|
||||
|
|
Контейнеры vector и string Все контейнеры STL по-своему полезны, однако большинство программистов C++ работает с vectorи string чаще, чем с их собратьями, и это вполне понятно. Ведь контейнеры vectorи stringразрабатывались как замена массивов, а массивы настолько полезны и удобны, что встречаются во всех коммерческих языках программирования от COBOL до Java. В этой главе контейнеры vectorи stringрассматриваются с нескольких точек зрения. Сначала мы разберемся, чем они превосходят классические массивы STL, затем рассмотрим пути повышения быстродействия vectorи string, познакомимся с различными вариантами реализации string, изучим способы передачи stringи vectorфункциям API, принимающим данные в формате C. Далее будет показано, как избежать лишних операций выделения памяти. Глава завершается анализом поучительной аномалии, vector<bool>. Совет 13. Используйте vector и string вместо динамических массивов Принимая решение о динамическом выделении памяти оператором new, вы берете на себя ряд обязательств. 1. Выделенная память в дальнейшем должна быть освобождена оператором delete. Вызов newбез последующего deleteприводит к утечке ресурсов. 2. Освобождение должно выполняться соответствующей формой оператора delete. Одиночный объект освобождается простым вызовом delete, а для массивов требуется форма delete[]. Ошибка в выборе формы deleteприводит к непредсказуемым последствиям. На одних платформах программа «зависает» во время выполнения, а на других она продолжает работать с ошибками, приводящими к утечке ресурсов и порче содержимого памяти. 3. Оператор deleteдля освобождаемого объекта должен вызываться ровно один раз. Повторное освобождение памяти также приводит к непредсказуемым последствиям. Итак, динамическое выделение памяти сопряжено с немалой ответственностью, и я не понимаю, зачем брать на себя лишние обязательства. При использовании vectorи stringнеобходимость в динамическом выделении памяти возникает значительно реже. Каждый раз, когда вы готовы прибегнуть к динамическому выделению памяти под массив (то есть собираетесь включить в программу строку вида « new T[…]»), подумайте, нельзя ли вместо этого воспользоваться vectorили string. Как правило, stringиспользуется в том случае, если Tявляется символьным типом, а vector— во всех остальных случаях. Впрочем, позднее мы рассмотрим ситуацию, когда выбор vector<char>выгладит вполне разумно. Контейнеры vectorи stringизбавляют программиста от хлопот, о которых говорилось выше, поскольку они самостоятельно управляют своей памятью. Занимаемая ими память расширяется по мере добавления новых элементов, а при уничтожении vectorили stringдеструктор автоматически уничтожает элементы контейнера и освобождает память, в которой они находятся. Кроме того, vectorи stringвходят в семейство последовательных контейнеров STL, поэтому в вашем распоряжении оказывается весь арсенал алгоритмов STL, работающих с этими контейнерами. Впрочем, алгоритмы STL могут использоваться и с массивами, однако у массивов отсутствуют удобные функции begin, end, sizeи т. п., а также вложенные определения типов ( iterator, reverse_iterator, value_typeи т. д.), а указатели char*вряд ли могут сравниться со специализированными функциями контейнера string. Чем больше работаешь с STL, тем меньше энтузиазма вызывают встроенные массивы. Если вас беспокоит судьба унаследованного кода, работающего с массивами, не волнуйтесь и смело используйте vectorи string. В совете 16 показано, как легко организовать передачу содержимого vectorи stringфункциям C, работающим с массивами, поэтому интеграция с унаследованным кодом обычно обходится без затруднений. Честно говоря, мне приходит в голову лишь одна возможная проблема при замене динамических массивов контейнерами vector/string, причем она относится только к string. Многие реализации stringоснованы на подсчете ссылок (совет 15), что позволяет избавиться от лишних выделений памяти и копирования символов, а также во многих случаях ускоряет работу контейнера. Оптимизация stringна основе подсчета ссылок была сочтена настолько важной, что Комитет по стандартизации C++ специально разрешил ее использование. Впрочем, оптимизация нередко оборачивается «пессимизацией». При использовании stringс подсчетом ссылок в многопоточной среде время, сэкономленное на выделении памяти и копировании, может оказаться ничтожно малым по сравнению со временем, затраченным на синхронизацию доступа (за подробностями обращайтесь к статье Саттера «Optimizations That Aren't (In a Multithreaded World)» [20]). Таким образом, при использовании stringс подсчетом ссылок в многопоточной среде желательно следить за проблемами быстродействия, обусловленными поддержкой потоковой безопасности. Чтобы узнать, используется ли подсчет ссылок в вашей реализации string, проще всего обратиться к документации библиотеки. Поскольку подсчет ссылок считается оптимизацией, разработчики обычно отмечают его среди положительных особенностей библиотеки. Также можно обратиться к исходным текстам реализации string. Обычно я не рекомендую искать нужную информацию таким способом, но иногда другого выхода просто не остается. Если вы пойдете по этому пути, не забывайте, что stringявляется определением типа для basic_string<char>(а wstring— для basic_string<wchar_t>), поэтому искать следует в шаблоне basic_string. Вероятно, проще всего обратиться к копирующему конструктору класса. Посмотрите, увеличивает ли он переменную, которая может оказаться счетчиком ссылок. Если такая