|
||||
|
|
Глава 6 Наследование и объектно-ориентированное проектирование Объектно-ориентированное программирование (ООП) существует почти 20 лет, поэтому, вероятно, вы имеете некоторое представление о наследовании, производных классах и виртуальных функциях. Даже если вы программировали только на C, ничего не слышать об ООП вы просто не могли. И все же ООП в C++, скорее всего, несколько отличается от того, к чему вы привыкли. Наследование может быть одиночным и множественным, а отдельный путь наследования может быть открытым (public), защищенным (protected) или закрытым (private). Путь также может быть виртуальным или невиртуальным. Для функций-членов тоже есть варианты. Виртуальные? Невиртуальные? Чисто виртуальные? Добавьте сюда взаимодействие с другими средствами языка. Как соотносятся параметры по умолчанию с виртуальными функциями? Как влияет наследование на правила разрешения имен в C++? И что можно сказать по поводу методов проектирования? Если поведение класса должно быть модифицируемым, являются ли виртуальные функции лучшим способом достижения этого? Обо всем этом пойдет речь в настоящей главе. Я объясню, что на самом деле стоит за теми или иными возможностями C++: какую мысль вы выражаете, когда используете некоторую конструкцию. Например, открытое наследование моделирует отношение «является», и если вы попытаетесь придать ему какую-то иную семантику, то столкнетесь с проблемой. Аналогично, виртуальная функция означает «должен быть унаследован интерфейс», в то время как невиртуальная функция означает «должны наследоваться и интерфейс, и реализация». Если не делать различий между этими смыслами, то неприятностей не миновать. Когда вы поймете истинное назначение различных средств C++, то обнаружите, что ваш взгляд на ООП изменился. Вместо простого упражнения в нахождении отличий между языками это станет средством выражения того, что вы хотите сказать о своей программной системе. А поняв, что же вы в действительности имеете в виду, уже не составит большого труда перевести свои мысли этого на C++. Правило 32: Используйте открытое наследование для моделирования отношения «является» Вильям Демент (William Dement) в своей книге «Кто-то должен бодрствовать, пока остальные спят» (W. H. Freeman and Company, 1974) рассказывает о том, как он пытался донести до студентов наиболее важные идеи своего курса. Утверждается, говорил он своей группе, что средний британский школьник помнит из уроков истории лишь то, что битва при Хастингсе произошла в 1066 году. Даже если ученик почти ничего не запомнил из курса истории, подчеркивает Демент, 1066 год остается в его памяти. Демент пытался внушить слушателям несколько основных идей, в частности ту любопытную истину, что снотворное вызывает бессонницу. Он призывал своих студентов запомнить ряд ключевых фактов, даже если забудется все, что обсуждалось на протяжении курса, и в течение семестра возвращался к нескольким фундаментальным заповедям. Последним на заключительном экзамене был вопрос: «Напишите, какой факт из тех, что обсуждались на лекциях, вы запомните на всю жизнь». Проверяя работы, Демент был ошеломлен. Почти все упомянули 1066 год. Теперь я с трепетом хочу провозгласить, что самое важное правило в объектно-ориентированном программировании на C++ звучит так: открытое наследование означает «является». Твердо запомните это. Если вы пишете класс D (derived – «производный») открыто наследует классу B («base» – «базовый»), то тем самым сообщаете компилятору C++ (а заодно и людям, читающим ваш код), что каждый объект типа D является также объектом типа B, но не наоборот. Вы говорите, что B представляет собой более общую концепцию, чем D, а D – более конкретную концепцию, чем B. Вы утверждаете, что везде, где может быть использован объект B, можно использовать также объект D, потому что D является объектом типа B. С другой стороны, если вам нужен объект типа D, то объект B не подойдет, поскольку каждый D «является разновидностью» B, но не наоборот. Такой интерпретации открытого наследования придерживается C++. Рассмотрим следующий пример: class Person {...}; class Student: public Person {...}; Здравый смысл и опыт подсказывают нам, что каждый студент – человек, но не каждый человек – студент. Именно такую связь подразумевает данная иерархия. Мы ожидаем, что всякое утверждение, справедливое для человека – например, что у него есть дата рождения, – справедливо и для студента, но не все, что верно для студента – например, что он учится в каком-то определенном институте, – верно для человека в общем случае. Применительно к C++ это выглядит следующим образом: любая функция, которая принимает аргумент типа Person (или указатель на Person, или ссылку на Person), примет объект типа Student (или указатель на Student, или ссылку на Student): void eat(const Person& p); // все люди могут есть void study(const Student& s); // только студент учится Person p; // p – человек Student s; // s – студент eat(p); // правильно, p есть человек eat(s); // правильно, s – это студент, // и студент также является человеком study(s); // правильно study(p); // ошибка! p – не студент Все сказанное верно только для открытого наследования. C++ будет вести себя так, как описано выше, только в случае, если Student открыто наследует Person. Закрытое наследование означает нечто совсем иное (см. правило 39), а смысл защищенного наследования ускользает от меня по сей день. Идея тождества открытого наследования и понятия «является» кажется достаточно очевидной, но иногда интуиция нас подводит. Рассмотрим следующий пример: пингвин – это птица, птицы умеют летать. Если вы по наивности попытаетесь выразить это на C++, то вот что получится: class Bird { public: virtual void fly(); // птицы умеют летать ... }; class Penguin: public Bird { // пингвины – птицы ... }; Неожиданно мы столкнулись с затруднением. Утверждается, что пингвины могут летать, что, как известно, неверно. В чем тут дело? В данном случае нас подвела неточность разговорного языка. Когда мы говорим, что птицы умеют летать, то не имеем в виду, что все птицы летают, а только то, что обычно они обладают такой способностью. Если бы мы выбирали формулировки поточнее, то вспомнили бы, что существует несколько видов нелетающих птиц, и пришли к следующей иерархии, которая значительно лучше моделирует реальность: class Bird { ... // функция fly не объявлена }; class FlyingBird: public Bird { public: virtual void fly(); ... }; class Penguin: public Bird { ... // функция fly не объявлена }; Данная иерархия гораздо точнее отражает реальность, чем первоначальная. Но и теперь еще не все закончено с «птичьими делами», потому что для некоторых приложений может и не быть необходимости делать различие между летающими и нелетающими птицами. Так, если ваше приложение в основном имеет дело с клювами и крыльями и никак не отражает способность пернатых летать, вполне сойдет и исходная иерархия. Это наблюдение, сообственно, является лишь подтверждением того, что не существует идеального проекта, который подходил бы для всех видов программных систем. Выбор проекта зависит от того, что система должна делать – как сейчас, так и в будущем. Если ваше приложение никак не связано с полетами и не предполагается, что оно будет связано с ними в дальнейшем, то вполне можно не принимать во внимание различий между летающими и нелетающими птицами. На самом деле даже лучше не проводить таких различий, потому что его нет в мире, который вы пытаетесь моделировать. Существует другая школа, иначе относящаяся к рассматриваемой проблеме. Она предлагает переопределить для пингвинов функцию fly() так, чтобы во время исполнения она возвращала ошибку: void error(const std::string& msg); // определено в другом месте class Penguin: public Bird { public: virtual void fly() {error(“Попытка заставить пингвина летать!”);} ... }; Важно понимать, что это здесь имеется в виду не совсем то, что вам могло показаться. Мы не говорим: «Пингвины не могут летать», а лишь сообщаем: «Пингвины могут летать, но с их стороны было бы ошибкой это делать». В чем разница? Во времени обнаружения ошибки. Утверждение «пингвины не могут летать» может быть поддержано на уровне компилятора, а соответствие утверждения «попытка полета ошибочна для пингвинов» реальному положению дел может быть обнаружено во время выполнения программы. Чтобы обозначить ограничение «пингвины не могут летать – и точка», следует убедиться, что для объектов Penguin функция fly() не определена: class Bird { ... // функция fly не объявлена }; class Penguin: public Bird { ... // функция fly не объявлена }; Если теперь вы попробуете заставить пингвина взлететь, компилятор сделает вам выговор за нарушение правил: Penguin p; p.fly(); // ошибка! Это сильно отличается от поведения, которое получается, если применить подход, генерирующий ошибку времени исполнения. Ведь в таком случае компилятор ничего не может сказать о вызове p.fly(). В правиле 18 объясняется, что хороший интерфейс предотвращает компиляцию неверного кода, поэтому лучше выбрать проект, который отвергает попытки пингвинов полетать во время компиляции, а не во время исполнения. Возможно, вы решите, что вам недостает интуиции орнитолога, но вполне можете положиться на свои познания в элементарной геометрии, не так ли? Тогда ответьте на следующий простой вопрос: должен ли класс Square (квадрат) открыто наследовать классу Rectangle (прямоугольник)? 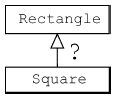 «Конечно! – скажете вы. – Каждый знает, что квадрат – это прямоугольник, а обратное утверждение в общем случае неверно». Что ж, правильно, по крайней мере, для школы. Но мы ведь решаем задачи посложнее школьных. class Rectangle { public: virtual void setHeight(int newHeight); virtual void setWidth(int newWidth); virtual int height() const; // возвращают текущие значения virtual int width() const; ... }; void makeBigger(Rectangle& r) // функция увеличивает площадь r { int oldHeight = r.height(); r.setWidth(r.width() + 10); // увеличить ширину r на 10 assert(r.height() == oldHeight); // убедиться, что высота r } // не изменилась Ясно, что утверждение assert никогда не должно нарушаться. Функция make-Bigger изменяет только ширину r. Высота остается постоянной. Теперь рассмотрим код, который посредством открытого наследования позволяет рассматривать квадрат как частный случай прямоугольника: class Square: public Rectangle {…}; Square s; ... assert(s.width() == s.height()); // должно быть справедливо для // всех квадратов makeBigger(s); // из-за наследования, s является // Rectangle, поэтому мы можем // увеличить его площадь assert(s.width() == s.height()); // По-прежнему должно быть справедливо // для всех квадратов Как и в предыдущем примере, что второе утверждение также никогда не должно быть нарушено. По определению, ширина квадрата равна его высоте. Но теперь перед нами встает проблема. Как примирить следующие утверждения? • Перед вызовом makeBigger высота s равна ширине. • Внутри makeBigger ширина s изменяется, а высота – нет. • После возврата из makeBigger высота s снова равна ширине (отметим, что s передается по ссылке, поэтому makeBigger модифицирует именно s, а не его копию). Так что же? Добро пожаловать в удивительный мир открытого наследования, где интуиция, приобретенная вами в других областях знания, включая математику, иногда оказывается плохим помощником. Основная трудность в данном случае заключается в том, что некоторые утверждения, справедливые для прямоугольника (его ширина может быть изменена независимо от высоты), не выполняются для квадрата (его ширина и высота должны быть одинаковы). Но открытое наследование предполагает, что все, что применимо к объектам базового класса, – все! – также применимо и к объектам производных классов. В ситуации с прямоугольниками и квадратами (а также в аналогичных случаях, включая множества и списки из правила 38), утверждение этого условия не выполняется, поэтому использование открытого наследования для моделирования здесь некорректно. Компилятор, конечно, этого не запрещает, но, как мы только что видели, не существует гарантий, что такой код будет вести себя должным образом. Любому программисту должно быть известно (некоторые знают это лучше других): если код компилируется, то это еще не значит, что он будет работать. Все же не стоит беспокоиться, что приобретенная вами за многие годы разработки программного обеспечения интуиция окажется бесполезной при переходе к объектно-ориентированному программированию. Все ваши знания по-прежнему актуальны, но теперь, когда вы добавили к своему арсеналу наследование, вам придется дополнить свою интуицию новым пониманием, позволяющим создавать приложения с использованием наследования. Со временем идея наследования Penguin от Bird или Square от Rectangle будет казаться вам столь же забавной, как функция объемом в несколько страниц. Такое решение может оказаться правильным, но это маловероятно. Отношение «является» – не единственное, возможное между классами. Два других, достаточно распространенных отношения – это «содержит» и «реализован посредством». Они рассматриваются в правилах 38 и 39. Очень часто при проектировании на C++ весь проект идет вкривь и вкось из-за того, что эти взаимосвязи моделируются отношением «является». Поэтому вы должны быть уверены, что понимаете различия между этими отношениями и знаете, каким образом их лучше всего моделировать в C++. Что следует помнить• Открытое наследование означает «является». Все, что применимо к базовому классу, должно быть применимо также и производным от него, потому что каждый объект производного класса является также объектом базового класса. Правило 33: Не скрывайте унаследованные имена Шекспир много размышлял об именах. Он писал: «Что в имени тебе? Роза пахнет розой, хоть розой назови ее, хоть нет». И еще писал бард: «Кто доброе мое похитит имя, несчастным сделает меня вовек…» Правильно. И это заставляет нас обратить взор на унаследованные имена в C++. Вообще-то эта тема относится не столько к наследованию, сколько к областям видимости. Все мы знаем, что в таком коде: int x; // глобальная переменная void someFunc() { double x; // локальная переменная std::cin >> x; // прочитать новое значение локальной переменной x } имя x в предложении считывания относится к локальной, а не к глобальной переменной, потому что имена во вложенной области видимости скрывают («затеняют») имена из внешних областей. Мы можем представить эту ситуацию визуально:  Когда компилятор встречает имя x внутри функции someFunc, он смотрит, определено ли что-то с таким именем в локальной области видимости. Если да, то объемлющие области видимости не просматриваются. В данном случае имя x в функции someFunc принадлежит переменной типа double, а глобальная переменная с тем же именем x имеет тип int, но это несущественно. Правила сокрытия имен в C++ предназначены для одной-единственной цели: скрывать имена. Относятся ли одинаковые имена к объектам одного или разных типов, не имеет значения. В нашем примере переменная x типа double скрывает переменную x типа int. Вернемся к наследованию. Мы знаем, что когда находимся внутри функции-члена производного класса и ссылаемся на что-то из базового класса (например, функцию-член, typedef или член данных), компилятор сможет найти то, на что мы ссылаемся, потому что производные классы наследуют свойства, объявленные в базовых классах. Механизм основан на том, что область видимости производного класса вложена в область видимости базового класса. Например:  class Base { private: int x; public: virtual void mf1() = 0; virtual void mf2(); void mf3(); ... }; class Derived: public Base { public: virtual void mf1() void mf4(); ... }; В этом примере встречаются как открытые, так и закрытые имена, как имена членов данных, так и функций-членов. Одна из функций-членов – чисто виртуальная, другая – просто виртуальная, а третья – невиртуальная. Это я к тому, что мы говорим именно об именах, а не о чем-то другом. Я мог бы включить в пример еще имена типов, например перечислений, вложенных классов и typedef. В данном контексте важно лишь то, что все это имена. Что они именуют – несущественно. В примере используется одиночное наследование, но, поняв, что происходит при одиночном наследовании, легко будет разобраться и в том, как C++ ведет себя при множественном наследовании. Предположим, что функция-член mf4 в производном классе реализована примерно так: void Derived::mf4() { ... mf2(); ... } Когда компилятор видит имя mf2, он должен понять, на что оно ссылается. Для этого в различных областях видимости производится поиск имени mf2. Сначала оно ищется в локальной области видимости (то есть внутри mf4), но там такого имени нет. Тогда просматривается объемлющая область видимости, то есть область видимости класса Derived. И здесь такое имя отсутствует, поэтому компилятор переходит к следующей область видимости, которой является базовый класс. И находит там нечто по имени mf2, после чего поиск завершается. Если бы mf2 не было и в классе Base, то поиск продолжился бы сначала в пространстве имен, содержащем Base, если таковое имеется, и, наконец, в глобальной области видимости. Данное мной описание правильно, хотя и исчерпывает всю сложность процесса поиска имен в C++. Наша цель, однако, не в том, чтобы узнать о поиске имен столько, чтобы самостоятельно написать компилятор. Достаточно будет, если мы сумеем избежать неприятных сюрпризов, а для этого изложенной информации должно хватить. Снова вернемся к предыдущему примеру, но на этот раз перегрузим функции mf1 и mf3, а также добавим версию mf3 в класс Derived. Как объясняется в правиле 36, перегрузка mf3 в производном классе Derived (когда наследуется невиртуальная функция) сама по себе подозрительна, но чтобы лучше разобраться с видимостью имен, закроем на это глаза.  class Base { private: int x; public: virtual void mf1() = 0; virtual void mf1(int); virtual void mf2(); void mf3(); void mf3(double); ... }; class Derived: public Base { public: virtual void mf1() void mf3(); void mf4(); ... }; Этот код приводит к поведению, которое удивит любого программиста C++, впервые столкнувшегося с ним. Основанное на областях видимости правило сокрытия имен никуда не делось, поэтому все функции с именами mf1 и mf3 в базовом классе окажутся скрыты одноименными функциями в производном классе. С точки зрения поиска имен, Base::mf1 и Base::mf3 более не наследуются классом Derived! Derived d; int x; ... d.mf1(); // правильно, вызывается Derived::mf1 d.mf1(x); // ошибка! Derived::mf1 скрывает Base::mf1 d.mf2(); // правильно, вызывается Base::mf2 d.mf3(); // правильно, вызывается Derived::mf3 d.mf3(x); // ошибка! Derived::mf3 скрывает Base::mf3 Как видите, это касается даже тех случаев, когда функции в базовом и производном классах принимают параметры разных типов, независимо от того, идет ли речь о виртуальных или невиртуальных функциях. И точно так же, как в нашем первом примере double x внутри функции someFunc скрывает int x из глобального контекста, так и здесь функция mf3 в классе Derived скрывает функцию mf3 из класса Base, которая имеет другой тип. Обоснование такого поведения в том, что оно не дает нечаянно унаследовать перегруженные функции из базового класса, расположенного много выше в иерархии наследования, упрятанной в библиотеке или каркасе приложения. К сожалению, обычно вы хотите унаследовать перегруженные функции. Фактически если вы используете открытое наследование и не наследуете перегруженные функций, то нарушаете семантику отношения «является» между базовым и производным классами, которое в правиле 32 провозглашено фундаментальным принципом открытого наследования. То есть это тот случай, когда вы почти всегда хотите обойти принятое в C++ по умолчанию правило сокрытия имен. Это можно сделать с помощью using-объявлений:  class Base { private: int x; public: virtual void mf1() = 0; virtual void mf1(int); virtual void mf2(); void mf3(); void mf3(double); ... }; class Derived: public Base { public: using Base::mf1; // обеспечить видимость всех (открытых) имен using Base::mf3; // mf1 и mf3 из класса Base в классе Derived virtual void mf1() void mf3(); void mf4(); ... }; Теперь наследование будет работать, как и ожидается. Derived d; int x; ... d.mf1(); // по-прежнему правильно, вызывается Derived::mf1 d.mf1(x); // теперь правильно, вызывается Base::mf1 d.mf2(); // по-прежнему правильно, вызывается Base::mf2 d.mf3(); // по-прежнему правильно, вызывается Derived::mf3 d.mf3(x); // теперь правильно, вызывается Base::mf3 Это означает, что если вы наследуете базовому классу с перегруженными функциями и хотите переопределить только некоторые из них, то должны включить using-объявление для каждого имени, иначе оно будет скрыто. Можно представить себе ситуацию, когда вы не хотите наследовать все функции из базовых классов. При открытом наследовании такое никогда не должно происходить, так как это противоречит смыслу отношения «является» между базовым классом и производным от него. Вот почему using-объявление находится в секции public объявления производного класса; имена, которые открыты в базовом классе, должны оставаться открытыми и в открыто унаследованном от него. Но при закрытом наследовании (см. правило 39) такое желание иногда осмыслено. Например, предположим, что класс Derived закрыто наследует классу Base, и единственная версия mfl, которую Derived хочет унаследовать, – это та, что не принимает параметров. Using-объявление в этом случае не поможет, поскольку оно делает видимыми в производном классе все унаследованные функции с заданным именем. Здесь требуется другая техника – простая перенаправляющая функция: class Base { public: virtual void mf1() = 0; virtual void mf1(int); ... // как раньше }; class Derived: private Base { public: virtual void mf1() // перенаправляющая функция { Base::mf1();} // неявно встроена (см. правило 30) ... }; ... Derived d; Int x; d.mf1(); // правильно, вызывается Derived::mf1 d.mf1(x); // ошибка! Base::mf1 скрыта Другое применение встроенных перенаправляющих функций – обойти дефект в тех устаревших компиляторах, которые не поддерживают using-объявления для импорта унаследованных имен в область видимости производного класса. Это все, что можно сказать о наследовании и сокрытии имен. Впрочем, когда наследование сочетается с шаблонами, возникает совсем другой вариант проблемы «сокрытия унаследованных имен». Все подробности, касающиеся шаблонов, см. в правиле 43. Что следует помнить• Имена в производных классах скрывают имена из базовых классов. При открытом наследовании это всегда нежелательно. • Чтобы сделать скрытые имена видимыми, используйте using-объявления либо перенаправляющие функции. Правило 34: Различайте наследование интерфейса и наследование реализации Внешне простая идея открытого наследования при ближайшем рассмотрении оказывается состоящей из двух различных частей: наследования интерфейса функций и наследования их реализации. Различие между этими двумя видами наследования соответствует различию между объявлениями и определениями функций, обсуждавшемуся во введении к этой книге. При разработке классов иногда требуется, чтобы производные классы наследовали только интерфейс (объявления) функций-членов. В других случаях необходимо, чтобы производные классы наследовали и интерфейс, и реализацию функций, но могли переопределять унаследованную реализацию. А иногда вам может понадобиться использование наследования интерфейса и реализации, но без возможности что-либо переопределять. Чтобы лучше почувствовать различия между этими вариантами, рассмотрим иерархию классов для представления геометрических фигур в графическом приложении: class Shape { public: virtual void draw() const = 0; virtual void error(const std::string& msg); int objectID() const; ... }; class Rectangle: public Shape {…}; class Ellipse: public Shape {…}; Shape – это абстрактный класс; таковым его делает чисто виртуальная функция draw. В результате пользователи не могут создавать объекты класса Shape, а лишь классов, производных от него. Несмотря на это, Shape оказывает сильное влияние на все открыто наследующие ему классы по следующей причине: • Интерфейс функций-членов наследуется всегда. Как объясняется в правиле 32, открытое наследование означает «является», поэтому все, что верно для базового класса, также верно и для производных от него. Поэтому если функция применима к классу, она остается применимой и для подклассов. В классе Shape объявлены три функции. Первая, draw, выводит текущий объект на дисплей, подразумеваемый по умолчанию. Вторая, error, вызывается функциями-членами, если необходимо сообщить об ошибке. Третья, objectID, возвращает уникальный целочисленный идентификатор текущего объекта. Каждая из трех функций объявлена по-разному: draw – как чисто виртуальная; error – как просто виртуальная; а objectID – как невиртуальная функция. Каковы практические последствия этих различий? Рассмотрим первую чисто виртуальную функцию draw: class Shape { public: virtual void draw() const = 0; ... }; Две наиболее заметные характеристики чисто виртуальных функций – они должны быть заново объявлены в любом конкретном наследующем их классе, и в абстрактном классе они обычно не определяются. Сопоставьте эти два свойства, и вы придете к пониманию следующего обстоятельства: • Цель объявления чисто виртуальной функции состоит в том, чтобы производные классы наследовали только ее интерфейс. Это в полной мере относится к функции Shape::draw, поскольку наиболее разумное требование ко всем объектам класса Shape заключается в том, что они должны быть отображены на дисплее, но Shape не может обеспечить разумной реализации этой функции по умолчанию. Алгоритм рисования эллипса очень сильно отличается от алгоритма рисования прямоугольника. Объявление Shape::draw можно интерпретировать как следующее сообщение разработчикам конкретных подклассов: «Вы должны обеспечить наличие функции draw, но у меня нет ни малейшего представления, как вы это собираетесь сделать». Между прочим, дать определение чисто виртуальной функции возможно. Иными словами, вы можете предоставить реализацию для Shape::draw, и С++ будет ее компилировать, но единственный способ вызвать – квалифицировать имя функции названием класса: Shape *ps = new Shape; // ошибка! Shape – абстрактный Shape *ps1 = new