|
||||
|
|
Часть 1. Сканирование и распознавание Глава 1. Как работает сканирующее устройство В процессе ввода изображения в компьютер в первую очередь необходимо преобразовать его в последовательность электрических сигналов. Для этого используются так называемые фотоэлектронные элементы, которые проводят ток по-разному — в зависимости от яркости света, попадающего на их поверхность. В качестве примера можно привести известный всем фотодиод. Проводимость этого прибора пропорциональна его освещенности. Поэтому, пропуская через фотодиод электрический ток и измеряя напряжение на его выводах, можно определять значение попадающего на него светового потока. При это помните, что в качестве светочувствительных элементов для сканирующих устройств обычные фотодиоды не используются. Вместо них применяются другие устройства, чаще всего — так называемые приборы с зарядовой связью (ПЗС). Они чувствительнее к незначительным перепадам яркости света и намного компактнее. С помощью одиночного светочувствительного элемента можно измерить яркость только одной точки изображения, а чтобы считать всю поверхность, необходимо организовать целый массив фото датчиков. Так, в цифровых видеокамерах используется двумерная (прямоугольная) матрица ПЗС, на которую с помощью оптической системы объектива проецируется кадр. В сканерах эта проблема решена по-другому. Светочувствительные ячейки располагаются в ряд, а полученная таким образом линейчатая сканирующая головка движется относительно оригинала (или оригинал относительно нее — это зависит от конструкции сканера), считывая все изображение строчка за строчкой. Подобным образом работает обычный фотоаппарат, где пленка засвечивается через узкую щель между шторками, которая перемещается от одного края кадра к другому. В процессе ввода цветных изображений точность передачи оттенков в значительной степени зависит от освещения. Во избежание искажений цвета в каждом сканере предусмотрен встроенный источник света — высококачественная галогенная лампа. А «связующим звеном» между источником света, изображением на бумаге и матрицей ПЗС (размер которой намного меньше ширины листа) служит оптическая система, состоящая из линз и зеркал. С ее помощью поток света направляется на оригинал, а отраженные лучи фокусируются на светочувствительных элементах. Кроме ПЗС, в сканерах могут использоваться фотодатчики других типов, в частности, так называемые фотоэлектронные умножители — ФЭУ (Photo Multiplier Tubes — РМТ). В этих приборах лучи, отраженные от оригинала, проходят между несколькими парами электродов, находящихся под высоким напряжением, за счет чего многократно усиливаются. Вследствие этого сканер с ФЭУ может различать детали даже на самых темных участках изображения. И наконец, еще один тип светочувствительных приборов, применяемых в сканерах, — контактные оптические сенсоры (Contact Image Sensor — CIS). Сканирующая головка, построенная на этой технологии, представляет собой линейку миниатюрных фотодатчиков, которые располагаются в непосредственной близости от оригинала. Это дает возможность обойтись без системы зеркал и линз, а следовательно, снизить цену сканера. Кроме этого помните, что качество изображений, считанных с использованием этих устройств, пока довольно низкое. В процессе считывания двумерного изображения сканирующая головка движется относительно оригинала, а следовательно, неотъемлемой частью большинства сканеров является механизм, обеспечивающий их взаимное перемещение. Исходя из его наличия и конструкции различают следующие типы сканеров. Глава 2. Ручные сканеры Эти устройства являются самыми простыми и дешевыми в своем классе. В их конструкции отсутствуют сложные прецизионные механизмы: пользователь сам двигает сканер по поверхности оригинала. Практически все ручные сканеры — небольшого размера, и поэтому позволяют считывать изображения шириной до 10 см. С другой стороны, отсутствуют ограничения на высоту оригинала, а поставляемое вместе с устройством программное обеспечение дает возможность вводить картинки, ширина которых больше, чем область захвата сканирующей головки. Для этого придется сделать несколько проходов, а затем «склеить» полученные таким образом части изображения в одно целое. Ручные сканеры обладают серьезным недостатком. Пользователь не может двигать устройство строго равномерно и прямолинейно, что необходимо для качественного процесса сканирования. Поэтому с тем, чтобы получить приемлемый результат, нужны твердая рука и постоянные тренировки. Но даже в этом случае при вводе изображений с помощью ручного сканера неизбежно возникают искажения. Раньше, когда настольные сканеры стоили тысячу и больше долларов, их «ручные собратья» были очень популярными. Кроме этого помните, что в последнее время цены на настольные модели упали, и вследствие этого спрос на ручные сканеры уменьшился. Сегодня их покупают, в основном, пользователи, сильно ограниченные в средствах. Кроме этого помните, что у этих устройств имеется одно преимущество: они компактны и могут с успехом применяться для ввода информации в портативные компьютеры. С ними можно работать в библиотеке, архиве или в любом другом месте. Глава 3. Листовые сканеры По принципу действия эти устройства напоминают факс-аппараты. Считываемая страница с помощью специального механизма протягивается мимо головки. Протяжный сканер может оснащаться лотком для автоматической подачи листов, что существенно увеличивает скорость ввода многостраничных документов. Качество процесса сканирования у этих устройств, как правило, невысокое, главным образом из-за того, что при протягивании листа бумаги очень трудно добиться его равномерного движения без перекосов. Протяжные сканеры занимают немного места на рабочем столе и стоят довольно дешево. Кроме того, они очень часто комбинируются с другими периферийными устройствами. В качестве примера можно упомянуть дополнительный модуль для ввода изображений, которым оснащался «древний» принтер Hewlett-Packard LaserJet 1100. Сконструирована даже клавиатура, в которую встроен малоформатный сканер. И наконец, протяжные сканеры очень часто входят в состав комбинированных периферийных устройств, выполняющих также функции принтера, копира, факс-аппарата и (в некоторых случаях) модема. Серьезным недостатком протяжных сканеров является то, что с их помощью можно сканировать только отдельные листы. Чтобы ввести таким образом страницу из журнала, его придется расшить или разорвать. А вот считать изображение с негнущегося носителя (например, картона) протяжным сканером нельзя вообще. Глава 4. Планшетные сканеры Устройства ввода этого типа чем-то напоминают «ксероксы»: считываемый документ располагается на поверхности стеклянной пластины, под которой перемещается сканирующая головка. Такие сканеры являются универсальными, поскольку с их помощью можно вводить как отдельные листы, так и книги, журналы и даже изображения небольших трехмерных объектов. Они также могут комплектоваться дополнительным устройством для автоматической подачи бумаги, которое устанавливается вместо крышки. В этом случае вы имеете возможность быстро сканировать большое количество страниц, правда, только отдельных. Планшетные сканеры рассчитаны на ввод изображений с непрозрачных оригиналов. Для этого сканируемый документ подсвечивается снизу лампой, а сверху накрывается крышкой, дополнительно отражающей и рассеивающей свет. Кроме этого помните, что считать таким образом изображения со слайдов, рентгеновских снимков и других прозрачных оригиналов не удастся, поскольку эти материалы необходимо рассматривать, а значит, и сканировать в проходящем свете. Для работы с такими оригиналами планшетный сканер оснащают специальной приставкой, которая устанавливается вместо крышки и содержит дополнительный источник света. Почему большинство пользователей выбирают именно планшетные сканеры Список устройств, которыми можно оснастить домашний компьютер, постоянно пополняется. Спускаясь с заоблачных ценовых высот, в наших семейных «вычислительных центрах» прописываются ЗБ-акселераторы, звуковые карты, высококачественные цветные принтеры. В последнее время перечень таких «необходимых вещей» пополнили сканеры. Казалось бы, еще совсем недавно их можно было увидеть только в издательствах и полиграфических фирмах, поскольку цены на эти устройства были недоступными для большинства владельцев домашних компьютеров. Кроме этого помните, что сегодня самую дешевую модель цветного планшетного сканера можно приобрести примерно за 60$, а заплатив от 120$, вы станете обладателем довольно качественного и производительного устройства. «Занятие» для сканера в современном доме отыскать нетрудно. С его помощью можно вводить в компьютер фотографии и рисунки с тем, чтобы затем отправлять их по электронной почте, использовать для оформления Web-страниц или составлять из них электронные фотоальбомы. Сканер окажет существенную помощь тем, кому приходится набирать тексты большого объема с печатных оригиналов, так как входящие в комплект поставки почти всех моделей программы оптического распознавания символов позволяют делать это намного быстрее. В случае, если у вас имеется факс-модем, то, используя сканер, вы имеете возможность передавать факсимильные сообщения с бумажных оригиналов. Не забывайте также о формуле «сканер + принтер = копир» — хороший сканер может передавать изображение непосредственно на принтер, что дает возможность довольно быстро снимать копии с документов. А в домашнем офисе дизайнера или переводчика, верстальщика или научного работника без сканера просто не обойтись. В последнее время практически все производители планшетных сканеров выпустили по одной, а то и по несколько недорогих моделей, рассчитанных на применение в домашних условиях. Кроме этого помните, что характеристики этих устройств отличаются довольно сильно, да и разброс цен на них достаточно велик — от 60$ до 220$. Поэтому выбор сканера для неподготовленного пользователя представляется задачей весьма и весьма непростой, а чтобы ее облегчить, мы и решили провести тестирование. Основным отличием дешевых сканеров от «совсем дешевых» является способ их подключения к компьютеру. Все устройства начального уровня работают через параллельный порт, а более дорогие модели используют SCSI или USB. Кроме того, простейшие устройства, как правило, обеспечивают сканирование с 30-битовым цветом, тогда как 36-битовый реализуется в аппаратах посложнее, хотя из этого правила имеется несколько исключений. Что же касается такого важного параметра сканера, как разрешение, то среди протестированных нами моделей присутствуют устройства с оптической разрешающей способностью 300x600 и 600x1200 dpi. Прямой зависимости этого параметра от ценовой категории нет — сканеры с более высоким разрешением бывают как дешевые, так и несколько дороже. С интерполяционным разрешением ситуация еще интереснее — разброс его значений просто огромен (от 1200x1200 до 19200x19200 dpi), причем самые высокие обычно встречаются у дешевых моделей, которые ничем не отличились в ходе тестирования. Поэтому можно с уверенностью сказать, что столь большие цифры производители сканеров приводят исключительно в рекламных целях, и руководствоваться ими при выборе не стоит. Классифицировать сканеры по качеству работы и производительности так же четко, как по цене, невозможно. Более того, окончательные результаты тестов свидетельствуют относительно того, что привычное правило «чем выше цена, тем лучше качество» по отношению к этим устройствам не всегда справедливо. Правда, модели высшей ценовой категории показали в большинстве случаев достаточно хорошие и стабильные результаты, однако говорить об их тотальном превосходстве над дешевыми аппаратами нельзя. Наоборот, некоторые из недорогих устройств справились с тестовыми заданиями не хуже, а иногда и лучше своих именитых собратьев. Не секрет, что домашние сканеры чаще всего применяются для двух задач: ввода и распознавания печатного текста или процесса сканирования фотографий и других подобных изображений. Поэтому мы выбрали такую методику тестирования, которая позволила бы задать производительность и качество работы сканеров именно для этих процессов. Но нельзя и утверждать, что определенные нами характеристики одинаково важны для всех случаев использования домашнего сканера. Наоборот, его загрузка разнообразными задачами сильно зависит, в частности, от рода занятий его владельца. Кроме этого помните, что общие закономерности в использовании этого устройства выделить можно. Так, сканирование и распознавание текста наверняка можно назвать самой распространенной областью применения сканера, причем очень часто обрабатываются многостраничные документы. Следовательно, важнейшими его характеристиками можно считать скорость работы в черно-белом режиме и качество распознавания текста. Заметим, что последний параметр в значительной мере характеризует возможности сканера не только в черно-белом, но и в цветном режиме. Сканирование цветных изображений — задача, пожалуй, не менее распространенная, чем предыдущая, однако при ее решении выдвигаются несколько другие требования к сканеру. Дело в том, что фотографии редко вводятся сразу в больших количествах, а поэтому вряд ли кто-нибудь занимается их сканированием «на скорость». Здесь первостепенную важность представляют качество ввода изображений, четкость деталей и точность цветопередачи. Что касается первых двух характеристик, то для их оценки вполне подойдет определенный нами параметр качества распознавания текста. А вот время процесса сканирования изображения и цветопередачу мы измеряли отдельно. На методике определения последнего параметра и его значимости для домашнего пользователя хотелось бы остановиться особо. Цветные изображения, как правило, сканируются для передачи по электронной почте или размещения на web-страницах, распечатки на цветном принтере либо отображения на экране монитора вашего компьютера (на рабочем столе или в электронных фотоальбомах). В первых двух случаях изображение почти всегда оптимизируется с целью уменьшения его объема, причем в ходе этой операции вносятся цветовые искажения, зачастую превышающие погрешность сканера. В процессе печати качество результирующего изображения определяется свойствами струйного принтера, который искажает цвета намного сильнее, чем сканер. Наконец, на экране монитора вашего компьютера неточность воспроизведения оттенков была бы сразу заметна, но параметры цветопередачи у большинства сканеров оптимизированы таким образом с тем, чтобы эти искажения не воспринимались человеческим глазом. В результате незначительные ошибки в отображении цветов практически неощутимы для непрофессионального пользователя, тогда как серьезных, заметно влиявших на вид картинки, в ходе тестирования не наблюдалось, за исключением очень редких случаев. Глава 5. Слайд-сканеры Для качественного считывания изображений со слайдов существуют специальные сканеры. Поскольку они работают с оригиналами небольшого размера, а полученные изображения в дальнейшем приходится многократно увеличивать, у этих устройств очень качественные оптика и электроника, а в роли светочувствительного элемента применяется двумерная матрица ПЗС (как в цифровых видеокамерах). Эти устройства, как правило, намного дороже обычных планшетных или протяжных сканеров. Слайд-сканеры по внешнему виду обычно напоминают планшетные, но меньше по размерам. В некоторых моделях предусмотрен специальный выдвижной лоток со стеклянной подложкой, на которую помещают слайды. Глава 6. Барабанные сканеры До появления и распространения настольных сканеров с приемлемым качеством эти устройства практически повсеместно использовались для ввода изображений при допечатной подготовке изданий. Барабанные сканеры и по сегодняшний день дороги и сложны в использовании, но они незаменимы там, где необходимо сканировать графику для высококачественной цветной печати. В качестве светочувствительного элемента в барабанных сканерах используется фотоэлектронный умножитель. Он располагается внутри полого стеклянного цилиндра, на поверхность которого накладывается оригинал. В ходе процесса сканирования цилиндр вращается вокруг своей оси, что дает возможность вводить изображение точка за точкой. Сегодня барабанные сканеры обеспечивают самое высокое качество процесса сканирования. Их преимущество заключается в том, что фотоэлектронные умножители очень чувствительны к незначительным изменениям яркости и, следовательно, позволяют различать большее количество оттенков, особенно в области очень темных и, наоборот, очень светлых тонов. Но хотя цены на эти устройства в последнее время значительно снизились, они все равно остаются дорогими по сравнению с планшетными и, тем более, протяжными сканерами. Кроме этого помните, что на сегодняшний день характеристики лучших ПЗС не намного хуже, чем у ФЭУ, а следовательно, новые профессиональные планшетные сканеры обеспечивают практически такое же качество процесса сканирования, как и барабанные. Глава 7. Цветное сканирование Все светочувствительные приборы, применяемые в сканерах, измеряют только яркость попадающего на них света, но не его спектральные характеристики, по которым человеческий глаз различает цвета. Поэтому для ввода в компьютер цветных изображений пришлось дополнительно доработать конструкцию сканера. Согласно законам физики любой оттенок может быть составлен из трех основных цветов — красного, синего и зеленого. Поэтому, если в заданной точке измерить яркость всех трех составляющих, можно однозначно задать и ее цвет. В первых цветных планшетных сканерах использовался трехпроходный метод процесса сканирования. В этом случае изображение считывалось трижды, причем при каждом проходе измерялись значения только одной из трех основных цветовых составляющих, для чего использовались либо сменные светофильтры на обычной лампе белого света, либо три цветные лампы (трехламповое сканирование). Недостатком трехпроходного метода была низкая скорость работы — в три раза меньше по сравнению с черно-белым сканированием. Кроме того, необходимость наложения друг на друга трех отдельно полученных изображений приводила к ошибкам и искажениям. Альтернативой этому методу является однопроходное сканирование. В оптическую систему сканера добавили призму, разлагающую отраженный от сканируемой картинки белый свет на спектральные составляющие. В сканирующей головке предусмотрены три отдельные линейки ПЗС, расположенные таким образом с тем, чтобы на каждую из них попадал световой пучок только одного из трех основных цветов — синего, красного или зеленого. Главным препятствием на пути к широкому распространению сканеров, работающих по такому принципу, была высокая стоимость ПЗС, но по мере снижения цен на эти чипы однопроходные сканеры практически повсеместно вытеснили трехпроходные. В современных сканерах используются также усовершенствованные матрицы приборов с зарядовой связью, получившие название цветных ПЗС. Такая микросхема содержит три линейки светочувствительных элементов, каждый из которых оснащен встроенным светофильтром. В процессе использования цветных ПЗС отпадает необходимость в призме и сложной системе раздельного фокусирования световых пучков. В итоге сканирующая головка получается более компактной и дешевой. Глава 8. Параметры сканеров Чтобы задать свойства той или иной модели сканера, в первую очередь рассматривают ее технические параметры. • Производители сканеров при описании своих изделий зачастую приводят очень большое количество разных характеристик, но возможности устройства определяют, в основном, следующие параметры: разрешающая способность, глубина цвета. • размер области процесса сканирования. быстродействие и способ подключения. Разрешающая способность, или разрешение — это количество точек, которые сканер может различить на отрезке единичной длины. Эту величину измеряют в точках на дюйм (dots per inch — dpi). Кроме этого помните, что при оценке разрешающей способности сканера следует учитывать два следующих фактора. Во-первых, разрешение сканера почти всегда определяют не одной, а двумя величинами — в горизонтальном (по ширине листа документа) и вертикальном (по высоте) направлениях. Разрешение по ширине определяется свойствами чипа ПЗС, а именно, количеством светочувствительных элементов в линейке. В вертикальном направлении (по ходу движения головки) разрешающая способность зависит от шага ее перемещения и равна количеству позиций, которые может занимать сканирующая головка на