переменная будет найдена, stringиспользует подсчет ссылок, а если нет — не использует… или вы просто ошиблись при поиске. Если доступная реализация stringпостроена на подсчете ссылок, а ее использование в многопоточной среде порождает проблемы с быстродействием, возможны по крайней мере три разумных варианта, ни один из которых не связан с отказом от STL. Во-первых, проверьте, не позволяет ли реализация библиотеки отключить подсчет ссылок (обычно это делается изменением значения препроцессорной переменной). Конечно, переносимость при этом теряется, но с учетом минимального объема работы данный вариант все же стоит рассмотреть. Во-вторых, найдите или создайте альтернативную реализацию string(хотя бы частичную), не использующую подсчета ссылок. В-третьих, посмотрите, нельзя ли использовать vector<char>вместо string. Реализации vectorне могут использовать подсчет ссылок, поэтому скрытые проблемы многопоточного быстродействия им не присущи. Конечно, при переходе к vector<char>теряются многие удобные функции контейнера string, но большая часть их функциональности доступна через алгоритмы STL, поэтому речь идет не столько о сужении возможностей, сколько о смене синтаксиса. Из всего сказанного можно сделать простой вывод — массивы с динамическим выделением памяти часто требуют лишней работы. Чтобы упростить себе жизнь, используйте vectorи string. Совет 14. Используйте reserve для предотвращения лишних операций перераспределения памяти Одной из самых замечательных особенностей контейнеров STL является автоматическое наращивание памяти в соответствии с объемом внесенных данных (при условии, что при этом не превышается максимальный размер контейнера — его можно узнать при помощи функции max_size). Для контейнеров vectorи stringдополнительная память выделяется аналогом функции realloc. Процедура состоит из четырех этапов: 1. Выделение нового блока памяти, размер которого кратен текущей емкости контейнера. В большинстве реализаций vectorи stringиспользуется двукратное увеличение, то есть при каждом выделении дополнительной памяти емкость контейнера увеличивается вдвое. 2. Копирование всех элементов из старой памяти контейнера в новую память. 3. Уничтожение объектов в старой памяти. 4. Освобождение старой памяти. При таком количестве операций не приходится удивляться тому, что динамическое увеличение контейнера порой обходится довольно дорого. Естественно, эту операцию хотелось бы выполнять как можно реже. А если это еще не кажется естественным, вспомните, что при каждом выполнении перечисленных операций все итераторы, указатели и ссылки на содержимое vectorили stringстановятся недействительными. Таким образом, простая вставка элемента в vector/stringможет потребовать обновления других структур данных, содержащих итераторы, указатели и ссылки расширяемого контейнера. Функция reserveпозволяет свести к минимуму количество дополнительных перераспределений памяти и избежать затрат на обновление недействительных итераторов/указателей/ссылок. Но прежде чем объяснять, как это происходит, позвольте напомнить о существовании четырех взаимосвязанных функций, которые иногда путают друг с другом. Из всех стандартных контейнеров перечисленные функции поддерживаются только контейнерами vectorи string. • Функция size()возвращает текущее количество элементов в контейнере. Она не сообщает, сколько памяти контейнер выделил для хранящихся в нем элементов. • Функция capacity()сообщает, сколько элементов поместится в выделенной памяти. Речь идет об общемколичестве элементов, а не о том, сколько ещеэлементов можно разместить без расширения контейнера. Если вас интересует объем свободной памяти vectorили string, вычтите size()из capacity(). Если size()и capacity()возвращают одинаковые значения, значит, в контейнере не осталось свободного места, и следующая вставка ( insert, push_backи т. д.) вызовет процедуру перераспределения памяти, описанную выше. • Функция resize(size_t n)изменяет количество элементов, хранящихся в контейнере. После вызова resizeфункция sizeвернет значение n. Если nменьше текущего размера, лишние элементы в конце контейнера уничтожаются. Если nбольше текущего размера, в конец контейнера добавляются новые элементы, созданные конструктором по умолчанию. Если nбольше текущей емкости контейнера, перед созданием новых элементов происходит перераспределение памяти. •Функция reserve(size_t n)устанавливает минимальную емкость контейнера равной n— при условии, что nне меньше текущего размера. Обычно это приводит к перераспределению памяти вследствие увеличения емкости (если nменьше текущей емкости, vectorигнорирует вызов функции и не делает ничего, а stringможетуменьшить емкость до большей из величин ( size(), n)), но размер stringпри этом заведомо не изменяется. По собственному опыту знаю, что усечение емкости stringвызовом reserveобычно менее надежно, чем «фокус с перестановкой», описанный в совете 17. Из краткого описания функций становится ясно, что перераспределение (выделение и освобождение блоков памяти, копирование и уничтожение объектов, обновление недействительных итераторов, указателей и ссылок) происходит каждый раз, когда при вставке нового элемента текущая емкость контейнера оказывается недостаточной. Таким образом, для предотвращения лишних затрат следует установить достаточно большую емкость контейнера функцией reserve, причем сделать это нужно как можно раньше — желательно сразу же после конструирования контейнера. Предположим, вы хотите создать vector<int>с числами из интервала 