообще не осуществлять. Это расходует время загрузки, расходует ресурсы сервера, расходует канал. Обычно при ответе с кодом 404 сервер пересылает еще и HTML-документ, который браузер может отобразить (это та самая 404-страница). Теперь представим, что браузер запросил небольшую фоновую картинку в 500 байтов. Вместо этого он получает 10 Кб HTML-кода, который не может отобразить (потому что это не картинка). Это совсем плохо. К счастью, все такие запросы легко отследить и устранить при своевременном анализе сайта на «битые» ссылки. 5.5. Асинхронные HTTP-запросы Для большинства сайтов загрузка страницы затрагивает десятки внешних объектов, основное время загрузки тратится на различные HTTP-запросы картинок, JavaScript-файлов и файлов стилей. При работе над оптимизацией времени загрузки страницы в сложном AJAX-приложении было исследовано, насколько можно уменьшить задержку за счет внешних объектов. Особый интерес при этом был вызван конкретной реализацией HTTP-клиента в известных браузерах и параметрами распространенных интернет-соединений, а также тем, как они влияют на загрузку страниц, содержащих большое количество маленьких объектов. Можно отметить несколько интересных фактов. В IE, Firefox и Safari по умолчанию выключена техника HTTP-конвейера (англ. HTTP pipelining). Opera является единственным браузером, где она включена. Отсутствие конвейера при обработке запросов означает, что после каждого ответа на запрос его соединение освобождается прежде, чем отправлять новый запрос. Не следует путать конвейерную обработку с Connection: keep-alive, когда браузер может использовать одно соединение с сервером, чтобы загружать через него достаточно большое количество ресурсов. В случае конвейера браузер может послать несколько GET-запросов в одном соединении, не дожидаясь ответа от сервера. Сервер в таком случае должен ответить на все запросы последовательно. Это влечет дополнительные задержки на прохождение запроса туда-обратно, что, в общем случае, примерно равно времени ping (отнесенному к разрешенному числу одновременных соединений). Если же на сервере нет элементов поддержки активных HTTP-соединений, то это повлечет еще одно трехступенчатое TCP «рукопожатие», которое в лучшем случае удваивает задержку. По умолчанию в IE (а с ним работают сейчас 50-70% пользователей) можно установить только два внешних соединения на один хост при запросе на сервер, поддерживающий HTTP/1.1, или всего 8 исходящих соединений. Использование 4 хостов вместо одного может обеспечить большее число одновременных соединений. IP-адрес в таком случае не играет роли: все хосты могут указывать на один адрес. У большинства DSL- или выделенных Интернет-соединений несимметричная полоса пропускания, она варьируется от 1,5 Мб входящего / 128 Кб исходящего до 6 Мб входящего / 512 Кб исходящего и т. д. Отношение входящего к исходящему каналу в основном находится в пределах от 5:1 до 20:1. Это означает для ваших пользователей, что отправка запроса занимает столько же времени, как и принятие ответа, который в 5–20 раз больше самого запроса. Средний запрос занимает около 500 байтов, поэтому больше всего влияния ощущают объекты, которые меньше, чем, может быть, 2,5–10 Кб. Это означает, что доставка небольших объектов может существенно снизить скорость загрузки страницы в силу ограничения на исходящий канал, как это ни странно. Моделируем параллельные запросы На основе заявленных предпосылок можно смоделировать эффективную ширину канала для пользователей, учитывая некоторые сетевые особенности при загрузке объектов различных размеров. Предположим, что каждый HTTP-запрос занимает 500 байтов и что HTTP-ответ содержит дополнительно к размеру запрошенного объекта еще 500 байтов заголовков. Это наиболее простая модель, которая рассматривает только ограничения на канал и его асимметрию, но не учитывает задержки на открытие TCP-соединения при первом запросе для активного соединения, которые, однако, сходят на нет при большом количестве объектов, передаваемых за один раз. Следует также отметить, что рассматривается наилучший случай, который не включает другие ограничения, например, «медленный старт» TCP, потерю пакетов и т. д. Полученные результаты достаточно интересны, чтобы предложить несколько путей для дальнейшего исследования, однако не могут никоим образом рассматриваться как замена экспериментов, проведенных с помощью реальных браузеров. Чтобы выявить эффект от активных соединений и введения нескольких хостов, давайте возьмем пользователя с интернет-соединением с 1,5 Мб входящим / 384 Кб исходящим каналом, находящегося на расстоянии 100 мс без потери пакетов. Это в очень грубом приближении соответствует среднему ADSL-соединению на другом краю России с серверами, расположенными в Москве. Ниже показана эффективная пропускная способность канала при загрузке страницы с множеством объектов определенного размера. Эффективная пропускная способность определялась как отношение общего числа полученных байтов ко времени их получения.