Rectangle; // правильно ps1->draw(); // вызов Rectangle::draw Shape *ps2 = new Ellipse; // правильно Ps2->draw(); // вызов Ellipse::draw ps1->Shape::draw(); // вызов Shape::draw ps2->Shape::draw(); // вызов Shape::draw Кроме перспективы блеснуть перед приятелями-программистами во время вечеринки, знание этой особенности вряд ли даст вам что-то ценное. Тем не менее, как вы увидите ниже, возможность определения чисто виртуальной функции может быть использована в качестве механизма обеспечения более безопасной реализации по умолчанию обычных виртуальных функций. Ситуация с обычными виртуальными функциями несколько отличается от ситуации с чисто виртуальными функциями. Как всегда, производные классы наследуют интерфейс функции, но обычные виртуальные функции традиционно обеспечивают реализацию, которую подклассы могут переопределить. Если вы на минуту задумаетесь над этим, то поймете, что: • Цель объявлений обычной виртуальной функции – наследовать в производных классах как интерфейс, так и ее реализацию по умолчанию. Рассмотрим функцию Shape::error: class Shape { public: virtual void error(const std::string& msg); ... }; Интерфейс говорит о том, что каждый класс должен поддерживать функцию, которую необходимо вызывать при возникновении ошибки, но каждый класс волен обрабатывать ошибки наиболее подходящим для себя образом. Если класс не предполагает производить специальные действия, он может просто положиться на обработку ошибок по умолчанию, которую предоставляет класс Shape. То есть объявление Shape::error говорит разработчикам производных классов: «Вы должны поддерживать функцию error, но если не хотите писать свою собственную, то можете рассчитывать просто использовать версию по умолчанию из класса Shape». Оказывается, иногда может быть опасно использовать обычные виртуальные функции, которые обеспечивают как интерфейс функции, так и ее реализацию по умолчанию. Для того чтобы понять, почему имеется такая вероятность, рассмотрим иерархию самолетов в компании XYZ Airlines. XYZ располагает самолетами только двух типов: модель A и модель B, и оба летают одинаково. В связи с этим разработчики XYZ проектирует такую иерархию: class Airport {…}; // представляет аэропорты class Airplane { public: virtual void fly(const Airport& destination); ... }; void Airplane::fly(const Airport& destination) { код по умолчанию, описывающий полет самолета в заданный пункт назначения – destination } class ModelA: public Airplane {...}; class ModelB: public Airplane {...}; Чтобы выразить тот факт, что все самолеты должны поддерживать функцию fly, и для того чтобы засвидетельствовать, что для разных моделей, в принципе, могут потребоваться различные реализации fly, функция Airplane::fly объявлена виртуальной. При этом во избежание написания идентичного кода в классах ModelA и ModelB в качестве стандартного поведения используется тело функции Airplane::fly, которую наследуют как ModelA, так и ModelB. Это классический пример объектно-ориентированного проектирования. Два класса имеют общее свойство (способ реализации fly), поэтому оно реализуется в базовом классе и наследуется обоими подклассами. Благодаря этому проект явным образом выделяет общие свойства, что позволяет избежать дублирования, благоприятствует проведению будущих модернизаций и упрощает долгосрочную эксплуатацию – иными словами, обеспечивает все, за что так ценится объектно-ориентированная технология. Программисты компании XYZ Airlines могут собой гордиться. А теперь предположим, что дела XYZ идут в гору, и компания решает приобрести новый самолет модели C. Эта модель отличается от моделей A и B, в частности, тем, что летает по-другому. Программисты компании XYZ добавляют в иерархию класс ModelC, но в спешке забывают переопределить функцию fly: class ModelB: public Airplane { ... // функция fly не объявлена }; В своем коде потом они пишут что-то вроде этого: Airport PDX(...); // PDX – аэропорт возле моего дома Airplane *pa = new ModelC; ... pa->fly(PDX); // вызывается Airplane::fly! Назревает катастрофа: делается попытка отправить в полет объект ModelC, как если бы он принадлежал одному из классов ModelA или ModelB. Такой образ действия вряд ли может внушить доверие пассажирам. Проблема здесь заключается не в том, что Airplane::fly ведет себя определенным образом по умолчанию, а в том, что такое наследование допускает неявное применение этой функции для ModelC. К счастью, легко можно предложить подклассам поведение по умолчанию, но не предоставлять его, если они сами об этом не попросят. Трюк состоит в том, чтобы разделить интерфейс виртуальной функции и ее реализацию по умолчанию. Вот один из способов добиться этого: class Airplane { public: virtual void fly(const Airport& destination) = 0; ... protected: void defaultFly(const Airport& destination); }; void Airplane::defaultFly(const Airport& destination) { код по умолчанию, описывающий полет самолета в заданный пункт назначения } Обратите внимание, что функция Airplane::fly преобразовна в чисто виртуальную. Она предоставляет интерфейс для полета. В классе Airplane присутствует и реализация по умолчанию, но теперь она представлена в форме независимой функции defaultFly. Классы, подобные ModelA и ModelB, которые хотят использовать поведение по умолчанию, просто выполняют встроенный вызов defaultFly внутри fly (см. также правило 30 о взаимодействии встраивания и виртуальных функций): class ModelA: public Airplane { public: virtual void fly(const Airport& destination) { defaultFly(destination};} ... }; class ModelB: public Airplane { public: virtual void fly(const Airport& destination) { defaultFly(destination};} ... }; Теперь для класса ModelC возможность случайно унаследовать некорректную реализацию fly исключена, поскольку чисто виртуальная функция в Airplane вынуждает ModelC создавать свою собственную версию fly. class ModelC: public Airplane { public: virtual void fly(const Airport& destination) ... }; void ModelC::fly(const Airport& destination) { код, описывающий полет самолета ModelC в заданный пункт назначения } Эта схема не обеспечивает «защиту от дурака» (программисты все же могут создать себе проблемы копированием/вставкой), но она более надежна, чем исходная. Что же касается функции Airplane::defaultFly, то она объявлена защищенной, поскольку действительно является деталью реализации класса Airplane и производных от него. Пассажиры теперь должны беспокоиться только о том, чтобы улететь, а не о том, как происходит полет. Важно также то, что Airplane::defaultFly объявлена как невиртуальная функция. Это связано с тем, что никакой подкласс не должен ее переопределять – обстоятельство, которому посвящено правило 36. Если бы defaultFly была виртуальной, перед вами снова встала бы та же самая проблема: что, если некоторые подклассы забудут переопределить defaultFly должным образом? Иногда высказываются возражения против идеи разделения функций на обеспечивающие интерфейс и реализацию по умолчанию, такие, например, как fly и defaultFly. Прежде всего, отмечают противники этой идеи, это засоряет пространство имен класса близкими названиями функций. Все же они соглашаются с тем, что интерфейс и реализация по умолчанию должны быть разделены. Как разрешить кажущееся противоречие? Для этого используется тот факт, что производные классы должны переопределять чисто виртуальные функции и при необходимости предоставлять свои собственные реализации. Вот как можно было бы использовать возможность определения чисто виртуальных функций в иерархии Airplane: class Airplane { public: virtual void fly(const Airport& destination) = 0; ... }; void Airplane::fly(const Airport& destination) // реализация чисто { // виртуальной функции код по умолчанию, описывающий полет самолета в заданный пункт назначения } class ModelA: pubic Airplane { public: virtual void fly(const Airport& destination) { Airplane::fly(destination);} ... }; class ModelB: pubic Airplane { public: virtual void fly(const Airport& destination) { Airplane::fly(destination);} ... }; class ModelC: pubic Airplane { public: virtual void fly(const Airport& destination); ... }; void ModelC::fly(const Airport& destination) { код, описывающий полет самолета ModelC в заданный пункт назначения } Это практически такой же подход, как и прежде, за исключением того, что тело чисто виртуальной функции Airplane::fly заменяет собой независимую функцию Airplane::defaultFly. По существу, fly разбита на две основные составляющие. Объявление задает интерфейс (который должен быть использован в производных классах), а определение задает поведение по умолчанию (которое может использоваться производным классом, но только по явному требованию). Однако, производя слияние fly и defaultFly, мы теряем возможность задать для этих функций разные уровни доступа: код, который должен быть защищенным (функция defaultFly), становится открытым (потому что теперь он находится внутри fly). И наконец, пришла очередь невиртуальной функции класса Shape – objectID: class Shape { public: int objectID() const; ... }; Когда функция-член объявлена невиртуальной, не предполагается, что она будет вести себя иначе в производных классах. В действительности невиртуальные функции-члены выражают инвариант относительно специализации, поскольку определяют поведение, которое должно сохраняться независимо от того, как специализируются производные классы. Справедливо следующее: • Цель объявления невиртуальной функции – заставить производные классы наследовать как ее интерфейс, так и обязательную реализацию. Вы можете представлять себе объявление Shape::objectID как утверждение: «Каждый объект Shape имеет функцию, которая дает идентификатор объекта, и этот идентификатор всегда вычисляется одним и тем же способом. Этот способ задается определением функции Shape::objectID, и никакой производный класс не должен его изменять». Поскольку невиртуальная функция определяет инвариант относительно специализации, ее не следует переопределять в производных классах (см. правило 36). Разница в объявлениях чисто виртуальных, просто виртуальных и невиртуальных функций позволяет точно указать, что, по вашему замыслу, должны наследовать производные классы: только интерфейс, интерфейс и реализацию по умолчанию либо интерфейс и обязательную реализацию соответственно. Поскольку эти типы объявлений обозначают принципиально разные вещи, следует тщательно подходить к выбору подходящего варианта при объявлянии функции-члена. При этом вы должны избегать двух ошибок, чаще всего совершаемых неопытными проектировщиками классов. Первая ошибка – объявление всех функций невиртуальными. Это не оставляет возможности для маневров в производных классах; при этом больше всего проблем вызывают невиртуальные деструкторы (см. правило 7). Конечно, нет ничего плохого в проектировании классов, которые не предполагается использовать в качестве базовых. В этом случае вполне уместен набор из одних только невиртуальных функций-членов. Однако очень часто такие классы объявляются либо из-за незнания различий между виртуальными и невиртуальными функциями, либо в результате необоснованного беспокойства по поводу потери производительности при использовании виртуальных функций. Факт остается фактом: практически любой класс, который должен использоваться как базовый, будет содержать виртуальные функции (см. правило 7). Если вы обеспокоены тем, во что обходится использование виртуальных функций, позвольте мне напомнить вам эмпирическое правило «80–20» (см. также правило 30), которое утверждает, что в типичной программе 80 % времени исполнения затрачивается на 20 % кода. Это правило крайне важно, потому что оно означает, что в среднем 80 % ваших функций могут быть виртуальными, не оказывая ощутимого влияния на общую производительность программы. Прежде чем начать беспокоиться о том, можете ли вы позволить себе использование виртуальных функций, убедитесь, что вы имеете дело с теми 20 % программы, для которых ваше решение окажет существенное влияние на производительность. Другая распространенная ошибка – объявление всех функций виртуальными. Иногда это правильно, о чем свидетельствуют, например, интерфейсные классы (см. правило 31). Однако данное решение может также навести на мысль, что у разработчика нет ясного понимания задачи. Некоторые функции не должны переопределяться в производных классах, и в таком случае необходимо недвусмысленно указать на это, объявляя функции невиртуальными. Не имеет смысла делать вид, что ваш класс годится на все случаи жизни, стоит лишь переопределить его функции. Если вы видите необходимость в инвариантности относительно специализации, не бойтесь это признать! Что следует помнить• Наследование интерфейса отличается от наследования реализации. При открытом наследовании производные классы всегда наследуют интерфейсы базовых классов. • Чисто виртуальные функции означают, что наследуется только интерфейс. • Обычные виртуальные функции означают, что наследуются интерфейс и реализация по умолчанию. • Невиртуальные функции означают, что наследуются интерфейс и обязательная реализация. Правило 35: Рассмотрите альтернативы виртуальным функциям Предположим, что вы работаете над