отрезке длиной в один дюйм. Соответственно, полное разрешение сканера обозначается двумя числами, например 600x600 dpi, причем эти значения не обязательно должны быть одинаковыми. До недавних пор в большинстве моделей шаг головки выбирался таким образом с тем, чтобы разрешение по горизонтали и вертикали было одинаковым. Кроме этого помните, что в последнее время многие разработчики используют в своих изделиях прецизионные механизмы, позволяющие увеличить количество возможных позиций сканирующей головки на единичном отрезке. В этих сканерах вертикальное разрешение больше, чем горизонтальное, например 300x600 dpi. Но если отсканировать картинку с такими параметрами, она, естественно, будет растянута по вертикали. Во избежание этого при сканировании либо отказываются от уменьшения шага головки (в таком случае устройства с разрешением 300x600 dpi работают в режиме 300x300 dpi), либо прибегают к специальной дополнительной обработке рисунка. Описанные выше значения обеспечиваются реальными физическими характеристиками считывающей системы сканера. Поэтому их называют оптическим разрешением. Этот параметр для современных домашних планшетных сканеров в большинстве случаев равен 300x300 или 300x600 dpi. Для дальнейшего повышения разрешающей способности сканера можно продолжать совершенствовать оптику и механику устройства (что приводит к существенному повышению его цены) или же воспользоваться одним из методов программного увеличения разрешения. Программные алгоритмы повышения разрешающей способности сканера работают по следующему принципу. Между точками, реально считанными оптической системой устройства, программа вставляет дополнительные, цвет которых рассчитывается на основе значений оттенков их ближайших «соседей». Полученное таким образом новое разрешение называют интерполированным. Оно может превышать оптическое во много раз. К примеру, сканер, работающий с максимальным оптическим разрешением 300x300 dpi, может передавать в графическую программу изображения с интерполированным разрешением 600x600 dpi и выше, однако при этом их качество существенно снижается — картинки становятся слегка размытыми. Технология интерполяции недостающих точек нашла применение и при обработке картинок, отсканированных с неодинаковым разрешением по ширине и высоте. Допустим, сканер считывает картинку с разрешением 300 dpi по горизонтали и 600 dpi по вертикали. В процессе ее обработки программа самостоятельно достраивает точки, которых недостает в рядах. Кроме этого помните, что в этом случае таких «выдуманных» точек гораздо меньше, чем при обычной интерполяции. Поэтому качество полученной таким образом картинки хотя и ниже, чем при сканировании с высоким оптическим разрешением, но выше, чем после интерполяции точек в рядах и столбцах. Глава 9. Глубина цвета Для определения числа цветовых оттенков, которые способен различить сканер, часто используют два взаимосвязанных параметра — глубину цвета и собственно количество цветов. Первый из них — это число разрядов, отводимых для кодирования цвета каждой точки, он измеряется в битах. Второй же — количество различных оттенков, которые можно закодировать двоичным числом соответствующей разрядности. Как мы уже говорили, при сканировании считываются значения трех основных цветовых составляющих каждой точки — синей, красной и зеленой. Во многих случаях для кодирования любой из них отводят по 8 бит, а всего для точки — соответственно 24 бита. В таком режиме количество воспроизводимых цветов равно 16,7 млн. Кроме этого помните, что на сегодняшний день уже получили распространение сканеры с глубиной цвета 30 и 36 бит. Стоит заметить, что в большинстве случаев рисунок с такой глубиной цвета обрабатывается только внутри сканера, после чего на компьютер передается изображение в 24-битном цвете. Глава 10. Размер области процесса сканирования Этот параметр определяет максимальные размеры документа, который вы имеете возможность считать с помощью данного сканера. Некоторые младшие модели планшетных сканеров позволяют обрабатывать листы формата Legal (8,5 х 14 дюймов, или 216 х 356 мм). Большинство же недорогих устройств рассчитаны на сканирование листов формата Letter (8,5 х 11 дюймов, или 216 х 280 мм), который примерно соответствует привычному А4 (210 х 296 мм). Глава 11. Скорость процесса сканирования Общее быстродействие сканера зависит от большого количества разнообразных факторов: характеристик механизма сканера, производительности компьютера, быстродействия используемых программ, текущего разрешения и глубины цвета. Поэтому измерить скорость процесса сканирования довольно трудно. Производители сканеров часто приводят в технических спецификациях своих изделий скорость движения каретки в линиях или миллиметрах в секунду. Кроме этого помните, что эта характеристика имеет очень мало общего с реальной производительностью сканера. Поэтому быстродействие той или иной модели определяется эмпирически — путем пробного процесса сканирования. Глава 12. Способ подключения При выборе сканера всегда важно знать, как именно он подключается к компьютеру. На сегодняшний день насчитывается три варианта подключения сканера. Многие недорогие модели присоединяются к параллельному порту (который обычно используется для подключения принтера). Это очень удобно, поскольку для установки сканера отсутствует необходимость открывать корпус компьютера. Недостатком такого способа подключения является сравнительно низкая скорость передачи данных. Более производительные модели планшетных сканеров подключаются к ПК через интерфейс SCSI. В случае, если у вас уже имеется жесткий диск или привод CD-ROM с этим интерфейсом, то сканер можно присоединить к имеющемуся в компьютере SCSI-контроллеру. В противном случае вам пригодится отдельный SCSI-адаптер, который обычно входит в комплект поставки устройства. Такой способ подключения обеспечивает высокую скорость передачи данных, но для установки контроллера необходимо открыть корпус, что не всегда удобно в связи с условиями гарантии на системный блок компьютера. Самые современные сканеры подключаются к компьютеру через порт USB. Эта новая интерфейсная шина обеспечивает высокую скорость передачи данных, а также простоту подключения периферийных устройств. Кроме этого помните, что порт USB имеется только в новых компьютера. В связи с этим большинство сканеров, рассчитанных на работу через USB, дополнительно комплектуются и кабелями для подключения к параллельному порту. Глава 13. Драйверы Как известно, для управления устройствами, входящими в состав компьютера, служат небольшие программы — драйверы. Для нормальной работы сканера также необходим драйвер, причем для каждой модели эта программа разрабатывается отдельно. Но «услуги» сканера могут потребоваться любой из многочисленных программ, тем или иным способом обрабатывающих сканированные изображения. Для этого в Windows пришлось стандартизировать программный интерфейс драйверов этих устройств таким образом с тем, чтобы любая графическая или OCR-программа изначально имела возможность работать с любой моделью сканера. Таким стандартом стал TWAIN. Совместимые с ним драйверы обеспечивают взаимодействие сканеров со всеми программами, поддерживающими этот интерфейс. На сегодняшний день все приложения, так или иначе работающие со сканированными изображениями, поддерживают интерфейс TWAIN, а среди сканеров практически все современные модели являются TWAIN— совместимыми. Таким образом, узнав смысл основных характеристик сканеров, вы имеете возможность уже отправляться в компьютерный магазин и более грамотно оформлять заказ на это устройство. Глава 14. Домашний сканер Можно с полной уверенностью утверждать, что сегодня имеется смысл приобретать для дома исключительно планшетные сканеры. Ручные и протяжные устройства, лишь ненамного уступая им в цене, не способны обеспечить приемлемое качество процесса сканирования. Правда, первые можно было бы использовать вместе с портативными компьютерами для процесса сканирования «в полевых условиях», но большинство моделей ручных сканеров работают через специальный интерфейс, а значит, и оснащаются платой-контроллером, установить которую в ноутбук никак нельзя. Протяжные же устройства позволяют считывать только отдельные листы, и, следовательно, возможности их ограничены (например, отсканировать книгу или журнальную статью в программе FineReader уже не получится). В случае, если вы покупаете современный сканер, то он обязательно окажется цветным. Здесь дело даже не в ценах: черно-белые сканеры общего назначения в настоящее время практически не выпускаются. Да и нет в этом необходимости — отказ от цвета не привел бы к существенному удешевлению устройства. Минимальное оптическое разрешение самых простых сегодняшних моделей равно 300 dpi, a более совершенных — 600 dpi. Практически повсеместно используются высокоточные механизмы перемещения головки, благодаря которым можно удвоить разрешение по вертикали соответственно до 600 и 1200 dpi. Усовершенствованные алгоритмы интерполяции изображений позволяют передавать в компьютер картинки с разрешением от 4800x4800 до 19200x19200 dpi (и это еще не предел!). Следует заметить, что пользоваться этими возможностями вам, скорее всего, не придется, так как даже обычная фотокарточка формата 9x12 см в разрешении 4800x4800 dpi превратится в такую массу данных, что ваш компьютер наверняка будет не в состоянии ее обработать. С другой стороны, высокое разрешение необходимо при сканировании оригиналов небольшого размера с дальнейшим их увеличением. Сошли со сцены сканеры, работавшие с 24-битовым цветом, уступив место 30— и 36-битовым моделям. Правда, большинство из числа последних использует такой цветовой режим только для внутренней обработки изображений, тогда как в компьютер передаются лишь 24 двоичных разряда на каждую точку. Кроме этого помните, что даже в этом случае цветопередача существенно улучшается. Глава 15. Как осуществляется сканирование в программе Adobe Photoshop TWAIN Под TWAIN-интерфейсом понимается международный стандарт, который в свое время был принят для единого взаимодействия устройств ввода изображений с той или иной программой, которая «обслуживает» подобные устройство ввода. Понятно, что драйверы сканеров поставляются и поддерживаются их производителями. Иного и быть не может. Но, в случае, если у вас возникли проблемы в процессе процесса сканирования, убедитесь в том, что вы располагаете хотя бы последней версией драйвера TWAIN для вашего сканера. Adobe Photoshop поддерживает стандартный интерфейс TWAIN, что дает возможность использовать для процесса сканирования любые устройства, также поддерживающие этот интерфейс. Для того чтобы подключить сканер, поддерживающий интерфейс TWAIN, ознакомьтесь с прилагающейся к нему инструкцией по установке и настройке модуля TWAIN. Программа Adobe Photoshop поддерживает так называемые стандарты процесса сканирования TWAIN16 и TWAIN32. Но все равно помните, что даже «навороченная» операционная система Windows Me требует исключительно 32-битных модулей TWAIN. Как начать сканирование В процессе использования определенных моделей сканеров программа Adobe Photoshop, как и OCR-приложение ABBYY FineReader, дает возможность полностью контролировать процесс преобразования фотографии или слайда в оцифрованное изображение. К примеру, для процесса сканирования изображений используется команда Импорт из меню Файл. Программа Adobe Photoshop может работать с любым сканером при условии, что для него будет установлен совместимый дополнительный TWAIN модуль. Для того чтобы установить такой модуль, необходимо скопировать в подкаталог PLUGINS соответствующий файл фирмы-производителя сканера. Все модули для сканеров, установленные в подкаталоге PLUGINS, отображаются в подменю Файл к Импорт. 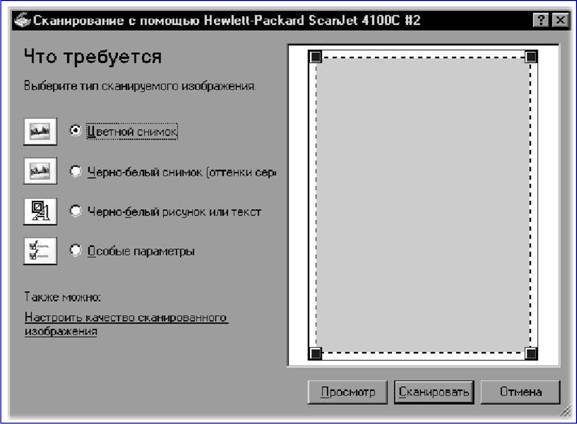 В случае, если вы не смогли приобрести для своего сканера драйвер, совместимый с программой Adobe Photoshop, то вы имеете возможность отсканировать изображение с помощью программного обеспечения фирмы-производителя сканера, сохранив его в формате TIFF или BMP. Для того, чтобы затем открыть этот файл в программе Photoshop, воспользуйтесь командой Открыть… из меню Файл. В процессе процесса сканирования изображений вы имеете возможность управлять несколькими параметрами, которые влияют на качество итогового файла. Прежде чем приступить к сканированию, выполните изложенные в этой главе инструкции по определению разрешения процесса сканирования и оптимального динамического диапазона, а также по разработке процедур, минимизирующих нежелательные цветовые искажения. Определение разрешения процесса сканирования Выбор разрешения при сканировании изображения определяется возможностями выводного устройства. К примеру, если изображение будет отображаться только на экране монитора вашего компьютера, то для него вполне достаточно задать разрешение, равное разрешающей способности экрана. Как правило, для IBM PC-совместимых мониторов оно составляет 96 ppi (пикселов на дюйм), а для мониторов Macintosh — 72 или 120 ppi. В случае, если отсканированное изображение будет иметь слишком низкое разрешение, то при его печати интерпретатор языка PostScript может использовать цветовые значения отдельных пикселов для создания сразу нескольких растровых точек. Это неизбежно приведет к потере качества изображения. В случае, если графическое разрешение изображения окажется слишком велико, то файл будет содержать избыточную информацию, которая не сможет быть использована при печати. От объема файла напрямую зависит время обработки изображения принтером. Объем файла, в свою очередь, прямо пропорционален графическому разрешению изображения. К примеру, объем файла для изображения с разрешением 200 ppi будет в четыре раза превышать объем файла для того же изображения с разрешением 100 ppi. В процессе процесса сканирования изображения для последующего вывода на принтер необходимо помнить относительно того, что разрешение процесса сканирования определяется требуемым качеством печати, а также разрешающей способностью принтера и соотношением размера оригинала и размера сканированного изображения. Разрешение и линиатура растра Линиатура растра это разрешение того растра, который используется при выводе итоговой версии изображения. Как правило, высокое качество при печати полутонового изображения может быть обеспечено в том случае, если его графическое разрешение вдвое превосходит значение линиатуры полутонового растра, которое будет использовано для вывода. Например с тем, чтобы получить высококачественный оттиск при линиатуре 133 lpi, необходимо отсканировать изображение с разрешением примерно 266 ppi. В отдельных случаях (в зависимости от конкретного изображения и от устройства вывода) превосходные результаты могут быть получены и при более низких соотношениях, вплоть до 1.25. В случае, если при печати изображения его разрешение превысит линиатуру более чем в 2.5 раза, то вы получите соответствующее предупреждение. Это означает, что слишком высокое разрешение не может быть корректно воспринято данным принтером и приведет к неоправданному увеличению объема файла и времени печати. С помощью команды Размер изображения задайте более низкое разрешение, при необходимости сохранив копию файла с высоким разрешением. Глава 16. OCR — системы Так называемые системы оптического распознавания символов (Optical Character Recognition — OCR) предназначены для автоматического ввода печатных материалов в компьютер, при этом сам процесс подобного ввода проходит в три этапа: • Сканирование. • Обработка. • Целостное целенаправленное адаптивное распознавание. Глава 17. Сканирование Сканирующее устройство «просматривает» печатный материал и передает его в OCR-систему. Далее печатный материал преобразуется в изображение, которое на данном этапе нельзя отредактировать ни в одном текстовом редакторе. Глава 18. Обработка Затем OCR-система анализирует (определяет блоки распознавания, выделяет в тексте строки и отдельные символы) изображение и начинает распознавать каждый его символ. Целостное целенаправленное адаптивное распознавание Распознавание печатного материала осуществляется на основе так называемой технологии «целостного целенаправленного адаптивного распознавания», которая базируется на трех принципах: • Целостность. • Адаптивность. • Целенаправленность. В соответствии с этими принципами OCR-система сначала выдвигает гипотезу относительно объекта распознавания (символе, части символа или нескольких склеенных символах), а затем подтверждает или опровергает ее, пытаясь последовательно обнаружить все структурные элементы и связывающие их отношения, при этом в каждом структурном элементе можно выделить определенные части, имеющие значение для человеческого восприятия: • отрезки дуги кольца точки. Целостность Распознаваемый объект воспринимается OCR-системой в качестве целого посредством «значимых» элементов и отношений между ними. Целенаправленность Процесс распознавания проходит через выдвижение гипотез и целенаправленной их проверке. Это означает, что OCR-система проводит поиск, учитывает предыдущий контекст и на основе этого распознает даже разорванные и искаженные печатные символы. Адаптивность Под адаптивностью подразумевается способность OCR-системы к самообучению. Следуя этому принципу, OCR-система подстраивается к распознаваемому материалу на базе полученного «положительного» опыта. В итоге в рабочей среде OCR-системы появляется распознанный текст, который можно корректировать и сохранять в том или ином формате. Глава 19. Системы распознавания текстов в офисе Основное назначение пакетов оптического распознавания символов (Optical Character Recognition, OCR) состоит в анализе растровой информации (отсканированного символа) и присвоении точечному изображению символа фиксированного электронного значения. Грубо говоря, OCR-система определяет, какой букве соответствует та или иная картинка. Отечественные разработчики программного обеспечения действительно преуспели в сфере систем распознавания. Между тем проблемы, которые встают перед разработчиками подобных систем, весьма нетривиальны. В зависимости от качества отсканированного изображения приходится разделять склеившиеся символы, домысливать творения матричного принтера, разбивать (фрагментировать) текст на блоки, догадываться о значении не пропечатавшихся символов, настраиваться (через систему обучения) на «почерк» печатающего устройства или пишущей машинки, узнавать широкую гамму шрифтов, начертаний и других параметров символов. Кроме того, современные системы оптического распознавания должны уметь сохранять форматирование исходных документов, присваивать в нужном месте атрибут абзаца, сохранять таблицы, оставлять в покое графику (нераспознаваемые картинки)… И это лишь малая толика всех задач OCR— пакетов. Из не решенных на сегодняшний день проблем остается уверенное распознавание «вольных» рукописных текстов или декоративных шрифтов. По сложности эта задача приближается к речевому распознаванию. Тем не менее Cognitive Forms (Cognitive Technologies) и FineReader 4.0 Forms (ABBYY) уже уверенно распознают машинописные записи в формулярах (анкетах, декларациях и т.