1–1000. Без использования reserveэто делалось бы примерно так: vector<int> v; for (int i=1; i<=1000; ++i) v.push_back(i): В большинстве реализаций STL при выполнении этого фрагмента произойдет от 2 до 10 расширений контейнера. Кстати, число 10 объясняется очень просто. Вспомните, что при каждом перераспределении емкость vectorобычно увеличивается вдвое, а 1000примерно равно 210. vector<int> v; v.reserve(1000); for (int i=1; i<=1000; ++i) v.push_back(i); В этом случае количество расширений будет равно нулю. Взаимосвязь между sizeи capacityпозволяет узнать, когда вставка в vectorили stringприведет к расширению контейнера. В свою очередь, это позволяет предсказать, когда вставка приведет к недействительности итераторов, указателей и ссылок в контейнере. Пример: string s; if (s.size() < s.capacity()) { s.push_back('x'); } В этом фрагменте вызов push_backне может привести к появлению недействительных итераторов, указателей и ссылок, поскольку емкость stringзаведомо больше текущего размера. Если бы вместо push_backвыполнялась вставка в произвольной позиции строки функцией insert, это также гарантировало бы отсутствие перераспределений памяти, но в соответствии с обычными правилами действительности итераторов для вставки в stringвсе итераторы/указатели/ссылки от точки вставки до конца строки стали бы недействительными. Вернемся к основной теме настоящего совета. Существуют два основных способа применения функции reserveдля предотвращения нежелательного перераспределения памяти. Первый способ используется в ситуации, когда известно точное или приблизительное количество элементов в контейнере. В этом случае, как в приведенном выше примере с vector, нужный объем памяти просто резервируется заранее. Во втором варианте функция reserveрезервирует максимальный объем памяти, который может понадобиться, а затем после включения данных в контейнер вся свободная память освобождается. В усечении свободной памяти нет ничего сложного, однако я не буду описывать эту операцию здесь, потому что в ней используется особый прием, рассмотренный в совете 17. Совет 15. Помните о различиях в реализации string Бьерн Страуструп однажды написал статью с интригующим названием «Sixteen Ways to Stack a Cat» [27], в которой были представлены разные варианты реализации стеков. Оказывается, по количеству возможных реализаций контейнеры stringне уступают стекам. Конечно, нам, опытным и квалифицированным программистам, положено презирать «подробности реализации», но если Эйнштейн был прав, и Бог действительно проявляется в мелочах… Даже если подробности действительно несущественны, в них все же желательно разбираться. Только тогда можно быть полностью уверенным в том, что они действительнонесущественны. Например, сколько памяти занимает объект string? Иначе говоря, чему равен результат sizeof(string)? Ответ на этот вопрос может быть весьма важным, особенно если вы внимательно следите за расходами памяти и думаете о замене низкоуровневого указателя char*объектом string. Оказывается, результат sizeof(string)неоднозначен — и если вы действительно следите за расходами памяти, вряд ли этот ответ вас устроит. Хотя у некоторых реализаций контейнер stringпо размеру совпадает с char*, так же часто встречаются реализации, у которой stringзанимает в семь раз больше памяти. Чем объясняются подобные различия? Чтобы понять это, необходимо знать, какие данные и каким образом будут храниться в объекте string. Практически каждая реализация stringхранит следующую информацию: • размер строки, то есть количество символов; • емкость блока памяти, содержащего символы строки (различия между размером и емкостью описаны в совете 14); • содержимое строки, то есть символы, непосредственно входящие в строку. Кроме того, в контейнере string может храниться: • копия распределителя памяти. В совете 10 рассказано, почему это поле не является обязательным. Там же описаны странные правила, по которым работают распределители памяти. Реализации string, основанные на подсчете ссылок, также содержат: • счетчик ссылок для текущего содержимого. В разных реализациях stringэти данные хранятся по-разному. Для наглядности мы рассмотрим структуры данных, используемые в четырех вариантах реализации string. В выборе нет ничего особенного, все варианты позаимствованы из широко распространенных реализаций STL. Просто они оказались первыми, попавшимися мне на глаза. В реализации A каждый объект stringсодержит копию своего распределителя памяти, размер строки, ее емкость и указатель на динамически выделенный буфер со счетчиком ссылок ( RefCnt) и содержимым строки. В этом варианте объект string, использующий стандартный распределитель памяти, занимает в четыре раза больше памяти по сравнению с указателем. При использовании нестандартного указателя объект stringувеличится на размер объекта распределителя. 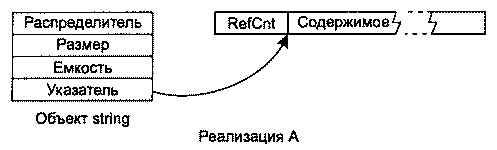 В реализации B объекты stringпо размерам не отличаются от указателей, поскольку они содержат указатель на структуру. При этом также предполагается использование стандартного распределителя памяти. Как и в реализации A, при использовании нестандартного распределителя размер объекта stringувеличивается на размер объекта распределителя. Благодаря оптимизации, присутствующей в этом варианте, но не предусмотренной в варианте A, использование стандартного распределителя обходится без затрат памяти. В объекте, на который ссылается указатель, хранится размер строки, емкость и счетчик ссылок, а также указатель на динамически выделенный буфер с текущим содержимым строки. Здесь же хранятся дополнительные данные, относящиеся к синхронизации доступа в многопоточных системах. К нашей теме они не относятся, поэтому на рисунке соответствующая часть структуры данных обозначена «Прочее». 