видеоигрой и проектируете иерархию игровых персонажей. В вашей игре будут использоваться разные варианты сражений, персонажи могут подвергаться ранениям или иначе терять жизненные силы. Поэтому вы решаете включить в класс функцию-член healthValue, которая возвращает целочисленное значение, показывающее, сколько жизненных сил осталось у персонажа. Поскольку разные персонажи могут вычислять свою жизненную силу по-разному, то представляется естественным объявить функцию healthValue следующим образом: class GameCharacter { public: virtual void healthValue() const; // возвращает жизненную силу персонажа ... // в производных классах можно }; // переопределить Тот факт, что healthValue не объявлена как чисто виртуальная, наводит на мысль, что существует алгоритм вычисления жизненной силы по умолчанию (см. правило 34). Это очевидный подход к проектированию, и в каком-то смысле в очевидности и заключается его слабость. Поскольку решение кажется совершенно естественным, не исключено, что вы забудете уделить должное внимание рассмотрению альтернатив. Чтобы помочь вам выбраться из колеи, рассмотрим некоторые другие подходы к проблеме. Реализация паттерна««Шаблонный метод» с помощью идиомы невиртуального интерфейса Начнем с интересной концепции, которая утверждает, что виртуальные функции почти всегда должны быть закрытыми. Сторонники этой школы предполагают, что правильно было бы оставить функцию-член healthValue открытой, но сделать ее невиртуальной и заставить вызывать закрытую виртуальную функцию, которая и выполнит реальную работу. Назовем эту функцию doHealthValue: class GameCharacter { public: int healthValue() const // производные классы не переопределяют { // эту функцию, см. правило 36 ... // выполнить предварительные действия – // см. ниже int retVal = doHealthValue(); // выполнить реальную работу ... // выполнить завершающие действия – // см. ниже return retVal; } ... private: virtual int doHealthValue() const // производные классы могут { // переопределить эту функцию ... // алгоритм по умолчанию для вычисления } // жизненной силы персонажа }; В этом коде (и ниже в данном правиле) я привожу тела функций в определениях классов. Как следует из правила 30, тем самым они неявно объявляются встроенными. Я поступаю так лишь для того, чтобы смысл кода было проще понять. Описываемый подход к проектированию никак не зависит от того, будут ли функции встроенными или нет. Основная идея этого подхода – дать возможность клиентам вызывать закрытые виртуальные функции опосредованно, через открытые невиртуальные функции-члены – известен под названием идиома невиртуального интерфейса (non-virtual interface idiom – NVI). Это частный случай более общего паттерна проектирования, называемого «Шаблонный метод» (Template Method) (к сожалению, он не имеет никакого отношения к шаблонам C++). Я называю невиртуальную функцию (healthValue) оберткой (wrapper) виртуальной функции. Преимущество идиомы NVI таится в коде, скрытом за комментариями «выполнить предварительные действия» и «выполнить завершающие действия». Подразумевается, что некоторый код гарантированно будет выполнен перед вызовом виртуальной функции, выполняющей реальную работу, и после возврата из нее. Таким образом, обертка настроит контекст перед вызовом виртуальной функции создания, а после возврата произведет очистку. Например, «предварительные действия» могут заключаться в захвате мьютекса, записи в протокол, проверке инвариантов класса и выполнении предусловий и т. п. В состав «завершающих действий» могут входить освобождение мьютекса, проверка постусловий функции, повторная проверка инвариантов класса и т. п. Будет затруднительно проделать все это, если вы позволите клиентам вызывать виртуальную функцию непосредственно. Возможно, вас поразила следующая странность: идиома NVI предполагает, что производные классы-наследники переопределяют закрытые виртуальные функции, которых они и вызывать-то не могут! Но здесь нет противоречия. Переопределяя виртуальную функцию, мы говорим, как должно быть выполнено некоторое действие. Вызов же виртуальной функции определяет момент, когда это действие выполняется. Одно от другого не зависит. Идиома NVI позволяет производным классам переопределить виртуальную функцию и, стало быть, управлять тем, как реализована некоторая функциональность. Базовый же класс оставляет за собой право определять, когда должна быть вызвана функция. Поначалу это может показаться странным, но то, что C++ разрешает в производных классах переопределять закрытые виртуальные функции, вполне разумно. Идиома NVI не требует, чтобы виртуальные функции обязательно были закрытыми. В некоторых иерархиях классов ожидается, что виртуальная функция, переопределенная в производном классе, будем вызывать одноименную функцию из базового класса (как в примере из правила 27). Чтобы такие вызовы были возможны, виртуальная функция должна быть защищенной, а не закрытой. Иногда она даже может быть открытой (как, например, деструкторы в полиморфных базовых классах – см. правило 7), но к этому случаю идиома NVI уже неприменима. Реализация паттерна «Стратегия» посредством указателей на функции Идиома NVI – это интересная альтернатива открытым виртуальным функциям, но с точки зрения проектирования она дает не слишком много. В конце концов, мы по-прежнему используем виртуальные функции для вычисления жизненной силы каждого персонажа. С точки зрения проектирования гораздо более сильным было бы утверждение о том, что вычисление жизненной силы персонажа не зависит от типа персонажа, что такие вычисления вообще не являются свойством персонажа как такового. Например, мы можем потребовать, чтобы конструктору каждого персонажа передавался указатель на функцию, которая вызывалась бы для вычисления его жизненной силы: class GameCharacter; // опережающее объявление // функция алгоритма по умолчанию для вычисления жизненной силы персонажа int defaultHealthCalc(const GameCharacter& gc); class GameCharacter { public: typedef int (*HealthCalcFunc)(const GameCharacter&); explicit GameCharacter(HealthCalcFunc hcf = defaultHealthCalc) : healthFunc(hcf) {} int healthValue() const { return healthFunc(*this);} ... private: HealthCalcFunc healthFunc; }; Это простой пример применения другого распространенного паттерна проектирования – «Стратегия» (Strategy). По сравнению с подходами, основанными на виртуальных функциях в иерархии GameCharacter, он предоставляет некоторые любопытные возможности, повышающие гибкость: • Разные экземпляры персонажей одного и того же типа могут иметь разные функции вычисления жизненной силы. Например: class EvilBadGay: public GameCharacter { public: explicit EvilBadGay(HealthCalcFunc hcf = defaultHealthCalc) : GameCharacter(hcf) {...} ... }; int loseHealthQuickly(const GameCharacter&); // функции вычисления int loseHealthSlowly(const GameCharacter&); // жизненной силы // с разным поведением EvilBadGay ebg1(loseHealthQuickly); // однотипные персонажи EvilBadGay ebg2(loseHealthSlowly); // с разным поведением // относительно здоровья • Функция вычисления жизненной силы для одного и того же персонажа может изменяться во время исполнения. Например, класс GameCharacter мог бы предложить функцию-член setHealthCalculator, которая позволяет заменить текущую функцию вычисления жизненной силы. С другой стороны, тот факт, что функция вычисления жизненной силы больше не является функцией-членом иерархии GameCharacter, означает, что она не имеет специального доступа к внутреннему состоянию объекта, чью жизненную силу вычисляет. Например, defaultHealthCalc не имеет доступа к закрытым частям EvilBadGay. Это не страшно, если жизненная сила персонажа может быть вычислена с помощью его открытого интерфейса, но для максимально точных расчетов может понадобиться доступ к закрытой информации. На самом деле такая проблема может возникать всегда, когда некоторая функциональность выносится из класса наружу (например, из функций-членов в свободные функции, не являющиеся друзьями класса, или в функции-члены другого класса, не дружественного данному). Она будет встречаться в настоящем правиле и далее, потому что все прочие проектные решения, которые нам еще предстоит рассмотреть, тоже включают использование функций, находящихся вне иерархии GameCharacter. Общее правило таково: единственный способ рарешить функциям, не являющимся членами класса, доступ к его закрытой части – ослабить степень инкапсуляции. Например, класс может объявлять функции-нечлены в качестве друзей либо предоставлять открытые функции для доступа к тем частям реализации, которые лучше было бы оставить закрытыми. Имеет ли смысл жертвовать инкапсуляцией ради выгоды от использования указателей на функции вместо виртуальных функций (например, чтобы иметь разные функции жизненной силы для разных объектов и динамически менять их), решать вам в каждом конкретном случае. Реализация паттерна «Стратегия» посредством класса tr::function Если вы привыкли к шаблонам и их применению для построения неявных интерфейсов (см. правило 41), то применение указателей на функции покажется вам не слишком гибким решением. Почему вообще для вычисления жизненной силы нужно обязательно использовать функцию, а не что-то ведущее себя как функция (например, функциональный объект)? Если от функции никуда не деться, то почему не сделать ее членом класса? И почему функция должна возвращать int, а не объект, который можно преобразовать в int? Эти ограничения исчезают, если вместо указателя на функцию (подобную healthFunc) воспользоваться объектом типа tr::function. Как объясняется в правиле 54, такой объект может содержать любую вызываемую сущность (указатель на функцию, функциональный объект либо указатель на функцию-член), чья сигнатура совместима с ожидаемой. Вот пример такого подхода, на этот раз с использованием tr1::function: class GameCharacter; // как раньше int defaultHealthCalc(const GameCharacter& gc); // как раньше class GameCharacter { public: // HealthCalcFunction – это любая вызываемая сущность, которой можно // передать в качестве параметра нечто, совместимое с GameCharacter, // и которая возвращает нечто, совместимое с int; подробности см. ниже typedef std::tr1::function<int (const GameCharacter&)> HealthCalcFunc; explicit GameCharacter(HealthCalcFunc hcf = defaultHealthCalc) : healthFunc(hcf) {} int healthValue() const { return healthFunc(*this);} ... private: HealthCalcFunc healthFunc; }; Как видите, HealthCalcFunc – это typedef, описывающий конкретизацию шаблона tr1::function. А значит, он работает как обобщенный указатель на функцию. Посмотрим внимательнее, как определен тип HealthCalcFunc: std::tr1::function<int (const GameCharacter&)> Здесь я выделил «целевую сигнатуру» данной конкретизации tr1::function. Словами ее можно описать так: «функция, принимающая ссылку на объект типа const GameCharacter и возвращающая int». Объект типа HealthCalcFunc может содержать любую вызываемую сущность, чья сигнатура совместима с заданной. Быть совместимой в данном случае означает, что параметр можно неявно преобразовать в const GameCharacter&, а тип возвращаемого значения неявно конвертируется в int. Если сравнить с предыдущим вариантом дизайна (где GameCharacter включал в себя указатель на функцию), то вы не обнаружите почти никаких отличий. Единственная разница в том, что GameCharacter теперь содержит объект типа tr1::function – обобщенный указатель на функцию. Это изменение так незначительно, что я назвал бы его несущественным, если бы не то обстоятельство, что теперь пользователь получает ошеломляющую гибкость в спецификации функций, вычисляющих жизненную силу: short calcHealth(const gameCharacter&); // функция вычисления // жизненной силы; // она возвращает не int stuct HealthCalculator { // класс функциональных int operator()(const GameCharacter&) const // объектов, вычисляющих {...