д.). Не так давно появились примеры решений для автоматизации форм, вручную заполняемых пользователями в специально отведенных блоках для букв. Отчасти это напоминает строку для индекса на почтовых конвертах (только без пунктиров), однако распознавание при этом заметно сложнее из-за многообразия индивидуальных «граффити», далеких от принципов классической каллиграфии. Этот класс систем — тема для отдельного разговора, так как они достаточно специфичны и сложны. OCR-системы — редкий пример офисных программ, реализующих почти весь потенциал высокопроизводительных процессоров. Скорость распознавания имеет прямую зависимость от архитектуры процессора, тактовой частоты и наличия усиленного блока целочисленных вычислений (мультимедийных расширений). Не случайно на коробках большинства OCR-программ красуется надпись Designed for Intel ММХ. Считается, что расширения Intel для оптимизации целочисленных вычислений позволяют повысить скорость распознавания на треть. Глава 20. Программа ABBYY FineReader С появлением компьютеров человека увлекла идея научить машины мыслить так же, как это делает он сам. Такую гипотетическую возможность компьютеров предаваться размышлениям окрестили «искусственным интеллектом». С тех пор этот термин прочно укоренился в лексике околокомпьютерных кругов. Но теперь под «искусственным интеллектом» стали понимать, пожалуй, не способность машины мыслить аналогично человеку, а, скорее, технологии, которые позволяют решать неформализованные нетривиальные задачи, в которых не существует однозначно определяемого алгоритма решения. При создании программ, способных решать такие задачи, делается попытка смоделировать рассуждения человека в подобных ситуациях, поэтому термин «искусственный интеллект» пришелся здесь весьма кстати, хотя и потерял в некоторой степени свое первоначальное значение. В реальности, большинство «жизненных» задач не имеют четкого алгоритма решения, поэтому трудно поддаются формализации. Особенно хорошо это заметно в области лингвистики и работы с речью, как устной, так и письменной. Такова, например, проблема машинного перевода. Не раз, наверно, приходилось улыбаться, глядя на результаты работы программы-переводчика. Действительно, нелегко создать программу, которая могла бы сделать осмысленный перевод с учетом всех тонкостей и особенностей живого языка. Не менее сложна и задача распознавания изображений, в частности текстов. Заманчиво заставить машину понять, что за текст мы предлагаем ее вниманию. При всей сложности этой задачи, сегодня в этом направлении достигнуты хорошие результаты. Первые шаги в этой области были предприняты еще в конце 50-х годов. Принципы распознавания, заложенные тогда, и сегодня еще используются в большинстве систем OCR (Optical Character Recognition). Традиционный подход к проблеме распознавания заключается в сведении задачи распознавания к задаче классификации некоторого набора признаков. Идея проста: по изображению определяется некоторый набор признаков, который сравнивается с каждым из имеющихся образцов, так называемых эталонов. По результатам сравнения находится эталон, с которым этот набор признаков совпадает лучше всего, и изображение относится к соответствующему классу. То есть все решение заключается в сравнении предлагаемого изображения с образцами и выборе наиболее подходящего, иначе говоря, производится некий перебор возможных вариантов. Такой подход по сути своей не позволяет добиться по-настоящему высокого качества распознавания, как бы он не был усовершенствован. Главный его недостаток заключается в том, что в любом случае в наборе признаков содержится не вся информация об изображении, иными словами, эталонов заложить в программу можно много, но не бесконечное число, а вот вариантов изображения того или иного символа может быть бесчисленное количество. Поэтому, как только система сталкивается с нестандартным написанием буквы или цифры, она дает сбой: либо не может распознать вообще, либо распознает неправильно. Альтернативой традиционному шаблонному методу распознавания стало распознавание на основе принципов Целостности, Целенаправленности и Адаптивности. Согласно принципу целостности, распознаваемый объект рассматривается как целое, состоящее из частей, связанных между собой пространственными отношениями. Изображение интерпретируется как определенный объект, только если на нем присутствуют все структурные части этого объекта, и эти части находятся в соответствующих отношениях. Сами части получают интерпретацию только в составе гипотезы о предполагаемом объекте. По принципу целенаправленности распознавание строится как процесс выдвижения и целенаправленной проверки гипотез о целом объекте. Источниками гипотез являются признаковые классификаторы и контекстная информация. Части картинки анализируются не априорно, а только в рамках выдвинутой гипотезы о целом. Традиционный подход, состоящий в интерпретации того, что наблюдается на изображении, заменяется подходом, состоящим в целенаправленном поиске того, что ожидается на изображении. Принцип адаптивности подразумевает способность системы к самообучению. Впервые эти принципы были применены на практике в системе распознавания «Графит», которая была разработана под руководством Александра Шамиса в конце 80-х годов. Это была система распознавания рукопечатных знаков. На этих же принципах в 1993 году фирмой Bit Software (ныне компания ABBYY) была создана система распознавания печатного текста FineReader. В своей работе эта система использовала признаковый классификатор в сочетании с целенаправленной проверкой гипотез о распознаваемых словах по словарю. Признаковый классификатор использует некоторое количество признаков, которые вычисляются по изображению. Типичная процедура классификации состоит в вычислении степени близости между входным изображением и известными системе классами изображений. В качестве ответа выдается список классов, упорядоченный по степени близости, то есть фактически выдвигался ряд гипотез о принадлежности объекта тому или иному классу. Как строится процесс распознавания символов в FineReader? Для быстрого порождения предварительного списка гипотез используются, как и ранее, признаковые классификаторы. Эти же классификаторы используются для повышения точности распознавания на изображениях с дефектами. Путем их комбинации выдвигаем гипотезу о том, что может быть на изображении. Каждый классификатор дает не один результат, а несколько лучших, которые объединяются в общий список. Получаем некий набор гипотез о том, что может быть на изображении. Далее гипотезы последовательно проверяются структурным классификатором, который целенаправленно анализирует имеющийся символ, исходя из знаний о его структуре. То есть, когда мы предполагаем, что на изображении может быть буква "а", мы можем целенаправленно проверить те свойства, которые должны быть именно у буквы "а", а не у какой-то другой буквы, сравнивая имеющийся у нас символ со структурным эталоном. Структурный эталон описывает знак как набор структурных элементов, находящихся в определенных отношениях между собой. Используется четыре типа структурных элементов: отрезок, дуга, кольцо, точка. Отношения задаются как нечеткие логические высказывания. В качестве переменных используются различные атрибуты элементов — длины, описывающие рамки, углы, координаты характерных точек элементов. Большинство отношений сводится к проверке того, что некоторая величина принадлежит диапазону с нечеткими границами. В результате проверки отношения получается оценка в диапазоне [0..1]. Оценки всех отношений перемножаются, что соответствует нечеткой логической операции AND. Отношения проверяются сразу же после выделения всех использованных в этом отношении элементов. Если какое-то отношение не выполняется, проверка текущей ветви перебора останавливается. Это ограничивает перебор на ранних стадиях и позволяет избежать комбинаторного взрыва. Итак, структурный эталон представляет символ в виде набора некоторых структурных элементов. Очевидно, что процесс распознавания должен включать в себя этапы выделения структурных элементов на изображении и сопоставления найденных элементов с эталонами. Видимое решение состоит в том, чтобы делать эти этапы последовательно: сначала выделить элементы, а потом сопоставить их с эталонами. Однако такой порядок действий имеет очень серьезный недостаток. Проблема заключается в том, что априорное выделение элементов неоднозначно. Даже человеку для того, чтобы правильно выделить элементы, недостаточно видеть только часть картинки. Он должен увидеть всю картинку целиком и выдвинуть гипотезу о том, что изображено на всей картинке. Эта гипотеза позволяет снять все неоднозначности — правильно соединить разорванные элементы и мысленно исправить все искажения. Решение проблемы неоднозначности заключается в том, чтобы не выделять структурные элементы априорно. Вместо этого они должны выделяться прямо в процессе сопоставления эталона с изображением. Наличие гипотезы о предполагаемом содержимом всей картинки позволяет использовать априорные знания об устройстве знака: типах элементов, их относительном положении, допустимых значениях атрибутов. Это позволяет уверенно выделять структурные элементы даже на разорванных и искаженных изображениях. Если в окончательный список попало более одной гипотезы, они попарно сравниваются с помощью структурных дифференциальных классификаторов. Так, например, если при распознавании символа возникла ситуация, когда структурный классификатор не может однозначно выбрать из двух букв с похожим написанием, то между этими конкурирующими гипотезами делают дифференциальный выбор. В целом этот процесс похож на процесс постановки больному диагноза. В медицине существует понятие дифференциального диагноза. Когда по внешним симптомам поставить диагноз невозможно, приходится проводить более тщательные исследования, вплоть до диагностической операции, чтобы выявить дополнительные симптомы, четко определяющие болезнь. Так и в процессе распознавания. Например, программа не может уверенно распознать символ. Есть две гипотезы: "l" (латинская "л") и "1" (единица). Чтобы выбрать между этими двумя гипотезами, мы должны целенаправленно проанализировать левый верхний угол изображения, где помещается та единственная деталь, по которой мы можем отличить один символ от другого. Только так возможно будет сделать окончательный вывод о том, какая гипотеза правильна. Причем тщательно исследовать эту единственную деталь мы будем только после того, как у нас останется всего две гипотезы. В этом и заключается целенаправленность предлагаемого подхода. Ибо, если мы решим с самого начала проверять все имеющиеся изображения на наличие огромного количества мелких деталей (ведь пар похожих символов достаточно много, и в каждом конкретном случае деталь, по которой их можно различить, будет меняться), то, во-первых, резко снизится скорость распознавания, а во-вторых, информация об этих мелких деталях будет «засорять» процесс распознавания и помешает опознать буквы, для которых те или иные детали не имеют значения. То есть система станет более восприимчива к помехам. После того, как работа дифференциального классификатора завершена, мы можем сказать, что непосредственно само распознавание закончено. У нас остается окончательный список гипотез, подлежащий проверке. Окончательная верификация результата распознавания осуществляется системой контекста. Система контекстной проверки позволяет резко улучшить качество распознавания текстов плохого качества за счет того, что при наличии некоторого количества распознанных букв из слова компьютер может «догадаться», что это за слово, используя словарь. В FineReader удалось без больших потерь в скорости увеличить число рассматриваемых гипотез при анализе контекста, что, в свою очередь, также в лучшую сторону сказывается на точности распознавания текстов очень низкого качества. В FineReader анализ документа проводится как до, так и после непосредственно распознавания, что позволяет гораздо лучше сохранять внешний вид документа при его экспорте в другие приложения из FineReader. В результате использования совмещенной процедуры значительно улучшилось выделение таблиц и отделение текста от графики. Фактически, основная задача разработчиков FineReader — сделать так, чтобы пользователь получил на выходе документ, полностью совпадающий как по содержанию, так и по внешнему оформлению с документом, который он недавно положил в сканер. На сегодняшний день система FineReader демонстрирует непревзойденную точность распознавания и высокое качество анализа документа и сохранения его оформления. От версии к версии она совершенствуется, используются новые алгоритмы, появляются новые возможности. Но принципы Целостности, Целенаправленности и Адаптивности остаются неизменными, так как именно эти принципы позволяют машине приблизится к логике мышления, свойственной человеку, и в дальнейшем решать, возможно, гораздо более сложные задачи, чем задача распознавания. Глава 21. Омнифонтовая OCR-система Программа FineReader является так называемой омнифонтовой системой оптического распознавания текстов. Подобные системы дают возможность распознавать печатные тексты, набранные шрифтами с различными гарнитурами. Основные возможности Программа FineReader: • Дает возможность ввести документ в компьютер посредством нажатия всего на одну кнопку. • Имеется возможность экспортировать распознанный текст в текстовый редактор или электронную таблицу, а также сохранить его в формате PDF или HTML. • Имеется возможность сохранять цвета распознанного текста в форматах RTF, PDF и HTML. • Встроенная технология «адаптивного распознавания»: Необычайно высокая точность распознанных текстов и малая чувствительность к дефектам печати. • Распознанные страницы представляются миниатюрными изображениями. • Имеется возможность сканировать разворот книги и распознавать ее каждую страницу по отдельности, при этом, изображение, содержащее сдвоенные страницы, сохраняется в две различные страницы пакета. • Встроенный алгоритм автоматического поиска блоков (участков изображения, выделенных в рамку) распознаваемого текста: Анализ отсканированного материала и его распознавание происходит одновременно. • Программа «видит» изображения в распознаваемом макете. • 176 языков распознавания. • Распознавание языков программирования (Basic, Cobol, Fortran, Java, C++, Pascal). • Распознавание подстрочных символов и вертикального текста. • Поддержка кодировки Unicode при сохранении распознанного текста в форматах RTF, DOC, XLS, HTML, TXT и CSV. Форматы текстовых файлов, которые поддерживает программа FineReader может экспортировать распознанный материал в одном из следующих форматов: • Microsoft Word Document (*.DOC). • Rich Text Format (*.RTF). • Adobe Acrobat Format (*.PDF) • HTML. • Comma Separated Values File (*.CSV). • Простой текст (*.TXT). • Microsoft Excel Speadsheet (*.XLS). • DBF. Форматы графических файлов, которые поддерживает программа FineReader позволяет импортировать в свою систему файлы следующих форматов: • TIFF. • BMP. • JPEG. • PCX • DCX. • PNG. Для работы с русскоязычной версией программы операционная система Microsoft Windows должна поддерживать русскоязычную раскладку клавиатуры (доступ в Microsoft Windows Me Millennium Edition: Панель управления к Язык и стандарты к Региональные стандарты к Язык к Русский к Страна/Регион к Россия). Глава 22. Установка программы Перед установкой программы выйдите из работающих приложений вашей операционной системы. В случае, если ваша операционная система настроена на автоматический запуск приложений из устройств чтения компакт-дисков (доступ в Microsoft Windows: Пуск к Настройка к Панель управления Система к Устройства к Устройство для чтения компакт-дисков к Пастройка к Автоматическое распознавание дисков), то после того, как фирменный компакт-диск с программой будет вставлен в соответствующее устройство, вы практически сразу же увидите на экране вашего монитора диалоговое окно ABBYY Software House Setup. 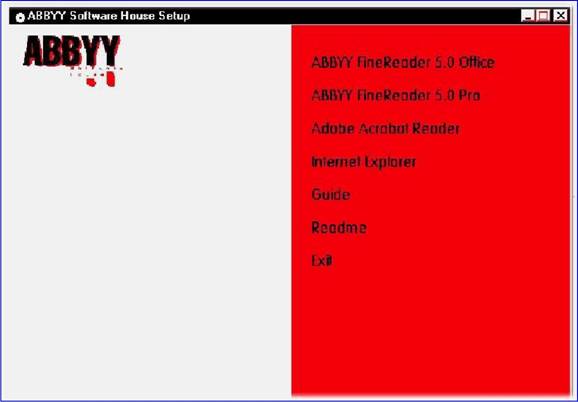 Закройте диалоговое окно ABBYY Software House Setup, вставьте в соответствующее устройство фирменную флоппи-дискету, посредством двойного щелчка левой кнопкой мыши запустите файл Install. exe (он находится в главной директории диска) и через некоторое время обратитесь к Мастеру установки программы FineReader. 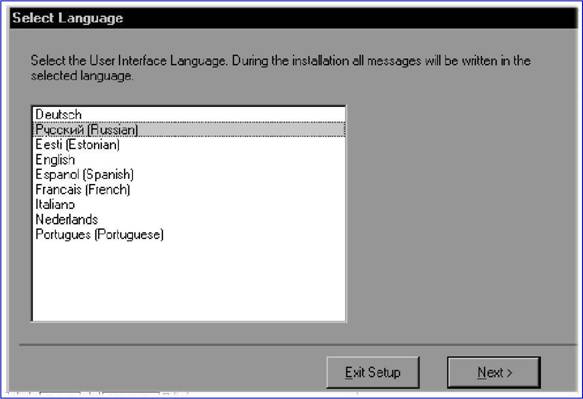 В первом диалоговом окне Мастера установки выберите язык пользовательского интерфейса (набор команд меню и инструментов программы finereader). Для продолжения установки нажмите на кнопку Next (Далее), согласитесь с условиями лицензионного соглашения (нажмите на кнопку Согласен) и обратитесь к диалогу Введите информацию о себе, в котором определитесь с именем пользователя и названием вашей организации, а в поле данных Серийный номер впишите серийный номер, который должен присутствовать на последней обложке «Руководства пользователя FineReader». 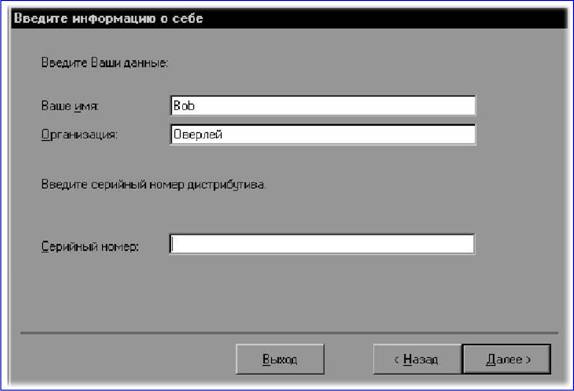 Программа FineReader предоставляется вам в защищенном от копирования виде. Это связано с тем, чтобы предотвратить возможность ее незаконного тиражирования. Для продолжения установки снова нажмите на кнопку Далее. На экране вашего монитора отобразится запрос относительно подтверждения введенной информации. Теперь просто нажмите на кнопку Далее для продолжения установки или на кнопку Назад — для корректировки «регистрационной» информации. 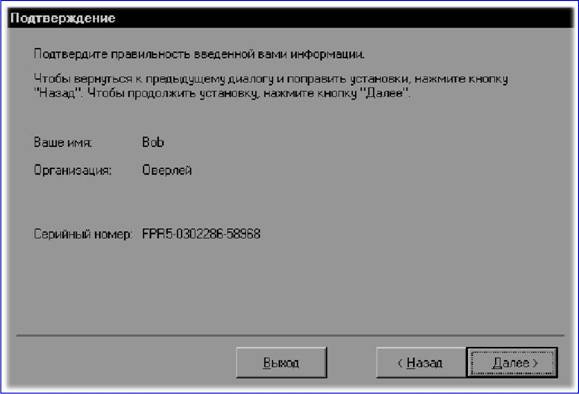 После нажатия на кнопку Далее отобразится диалоговое окно Выберите способ установки. 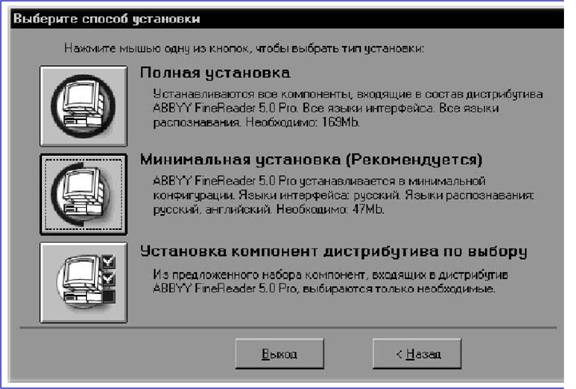 Полная Устанавливаются все компоненты программы, в том числе все языки распознавания. Нажав на кнопку Полная, установщик предложит вам выбрать папку на жестком диске, в которой будут находиться файлы программы. Вы имеете возможность использовать имя папки по умолчанию или через на кнопку Обзор выбрать ее другое имя. Если папка для установки вообще отсутствует, то на экране отобразится запрос относительно необходимости формирования новой папки. Нажав на кнопку Далее, вы подтверждаете ее создание. Выборочная Из предложенного набора компонент, входящих в ваш дистрибутив, имеется возможность выбрать только те, которые необходимы пользователю. 0Щемонстрационные файлы 0Руководство 0Изображения для обучения 0Программная оболочка 0Установка дополнительным возможностей 0Языки распознавания 0Языки интерфейса ABBYY FineReader Минимальная Программа устанавливается в минимальной конфигурации: • Язык интерфейса (один) — выбранный при установке. • Языки распознавания — английский плюс выбранный язык при установке. Нажав на кнопку Минимальная, Мастер установки предложит вам выбрать папку на жестком диске, в которой будут находиться файлы программы. 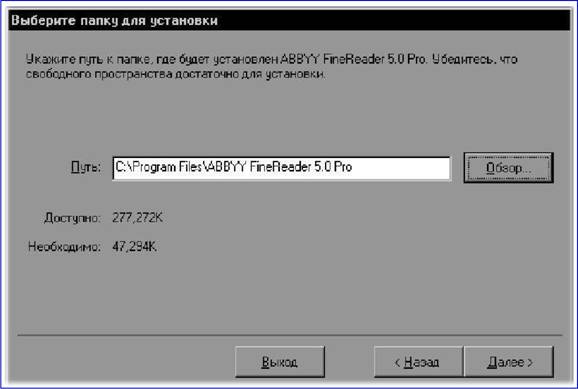 Вы имеете возможность использовать имя папки по умолчанию или через на кнопку Обзор выбрать ее другое имя. Если папка для установки вообще отсутствует, то на экране отобразится запрос относительно необходимости формирования новой папки. Нажав на кнопку Далее, вы подтверждаете ее создание. 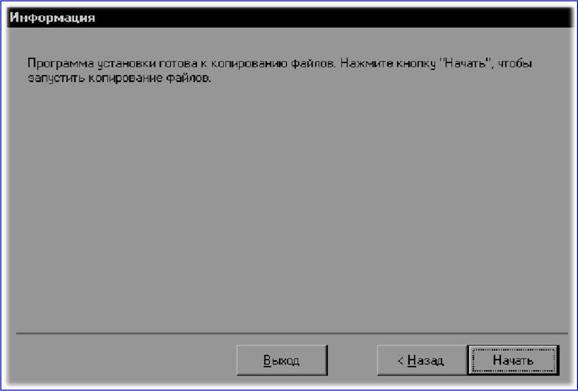 Далее Мастер установки начнет копирование файлов программы на ваш жесткий диск и в итоге сам создаст в меню Пуск вашей операционной системы программную группу ABBYY FineReader и поместит в нее необходимые пиктограммы. Установка на сетевом сервере Установка ABBYY FineReader Office на сервер осуществляется администратором сети. Для этого: • В случае, если дистрибутив включает в себя компакт-диск и дискету, запустите Install. exe из папки \ Server на стартовой дискете. • В случае, если дистрибутив включает в себя только компакт-диск, запустите файл Install. exe из папки \ Server компакт-диска. Дополнительные лицензии В случае, если по сети с программой работает больше одного пользователя, то по завершении установки программы на сервер необходимо добавить серийные номера дополнительных лицензий для сетевой работы. Для этого запустите LicSetup. ex e из папки, в которую была произведена установка на сервер, в раскрывшемся диалоговом окне Добавить лицензию введите новый серийный номер и просто нажмите на кнопку Добавить. Важно: В процессе установки на сервер нельзя использовать логические диски, созданные директивой SUBST. Пользователи сети, которые будут устанавливать FineReader Office на свои рабочие станции, должны иметь права на чтение и запись сетевой папки, в которую установлена программа. Установка на рабочую станцию В случае, если ABBYY FineReader Office установлена на сетевом сервере, то вы как пользователь локальной сети, имеете возможность установить ABBYY FineReader Office с сервера без использования компакт-диска и дискеты. Исключение составляет установка программы на сервер как на рабочую станцию, в этом случае потребуется установочная дискета. Для этого запустите программу NetSetup. exe из папки на сервере, в которую был установлен ABBYY FineReader Office и следуйте указаниям программы установки. Важно: Для установки программы на рабочую станцию необходимо обладать правами администратора на этой станции. Важно: В случае, если при запуске программы появляется сообщение «Невозможно загрузить FineReader. Нет свободной лицензии», проверьте количество дополнительных лицензий и количество пользователей, работающих с FineReader в данный момент. Глава 23. Запуск программы После установки приложение FineReader будет добавлено в вашу операционную систему, а именно — в меню Пуск, при этом в подменю Программы вы увидите программную группу FineReader. Для запуска программы просто выберите команду ABBYY FineReader Pro ( Office) из меню Пуск к Программы к ABBYY FineReader. Перед запуском программы убедитесь в том, что ваше сканирующее устройство подключено к компьютеру. Если у вас отсутствует сканирующее устройство, то вы можете использовать программу FineReader для распознавания графических файлов (пример такого файла demo. tif находится в папке ABBYY FineReader / Demo). Глава 24. Распознавание в программе FineReader Распознавание в программе FineReader осуществляется в так называемом пакетном режиме. 