|
||||
|
|
6. Статистический анализ качества тестовых заданий и тестов 6.1. Классическая теория и методики конструирования тестов Понятие истинного балла (true score) – параметра испытуемого – является основополагающим в педагогических измерениях наряду с терминами «сырой балл»и «наблюдаемый балл», которые получаются простым суммированием оценок по отдельным заданиям теста. Нередко истинный балл называют константой испытуемого в момент измерения, не зависящей от средства измерения. Поэтому при одномерных измерениях каждому испытуемому можно поставить в соответствие только один истинный балл в отличие от наблюдаемых баллов, которых может быть столько, сколько используемых для измерения этой переменной тестов. Получение наиболее точной оценки параметра подготовленности испытуемых – главная цель каждого, кто создает или применяет педагогический тест, поскольку любые результаты тестирования всегда содержат в себе ошибочные компоненты измерения. По этой причине при создании тесты проходят процесс научного обоснования качества, который нацелен на улучшение характеристик заданий для повышения точности тестовых баллов. Этот процесс основывается на математико-статистическом аппарате классической или современной теории тестов (Item Response Theory) [1, 28, 35, 37]. Современная теория достаточно сложна, обычно она применяется профессиональными тестовыми службами для больших выборок испытуемых (более 1000 человек на вариант) и требует значительных трудозатрат при обработке и интерпретации данных для коррекции тестов. Классическую теорию используют значительно чаще, особенно при небольших выборках в 50–100 человек на каждый вариант теста. Если сразу затруднительно собрать даже столько данных, то их нужно накапливать на протяжении нескольких лет, поскольку меньшие выборки при разработке итогового теста нежелательны. Математико-статистическая обработка обычно проводится с помощью специального программного обеспечения, но хотя бы один раз ее стоит проделать вручную, чтобы понять смысл некоторых показателей качества теста. 6.2. Математико-статистический анализ качества тестов и тестовых заданий на основе классической теории тестов Если за каждый правильный ответ на задание испытуемому давать 1 балл, а за неправильный ответ или пропуск задания – 0 баллов, то профиль ответов студента будет иметь вид последовательности из единиц и нулей. Поскольку каждая единица или нуль появляются в результате взаимодействия испытуемого с заданием, то наиболее адекватной формой представления наблюдаемых результатов выполнения теста служит матрица, т.е. прямоугольная таблица, сводящая воедино профили ответов студентов и профили заданий теста (столбцы из оценок всех студентов по каждому заданию теста). Пример матрицы наблюдаемых результатов, полученной при выполнения N (N = 10) студентами n (n = 10) заданий теста при дихотомических оценках (1 или 0) по заданиям приведен в табл. 6. 1. Справа в вертикальном столбце содержатся индивидуальные баллы студентов Xi (i = 1, 2, …, N), которые получаются суммированием единиц по горизонтали в каждом профиле ответов. Сложение единиц в столбцах по профилям ответов на n заданий теста позволяет получить числа Yj (j = 1, 2, …, i), соответствующие количеству правильных ответов на каждое задание. С помощью матрицы можно выполнить ряд расчетов, интерпретация результатов которых позволяет сделать важные выводы относительно качества заданий теста и получить достаточно точные оценки параметра испытуемых в том случае, если тест соответствует определенным критериям качества. Таблица 6.1 Пример матрицы наблюдаемых результатов выполнения теста 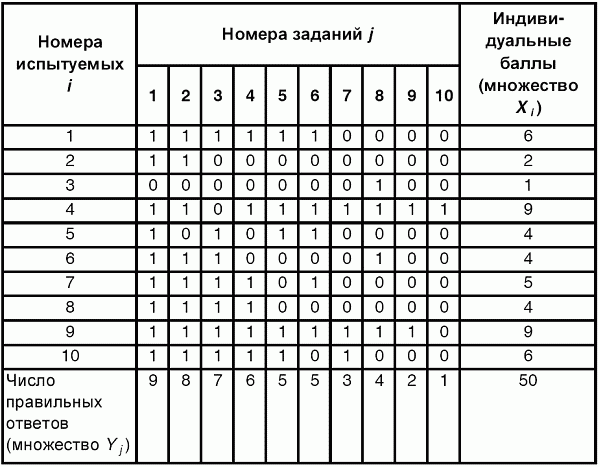 Для анализа