} // жизненную силу }; class GameLevel { public: float health(const GameCharacter&) const; // функция-член для ... // вычисления жизненной }; // силы; возвращает не int class EvilBadGay: public GameCharacter { // как раньше ... }; class EyeCandyCharacter: public GameCharacter { // другой тип персонажей; ... // предполагается такой же }; // конструктор как // у EvilBadGay EvilBadGay ebg1(calcHealh); // персонаж использует // функцию вычисления // жизненной силы EyeCandyCharacter ecc1(HealthCalculator()); // персонаж использует // функциональный объект // вычисления жизненной // силы GameLevel currentLevel; ... EvilBadGay ebg2( // персонаж использует std::tr1::bind(&GameLevel::health, // функцию-член для currentLevel, // вычисления жизненной _1) // силы; подробности ); // см. ниже Лично я поражаюсь тому, какие удивительные вещи позволяет делать шаблон tr1::function. Если вы не разделяете моих чувств, то не исключено, что просто не понимаете, для чего используется tr1::bind в определении ebg2. Позвольте мне объяснить. Мы хотим сказать, что для вычисления жизненной силы персонажа ebg2 следует использовать функцию-член класса GameLevel. Но из объявления GameLevel::health следует, что она должна принимать один параметр (ссылку на GameCharacter), а на самом деле она принимает два, потому что имеется еще неявный параметр типа GameLevel – тот, на который внутри нее указывает this. Все функции вычисления жизненной силы принимают лишь один параметр: ссылку на персонажа GameCharacter, чья жизненная сила вычисляется. Если мы используем функцию GameLevel::health, то должны каким-то образом «адаптировать» ее, чтобы вместо двух параметров (GameCharacter и GameLevel) она принимала только один (GameCharacter). В этом примере мы хотим для вычисления здоровья ebg2 в качестве параметра типа GameLevel всегда использовать объект currentLevel, поэтому «привязываем» его как первый параметр при вызове GameLevel::health. Именно в этом и заключается смысл вызова tr1::bind: указать, что функция вычисления жизненной силы персонажа ebg2 должна в качестве объекта типа GameLevel использовать currentLevel. Я пропускаю целый ряд подробностей, к примеру: почему «_1» означает «использовать currentLevel в качестве объекта GameLevel при вызове GameLevel::health для ebg2». Эти детали не столь сложны, к тому же они не имеют прямого отношения к основной идее, которую я хочу продемонстрировать, а именно: используя tr1::function вместо указателя на функцию, мы позволяем пользователям применять любую совместимую вызываемую сущность для вычислении жизненной силы персонажа. Впечатляет, не правда ли? «Классический» паттерн «Стратегия» Если вас больше интересуют паттерны проектирования, чем собственно язык C++, то более традиционный подход к реализации паттерна «Стратегия» состоит в том, чтобы сделать функцию вычисления жизненной силы виртуальной функцией-членом в классах, принадлежащих отдельной иерархии. Эта иерархия может выглядеть примерно так: 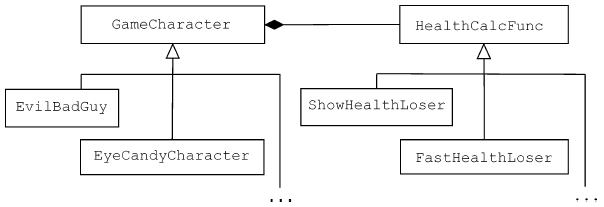 Если вы не знакомы с нотацией UML, поясню: здесь говорится, что GameCharacter – корень иерархии, в которой EvilBadGay и EyeCandyCharacter являются производными классами; HealthCalcFunc – корень иерархии, в которой производными классами являются SlowHealthLooser и FastHealthLooser; и каждый объект типа GameCharacter содержит указатель на объект из иерархии HealthCalcFunc. А вот как структурируется соответствующий код: class GameCharacter; // опережающее объявление class HealthCalcFunc { public: ... virtual int calc(const GameCharacter& gc) const {...} ... }; HealthCalcFunc defaultHealthCalc; class GameCharacter { public: explicit GameCharacter(HealhCalcFunc *phfc = &defaultHealthCalc) :pHealtCalc(pfhc) {} int healthValue() const { return pHealthCalc->calc(*this);} ... private: HealhCalcFunc * pHealtCalc; }; Этот подход привлекателен тем, что программисты, знакомые со «стандартной» реализацией паттерна «Стратегия», сразу видят, что к чему. К тому же он предоставляет возможность модифицировать существующий алгоритм вычисления жизненной силы путем добавления производных классов в иерархию HealthCalcFunc. Резюме Из этого правила вы должны извлечь одну практическую рекомендацию: размышляя над тем, как решить стоящую перед вами задачу, имеет смысл рассматривать не только виртуальные функции. Вот краткий перечень предложенных альтернатив: • Применение идиомы невиртуального интерфейса (NVI), варианта паттерна проектирования «Шаблонный Метод». Смысл ее в том, чтобы обернуть открытыми невиртуальными функциями-членами вызовы менее доступных виртуальных функций. • Замена виртуальных функций членами данных – указателями на функции. Это упрощенное проявление паттерна проектирования «Стратегия». • Замена виртуальных функций членами данных – tr1::function. Это позволяет применять любую вызываемую сущность, сигнатура которой совместима с той, что вам нужна. Это тоже форма паттерна проектирования «Стратегия». • Замена виртуальных функций из одной иерархии виртуальными функциями из другой иерархии. Это традиционная реализация паттерна проектирования «Стратегия». Это не исчерпывающий список альтернатив виртуальным функциям, но его должно хватить, чтобы убедить вас в том, что такие альтернативы существуют. Более того, из сравнения их достоинств и недостатков должны быть ясно, что рассматривать их стоит. Чтобы не застрять в колее на дороге объектно-ориентированного проектирования, стоит время от времени резко поворачивать руль. Путей много. Потратьте время на знакомство с ними. Что следует помнить• К числу альтернатив виртуальным функциям относятся идиома NVI и различные формы паттерна проектирования «Стратегия». Идиома NVI сама по себе – это пример реализации паттерна «Шаблонный Метод». • Недостаток переноса функциональности из функций-членов вовне класса заключается в том, что функциям-нечленам недостает прав доступа к закрытым членам класса. • Объекты tr1::function работают как обобщенные указатели на функции. Такие объекты поддерживают все вызываемые сущности, совместимые с сигнатурой целевой функции. Правило 36: Никогда не переопределяйте наследуемые невиртуальные функции Предположим, я сообщаю вам, что класс D открыто наследует классу B и что в классе B определена открытая функция-член mf. Ее параметры и тип возвращаемого значения не важны, поэтому давайте просто предположим, что это void. Другими словами, я говорю следующее: class B { public: void mf(); ... }; class D: public B {...}; Даже ничего не зная о B, D или mf, имея объект x типа D, D x; // x – объект типа D вы, наверное, удивитесь, когда код B *pB = &x; // получить указатель на x PB->mf(); // вызвать mf с помощью ука поведет себя иначе, чем D *pD = &x; // получить указатель на x PD->mf(); // вызвать mf через указатель Ведь в обоих случаях вы вызываете функцию-член объекта x. Поскольку вы имеете дело с одной и той же функцией и одним и тем же объектом, поведение в обоих случаях должно быть одинаково, не так ли? Да, так должно быть, но не всегда бывает. В частности, вы получите иной результат, если mf невиртуальна, а D определяет собственную версию mf: class D: public B { public: void mf(); // скрывает B:mf; см. правило 33 ... }; PB->mf(); // вызвать B::mf PD->mf(); // вызвать D::mf Причина такого «двуличного» поведения заключается в том, что невиртуальные функции, подобные B::mf и D::mf, связываются статически (см. правило 37). Это означает, что когда pB объявляется как указатель на объект тип B, невиртуальные функции, вызываемые посредством pB, – это всегда функции, определения которых даны в классе B, даже если pB, как в данном примере, указывает на объект класса, производного от B. С другой стороны, виртуальные функции связываются динамически (снова см. правило 37), поэтому для них не существует такой проблемы. Если бы функция mf была виртуальной, то ее вызов как посредством pB, так и посредством pD означал бы вызов D::mf, потому в действительности pB и pD указывают на объект типа D. В итоге, если вы пишете класс D и переопределяете невиртуальную функцию mf, наследуемую от класса B, есть вероятность, что объекты D будут вести себя совершенно непредсказуемо. В частности, любой конкретный объект D может вести себя при вызове mf либо как B, либо как D, причем определяющим фактором будет не тип самого объекта, а лишь тип указателя на него. При этом ссылки в этом отношении ведут себя ничем не лучше указателей. Это все, что относится к «прагматической» аргументации. Теперь, я уверен, требуется некоторое теоретическое обоснование запрета на переопределение наследуемых невиртуальных функций. С удовольствием его представлю. В правиле 32 объясняется, что открытое наследование всегда означает «является разновидностью», а в правиле 34 говорится, почему объявление невиртуальной функции в классе определяет инвариант относительно специализации этого класса. Если вы примените эти наблюдения к классам B и D и невиртуальной функции B: mf, то получите следующее: • Все, что применимо к объектам B, применимо и к объектам D, поскольку каждый объект D также является объектом B; • Подклассы B должны наследовать как интерфейс, так и реализацию mf, потому что mf невиртуальна в B. Теперь, если D переопределяет mf, возникает противоречие. Если класс D действительно должен содержать отличную от B реализацию mf и если каждый объект B, являющийся разновидностью B, действительно должен использовать реализацию mf из B, тогда неверно, что каждый объект класса D является разновидностью B. В этом случае D не должен открыто наследовать B. С другой стороны, если класс D действительно должен открыто наследовать B и если D действительно должен содержать реализацию mf, отличную от B, тогда неверно, что mf является инвариантом относительно специализации B. В этом случае mf должна быть виртуальной. И наконец, если каждый объект класса D действительно является разновидностью B и если mf – действительно инвариант относительно специализации B, тогда D, по правде говоря, не нуждается в переопределении mf и не должен пытаться это делать. Независимо от того, какой из аргументов применим в вашем случае, чем-то придется пожертвовать, но при любых обстоятельствах запрет на переопределение наследуемых невиртуальных функций остается в силе. Если при чтении этого правила у вас возникло ощущение «дежа вю», то, наверное, вы просто вспомнили правило 7, где я объяснял, почему деструкторы в полиморфных базовых классах должны быть виртуальными. Если вы не следуете этому совету (то есть объявляете невиртуальные деструкторы в полиморфных базовых классах), то нарушаете и требование, изложенное в настоящем правиле, потому что все производные классы автоматически переопределяют унаследованную невиртуальную функцию – деструктор базового класса. Это верно даже для производных классов, в которых нет деструкторов, потому что, как объясняется в правиле 5, компилятор генерирует деструктор автоматически, если вы не определяете его сами. По существу, правило 7 – это лишь частный случай настоящего правила, хотя и заслуживает отдельного внимания и рекомендаций по применению. Что следует помнить• Никогда не переопределяйте наследуемые невиртуальные функции. Правило 37: Никогда не переопределяйте наследуемое значение аргумента функции по умолчанию Давайте с самого начала упростим обсуждение. Есть только два типа функций, которые можно наследовать: виртуальные и невиртуальные. Но переопределять наследуемые невиртуальные функции в любом случае ошибочно (см. правило 36), поэтому мы вполне можем ограничить наше обсуждение случаем наследования виртуальной функции со значением аргумента по умолчанию. В этих обстоятельствах мотивировка настоящего правила становится достаточно очевидной: виртуальные функции связываются динамически, а значения аргументов по умолчанию – статически. Что это значит? Вы говорите, что уже позабыли, в чем заключается разница между статическим и динамическим связыванием? (Кстати, статическое связывание называют еще ранним связыванием, а динамическое – поздним.) Что ж, давайте освежим вашу память. Статический тип объекта – это тип, объявленный вами в тексте программы. Рассмотрим следующую иерархию классов: // классы для представления геометрических фигур class Shape { public: enum ShapeColor { Red, Green, Blue }; // все фигуры должны предоставлять функцию для рисования virtual void draw(ShapeColor color = Red) const = 0; ... }; class Rectangle: public Shape { public: // заметьте, другое значение параметра по умолчанию – плохо! virtual void draw(ShapeColor color = Green) const; ... }; class Circle: public Shape { public: virtual void draw(ShapeColor color) const; ... }; Графически это можно представить так: 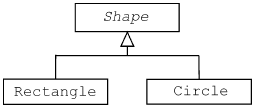 Теперь рассмотрим следующие указатели: Shape *ps; // статический тип – Shape* Shape *pc = new Circle; // статический тип – Shape* Shape *pr = new Rectangle; // статический тип – Shape* В этом примере ps, pc и pr объявлены как указатели на Shape, так что для всех них он и будет выступать в роли статического типа. Отметим, что не совершенно безразлично, на что они указывают в действительности, – независимо от этого они имеют статический тип Shape*. Динамический тип объекта определяется типом того объекта, на который он ссылается в данный момент. Иными словами, динамический тип определяет поведение объекта. В приведенном выше примере динамический тип pc – это Circle*, а динамический тип pr – Recangle*. Что касается ps, то он не имеет динамического типа, потому что не указывает ни на какой объект (пока). Динамические типы, как следует из их названия, могут изменяться в процессе работы программы, обычно вследствие присваивания: ps = pc; // динамический тип ps теперь Circle* ps = pr; // динамический тип ps теперь Rectangle* Виртуальные функции связываются динамически, то есть динамический тип вызывающего объекта определяет, какая конкретная функция вызывается: pc->draw(Shape::Red); // вызывается Circle::draw(Shape::Red) pr->draw(Shape::Red); // вызывается Rectangle::draw(Shape::Red) Я знаю, что все это давно известно, и вы, несомненно, разбираетесь в виртуальных функциях. Самое интересное начинается, когда мы подходим к виртуальным функциям с аргументами, принимающими значения по умолчанию, поскольку, как я уже сказал, виртуальные функции связываются динамически, а аргументы по умолчанию – статически. Следовательно, вы можете прийти к тому, что будете вызывать виртуальную функцию, определенную в производном классе, но при этом использовать