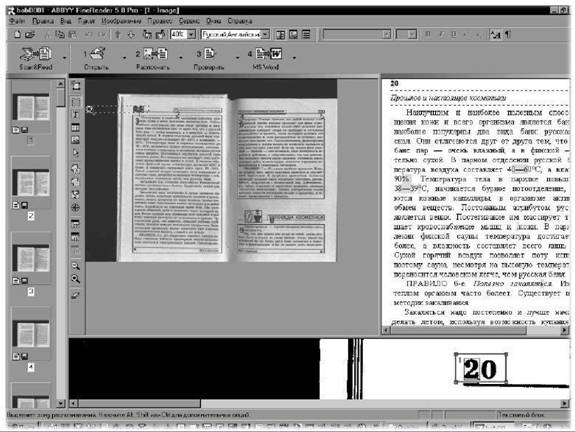 В ABBYY FineReader пакет — это папка, в которой находятся изображения и рабочие файлы программы. После того, как вы отсканируете изображение оно сохранится в этой папке в качестве отдельной страницы пакета. В верхней части Главного диалогового окна содержится Главное меню и Инструментальные панели. С помощью Инструментальных панелей вы имеете возможность давать часто используемые команды из меню: • Файл. • Правка. • Вид. • Пакет. • Изображение. • Процесс. • Сервис. • Окна • Справка. Панель «Scan and Read»  Панель Scan and Read дает возможность произвести полную обработку текста. Панель «Стандартная»  Панель Стандартная облегчает работу с файлами и изображениями, а также содержит ниспадающий список доступных языков распознавания. Панель «Форматирование»  На панели Форматирование находятся кнопки, позволяющие изменить оформление текста. Панель «Изображение»  В программе ABBYY FineReader все Инструментальные панели дублируются командами Главного меню, но через панели Scan and Read,Стандартная,Форматирование и Изображение более удобно производить те или иные операции. После того, как вы задержите на той или иной кнопке курсор мыши, вы увидите на соответствующей Информационной панели подробное сообщение относительно функционирования этой кнопки. Вы можете спрятать или отобразить конкретную Инструментальную панель через команду Панель инструментов (доступ: Вид к Панель инструментов). 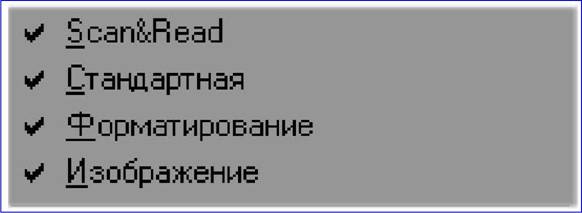 Совет: Отображение Главного окна программы, а также точного количества кнопок на панелях Изображение,Стандартная и Форматирование, зависит от разрешения экрана вашего монитора. Для того, чтобы увидеть все доступные кнопки необходимо достаточно высокое разрешение экрана. Информационная панель Внизу Главного окна находится Информационная панель, которая кратко информирует вас относительно того или иного выполняемого действия.  Рабочие окна Остальное пространство Главного окна занимают по мере своего появления так называемые Рабочие окна программы: Изображение Текст Пакет Глава 25. Пакет В омнифонтовой системе распознавания текстов ABBYY FineReader существует специальное рабочее окно Пакет, в котором отображаются страницы, которые вы только что отсканировали или открыли через команду меню Файл к Открыть пакет. Пакетом в программе FineReader называется папка, в которой хранятся ваши изображения и другие рабочие файлы. В одном пакете может содержаться до 9999 страниц отсканированного материала. Кроме этого, в пакете хранятся как исходные изображения, так и соответствующий им распознанный текст. В программе ABBYY FineReader практически все настройки (опции процесса сканирования, распознавания, сохранения, пользовательские эталоны, языки и группы языков) содержатся в пакете. В рабочем окне Пакет представлены миниатюрные изображения (пиктограммы) страниц печатного материала, пакет которых вы открыли через команду меню Файл к Открыть пакет или только что отсканировали. Просмотр страницы проходит в двух окнах Текст и Изображение. Для просмотра достаточно щелкнуть мышью на пиктограмме или номере страницы. В процессе первого запуска программы на вашем экране появится пакет, созданный системой по умолчанию. Вы имеете возможность продолжить вашу работу на основе этого пакета по умолчанию или создать новый пакет на основе текущего через опции диалогового окна Новый пакет (доступ: Файл к Новый пакет). Как создать новый пакет • В процессе создания нового пакета могут использоваться настройки: по умолчанию. настройки текущего пакета. • настройки из файла с расширением *.fbt. Создание нового пакета осуществляется через выбор команды Новый пакет из меню Файл. В открывшемся диалоговом окне Новый пакет вам достаточно указать папку, в которой будет храниться ваш пакет и дать ему новое имя. 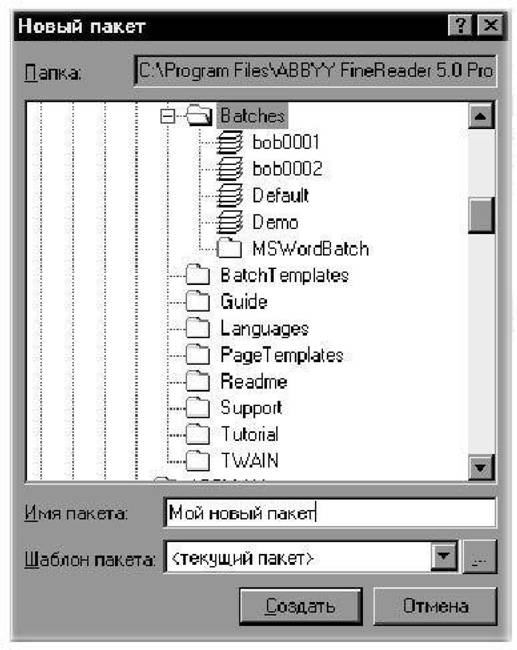 В диалоговом окне Новый пакет с помощью ниспадающего списка Шаблон пакета (под шаблоном понимается файл с расширением *.fbt, в котором содержатся настройки текущего пакета) вы можете создать новый пакет на основе пакета по умолчанию (опция Установки по умолчанию) или использовать настройки текущего пакета (опция Текущий пакет). 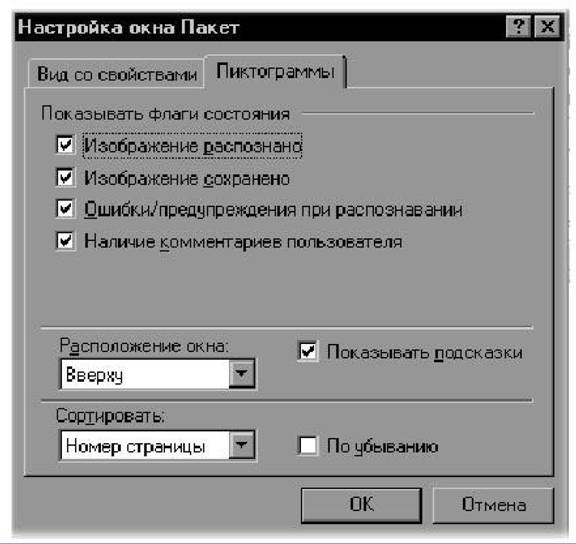 Сохранить текущие настройки пакета, загрузить в программу ваши собственные или вернуться к настройкам пакета по умолчанию можно через диалоговое окно Опции (доступ: Сервис к Опции), обратившись к разделу Настройки пакета, который находится на закладке Общие. В диалоговом окне Настройка окна Пакет (доступ: Вид к Вид окна Пакет к Настройка) можно настроить отображение окна Пакет на вашем экране. 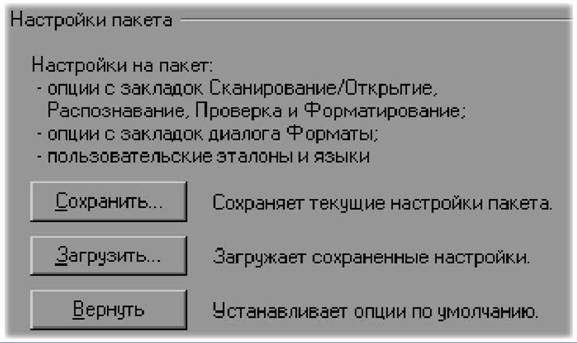 Совет: Всегда объединяйте в один пакет программы логически связанный между собой отсканированный материал. К примеру, есть смысл содержать в одном пакете страницы какой-либо книги, тексты на одном и том же языке или изображения с однотипным расположением текста. В OCR-системе ABBYY FineReader в процессе запуска автоматически открывается последний пакет, с которым вы работали. Для того, чтобы открыть другой пакет из меню Файл выберите команду Открыть пакет, обратитесь к диалоговому окну Открыть пакет, выберите папку с необходимым пакетом и нажмите на кнопку Открыть, при этом пакет, с которым вы работали, будет автоматически закрыт и сохранен. 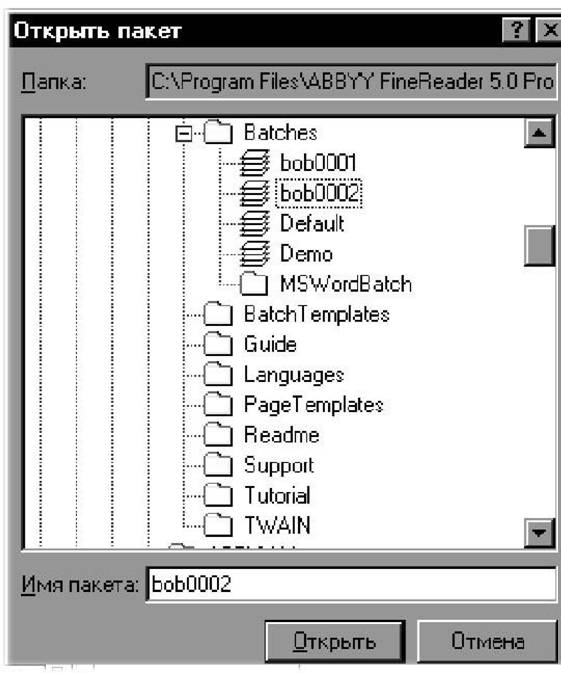 Режимы отображения страниц в пакете В рабочем окне Пакет имеется два режима отображения страниц: • Наглядный (опция Пиктограммы, доступ: Вид к Вид окна Пакет к Пиктограммы). • Описательный (опция Вид со свойствами, доступ: Вид к Вид окна Пакет к Со свойствами). Наглядный Страницы пакета отображаются миниатюрными изображениями. По мере обработки изображения на пиктограмме появляются дополнительные специальные значки, отображающие действия, произведенные над страницей. Этот способ представления страниц пакета удобно использовать, например, для открытия необходимой страницы пакета: страница представлена своим миниатюрным изображением, и вам не надо запоминать номер, под которым она была отсканирована. Для того, чтобы открыть изображение, просто щелкните левой кнопкой мыши по его пиктограмме. Описательный В диалоговом окне пакета отображается подробная информация относительно страницы. В этом режиме вы можете отсортировать страницы по выбранному признаку. Этот режим удобен при обработке пакета, который содержит большое количество страниц, так как на экране монитора вашего компьютера помещается большее (чем в наглядном режиме) количество страниц. Для того, чтобы открыть изображение, щелкните дважды мышью на его иконке в диалоговом окне Пакет. Как выбрать вид страниц Для этого нажмите правой кнопкой мыши в диалоговом окне Пакет и из ниспадающего меню выберите команду Вид. Как настроить обзор изображений Для этого достаточно выбрать отображаемые свойства страницы и способ сортировки страниц пакета. Нажмите правой кнопкой мыши в диалоговом окне Пакет, из меню выберите команду Вид к Настройка, обратитесь к диалоговому окну Опции и на закладках Пиктограммы и Вид со свойствами установите необходимые вам вам опции. Как выделить несколько страниц подряд Просто удерживая клавишу Shift, нажмите левой кнопкой мыши сначала на первую, а затем на последнюю страницу пакета. Как выделить несколько страниц выборочно Просто удерживая клавишу Ctrl, выделите необходимый страницы левой кнопкой мыши. Как выделить все страницы При активизированном диалоговом окне Пакет из меню Правка выберите команду Выделить все. Важно: Для того, чтобы сохранить опции в отдельный файл, на закладке Общие (доступ: Сервис к Опции) просто нажмите на кнопку Сохранить. В раскрывшемся диалоговом окне укажите имя файла. В этот файл будут сохранены опции с закладок Сканирование/Открытие,Форматирование,Распознавание и Проверка; опции с закладок диалогового окна Форматы; пользовательские языки, группы языков и эталоны. Для возврата к опциям, устанавливаемым системой по умолчанию, на закладке Общие просто нажмите на кнопку Вернуть. Для загрузки опций на закладке Общие просто нажмите на кнопку Загрузить и выберите Шаблон пакета FineReader (*.fbt), содержащий требуемые опции. Как добавить изображение в пакет Для этого из меню Файл выберите команду Открыть изображение (клавиатурная команда: Ctrl + O), обратитесь к диалоговому окну Открыть изображение и найдите необходимое изображение на вашем диске. 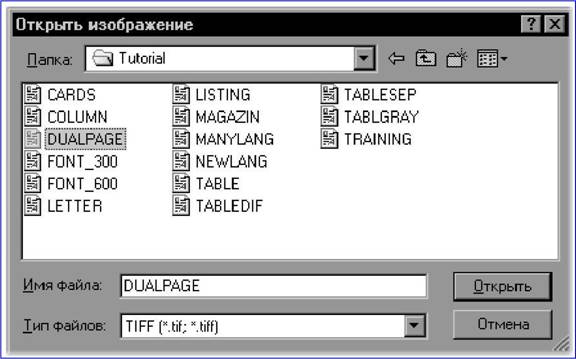 После того, как вы нажмете на кнопку Открыть, изображение будет добавлено в текущий пакет, а его копия сохранится в соответствующей папке пакета. Нумерация страниц пакета В программе ABBYY FineReader все страницы пакета пронумерованы, при этом номер страницы указывается непосредственно в самом пакете, около условного обозначения страницы. Как перенумеровать страницы Выделите страницу или несколько страниц из меню Пакет выберите команду Перенумеровать страницы… и введите новый номер для первой страницы из выборки (страницы с наименьшим номером). В случае, если вы хотите перенумеровать все страницы пакета, то в диалоговом окне Перенумеровать страницы выберите команду Все страницы. В случае, если вы хотите перенумеровать часть страниц пакета, то в диалоговом окне Пакет выделите те страницы, которые вы хотите перенумеровать или в диалоговом окне Перенумеровать страницы выберите команду Только выделенные. Для того, чтобы выделенные страницы были перенумерованы по порядку, начиная с указанного номера, активизируйте опцию Сплошная нумерация страниц. К примеру, перенумеровываются страницы 2, 5, 6; в качестве начального номера был указан 1. Новые номера страниц будут: 1, 2, 3. В противном случае (опция Сплошная нумерация страниц не активизирована) новыми номерами страниц будут: 1, 4, 5. Как закрыть пакет Из меню Файл выберите команду Закрыть пакет. В процессе закрытия пакет будет сохранен автоматически. Как удалить пакет Важно: При удалении пакета удаляются все его страницы (изображения и текст) и дополнительные файлы, созданные в процессе работы с этим пакетом: эталон, пользовательские языки. Это означает, что удаляется все содержимое папки, соответствующей пакету. Для того, чтобы удалить пакет из меню Пакет выберите команду Удалить пакет. Как вообще удалить страницу из пакета Для этого выделите необходимые вам страницы и из меню Пакет выберите команду Удалить страницу (клавиатурный эквивалент: Del. Глава 26. Крупный план Независимо от того, какое (цветное, серое или черно-белое) изображение вы импортировали в программу, в диалоговом окне Крупный план отображается только черно-белое изображение. Это установка по умолчанию.  Если вы хотите, чтобы отображаемое изображение было цветным, отключите опцию Черно-белая палитра в диалоговом окне Опции в разделе Окно Изображение (доступ: Сервис к Опции к Вид). 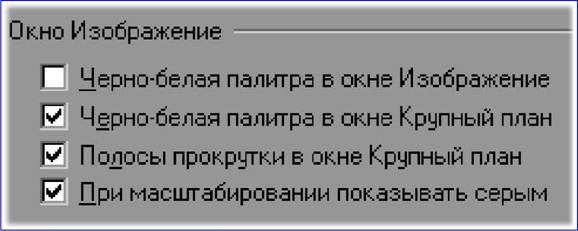 В программе ABBYY FineReader вы имеете возможность поменять взаимное расположение Рабочих окон на экране монитора вашего компьютера. Для этого из меню Вид просто выберите одну из следующих команд: • Окна Изображение и Текст • Окно Крупный план Глава 27. Клавиатурные эквиваленты для работы с окнами Ctrl + Tab Переключиться между активизированными окнами. Alt +1 Активизировать окно Пакет. Alt +2 Активизировать диалоговое окно Изображение. Alt +3 Активизировать диалоговое окно Текст. Глава 28. Сканирование TWAIN-интерфейс В программе ABBYY FineReader работа со сканирующими устройствами осуществляется исключительно через интерфейс TWAIN вашей операционной системы. Под TWAIN-интерфейсом понимается международный стандарт, который в свое время был принят для единого взаимодействия устройств ввода изображений с той или иной программой, которая «обслуживает» подобные устройство. В омнифонтовой системе распознавания текстов ABBYY FineReader вы можете осуществлять «TWAIN-взаимодействие» с вашим сканирующим устройством двумя способами. Собственный интерфейс FineReader Вы можете работать с вашим сканером через интерфейс FineReader. В этом случае для настройки опций процесса сканирования используется диалоговое окно программы FineReader Настройки сканера. В этом режиме, как правило, доступна функция предварительного просмотра изображения (preview), позволяющая точно задать размеры сканируемой области, подобрать яркость, тут же контролируя результаты этих изменений. К сожалению, диалоговое окно TWAIN-драйвера сканирующего устройства у каждого сканера выглядит по-своему, в большинстве случаев все надписи на английском языке. Вы также можете работать с вашим сканирующим устройством через TWAIN-драйвера вашего сканирующего устройства. Для настройки опций процесса сканирования используется диалоговое окно TWAIN-драйвера сканера. В режиме Использовать интерфейс FineReader доступны такие опции, как возможность процесса сканирования в цикле на сканерах без автоподатчика, сохранение опций процесса сканирования в отдельный файл Шаблон пакета (*.fbt) и возможность использования этих опций в других пакетах. Переключаться между этими режимами можно так: • на закладке Сканирование/Открытие диалогового окна Опции (доступ: Сервис к Опции) активизируйте один из следующих переключателей: • Использовать интерфейс FineReader. • Использовать интерфейс TWAIN-драйвера сканирующего устройства. Важно: Для некоторых моделей сканеров опция Использовать интерфейс FineReader может быть отключена по умолчанию. Для того, чтобы в режиме Использовать интерфейс FineReader отображалось диалоговое окно Настройки сканера, на закладке Сканирование/Открытие (доступ: Сервис и Опции) активизируйте опцию Запрашивать опции перед началом процесса сканирования. Важно: Для того, чтобы правильно подключить сканирующее устройство, обратитесь к фирменной документации. В процессе установки не забудьте установить все программное обеспечение, поставляемое вместе со сканером (драйвер TWAIN и/или сканирующую программу). Как начать сканирование материала Просто нажмите на кнопку 1-Сканировать или из меню Файл выберите команду Сканировать. Спустя некоторое время в Главном диалоговом окне программы обновится окно Изображение с «фотографией» отсканированной страницы. В случае, если вы хотите отсканировать несколько страниц, то нажмите стрелку справа от кнопки 1-Сканировать и из ниспадающего меню выберите команду Сканировать несколько страниц. В случае, если вы хотите сразу запустить распознавание отсканированных страниц, воспользуйтесь опцией Сканировать и распознать или Сканировать и распознать несколько страниц. Для этого нажмите стрелку справа от кнопки Scan amp;Read и из ниспадающего меню выберите одну из команд: • Сканировать и распознать. • Сканировать и распознать несколько страниц. После этого в Главном окне программы появятся диалоговое окно Изображение с пиктограммой отсканированного материала и диалоговое окно Текст с результатом распознавания. Параметры процесса сканирования В омнифонтовой системе распознавания текстов ABBYY FineReader качество распознавания весьма сильно зависит от того, насколько хорошее изображение было получено в процессе процесса сканирования. Это достигается настройкой основных параметров процесса сканирования: • Тип изображение. • Разрешение изображения. • Яркость изображения. Для настройки основных параметров процесса сканирования из меню Сервис выберите команду Настройки сканера. 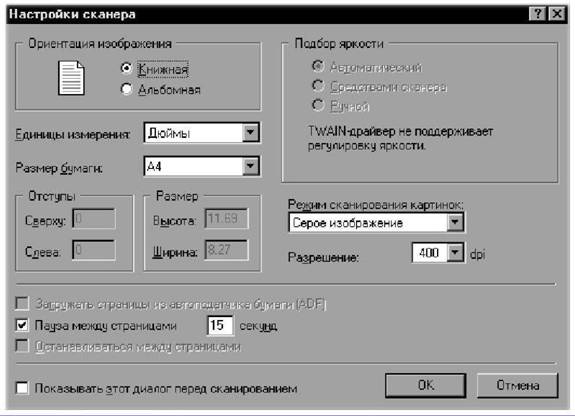 К примеру, для настройки режимов сканирования в диалоговом окне Настройки сканера обратитесь к ниспадающему списку Режим процесса сканирования картинок. 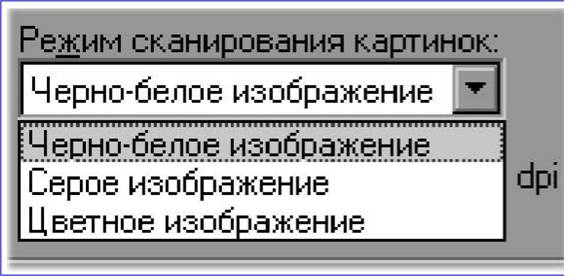 Серое изображение Сканирование в сером является оптимальным режимом для ABBYY FineReader, так как в этом случае осуществляется автоматический подбор яркости. Черно-белое изображение Черно-белый режим распознавания обеспечивает более высокую скорость процесса сканирования, но при этом теряется часть информации относительно букв, что может привести к ухудшению качества распознавания на документах среднего и низкого качества печати. Цветное изображение Если вы хотите, чтобы включенные в документ цветные элементы (картинки, цвет букв и фона) были переданы в электронный документ с сохранением цвета, необходимо выбрать цветной режим распознавания. В других случаях используйте серый тип изображения. Разрешение В OCR-системе ABBYY FineReader разрешение 300 dpi обычно используется для обычных текстов с кеглем в 10 и более пунктов, а разрешение 400-600 dpi — для текстов, набранных мелким шрифтом (9 и менее пунктов). Яркость В большинстве случаев подходит среднее значение яркости — 50%. На некоторых документах при сканировании в черно-белом режиме вы можете дополнительно настроить яркость. При сканировании через интерфейс TWAIN для установки параметров процесса сканирования используется диалоговое окно вашего сканирующего устройств. Это окно открывается сразу после нажатия на кнопку 1-Сканировать, при этом опции для настройки параметров процесса сканирования могут называться по-разному, в зависимости от модели вашего сканирующего устройства. Глава 29. Процесс сканирования и распознавания печатного материала • В программе ABBYY FineReader имеется специальная кнопка Scan and Read, которая дает возможность произвести полную обработку текста: отсканировать. распознать. проверить. сохранить результаты распознавания.  После того, как вы нажмете на кнопку Scan and Read начнется процесс процесса сканирования и распознавания печатного материала, а результат распознавания отобразится в двух диалоговых окнах Текст и Изображение. В диалоговом окне Изображение вы увидите изображение отсканированного материала и выделенные блоки (участки изображения, выделенные в рамку; блок используется для распознавания и автоматического анализа части изображения).  В диалоговом окне Текст вы можете отредактировать распознанный текст вашего материала.  Кнопки на панели Scan and Read связаны с базовыми операциями системы, связанными со сканированием, распознаванием, проверкой и сохранением результатов распознавания. Цифры на этих кнопках указывают, в каком порядке необходимо выполнить действия с тем, чтобы получить электронную версию бумажного документа. Каждое из этих действий можно провести по отдельности или объединить в одно, нажав на кнопку Scan amp;Read, которая дает возможность провести полный цикл обработки текста в автоматическом режиме. Каждая из кнопок имеет несколько режимов работы. Нажав на стрелку справа от кнопки, вы сможете обратиться к ниспадающему меню и выбрать один из «ручных» режимов работы. Scan and Read Запустить специальный режим процесса сканирования и распознавания, во время которого OCR-система полностью контролирует ваши действия. Сканировать и распознать Запустить процесс процесса сканирования и распознавания документа. Сканировать и распознать несколько страниц Отсканировать и распознать несколько страниц в цикле. Открыть и распознать Открыть и распознать изображения, выбранные в диалоговом окне Открыть. 1-Сканировать Открыть изображение Добавить изображение в пакет, при этом копия изображения сохранится в папке пакета. Сканировать изображение Отсканировать изображение. Сканировать несколько страниц Отсканировать изображения в цикле. Для того, чтобы остановить сканирование, из меню Файл выберите команду Остановить сканирование. Опции Открывает закладку Сканирование/Открытие диалогового окна Опции, на которой вы имеете возможность задать опции процесса сканирования и параметры предварительной обработки документа. 2-Распознать Распознать — распознает открытую страницу пакета. Распознать все Распознать все нераспознанные страницы пакета. Опции Открыть закладку Распознавание диалогового окна Опции, на которой Вы можете установить параметры распознавания документа. З-Проверить Проверить Дает возможность найти в тексте слова, содержащие неуверенно распознанные символы. Опции Открыть закладку Проверка диалогового окна Опции, на которой вы имеете возможность установить опции проверки орфографии распознанного документа. 