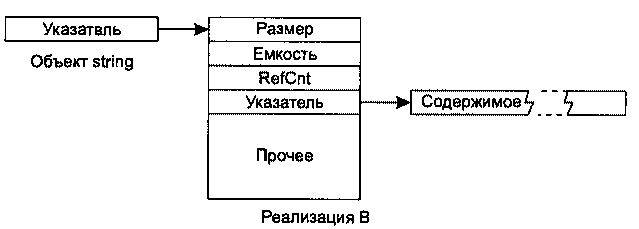 Блок «Прочее» оказался больше остальных блоков, поскольку я постарался выдержать масштаб изображения. Если один блок вдвое больше другого, значит, он занимает вдвое больше памяти. В реализации B размер данных синхронизации примерно в шесть раз превышает размер указателя. В реализации C размер объекта stringвсегда равен размеру указателя, но этот указатель всегда ссылается на динамически выделенный буфер, содержащий все данные строки: размер, емкость, счетчик ссылок и текущее содержимое. Распределители уровня объекта не поддерживаются. В буфере также хранятся данные, описывающие возможности совместного доступа к содержимому; эта тема здесь не рассматривается, поэтому соответствующий блок на рисунке помечен буквой «X» (если вас интересует, зачем может потребоваться ограничение доступа к данным с подсчетом ссылок, обратитесь к совету 29 «More Effective C++»).  В реализации D объекты stringзанимают в семь раз больше памяти, чем указатель (при использовании стандартного распределителя памяти). В этой реализации подсчет ссылок не используется, но каждый объект stringсодержит внутренний буфер, в котором могут храниться до 15 символов. Таким образом, небольшие строки хранятся непосредственно в объекте string— данная возможность иногда называется «оптимизацией малых строк». Если емкость строки превышает 15 символов, в начале буфера хранится указатель на динамически выделенный блок памяти, в котором содержатся символы строки. 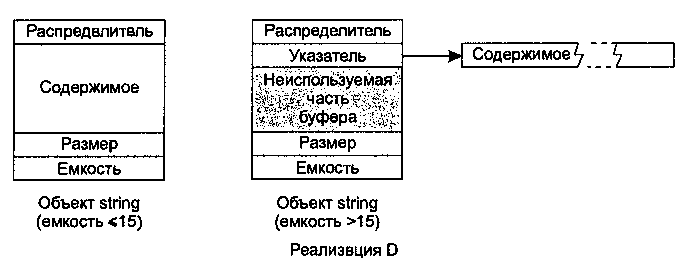 Я поместил здесь эти диаграммы совсем не для того, чтобы убедить читателя в своем умении читать исходные тексты и рисовать красивые картинки. По ним также можно сделать вывод, что создание объекта stringкомандами вида string s("Perse"); // Имя нашей собаки - Персефона, но мы // обычно зовем ее просто "Перси" в реализации D обходится без динамического выделения памяти, обходится одним выделением в реализациях A и C и двумя — в реализации B (для объекта, на который ссылается указатель string, и для символьного буфера, на который ссылается указатель в этом объекте). Если для вас существенно количество операций выделения/освобождения или затраты памяти, часто связанные с этими операциями, от реализации B лучше держаться подальше. С другой стороны, наличие специальной поддержки синхронизации доступа в реализации B может привести к тому, что эта реализация подойдет для ваших целей лучше, чем реализации A и C, а количество динамических выделений памяти уйдет на второй план. Реализация D не требует специальной поддержки многопоточности, поскольку в ней не используется подсчет ссылок. За дополнительной информацией о связи между многопоточностью и строками с подсчетом ссылок обращайтесь к совету 13. Типичная поддержка многопоточности в контейнерах STL описана в совете 12. В архитектуре, основанной на подсчете ссылок, все данные, находящиеся за пределами объекта string, могут совместно использоваться разными объектами string(имеющими одинаковое содержимое), поэтому из приведенных диаграмм также можно сделать вывод, что реализация A обладает меньшими возможностями для совместного использования данных. В частности, реализации B и C допускают совместное использование данных размера и емкости объекта, что приводит к потенциальному уменьшению затрат на хранение этих данных на уровне объекта. Интересно и другое: отсутствие поддержки распределителей уровня объекта в реализации C означает, что это единственная реализация с возможностью использования общих распределителей: все объекты stringдолжны работать с одним распределителем! (За информацией о принципах работы распределителей обращайтесь к совету 10.) Реализация D не позволяет совместно использовать данные в объектах string. Один из интересных аспектов поведения string, не следующий непосредственно из этих диаграмм, относится к стратегии выделения памяти для малых строк. В некоторых реализациях устанавливается минимальный размер выделяемого блока памяти; к их числу принадлежат реализации A, C и D. Вернемся к команде string s ("Perse"); // Строка s состоит из 5 символов В реализации A минимальный размер выделяемого буфера равен 32 символам. Таким образом, хотя размер s во всех реализациях равен 5 символам, емкость этого контейнера в реализации A равна 31 (видимо, 32-й символ зарезервирован для завершающего нуль-символа, упрощающего реализацию функции c_str). В реализации C также установлен минимальный размер буфера, равный 16, при этом место для завершающего нуль-символа не резервируется, поэтому в реализации C емкость sравна 16. Минимальный размер буфера в реализации D также равен 16, но с резервированием места для завершающего нуль-символа. Принципиальное отличие реализации D заключается в том, что содержимое строк емкостью менее 16 символов хранится в самом объекте string. Реализация B не имеет ограничений на минимальный размер выделяемого блока, и в ней емкость s равна 7. (Почему не 6 или 5? Не знаю. Простите, я не настолько внимательно анализировал исходные тексты.) Из сказанного очевидно следует, что стратегия выделения памяти для малых строк может сыграть важную роль, если вы собираетесь работать с большим количеством коротких строк и (1) в вашей рабочей среде не хватает памяти