обычно используется упорядоченная матрица, в которой не только задания ранжированы по нарастанию трудности (см. табл. 6.1), но и баллы испытуемых расположены по убыванию или нарастанию сверху вниз (табл. 6.2). По данным матрицы обычно проводят графическую интерпретацию распределений для трудности заданий и индивидуальных баллов испытуемых, которые представляют в виде полигона, гистограммы или сглаженной кривой (процентилей, огивы). Для больших выборок испытуемых (50 студентов и более) графическую интерпретацию предваряет формирование частотного распределения (табл. 6.3). Таблица 6.2 Упорядоченная матрица данных тестирования 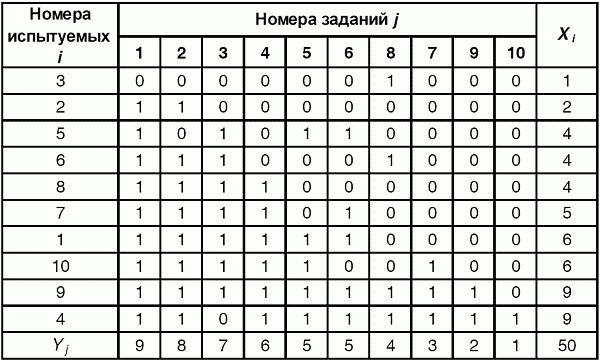 Таблица 6.3 Частотное распределение баллов  В табл. 6.3 содержатся только различные индивидуальные баллы испытуемых, взятые из последнего столбца матрицы эмпирических результатов выполнения теста и расположенные в порядке возрастания слева вместе с числом их повторений (f). Сумма всех частот для данного примера N = 1 + 1 + 3 + 1 + 2 + 2 =10, т.е. числу студентов в группе. Для очень большой группы в 100 или более студентов строят сгруппированное частотное распределение, в котором оценки объединяют в группы. Каждая группа называется разрядом оценок. В случае полного размещения оценок по разрядам говорят о распределении сгруппированных частот баллов студентов. Хотя четкого правила выбора количества разрядов нет, но обычно их число стараются варьировать в пределах от 12 до 15. По ряду частотного распределения можно получить графическое представление результатов тестирования в виде гистограммы – последовательности столбцов, каждый из которых опирается на единичный (разрядный) интервал, а высота его пропорциональна частоте наблюдаемых баллов. Например, для рассматриваемого примера (см. табл. 6.3) гистограмма приведена на рис. 6.1. Середина столбца совмещается с серединой интервала разряда, который выбран длиной в 1 балл. 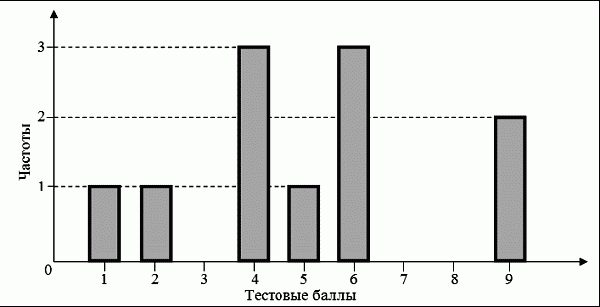 Рис. 6.1. Столбчатая гистограмма для распределения баллов в табл. 6.3 Для дальнейшего анализа данных оцениваются меры центральной тенденции в распределении результатов тестирования, которые предназначены для выявления той точки, вокруг которой в основном группируются все результаты выполнения теста. При анализе результатов тестирования можно использовать разные подходы к определению такой центральной точки. Наиболее простой способ основан на выявлении моды распределения и среднего арифметического баллов. Мода – это такое значение, которое встречается наиболее часто среди результатов выполнения теста. Например, для данных табл. 6.3 модой является балл 4, потому что он встречается чаще (3 раза) любого другого балла. Конечно, не всякое распределение имеет единственную моду, их может быть две или больше. В случае существования двух мод распределение называется бимодальным. Если все значения баллов студентов встречаются одинаково часто, принято считать, что моды у распределения нет. Среднее выборочное (среднее арифметическое) определяется суммированием всех значений совокупности и последующим делением на их число. Для индивидуальных баллов ?1, ?2, …, ХN группы N испытуемых среднее значение X? будет: (6.1) 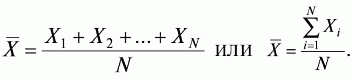 Среднее арифметическое индивидуальных баллов испытуемых для рассматриваемого выше примера матрицы (см. табл. 6.2) равно 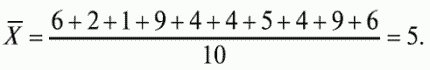 В отличие от моды, фиксирующей одно или несколько значений, на величину среднего влияют значения всех результатов распределения. Таким образом, среднее арифметическое характеризует все распределение в целом. Оно обобщает индивидуальные особенности составляющих распределения на основе уравнивания отдельных значений рассматриваемой величины. Меры центральной тенденции полезны при оценке качества теста, если есть результаты апробации теста на репрезентативной выборке студентов. Обычно считают, что хороший нормативно-ориентированный тест обеспечивает нормальное распределение индивидуальных баллов репрезентативной выборки испытуемых, если среднее значение баллов находится в центре распределения, а остальные значения концентрируются вокруг среднего по нормальному закону, т.