|
||||
|
|
Алгоритмы В начале главы 1 я упоминал о том, что львиная доля репутации STL связана с контейнерами, и это вполне объяснимо. Контейнеры обладают массой достоинств и упрощают повседневную работу бесчисленных программистов C++. Но и алгоритмы STL тоже по-своему замечательны и в той же степени облегчают бремя разработчика. Существует более 100 алгоритмов, и встречается мнение, что они предо-ставляют программисту более гибкий инструментарий по сравнению с контейнерами (которых всего-то восемь!). Возможно, недостаточное применение алгоритмов отчасти и объясняется их количеством. Разобраться в восьми типах контейнеров проще, чем запомнить имена и предназначение многочисленных алгоритмов. В этой главе я постараюсь решить две основные задачи. Во-первых, я представлю некоторые малоизвестные алгоритмы и покажу, как с их помощью упростить себе жизнь. Не беспокойтесь, вам не придется запоминать длинные списки имен. Алгоритмы, представленные в этой главе, предназначены для решения повседневных задач — сравнение строк без учета регистра символов, эффективный поиск nобъектов, в наибольшей степени соответствующих заданному критерию, обобщение характеристик всех объектов в заданном интервале и имитация copy_if(алгоритм из исходной реализации HP STL, исключенный в процессе стандартизации). Во-вторых, я научу вас избегать стандартных ошибок, возникающих при работе с алгоритмами. Например, при вызове алгоритма remove и его родственников remove_ifи uniqueнеобходимо точно знать, что эти алгоритмы делают (и чего они не делают). Данное правило особенно актуально при вызове removeдля интервала, содержащего указатели. Многие алгоритмы работают только с отсортированными интервалами, и программист должен понимать, что это за алгоритмы и почему для них установлено подобное ограничение. Наконец, одна из наиболее распространенных ошибок, допускаемых при работе с алгоритмами, заключается в том, что программист предлагает алгоритму записать результаты своей работы в несуществующую область памяти. Я покажу, как это происходит и как предотвратить эту ошибку. Возможно, к концу главы вы и не будете относиться к алгоритмам с тем же энтузиазмом, с которым обычно относятся к контейнерам, но по крайней мере будете чаще применять их в своей работе. Совет 30. Следите за тем, чтобы приемный интервал имел достаточный размер Контейнеры STL автоматически увеличиваются с добавлением новых объектов (функциями insert, push_front, push_backи т. д.). Автоматическое изменение размеров чрезвычайно удобно, и у многих программистов создается ложное впечатление, что контейнер сам обо всем позаботится и им никогда не придется следить за наличием свободного места. Если бы так! Проблемы возникают в ситуации, когда программист думает о вставке объектов в контейнер, но не сообщает о своих мыслях STL. Типичный пример: int transmogrify(int х); // Функция вычисляет некое новое значение // по переданному параметру х vector<int> values; … // Заполнение вектора values данными vector<int> results; // Применить transmogrify к каждому объекту transform(values.begin(), // вектора values и присоединить возвращаемые values.end(), // значения к results. results.end(), // Фрагмент содержит ошибку! transmogrify); В приведенном примере алгоритм transformполучает информацию о том, что приемный интервал начинается с results.end. С этой позиции он и начинает вывод значений, полученных в результате вызова transmogrifyдля каждого элемента values. Как и все алгоритмы, использующие приемный интервал, transformзаписывает свои результаты, присваивая значения элементам заданного интервала. Таким образом, transformвызовет transmogrifyдля values[0]и присвоит результат *results.end(). Затем функция transmogrifyвызывается для values[1]с присваиванием результата *(results.end()+1). Происходит катастрофа, поскольку в позиции *results.end()(и тем более в *(results.end()+1))не существует объекта! Вызов transformнекорректен из-за попытки присвоить значение несуществующему объекту (в совете 50 объясняется, как отладочная реализация STL позволит обнаружить эту проблему на стадии выполнения). Допуская подобную ошибку, программист почти всегда рассчитывает на то, что результаты вызова алгоритма будут вставлены в приемный контейнер вызовом insert. Если вы хотите, чтобы это произошло, так и скажите. В конце концов, STL — всего лишь библиотека, и читать мысли ей не положено. В нашем примере задача решается построением итератора, определяющего начало приемного интервала, вызовом back_inserter: vector<int> values; transform(values.begin(), // Применить transmogrify к каждому values.end(), // объекту вектора values back_inserter(results), // и дописать значения в конец results transmogrify); При использовании итератора, возвращаемого при вызове back_inserter, вызывается push_back, поэтому back_inserterможет использоваться со всеми контейнерами, поддерживающими push_back(то есть со всеми стандартными последовательными контейнерами: vector, string, dequeи list). Если вы предпочитаете, чтобы алгоритм вставлял элементы в начало контейнера, Воспользуйтесь front_inserter. Во внутренней реализации front_inserterиспользуется push_front, поэтому front_inserterработает только с контейнерами, поддерживающими эту функцию (то есть dequeи list). … //См. ранее list<int> results; // Теперь используется // контейнер list transform(values.begin(), values.end(), // Результаты вызова transform front_inserter(results), // вставляются в начало results transmogrify); //в обратном порядке Поскольку при использовании front_inserterновые элементы заносятся в начало resultsфункцией push_front, порядок следования объектов в resultsбудет обратным по отношению к порядку соответствующих объектов в values. Это ишь одна из причин, по которым front_inserterиспользуется реже back_inserter. Другая причина заключается в том, что vectorне поддерживает push_front, поэтому front_inserterне может использоваться с vector. Чтобы результаты transformвыводились в начале results, но с сохранением порядка следования элементов, достаточно перебрать содержимое valuesв обратном порядке: list<int> results; // См. ранее … transform(values.rbegin(), values.rend(), // Результаты вызова transform front_inserter(results), // вставляются в начало results transmogrify); // с сохранением исходного порядка Итак, front_inserterзаставляет алгоритмы вставлять результаты своей работы в начало контейнера, a back_inserterобеспечивает вставку в конец контейнера. Вполне логично предположить, что inserterзаставляет алгоритм выводить свои результаты с произвольной позиции: vector<int> values; // См. ранее … vector<int> results; // См. ранее - за исключением того, что … // results на этот раз содержит данные // перед вызовом transform. transform(values.begin(), // Результаты вызова transmogrify values.end(), // выводятся в середине results inserter(results, results, begin()+results.size()/2), transmogrify); Независимо от выбранной формы — back_inserter, front_inserterили inserter— объекты вставляются в приемный интервал по одному. Как объясняется в совете 5, это может привести к значительным затратам для блоковых контейнеров ( vector, stringи deque), однако средство, предложенное в совете 5 (интервальные функции), неприменимо в том случае, если вставка выполняется алгоритмом. В нашем примере transformзаписывает результаты в приемный интервал по одному элементу, и с этим ничего не поделаешь. При вставке в контейнеры vectorи stringдля сокращения затрат можно последовать совету 14 и заранее вызвать reserve. Затраты на сдвиг элементов при каждой вставке от этого не исчезнут, но по крайней мере вы избавитесь от необходимости перераспределения памяти контейнера: vector<int> values; // См. Ранее vector<int> results; … results.reserve(results.size()+values.size()); // Обеспечить наличие // в векторе results // емкости для value.size() // элементов transform(values.begin(), values.end(), // То же, что и ранее, inserter(results, results.begin()+results.size()/2), // но без лишних transmogrify); // перераспределений памяти При использовании функции reserveдля повышения эффективности серии вставок всегда помните, что reserveувеличивает только емкость контейнера, а размер остается неизменным. Даже после вызова reserveпри работе с алгоритмом, который должен включать новые элементы в vectorили string, необходимо использовать итератор вставки (то есть итератор, возвращаемый при вызове back_inserter, front_inserterили inserter). Чтобы это стало абсолютно ясно, рассмотрим ошибочный путь повышения эффективности для примера, приведенного в начале совета (с присоединением результатов обработки элементов valuesк results): vector<int> values; // См. ранее vector<int> results; … results.reserve(results.size()+values.size()); // См. ранее transform(values.begin(), values.end(), // Результаты вызова results.end(), // transmogrify записываются transmogrify); // в неинициализированную // память; последствия // непредсказуемы! В этом фрагменте