или (2) вы стремитесь по возможности локализовать ссылки и пытаетесь сгруппировать строки в минимальном количестве страниц памяти. Конечно, в выборе реализации stringразработчик обладает большей степенью свободы, чем кажется на первый взгляд, причем эта свобода используется разными способами. Ниже перечислены ишь некоторые переменные факторы. • По отношению к содержимому stringможет использоваться (или не использоваться) подсчет ссылок. По умолчанию во многих реализациях подсчет ссылок включен, но обычно предоставляется возможность его отключения (как правило, при помощи препроцессорного макроса). В совете 13 приведен пример специфической ситуации, когда может потребоваться отключение подсчета ссылок, но такая необходимость может возникнуть и по другим причинам. Например, подсчет ссылок экономит время лишь при частом копировании строк. Если в приложении строки копируются редко, затраты на подсчет ссылок не оправдываются. • Объекты stringзанимают в 1-7 (по меньшей мере) раз больше памяти, чем указатели char*. • Создание нового объекта stringможет потребовать нуля, одной или двух операций динамического выделения памяти. • Объекты stringмогут совместно использовать данные о размере и емкости строки. • Объекты stringмогут поддерживать (или не поддерживать) распределители памяти уровня объекта. • В разных реализациях могут использоваться разные стратегии ограничения размеров выделяемого блока. Только не поймите меня превратно. Я считаю, что контейнер stringявляется одним из важнейших компонентов стандартной библиотеки и рекомендую использовать его как можно чаще. Например, совет 13 посвящен возможности использования stringвместо динамических символьных массивов. Но для эффективного использования STL необходимо разбираться во всем разнообразии реализаций string, особенно если ваша программа должна работать на разных платформах STL при жестких требованиях к быстродействию. Кроме того, на концептуальном уровне контейнер stringвыглядел предельно просто. Кто бы мог подумать, что его реализация таит столько неожиданностей? Совет 16. Научитесь передавать данные vector и string функциям унаследованного интерфейса С момента стандартизации C++ в 1998 году элита C++ настойчиво подталкивает программистов к переходу с массивов на vector. Столь же открыто пропагандируется переход от указателей char*к объектам string. В пользу перехода имеются достаточно веские аргументы, в том числе ликвидация распространенных ошибок программирования (совет 13) и возможность полноценного использования всей мощи алгоритмов STL (совет 31). Но на этом пути остаются некоторые препятствия, из которых едва ли не самым распространенным являются унаследованные интерфейсы языка C, работающие с массивами и указателями char*вместо объектов vectorи string. Они существуют с давних времен, и если мы хотим эффективно использовать STL, придется как-то уживаться с этими «пережитками прошлого». К счастью, задача решается просто. Если у вас имеется vector vи вы хотите получить указатель на данные v, которые интерпретировались бы как массив, воспользуйтесь записью &v[0]. Для string sаналогичная запись имеет вид s.c_str(). Впрочем, это не все — существуют некоторые ограничения (то, о чем в рекламе обычно пишется самым мелким шрифтом). Рассмотрим следующее объявление: vector<int> v; Выражение v[0]дает ссылку на первый элемент вектора, соответственно &v[0]— указатель на первый элемент. В соответствии со Стандартом C++ элементы vectorдолжны храниться в памяти непрерывно, по аналогии с массивом. Допустим, у нас имеется функция C, объявленная следующим образом: void doSomething(const int* pInts, size_t numlnts); Передача данных должна происходить так: doSomething(&v[0], v.size()); Во всяком случае, так должнобыть. Остается лишь понять, что произойдет, если вектор vпуст. В этом случае функция v.size()вернет 0, а &v[0]пытается получить указатель на несуществующий блок памяти с непредсказуемыми последствиями. Нехорошо. Более надежный вариант вызова выглядит так: if (!v.empty()) { doSomething(&v[0], v.size()); } Отдельные подозрительные личности утверждают, что &v[0]можно заменить на v.begin(), поскольку beginвозвращает итератор, а для vectorитератор в действительности представляет собой указатель. Во многих случаях это действительно так, но, как будет показано в совете 50, это правило соблюдается не всегда, и полагаться на него не стоит. Функция beginвозвращает итератор, а не указатель, поэтому она никогда не должна использоваться для получения указателя на данные vector. А если уж вам очень приглянулась запись v.begin(), используйте конструкцию &*v.begin()— она вернет тот же указатель, что и &v[0], хотя это увеличивает количество вводимых символов и затрудняет работу людей, пытающихся разобраться в вашей программе. Если знакомые вам советуют использовать v.begin()вместо &v[0]— лучше смените круг общения. Способ получения указателя на данные контейнера, хорошо работающий для vector, недостаточно надежен для string. Во-первых, контейнер stringне гарантирует хранения данных в непрерывном блоке памяти; во-вторых, внутреннее представление строки не обязательно завершается нуль-символом. По этим причинам в контейнере string предусмотрена функция c_str, которая возвращает указатель на содержимое строки в формате C. Таким образом, передача строки sфункции void doSomething(const char *pString); происходит так: doSomething(s.c_str()); Данное решение подходит и для строк нулевой длины. В этом случае c_strвозвращает указатель на нуль-символ. Кроме