е. примерно 70% значений находятся в центре, а остальные сходят на нет к краям распределения, как на рис. 6.2. 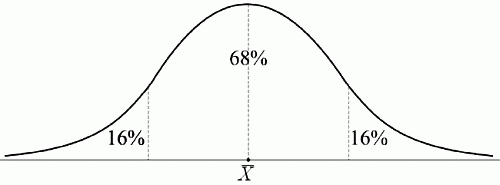 Рис. 6.2. Нормальная кривая распределения индивидуальных баллов Если тест обеспечивает распределение баллов, близкое к нормальному, то это означает, что на его основе можно определить устойчивое среднее, которое принимается в качестве одной из репрезентативных норм выполнения теста. Обратный вывод, вообще говоря, неверен: устойчивость тестовых норм не предполагает обязательного нормального распределения эмпирических результатов выполнения теста. Нормальная кривая – это изобретение математиков, которое в сглаженном, идеальном виде описывает реальный полигон частот. На практике никогда не была и не будет получена совокупность данных, распределенных точно по нормальному закону, просто иногда полезно, допуская определенную ошибку, утверждать, что распределение эмпирических данных близко к нормальной кривой. Нормальное распределение унимодально и симметрично, т.е. половина результатов, расположенная ниже моды, в точности совпадает с другой половиной, расположенной выше, а мода и среднее значение равны. Отсутствие полной симметрии в полигоне частот на практике приводит к смещению моды относительно среднего значения. В малых выборках мода, как и среднее значение, теряет свою стабильность, хотя причина нестабильности может быть другая, связанная с неправильным подбором по трудности заданий в тесте. Например, если на репрезентативной выборке студентов получилась гистограмма тестовых баллов с бимодальным распределением, то среднее значение распределения, находящееся в центре, никак не может служить нормой выполнения теста. Скорее всего, тест был сконструирован неудачно, что послужило причиной отсутствия нормального распределения эмпирических результатов выполнения теста. Смещение среднего значения баллов студентов влево или вправо говорит о слишком трудной либо слишком легкой подборке заданий теста соответственно. Таким образом, правильно сконструированный нормативно-ориентированный тест на репрезентативной выборке студентов должен обеспечивать близкое к симметричному распределение индивидуальных баллов, когда мода и среднее значение примерно равны, а остальные результаты расположены вокруг среднего по нормальному закону. Дальнейший анализ данных тестирования связан с оцениванием мер изменчивости в распределении индивидуальных баллов. Характеристика изменчивости указывает на особенности разброса эмпирических данных вокруг среднего значения баллов. Отдельные значения индивидуальных баллов могут быть тесно сгруппированы вокруг своего среднего балла либо, наоборот, сильно удалены от него. Для отражения характера рассеяния отдельных значений вокруг среднего используют различные меры: размах, дисперсию и стандартное отклонение. Размах измеряет на шкале расстояние, в пределах которого изменяются все значения показателя в распределении. Например, для распределения индивидуальных баллов в табл. 6.3 размах равен 9 – 1 = 8. Вариационный размах легко вычисляется, но используется крайне редко при характеристике распределения баллов по тесту. Во-первых, размах является