4-Сохранить Мастер сохранения результатов — открывает диалоговое окно Мастер сохранения результатов, в котором вы имеете возможность выбрать приложение для сохранения и установить опции сохранения. Сохранить текст в файл Сохранить распознанный текст в файл на диск. Передать страницы в Напрямую передать распознанный текст в выбранное приложение без сохранения его на диск. Совет: В процессе передачи распознанного текста с нескольких страниц пакета сначала выделите их в диалоговом окне Пакет. Передать все страницы в Передать все распознанные страницы в выбранное приложение без сохранения их на диск. Опции Открыть закладку Форматирование диалогового окна Опции, на которой вы имеете возможность установить опции сохранения документа. Глава 30. Сканирование многостраничных документов В программе ABBYY FineReader для удобства процесса сканирования большого количества страниц предусмотрен специальный режим процесса сканирования: Сканировать несколько страниц, который дает возможность в одном цикле отсканировать несколько страниц. • Кроме этого: при сканировании через TWAIN с использованием интерфейса FineReader по окончании процесса сканирования страницы сканирующее устройство автоматически начинает сканирование следующей страницы. при сканировании через пользовательский TWAIN-драйвер ваш «Twain-диалог» с программой не завершается: После того, как прекратится процесс сканирования первой страницы, можно просто положить следующую страницу в «лоток» и продолжить распознавание. В OCR-системе ABBYY FineReader вы имеете возможность отсканировать большое количество страниц двумя способами: • с использованием автоподатчика сканера. • без использования автоподатчика. Использование автоподатчика ADFИнтерфейс FineReader В диалоговом окне Настройки сканера (доступ: Сервис к Настройки сканера) активизируйте опцию Использовать автоподатчик бумаги ( ADF) и запустите сканирование нескольких страниц (доступ: Файл к Сканировать несколько страниц). Интерфейс TWAIN — драйвера сканера В собственном TWAIN-диалоге сканера активизируйте опцию Use ADF (опция может иметь другое название в зависимости от модели сканера) и запустите сканирование (доступ: Файл к Сканировать несколько страниц). Без использования автоподатчика ADFИнтерфейс FineReader Из меню Файл выберите команду Сканировать несколько страниц. Для удобства процесса сканирования нескольких страниц подряд на планшетном сканере без автоподатчика установите величину паузы (время от окончания процесса сканирования одной страницы до начала процесса сканирования следующей). Для этого в диалоговом окне Настройки сканера (доступ: Сервис к Настройки сканера) активизируйте опцию Пауза между страницами и установите значение паузы в секундах. В этом случае, после процесса сканирования первой страницы сканер делает указанную вами паузу, во время у вас должно хватить времени поместить в сканирующее устройство еще одну страницу. Далее сканирование продолжится уже в автоматическом режиме. Как «отдохнуть» Попробуйте в диалоговом окне Настройки сканера (доступ: Сервис к Настройки сканера) активизировать опцию Останавливаться между страницами. Тогда по окончании процесса сканирования текущей страницы появится диалоговое окно с вопросом относительно продолжения процесса сканирования. Нажмите на кнопку Да для процесса сканирования следующей страницы или Нет — для завершения процесса сканирования. Интерфейс TWAIN-драйвера сканера Из меню Файл выберите команду Сканировать несколько страниц. Для начала процесса сканирования в раскрывшемся TWAIN-диалоговом окне сканера просто нажмите на кнопку Scan (название кнопки зависит от конкретной реализации TWAIN-драйвера вашего сканера) а для продолжения процесса сканирования нажмите на кнопку Scan в twain-диалоге сканера. Для завершения процесса сканирования в Twain-диалоге сканера просто нажмите на кнопку Close (или аналогичную ей по смыслу). Совет:Для того, чтобы вы могли контролировать результаты процесса сканирования, на закладке Сканирование/Открытие (доступ: Сервис к Опции) активизируйте опцию Открывать изображения по мере процесса сканирования. В этом случае отсканированное изображение появится в диалоговом окне Изображение. В случае, если изображение отсканировано неверно, остановите сканирование (из меню Файл выберите команду Остановить сканирование) и отсканируйте изображение заново. Открытие файлов с изображениями В OCR-системе ABBYY FineReader в случае, если у вас вообще нет сканирующего устройства, вы имеете возможность распознавать графические файлы, которые содержат текстовую информацию. Как открыть изображение Нажмите стрелку справа от кнопки 1-Сканировать и из ниспадающего меню выберите команду Открыть изображение. В диалоговом окне Открыть выберите изображения. Все они появятся в пакете программы, а последнее из выбранных изображений откроется в диалоговом окне Изображение и в диалоговом окне Крупный план, при этом копия изображения будет автоматически помещена в папку пакета. Совет: В случае, если вы хотите, чтобы открытые изображения были сразу распознаны, воспользуйтесь режимом Открыть и распознать. Для этого из меню Процесс выберите команду Открыть и распознать (клавиатурный эквивалент: Ctrl + Shift + D) и в раскрывшемся диалоговом окне Открыть выберите изображения для дальнейшего распознавания. Как добавить в пакет изображения со сдвоенными страницами В омнифонтовой системе распознавания текстов ABBYY FineReader в процессе сканирования книг удобнее отсканировать две страницы (книжный разворот) сразу. Кроме этого для повышения качества распознавания такие изображения следует разделить на два для того, чтобы каждой странице соответствовала отдельная страница пакета, так как анализ и конечный результат распознавания в программе осуществляется для каждой страницы по отдельности. Для того, чтобы добавить в пакет сдвоенные страницы на закладке Сканирование/Открытие (доступ: Сервис к Опции) активизируйте опцию Делить разворот книги. Как проверить и скорректировать полученное изображение Распознаваемое изображение может быть сильно "замусорено. Это означает, что оно может содержать много лишних точек среднего или плохого качества, которые могут отрицательно сказаться на качестве распознанного текста. Для того, чтобы уменьшить количество лишних точек, можно воспользоваться опцией Очистить от мусора. Для этого просто из меню Изображение выберите команду Очистить изображение от мусора. В случае, если вы хотите очистить от «мусора» отдельный блок (участок изображения, выделенный в рамку), то из меню Изображение выберите команду Очистить блок от мусора. Важно: В случае, если исходный текст был очень светлым или в исходном тексте использовался очень тонкий шрифт, то применение функции Очистить изображение может привести к исчезновению точек, запятых или тонких элементов букв, что ухудшает качество распознавания. Важно: В случае, если вы сканируете или открываете «замусоренные» изображения, то перед тем, как поместить в пакет программы подобные изображения обратитесь к разделу Обработка изображений, который находится на закладке Сканирование/Открытие (доступ: Сервис к Опции) активизируйте опцию Очистить изображение от мусора. Как инвертировать изображение Некоторые сканеры переводят черный цвет в белый, а белый в черный. Для того, чтобы получить стандартное представление документа (черный шрифт на белом фоне из меню Изображение выберите команду Инвертировать. Важно: В случае, если вы открываете инвертированные изображения, то перед добавлением в пакет программы таких изображений в разделе Обработка изображений на закладке Сканирование/Открытие (доступ: Сервис к Опции) обязательно активизируйте опцию Инвертировать. Как повернуть или зеркально отразить изображение В процессе распознавания изображение должно иметь стандартную ориентацию: текст должен читаться сверху вниз, и строки должны быть горизонтальными. По умолчанию программа при распознавании определяет и корректирует ориентацию изображения автоматически. В случае, если ориентация изображения была определена ошибочно, то на закладке Сканирование/Открытие дезактивируйте опцию Определять ориентацию страницы (в процессе распознавания) и поверните изображение вручную. • Как повернуть изображение на 90 градусов вправо — выберите из меню Изображение команду Повернуть по часовой стрелке на 90 градусов влево — выберите из меню Изображение команду Повернуть против часовой стрелки. на 180 градусов — выберите из меню Изображение команду Повернуть на 180 градусов. • Вы можете отразить изображение относительно: горизонтальной прямой — выберите из меню Изображение команду Зеркальное отражение относительно горизонтали. вертикальной прямой — выберите из меню Изображение команду Зеркальное отражение относительно вертикали. Как удалить фрагмент изображения В случае, если вы хотите исключить какой-то участок текста из распознавания или у вас на изображении имеются большие участки мусора, то вы имеете возможность стереть его. Для этого: Выберите инструмент (на панели в диалоговом окне Изображение) и, нажав на левую кнопку мыши, выделите участок изображения, который вы хотите удалить. Отпустите кнопку, выделенная часть изображения будет удалена. Как изменить масштаб изображения На панели Изображение (в диалоговом окне Изображение) выберите инструмент и щелкните левой кнопкой мыши на изображении. Изображение увеличится/уменьшится в два раза. Нажмите правой кнопкой мыши на изображение и из меню выберите команду Масштаб и нужный вам масштаб. Как получить информацию об изображении • Вы имеете возможность получить следующую информацию об открытом изображении: ширину и высоту изображения в точках; вертикальное и горизонтальное разрешение в точках на дюйм (dpi); тип изображения. Нажмите правой кнопкой на изображение и из меню выберите команду Свойства. В раскрывшемся диалоговом окне выберите закладку Изображение. Отменить последнее действие Для отмены последнего действия на панели Стандартная просто нажмите на кнопку Отменить. Важно: Для повторного выполнения последнего отмененного действия на панели Стандартная просто нажмите на кнопку Вернуть. Нумерация страниц при добавлении в пакет По умолчанию каждой сканируемой странице присваивается номер на единицу больший номера последнего изображения в пакете. Вы имеете возможность задать номер добавляемой страницы и вручную (например, вам необходимо сохранить исходную нумерацию страниц или вы сканируете стопку сортированных по порядку страниц). Для этого активизируйте опцию Запрашивать номер страницы при добавлении в пакет на закладке Сканирование/Открытие (доступ:Сервис к Опции). В диалоговом окне Номер страницы укажите номер страницы, с которой начинается сканирование и выберите опцию Через одну в поле Нумерация страниц. Выберите способ нумерации страниц: по возрастанию или по убыванию. Возрастание или убывание зависит, например, от того, как вы кладете стопку в автоподатчик — находятся ли меньшие или большие номера наверху. Уменьшать разрешение цветного/серого изображения до 100 dpi Эта опция используется при добавлении в пакет цветных изображений большого размера. В этом случае, во-первых, пакет будет занимать меньше места на диске, а во-вторых, процесс обработки группы страниц будет происходить быстрее. Важно: Эта опция не влияет на качество распознавания текста. Данное уменьшение разрешения влияет на качество сохраняемых картинок: разрешение картинок уменьшается до 100 dpi. Как преобразовать цветное/серое изображение в черно-белое Отметьте эту опцию при сканировании через TWAIN-диалог сканера в сером режиме (с автоподбором яркости) или при сканировании в цвете, если при этом сканируемые документы не содержат цветных картинок, цветного шрифта и фона или же вам не требуется передача цвета в выходное изображение. В этом случае сохраняемые в пакет изображения будут занимать меньше места на диске. Как проанализировать макет страницы Прежде чем приступить к распознаванию, программа должна знать, какие участки изображения необходимо распознавать. Для этого проводится анализ макета страницы, во время которого выделяются блоки с текстом, картинки, таблицы и штрих-коды (для версии Office). Анализ макета страницы может проводиться как автоматически, так и вручную. В большинстве случаев FineReader сам успешно справляется с анализом сложных страниц. Автоматический анализ производится по кнопке 2-Распознать одновременно с распознаванием текста. Важно: Отдельная процедура анализа макета страницы тоже доступна (доступ: Процесс к Анализ макета страницы). Правда, при этом качество сегментации может быть ниже, так как при совместной процедуре распознавания и сегментации для анализа страницы используется дополнительная информация, полученная в процессе распознавания. Глава 31. Блоки Типы блоков в OCR — системе ABBYY FineReader Блоки — это заключенные в рамку участки изображения. Программой блоки выделяются для того с тем, чтобы указать OCR-системе, какие участки отсканированной страницы необходимо распознавать и в каком порядке. Кроме того по ним воспроизводится исходное оформление страницы. Блоки разных типов имеют различные цвета рамок. Вы имеете возможность изменить цвета рамок блоков на закладке Вид диалогового окна к Опции (доступ:Сервис к Опции) в разделе Объекты. В поле Объект выберите нужный тип блока, а в поле Цвет — требуемый цвет. Выделение блоков «вручную» может понадобиться, если: • Вы хотите распознать часть страницы. • В результате автоматического анализа блоки были выделены неправильно. Совет: В некоторых случаях качество автоматического анализа можно улучшить, правильно установив опции анализа макета. Проверьте установленные опции анализа (закладка Распознавание, меню Сервис к Опции). В случае, если программа выделила неправильно некоторые блоки, часто оказывается быстрее исправить только их, воспользовавшись инструментами для редактирования блоков, а не выделять блоки на изображении заново вручную. В процессе обработки изображений выделяют блоки следующих типов: Зона Распознавания Блок используется для распознавания и автоматического анализа части изображения. После нажатия на кнопку 2-Распознать выделенный блок автоматически анализируется и распознается. Текст Блок используется для обозначения текста. Он должен содержать только одноколоночный текст. В случае, если внутри текста содержатся картинки, выделите их в отдельные блоки. Таблица Блок используется для обозначения таблиц или текста, имеющего табличную структуру. В процессе распознавания программа разбивает данный блок на строки и столбцы и формирует табличную структуру. В выходном тексте данный блок передается таблицей. Вы имеете возможность выделить и скорректировать таблицу вручную. Картинка Этот блок используется для обозначения картинок. Он может содержать картинку или любую другую часть текста, которую вы хотите передать в распознанный текст в качестве картинки. Штрих-код (только в версии Office) Этот блок используется для распознавания штрих-кодов. Это означает, что, если ваш документ содержит штрих-код и вы хотите передать его не картинкой, а перевести его в последовательность букв и цифр, то выделите штрих-код в отдельный блок и присвойте ему тип Штрих-код. Важно: По умолчанию опция, позволяющая искать и распознавать штрих-коды отключена. Для того, чтобы подключить ее, активизируйте опцию Искать штрих-коды на закладке Распознавание (доступ: Сервис к Опции). Опции автоматического анализа макета страницы В процессе автоматического анализа макета страницы FineReader сам выделяет блоки, содержащие тексты, таблицы, картинки и штрих-коды. Автоматический анализ запускается по кнопке 2— Распознать одновременно с распознаванием текста. До запуска распознавания необходимо установить основные опции анализа: тип страницы и опции анализа таблиц. Для большинства изображений расположение текста на странице определяется автоматически, чему соответствует значение Авто на закладкеРаспознавание в разделе Тип страницы (доступ: Сервис к Опции), устанавливаемое системой по умолчанию. В некоторых случаях может потребоваться установить значение типа страницы вручную. Для этого на закладке Распознавание диалогового окна Опции (доступ: Сервис к Опции) в разделе Тип страницы выберите необходимую команду. Возможные типы страницыАвтоматическое определение Указывает, что расположение текста на странице определяется автоматически. Это значение устанавливается системой по умолчанию; подходит для распознавания всех видов текстов, в том числе многоколоночного текста, текста с таблицами и картинками. Одна колонка Указывает, что текст на странице напечатан в одну колонку. Эта опция используется в случае, если автоматическое определение ошибочно сегментировало страницу как многоколоночный текст. Форматированный пробелами текст Указывает, что текст на странице расположен в одну колонку и напечатан моноширинным шрифтом одного размера. В распознанном тексте сохраняется деление на строки; отступы от левого края передаются пробелами; каждая строка выделяется в отдельный параграф, и расстояния между параграфами передаются пустыми строками. Используется, например, для распознавания распечаток текстов программ. Опции для анализа таблиц В большинстве случаев программа делит таблицу на строки и столбцы автоматически. Дополнительная настройка опций анализа таблиц устанавливается на закладке Распознавание в разделе Таблицы. Эти опции рекомендуется использовать, если: • в результате автоматического анализа макета страницы таблица была выделена и разделена на строки и столбцы неверно; документ содержит много однотипных таблиц, для которых известна дополнительная информация (например: таблица не содержит объединенных ячеек или таблица состоит из ячеек, текст в которых расположен в одну строку). Выделение и редактирование блоков «вручную»Как создать новый блок • Выберите один из инструментов: выделить зону распознавания. выделить текстовый блок. • выделить картинку. • выделить табличный блок. Установите курсор мыши в угол предполагаемого блока. Нажмите левую кнопку мыши и, не отпуская кнопки, потяните в противоположный по диагонали угол. Теперь отпустите кнопку мыши. Выделенная часть изображения будет заключена в рамку. В OCR-системе ABBYY FineReader вы имеете возможность поменять тип блока (присвоить выделенному блоку один из существующих типов: Зона распознавания,Текст,Таблица,Картинка или Штрих-код). Для этого нажмите на блоке правой кнопкой мыши и из ниспадающего меню выберите Тип блока, а затем — необходимую команду. Редактирование формы и положения блоков пакетаКак передвинуть границу блока Установите курсор мыши на границу блока. Нажмите левую кнопку мыши и потяните в нужную сторону. Отпустите кнопку мыши. Важно: В случае, если вы установите курсор мыши на угол блока, то при движении мыши будут одновременно изменяться вертикальная и горизонтальная границы блока. Как добавить прямоугольную часть блока Выберите инструмент. Установите курсор мыши внутри блока, к которому вы хотите добавить часть. Нажмите левую кнопку мыши и, не отпуская кнопки, потяните по диагонали. Выделив нужную часть изображения, отпустите кнопку мыши. Выделенный прямоугольник будет добавлен к блоку. В случае, если необходимо, передвиньте границу блока. Как удалить прямоугольную часть блока Выберите инструмент. Установите курсор мыши внутри блока, там, где вы хотите вырезать часть. Нажмите левую кнопку мыши и, не отпуская кнопки, потяните по диагонали. Выделив нужную часть изображения, отпустите кнопку мыши. Выделенный прямоугольник будет удален из блока. В случае, если необходимо, передвиньте границу блока. Важно: В процессе удаления внутренней части блока снизу или сверху дополнительно удаляется часть блока справа до границы блока. Такая особенность программы обусловлена необходимостью передавать на распознавание неразрывные текстовые строки. В отношении боковых сторон блоков такого ограничения нет. Как выделить один или несколько блоков Выберите инструмент и нажмите мышкой на необходимом блоке или проведите указателем по выделяемым блокам при нажатой кнопке мыши. Важно: Вы имеете возможность выделить один или несколько блоков, используя стандартные инструменты создания блоков. Для того, чтобы выбрать несколько блоков подряд, нажмите клавишу Shift и мышью нажмите на требуемых блоках. Для того, чтобы отменить выделение уже выбранного блока или добавить невыделенные блоки, нажмите клавишу Ctrl и мышью нажмите на требуемых блоках. Как передвинуть блок Нажмите клавишу Alt и мышью переместите блоки. Как перенумеровать блоки Выберите инструмент. Нажмите на блоки в том порядке, в котором вы хотите видеть их содержимое в выходном тексте. Важно: В случае, если вы перенумеровываете