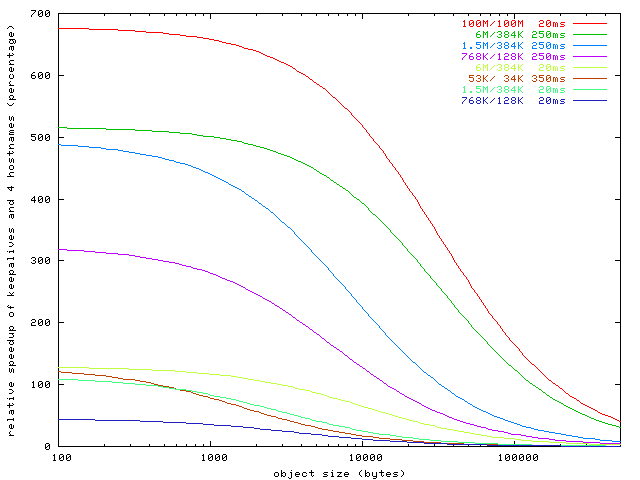
Предварительные выводы Следует отметить следующее: Для относительно небольших объектов (левая часть графика) можно сказать, судя по большому пустому месту над линиями, что пользователь очень слабо использует свой канал; при этом браузер запрашивает объекты так быстро, насколько может. Для такого пользователя эффективное использование входящего канала наступает при загрузке объектов размером 100 Кб и более. Для объектов размером примерно в 8 Кб можно удвоить эффективную пропускную способность канала, включив постоянные соединения на сервере и распределив запросы по 4 серверам. Это значительное преимущество. Если пользователь включит конвейерную передачу запросов в своем браузере (для Firefox это будет network.http.pipelining в about:config), число используемых хостов перестанет играть значительную роль, и он будет задействовать свой канал еще более эффективно, однако мы не сможем контролировать это на стороне сервера. Возможно, более прозрачным будет следующий график, на котором изображено несколько различных интернет-соединений и выведено относительное ускорение для запроса страницы с множеством мелких объектов для случая использования 4 хостов и включения активного соединения на сервере. Ускорение измеряется относительно случая 1 хоста с выключенным keep-alive (0%).
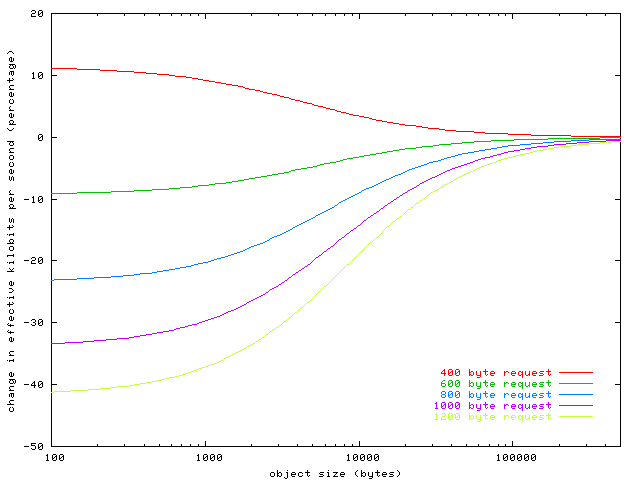
Что тут интересного? Если вы загружаете много мелких объектов, меньших, чем 10 Кб, оба пользователя — и тот, что находится локально, и тот, что на другом конце континента, — почувствуют значительное ускорение от включения активного соединения и введения 4 хостов вместо одного. Чем дальше находится пользователь, тем значительнее выигрыш. Чем больше скорость соединения, тем больше выигрыш. Пользователь с Ethernet-каналом в 100 Мб на расстоянии всего 20 мс от сервера почувствует наибольшее ускорение. Влияние заголовков Давайте теперь посмотрим, как размер заголовков влияет на эффективную пропускную способность канала. Предыдущий график предполагает, что размер заголовков составляет 500 байтов дополнительно к размеру объекта, как для запроса, так и для ответа. Как же изменение этого параметра отразится на производительности нашего 1,5 Мб / 384 Кб канала и расстояния до пользователя в 100 мс? Предполагается, что пользователь уже изначально использует 4 хоста и активное соединение.