весьма приближенным показателем, так как не зависит от степени изменчивости промежуточных значений, расположенных между крайними значениями в распределении баллов по тесту. Во-вторых, крайние значения индивидуальных баллов, как правило, ненадежны, поскольку содержат в себе значительную ошибку измерения. В этой связи более удачной мерой изменчивости считается дисперсия. Подсчет дисперсии основан на вычислении отклонений Xi – X? (i = 1, 2, …, N) каждого значения показателя от среднего арифметического в распределении. Для индивидуальных баллов значения отклонений несут информацию о вариации совокупности значений баллов N студентов, поскольку отражают меру неоднородности результатов по тесту. Совокупность с большей неоднородностью будет иметь большие по модулю отклонения, наоборот, для однородных распределений отклонения должны быть близки к нулю. Знак отклонения указывает место результата студента по отношению к среднему арифметическому по тесту. Для студента с индивидуальным баллом выше среднего значение разности Xi – X? будет положительно, а для тех, у кого результат ниже X?, отклонение Xi – X? меньше нуля. Если просуммировать все отклонения, взятые со своим знаком, то для симметричных распределений сумма будет равна нулю. В рассматриваемом примере матрицы сумма отклонений 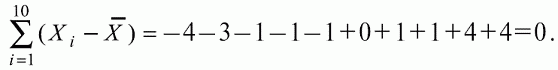 Чтобы отрицательные и положительные слагаемые не уничтожали друг друга, каждое отклонение возводят в квадрат и находят сумму квадратов отклонений. Эта сумма будет большой, если результаты тестирования отличаются существенной неоднородностью, и малой в случае близких результатов испытуемых по тесту. 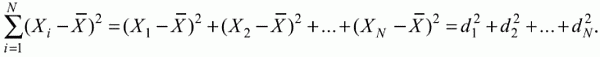 Для рассматриваемого примера данных сумма квадратов отклонений 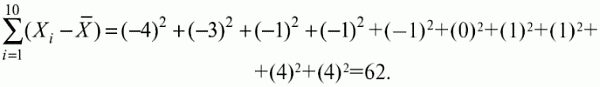 Величина суммы зависит также от размера выборки испытуемых, выполнявших тест, поэтому для сопоставимости мер изменчивости распределений, отличающихся по объему, каждую сумму делят на N – 1, где N – число студентов, выполнявших тест. Определяемая таким образом мера изменчивости называется исправленной дисперсией. Она обычно обозначается символом Sx2 и вычисляется по формуле (6.2) 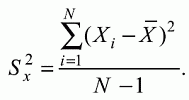 Кроме дисперсии, для характеристики меры изменчивости распределения удобно использовать еще один показатель вариации, который называется стандартным отклонением и вычисляется путем извлечения квадратного корня из дисперсии: (6.3) 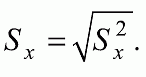 Для рассматриваемого примера данных тестирования 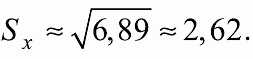 Свойства дисперсии и стандартного отклонения рассматриваются подробно в учебниках по статистике. Заинтересованному читателю можно порекомендовать, например, книгу Дж. Гласс, Дж. Стенли «Статистические методы в педагогике и психологии» [7]. Дисперсия играет важную роль в оценке качества тестов. Низкая дисперсия указывает на плохое качество нормативно-ориентированного теста, поскольку не обеспечивает высокий дифференцирующий эффект. Излишне высокая дисперсия, характерная для случая, когда все студенты отличаются по числу выполненных заданий, также требует переработки теста из-за существенного отличия вида распределения баллов от планируемой нормальной кривой. В процессе коррекции теста следует руководствоваться простым правилом: если проверка согласованности эмпирического распределения с нормальным дает положительные результаты, а дисперсия растет, то это означает, что переработка приводит к повышению его качества. Использование стандартного отклонения как меры вариации особенно эффективно для нормального распределения баллов испытуемых, поскольку в этом случае можно прогнозировать процент данных, лежащих внутри одного, двух и трех стандартных отклонений, откладываемых от центра распределения. В любом нормальном распределении приблизительно 68% площади под кривой лежит в пределах одного стандартного отклонения, откладываемого влево и вправо от среднего (т.