аргументы по умолчанию, заданные в базовом классе: pr->draw(); // вызывается Rectangle::draw(Shape::Red)! В этом случае динамический тип pr – это Rectangle*, поэтому, как вы и ожидали, вызывается виртуальная функция класса Rectangle. Для функции Rectangle::draw значение аргумента по умолчанию – Green. Но поскольку статический тип pr – Shape*, то значения аргумента по умолчанию берутся из класса Shape, а не Rectangle! В результате получаем вызов, состоящий из странной, совершенно неожиданной комбинации объявлений draw из классов Shape и Rectangle. Тот факт, что ps, pc и pr являются указателями, не играет никакой роли. Будь они ссылками, результат остался бы таким же. Важно лишь, что draw – виртуальная функция, и значение по умолчанию одного из ее аргументов переопределено в производном классе. Почему C++ настаивает на таком диковинном поведении? Ответ на этот вопрос связан с эффективностью исполнения программы. Если бы значения аргументов по умолчанию связывались динамически, то компилятору пришлось бы найти способ во время исполнения определять, какое значение по умолчанию должно быть у параметра виртуальной функции, что медленнее и технически сложнее нынешнего механизма. Решение было принято в пользу скорости и простоты реализации, в результате чего вы можете пользоваться преимуществами эффективного выполнения кода программы. Но если не последуете совету, изложенному в настоящем правиле, то программа будет вести себя нелогично. Все это прекрасно, но посмотрите, что получится, если, пытаясь следовать этому правилу, вы включите аргументы со значениями по умолчанию в функцию-член, объявленную и в базовом, и в производном классах: class Shape { public: enum ShapeColor { Red, Green, Blue }; virtual void draw(ShapeColor color = Red) const = 0; ... }; class Rectangle: public Shape { public: virtual void draw(ShapeColor color = Red) const; ... }; Гм, дублирование кода! Хуже того: дублирование кода с зависимостями: если значение аргумента по умолчанию изменится в Shape, придется изменить его и во всех производных классах. В противном случае дело закончится переопределением наследуемого значения по умолчанию. Что делать? Когда у вас возникает проблема с тем, чтобы заставить виртуальную функцию вести себя так, как вы хотите, то благоразумнее рассмотреть альтернативные решения, и в правиле 35 таких альтернатив приведено немало. Одна из них – идиома невиртуального интерфейса (NVI): определить в базовом классе открытую невиртуальную функцию, которая вызывает закрытую виртуальную функцию, переопределяемую в подклассах. В данном случае можно предложить невиртуальную функцию с аргументом по умолчанию и виртуальную функцию, которая выполняет всю реальную работу: class Shape { public: enum ShapeColor( Red, Green, Blue }; void draw(ShapeColor color = Red) const // теперь – невиртуальная { doDraw(color); // вызов виртуальной функции } ... private: virtual void doDraw(ShapeColor color) const = 0; // реальная работа }; // выполняется // в этой функции class Rectangle: public Shape { public: ... private: virtual void doDraw(ShapeColor color) const // обратите внимание ... // на отсутствие у аргумента }; // значения по умолчанию Поскольку невиртуальные функции никогда не должны переопределяться в производных классах (см. правило 36), то ясно, что при таком подходе значение по умолчанию для параметра color функции draw всегда будет Red. Что следует помнить• Никогда не переопределяйте наследуемые значения аргументов по умолчанию, потому что аргументы по умолчанию связываются статически, тогда как виртуальные функции – а только их и можно переопределять, – динамически. Правило 38: Моделируйте отношение «содержит» или «реализуется посредством» с помощью композиции Композиция – это отношение между типами, которое возникает тогда, когда объект одного типа содержит в себе объекты других типов. Например: class Address {...}; // адрес проживания class PhoneNumber {...}; class Person { public: ... private: std::string name; // вложенный объект Address address; // то же PhoneNumber voiceNumber; // то же PhoneNumber faxNumber; // то же }; В данном случае объекты класса Person включают в себя объекты классов string, Address и PhoneNumber. Термин композиция имеет ряд синонимов, например: вложение, агрегирование или встраивание. В правиле 32 объясняется, что открытое наследование означает «класс является разновидностью другого класса». У композиции тоже есть семантика, даже две: «содержит» или «реализуется посредством». Дело в том, что в своих программах вы имеете дело с двумя различными областями. Некоторые программные объекты описывают сущности из моделируемого мира: людей, автомобили, видеокадры и т. п. Такие объекты являются частью предметной области. Другие объекты возникают как часть реализации, например: буферы, мьютексы, деревья поиска и т. д. Они относятся к области реализации, свойственной для вашего приложения. Когда отношение композиции возникает между объектами из предметной области, оно имеет семантику «реализовано посредством». Вышеприведенный класс Person демонстрирует отношение типа «содержит». Объект Person имеет имя, адрес, номера телефона и факса. Нельзя сказать, что человек «есть разновидность» имени или что человек «есть разновидность» адреса. Можно сказать, что человек «имеет» («содержит») имя и адрес. Большинство людей не испытывают затруднений при проведении подобных различий, поэтому путаница между ролями «является» и «содержит» возникает сравнительно редко. Чуть сложнее провести различие между отношениями «является» и «реализуется посредством». Например, предположим, что вам нужен шаблон для классов, представляющих множества произвольных объектов, то есть наборов без дубликатов. Поскольку повторное использование – прекрасная вещь, то сразу возникает желание обратиться к шаблону set из стандартной библиотеки. В конце концов, зачем писать новый шаблон, когда есть возможность использовать уже готовый? К сожалению, реализации set обычно влекут за собой накладные расходы – по три указателя на элемент. Связано это с тем, что множества обычно реализованы в виде сбалансированных деревьев поиска, гарантирующих логарифмическое время поиска, вставки и удаления. Когда быстродействие важнее, чем объем занимаемой памяти, это вполне разумное решение, но конкретно для вашего приложения выясняется, что экономия памяти более существенна. Поэтому стандартный шаблон set для вас неприемлем. Похоже, нужно писать свой собственный. Тем не менее повторное использование – прекрасная вещь. Будучи экспертом в области структур данных, вы знаете, что среди многих вариантов реализации множеств есть и такой, который базируется на применении связанных списков. Вы также знаете, что в стандартной библиотеке C++ есть шаблон list, поэтому решаете им воспользоваться (повторно). В частности, вы решаете, что создаваемый вами шаблон Set должен наследовать от list. То есть Set<T> будет наследовать list<T>. В итоге в вашей реализации объект Set будет выступать как объект list. Соответственно, вы объявляете Set следующим образом: template<typename T> // неправильный способ использования class Set: public std::list<T> {...}; // list для определения Set До сих пор все вроде бы шло хорошо, но, если присмотреться, в код вкралась ошибка. Как объясняется в правиле 32, если D является разновидностью B, то все, что верно для B, должно быть верно также и для D. Однако объект list может содержать дубликаты, поэтому если значение 3051 вставляется в list<int> дважды, то список будет содержать две копии 3051. Напротив, Set не может содержать дубликатов, поэтому, если значение 3051 вставляется в Set<int> дважды, множество будет содержать лишь одну копию данного значения. Следовательно, утверждение, что Set является разновидностью list, ложно: ведь некоторые положения, верные для объектов list, неверны для объектов Set. Из-за этого отношение между этими двумя классами не подходит под определение «является», открытое наследование – неправильный способ моделирования этой взаимосязи. Правильный подход основан на понимании того факта, что объект Set может быть реализован посредством объекта list: template<typename T> // правильный способ использования list class Set { // для определения Set public: bool member(const T& item) const; void insert(const T& item); void remove(const T& item); std::size_t size() const; private: std::list<T> rep; // представление множества }; Функции-члены класса Set могут опереться на функциональность, предоставляемую list и другими частями стандартной библиотеки, поэтому их реализацию нетрудно написать, коль скоро вам знакомы основы программирования с применением библиотеки STL: template<typename T> bool Set<T>::member(const T& item) const { return std::find(rep.begin(), rel.end(), item) != rep.end(); } template<typename T> void Set<T>::insert(const T& item) { if(!member(item)) rep.push_back(item); } template<typename T> void Set<t>::remove(const T& item) { typename std::list<T>::iterator it = // см. в правиле 42 std::find(rep.begin(), rep.end(), item); // информацию о “typename” if(it != rep.end()) rep.erase(it); } template<typename T> std::size_t Set<T>::size() const { return rep.size(); } Эти функции достаточно просты, чтобы стать кандидатами для встраивания, хотя перед принятием окончательного решения стоит еще раз прочитать правило 30. Стоит отметить, что интерфейс Set лучше отвечал бы требованиям правила 18 (проектировать интерфейсы так, чтобы их легко было использовать правильно и трудно – неправильно), если бы он следовал соглашениям, принятым для STL-контейнеров, но для этого пришлось бы добавить в класс Set столько кода, что в нем потонула бы основная идея: проиллюстрировать взаимосвязь между Set и list. Поскольку тема настоящего правила – именно эта взаимосвязь, то мы пожертвуем совместимостью с STL ради наглядности. Недостатки интерфейса Set не должны, однако, затенять тот неоспоримый факт, что отношение между классами Set и list – не «является» (как это вначале могло показаться), а «реализовано посредством». Что следует помнить• Семантика композиции кардинально отличается от семантики открытого наследования. • В предметной области композиция означает «содержит». В области реализации она означает «реализовано посредством». Правило 39: Продумывайте подход к использованию закрытого наследования В правиле 32 показано, что C++ рассматривает открытое наследование как отношение типа «является». В частности, говорится, что компиляторы, столкнувшись с иерархией, где класс Student открыто наследует классу Person, неявно преобразуют объект класса Student в объект класса Person, если это необходимо для вызова функций. Очевидно, стоит еще раз привести фрагмент кода, заменив в нем открытое наследование закрытым: class Person {...} class Student: private Person {...} // теперь наследование закрытое void eat(const Person& p); // все люди могут есть void study(const Student& s); // только студенты учатся Person p; // p – человек (Person) Student s; // s – студент (Student) eat(p); // нормально, p – типа Person eat(s); // ошибка! Student не является объектом // Person Ясно, что закрытое наследование не означает «является». А что же тогда оно означает? «Стоп! – восклицаете вы. – Прежде чем говорить о значении, давайте поговорим о поведении. Как ведет себя закрытое наследование?» Первое из правил, регламентирующих закрытое наследование, вы только что наблюдали в действии: в противоположность открытому наследованию компиляторы в общем случае не преобразуют объекты производного класса (такие как Student) в объекты базового класса (такие как Person). Вот почему вызов eat для объекта s ошибочен. Второе правило состоит в том, что члены, наследуемые от закрытого базового класса, становятся закрытыми, даже если в базовом классе они были объявлены как защищенные или открытые. Это то, что касается поведения. А теперь вернемся к значению. Закрытое наследование означает «реализовано посредством…». Делая класс D закрытым наследником класса B, вы поступаете так потому, что заинтересованы в использовании некоторого когда, уже написанного для B, а не потому, что между объектами B и D существует некая концептуальная взаимосвязь. Таким образом, закрытое наследование – это исключительно прием реализации. (Вот почему все унаследованное от закрытого базового класса становится закрытым и в вашем классе: это не более чем деталь реализации). Используя терминологию из правила 34, можно сказать, что закрытое наследование означает наследование одной только реализации, без интерфейса. Если D закрыто наследует B, это означает, что объекты D реализованы посредством объектов B, и ничего больше. Закрытое наследование ничего не означает в ходе проектирования программного обеспечения и обретает смысл только на этапе реализации. Утверждение, что закрытое наследование означает «реализован посредством», вероятно, слегка вас озадачит, поскольку в правиле 38 указывалось, что композиция может означать то же самое. Как же сделать выбор между ними? Ответ прост: используйте композицию, когда можете, а закрытое наследование – когда обязаны так поступить. А в каких случаях вы обязаны использовать закрытое