transformв блаженном неведении пытается выполнить присваивание в неинициализированной памяти за последним элементом results. Обычно подобные попытки приводят к ошибкам времени выполнения, поскольку операция присваивания имеет смысл лишь для двух объектов, но не между объектом и двоичным блоком с неизвестным содержимым. Но даже если этот код каким-то образом справится с задачей, вектор resultsне будет знать о новых «объектах», якобы созданных в его неиспользуемой памяти. С точки зрения resultsвектор после вызова transformсохраняет прежний размер, а его конечный итератор будет указывать на ту же позицию, на которую он указывал до вызова transform. Мораль? Использование reserveбез итератора вставки приводит к непредсказуемым последствиям внутри алгоритмов и нарушению целостности данных в контейнере. В правильном решении функция reserveиспользуется в сочетании с итератором вставки: vector<int> values; // См. ранее vector<int> results; … results.reserve(results.size()+values.size()); // См. ранее transform(values.begin(), values.end(), // Результаты вызова back_inserter(results), // transmogrify записываются transmogrify); // в конец вектора results // без лишних перераспределений // памяти До настоящего момента предполагалось, что алгоритмы (такие как transform) записывают результаты своей работы в контейнер в виде новых элементов. Эта ситуация является наиболее распространенной, но иногда новые данные требуется записать поверх существующих. В таких случаях итератор вставки не нужен, но вы должны в соответствии с данным советом проследить за тем, чтобы приемный интервал был достаточно велик. Допустим, вызов transformдолжен записывать результаты в resultsповерх существующих элементов. Если количество элементов в resultsне меньше их количества в values, задача решается просто. В противном случае придется либо воспользоваться функцией resizeдля приведения resultsк нужному размеру: vector<int> results; … if (results.size() < values.size()) { // Убедиться в том, что размер results.resize(values.size()); // results по крайней мере } // не меньше размера values transform(values,begin(), values.end(), // Перезаписать первые back_inserter(results), // values.size() элементов results transmogrify); либо очистить resultsи затем использовать итератор вставки стандартным способом: … results.clear(); // Удалить из results все элементы results.reserve(values.size()); // Зарезервировать память transform(values.begin(), values.end(), // Занести выходные данные back_inserter(results), // transform в results transmogrify); В данном совете было продемонстрировано немало вариаций на заданную тему, но я надеюсь, что в памяти у вас останется основная мелодия. Каждый раз, когда вы используете алгоритм, требующий определения приемного интервала, позаботьтесь о том, чтобы приемный интервал имел достаточные размеры или автоматически увеличивался во время работы алгоритма. Второй вариант реализуется при помощи итераторов вставки — таких, как ostream_iterator, или возвращаемых в результате вызова back_inserter, front_inserterи inserter. Вот и все, о чем необходимо помнить. Совет 31. Помните о существовании разных средств сортировки Когда речь заходит об упорядочении объектов, многим программистам приходит в голову всего один алгоритм: sort(некоторые вспоминают о qsort, но после прочтения совета 46 они раскаиваются и возвращаются к мыслям о sort). Действительно, sort— превосходный алгоритм, однако полноценная сортировка требуется далеко не всегда. Например, если у вас имеется вектор объектов Widgetи вы хотите отобрать 20 «лучших» объектов с максимальным рангом, можно ограничиться сортировкой, позволяющей выявить 20 нужных объектов и оставить остальные объекты несортированными. Задача называется частичной сортировкой, и для ее решения существует специальный алгоритм partial_sort: bool qualityCompare(const Widgets lhs, const Widgets rhs) { // Вернуть признак сравнения атрибутов quality // объектов lhs и rhs } … partial_sort(widgets.begin(), // Разместить 20 элементов widgets.begin()+20, // с максимальным рангом widgets.end(), // в начале вектора widgets qualityCompare); … // Использование widgets После вызова partial_sortпервые 20 элементов widgetsнаходятся в начале контейнера и располагаются по порядку, то есть widgets[0]содержит Widgetс наибольшим рангом, затем следует widgets[1]и т. д. Если вы хотите выделить 20 объектов Widgetи передать их 20 клиентам, но при этом вас не интересует, какой объект будет передан тому или иному клиенту, даже алгоритм partial_sortпревышает реальные потребности. В описанной ситуации требуется выделить 20 «лучших» объектов Widgetв произвольном порядке. В STL имеется алгоритм, который решает именно эту задачу, однако его имя выглядит несколько неожиданно — он называется nth_element. Алгоритм nth_elementсортирует интервал таким образом, что в заданной вами позиции nоказывается именно тот элемент, который оказался бы в ней при полной сортировке контейнера. Кроме того, при выходе из nth_elementни один из элементов в позициях до nне находится в порядке сортировки после элемента, находящегося в позиции n, а ни один из элементов в позициях после nне предшествует элементу, находящемуся в позиции n. Если такая формулировка кажется слишком сложной, это объясняется лишь тем, что мне приходилось тщательно подбирать слова. Вскоре я объясню причины, но сначала мы рассмотрим пример использования nth_elementдля перемещения 20 «лучших» объектов Widgetв начало контейнера widgets: nth_element(widgets.begin(), // Переместить 20 «лучших» элементов widgets.begin()+20, // в начало widgets widgets.end(), // в произвольном порядке qualityCompare); Как видите, вызов nth_elementпрактически не отличается от вызова partial_sort. Единственное различие заключается в том, что partial_sortсортирует элементы в позициях 1-20, a nth_elementэтого не делает. Впрочем, оба алгоритма перемещают 20 объектов Widgetс максимальными значениями ранга в начало вектора. Возникает важный вопрос — что делают эти алгоритмы для элементов с одинаковыми значениями атрибута? Предположим, вектор содержит 12 элементов с рангом 1 и 15 элементов с рангом 2. В этом случае выборка 20 «лучших» объектов Widgetбудет состоять из 12 объектов с рангом 1 и 8 из 15 объектов с рангом 2. Но как алгоритмы partial_sortи nth_elementопределяют, какие из 15 объектов следует отобрать в «верхнюю двадцатку»? И как алгоритм sortвыбирает относительный порядок размещения элементов при совпадении рангов? Алгоритмы partial_sortи nth_elementупорядочивают эквивалентные элементы по своему усмотрению, и сделать с этим ничего нельзя (понятие эквивалентности рассматривается в совете 19). Когда в приведенном примере возникает задача заполнения объектами Widgetс рангом 2 восьми последних позиций в «верхней двадцатке», алгоритм выберет такие объекты, какие сочтет нужным. Впрочем, такое поведение вполне разумно. Если вы запрашиваете 20 «лучших» объектов Widget, а некоторых объекты равны, то в результате возвращенные объекты будут по крайней мере «не хуже» тех, которые возвращены не были. Полноценная сортировка обладает несколько большими возможностями. Некоторые алгоритмы сортировки стабильны. При стабильной сортировке два эквивалентных элемента в интервале сохраняют свои относительные позиции после сортировки. Таким образом, если WidgetA предшествует WidgetB в несортированном векторе widgetsи при этом ранги двух объектов совпадают, стабильный алгоритм сортировки гарантирует, что после сортировки WidgetA по-прежнему будет предшествовать WidgetB. Нестабильный алгоритм такой гарантии не дает. Алгоритм partial_sort, как и алгоритм nth_element, стабильным не является. Алгоритм sortтакже не обладает свойством стабильности, но существует специальный алгоритм stable_sort, который, как следует из его названия, является стабильным. При необходимости выполнить стабильную сортировку, вероятно, следует воспользоваться stable_sort. В STL не входят стабильные версии partial_sortи nth_element. Следует заметить, что алгоритм nth_element чрезвычайно универсален. Помимо выделения nверхних элементов в интервале, он также может использоваться для вычисления медианы по интервалу и поиска значения конкретного процентиля[3]: vector<Widget>::iterator begin(widgets.begin()); // Вспомогательные переменные vector<Widget>::iterator end(widgets.end()); // для начального и конечного // итераторов widgets vector<Widget>::iterator goalPosition; // Итератор, указывающий на // интересующий нас объект Widget // Следующий фрагмент находит Widget с рангом median goalPosition = begin + widgets.size()/2; // Нужный объект находится // в середине отсортированного вектора nth_element(begin, goalPosition, end, // Найти ранг median в widgets qualityCompare); … // goalPositon теперь указывает // на Widget с рангом median // Следующий фрагмент находит Widget с уровнем 75 процентилей vector<Widget>::size_type goalOffset = // Вычислить удаление нужного 0.25*widgets.size(); // объекта Widget