е. X? ± 1 · Sx); 95% площади под кривой расположено в пределах двух Sx откладываемых слева и справа от среднего (X?·± 2 · S ); 99,7% площади под кривой – в пределах трех Sx по обе стороны от X? (X? ± 2 · Sx). Вообще существует бесконечное множество нормальных кривых, отличающихся друг от друга значениями X? и Sx, но все они объединяются общими свойствами, которые связаны с долями площади под кривой в пределах определенного числа отклонений. Из всех нормальных кривых наиболее удобна единичная, площадь под которой равна единице. Для нее среднее значение равно нулю, а стандартное отклонение единице. Для преобразования любой нормальной кривой в единичную достаточно выполнить вычитание среднего значения X? из каждого индивидуального балла Xi и разделить полученную разность на стандартное отклонение Sx, т.е., применив формулу 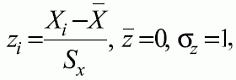 получим нормированное нормальное распределение со средним в нуле и единичным стандартным отклонением. При разработке теста необходимо помнить о том, что кривая распределения индивидуальных баллов, получаемых на репрезентативной выборке, носит неслучайный характер. Она является следствием подбора трудности заданий теста. При смещении в сторону легких заданий большая часть студентов выполнит почти все задания теста и получит высокие индивидуальные баллы. При приоритетном подборе самых трудных заданий в распределении индивидуальных баллов получится всплеск вблизи начала горизонтальной оси. При оптимальной трудности теста, когда распределение оценок параметра трудности заданий имеет вид нормальной кривой, автоматически возникает нормальность распределения индивидуальных баллов репрезентативной выборки студентов, что в свою очередь позволяет считать полученное распределение устойчивым по отношению к генеральной совокупности и определить репрезентативные нормы выполнения теста. Углубленный анализ качества теста, позволяющий сделать выводы о направлениях коррекции содержания отдельных заданий, связан с вычислением показателей связи между результатами испытуемых по отдельным заданиям теста. При оценке качества заданий важно понять, существует ли тенденция, когда одни и те же студенты добиваются успеха в какой-либо паре заданий теста либо состав учеников, добивающихся успеха, полностью меняется при переходе от одного задания теста к другому. Ответ на вопрос о существовании связи между двумя наборами данных получают с помощью корреляции. Для выражения степени соответствия между наборами данных X и Y используется специальная мера, которая называется ковариацией. Смысл понятия «ковариация» удобно пояснить на примере результатов выполнения одной группой испытуемых двух тестов X и Y Пусть результаты по первому тесту X – это множество хi (i = l, 2, …, ?), а по второму тесту – Yi (i = 1, 2, …, ?). Тогда для установления меры связи между результатами студентов по двум тестам необходимо сравнить положение каждого тестируемого по отношению к средним в распределении результатов по тесту X и по тесту Y. Степень соответствия результатов i-го испытуемого в первом (X) и во втором (Y) тестированиях будет проявляться в величине и знаке произведения отклонений (Xi – X?)(Yi – Y?), где Xi, Yi – результаты i-го испытуемого в первом и во втором тестированиях соответственно (i = 1, 2, …, N); X?, Y? — средние значения результатов по тестам X и Y, N — число студентов тестируемой группы. Если результат i-го испытуемого намного выше или ниже среднего балла по обоим тестам, то произведение (Xi – X?)