того, оно годится и для строк с внутренними нуль-символами, хотя в этом случае doSomethingс большой вероятностью интерпретирует первый внутренний нуль-символ как признак конца строки. Присутствие внутренних нуль-символов несущественно для объектов string, но не для функций C, использующих char*. Вернемся к объявлениям doSomething: void doSomething(const int* pints, size_t numInts); void doSomething(const char *pString); В обоих случаях передаются указатели на const. Функция C, получающая данные vectorили string, читаетих, не пытаясь модифицировать. Такой вариант наиболее безопасен. Для stringон неизбежен, поскольку не существует гарантии, что c_strвернет указатель на внутреннее представление строковых данных; функция может вернуть указатель на неизменяемую копиюданных в формате C (если вас встревожила эффективность этих операций, не волнуйтесь — мне не известна ни одна современная реализация библиотеки, в которой бы использовалась данная возможность). Vector предоставляет программисту чуть большую свободу действий. Передача vфункции C, модифицирующей элементы v, обычно обходится без проблем, но вызванная функция не должна изменять количество элементов в векторе. Например, она не может «создавать» новые элементы в неиспользуемой памяти vector. Такие попытки приведут к нарушению логической целостности контейнера v, поскольку объект не будет знать свой правильный размер, и вызов функции v.size()возвратит неправильные результаты. А если вызванная функция попытается добавить новые данные в вектор, у которого текущий размер совпадает с емкостью (совет 14), произойдет сущий кошмар. Я даже не пытаюсь предугадать последствия, настолько они ужасны. Вы обратили внимание на формулировку «обычно обходится без проблем» в предыдущем абзаце? Конечно, обратили. Некоторые векторы устанавливают для своих данных дополнительные ограничения, и при передаче вектора функции API, изменяющей его содержимое, вы должны проследить за тем, чтобы эти ограничения не были нарушены. Например, как объясняется в совете 23, сортируемые векторы часто могут рассматриваться в качестве разумной альтернативы для ассоциативных контейнеров, но при этом содержимое таких векторов должно оставаться правильно отсортированным. При передаче сортируемого вектора функции, способной изменить его содержимое, вам придется учитывать, что при возвращении из функции сортировка элементов может быть нарушена. Если у вас имеется vector, который должен инициализироваться внутри функции C, можно воспользоваться структурной совместимостью vectorс массивами и передать функции указатель на блок элементов вектора: // Функция fillArray получает указатель на массив. // содержащий не более arraySize чисел типа double. // и записывает в него данные. Возвращаемое количество записанных // чисел заведомо не превышает maxNumDoubles. size_t fillArray(double *pArray, size_t arraySize); vector<double> vd(maxNumDoubles); // Создать vector, емкость которого // равна maxNumDoubles vd.resize(fillArray(&vd[0], vd.size())); // Заполнить vd вызовом // функции fillArray, после чего // изменить размер по количеству // записанных элементов Данный способ подходит только для vector, поскольку только этот контейнер заведомо совместим с массивами по структуре памяти. Впрочем, задача инициализации stringфункцией C тоже решается достаточно просто. Данные, возвращаемые функцией, заносятся в vector<char>и затем копируются из вектора в string: // Функция получает указатель на массив, содержащий не более // arraySize символов, и записывает в него данные. // Возвращаемое количество записанных чисел заведомо не превышает // maxNumChars size_t fillString(char *pArray, sizet arraySize); vector<char> vc(maxNumChars); // Создать vector, емкость которого // равна maxNumChars size_t charsWritten = fillString(&vc[0],vc.size()); // Заполнить vc // вызовом fillString string s(vc.begin(), vc.begin()+charsWritten); // Скопировать данные // из vc в s интервальным // конструктором (совет 5) Собственно, сам принцип сохранения данных функцией API в vectorи их последующего копирования в нужный контейнер STL работает всегда: size_t fillArray(double *pArray, size_t arraySize); // См. ранее vector<double> vd(maxNumDoubles);// Также см. ранее vd.resize(fillArray(&vd[0], vd.size()); deque<double> d(vd.begin(), vd.end()); // Копирование в deque list<double> l(vd.begin(), vd.end()); // Копирование в list set<double> s(vd.begin(), vd.end()); // Копирование в set Более того, этот фрагмент подсказывает, как организовать передачу данных из других контейнеров STL, кроме vectorи string, функциям C. Для этого достаточно скопировать данные контейнера в vectorи передать его при вызове: void doSomething(const int* pints, size_t numInts); // Функция C (см. ранее) set<int> intSet; // Множество, в котором … // хранятся передаваемые // данные vector<int> v(intSet.begin(), intSet.end());// Скопировать данные // из set в vector if (!v.empty()) doSomething(&v[0], v.size()); // Передать данные // функции С Вообще говоря, данные также можно скопировать в массив и передать их функции C, но зачем это нужно? Если размер контейнера не известен на стадии компиляции, память придется выделять динамически, а в совете 13 объясняется, почему вместо динамических массивов следует использовать vector. Совет 17. Используйте «фокус с перестановкой» для уменьшения емкости Предположим, вы пишете программу для нового телешоу «Бешеные деньги». Информация о потенциальных участниках хранится в векторе: class Contestant {…}; vector<Contestant> contestants; При объявлении набора участников заявки сыплются градом, и вектор быстро заполняется элементами. Но по мере отбора перспективных кандидатов относительно небольшое количество элементов перемещается в начало вектора (вероятно, вызовом partial_sortили partition— см. совет 31), а неудачники удаляются из вектора (как правило, при помощи интервальной формы erase— см. совет 5). В результате удаления длина вектора уменьшается, но емкость остается прежней. Если в какой-то момент времени вектор содержал данные о 100 000 кандидатов, то его емкость останется равной 100 000, даже если позднее количество элементов уменьшится до 10. Чтобы вектор не удерживал ненужную память, необходимы средства, которые бы позволяли сократить емкость от максимальной до используемой в настоящий момент. Подобное сокращение емкости обычно называется «сжатием по размеру». Сжатие по размеру легко программируется, однако код — как бы выразиться поделикатнее? — выглядит недостаточно интуитивно. Давайте разберемся, как он работает. Усечение лишней емкости в векторе contestants производится следующим образом: vector<Contestant>(contestants).swap(contestants); Выражение vector<Contestant>(contestants)создает временный вектор, содержащий копию contestants; основная работа выполняется копирующим конструктором vector. Тем не менее, копирующий конструктор vectorвыделяет ровно столько памяти, сколько необходимо для хранения копируемых элементов, поэтому временный вектор не содержит лишней емкости. Затем содержимое вектора contestantsменяется местами с временным вектором функцией swap. После завершения этой операции в contestantsоказывается содержимое временного вектора с усеченной емкостью, а временный вектор содержит «раздутые» данные, ранее находившиеся в contestants. В этот момент (то есть в конце команды) временный вектор уничтожается, освобождая память, ранее занимаемую вектором contestants. Аналогичный прием применяется и по отношению к строкам: string s; // Создать большую строку и удалить из нее … // большую часть символов string(s).swap(s); // Выполнить "сжатие по размеру" с объектом s Я не могу предоставить стопроцентной гарантии того, что этом прием действительно удалит из контейнера лишнюю емкость. Авторы реализаций при желании могут намеренно выделить в контейнерах vectorи stringлишнюю память, и иногда они так и поступают. Например, контейнер может обладать минимальной емкостью или же значения емкости vector/stringмогут ограничиваться степенями 2 (по собственному опыту могу сказать, что подобные аномалии чаще встречаются в реализациях string, нежели в реализациях vector. За примерами обращайтесь к совету 15). Таким образом, «сжатие по размеру» следует понимать не как «приведение к минимальной емкости», а как «приведение к минимальной емкости, допускаемой реализацией для текущего размера контейнера». Впрочем, это лучшее, что вы можете сделать (не считая перехода на другую реализацию STL), поэтому «сжатие по размеру» для контейнеров vectorи stringфактически эквивалентно «фокусу с перестановкой». Кстати говоря, одна из разновидностей «фокуса с перестановкой» может использоваться для очистки контейнера с одновременным сокращением емкости до минимальной величины, поддерживаемой вашей реализацией. Для этого в перестановке используется временный объект vectorили string, содержимое которого создается конструктором по умолчанию: vector<Contestant> v; string s; … // Использовать v и s vector<Contestant>().swap(v); // Очистить v с уменьшением емкости string().swap(s); // Очистить s с уменьшением емкости Остается сделать последнее замечание, относящееся к функции swapв целом. Перестановка содержимого двух контейнеров также приводит к перестановке их итераторов, указателей и ссылок. Итераторы, указатели и ссылки, относившиеся к элементам одного контейнера, после вызова swapостаются действительными и указывают на те же элементы — но в другом контейнере. Совет 18. Избегайте vector<bool> Vector<bool> как контейнер STL обладает лишь двумя недостатками. Во-первых, это вообще не контейнер STL. Во-вторых, он не содержит bool. Объект не становится контейнером STL только потому, что кто-то назвал его таковым — он становится контейнером STL лишь при соблюдении всех требований, изложенных в разделе 23.1 Стандарта C++. В частности, в этих требованиях говорится, что если c— контейнер объектов типа T, поддерживающий оператор [], то следующая конструкция должна нормально компилироваться: T *р = &с[0];// Инициализировать T* адресом данных, // возвращаемых оператором [] Иначе говоря, если оператор []используется для получения одного из объектов Tв Container<T>, то указатель на этот объект можно получить простым взятием его адреса (предполагается, что оператор &типа Tне был перегружен извращенным способом). Следовательно, чтобы vector<bool>был контейнером, следующий фрагмент должен компилироваться: vector<bool> v; bool *pb = &v[0]; // Инициализировать bool* адресом результата, // возвращаемого оператором vector<bool>::operator[] Однако приведенный фрагмент компилироваться не будет. Дело в том, что vector<bool>— псевдоконтейнер, содержащий не настоящие логические величины bool, а их представления, упакованные для экономии места. В типичной реализации каждая псевдовеличина « bool», хранящаяся в псевдовекторе, занимает один бит, а восьмибитовый байт представляет восемь « bool». Во внутреннем представлении vector<bool>булевы значения, которые должны храниться в контейнере, представляются аналогами