от начала nth_element(begin, egin+goalOffset, nd, // Найти ранг в ualityCompare); // begin+goalOffset теперь … // указывает на Widget // с уровнем 75 процентилей Алгоритмы sort, stable_sortи partial_sortхорошо подходят для упорядочивания результатов сортировки, а алгоритм nth_elementрешает задачу идентификации верхних nэлементов или элемента, находящегося в заданной позиции. Иногда возникает задача, близкая к алгоритму nth_element, но несколько отличающаяся от него. Предположим, вместо 20 объектов Widgetс максимальным рангом потребовалось выделить все объекты Widgetс рангом 1 или 2. Конечно, можно отсортировать вектор по рангу и затем найти первый элемент с рангом, большим 2. Найденный элемент определяет начало интервала с объектами Widget, ранг которых превышает 2. Полная сортировка потребует большого объема работы, совершенно ненужной для поставленной цели. Более разумное решение основано на использовании алгоритма partition, упорядочивающего элементы интервала так, что все элементы, удовлетворяющие заданному критерию, оказываются в начале интервала. Например, для перемещения всех объектов Widgetс рангом 2 и более в начало вектора widgetsопределяется функция идентификации: bool hasAcceptableQualty(const Widgets w) { // Вернуть результат проверки того, имеет ли объект w ранг больше 2 } Затем эта функция передается при вызове partition: vector<Widget>::iterator goodEnd = // Переместить все объекты Widget, partition(widgets.begin(), // удовлетворяющие условию widgets.end(), // hasAcceptableQuality, в начало hasAcceptableQuality); // widgets и вернуть итератор // для первого объекта, // не удовлетворяющего условию После вызова интервал от widgets.begin()до goodEndсодержит все объекты Widgetс рангом 1 и 2, а интервал от goodEndдо widgets.end()содержит все объекты Widgetс большими значениями ранга. Если бы в процессе деления потребовалось сохранить относительные позиции объектов Widgetс эквивалентными рангами, вместо алгоритма partition следовало бы использовать stable_partition. Алгоритмы sort, stable_sort, partial_sortи nth_elementработают с итераторами произвольного доступа, поэтому они применимы только к контейнерам vector, string, dequeи array. Сортировка элементов в стандартных ассоциативных контейнерах бессмысленна, поскольку эти контейнеры автоматически хранятся в отсортированном состоянии благодаря собственным функциям сравнения. Единственным контейнером, к которому хотелось бы применить алгоритмы sort, stable_sort, partial_sortи nth_element, является контейнер list— к сожалению, это невозможно, но контейнер listотчасти компенсирует этот недостаток функцией sort(интересная подробность: list::sortвыполняет стабильную сортировку). Таким образом, полноценная сортировка listвозможна, но алгоритмы partial_sortи nth_elementприходится имитировать. В одном из таких обходных решений элементы копируются в контейнер с итераторами произвольного доступа, после чего нужный алгоритм применяется к этому контейнеру. Другое обходное решение заключается в создании контейнера, содержащего list::iterator, применении алгоритма к этому контейнеру и последующему обращению к элементам списка через итераторы. Третье решение основано на использовании информации упорядоченного контейнера итераторов для итеративной врезки ( splice) элементов listв нужной позиции. Как видите, выбор достаточно широк. Алгоритмы partitionи stable_partitionотличаются от sort, stable_sort, partial_sortи nth_elementтем, что они работают только с двусторонними итераторами. Таким образом, алгоритмы partitionи stable_partitionмогут использоваться с любыми стандартными последовательными контейнерами. Подведем краткий итог возможностей и средств сортировки. • Полная сортировка в контейнерах vector, string, dequeи array: алгоритмы sortи stable_sort. • Выделение nначальных элементов в контейнерах vector, string, dequeи array: алгоритм partial_sort. • Идентификация nначальных элементов или элемента, находящегося в позиции n, в контейнерах vector, string, dequeи array: алгоритм nth_element. • Разделение элементов стандартного последовательного контейнера на удовлетворяющие и не удовлетворяющие некоторому критерию: алгоритмы partitionи stable_partition. • Контейнер list: алгоритмы partitionи stable_partition; вместо sortи stable_sortможет использоваться list::sort. Алгоритмы partial_sortили nth_elementприходится имитировать. Существует несколько вариантов их реализации, некоторые из которых были представлены выше. Чтобы данные постоянно находились в отсортированном состоянии, сохраните их в стандартном ассоциативном контейнере. Стоит также рассмотреть возможность использования стандартного контейнера priority_queue, данные которого тоже хранятся в отсортированном виде (контейнер priority_queueтрадиционно считается частью STL, но, как упоминалось в предисловии, в моем определении «контейнер STL» должен поддерживать итераторы, тогда как контейнер priority_queueих не поддерживает). «А что можно сказать о быстродействии?» — спросите вы. Хороший вопрос. В общем случае время работы алгоритма зависит от объема выполняемой работы, а алгоритмам стабильной сортировки приходится выполнять больше работы, чем алгоритмам, игнорирующим фактор стабильности. В следующем списке алгоритмы, описанные в данном совете, упорядочены по возрастанию затрачиваемых ресурсов (времени и памяти): 1. partition; 2. stable_partition; 3. nth_element; 4. partial_sort; 5. sort; 6. stable_sort. При выборе алгоритма сортировки я рекомендую руководствоваться целью, а не соображениями быстродействия. Если выбранный алгоритм ограничивается строго необходимыми функциями и не выполняет лишней работы (например, partitionвместо полной сортировки алгоритмом sort), то программа будет не только четко выражать свое предназначение, но и наиболее эффективно решать поставленную задачу средствами STL. Совет 32. Сопровождайте вызовы remove-подобных алгоритмов вызовом erase Начнем с краткого обзора remove, поскольку этот алгоритм вызывает больше всего недоразумений в STL. Прежде всего необходимо рассеять все сомнения относительно того, что делает алгоритм remove, а также почему и как он это делает. Объявление removeвыглядит следующим образом: template<class ForwardIterator, class T> ForwardIterator remove(ForwardIterator first, ForwardIterator last, const T& value); Как и все алгоритмы, removeполучает пару итераторов, определяющих интервал элементов, с которыми выполняется операция. Контейнер при вызове не передается, потому removeне знает, в каком контейнере находятся искомые элементы. Более того, removeне может самостоятельно определить этот контейнер, поскольку не существует способа перехода от итератора к контейнеру, соответствующему ему. Попробуем разобраться, как происходит удаление элементов из контейнера. Существует только один способ — вызов соответствующей функции контейнера, почти всегда некоторой разновидности erase(контейнер listсодержит пару функций удаления элементов, имена которых не содержат erase). Поскольку удаление элемента из контейнера может производиться только вызовом функции данного контейнера, а алгоритм removeне может определить, с каким контейнером он работает, значит, алгоритм removeне может удалять элементы из контейнера. Этим объясняется тот удивительный факт, что вызов removeне изменяет количества элементов в контейнере: vector<int> v; // Создать vector<int> и заполнить его v.reserve(10); // числами 1-10 (вызов reserve описан for (int i=1; i<=10; ++i){ // в совете 14) v.push_back(i); }; cout << v.size(); // Выводится число 10 v[3]=v[5]=v[9]=99; // Присвоить 3 элементам значение 99 remove(v.begin(), v.end(), 99); // Удалить все элементы со значением 99 cout << v.size(); // Все равно выводится 10! Чтобы понять смысл происходящего, необходимо запомнить следующее: Алгоритм remove «по настоящему» ничего не удаляет, потому что не может. На всякий случай повторю: …потому что не может! Алгоритм removeне знает, из какого контейнера он должен удалять элементы, а без этого он не может вызвать функцию «настоящего» удаления. Итак, теперь вы знаете, чего алгоритм removeсделать не может и по каким причинам. Остается понять, что же он все-таки делает. В общих чертах removeперемещает элементы в заданном интервале до тех пор, пока все «оставшиеся» элементы не окажутся в начале интервала (с сохранением их относительного порядка). Алгоритм возвращает итератор, указывающий на позицию за последним «оставшимся» элементом. Таким образом, возвращаемое значение можно интерпретировать как новый «логический конец» интервала. В рассмотренном выше примере вектор vперед вызовом removeвыглядел следующим образом: 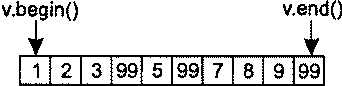 Предположим, возвращаемое значение removeсохраняется в новом итераторе с именем newEnd: vector<int>::iterator newEnd(remove(v.begin(), v.end(), 99)); После вызова вектор vпринимает следующий вид: 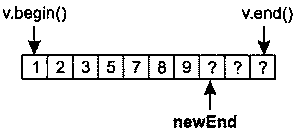 Вопросительными знаками отмечены значения элементов, «концептуально» удаленных