На графике хорошо видно, что при небольших размерах файлов основные задержки приходятся на исходящий канал. Браузер, отправляющий «тяжелые» запросы на сервер (например, с большим количеством cookie), по-видимому, замедляет скорость передачи данных более чем на 40% для этого пользователя. Естественно, размер cookie можно и нужно регулировать на сервере. Отсюда простой вывод: cookie нужно по возможности делать минимальными или направлять ресурсные запросы на серверы, которые не выставляют cookie. Все полученные графики являются результатом моделирования и не учитывают некоторые реальные особенности окружающего мира. Но можно взять и проверить полученные результаты в реальных браузерах в «боевых» условиях и убедиться в их состоятельности. Реальное положение дел определенно усугубляет ситуацию, ибо медленные соединения и большие задержки становятся еще больше, а быстрые методы соединения по-прежнему выигрывают. 5.6. Уплотняем поток загрузки Рассмотрев методы сжатия, объединения, кэширования и создания параллельных соединений, разумно было бы озадачиться следующим вопросом: какая часть страницы должна загружаться вместе с основным HTML-файлом, а какая — только с внешними файлами? Было собрано тестовое окружение в виде одной страницы, для которой применены различные оптимизационные техники (заодно было получено реальное ускорение для загрузки произвольной страницы и показано, как все эти техники реально влияют на скорость загрузки страницы). Кроме того, были проведены теоретические выкладки для определения оптимального распределения загрузки по стадиям с учетом всех аспектов. Реальная ситуация
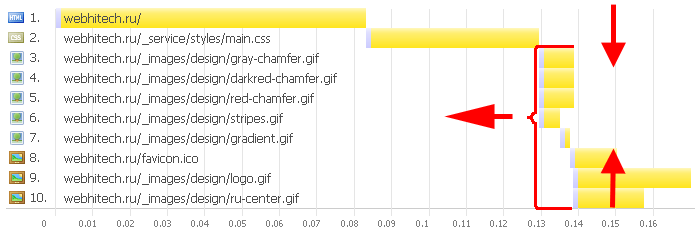
Основная идея вариации потока загрузки заключалась в создании минимального количества «белых мест» на диаграмме загрузки. Как видно из рис. 5.7, около 80% при загрузке страницы составляют простои соединений (естественно, что данный график не отражает реальную загрузку открытых в браузере каналов загрузки, однако при уточнении картины ситуация практически не меняется). Параллельные загрузки начинаются только после прохождения «узкого места», которое заканчивается (в данном случае) после предзагрузки страницы — после CSS-файла. Для оптимизации скорости загрузки нам нужно уменьшить число файлов (вертикальные стрелки), загружающихся параллельно, и «сдвинуть» их максимально влево (горизонтальная стрелка). Уменьшение «белых мест» (фактически, уменьшение простоя каналов загрузки), по идее, должно увеличить скорость загрузки за счет ее распараллеливания. Давайте посмотрим, действительно ли это так и как этого добиться. Шаг первый: простая страница Вначале бралась обычная страница, для которой использовалось только gzip-сжатие HTML-файла. Это самое простое, что может быть сделано для ускорения загрузки страницы. Данная оптимизация бралась за основу, с которой сравнивалось все остальное. Для тестов препарировалась главная страница конкурса WebHiTech ( http://webhitech.ru/ ) с небольшим количеством дополнительных картинок (чтобы было больше внешних объектов, и размер страницы увеличивался). В самом начале (head) страницы замеряется начальное время, а по событию window.onload (заметим, что только по нему, ибо только оно гарантирует, что вся страница целиком находится в клиентском браузере) — конечное, затем вычисляется разница. Но это очень простой пример, перейдем к следующим шагам. Шаг второй: уменьшаем изображения Для начала минимизируем все исходные изображения (основные прикладные техники уже были освещены во второй главе). Получилось довольно забавно: суммарный размер страницы уменьшился на 8%, и скорость загрузки возросла на 8% (т. е. получилось пропорциональное ускорение). Дополнительно с минимизацией картинок была уменьшена таблица стилей (через CSS Tidy) и сам HTML-файл (убраны лишние пробелы и переводы строк). Скриптов на странице не было, поэтому общее время загрузки изменилось несильно. Но это еще не конец, и мы переходим к третьему шагу. Шаг третий: все-в-одном Можно использовать data:URI и внедрить все изображения в соответствующие HTML/CSS-файлы, уменьшив таким образом размер страницы (за счет gzip-сжатия, по большому счету, потому