(Yi – Y?) будет большим и положительным. Таким образом, при прямой связи значений Xi и Yi (i = 1, 2, …, N) по тестам X и Y большой и положительной получится сумма всех произведений, т.е. 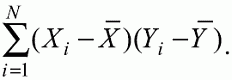 При обратной связи результатов тестирования, когда большинство значений Xi выше (ниже) среднего X? по тесту X сменяются на значения Yi ниже (выше) среднего Y? по тесту Y, сумма будет меньше нуля и велика по модулю в силу отрицательного знака всех или почти всех произведений (Xi – X?)(Yi – Y?). Наконец, если систематической связи между результатами студентов по тестам X и Y не наблюдается, знак произведения (Xi – X?)(Yi – Y?) будет хаотически меняться. Вполне возможно, что для достаточно большой выборки испытуемых, положительные слагаемые будут уравновешиваться отрицательными и потому сумма произведений получится близкой к нулю. Таким образом, произведение (Xi – X?)(Yi – Y?) по знаку и абсолютной величине отражает характер связи между наборами данных. Операция усреднения, осуществляемая путем деления суммы произведений отклонений на число испытуемых в выборке, позволяет получить показатель связи, не зависящий от размеров выборок, который называется ковариацией и обозначается символом. Его можно использовать для сравнения мер связи между результатами тестовых измерений по выборкам разного объема. (6.4) 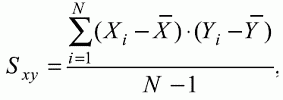 (Замечание, также как и в случае подсчета дисперсии, для различных прикладных задач в статистике удобнее делить не на N, а на N – 1, что при больших размерах выборок не сказывается существенно на величине Sxy). Для повышения сопоставимости оценок показателей связи по выборкам с различной дисперсией ковариацию делят на стандартные отклонения. Таким образом, Sxy необходимо разделить на Sx и Sy, где Sx и Sy – стандартные отклонения по множествам X и Y соответственно. В результате после преобразований получается величина, которая называется коэффициентом корреляции Пирсона rxy: (6.5) 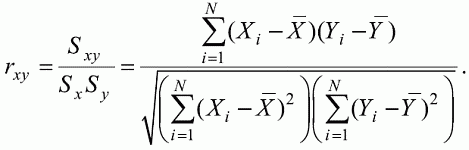 При исследовании связи между наборами данных необходимо правильно выбрать вид и форму показателя, зависящих от шкал, в которых представлены данные (см. подробнее в книге: [7]). В частности, для оценки связи между результатами выполнения учащимися двух заданий теста коэффициент корреляции Пирсона rxy необходимо преобразовать, поскольку результаты выполнения заданий представляются в дихотомической шкале (столбцы из нулей и единиц в матрице данных по тесту). Преобразованный коэффициент Пирсона для дихотомических данных называется коэффициентом ц и вычисляется по формуле (6.6) 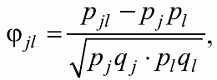 где pjl – доля испытуемых, выполнивших правильно оба задания с номерами j и l, т.е. доля тех, кто получил 1 балл по обоим заданиям; pj – доля испытуемых, правильно выполнивших j-е задание, qj = 1 – pj; pl – доля испытуемых, правильно выполнивших l-е задание теста, ql = 1 – pl. Например, для рассматриваемого примера матрицы корреляция между результатами по 5-му и 6-му заданиям теста будет: 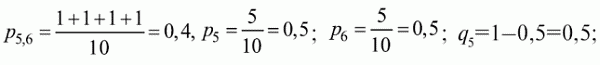 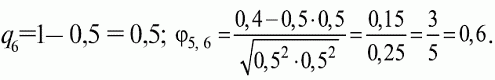 Результаты подсчета значений коэффициента корреляции между всеми заданиями для примера матрицы сведены в табл. 6.4. Анализ значений коэффициента корреляции в табл. 6.4 позволяет выделить в категорию «плохих» 3-е и 8-е задания теста. Задание 3 отрицательно коррелирует с заданиями 7, 8, 9 и 10. О том, что «виновато» 3-е, а не другие задания теста, свидетельствует анализ значений коэффициента корреляции в столбцах