из v, но продолжающих благополучно существовать. Раз «оставшиеся» элементы v находятся между v.begin()и newEnd, было бы логично предположить, что «удаленные» элементы будут находиться между newEndи v.end(). Но это не так! Присутствие «удаленных» элементов в v вообще не гарантировано. Алгоритм removeне изменяет порядок элементов в интервале так, чтобы «удаленные» элементы сгруппировались в конце — он перемещает «остающиеся» элементы в начало. Хотя в Стандарте такое требование отсутствует, элементы за новым логическим концом интервала обычно сохраняют свои старые значения. Во всех известных мне реализациях после вызова removeвектор vвыглядит так: 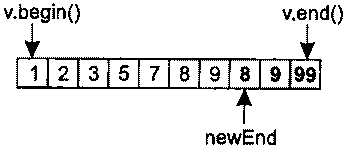 Как видите, два значения «99», ранее существовавших в v, исчезли, а одно осталось. В общем случае после вызова removeэлементы, удаленные из интервала, могут остаться в нем, а могут исчезнуть. Многие программисты находят это странным, но почему? Вы просите removeубрать некоторые элементы, алгоритм выполняет вашу просьбу. Вы же не просили разместить удаленные значения в особом месте для последующего использования… Так в чем проблема? (Чтобы предотвратить потерю значений, вместо remove лучше воспользоваться алгоритмом partition, описанным в совете 31.) На первый взгляд поведение remove выглядит довольно странно, но оно является прямым следствием принципа работы алгоритма. Во внутренней реализации removeперебирает содержимое интервала и перезаписывает «удаляемые» значения «сохраняемыми». Перезапись реализуется посредством присваивания. Алгоритм removeможно рассматривать как разновидность уплотнения, при этом удаляемые значения играют роль «пустот», заполняемых в процессе уплотнения. Опишем, что происходит с вектором v из нашего примера. 1. Алгоритм removeанализирует v[0], видит, что данный элемент не должен удаляться, и перемещается к v[1]. То же самое происходит с элементами v[1]и v[2]. 2. Алгоритм определяет, что элемент v[3]подлежит удалению, запоминает этот факт и переходит к v[4]. Фактически v[3]рассматривается как «дыра», подлежащая заполнению. 3. Значение v[4]необходимо сохранить, поэтому алгоритм присваивает v[4]элементу v[3], запоминает, что v[4]подлежит перезаписи, и переходит к v[5]. Если продолжить аналогию с уплотнением, элемент v[3]«заполняется» значением v[4], а на месте v[4]образуется новая «дыра». 4. Элемент v[5]исключается, поэтому алгоритм игнорирует его и переходит к v[6]. При этом он продолжает помнить, что на месте v[4]остается «дыра», которую нужно заполнить. 5. Элемент v[6]сохраняется, поэтому алгоритм присваивает v[6]элементу v[4], вспоминает, что следующая «дыра» находится на месте v[5], и переходит к v[7]. 6. Аналогичным образом анализируются элементы v[7], v[8]и v[9]. Значение v[7]присваивается элементу v[5], а значение v[8]присваивается элементу v[6]. Элемент v[9]игнорируется, поскольку находящееся в нем значение подлежит удалению. 7. Алгоритм возвращает итератор для элемента, следующего за последним «оставшимся». В данном примере это элемент v[7]. Перемещения элементов в векторе vвыглядят следующим образом: 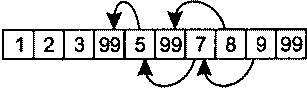 Как объясняется в совете 33, факт перезаписи некоторых удаляемых значений имеет важные последствия в том случае, если эти значения являются указателями. Но в контексте данного совета достаточно понимать, что removeне удаляет элементы из контейнера, поскольку в принципе не может этого сделать. Элементы могут удаляться лишь функциями контейнера, отсюда следует и главное правило настоящего совета: чтобы удалить элементы из контейнера, вызовите eraseпосле remove. Элементы, подлежащие фактическому удалению, определить нетрудно — это все элементы исходного интервала, начиная с нового «логического конца» интервала и завершая его «физическим» концом. Чтобы уничтожить все эти элементы, достаточно вызвать интервальную форму erase(см. совет 5) и передать ей эти два итератора. Поскольку сам алгоритм removeвозвращает итератор для нового логического конца массива, задача решается прямолинейно: vector<int> v; //См. ранее … v.erase(remove(v.begin(), v.end(), 99), v.end()); // Фактическое удаление // элементов со значением 99 cout << v.size(); // Теперь выводится 7 Передача в первом аргументе интервальной формы eraseвозвращаемого значения removeиспользуется так часто, что рассматривается как стандартная конструкция. Removeи eraseнастолько тесно связаны, что они были объединены в функцию removeконтейнера list. Это единственная функция STL с именем remove, которая производит фактическое удаление элементов из контейнера: list<int> li; // Создать список … // Заполнить данными li.remove(99); // Удалить все элементы со значением 99. // Команда производит фактическое удаление // элементов из контейнера, поэтому размер li // может измениться Честно говоря, выбор имени removeв данном случае выглядит непоследовательно. В ассоциативных контейнерах аналогичная функция называется erase, поэтому в контейнере listфункцию removeтоже следовало назвать erase. Впрочем, этого не произошло, поэтому остается лишь смириться. Мир, в котором мы живем, не идеален, но другого все равно нет. Как упоминается в совете 44, для контейнеров listвызов функции removeболее эффективен, чем применение идиомы erase/remove. Как только вы поймете, что алгоритм removeне может «по-настоящему» удалять объекты из контейнера, применение его в сочетании с eraseвойдет в привычку. Не забывайте, что remove— не единственный алгоритм, к которому относится это замечание. Существуют два других remove-подобных алгоритма: remove_ifи unique. Сходство между removeи remove_ifнастолько прямолинейно, что я не буду на нем останавливаться, но алгоритм uniqueтоже похож на remove. Он предназначен для удаления смежных повторяющихся значений из интервала без доступа к контейнеру, содержащему элементы интервала. Следовательно, если вы хотите действительно удалить элементы из контейнера, вызов uniqueдолжен сопровождаться парным вызовом erase. В контейнере listтакже предусмотрена функция unique, производящая фактическое удаление смежных дубликатов. По эффективности она превосходит связку erase-unique. Совет 33. Будьте внимательны при использовании remove-подобных алгоритмов с контейнерами указателей Предположим, мы динамически создаем ряд объектов Widgetи сохраняем полученные указатели в векторе: class Widget { public: … bool isCertified() const; // Функция сертификации объектов Widget } vector<Widget*> v; // Создать вектор и заполнить его указателями … // на динамически созданные объекты Widget v.push_back(new Widget); … Поработав с vв течение некоторого времени, вы решаете избавиться от объектов Widget, не сертифицированных функцией Widget, поскольку они вам не нужны. С учетом рекомендаций, приведенных в совете 43 (по возможности использовать алгоритмы вместо циклов), и того, что говорилось в совете 32 о связи removeи erase, возникает естественное желание использовать идиому erase-remove, хотя в данном случае используется алгоритм remove_if: v.erase(remove_if(v.begin(), v.end(), // Удалить указатели на объекты not1(mem_fun(&Widget::isCertified))), // Widget, непрошедшие v.end()); // сертификацию. // Информация о mem_fun // приведена в совете 41. Внезапно у вас возникает беспокойство по поводу вызова erase, поскольку вам смутно припоминается совет 7 — уничтожение указателя в контейнере не приводит к удалению объекта, на который он ссылается. Беспокойство вполне оправданное, но в этом случае оно запоздало. Вполне возможно, что к моменту вызова eraseутечка ресурсов уже произошла. Прежде чем беспокоиться о вызове erase, стоит обратить внимание на remove_if. Допустим, перед вызовом remove_ifвектор vимеет следующий вид: 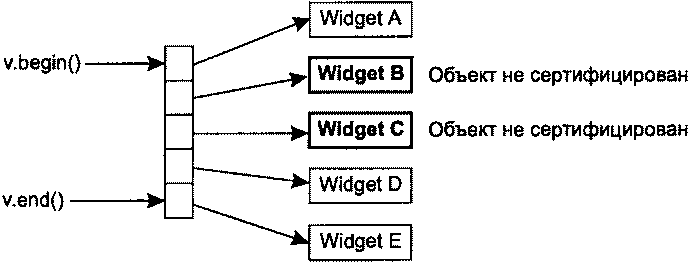 После вызова remove_ifвектор выглядит примерно так (с итератором, возвращаемым при вызове remove_if): 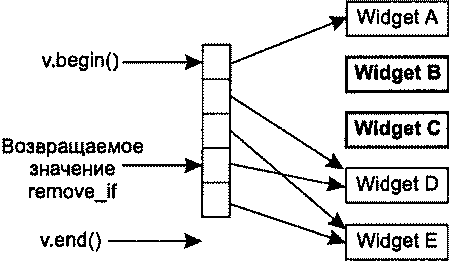 Если подобное превращение кажется непонятным, обратитесь к совету 32, где подробно описано, что происходит при вызове remove(в данном случае — remove_if). Причина утечки ресурсов очевидна. «Удаленные» указатели на объекты B и C были перезаписаны «оставшимися» указателями. На два объекта Widgetне существует ни одного указателя, они никогда не будут удалены, а занимаемая ими память расходуется впустую. После выполнения remove_ifи eraseситуация выглядит следующим образом: 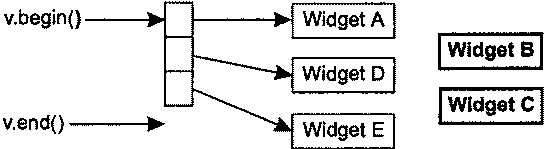 Здесь утечка ресурсов становится особенно очевидной, и к настоящему моменту вам должно быть ясно, почему алгоритмы removeи его аналоги ( remove_ifи unique) не рекомендуется вызывать для контейнеров, содержащих указатели на динамически выделенную память. Во многих случаях разумной альтернативой является алгоритм partition(см. совет 31). Если без removeникак не обойтись, одно из решений проблемы заключается в освобождении указателей на несертифицированные объекты и присваивании им nullперед применением идиомы erase-removeс последующим удалением из контейнера всех null-указателей: void delAndNullifyUncertified(Widget*& pWidget) // Если объект *pWidget { // не сертифицирован, if (!pWidget()->isCertified()) { //удалить указатель delete pWidget; //и присвоить ему null pWidget = 0; } for_each(v.begin(), v.end(), // Удалить и обнулить все указатели на delAndNullifyUncertified); // все указатели на объекты, не прошедшие // сертификацию v.erase(remove(v.begin(), v.end(), // Удалить из v указатели null; static_cast<Widget*>(0)), // 0 преобразуется в указатель, чтобы C++ v.end()); // правильно определял тип третьего параметра Приведенное решение предполагает, что вектор не содержит null-указателей, которые бы требовалось сохранить. В противном случае вам, вероятно, придется написать собственный цикл, который будет удалять указатели в процессе перебора. Удаление элементов из контейнера в процессе перебора связано с некоторыми тонкостями, поэтому перед реализацией этого решения желательно прочитать совет 9. Если контейнер указателей заменяется контейнером умных указателей с подсчетом ссылок, то все трудности, связанные с remove, исчезают, а идиома erase-removeможет использоваться непосредственно: template<typename T> class RCSP{…}; // RCSP = "Reference Counting Smart Pointer" typedef RCSP<Widget> RCSPW; // RCSPW = "RCSP to Widget" vector<RCSPW> v; // Создать вектор и заполнить его … // умными указателями на динамически v.push_back(RCSPW(new Widget)); // созданные объекты Widget v.erase(remove_if(v.begin(), v.end(), // Удалить указатели на объекты not1(mem_fun(&Widget::isCertified))), // Widget, не прошедшие v.end()); // сертификацию. // Утечка ресурсов отсутствует! Чтобы этот фрагмент работал, тип умного указателя (например, RCSP<Widget>) должен преобразовываться в соответствующий тип встроенного указателя (например Widget*). Дело в том, что контейнер содержит умные указатели, но вызываемая функция (например Widget::isCertifed) работает только со встроенными указателями. Если автоматическое преобразование невозможно, компилятор выдаст сообщение об ошибке. Если в вашем программном инструментарии отсутствует шаблон умного указателя с подсчетом ссылок, попробуйте шаблон shared_ptrиз библиотеки Boost. Начальные сведения о Boostприведены в совете 50. Независимо от того, какая методика будет выбрана для работы с контейнерами динамически созданных указателей — умные указатели с подсчетом ссылок, ручное удаление и обнуление указателей перед вызовом remove-подобных алгоритмов или другой способ вашего собственного изобретения — главная тема данного совета остается актуальной: будьте внимательны при использовании remove-подобных алгоритмов с контейнерами указателей. Забывая об этой рекомендации, вы своими руками создаете предпосылки для утечки ресурсов. Совет 34. Помните о том. какие алгоритмы получают сортированные интервалы Не все алгоритмы работают с произвольными интервалами. Например, для алгоритма remove(см. советы 32 и 33) необходимы прямые итераторы и возможность присваивания через эти итераторы. Таким образом, алгоритм не применим к интервалам, определяемым итераторами ввода, а также к контейнерам map/multimapи некоторым реализациям set/multiset(см. совет 22). Аналогично, многие алгоритмы сортировки (см. совет 31) требуют итераторов произвольного доступа и потому не могут применяться к элементам списка. При нарушении этих правил компилятор выдает длинные, невразумительные сообщения об ошибках (см. совет 49). Впрочем, существуют и другие, более сложные условия. Самым распространенным среди них является то, что некоторые алгоритмы работают только с интервалами отсортированных значений. Данное требование должно неукоснительно соблюдаться, поскольку нарушение приводит не только к выдаче диагностических сообщений компилятора, но и к непредсказуемому поведению программы на стадии выполнения. Некоторые алгоритмы работают как с сортированными, так и с несортированными интервалами, но максимальную пользу приносят лишь в первом случае. Чтобы понять, почему сортированные интервалы подходят лучше, необходимо понимать принципы работы этих алгоритмов. Я знаю, что среди читателей встречаются приверженцы «силового запоминания». Ниже перечислены алгоритмы, требующие обязательной сортировки данных: binary_search lower_bound upper_bound equal_range set_union set_intersection set_difference set_symmetric_difference merge inplace_merge includes Кроме того, следующие алгоритмы обычно используются с сортированными интервалами, хотя сортировка и не является обязательным требованием: unique unique_copy Вскоре будет показано, что в определении «сортированный интервал» кроется одно важное ограничение, но сначала позвольте мне немного прояснить ситуацию с этими алгоритмами. Вам будет проще запомнить, какие алгоритмы работают с сортированными интервалами, если вы поймете, для чего нужна сортировка. Алгоритмы поиска binary_search, lower_bound, upper_boundи equal_range(см. совет 45) требуют сортированные интервалы, потому что их работа построена на бинарном поиске. Эти алгоритмы, как и функция bsearchиз библиотеки C, обеспечивают логарифмическое время поиска, но взамен вы должны предоставить им заранее отсортированные значения. Вообще говоря, логарифмическое время поиска обеспечивается не всегда. Оно гарантировано лишь в том случае, если алгоритмам передаются итераторы произвольного доступа. Если алгоритм получает менее мощные итераторы (например, двусторонние), он выполняет логарифмическое число сравнений, но работает с линейной сложностью. Это объясняется тем, что без поддержки «итераторной математики» алгоритму необходимо линейное время для перемещения между позициями интервала, в котором производится поиск. Четверка алгоритмов set_unon, set_inesection, set_diffeenceи set_symmetric_differenceпредназначена для выполнения со множествами операций с линейным временем. Почему этим алгоритмам нужны сортированные интервалы? Потому что в противном случае они не справятся со своей задачей за линейное время. Начинает прослеживаться некая закономерность — алгоритмы требуют передачи сортированных интервалов для того, чтобы обеспечить лучшее быстродействие, невозможное при работе с несортированными интервалами. В дальнейшем мы лишь найдем подтверждение этой закономерности. Алгоритмы mergeи inplace_mergeвыполняют однопроходное слияние с сортировкой: они читают два сортированных интервала и строят новый сортированный интервал, содержащий все элементы обоих исходных интервалов. Эти алгоритмы работают с линейным временем, что было бы невозможно без предварительной сортировки исходных интервалов. Перечень алгоритмов, работающих с сортированными интервалами, завершает алгоритм includes. Он проверяет, входят ли все объекты одного интервала в другой интервал. Поскольку includesрассчитывает на сортировку обоих интервалов, он обеспечивает линейное время. Без этого он в общем случае работает медленнее. В отличие от перечисленных алгоритмов, uniqueи unique_copyспособны работать и с несортированными интервалами. Но давайте взглянем на описание uniqueв Стандарте (курсив мой): «…Удаляет из каждой смежной группы равных элементов все элементы, кроме первого». Иначе говоря, если вы хотите, чтобы алгоритм uniqueудалил из интервала все дубликаты (то есть обеспечил «уникальность» значений в интервале), сначала необходимо позаботиться о группировке всех дубликатов. Как нетрудно догадаться, именно эта задача и решается в процессе сортировки. На практике алгоритм uniqueобычно применяется для исключения всех дубликатов из интервала, поэтому интервал, передаваемый при вызове unique(или unique_copy), должен быть отсортирован. Программисты Unix могут обратить внимание на поразительное сходство между алгоритмом STL uniqueи командой Unix uniq— подозреваю, что совпадение отнюдь не случайное. Следует помнить, что uniqueисключает элементы из интервала по тому же принципу, что и remove, то есть ограничивается «логическим» удалением. Если вы не совсем уверены в том, что означает этот термин, немедленно обратитесь к советам 32 и 33. Трудно выразить, сколь важно доскональное понимание принципов работы removeи remove-подобных алгоритмов. Общих представлений о происходящем недостаточно. Если вы не знаете, как работают эти алгоритмы, у вас будут неприятности. Давайте посмотрим, что же означает само понятие «сортированный интервал». Поскольку STL позволяет задать функцию сравнения, используемую в процессе сортировки, разные интервалы могут сортироваться по разным критериям. Например, интервал intможно отсортировать как стандартным образом (то есть по возрастанию), так и с использованием greater<int>, то есть по убыванию. Интервал объектов Widgetможет сортироваться как по цене, так и по дате. При таком изобилии способов сортировки очень важно, чтобы данные сортировки, находящиеся в распоряжении контейнера STL, была логически согласованы. При передаче сортированного интервала алгоритму, который также получает функцию сравнения, проследите за тем, чтобы переданная функция сравнения вела себя так же, как функция, применявшаяся при сортировке интервала. Рассмотрим пример неправильного подхода: vector<int> v; // Создать вектор, заполнить … // данными, отсортировать sort(v.begin(), v.end(), greater<int>()); // по убыванию. … // Операции с вектором // (не изменяющие содержимого). bool a5Exists = // Поиск числа 5 в векторе. binary_search(v.begin(), v.end(), 5); // Предполагается, что вектор // отсортирован по возрастанию! По умолчанию binary_searchпредполагает, что интервал, в котором производится поиск, отсортирован оператором <(то есть по возрастанию), но в приведенном примере вектор сортируется по убыванию. Как нетрудно догадаться, вызов binary_search(или lower_boundи т. д.) для интервала, порядок сортировки которого отличен от ожидаемого, приводит к непредсказуемым последствиям. Чтобы программа работала правильно, алгоритм binary_searchдолжен использовать ту же функцию сравнения, которая использовалась при вызове sort: bool a5Exists = binаry_search(v.begin(), v.end(), 5, greater<int>()); Все алгоритмы, работающие только с сортированными интервалами (то есть все алгоритмы, упоминавшиеся в данном совете, кроме uniqueи unique_copy), проверяют совпадение по критерию эквивалентности, как и стандартные ассоциативные контейнеры (которые также сортируются). С другой стороны, uniqueи unique_copyпо умолчанию проверяют совпадение по критерию равенства, хотя при вызове этим алгоритмам может передаваться предикат, определяющий альтернативный смысл «совпадения». За подробной информацией о различиях между равенством и эквивалентностью обращайтесь к совету 19. Одиннадцать алгоритмов требуют передачи сортированных интервалов для того, чтобы обеспечить повышенную эффективность, невозможную без соблюдения этого требования. Передавайте им только сортированные интервалы, помните о соответствии двух функций сравнения (передаваемой алгоритму и используемой при сортировке) и вы избавитесь от хлопот при проведении поиска, слияния и операций с множествами, а алгоритмы uniqueи unique_copyбудут удалять все дубликаты — чего вы, вероятно, и добивались. Совет 35. Реализуйте простые сравнения строк без учета регистра символов с использованием mismatch или lexicographical_compare Один из вопросов, часто задаваемых новичками в STL — «Как в STL сравниваются строки без учета регистра символов?» Простота этого вопроса обманчива. Сравнения строк без учета регистра символов могут быть очень простыми или очень сложными в зависимости от того, насколько общим должно быть ваше решение. Если игнорировать проблемы интернационализации и ограничиться строками, на которые была рассчитана функция strcmp, задача проста. Если решение должно работать со строками в языках, не поддерживаемых strcmp(то есть практически в любом языке, кроме английского), или программа должна использовать нестандартный локальный контекст, задача чрезвычайно сложна. В этом совете рассматривается простой вариант, поскольку он достаточно наглядно демонстрирует роль STL в решении задачи (более сложный вариант связан не столько с STL, сколько с проблемами локального контекста, упоминаемыми в приложении A). Чтобы простая задача стала интереснее, мы рассмотрим два возможных решения. Программисты, разрабатывающие интерфейсы сравнения строк без учета регистра, часто определяют два разных интерфейса: первый по аналогии с strcmpвозвращает отрицательное число, ноль или положительное число, а второй по аналогии с оператором <возвращает trueили false. Мы рассмотрим способы реализации обоих интерфейсов вызова с применением алгоритмов STL. Но сначала необходимо определить способ сравнения двух символов без учета регистра. Если принять во внимание аспекты интернационализации, задача не из простых. Следующая функция сравнения несколько упрощена, но в данном совете проблемы интернационализации игнорируются, и эта функция вполне подойдет: int ciCharCompare(char c1, char c2) // Сравнение символов без учета { { // регистра. Функция возвращает -1, // если c1 < c2, 0, если c1 = c2, и 1, // если c1 > c2. int lc1 = tolower(static_cast<unsigned char>(c1)); // См. Далее int lс2 = tolower(static_cast<unsigned char>(c2)); if (lc1 < lc2) return -1; if (lc1 > lc2) return 1; return 0; }; Функция ciCharCompareпо примеру strcmpвозвращает отрицательное число, ноль или положительное число в зависимости от отношения между c1и c2. В отличие от strcmp, функция ciCharCompareперед сравнением преобразует оба параметра к нижнему регистру. Именно так и достигается игнорирование регистра символов при сравнении. Параметр и возвращаемое значение функции tolower, как и у многих функций <cctype.h>, относятся к типу int, но эти числа (кроме EOF) должны представляться в виде unsigned char. В C и C++ тип charможет быть как знаковым, так и беззнаковым (в зависимости от реализации). Если тип charявляется знаковым, гарантировать его возможное представление в виде unsigned charможно лишь одним способом: преобразованием типа перед вызовом tolower, этим и объясняется присутствие преобразований в приведенном выше фрагменте (в реализациях с беззнаковым типом charпреобразование игнорируется). Кроме того, это объясняет сохранение возвращаемого значения tolowerв переменной типа intвместо char. При наличии chCharCompareпервая из двух функций сравнения строк (с интерфейсом в стиле strcmp) пишется просто. Эта функция, ciStringCompare, возвращает отрицательное число, ноль или положительное число в зависимости от отношения между сравниваемыми строками. Функция основана на алгоритме mismatch, определяющем первую позицию в двух интервалах, в которой элементы не совпадают. Но для вызова mismatchдолжны выполняться некоторые условия. В частности, необходимо проследить за тем, чтобы более короткая строка (в случае строк разной длины) передавалась в первом интервале. Вся настоящая работа выполняется функцией ciStringCompareImpl, а функция ciStringCompareлишь проверяет правильность порядка аргументов и меняет знак возвращаемого значения, если аргументы пришлось переставлять: int ciStringCompareImpl(const string& si, // Реализация приведена далее const string& s2); int ciStringCompare(const string& s1, const string& s2) { if (s1.size()<=s2.size() return cStringCompareImpl(s1, s2); else return -ciStringComparelmpl(s2, s1); } Внутри ciStringCompareImplвсю тяжелую работу выполняет алгоритм mismatch. Он возвращает пару итераторов, обозначающих позиции первых отличающихся символов в интервалах: int ciStringCompareImpl(const string& si, const string& s2) { typedef pair<string::const_iterator, // PSCI = "pair of string::const_iterator> PSCI; // string::const_iterator" PSCI p = mismatch( // Использование ptr_fun s1.begin(), s1, end(), // рассматривается s2.begin(), // в совете 41 not2(ptr_fun(сiCharCompare))); if (p.first==s1.end()) { // Если условие истинно, if (p.second==s2.end()) return 0; // либо s1 и s2 равны. else return -1; // либо s1 короче s2 } return ciCharCompare(*p.first, *p.second); // Отношение между строками } // соответствует отношению // между отличающимися // символами Надеюсь, комментарии достаточно четко объясняют происходящее. Зная первую позицию, в которой строки различаются, можно легко определить, какая из строк предшествует другой (или же определить, что эти строки равны), В предикате, переданном mismatch, может показаться странной лишь конструкция not2(ptr_fun(ciCharCompare)). Предикат возвращает trueдля совпадающих символов, поскольку алгоритм mismatchпрекращает работу, когда предикат возвращает false. Для этой цели нельзя использовать ciCharCompare, поскольку возвращается -1, 0 или 1, причем по аналогии с strcmpнулевое значение возвращается для совпадающих символов. Если передать ciCharCompareв качестве предиката для mismatch, C++ преобразует возвращаемое значение ciCharCompareк типу bool, а в этом типе нулю соответствует значениеfalse — результат прямо противоположен тому, что требовалось! Аналогично, когда ciCharCompareвозвращает 1 или -1, результат будет интерпретирован как true, поскольку в языке C все целые числа, отличные от нуля, считаются истинными логическими величинами. Чтобы исправить эту семантическую «смену знака», мы ставим not2и ptr_funперед ciCharCompareи добиваемся желаемого результата. Второй вариант реализации ciStringCompareоснован на традиционном предикате STL; такая функция может использоваться в качестве функции сравнения в ассоциативных контейнерах. Реализация проста и предельно наглядна, поскольку достаточно модифицировать ciCharCompareдля получения функции сравнения символов с предикатным интерфейсом, а затем поручить всю работу по сравнению строк алгоритму lexicographical_compare, занимающему второе место в STL по длине имени: bool ciCharLess(char c1, char c2) // Вернуть признак того, { // предшествует ли c1 // символу с2 без учета return // регистра. В совете 46 tolower(static_cast<unsigned char>(c1))< // объясняется, почему tolower(static_cast<unsigned char>(c2)); // вместо функции может } // оказаться предпочтительным // объект функции bool ciStringCompare(const