что таблица стилей перед этим не сжималась) еще на 15%, однако время загрузки при этом уменьшилось всего на 4% (при включенном кэшировании уменьшилось число запросов с 304-ответом). При загрузке страницы в первый раз улучшения гораздо более стабильны: 20%. CSS-файл, естественно, тоже был включен в HTML, поэтому при загрузке всей страницы осуществлялся только один запрос к серверу (для отображения целой страницы с парой десятков объектов). Шаг четвертый: нарезаем поток Можно попробовать распределить первоначальный монолитный файл на несколько (5-10) равных частей, которые бы затем собирались и внедрялись прямо в document.body.innerHTML. Т. е. сам начальный HTML-файл очень мал (фактически, содержит только предзагрузчик) и загружается весьма быстро, а после этого стартует параллельная загрузка еще множества одинаковых файлов, которые используют канал загрузки максимально плотно. Однако, как показали исследования, издержки на XHR-запросы и сборку innerHTML на клиенте сильно превосходят выигрыш от такого распараллеливания. В итоге страница будет загружаться в 2-5 раз дольше, размер при этом изменяется несильно. Можно попробовать использовать вместо XHR-запросов классические iframe, чтобы избежать части издержек. Это помогает, но не особенно. Страница все равно будет загружаться в 2-3 раза дольше, чем хотелось бы. И немного к вопросу применения фреймов: очень часто наиболее используемые части сайта делают именно на них, чтобы снизить размер передаваемых данных. Как уже упомянуто выше, основная часть задержек происходит из-за большого количества внешних объектов на странице, а не из-за размера внешних объектов. Поэтому на данный момент эта технология далеко не так актуальна, как в 90-е годы прошлого столетия. Также стоит упомянуть, что при использовании iframe для навигации по сайту встает проблема обновления этой самой навигации (например, если мы хотим выделить какой-то пункт меню как активный). Корректное решение этой проблемы требует от пользователя включенного JavaScript, и оно довольно нетривиально с технической стороны. В общем, если при проектировании сайта без фреймов можно обойтись — значит их не нужно использовать. Шаг пятой: алгоритмическое кэширование Проанализировав ситуацию с первыми тремя шагами, мы видим, что часть ускорения может быть достигнута, если предоставить браузеру возможность самому загружать внешние файлы как отдельные объекты, а не как JSON-код, который нужно как-то преобразовать. Дополнительно к этому всплывают аспекты кэширования: ведь быстрее загрузить половину страницы, а для второй половины проверить запросами со статус-кодами 304, что объекты не изменились. Загрузка всей страницы клиентом в первый раз в данном случае будет немного медленнее (естественно, решение по этому поводу будет зависеть от числа постоянных пользователей ресурса). В результате удалось уменьшить время загрузки еще на 5%, итоговое ускорение (в случае полного кэша) достигло 20%, размер страницы при этом уменьшился на 21%. Возможно вынесение не более 50% от размера страницы в загрузку внешних объектов, при этом объекты должны быть примерно равного размера (расхождение не более 20%). В таком случае скорость загрузки страницы для пользователей с полным кэшем будет наибольшей. Если страница оптимизируется под пользователей с пустым кэшем, то наилучший результат достигается только при включении всех внешних файлов в исходный HTML. Итоговая таблица Ниже приведены все результаты оптимизации для отдельной взятой страницы. Загрузка тестировалась на соединении 100 Кб/с, общее число первоначальных объектов: 23. Номер шага Описание Общий размер (кб) Время загрузки (мс) 1 Обычная страница. Ничего не сжато (только html отдается через gzip) 63 117 2 HTML/CSS файлы и картинки минимизированы 58 108 3 Один-единственный файл. Картинки вставлены через data:URI 49 104 4 HTML-файл параллельно загружает 6 частей с данными и собирает их на клиенте 49 233 4.5 HTML-файл загружает 4 iframe 49 205 5 Вариант #3, только JPEG-изображения (примерно одинаковые по размеру) вынесены в файлы и загружаются через (new Image()).src в head странице 49 98 Таблица 5.1. Различные способы параллельной загрузки