с номерами 7, 9 и 10. В них просматривается только один минус на месте, соответствующем заданию теста 3, которое в свою очередь отрицательно коррелирует с четырьмя заданиями теста. Аналогичная ситуация наблюдается для задания 8. Отрицательные значения коэффициента корреляции указывают на определенный просчет разработчиков в содержании заданий, которые рекомендуется из теста удалить. Наиболее распространенная причина появления отрицательной корреляции – отсутствие предметной чистоты содержания – нередко встречается при разработке самых разных тестов. Понятно, что предметная чистота – скорее, идеализируемое, чем реальное требование к содержанию любого теста. Например, в тесте по физике всегда встречаются задания с большим количеством математических преобразований, в тесте по биологии – задания, требующие серьезных знаний по химии, в тесте по истории – задания, рассчитанные на выявление культурологических знаний, и т.п. Поэтому можно лишь стремиться к тому, чтобы при выполнении каждого задания доминировали знания по проверяемому предмету. 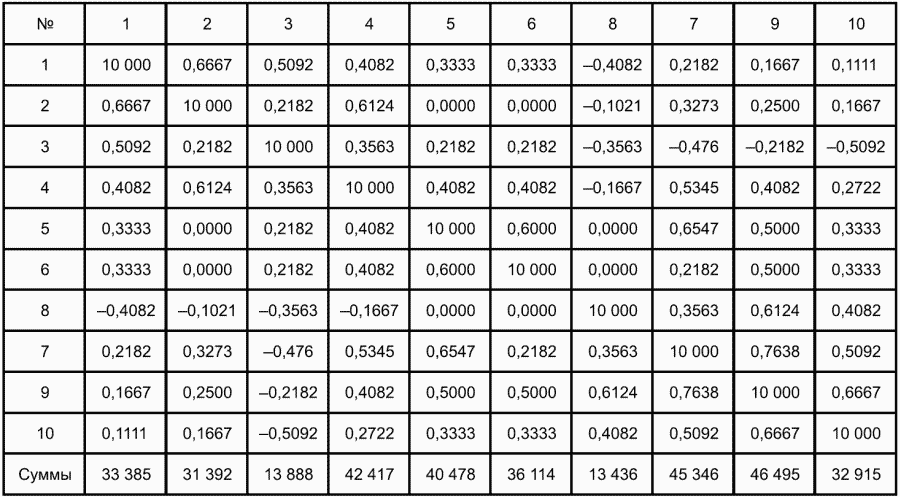 Таблица 6.4 Коэффициенты корреляции заданий Анализ 9-го столбца табл. 6.4 с максимальной суммой 4,6495, приведенной в конце, указывает на наличие ряда довольно высоких значений коэффициента корреляции (?9,8 = 0,6124; ?9,7 = 0,7638; ?9,10 = 0,6667), которые могут получить различную трактовку в зависимости от вида разрабатываемого теста. Для тематических тестов высокая корреляция между заданиями неизбежна, так как они в большинстве своем имеют слабо варьирующее исходное содержание, что вполне объяснимо назначением теста. Однако для итоговых тестов высокой корреляции между заданиями по возможности стараются избегать, поскольку вряд ли имеет смысл включать в итоговый тест несколько заданий, оценивающих одинаковые содержательные элементы. Поэтому в итоговых аттестационных тестах обычно стремятся к невысокой положительной корреляции, когда значения коэффициента варьируют в интервале (0; 0,3), и каждое задание привносит свой специфический вклад в общее содержание теста. Далее с помощью подсчета значений точечного бисериального коэффициента корреляции можно оценить валидность отдельных заданий теста. Бисериальный коэффициент корреляции используется в том случае, когда один набор значений распределения задается в дихотомической шкале, а другой – в интервальной. Под эту ситуацию подпадает подсчет корреляции между результатами выполнения каждого задания (дихотомическая шкала) и суммой баллов испытуемых (интервальная или квазиинтервальная шкала) по заданиям теста. Формула для вычисления значения точечного бисериального коэффициента rpbis, имеет вид: (6.7) 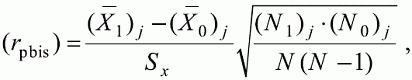 где (X?1)j — среднее значение индивидуальных баллов испытуемых, выполнивших верно j-е задание теста; (X?0) – среднее значение индивидуальных баллов испытуемых, выполнивших неверно j-е задание теста; Sx — стандартное отклонение по множеству значений индивидуальных баллов; (N1)j – число испытуемых, выполнивших верно j-е задание теста; (N0)j — число испытуемых, выполнивших неверно j-е задание теста; N — общее число испытуемых, N = N1 + N0. Применение формулы (6.7) для данных по 5-му заданию рассматриваемого примера матрицы дает достаточно высокое значение точечного бисериального коэффициента. 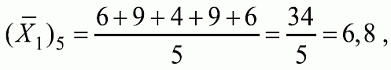 так как 1, 4, 5, 9 и 10-й испытуемые выполнили задание 5 верно. 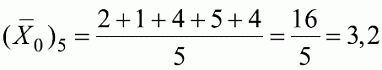 так как 2, 3, 6, 7 и 8-й испытуемые выполнили задание 5 неверно. Стандартное отклонение, подсчитанное для рассматриваемого примера ранее, Sx ? 