string& s1, const string& s2) { return lexicographical_compare(s1.begin(), s1.end(), // Описание s2.begin(), s2.end(), // алгоритма ciCharLess); // приведено далее } Нет, я не буду долго хранить секрет. Самое длинное имя у алгоритма set_symmetric_difference. Если вы знаете, как работает lexicographical_compare, приведенный выше фрагмент понятен без объяснений, а если не знаете — это легко поправимо. Алгоритм lexicographical_compareявляется обобщенной версией strcmp. Функция strcmpработает только с символьными массивами, а lexicographical_compareработает с интервалами значений любого типа. Кроме того, если strcmpвсегда сравнивает два символа и определяет отношение между ними (равенство, меньше, больше), то lexicographical_compareможет получать произвольный предикат, который определяет, удовлетворяют ли два значения пользовательскому критерию. В предыдущем примере алгоритм lexicographical_compareдолжен найти первую позицию, в которой s1и s2различаются по критерию ciCharLess. Если для символов в этой позиции ciCharLessвозвращает true, то же самое делает и lexicographical_compare: если в первой позиции, где символы различаются, символ первой строки предшествует соответствующему символу второй строки, то первая строка предшествует второй. Алгоритм lexicographical_compare, как и strcmp, считает два интервала равных величин равными, поэтому для таких интервалов возвращается значение false: первый интервал не предшествует второму. Кроме того, по аналогии с strcmp, если первый интервал завершается до обнаружения различия, lexicographical_compareвозвращает true— префикс предшествует любому интервалу, в который он входит. Довольно о mismatchи lexicographical_compare. Хотя в этой книге большое значение уделяется переносимости программ, я просто обязан упомянуть о том, что функции сравнения строк без учета регистра символов присутствуют во многих нестандартных расширениях стандартной библиотеки C. Обычно эти функции называются stricmpили strcmpiи по аналогии с функциями, приведенными в данном совете, игнорируют проблемы интернационализации. Если вы готовы частично пожертвовать переносимостью программы, если строки заведомо не содержат внутренних нуль-символов, а проблемы интернационализации вас не волнуют, то простейший способ сравнения строк без учета регистра символов вообще не связан с STL. Обе строки преобразуются в указатели const char*(см. совет 16), передаваемые при вызове stricmpили strcmpi: int ciStringCompare(const string& si1, const string& s2) { return stricmp(sl.c_str(), s2.c_str()); // В вашей системе вместо stricmp } // может использоваться другое имя Функции strcmp/strcmp, оптимизированные для выполнения единственной задачи, обычно обрабатывают длинные строки значительно быстрее, чем обобщенные алгоритмы mismatchи lexicographical_compare. Если быстродействие особенно важно в вашей ситуации, переход от стандартных алгоритмов STL к нестандартным функциям C вполне оправдан. Иногда самый эффективный путь использования STL заключается в том, чтобы вовремя понять, что другие способы работают лучше. Совет 36. Правильно реализуйте copy_if В STL имеется 11 алгоритмов, в именах которых присутствует слово copy: copy copy_backward replace_copy reverse_copy replace_copy_if unique_copy remove_copy rotate_copy remove_copy_if partial_sort_copy uninitialized_copy Но как ни странно, алгоритма copy_ifсреди них нет. Таким образом, вы можете вызывать replace_copy_ifи remove_copy_if, к вашим услугам copy_backwardи reverse_copy, но если вдруг потребуется просто скопировать элементы интервала, удовлетворяющие определенному предикату, вам придется действовать самостоятельно. Предположим, имеется функция для отбора «дефектных» объектов Widget: bool isDefective(const Widget& w); Требуется скопировать все дефектные объекты Widgetиз вектора в cerr. Если бы алгоритм copy_ifсуществовал, это можно было бы сделать так: vector<Widget> widgets; … copy_if(widgets.begin(), widgets.end(), // He компилируется - ostream_iterator<Widget>(cerr, "\n"), // в STL не существует isDefective); // алгоритма copy_if По иронии судьбы алгоритм copy_ifвходил в исходную версию STL от Hewlett Packard, которая была заложена в основу библиотеки STL, ставшей частью стандартной библиотеки C++. В процессе сокращения HP STL до размеров, подходящих для стандартизации, алгоритм copy_ifостался за бортом. В книге «The C++ Programming Language» [7] Страуструп замечает, что реализация copy_ifвыглядит элементарно — и он прав, но это вовсе не означает, что каждый программист сразу придет к нужному решению. Например, ниже приведена вполне разумная версия copy_if, которую предлагали многие программисты (в том числе и я): template<typename InputIterator, // Не совсем правильная typename OutputIterator, // реализация copy_if typename Predicate> OutputIterator copy_if(InputIterator begin, InputIterator end, OutputIterator destBegin, Predicate p) { return remove_copy_if(begin, end, destBegin, not1(p)); } Решение основано на простом факте: хотя STL не позволяет сказать «скопировать все элементы, для которых предикат равен true», но зато можно потребовать «скопировать все элементы, кроме тех, для которых предикат неравен true». Создается впечатление, что для реализации copy_ifдостаточно поставить not1перед предикатом, который должен передаваться copy_if, после чего передать полученный предикат remove_copy_if. Результатом является приведенный выше код. Если бы эти рассуждения были верны, копирование дефектных объектов Widget можно было бы произвести следующим образом: copy_if(widgets.begin(), widgets.end(), // Хорошо задумано, ostream_iterator<Widget>(cerr, "\n"), // но не компилируется isDefective); Компилятор недоволен попыткой применения not1к isDefective(это происходит внутри copy_if). Как объясняется в совете 41, not1не может напрямую применяться к указателю на функцию — сначала указатель должен пройти через ptr_fun. Чтобы вызвать эту реализацию copy_if, необходимо передать не просто объект функции, а адаптируемый объект функции. Сделать это несложно, однако возлагать эти хлопоты на будущих клиентов алгоритма STL нельзя. Стандартные алгоритмы STL никогда не требуют, чтобы их функторы были адаптируемыми, поэтому нельзя предъявлять это требование к copy_if. Приведенная выше реализация хороша, но недостаточно хороша. Правильная реализация copy_ifдолжна выглядеть так: template<typename InputIterator, // Правильная typename OutputIterator, // реализация copy_if typename Predicate> OutputIterator copy_if(InputIterator begin, InputIterator end, OutputIterator destBegin, Predicate p) { while (begin != end) { if (p(*begin)) *destBegn++ = *begin; ++begin; } return destBegn; } Поскольку алгоритм copy_ifчрезвычайно полезен, а неопытные программисты STL часто полагают, что он входит в библиотеку, можно порекомендовать разместить реализацию copy_if— правильную реализацию! — в локальной вспомогательной библиотеке и использовать ее в случае надобности. Совет 37. Используйте accumulate или for_each для обобщения интервальных данных Иногда возникает необходимость свести целый интервал к одному числу или, в более общем случае, к одному объекту. Для стандартных задач обобщения существуют специальные алгоритмы. Так, алгоритм countвозвращает количество элементов в интервале, а алгоритм count_ifвозвращает количество элементов, соответствующих заданному предикату. Минимальное и максимальное значение элемента в интервале можно получить при помощи алгоритмов min_elementи max_element. Но в некоторых ситуациях возникает необходимость обработки интервальных данных по нестандартным критериям, и в таких случаях нужны более гибкие и универсальные средства, нежели алгоритмы count, count_if, min_elementи max_element. Предположим, вы хотите вычислить сумму длин строк в контейнере, произведение чисел из заданного интервала, усредненные координаты точек и т. д. В каждом из этих случаев производится обобщение интервала, но при этом критерий обобщения вы должны определять самостоятельно. Для подобных ситуаций в STL предусмотрен специальный алгоритм accumulate. Многим программистам этот алгоритм незнаком, поскольку в отличие от большинства алгоритмов он не находится в <algorthm>, а вместе с тремя другими «числовыми алгоритмами» ( inner_product, adjacent_differenceи partial_sum) выделен в библиотеку <numeric>. Как и многие другие алгоритмы, accumulateсуществует в двух формах. Первая форма, получающая пару итераторов и начальное значение, возвращает начальное значение в сумме со значениями из интервала, определяемого итераторами: list<double> ld; // Создать список и заполнить // несколькими значениями типа double. double sum = accumulate(ld.begin(), ld.end(), 0.0); // Вычислить сумму чисел // с начальным значением 0.0 Обратите внимание: в приведенном примере начальное значение задается в форме 0.0. Эта подробность важна. Число 0.0 относится к типу double, поэтому accumulateиспользует для хранения вычисляемой суммы переменную типа double. Предположим, вызов