объектов на странице Шаг шестой: балансируем стадии загрузки Итак, как нам лучше всего балансировать загрузку страницы между ее стадиями? Где та «золотая середина», обеспечивающая оптимум загрузки? Начнем с предположения, что у нас уже выполнены все советы по уменьшению объема данных. Это можно сделать всегда, это достаточно просто (в большинстве случаев нужны лишь небольшие изменения в конфигурации сервера). Также предположим, что статика отдается уже с кэширующими заголовками (чтобы возвращать 304-ответы в том случае, если ресурсный файл физически не изменился с момента последнего посещения). Что дальше? Дальнейшие действия зависят от структуры внешних файлов. При большом (больше двух) числе файлов, подключаемых в head страницы, необходимо объединить файлы стилей и файлы скриптов. Ускорение предзагрузки страницы будет налицо. Если объем скриптов даже после сжатия достаточно велик (больше 10 Кб), то стоит их подключить перед закрывающим </body>, либо вообще загружать по комбинированному событию window.onload (динамической загрузке скриптов посвящено начало седьмой главы). Тут мы фактически переносим часть загрузки из второй стадии в четвертую — ускоряется лишь «визуальная» загрузка страницы. Общее количество картинок должно быть минимальным. Однако тут тоже очень важно равномерно распределить их объем по третьей стадии загрузки. Довольно часто одно изображение в 50-100 Кб тормозит завершение загрузки — разбиение его на 3-4 составляющие способно ускорить общий процесс. Поэтому при использовании большого количества фоновых изображений лучше разбивать их на блоки по 10–20, которые будут загружаться параллельно. Шаг седьмой: балансируем кэширование Если все же на странице присутствует больше 10 внешних объектов в третьей стадии (картинок и различных мультимедийных файлов), тут уже стоит вводить дополнительный хост для увеличения числа параллельных потоков. В этом случае издержки на DNS-запрос окупятся снижением среднего времени установления соединения. 3 хоста стоит вводить уже после 20 объектов, и т. д. Всего не более 4 (как показало исследование рабочей группы Yahoo!, после 4 хостов издержки скорее возрастут, чем снизятся). Вопрос о том, сколько объема страницы включать в сам HTML-файл (кода в виде CSS, JavaScript или data:URI), а сколько оставлять на внешних объектах, решается очень просто. Баланс в данном случае примерно равен соотношению числа постоянных и единовременных посещений. Например, если 70% пользователей заходят на сайт в течение недели, то примерно 70% страницы должно находиться во внешних объектах и только 30% — в HTML-документе. Когда страницу должны увидеть только один раз, логично будет включить все в саму страницу. Однако тут уже вступают в силу психологические моменты. Если у среднего пользователя страница при этом будет загружаться больше 3-4 секунд (учитывая время на DNS-запрос и соединение с сервером), то будет необходимо разбиение на две части: первоначальная версия, которая отобразится достаточно быстро, и остальная часть страницы. Очень важно понимать, какая стадия загрузки при этом оптимизируется и что видит реальный пользователь (с чистым кэшем и, может быть, небыстрым каналом). Подробнее об анализе процесса загрузки страницы на конкретных примерах рассказывается в восьмой главе. Заключение Вот так, на примере обычной страницы (уже достаточно хорошо сделанной, стоит отметить) мы добились ускорения ее загрузки еще на 15-20% (и это без учета применения gzip-сжатия для HTML, которое в данном случае дает примерно 10% от общей скорости). Наиболее важные методы уже приведены выше, сейчас лишь можно упомянуть, что при оптимизации скорости работы страницы лучше всегда полагаться на внутренние механизмы браузера, а не пытаться их эмулировать на JavaScript (в данном случае речь идет об искусственной «нарезке» потока). Может быть, в будущем клиентские машины станут достаточно мощными (или же JavaScript-движки — лучше оптимизированными), чтобы такие методы заработали. Сейчас же выбор один — алгоритмическое кэширование. |
|
||
|
Главная | Контакты | Нашёл ошибку | Прислать материал | Добавить в избранное |
||||
|
|
||||
{kind=link}
{kind=link}