битовых полей. Битовые поля, как и bool, принимают только два возможных значения, но между «настоящими» логическими величинами и маскирующимися под них битовыми полями существует принципиальное различие. Создать указатель на реальное число boolможно, но указатели на отдельные биты запрещены. Ссылки на отдельные биты тоже запрещены, что представляет определенную проблему для дизайна интерфейса vector<bool>, поскольку функция vector<T>::operator[]должна возвращать значение типа T&. Если бы контейнер vector<bool>действительно содержал bool, этой проблемы не существовало бы, но вследствие особенностей внутреннего представления функция vector<T>::operator[]должна вернуть несуществующую ссылку на отдельный бит. Чтобы справиться с этим затруднением, функция vector<T>::operator[]возвращает объект, который имитируетссылку на отдельный бит — так называемый промежуточный объект. Для использования STL не обязательно понимать, как работают промежуточные объекты, но вообще это весьма полезная идиома C++. Дополнительная информация о промежуточных объектах приведена в совете 30 «More Effective C++», а также в разделе «Паттерн Proxy» книги «Приемы объектно-ориентированного проектирования» [6]. На простейшем уровне vector<bool>выглядит примерно так: template <typename Allocator> vector<bool, Allocator> { public: class reference {…};// Класс, генерирующий промежуточные // объекты для ссылок на отдельные биты reference operator[](size_type n); // operator[] возвращает … // промежуточный объект }; Теперь понятно, почему следующий фрагмент не компилируется: vector<bool> v; bool *pb=&v[0]; // Ошибка! Выражение в правой части относится к типу // vector<bool>::reference*, а не bool* А раз фрагмент не компилируется, vector<bool>не удовлетворяет требованиям к контейнерам STL. Да, специфика vector<bool>особо оговорена в Стандарте; да, этот контейнер почтиудовлетворяет требованиям к контейнерам STL, но «почти» не считается. Чем больше вы напишете шаблонов, предназначенных для работы с STL, тем глубже вы осознаете эту истину. Уверяю вас, наступит день, когда написанный вами шаблон будет работать лишь в том случае, если получение адреса элемента контейнера дает указатель на тип элемента; и когда этот день придет, вы наглядно ощутите разницу между контейнером и почтиконтейнером. Спрашивается, почему же vector<bool>присутствует в Стандарте, если это не контейнер? Отчасти это связано с одним благородным, но неудачным экспериментом, но позвольте мне ненадолго отложить эту тему и заняться более насущным вопросом. Итак, от vector<bool>следует держаться подальше, потому что это не контейнер — но что же делать, когда вам действительно понадобитсявектор логических величин? В стандартную библиотеку входят два альтернативных решения, которые подходят практически для любых ситуаций. Первое решение — deque<bool>. Контейнер dequeобладает практически всеми возможностями vector(за исключением разве что reserveи capacity), но при этом deque<bool>является полноценным контейнером STL, содержащим настоящие значения bool. Конечно, внутренняя память dequeне образует непрерывный блок, поэтому данные deque<bool>не удастся передать функции C, получающей массив bool(см. совет 16), но это не удалось бы сделать и с vector<bool>из-за отсутствия переносимого способа получения данных vector<bool>. (Прием, продемонстрированный для vectorв совете 16, не компилируется для vector<bool>, поскольку он зависит от возможности получения на тип элемента, хранящегося в векторе, — как упоминалось выше, vector<bool>не содержит bool.) Второй альтернативой для vector<bool>является bitset. Вообще говоря, bitsetне является стандартным контейнером STL, но входит в стандартную библиотеку C++. В отличие от контейнеров STL, размер bitset(количество элементов) фиксируется на стадии компиляции, поэтому операции вставки-удаления элементов не поддерживаются. Более того, поскольку bitsetне является контейнером STL, в нем отсутствует поддержка итераторов. Тем не менее bitset, как и vector<bool>, использует компактное представление каждого элемента одним битом, поддерживает функцию flipконтейнера vector<bool>и ряд других специальных функций, имеющих смысл в контексте битовых множеств. Если вы переживете без итераторов и динамического изменения размеров, вероятно, bitsetхорошо подойдет для ваших целей. А теперь вернемся к благородному, но неудачному эксперименту, из-за которого появился «псевдоконтейнер» vector<bool>. Я уже упоминал о том, что промежуточные объекты часто используются при программировании на C++. Члены Комитета по стандартизации C++ знали об этом, поэтому они решили создать vector<bool>как наглядный пример контейнера, доступ к элементам которого производится через промежуточные объекты. Предполагалось, что при наличии такого примера в Стандарте у программистов появится готовый образец для построения собственных аналогов. В итоге выяснилось, что создать контейнер с промежуточными объектами, удовлетворяющий всем требованиям к контейнеру STL, невозможно. Так или иначе, следы этой неудачной попытки сохранились в Стандарте. Можно долго гадать, почему vector<bool>был сохранен, но с практической точки зрения это несущественно. Главное — помните, что vector<bool>не удовлетворяет требованиям к контейнерам STL, что им лучше не пользоваться и что существуют альтернативные структуры данных deque<bool>и bitset, почти всегда способные заменить vector<bool>. |
|
||
|
Главная | Контакты | Нашёл ошибку | Прислать материал | Добавить в избранное |
||||
|
|
||||