выглядит следующим образом: double sum = accumulate(ld.begin(), ld.end(), 0); // Вычисление суммы чисел // с начальным значением 0; // неправильно! В качестве начального значения используется int 0, поэтому accumulate накапливает вычисляемое значение в переменной типа int. В итоге это значение будет возвращено алгоритмом accumulateи использовано для инициализации переменной sum. Программа компилируется и работает, но значение sumбудет неправильным. Вместо настоящей суммы списка чисел типа double переменная содержит сумму всех чисел, преобразуемую к intпосле каждого суммирования. Алгоритм accumulateработает только с итераторами ввода и поэтому может использоваться даже с istream_iteratorи istreambuf_iterator(см. совет 29): cout << "The sum of the ints on the standard input is " // Вывести сумму << accumulate(istream_iterator<int>(cin), // чисел из входного istream_iterator<int>(), // потока 0); Из-за своей первой, стандартной формы алгоритм accumulateбыл отнесен к числовым алгоритмам. Но существует и другая, альтернативная форма, которой при вызове передается начальное значение и произвольная обобщающая функция. В этом варианте алгоритм accumulateстановится гораздо более универсальным. В качестве примера рассмотрим возможность применения accumulateдля вычисления суммы длин всех строк в контейнере. Для вычисления суммы алгоритм должен знать две вещи: начальное значение суммы (в данном случае 0) и функцию обновления суммы для каждой новой строки. Следующая функция берет предыдущее значение суммы, прибавляет к нему длину новой строки и возвращает обновленную сумму: string::size_type // См. далее stringLengthSum(string::size_type sumSoFar, const string& s) { return sumSoFar + s.size(); } Тело функции убеждает в том, что происходящее весьма тривиально, но на первый взгляд смущают объявления string::size_type. На самом деле в них нет ничего страшного. У каждого стандартного контейнера STL имеется определение типа size_type, относящееся к счетному типу данного контейнера. В частности, значение этого типа возвращается функцией size. Для всех стандартных контейнеров определение size_typeдолжно совпадать с size_t, хотя теоретически нестандартные STL-совместимые контейнеры могут использовать в size_typeдругой тип (хотя я не представляю, для чего это может понадобиться). Для стандартных контейнеров запись контейнер ::size_typeможно рассматривать как специальный синтаксис для size_t. Функция stringLenghSumявляется типичным представителем обобщающих функций, используемых при вызове accumulate. Функция получает текущее значение суммы и следующий элемент интервала, а возвращает новое значение накапливаемой суммы. Накапливаемая сумма (сумма длин строк, встречавшихся ранее) относится к типу string::size_type, а обрабатываемый элемент относится к типу string. Как это часто бывает, возвращаемое значение относится к тому же типу, что и первый параметр функции. Функция stringLenghSumиспользуется в сочетании с accumulateследующим образом: set<string> ss; // Создать контейнер строк … // и заполнить его данными string::size_type lengthSum = // Присвоить lengthSum accumulate(ss.begin(), ss.end(), // результат вызова stringLengthSum 0, stringLengthSum); // для каждого элемента ss // с нулевым начальным значением Изящно, не правда ли? Произведение вычисляется еще проще, поскольку вместо написания собственной функции суммирования можно обойтись стандартным функтором multiplies: vector<float> vf; // Создать контейнер типа float … // и заполнить его данными float product = // Присвоить product результат accumulate(vf.begin(), vf.end(), // вызова multiplies<float> 1.0, multples<float>()); // для каждого элемента vf // с начальным значением 1.0 Только не забудьте о том, что начальное значение вместо нуля должно быть равно единице (в вещественном формате, не в int!). Если начальное значение равно нулю, то результат всегда будет равен нулю — ноль, умноженный на любое число, остается нулем. Последний пример не столь тривиален. В нем вычисляется среднее арифметическое по интервалу точек, представленных структурами следующего вида: struct Point { Point(double initX, double initY): x(initX), y(initY) {} double x, y; }; В этом примере обобщающей функцией будет функтор PointAverage, но перед рассмотрением класса этого функтора стоит рассмотреть его использование при вызове accumulate: list<Point> lp; … Point avg = // Вычисление среднего accumulate(lp.begin(), lp.end(), // арифметического по точкам, Point(0,0), PointAverage()); // входящим в список lр Просто и бесхитростно, как и должно быть. На этот раз в качестве начального значения используется объектPoint, соответствующий началу координат, а нам остается лишь помнить о необходимости исключения этой точки из вычислений. Функтор PointAverageотслеживает количество обработанных точек, а также суммы их компонентов xи y. При каждом вызове он обновляет данные и возвращает средние координаты по обработанным точкам. Поскольку для каждой точки в интервале функтор вызывается ровно один раз, он делит суммы по составляющим xи yна количество точек в интервале. Начальная точка, переданная при вызове accumulate, игнорируется. class PointAverage: publiс binary_function<Point, Point, Point> { public: PointAverage(): xSum(0), ySum(0), numPoints(0) {} const Point operator() (const Point& avgSoFar, const Point& p) { ++numPoints; xSum += p.x; ySum += p.y; return Point(xSum/numPoints, ySum/numPoints); } private: size_t numPoints; double xSum; double ySum; }; Такое решение прекрасно работает, и лишь из-за периодических контактов с неординарно мыслящими личностями (многие из которых работают в Комитете по стандартизации) я могу представить себе реализации STL, в которых возможны проблемы. Тем не менее, PointAverageнарушает параграф 2 раздела 26.4.1 Стандарта, который, как вы помните, запрещает побочные эффекты по отношению к функции,передаваемой accumulate. Модификация переменных numPoints, xSumи ySumотносится к побочным эффектам, поэтому с технической точки зрения приведенный выше фрагмент приводит к непредсказуемым последствиям. На практике трудно представить, что приведенный код может не работать, но чтобы моя совесть была чиста, я обязан специально оговорить это обстоятельство. Впрочем, у меня появляется удобная возможность упомянуть о for_each— другом алгоритме, который может использоваться для обобщения интервалов. На for_eachне распространяются ограничения, установленные для accumulate. Алгоритм for_each, как и accumulate, получает интервал и функцию (обычно в виде объекта функции), вызываемую для каждого элемента в интервале, однако функция, передаваемая for_each, получает только один аргумент (текущий элемент интервала), а после завершения работы for_eachвозвращает свою функцию (а точнее, ее копию — см. совет 38). Что еще важнее, переданная (и позднее возвращаемая) функция может обладать побочными эффектами. Помимо побочных эффектов между for_eachи accumulateсуществуют два основных различия. Во-первых, само название accumulateассоциируется с вычислением сводного значения по интервалу, а название for_eachскорее предполагает выполнение некой операции с каждым элементом интервала. Алгоритм for_eachможет использоваться дя вычисления сводной величины, но такие решения по наглядности уступают accumulate. Во-вторых, accumulate непосредственно возвращает вычисленное значение, а for_eachвозвращает объект функции, используемый для дальнейшего получения информации. В C++ это означает, что в класс функтора необходимо включить функцию для получения искомых данных. Ниже приведен предыдущий пример, в котором вместо accumulate используется for_each: struct Point{…}; // См. ранее class PointAverage; public unary_function<Point, void>{ // См. совет 40 public: PointAverage(): xSum(0), ySum(0), numPoints(0) {} void operator()(const Point& p) { ++numPoints; xSum += p.x; ySum += p.y; } Point result() const { return Point(xSum/numPoints, ySum/numPoints); } private: size t numPoints; double xSum; double ySum; }; list<Point> lp; … Point avg = for_each(lp.begin(), lp.end(), PointAverage()).result(); Лично я предпочитаю обобщать интервальные данные при помощи accumulate, поскольку мне кажется, что этот алгоритм наиболее четко передает суть происходящего, однако foreachтоже работает, а вопрос побочных эффектов для for_eachне так принципиален, как для accumulate. Словом, для обобщения интервальных данных могут использоваться оба алгоритма; выберите тот, который вам лучше подойдет. Возможно, вас интересует, почему у for_eachпараметр-функция может иметь побочные эффекты, а у accumulate— не может? Представьте, я бы тоже хотел это знать. Что ж, дорогой читатель, некоторые тайны остаются за пределами наших познаний. Чем accumulateпринципиально отличается от for_each? Пока я еще не слышал убедительного ответа на этот вопрос. Примечания:3 Термин употребляется в статистике. — Примеч. ред. |
|
||
|
Главная | Контакты | Нашёл ошибку | Прислать материал | Добавить в избранное |
||||
|
|
||||