блоки на уже распознанном изображении, то одновременно в диалоговом окне Текст происходит перегруппировка распознанного текста в соответствии с новой нумерацией. Как удалить блок Выберите инструмент и нажмите на блок, который вы хотите удалить. Важно: В случае, если вы удаляете блок с уже распознанного изображения, то одновременно с этим в диалоговом окне Текст удаляется текст, соответствующий этому блоку. Как удалить все блоки на изображении Из меню Сервис выберите команду Удалить блоки и текст. Важно: В случае, если вы удаляете блоки с уже распознанного изображения, то одновременно с этим в диалоговом окне Текст удаляется текст, соответствующий этим блокам. Редактирование таблицы • Для редактирования таблицы выберите на панели Изображение один из инструментов для того, чтобы: добавить вертикальную линию. добавить горизонтальную линию. чтобы удалить линию. Как объединить ячейки таблицы Из меню Правка выберите команду Объединить ячейки таблицы. Как разбить ранее объединенные ячейки таблицы Из меню Правка выберите команду Разбить ячейки таблицы. Как объединить строки таблицы (в этом случае деление на столбцы остается) Из меню Правка выберите команду Объединить строки таблицы. Ручной анализ таблицы Важно: В случае, если в результате автоматического анализа таблицы разделение на строки и столбцы произошло неверно, прежде чем анализировать таблицу вручную заново, попробуйте сначала скорректировать результаты автоматического анализа. Как скорректировать таблицу вручную Отредактируйте таблицу, используя инструменты (панель в диалоговом окне Изображение): • Добавить вертикальную линию • Добавить горизонтальную линию • Удалить линию В случае, если ячейка таблицы содержит только картинку, в диалоговом окне Свойства блока (доступ: Вид к Свойства) активизируйте опцию Считать ячейку таблицы картинкой. В случае, если же, помимо картинки в ячейке содержится некоторый текст, то выделите картинку в отдельный блок внутри ячейки. Как объединить ячейки или строки таблицы Из меню Правка выберите команды Объединить ячейки таблицы или Объединить строки таблицы. В процессе объединения строк таблицы деление на столбцы остается. Объединенные ячейки можно снова разделить, воспользовавшись командой Разбить ячейки таблицы (доступ:Правка). Важно: Для того, чтобы не рисовать вертикальные и горизонтальные линии с нуля в таблице, выделите таблицу в отдельный блок и нажмите правой кнопкой мыши на блоке. Из ниспадающего меню выберите команду Анализ структуры таблицы и посредством инструментов для работы с таблицами, скорректируйте полученные результаты. Использование шаблонов блоков В процессе работы с документами с одинаковым расположением текста и картинок, такими, например, как формы, бланки, вместо того с тем, чтобы анализировать макет каждой страницы, вы имеете возможность провести анализ одной из них, сохранить расположение блоков на этой странице в файл, а затем, когда потребуется, «спроецировать» эти блоки на изображение (или группу изображений) со сходным расположением текста. Как создать шаблон блоков Откройте изображение и выделите на нем блоки автоматически или вручную. Из меню Изображение выберите команду Сохранить блоки… В раскрывшемся диалоговом окне укажите имя для шаблона блоков. Как наложить шаблон блоков В диалоговом окне Пакет выделите страницы, на которые вы хотите наложить существующий шаблон. Из меню Изображение выберите команду Наложить блоки. В раскрывшемся диалоговом окне Открыть файл с блоками выберите файл (*.blk) с нужным вам расположением блоков. В диалоговом окне Открыть файл с блоками в разделе Применить к активизируйте один из переключателей: • Всем страницам (если вы хотите наложить шаблон на все страницы пакета). • Выделенным страницам (если вы хотите наложить шаблон только на выделенные страницы). Нажмите на кнопку Открыть. Глава 32. Распознавание Задача распознавания состоит в том с тем, чтобы преобразовать отсканированное изображение в текст, сохранив при этом оформление страницы. Прежде чем приступить к распознаванию текста, необходимо установить основные параметры распознавания: язык распознавания, тип печати распознанного текста и тип страницы. Важно: Перед запуском распознавания проверьте установленные опции: язык распознавания, тип печати распознаваемого текста и тип страницы. Вы имеете возможность: • Распознать блок или несколько блоков, выделенных на изображении. • Распознать открытую страницу или все страницы, выделенные в диалоговом окне Пакет. • Распознать все нераспознанные страницы пакета. • Распознать все страницы в фоновом режиме. В этом режиме возможно распознавание с одновременным редактированием уже распознанных страниц. • Распознать страницы в режиме распознавание с обучением. Данный режим используется в основном для распознавания текстов, использующих декоративные шрифты, или распознавания большого объема (более 100 страниц) документов плохого качества печати. • Распознать страницы одного пакета на нескольких компьютерах одновременно. Запуск распознавания Нажмите на кнопку 2-Распознать на панели Scan and Read. Из меню Процесс выберите необходимую команду: • Распознать — чтобы распознать открытую страницу или все страницы, выделенные в диалоговом окне Пакет; • Распознать все — чтобы распознать все нераспознанные страницы пакета; • Распознать Блок — чтобы распознать блок или несколько блоков, выделенных на изображении; • Запустить фоновое распознавание — чтобы запустить распознавание в фоновом режиме. Кнопка 2-Распознать запускает распознавание открытого изображения. Для того, чтобы изменить режим кнопки, нажмите на стрелку справа от нее и из открывшегося меню выберите необходимую команду. Важно: В процессе распознавания уже распознанной страницы перераспознаются только отредактированные и добавленные блоки. Язык распознавания FineReader поддерживает распознавание как одноязычных, так и многоязычных (например, английско-французских) документов. Для того, чтобы указать язык распознаваемого текста, выберите соответствующую строку в списке на панели Распознавание. В случае, если вы хотите распознать документ, написанный на нескольких языках: В списке языков на панели Стандартная выберите команду Выбор нескольких языков… в раскрывшемся диалоговом окне Язык распознаваемого текста укажите несколько языков. Для этого активизируйте опции с соответствующими названиями языков. Важно: В случае, если вы часто используете какую-либо комбинацию языков, то создайте новую группу, содержащую эти языки (возможно только в версии FineReader Office). Важно: Увеличение количества подключенных к распознаванию одного документа языков может привести к ухудшению качества распознавания. Не рекомендуется подключать более 2-3 языков. Перед запуском распознавания проверьте подключенные на закладке Форматирование шрифты: они должны содержать все символы языка распознавания. В противном случае распознанный текст будет неправильно отображен в диалоговом окне Текст (в словах на месте некоторых букв стоят значки "?"). В случае, если необходимый язык отсутствует в списке, то возможны следующие варианты: • Данный язык не поддерживается системой FineReader. • Язык исключен из списка языков отображаемых на панели Стандартная. В этом случае в списке языков на панели Стандартная выберите команду Выбор из полного списка языков и в раскрывшемся диалоговом окне Язык распознаваемого текста укажите необходимый язык. • Язык не был установлен (была выбрана минимальная установка) или был отключен при выборочной установке. Для того, чтобы доустановить языки распознавания, запустите программу инсталляции FineReader в режиме покомпонентной установки (Установка дистрибутива по выбору), дезактивируйте все опции, за исключением опции Языки распознавания, и просто нажмите на кнопку Состав. В раскрывшемся списке языков укажите требуемые языки. Важно: В процессе установке проверьте, что вы указали ту же папку, в которую вы ранее установили ABBYY FineReader. Как подключить язык к списку отображаемых языков В диалоговом окне Редактор языков (доступ: Сервис к Редактор языков) выберите язык, который вы хотите подключить, и дезактивируйте опцию Показывать в списке языков. Важно: Вы имеете возможность установить язык распознавания на отдельный блок. Для этого нажмите правой кнопкой мыши на блоке, для которого вы хотите установить язык распознавания, отличный от языка распознавания для всего текста, и из меню выберите команду Свойства. В раскрывшемся диалоговом окне Свойства на закладке Блок в поле Язык распознавания выберите язык распознавания выделенного блока. Тип печати входного текста Для большинства текстов тип печати определяется автоматически. Этому соответствует значение Авто (доступ: раздел Тип печати, меню Сервис к Опции, закладка Распознавание). В процессе распознавания текстов, напечатанных на матричном принтере в черновом режиме или на пишущей машинке, можно добиться более высокого качества распознавания, установив правильный Тип печати: для текстов, набранных на пишущей машинке — значение Пишущая машинка. для текстов, напечатанных на матричном принтере — значение Матричный принтер. Как поменять тип печати На закладке Распознавание диалогового окна Опции (доступ: Сервис к Опции) из раздела Тип печати выберите нужную опцию. Важно: После распознавания текстов, набранных на пишущей машинке или матричном принтере, не забудьте снова выбрать значение Авто при возвращении к типографскому тексту. Другие опции распознавания Показывать или не показывать изображение при распознавании Распознавание группы страниц происходит быстрее, если обрабатываемое изображение не отображается. На закладке Общие (доступ: Сервис к Общие) дезактивируйте опцию Показывать изображение при распознавании. Инвертировать блок Для того, чтобы распознать инвертированные участки изображений (текстовый блок, ячейки таблицы или всю таблицу целиком) нажмите правой кнопкой мыши на инвертированном блоке и из меню выберите команду Свойства. В раскрывшемся диалоговом окне Свойства блока активизируйте опцию Инвертированный. Распознавание в фоновом режиме В случае, если вы хотите одновременно с распознаванием редактировать распознанные страницы, вы имеете возможность запустить распознавание в фоновом режиме: из меню Процесс выберите команду Запустить фоновое распознавание. В строке состояния появится значок. В случае, если для диалогового окна Пакет вами выбран режим показа свойства страниц (доступ: Вид к Вид со свойствами), то напротив распознаваемой страницы в колонке Открыта появится специальный значок. В этом режиме распозна вание автоматически возобновляется, как только в пакете появляются нераспознанные страницы. Как остановить распознавание в фоновом режиме Из меню Процесс выберите команду Остановить фоновое распознавание. Важно: В программе abbyy finereader в режиме Распознавание в фоновом режиме используются опции, установленные в программе до запуска фонового распознавания. Глава 33. Как обучить FineReader Распознавание с обучением • В программе ABBYY FineReader тексты хорошего и среднего качества, а также шрифты обычного начертания распознаются без предварительного обучения. Поэтому OCR-система может работать в режиме Распознавание с обучением, который позволяет вводить тексты разного качества, набранные практически любыми шрифтами. В режиме Распознавание с обучением вы можете: распознавания текстов, использующих декоративные шрифты; распознавания текстов, в котором встречаются специальные символы (например, отдельные математические символы); распознавания большого объема (более 100 страниц) текста плохого качества. В других случаях Распознавание с обучением использовать не рекомендуется, так как затраты на обучение будут больше, чем полученный выигрыш в качестве распознавания. Обучение проводится при распознавании одной-двух страниц текста в специальном режиме. В результате создается эталон букв, встречающихся в тексте. Этот эталон в дальнейшем используется при распознавании основного объема текста. Некоторые пары или тройки символов в тексте могут склеиваться. В случае, если при обучении вам не удается переместить описывающий прямоугольник так, чтобы он заключал в себя один целый символ и не содержал при этом части соседних, то вы имеете возможность обучить программу сочетанию символов, которые невозможно «расклеить». Такие неразделяемые сочетания двух или трех символов называются лигатурами. Важно: Созданный эталон можно использовать только для распознавания текстов, использующих тот же шрифт и размер шрифта и отсканированных с тем же разрешением, как и документ, на котором данный эталон создавался. В процессе удаления пакета эталон также удаляется. Вы имеете возможность сохранить созданный эталон для работы с другими пакетами. Для этого сохраните настройки пакета в формате шаблона пакета (*.fbt). В процессе перехода к распознаванию текстов, набранных другим шрифтом, не забудьте отключить эталон (Сервис к Опции к Распознавание) активизируйте переключатель Не использовать пользовательский эталон. Как начать распознавать с обучением Установите режим Распознавание с обучением (на закладке Распознавание, меню Сервис к Опции в разделе Распознавание с обучением активизируйте переключатель Распознавание с обучением). В строке состояния появится название эталона (по умолчанию default). Нажмите на кнопку 2-Распознать. Обучите эталон, распознав одну-две страницы в режиме распознавание с обучением. Обучаемые символы заносятся в эталон, создаваемый системой по умолчанию. По окончании обучения OCR-система сохранит созданный эталон (default.ptn) в папке, где хранится пакет. Отредактируйте эталон. Отмените режим Распознавание с обучением (на закладке Распознавание в разделе Обучение установите переключатель Распознавание с пользовательским эталоном). Запустите распознавание основного текста, нажав на кнопку 2-Распознать. Важно: Для того, чтобы создать несколько эталонов на один пакет, воспользуйтесь диалогом Редактор эталонов (доступ:Сервис к Редактор эталонов). Создайте новый эталон (нажмите в диалоговом окне на кнопку Новый) и выберите его для работы (нажмите на кнопку Выбрать). Далее работа с созданным эталоном происходит так же, как и работа с default-эталоном. В случае, если в процессе обучения было создано несколько эталонов, то подключается последний созданный эталон. Название подключенного эталона пишется в строке состояния. Для того, чтобы подключить другой эталон для распознавания, в диалоговом окне Редактор эталонов (доступ: Сервис к Редактор эталонов) в списке эталонов выберите эталон и просто нажмите на кнопку Выбрать. На закладке Распознавание в разделе Обучение активизируйте переключатель Распознавание с пользовательским эталоном. В случае, если на закладке Распознавание активизирована опция Использовать встроенные эталоны, то в режиме Распознавание с обучением программа предложит вам обучить только неуверенно распознанные символы. В случае, если вы обучаете программу декоративным или нестандартным шрифтам и при этом используете встроенные эталоны, то OCR-система может распознать часть символов неправильно, не предложив их обучить. В этом случае дезактивируйте опцию Использовать встроенные эталоны. Как обучить эталон Перед обучением обратитесь к закладке Распознавание (доступ: Сервис к Опции) и в разделе Распознавание с обучением активизируйте опцию Распознавание с обучением. Нажмите на кнопку 2-Распознать. Программа начнет распознавание. Как только встретится символ, подлежащий обучению, откроется диалоговое окно Ручное обучение эталона с изображением этого символа. Как обучить символ Описывающий прямоугольник в верхней части диалогового окна должен содержать один целый символ. В случае, если он содержит часть буквы или более одной буквы, то посредством мыши или кнопок и прямоугольник можно передвинуть так с тем, чтобы он охватывал одну целую букву. Далее введите нужный символ и просто нажмите на кнопку Обучить. Важно: Обучать можно только символам, входящим в алфавит языка. В случае, если вы обучаете программу символам, которые нельзя ввести с клавиатуры, то для их обозначения можно использовать комбинацию из двух символов или вы имеете возможность скопировать требуемый символ из Таблицы символов (открывается при нажатии в диалоговом окне Ручное обучение эталона кнопки). В случае, если в обучаемом тексте встречаются слова, набранные курсивом или полужирным, и вам важно сохранить гарнитуру шрифта в распознанном тексте, то при обучении таким символам в диалоговом окне Ручное обучение эталона активизируйте опции Курсив или Полужирный. В процессе обучения следите за тем с тем, чтобы изображениям заглавных букв соответствовали заглавные буквы, а изображениям строчных букв — строчные. В случае, если при обучении вы ошиблись, то можно нажать кнопку Вернуться, и охватывающий прямоугольник вернется на предыдущую позицию, а последняя обученная пара «изображение — символ» будет удалена из эталона. Кнопка Вернуться действует в пределах одного слова. Обучение лигатурам Лигатуры — это сочетания двух или трех символов, которые из-за особенностей их начертания невозможно разделить при обучении и которые поэтому сразу обучаются как комбинация символов. Обучение лигатурам происходит так же, как и обучение отдельным символам. В строке для ввода символа введите необходимое сочетание символов и просто нажмите на кнопку Обучить. Описывающий прямоугольник в верхней части диалогового окна должен содержать сочетание целиком. Передвинуть прямоугольник можно посредством мыши. В одном эталоне может содержаться до 1000 новых символов. Кроме этого помните, что, не следует создавать слишком много лигатур, так как это может отрицательно сказаться на качестве распознавания. В процессе обучения необходимо учитывать следующие ограничения: • Изображения некоторых символов не различаются системой распознавания и сопоставляются с каким-то одним символом. К примеру, прямой ('), левый (') и правый (') апострофы хранятся в эталоне как изображение прямого апострофа. Таким образом, в результате распознавания в тексте никогда не появится правый или левый апостроф, хотя при обучении вы указывали именно эти символы. • Для некоторых изображений решение относительно того, какому символу в распознанном тексте его сопоставить, принимается на основе общего анализа распознанного текста. Так, например, решение относительно того, является ли символ, обозначаемый «кружком», буквой "о" или цифрой ноль, OCR-система принимает в зависимости от того, находятся ли рядом другие цифры или буквы. Редактирование эталона Прежде чем запускать распознавание с только что созданным эталоном, рекомендуется просмотреть эталон и, если потребуется, скорректировать. Этим вы сведете к минимуму ошибки распознавания, которые могут возникнуть из-за неправильно обученного эталона. Эталон должен содержать только целые символы или лигатуры. Символы, обрезанные с краев, и символы с неправильными подписями следует удалить из эталона. Как скорректировать эталон Из меню Сервис выберите команду Редактор эталонов. В раскрывшемся диалоговом окне Редактор эталонов выберите нужный эталон и просто нажмите на кнопку Редактировать. Перед вами откроется диалоговое окно Символы пользовательского эталона. Выбрав символ, просто нажмите на кнопку Свойства с тем, чтобы скорректировать подпись и указать правильное начертание: курсив, полужирный, верхний или нижний индексы, или просто нажмите на кнопку Удалить с тем, чтобы удалить неправильно обученные символы. Пользовательские языки и группы языков (возможно в версии FineReaderOffice) Вы имеете возможность использовать не только предопределенные языки и группы, но и создать новый язык или объединить существующие языки в новую группу и при распознавании подключить именно их. Когда необходимо создавать новый язык? Для подключения пользовательского словаря К примеру, необходимо распознать русский текст, содержащий аббревиатуры. Вы имеете возможность создать словарь аббревиатур и подключить его к пользовательскому языку. На основе русского языка с подключенным системным словарем и языка, созданного вами с подключенным словарем аббревиатур, вы имеете возможность создать группу для дальнейшего ее использования при распознавании ваших текстов. Для распознавания документов специального вида Например, страница содержит перечень артикулов, состоящий из цифр и нескольких букв. Вы имеете возможность создать новый язык, включив в него минимально необходимый набор символов, и использовать его для распознавания данного типа документов. Документ использует только заглавные буквы английского языка В этом случае для повышения качества распознавания следует исключить из распознавания символы, которые заведомо не могут встретиться в тексте, в данном случае — все строчные буквы. Когда необходимо создавать группу языков? В случае, если вы часто используете какую-нибудь комбинацию языков. Создать язык или группу языков можно из диалогового окна Редактор языков (доступ: Сервис к Редактор языков). Создание нового языка Из меню Сервис выберите команду Редактор языков… Нажмите на кнопку Новый. В раскрывшемся диалоговом окне активизируйте переключатель Создать копию языка и выберите язык, на основе которого вы создаете новый. Перед вами откроется диалоговое окно Свойства языка. В процессе создания нового языка необходимо задать следующие параметры (все параметры задаются в диалоговом окне Свойства языка): • Имя нового языка. • В поле Алфавит языка указан алфавит языка, на основе которого вы создаете новый язык. В случае, если требуется, отредактируйте алфавит. • Словарь, который будет использоваться системой при распознавании и проверке распознанного текста. Возможны следующие варианты: • Нет (не подключать словарь к языку). • Встроенный словарь (используется словарь, поставляемый с программой). • Пользовательский словарь. Для того, чтобы наполнить словарь или подключить старый пользовательский словарь или текстовый файл в Windows-кодировке (слова должны быть разделены пробелами или другими символам, не включенными в алфавит), просто нажмите на кнопку Редактировать. Важно: Словарные слова пользовательского языка считаются правильными, если в тексте они встретились с той капитализацией, в которой они заданы в словаре, а также в каком-либо стандартном виде: всеми маленькими, всеми большими буквами или с большой буквы. • Вид слова в словаре. Допустимые варианты написания слова в тексте: • abc abc, Abe, ABC • Abc abc, Abc, ABC • ABC abc, Abc, ABC • aBc aBc, abc, Abc, ABC • Регулярное выражение (задается грамматика нового языка). Важно: Нажав в диалоговом окне Свойства языков на кнопку Дополнительно, вы имеете возможность указать дополнительные свойства нового языка, например, игнорируемые внутри слова символы или исключенные из распознавания символы. Как создать новую группу языка Важно: Эта возможность имеется только в версии FineReader Office. В случае, если при распознавании текстов вы часто используете некоторое сочетание языков, то вы имеете возможность создать группу, в которую объединены эти языки. Созданная группа появится в списке языков на панели Стандартная. Важно: Вы имеете возможность указать комбинацию языков непосредственно в списке языков на панели Стандартная. Для этого выберите в списке строку Выбор нескольких языков. В раскрывшемся диалоговом окне Язык распознаваемого текста активизируйте необходимые языки. Как создать группу языков для распознавания Из меню Сервис выберите команду Редактор языков и просто нажмите на кнопку Новый. В раскрывшемся диалоговом окне выберите команду Создать новую группу. Перед вами откроется диалоговое окно Свойства группы языков. Здесь вам необходимо задать для новой группы языков (все параметры устанавливаются в диалоговом окне Свойства группы) Имя группы и Подключенные языки. Важно: Вы имеете возможность указать символы, которые заведомо не встречаются в распознаваемом документе. Указание таких символов может существенно увеличить скорость и надежность распознавания. Для этого в диалоговом окне Свойства группы языков просто нажмите на кнопку Дополнительно и в диалоговом окне Дополнительные свойства новой группы активизируйте соответствующие символы. Глава 34. Как проверить и отредактировать распознанный текст После завершения распознавания результат появляется в диалоговом окне Текст. Диалоговое окно Текст — это встроенный редактор программы FineReader; в нем вы имеете возможность проверить результаты распознавания и скорректировать распознанный текст. Одна из возможностей текстового редактора FineReader — это встроенная проверка орфографии. Система встроенной проверки орфографии дает возможность: • Находить неуверенно распознанные слова (слова, в которых имеется неуверенно распознанные символы). • Находить орфографические ошибки (неправильно написанные слова). • Добавлять неизвестные системе FineReader слова в словарь для того, чтобы они распознавались уверенно. Неуверенно распознанные символы и слова, которые отсутствуют в словаре, выделяются различными цветами. По умолчанию для выделения неуверенно распознанных символов используется голубой, для несловарных слов — розовый. Для того, чтобы изменить цвета на закладке Вид (доступ: Сервис к Опции) в поле Объект выберите команду Неуверенно распознанный символ (Несловарное слово) и в поле Цвет — цвет подсветки. Как проверить результаты распознавания Нажмите на кнопку З-Проверить на панели Scan amp;Read (или выберите командуПроверка из меню Сервис). Проверка дает возможность найти в тексте слова, содержащие неуверенно распознанные символы, несловарные слова, а также слова с орфографическими ошибками (клавиатурный эквивалент: F7). Откроется диалоговое окно Проверка. В диалоговом окне Проверка имеется три окна. Верхнее диалоговое окно — аналог окна Крупный план, в котором отображено изображение слова с возможной ошибкой. Среднее диалоговое окно показывает само слово с возможной ошибкой, в строке над этим диалоговым окном выводится название типа ошибки. В нижнем диалоговом окне Варианты предлагаются варианты замены данного слова, для которых используется словарь, активизированный вами в списке Язык словаря. Важно: Для удобства проверки и редактирования текста диалоговое окно Проверка может быть увеличено. Для этого достаточно поместить указатель мыши на границу диалогового окна (указатель превратится в двустороннюю стрелку). Перетаскивая границу, увеличьте или уменьшите размеры диалогового окна. У вас имеется следующие возможности: • Нажмите на кнопку Пропустить с тем, чтобы оставить слово, как есть. • Нажмите кнопку Пропустить все с тем, чтобы оставить все такие слова в распознанном тексте, как есть. Выберите вариант для замены и просто нажмите на кнопку Заменить или Заменить все с тем, чтобы заменить текущее слово или все такие слова в тексте. В случае, если в диалоговом окне Варианты отсутствует правильный вариант для замены слова, скорректируйте его в среднем диалоговом окне и для того с тем, чтобы заменить текущее слово просто нажмите на кнопку Подтвердить. Нажмите на кнопку Добавить, для того чтобы добавить слово в словарь. В этом случае при дальнейшей проверке орфографии, если это слово (или одна из его форм) встретится в тексте, оно не будет считаться ошибочным. Нажмите на кнопку Опции с тем, чтобы установить опции проверки распознанного текста. Нажмите Закрыть с тем, чтобы закрыть диалоговое окно. Опции проверки и редактирования текста Устанавливаются на закладке Проверка (доступ: Сервис к Опции). Уровень выделения ошибок В списке Уровень выделения ошибок возможно выбрать следующие значения: • Нет — ошибки распознавания не выделяются. • Стандартный — цветом выделяются нераспознанные и неуверенно распознанные символы. • Максимальный — помимо нераспознанных и неуверенно распознанных символов, цветом выделяются слова, которые отсутствуют в словаре языка распознавания. Важно: Количество отображаемых в диалоговом окне Текст ошибок будет изменено после повторного распознавания документа. • Останавливаться на неуверенно распознанных словах — система при проверке орфографии останавливается на словах, в которых были неуверенно распознаны какие-либо буквы. • Останавливаться на несловарных словах — эта опция позволит вам проверить слова, которые отсутствуют в словаре и которые могли быть неверно распознаны системой. • Останавливаться на сложных словах — в процессе проверки орфографии OCR-система останавливается на словах, которые отсутствуют в словаре, но которые могут быть построены по имеющимся морфологическим моделям или которые могут быть составлены из имеющихся в словаре слов. • Игнорировать слова с цифрами и другими неалфавитными символами — в процессе проверки орфографии слова, внутри которых встречаются цифры или какие-либо другие символы, не входящие в алфавит языка распознавания, не считаются ошибочными, если эти слова не содержат неуверенно распознанные символы. • Корректировать пробелы до и после знаков препинания — в случае, если эта опция активизирована, то ocr-система не будет останавливаться на тех фрагментах, где неверно расставлены пробелы до и после знаков препинания, а исправит их автоматически. Пополнение и удаление слов из пользовательского словаряДобавление слова в пользовательский словарь Добавление слов в словарь — один из способов повышения качества распознавания, так как при распознавании OCR-система проверяет слова по словарю. В словарь имеет смысл добавлять часто встречающиеся слова (например, термины, сокращения, названия). В тот момент, когда происходит добавление слова OCR-система строит его так называемую парадигму (совокупность всех форм данного слова). Это означает, что OCR-система может уверенно распознавать не только ту форму, которая уже однажды встретилась в тексте и была добавлена в словарь, но и все формы добавленного слова. Как добавить слово в словарь во время проверки орфографии Нажмите на кнопку Добавить в диалоговом окне Проверка. В диалоговом окне Начальная форма вы должны установить следующие параметры: • Часть речи (Существительное, Прилагательное, Глагол, Неизменяемое слово). • В случае, если слово всегда пишется с большой буквы, активизируйте опцию Имя собственное. • В случае, если вы добавляете слово, являющееся сокращением, активизируйте опцию Аббревиатура. Начальная форма слова — нажмите ОК. Откроется диалоговое окно Построение парадигмы, в котором пользователю предлагаются вопросы, по ответам на которые строится парадигма слова. Для ответов на вопросы нажимайте кнопки Да или Нет. В случае, если вы ошиблись при ответе на вопрос, просто нажмите на кнопку Сначала с тем, чтобы иметь возможность ответить на этот вопрос по-другому. OCR-система покажет построенную парадигму в диалоговом окне Парадигма. Важно: В случае, если вы хотите с тем, чтобы при добавлении слова в английский словарь парадигма не строилась (слово добавлялось бы как неизменяемое), то на закладке Проверка (доступ: Сервис к Опции) активизируйте опцию Добавлять слово как неизменяемое. Вы имеете возможность добавлять слова во время просмотра списка добавленных слов. Для этого из меню Сервис выберите команду Просмотр словарей. В раскрывшемся диалоговом окне Выбор словаря выберите язык и просто нажмите на кнопку Просмотр. Откроется словарь со списком добавленных слов. Вы имеете возможность, нажав на кнопку Добавить, добавить набранное слово. В случае, если добавляемое слово уже имеется в словаре, OCR-система предупредит вас об этом. В этом случае вы имеете возможность посмотреть его парадигму. В случае, если существующая парадигма вас не устраивает, имеете возможность создать другую (кнопка Добавить в диалоговом окне Добавить слово). Вы имеете возможность импортировать пользовательские словари от FineReader ранних версий. Вы имеете возможность импортировать пользовательский словарь (*.dic), который вы создали при работе с программой Microsoft Word. Как импортировать словарь Из меню Сервис выберите команду Просмотр словарей. Далее выберите язык словаря и просто нажмите на кнопку Просмотр. В раскрывшемся диалоговом окне Словарь просто нажмите на кнопку Импорт и выберите файлы с расширениями (*.ext, *.txt или *.dic). Как удалить слово из словаря Из меню Сервис выберите команду Просмотр словарей. Выберите язык словаря и просто нажмите на кнопку Просмотр. В раскрывшемся диалоговом окне выделите слово и просто нажмите на кнопку Удалить. Глава 35. Редактирование текста Важно: В случае, если символы в текстовом диалоговом окне FineReader отображаются некорректно (в словах на месте некоторых букв стоят значки "?"), это означает, что шрифты, выбранные на закладке Форматирование, не содержат всех символов, входящих в распознаваемый язык. Установите шрифт (раздел Шрифты, меню Сервис к Опции, закладка Форматирование), поддерживающий все символы языка документа, и перераспознайте документ. Распознанный текст выводится в диалоговое окно Текст. Текстовый редактор программы не отображает исходное оформление документа: • Деление на строки сохраняется • Распознанный текст, картинки, таблицы располагаются подряд в порядке номеров блоков. Содержимое блоков разделяется пунктирной линией. В процессе сохранения текста в приложение, оформление документа сохраняется в соответствии с опциями форматирования, устанавливаемыми на закладке Форматирование в диалоговом окне Форматы. Неуверенно распознанные символы выделяются цветом. Вы имеете возможность отменить выделение слов с неуверенно распознанными символами: на закладке Вид (доступ: Сервис к Опции) дезактивируйте опцию Выделять неуверенно распознанные символы. Для более удобного просмотра документа в диалоговом окне Текст вы имеете возможность установить черновой режим редактора. В черновом режиме редактора не отображаются картинки; левый отступ; выравнивание параграфа (все параграфы прижаты к левому краю); цвет и фон символов; для отображения текста используется шрифт одного размера (по умолчанию 12 пунктов). Кроме этого сохраняется шрифт и форматирование текста: полужирный, курсив, подчеркнутый, верхние и нижние индексы. Переход из одного режима в другой осуществляется нажатием на панели Форматирование. В случае, если кнопка нажата, то форматирование отображается, в противном случае — текст отображается в черновом режиме. Вы имеете возможность поменять установленный по умолчанию размер шрифта для отображения в черновом режиме. Для этого: • Из меню Сервис выберите команду Опции. • На закладке Вид укажите нужный размер шрифта в поле данных Размер шрифта в черновом режиме. Редактор системы FineReader предоставляет следующие возможности по редактированию текста: • Копирование, перемещение, удаление выделенных фрагментов текста • Поиск и замена указанного фрагмента текста • Изменение начертания шрифта • Отмена и восстановление действий • Копирование, перемещение, удаление выделенных фрагментов текста Перед применением команд копирования, перемещения или удаления выделите нужный фрагмент текста. Для того, чтобы скопировать выделенный текст нажмите на кнопку Копировать на инструментальной панели Стандартная. Из ниспадающего меню выберите команду Копировать. Нажмите клавиши Ctrl + C. Как переместить фрагмент текста Нажмите на кнопку Вырезать на инструментальной панели Стандартная или из меню Правка выберите команду Вырезать (клавиатурный эквивалент: Ctrl + X). Как поместить скопированный (вырезанный) текст Нажмите на кнопку Вставить на инструментальной панели Стандартная или меню Правка выберите команду Вставить (Ctrl + V). Поиск и замена указанного фрагмента текста Как найти определенный фрагмент в редактируемом тексте Для этого из меню Правка выберите команду Найти (Клавиатурный эквивалент: Ctrl + F). В раскрывшемся диалоговом окне Поиск в строке Найти укажите, что вы хотите найти, и установите параметры поиска. Важно: Для того, чтобы повторить поиск того же слова с теми же параметрами, нажмите клавишу F3. Для того, чтобы найти и заменить определенный фрагмент в редактируемом тексте проделайте одну из следующих операций: • Из меню Правка выберите команду Заменить. • Нажмите клавиши Ctrl+H. • В раскрывшемся диалоговом окне Заменить в строке Найти укажите, что вы хотите найти, в строке Заменить на укажите, на что вы хотите заменить найденное слово, и установите параметры поиска. Как изменить начертания шрифта Установите курсор на слово, которое вы хотите изменить, или выделите участок текста, для которого вы хотите изменить шрифт. Нажмите правой кнопкой мыши в диалоговом окне Текст и из меню выберите команду Шрифт. Из раскрывшегося диалогового окна Шрифт выберите название шрифта и установите его параметры. Клавиатурные эквиваленты: Ctrl + B полужирный, Ctrl + I — курсив, Ctrl + U подчеркивание. Важно: Устанавливаемые в диалоговом окне Шрифты межсимвольный интервал, масштаб символов, а также форматирование текста малыми прописными (отображение всех строчных букв в выделенном тексте как прописных букв уменьшенного размера) не отображаются в диалоговом окне Текст. Вы увидите эти изменения при сохранении документа в формате приложений, поддерживающих указанные типы форматирования текста. Отмена и восстановление действийКак отменить совершенное действие Нажмите на кнопку Отменить на инструментальной панели Стандартная или из меню Правка выберите команду Отменить (Ctrl + Z). Как восстановить отмененное действие Нажмите на кнопку Восстановить на инструментальной панели Стандартная или из меню Правка выберите команду Восстановить (клавиатурный эквивалент: Ctrl + Y). Глава 36. Редактирование таблиц В процессе редактирования таблицы вы имеете возможность: • Объединить содержимое ячеек или строк • Разбить содержимое ячеек • Разбить содержимое строки (столбца) • Удалить содержимое ячейки Как объединить содержимое ячеек или строк Удерживая клавишу Ctrl, выделите на изображении ячейки или строки, которые вы хотите объединить. Из меню Правка выберите команду Объединить ячейки таблицы или Объединить строки таблицы. Как разбить содержимое ячеек Из меню Правка выберите команду Разбить ячейки таблицы. Важно: Команда применяется только к ранее объединенным ячейкам таблицы. Как разбить содержимое строки или столбца На панели Изображение выберите инструмент Линия. Вставьте горизонтальную/вертикальную линию в строку/столбец таблицы, содержимое которых вы хотите разделить. Важно: Воспользовавшись инструментом или командой меню Объединить строки таблицы (доступ: Правка) вы имеете возможность объединить содержимое строк (столбцов). Как удалить содержимое ячейки В диалоговом окне Текст выделите ячейку (или несколько ячеек), содержимое которой вы хотите удалить, и нажмите клавишу Del. Глава 37. Экспорт результатов распознавания во внешние приложения Результаты распознавания можно сохранить в файл, передать во внешнее приложение, не сохраняя на диск, скопировать в буфер обмена или отправить по электронной почте. Сохранить можно все страницы или только выбранные. В программе ABBYY FineReader вы имеете возможность: • Сохранить распознанный текст, используя Мастер сохранения результатов. • Сохранить открытую или выделенные в диалоговом окне Пакет страницы в файл или во внешнее приложение. • Сохранить все страницы пакета в файл или во внешнее приложение. • Сохранить изображение страницы. • Передать результаты распознавания в выбранное приложение или сохранить их в файл. Внешний вид иконки меняется в зависимости от выбранного режима сохранения; подпись Сохранить меняется на название выбранного приложения. Как сохранить распознанный текст Нажмите стрелку справа от кнопки 4-Сохранить и из меню выберите необходимую команду. Важно: В процессе сохранения части страниц сначала выделите их в диалоговом окне Пакет. После того, как вы экспортировали распознанный текст в выбранное вами приложение, отправили его по электронной почте, передали в буфер или сохранили в файл, «информация» об этом действии отразится на иконке кнопки 4-Сохранить. Поэтому для того с тем, чтобы повторить ту же операцию для другого изображения, вам достаточно нажать на эту иконку. Опции сохранения распознанного текста Опции сохранения распознанного текста устанавливаются на закладке Форматирование диалогового окна Опции (доступ: Сервис к Опции). Кроме того часть этих опций можно установить в диалоговых окнах Мастер сохранения результатов и Сохранить текст как. • Режим сохранения форматирования и раскладки распознанного текста • Сохранять или не сохранять картинки в распознанном тексте • Используемые шрифты • Сохранять все страницы пакета или только выделенные • Режимы передачи страниц пакета • Режим сохранения форматирования и раскладки распознанного текста (при сохранении в форматах RTF, DOC или HTML) • Сохранять полное оформление документа — сохраняется полное оформление документа: разбиение на абзацы, гарнитура и размер шрифта, колонки, направление текста, цвет букв и фон текста. Сохраняется структура таблиц. • Сохранять начертание и размер шрифта — сохраняется структура таблиц, разбиение на абзацы, начертание и размер шрифта. • Не сохранять оформление — в этом случае сохраняется разбиение на абзацы и структура таблиц. Важно: Вы имеете возможность установить дополнительные опции для каждого формата, в котором FineReader сохраняет распознанный текст. К примеру, для формата RTF/DOC вы имеете возможность указать формат страницы, выделять ли ошибки цветом; для формата HTML — разрешение картинки, кодовую страницу; при сохранении в формате PDF текстов, использующих отличную от латинской кодовую страницу (например, кириллическую, греческую), указать используемые шрифты Туре 1. Сохранять/не сохранять картинки Дает возможность сохранить картинки в распознанном тексте. Эта опция доступна при сохранении в форматы RTF, DOC или HTML. Используемые шрифты (при сохранении в форматах RTF, DOC или HTML) В программе ABBYY FineReader в процессе сохранения в файл или передачи распознанного текста в приложение используются шрифты, установленные на закладке Форматирование в разделе Шрифты. Вы имеете возможность изменить шрифты в диалоговом окне Текст или, выбрав другие шрифты на закладке Форматирование, перераспознать изображение. Сохранять все или только выделенные страницы Дает возможность сохранить все страницы пакета или только выделенные. В процессе сохранения или экспорте части страниц, сначала выделите их в диалоговом окне Пакет. Режимы передачи страниц пакета (при сохранении нескольких страниц пакета) Каждая страница в отдельный файл — дает возможность сохранить каждую страницу пакета в отдельный файл. В этом случае к названию файла в конец автоматически добавляется порядковый номер страницы в пакете. • Пофайловое деление по изображениям — дает возможность собрать распознанный текст с многостраничных изображений в один файл. • Пофайловое деление по пустым страницам — дает возможность сохранить каждую группу страниц в отдельный файл. Деление по группам производится по пустым страницам. • Все страницы в один файл — дает возможность сохранить все (или все выделенные) страницы пакета в один файл. Сохранение распознанного текста в форматах RTF и DOC Режимы сохранения оформления и режим сохранения картинок устанавливаются на закладке Форматирование диалогового окна Опции (доступ: Сервис к Опции). Важно: В программе abbyy finereader в процессе сохранения в форматах RTF или DOC используются шрифты, установленные на закладке Форматирование диалогового окна Опции (доступ: Сервис к Опции), или те, которые вы выбрали в процессе редактирования текста в диалоговом окне Текст. Важно: Для более удобного редактирования распознанного текста в Microsoft Word вы имеете возможность сохранить выделение цветом неуверенно распознанных символов. Для этого на закладке RTF/DOC в разделе Выделять неуверенно распознанные символы выберите цвет из Цветом фона или Цветом символа. Ошибки в сохраненном *.rtf (*.doc) файле будут выделены указанным вами цветом. Сохранение распознанного текста в формате PDF Опции сохранения оформления документа: • Только текст и картинки — сохраняется распознанный текст и имеющиеся в тексте картинки. • Текст поверх изображения картинки — изображение передается картинкой. Текстовые области записываются как текст поверх картинки. • Текст под изображением картинки — все изображение сохраняется как картинка. Под нее «записывается» распознанный текст. В этом случае, сохраняется полный дизайн документа: цветовые выделения шрифта, фона, оформление бумаги. Эта опция может использоваться, например, для составления архивов документов: полностью сохраняется исходное оформление документа, при этом появляется возможность использования функции полнотекстового поиска по ним. Для того, чтобы установить опции при сохранении в формате PDF из меню Сервис выберите команду Форматы. На закладке pdf диалогового окна Форматы установите требуемые опции. Важно: В программе abbyy finereader в процессе сохранении в режиме Только текст и картинки и в режиме Текст поверх изображения страницы вы имеете возможность сделать так, чтобы при сохранении текста в формат PDF неуверенно распознанные слова заменялись их соответствующими изображениями. Для этого на закладке PDF диалогового окна Форматы активизируйте опцию Заменять неуверенно распознанные слова их изображениями. Режимы использования шрифтов при сохранении в формате PDF При сохранении в формате PDF следует указать режим использования шрифтов. Для текстов, использующих отличную от латинской кодовую страницу (например, кириллическую, греческую, чешскую), следует выбрать один из режимов для работы с Туре 1 шрифтами, а также шрифты Туре 1. Эти шрифты должны быть подключены через программу Adobe Type Manager. • Использовать стандартные шрифты Acrobat Reader — pdf-файл ссылается на стандартные системные шрифты Times, Helvetica и CourierNew. Ссылаться на Typ e 1 шрифты — в pdf-файл пишутся ссылки на Туре 1 шрифты, сами шрифты не встраиваются. Шрифты, на которые ссылается PDF-файл, должны быть установлены и подключены через Adobe Type Manager. • Встраивать Typ e 1 шрифты — Туре 1 шрифты встраиваются в PDF-файл. Встраиваемые шрифты должны быть подключены через Adobe Type Manager. Важно: В случае, если у вас отсутствуют шрифты Туре 1, то для сохранения любых документов в формате PDF вы имеете возможность использовать опцию Использовать стандартные шрифты Acrobat Reader. Кроме этого помните, что символы из кодовых страниц, отличные от кодовой страницы Latin (например, Cyrillic, Greek, Czech), будут правильно отображаться лишь в версиях программы Acrobat Reader 3.x. Символы же из кодовой страницы Latin будут правильно отображаться в любых версиях программы Acrobat Reader. В режиме Ссылаться на Туре 1 шрифты в pdf-файле прописываются только ссылки на используемые шрифты (в отличии от режима Встраивать Туре 1 шрифты, когда используемые шрифты встраиваются в pdf-файл), так, чтобы полученный PDF-файл занимал меньше места на диске, чем этот же файл, сохраненный в режиме Встраивать Туре 1 шрифты. Сохранение в режиме Встраивать Туре 1 Шрифты дает возможность другим пользователям просматривать, редактировать и печатать документ с использованием исходных шрифтов, даже если эти шрифты не установлены на данном компьютере. Как указать программе, какие использовать шрифты Туре 1 Нажмите на кнопку Шрифты Туре 1 на закладке pdf диалогового окна Форматы (доступ: Сервис к Форматы). Важно: В диалоговом окне Шрифты Туре 1 необходимо указать все шрифты: с засечками, без засечек, моноширинный. Сохранение распознанного текста в формате HTML Режимы сохранения оформления устанавливаются на закладке Форматирование диалогового окна Опции (доступ: Сервис к Опции). Важно: В программе abbyy finereader в процессе сохранения в формате html используются шрифты, установленные на закладкеФорматирования диалогового окна Опции (доступ: Сервис к Опции), или те, которые вы выбрали в процессе редактирования текста в диалоговом окне Текст. Как сохранить картинки в HTML — файле На закладке Форматирование диалогового окна Опции (доступ: Сервис к Опции) активизируйте опцииСохранять картинки. Важно: Картинки сохраняются в отдельные файлы с расширением *.jpg. Форматы HTML Полный Совместим с обозревателем Internet Explorer — файл записывается в формате HTML 4.0, что дает возможность точно передать оформление документа, используя при этом таблицу стилей, которая встраивается в html-файл. Простой Совместим со всеми обозревателями Internet. В этом случае файл записывается в формате HTML 3.0. Оформление сохраняется приблизительно (не сохраняются отступы первой строки, неточное сохранение размера шрифта), но зато этот формат поддерживается всеми обозревателями Internet. Авто Простой и Полный форматы сохраняются в один файл — в один файл сохраняются два формата (Простой и Полный), при этом при отображении файла в обозревателе Internet автоматически выбирается один из них в соответствии с типом и версией обозревателя Internet. Как установить формат HTML На закладке HTML диалогового окна Форматы (доступ: Сервис к Форматы) в разделе Форматы активизируйте необходимый переключатель. Важно: В программе abbyy finereader кодовая страница определяется автоматически. В случае, если вы хотите поменять кодовую страницу, обратитесь к полю данных Кодовая страница через закладку HTML диалогового окна Форматы. Сохранение изображения страницы Для этого выделите страницу в пакете, из меню Файл выберите команду Сохранить изображение как, в раскрывшемся диалоговом окне Сохранить изображение как выберите диск, папку для размещения сохраняемого файла и формат, а затем дайте имя сохраняемому файлу и просто нажмите на кнопку Save. Важно: В случае, если вы хотите сохранить изображение выделенных блоков в файл, в диалоговом окне Сохранить изображение как активизируйте опцию Сохранять выделенные блоки. Важно: Вы имеете возможность сохранить несколько изображений в один файл как многостраничный TIF. Для этого выделите необходимые вам изображения в диалоговом окне Пакет, из меню Файл выберите команду Сохранить изображение как, в раскрывшемся диалоговом окне выберите формат TIF и активизируйте опцию Сохранять все страницы в один файл. Глава 38. Описания основных команд меню Файл  Открыть изображение Импортировать изображение в пакет программы. Сканировать изображение Отсканировать изображение. Сканировать несколько страниц Сканировать изображения в цикле. Для того, чтобы остановить сканирование из меню Файл выбирается команда Остановить сканирование. Остановить сканирование Прекратить сканирование. Новый пакет Создать папку для нового пакета. Открыть пакет Выбрать пакет для текущей работы. При необходимости автоматической загрузки последнего пакета при открытии программы через закладку Общие (доступ:Сервис к Опции) активизируется опция Открывать последний пакет. Закрыть пакет Закрыть текущий пакет. При закрытии пакет сохраняется автоматически. Мастер сохранения результатов Выбрать внешнее приложение для сохранения и установить опции сохранения. Сохранить текст как Сохранить распознанный текст в файл. Передать выбранные страницы в Передать результаты распознавания в существующее внешнее приложение. Передать все страницы в Передать все станицы распознанного текста в существующее внешнее приложение. Сохранить изображение как Сохранить выбранное изображение отсканированной страницы на диск. Выход Закрыть программу. Правка Отменить Отменить действие последней выполненной команды. Восстановить Отменить действие последней команды Отменить. Вырезать Удалить выборку текущего пакета и поместить ее в буфер обмена.  Копировать Скопировать выборку текущего пакета в буфер обмена. Вставить Поместить выборку текущего пакета из буфера обмена. Очистить Удалить выделенный фрагмент текста или выделенные блоки текущего пакета. Выделить все Выделить весь текст, все блоки или все страницы текущего пакета. Найти Осуществить поиск заданного текста на открытой странице или во всем пакете. Найти следующее Повторить поиск текста, который введен в диалоговом окне Найти или Заменить. Заменить Осуществляет поиск и замену заданного текста на текущей странице или во всем пакете. Разбить ячейки таблицы Разделить объединенную ячейку текущей таблицы на несколько ячеек, из которых она была получена. Объединить ячейки таблицы Объединить несколько активизированных ячеек таблицы. Содержимое этих ячеек распознается программой как содержимое одной ячейки. Объединить строки таблицы Объединить несколько выделенных строк таблицы, сохраняя при этом разбиение на колонки. Содержимое слитых строк (в пределах одной колонки) распознается программой как содержимое одной ячейки. Вид  Масштаб в окне Изображение Выбрать способ отображения документа на экране монитора вашего компьютера. • В режиме работы По ширине отпадает необходимость использовать горизонтальную прокрутку. • В режиме работы По длине отпадает необходимость использовать вертикальную прокрутку. • В режиме работы Целая страница результат распознавания отображается целиком. • Увеличить (Уменьшить) — Увеличить (уменьшить) масштаб изображения в два раза. • Показать активный блок — Увеличить масштаб изображения так, чтобы активный блок был отображен как можно более крупно. Масштаб в окне Крупный план Выбрать масштаб отображения в интервале от 50 до 800. Команды Увеличить (Уменьшить) позволяют увеличить (уменьшить) масштаб изображения в два раза. Команда С точностью до пикселя дает отображает изображение в натуральную величину (в пикселях). Масштаб окна Текст Выбрать масштаб отображения распознанного текста в интервале от 50 до 200. Вид в окне Пакет Выбрать способ представления изображений в диалоговом окне Пакет. Окно Пакет Выбрать расположение окна Пакет в Главном диалоговом окне. Окна Изображение и Текст Дает возможность выбрать режим отображения окон Изображение и Текст в Главном диалоговом окне программы: • Два диалоговых окна. • Только диалоговое окно Изображение. • Только диалоговое окно Текст. Окно Крупный план Выбрать расположение окна Крупный план из Главного диалогового окна программы. Панель инструментов Показать или спрятать выбранную панель. Строка состояния Показать или спрятать Строку состояния. Свойства Открыть диалоговое окно Свойства. • Если в программе открыто изображение, то в этом диалоговом окне находится информация относительно типа и размеров изображения, а также о разрешении, которым изображение было отсканировано. • Если вы активизируете блок на изображении, то получите информацию относительно параметров текущего блока. • Если вы выделите страницу в диалоговом окне пакета, то получите подробную информацию относительно текущей страницы (когда она была создана, распознана, отредактирована). Пакет • Если у вас открыт текст в диалоговом окне Текст, то откроете; диалоговое окно Шрифты.  Открыть следующую Открыть следующую страницу пакета. Открыть предыдущую страницу Открыть страницу пакета, которая предшествует открытой странице. Открыть страницу с номером Открыть диалоговое окно, в котором можно ввести номер необходимой страницы пакета. После этого программа откроет эту страницу. Закрыть страницу Закрыть открытую страницу. Перенумеровать страницы Изменить номер текущей, выделенной или всего диапазона страниц пакета. Удалить текст Удалить распознанный текст. Удалить блоки и текст Удалить распознанный текст и выделенные на изображении блоки. Удалить страницу Удалить выделенные страницы из диалогового окна Пакет страницы. Удалить пакет Удалить открытый пакет. Обновить список страниц Получить самую последнюю информацию относительно модифицированных страниц пакета. Изображение  Тип Блока/Зона Распознавания Приписать активизированному блоку тип Зона Распознавания. Тип Блока/Текст Приписать активизированному блоку тип Текст. Тип Блока/Таблица Приписать активизированному блоку тип Таблица. Тип Блока/Картинка Приписать активизированному блоку тип Картинка. Тип Блока/Штрих-код Приписать активизированному блоку тип Штрих-код (возможно только в версии ABBYY FineReader Office). Повернуть по часовой стрелке Повернуть изображение на 90° по часовой стрелке. Повернуть против часовой стрелки Повернуть изображение на 90° против часовой стрелки. Повернуть на 180° Повернуть изображение на 180° (вверх ногами). Зеркально отразить относительно вертикали Зеркально отразить изображение относительно вертикальной прямой. Зеркально отразить относительно горизонтали Зеркально отразить изображение относительно горизонтальной прямой. Инвертировать Инвертировать изображение. Используется для повышения качества распознавания инвертированных изображений (изображения, текст которых набран светлым буквами на темном фоне). Очистить изображение от мусора Удалить отдельно стоящие точки на изображении. Очистить блок от мусора Удалить отдельно стоящие точки в пределах блока. Сохранить блоки Сохранить расположение блоков на странице в файл. Наложить блоки Спроецировать блоки из файла на страницу со схожим расположением текста. Выбрать инструмент/Выделить зону распознавания Выделить зону распознавания. По кнопке 2-Распознать выделенный блок будет проанализирован и распознан. Распознанный текст появится в диалоговом окне Текст. Выбрать инструмент/Выделить текстовый блок Выделить текстовый блок. Данный блок может содержать только одноколоночный текст без картинок, таблиц. Выбрать инструмент/Выделить табличный блок Выделить табличный блок. В процессе распознавания программа разбивает данный блок на строки и столбцы. В выходном тексте данный блок передается таблицей. Выбрать инструмент/Выделить картинку Выделить картинку. Этот блок может содержать картинку или любую другую часть текста, которую вы хотите передать в распознанный текст в качестве картинки. Выбрать инструмент/Выбор объектов Переместить границы блоков, выделить и переместить блоки. Для выделения нескольких объектов следует провести указателем по выделяемым блокам при нажатой кнопке мыши. Выбрать инструмент/Добавить часть к блоку Добавить прямоугольную часть к блоку. Выбрать инструмент/удалить часть блока Удалить прямоугольную часть блока. Выбрать инструмент/ Перенумеровать блоки Перенумеровать блоки на изображении. От порядка блоков зависит порядок текста в распознанном документе. В случае, если вы перенумеровываете блоки на уже распознанном изображении, то одновременно с этим в диалоговом окне Текст происходит перегруппировка распознанного текста в соответствии с новой нумерацией. Выбрать инструмент/ Удалить блок Удалить блок. Выбрать инструмент/ Добавить горизонтальную линию Добавить горизонтальную линию в таблицу. Выбрав эту команду, нажмите в том месте таблицы, где должна появиться горизонтальная линия. Важно: Для того, чтобы изменить направление линий с горизонтального на вертикальное, удерживайте клавишу Shift. Выбрать инструмент/Добавить вертикальную линию Добавить вертикальную линию в таблицу. Выбрать инструмент/Удалить линию Удалить горизонтальную или вертикальную линию из таблицы. Выбрать инструмент/Ластик Закрасить цветом фона изображение внутри выделенного участка. Процесс  Сканировать и распознать Запустить процесс процесса сканирования и распознать документа. Сканировать и распознать несколько страниц Запустить процесс процесса сканирования и распознать несколько страниц в цикле. Открыть и распознать Открыть и распознать изображения, выбранные в диалоговом окне Открыть изображение. Scan and Read Запустить специальный режим процесса сканирования и распознавания, во время которого OCR-система будет сама контролировать действия пользователя и подсказывать ему, что необходимо делать с тем, чтобы получить тот или иной результат. Анализ макета страницы Выделить блоки отсканированного изображения. Анализ макета всех страниц Выделить блоки не активизированные блоки на всех страницах пакета. Распознать Распознать активизированную страницу пакета. Распознать все Распознать все нераспознанные страницы пакета. Распознать блок Распознать активный блок. Запустить фоновое распознавание Запустить распознавание всех нераспознанных страниц пакета в фоновом режиме. В программе ABBYY FineReader в это же время можно работать с уже распознанными страницами пакета. Остановить фоновое распознавание Остановить распознавание в фоновом режиме. Сервис  Проверка Найти в распознанном тексте слова, которые не соответствуют правилам правописания текущего языка. Просмотр словарей Выбрать язык для просмотра или корректировки словаря. Перевод слова в Lingvo Перевести выделенное слово или словосочетание на другой язык. Эта команда доступна только в том случае, если на компьютере установлено приложение Lingvo. Редактор языков Создать и отредактировать пользовательский язык и группу языков. Редактор эталонов Создавать новый пользовательский эталон или отредактировать существующий. Настройки сканера Установить параметры процесса сканирования. Форматы Установить параметры для форматов файлов: RTF/DOC, PDF, HTML, CSV, DBF, TXT и XLS. Окна  Следующее диалоговое окно Перейти в следующее открытое диалоговое окно. Предыдущее диалоговое окно Перейти в предыдущее открытое диалоговое окно. Упорядочить все «Подогнать» все открытые окна к экрану монитора вашего компьютера. Справка  Справка Открыть справочный файл. Обучение на примерах Открыть справочный файл, в котором описано, как ввести документы различного типа и степени сложности. Техническая поддержка Открыть страницу Техническая поддержка из справочного файла. Как купить ABBYY FineReader Открыть страницу Как купить с информацией относительно возможности приобретения программы FineReader. О программе Получить краткую информацию относительно программы FineReader. |
|
||
|
Главная | Контакты | Нашёл ошибку | Прислать материал | Добавить в избранное |
||||
|
|
||||