наследование? В первую очередь тогда, когда на сцене появляются защищенные члены и/или виртуальные функции, хотя существуют также пограничные ситуации, когда соображения экономии памяти могут продиктовать выбор в пользу закрытого наследования. Предположим, что вы работаете над приложением, в котором есть объекты класса Widget, и решили как следует разобраться с тем, как они используются. Например, интересно не только знать, насколько часто вызываются функции-члены Widget, но еще и как частота обращений к ним изменяется во времени. Программы, в которых есть несколько разных фаз исполнения, могут вести себя по-разному в каждой фазе. Например, функции, используемые компилятором на этапе синтаксического анализа, значительно отличаются от функций, вызываемых во время оптимизации и генерации кода. Мы решаем модифицировать класс Widget так, чтобы отслеживать, сколько раз вызывалась каждая функция-член. Во время исполнения мы будем периодически считывать эту информацию, возможно, вместе со значениями каждого объекта Widget и другими данными, которые сочтем необходимым. Для этого понадобится установить таймер, который будет извещать нас о том, когда наступает время собирать статистику использования. Предпочитая повторное использование существующего кода написанию нового, мы тщательно просмотрим наш набор инструментов и найдем следующий класс: class Timer { public: explicit Timer(int tickFrequency); virtual void onTick() const; // автоматически вызывается // при каждом тике ... }; Это как раз то, что мы искали. Объект Timer можно настроить для срабатывания с любой частотой, и при каждом «тике» будет вызываться виртуальная функция. Мы можем переопределить эту виртуальную функцию так, чтобы она проверяла текущее состояние Widget. Отлично! Для того чтобы класс Widget переопределял виртуальную функцию Timer, он должен наследовать Timer. Но открытое наследование в данном случае не подходит. Ведь Widget не является разновидностью Timer. Пользователи Widget не должны иметь возможности вызывать onTick для объекта Widget, потому что эта функция не является частью концептуального интерфейса этого класса. Если разрешить вызов подобной функции, то пользователи получат возможность работать с интерфейсом Widget некорректно, что очевидно нарушает рекомендацию из правила 18 о том, что интерфейсы должно быть легко применять правильно и трудно – неправильно. Открытое наследование в данном случае не подходит. Потому мы будем наследовать закрыто: class Widget: private Timer { private: virtual void onTick() const; // просмотр данных об использовании ... // Widget и т. п. }; Благодаря закрытому наследованию открытая функция onTick класса Timer становится закрытой в Widget, и после переопределения мы ее такой и оставим. Опять же, если поместить onTick в секцию public, то это введет в заблуждение пользователей, заставляя их думать, будто ее можно вызвать, а это идет вразрез с правилом 18. Это неплохое решение, но стоит отметить, что закрытое наследование не является здесь строго необходимым. Никто не мешает вместо него использовать композицию. Мы просто объявим закрытый вложенный класс внутри Widget, который будет открыто наследовать классу Timer и переопределять onTick, а затем поместим объект этого типа внутрь Widget. Вот эскиз такого подхода: 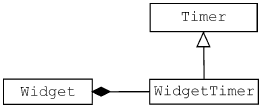 class Widget { private: class WidgetTimer: public Timer { public: virtual void onTick() const; ... }; WidgetTimer timer; ... }; Этот дизайн сложнее того, что использует только закрытое наследование, потому что здесь используются и открытое наследование, и композиция, а ко всему еще и новый класс (WidgetTimer). Честно говоря, я показал этот вариант в первую очередь для того, чтобы напомнить о существовании различных подходов к решению одной задачи. Стоит привыкать к тому, чтобы не ограничиваться единственным решением (см. также правило 35). Тем не менее я могу представить две причины, по которым иногда имеет смысл предпочесть открытое наследование в сочетании с композицией закрытому наследованию. Во-первых, вы можете спроектировать класс Widget так, чтобы ему можно было наследовать, но при этом запретить производным классам переопределять функцию onTick. Если Widget наследуется от Timer, то это невозможно, даже в случае закрытого наследования. (Напомню, что согласно правилу 35 производные классы могут переопределять виртуальные функции, даже если не могут вызывать их). Но если WidgetTimer – это закрытый класс внутри Widget, который наследует Timer, то производные от Widget классы не имеют доступа к WidgetTimer, а значит, не могут ни наследовать ему, ни переопределять его виртуальные функции. Если вам приходилось программировать на языках Java или C# и вы не обратили внимания на то, как можно запретить производным классам переопределять функции базового (с помощью ключевого слова final в Java или sealed в C#), то теперь вы знаете, как добиться примерно того же эффекта в C++. Во-вторых, вы можете захотеть минимизировать зависимости Widget на этапе компиляции. Если Widget наследует классу Timer, то определение Timer должно быть доступно во время компиляции Widget, поэтому файл, определяющий Widget, вероятно, должен содержать директиву #include "Timer.h". С другой стороны, если WidgetTimer вынести из Widget, а в Widget оставить только указатель на WidgetTimer, тогда Widget сможет обойтись простым объявлением класса WidgetTimer; так что необходимость включать заголовочный файл для Timer будет устранена. Для больших систем такая развязка может оказаться важной. Подробнее о минимизации зависимостей на этапе компиляциии см. правило 31. Я уже отмечал, что закрытое наследование удобно прежде всего тогда, когда предполагаемым производным классам нужен доступ к защищенным частям базового класса или у них может возникнуть потребность в переопределении одной или более виртуальных функций, но концептуальное отношение между этими классами выражается не словами «является разновидностью», а «реализован посредством». Я также говорил, что существуют ситуации, в частности, связанные с оптимизацией использования памяти, когда закрытое наследование оказывается предпочтительнее композиции. Граничный случай – действительно граничный: речь идет о классах, в которых вообще нет никаких данных. Такие классы не имеют ни нестатических членов-данных, ни виртуальных функций (поскольку наличие этих функций означает добавление указателя vptr в каждый объект – см. правило 7), ни виртуальных базовых классов (поскольку в этом случае тоже имеют место дополнительные расходы памяти – см. правило 40). Концептуально, объекты таких пустых классов вообще не занимают места, потому что в них не хранится никаких данных. Однако есть технические причины, по которым C++ требует, чтобы любой автономный объект должен иметь ненулевой размер, поэтому для следующих объявлений: class Empty {}; // не имеет данных, поэтому объекты // не должны занимать памяти class HoldsAnInt { // память, по идее, нужна только для int private: int x; Empty e; // не должен занимать память }; оказывается, что sizeof(HoldsAnlnt) > sizeof(int); член данных Empty занимает какую-то память. Для большинства компиляторов sizeof(Empty) будет равно 1, потому что требование C++ о том, что не должно быть объектов нулевой длины, обычно удовлетворяется молчаливой вставкой одного байта (char) в такой «пустой» объект. Однако из-за необходимости выравнивания (см. правило 50) компилятор может оказаться вынужден дополнить классы, подобные HoldsAnInt, поэтому вполне вероятно, что размер объектов HoldsAnInt увеличится больше чем на char, скорее всего, речь может идти о росте на размер int. На всех компиляторах, где я тестировал, происходило именно так. Возможно, вы обратили внимание, что, говоря о ненулевом размере, я упомянул «автономные» объекты. Это ограничение не относится к тем частям производного класса, которые унаследованы от базового, поскольку они уже не считаются «автономными». Если вы наследуете Empty вместо того, чтоб включать его, class HoldsAnInt: private Empty { private: int x; }; то почти наверняка обнаружите, что sizeof(HoldsAnlnt) = sizeof(int). Это явление известно как оптимизация пустого базового класса (empty base optimization – EBO), и оно реализовано во всех компиляторах, которые я тестировал. Если вы разрабатываете библиотеку, пользователям которой небезразлично потребление памяти, то знать о EBO будет полезно. Но имейте в виду, что в общем случае оптимизация EBO применяется только для одиночного наследования. Действующие в C++ правила размещения объектов в памяти обычно делают невозможной такую оптимизацию, если производный класс имеет более одного базового. На практике «пустые» классы на самом деле не совсем пусты. Хотя они и не содержат нестатических данных-членов, но часто включают typedefbi, перечисления, статические члены-данные, или невиртуальные функции. В библиотеке STL есть много технически пустых классов, которые содержат полезные члены (обычно typedef). К их числу относятся, в частности, базовые классы unary_function и binary_function, которым обычно наследуют классы определяемых пользователями функциональных объектов. Благодаря широкому распространению реализаций EBO такое наследование редко увеличивает размеры производных классов. Но вернемся к основам. Большинство классов не пусты, поэтому EBO редко может служить оправданием закрытому наследованию. Более того, в большинстве случаев наследование выражает отношение «является», а это признак открытого, а не закрытого наследования. Как композиция, так и закрытое наследование выражают отношение «реализован посредством», но композиция проще для понимания, поэтому использует ее всюду, где возможно. Закрытое наследование чаще всего оказывается разумной стратегией проектирования, когда вы имеете дело с двумя классами, не связанными отношением «является», причем один из них либо нуждается в доступе к защищенным членам другого, либо должен переопределять одну или несколько виртуальных функций последнего. И даже в этом случае мы видели, что сочетание открытого наследования и композиции часто помогают реализовать желаемое поведение, хотя и ценой некоторого усложнения. Говоря о продумывании подхода к применению закрытого наследования, я имею в виду, что прибегать к нему стоит лишь тогда, когда рассмотрены все другие альтернативы и выяснилось, что это лучший способ выразить отношение между двумя классами в вашей программе. Что следует помнить• Закрытое наследование означает «реализован посредством». Обычно этот вариант хуже композиции, но все же приобретает смысл, когда производный класс нуждается в доступе к защищенным членам базового класса или должен переопределять унаследованные виртуальные функции. • В отличие от композиции, закрытое наследование позволяет проводить оптимизацию пустого базового класса. Это может оказаться важным для разработчиков библиотек, которые стремятся минимизировать размеры объектов. Правило 40: Продумывайте подход к использованию множественного наследования Когда речь заходит о множественном наследовании (multiple inheritance – MI), сообщество разработчиков на C++ разделяется на два больших лагеря. Одни полагают, что раз одиночное исследование (SI) – это хорошо, то множественное наследование должно быть еще лучше. Другие говорят, что одиночное наследование – это на самом деле хорошо, а множественное не стоит хлопот. В этом правиле мы постараемся разобраться в обеих точках зрения. Первое, что нужно уяснить для себя о множественном наследовании, – это появляющаяся возможность унаследовать одно и то же имя (функции, typedef и т. п.) от нескольких базовых классов. Это может стать причиной неоднозначности. Например: class BorrowableItem { // нечто, что можно позаимствовать // из библиотеки public: void checkOut(); ... }; class ElectronicGadget { private: bool checkOut() const; // выполняет самотестирование, возвращает ... // признак успешности теста }; class MP3Player: // здесь множественное наследование (в некоторых public BorrowableItem, // библиотеках реализована функциональность, public ElectronicGadget // необходимая для MP3-плееров) {...} // определение класса не важно MP3Player mp; mp.checkout(); // неоднозначность! какой checkOut? Отметим, что в этом примере вызов функции checkOut неоднозначен, несмотря на то что доступна лишь одна из двух функций. (checkOut открыта в классе Borrowableltem и закрыта в классе ElectronicGadget.) И это согласуется с правилами разрешения имен перегруженных функций в C++: прежде чем проверять права доступа, C++ находит функцию, которая наиболее соответствует вызову. И только потом проверяется, доступна ли наиболее подходящая функция. В данном случае оба варианта функции checkOut одинаково хорошо соответствуют вызову, то есть ни одна из них не подходит лучше, чем другая. А стало быть, до проверки доступности ElectronicGadget::checkOut дело не доходит. Чтобы разрешить неоднозначность, вы можете указать имя базового класса, чью функцию нужно вызвать: mp.BorrowableItem::checkOut(); // вот какая checkOut мне нужна! Вы, конечно, также можете попытаться явно вызвать ElectronicGadget::check-Out, но тогда вместо ошибки неоднозначности получите другую: «вы пытаетесь вызвать закрытую функцию-член». Множественное наследование просто означает наследование более, чем от одного базового класса, но вполне может возникать также и в иерархиях, содержащих более двух уровней. Это может привести к «ромбовидному наследованию»: 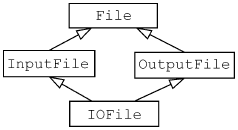 class File {...}; class InputFile: public File {...}; class OutputFile: public File {...}; class IOFile: public InputFile, public OutputFile {...}; Всякий раз, когда вы строите иерархию наследования, в которой от базового класса к производному ведет более одного пути (как в приведенном примере: от File к IOFile можно пройти как через InputFile, так и через OutputFile), вам приходится сталкиваться с вопросом о том, должны ли данные-члены базового класса дублироваться в объекте подкласса столько раз, сколько имеется путей. Например, предположим, что в классе File есть член filename. Сколько копий этого поля должно быть в классе IOFile? С одной стороны, он наследует по одной копии от каждого из своих базовых классов, следовательно, всего будет два члена данных с именем fileName. С другой стороны, простая логика подсказывает, что объект IOFile имеет только одно имя файла, поэтому поле fileName, наследуемое от двух базовых классов, не должно дублироваться. C++ не принимает ничью сторону в этом споре. Он успешно поддерживает оба варианта, хотя по умолчанию предполагается дублирование. Если это не то, что вам нужно, сделайте класс, содержащий данные (то есть File), виртуальным базовым классом. Для этого все непосредственные потомки должны использовать виртуальное наследование: 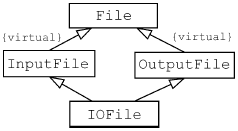 class File {...}; class InputFile: virtual public File {...}; class OutputFile: virtual public File {...}; class IOFile: public InputFile, public OutputFile {...}; В стандартной библиотеке C++ есть похожая иерархия, только классы в ней являются шаблонными и называются basic_ios, basic_istream, basic_ostream и basic_iostream, в не File, InputFile, OutputFile и IOFile. С точки зрения корректности, открытое наследование всегда должно быть виртуальным. Если бы это была единственная точка зрения, то правило было бы простым: всякий раз при открытом наследовании используйте виртуальное открытое наследование. К сожалению, корректность – не единственное, что нужно принимать во внимание. Чтобы избежать дублирования унаследованных членов, компилятору приходится прибегать к нетривиальным трюкам, из-за чего размер объектов классов, использующих множественное виртуальное наследование, обычно оказывается больше по сравнению со случаем, когда виртуальное наследование не используется. Доступ к данным-членам виртуальных базовых классов также медленнее, чем к данным невиртуальных базовых классов. Детали реализации зависят от компилятора, но суть остается неизменной: виртуальное наследование требует затрат. Оно обходится не бесплатно еще и по другой причине. Правила, определяющие инициализацию виртуальных базовых классов, сложнее и интуитивно не так понятны, как правила для невиртуальных базовых классов. Ответственность за инициализацию виртуального базового класса ложится на самый дальний производный класс в иерархии. Отсюда следует, что: (1) классы, наследующие виртуальному базовому и требующие инициализации, должны знать обо всех своих виртуальных базовых классах, независимо от того, как далеко они от них находятся в иерархии, и (2) когда в иерархию добавляется новый производный класс, он должен принять на себя ответственность за инициализацию виртуальных предков (как прямых, так и непрямых). Мой совет относительно виртуальных базовых классов (то есть виртуального наследования) прост. Во-первых, не применяйте виртуальных базовых классов до тех пор, пока в этом не возникнет настоятельная потребность. По умолчанию используйте невиртуальное наследование. Во-вторых, если все же избежать виртуальных базовых классов не удается, старайтесь не размещать в них данных. Тогда можно будет забыть о странностях правил инициализации (да, кстати, и присваивания) таких классов. Неспроста интерфейсы Java и. NET, которые во многом подобны виртуальным базовым классам C++, не могут содержать никаких данных. Теперь рассмотрим следующий интерфейсный класс C++ (см. правило 31) для моделирования физических лиц: class IPerson { public: virtual ~IPerson(); virtual std::string name() const = 0; virtual std::string birthDate() const = 0; }; Пользователи IPerson должны программировать в терминах указателей и ссылок на IPerson, поскольку создавать объекты абстрактных классов запрещено. Для создания объектов, которыми можно манипулировать как объектами IPerson, используются функции-фабрики (опять же см. правило 31), которые порождают объекты конкретных классов, производных от IPerson: // функция-фабрика для создания объекта Person по уникальному // идентификатору из базы данных; см. в правиле 18, // почему возвращаемый тип – не обычный указатель std::tr1::shared_ptr<IPerson> makePerson(DatabaseID personIdentifier); // функция для запроса идентификатора у пользователя DatabaseID askUserForDtabaseID(); DatabaseID id(askUserForDtabaseID()); std::tr1::shared_ptr<IPerson> pp(makePerson(id)); // создать объект, // поддерживающий // интерфейс IPerson ... // манипулировать *pp // через функции-члены // IPerson Но как makePerson создает объекты, на которые возвращает указатель? Ясно, что должен быть какой-то конкретный класс, унаследованный от IPerson, который makePerson может инстанцировать. Предположим, этот класс называется CPerson. Будучи конкретным классом, CPerson должен предоставлять реализацию чисто виртуальных функций, унаследованных от IPerson. Можно написать его «с нуля», но лучше воспользоваться уже готовыми компонентами, которые делают большую часть работы. Например, предположим, что старый, ориентированный только на базы данных класс Person-Info предоставляет почти все необходимое CPerson: class PersonInfo { public: explicit PersonInfo(DatabaseID pid) virtual ~PersonInfo(); virtual const char *theName() const; virtual const char *theBirthDate() const; ... private: virtual const char *valeDelimOpen() const; // ni. ie?a virtual const char *valeDelimClose() const; ... }; Понять, что этот класс старый, можно хотя бы потому, что функции-члены возвращают const char* вместо объектов string. Но если ботинки подходят, почему бы не носить их? Имена функций-членов класса наводят на мысль, что результат может оказаться вполне удовлетворительным. Вскоре вы приходите к выводу, что класс PersonInfo был спроектирован для печати полей базы данных в различных форматах, с выделением начала и конца каждого поля специальными строками-разделителями. По умолчанию открывающим и закрывающим разделителями служат квадратные скобки, поэтому значение поля «Ring-tailed Lemur» будет отформатировано так: [Ring-tailed Lemur] Учитывая тот факт, что квадратные скобки не всегда приемлемы для пользователей PersonInfo, в классе предусмотрены виртуальные функции valeDelimOpen и valeDelimClose, позволяющие производным классам задать другие открывающие и закрывающие строки-разделители. Функции-члены PersonInfo вызывают эти виртуальные функции для добавления разделителей к возвращаемым значениям. Так, функция PersonInfo::theName могла бы выглядеть следующим образом: const char *PersonInfo::valueDelimOpen() const { return “[“; // открывающий разделитель по умолчанию } const char *PersonInfo::valueDelimClose() const { return “]“; // закрывающий разделитель по умолчанию } const char * PersonInfo::theName() const { // резервирование буфера для возвращаемого значения; поскольку он // статический, автоматически инициализируется нулями static char value[Max_Formatted_Field_Value_Length]; // скопировать открывающий разделитель std::strcpy(value, valueDelimOpen()); добавить к строке value значение из поля name объекта (будьте осторожны – избегайте переполнения буфера!) // скопировать закрывающий разделитель std::strcpy(value, valueDelimClose()); return value; } Кто-то может посетовать на устаревший подход к реализации PersonInfo::theName (особенно это касается использования статического буфера фиксированного размера, опасного возможностью переполнения и потенциальными проблемами в многопоточной среде – см. правило 21), но оставим этот вопрос в стороне и сосредоточимся вот на чем: функция theName вызывает valueDelimOpen для получения открывающего разделителя, вставляемого в возвращаемую строку, затем дописывает имя и в конце вызывает valueDelimClose. Поскольку valueDelimOpen и valueDelimClose – виртуальные функции, возвращаемый результат theName зависит не только от PersonInfo, но и от классов, производных от него. Для разработчика CPerson это хорошая новость, потому что, внимательно просматривая документацию по функциям печати из класса IPerson, вы обнаруживаете, что функции name и birthDate должны возвращать неформатированные значения, то есть без добавления разделителей. Другими словами, если человека зовут Homer, то вызов функции name должен возвращать «Homer», а не «[Homer]». Взаимосвязь между CPerson и PersonInfo можно описать так: PersonInfo упрощает реализацию некоторых функций CPerson. И это все! Стало быть, речь идет об отношении «реализован посредством», и, как мы знаем, такое отношение можно представить двумя способами: с помощью композиции (см. правило 38) или закрытого наследования (см. правило 39). В правиле 39 отмечено, что композиция в общем случае более предпочтительна, но если нужно переопределять виртуальные функции, то требуется наследование. В данном случае CPerson должен переопределить valueDelimOpen и valueDelimClose – задача, которая с помощью композиции не решается. Самое очевидное решение – применить закрытое наследование CPerson от PersonInfo, хотя, как объясняется в правиле 39, это потребует несколько больше работы. Можно также при реализации CPerson воспользоваться сочетанием композиции и наследования с целью переопределения виртуальных функций PersonInfo. Но мы остановимся просто на закрытом наследовании. Однако CPerson также должен реализовать интерфейс IPerson, а для этого требуется открытое наследование. Вот мы и пришли к множественному наследованию: сочетанию открытого наследования интерфейса с закрытым наследованием реализации: class IPerson { // класс описывает интерфейс, public: // который должен быть реализован virtual ~IPerson(); virtual std::string name() const = 0; virtual std::string birthDate() const = 0; }; class DatabaseID {...}; // используется далее; // детали не существенны class PersonInfo { // в этом классе имеет функции, public: // помогающие при реализации explicit PersonInfo(DatabaseID pid) // интерфейса IPerson virtual ~PersonInfo(); virtual const char *theName() const; virtual const char *theBirthDate() const; virtual const char *valeDelimOpen() const; virtual const char *valeDelimClose() const; ... }; class CPerson: public IPerson, private PersonInfo { // используется public: // множественное explicit CPerson(DatabaseID pid): PersonInfo(pid) {} // наследование virtual std::string name() const // реализации { return PersonInfo::theName();} // функций-членов // из интерфейса // IPerson virtual std::string birthDate() const { return PersonInfo::theBirthDate();} private: // переопределения const char * valeDelimOpen() const { return “”;} // унаследованных const char * valeDelimClose() const { return “”;} // виртуальных }; // функций, // возвращающих // строки-разделители В нотации UML это решение выглядит так: 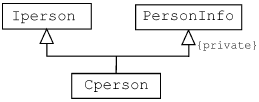 Рассмотренный пример показывает, что множественное наследование может быть и удобным, и понятным. Замечу, что множественное наследование – просто еще один инструмент в объектно-ориентированном инструментарии. По сравнению с одиночным наследованием оно несколько труднее для понимания и применения, поэтому если вы можете спроектировать программу с одним лишь одиночным наследованием, который более или менее эквивалентен варианту с множественным наследованием, то, скорее всего, предпочтение следует отдать первому подходу. Если вам кажется, что единственно возможный вариант дизайна требует применения множественного наследования, то рекомендую как следует подумать – почти наверняка найдется способ обойтись одиночным. В то же время иногда множественное наследование – это самый ясный, простой для сопровождения и разумный способ достижения цели. В таких случаях не бойтесь применять его. Просто делайте это, тщательно обдумав все последствия. Что следует помнить• Множественное наследование сложнее одиночного. Оно может привести к неоднозначности и необходимости применять виртуальное наследование. • Цена виртуального наследования – дополнительные затраты памяти, снижение быстродействия и усложнение операций инициализации и присваивания. На практике его разумно применять, когда виртуальные базовые классы не содержат данных. • Множественное наследование вполне законно. Один из сценариев включает комбинацию открытого наследования интерфейсного класса и закрытого наследования класса, помогающего в реализации. |
|
||
|
Главная | Контакты | Нашёл ошибку | Прислать материал | Добавить в избранное |
||||
|
|
||||