2,6; (N1)5 = (N0)5 = 5; N = 10. Поэтому 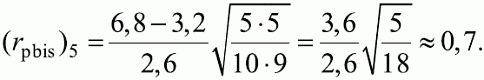 Значения бисериального коэффициента корреляции десяти заданий с суммой баллов по тесту rbis, рассчитанные с помощью компьютерных программ для данных матрицы, приводятся в табл. 6.5 Таблица 6.5 Значения коэффициента бисериальной корреляции  Анализ значений коэффициента бисериальной корреляции в табл. 6.5 указывает на два довольно неудачных задания теста – 3-е [(rbis)3 = 0,26] и 8-е [(rbis)8 = 0,24], которые имеют низкую валидность и должны быть удалены из теста. В целом задание можно считать валидным, когда значение (rbis)j ? 0,5 или выше этого числа. Оценка валидности задания позволяет судить о том, насколько оно пригодно для работы в соответствии с общей целью создания теста. Если эта цель – дифференциация студентов по уровню подготовки, то валидные задания должны четко отделять хорошо подготовленных от слабо подготовленных испытуемых тестируемой группы. Решающую роль в оценке валидности задания играет разность (X?1)j – (X?0)j, находящаяся в числителе дроби формулы (6.7). Чем выше значение этой разности, тем лучше работает задание на общую цель дифференциации испытуемых. Значения, близкие к нулю, указывают на низкую дифференцирующую способность заданий теста. В том случае, когда в разности доминирует вклад (X?0), а не (X?1), задание следует просто удалить из теста. В нем побеждают слабые испытуемые, а сильные выбирают неверный ответ либо пропускают задание при выполнении теста. Таким образом, подлежат удалению все задания, у которых rbis < 0. Оценка трудности тестовых заданий в классической теории получается по формуле
где pj — доля правильных ответов на j-е задание; Rj — количество студентов, выполнивших j-е задание верно; N — число студентов в тестируемой группе; j – номер задания теста, j = 1, 2, …, n. Трудность задания нередко выражают в процентах, тогда оценку, полученную по формуле (6.8), умножают на 100%. Долю правильных ответов на задание pj естественно интерпретировать как легкость задания, в то время как трудность скорее ассоциируется с долей неправильных ответов qj, которая находится путем вычитания pj из единицы: qj = 1 – pj . Однако по сложившейся традиции в классической теории тестов за трудность задания принимается именно доля pj. Для рассматриваемого примера матрицы доля правильных ответов на первое задание p1 = 9/10 = 0,9, а доля неправильных ответов q1 = 1 – 0,9 = 0,1 и т.д. После перевода доли p1 в проценты (0,9 · 100% = 90%) первое задание следует отнести к категории крайне легких: его выполнили 90% тестируемой выборки студентов. Подбор заданий по трудности в тесте удобно оценить с помощью гистограммы (рис. 6.3). 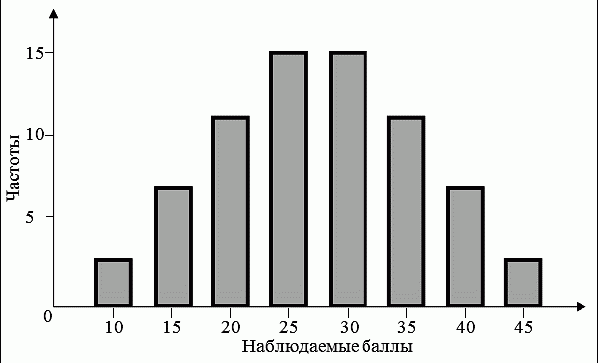 Рис. 6.3. Гистограмма хорошо сбалансированного по трудности нормативно-ориентированного теста В хорошо сбалансированном по трудности нормативно-ориентированном тесте есть несколько самых легких заданий со значениями p > 0. Есть несколько самых трудных с p > 1. Остальные задания по значениям p занимают промежуточное положение между этими крайними ситуациями и имеют в основном трудность 60–70%. Дополнительный аргумент в пользу преимущественного включения заданий средней трудности с p =? 0,5 связан с подсчетом дисперсии по каждому заданию теста, которая для дихотомического набора данных будет равна ?j = pjqj, (j = 1, 2, …, n). Так как произведение pjqj достигает максимального значения (0,5 · 0,5 =? 0,25) при pj =? 0,5 =? qj , то в рамках нормативно-ориентированного подхода наиболее удачными считаются задания средней трудности p = q =? 0,5, обеспечивающие максимальный вклад в общую дисперсию теста. В пользу преимущественного выбора заданий средней трудности также говорит подсчет ошибки измерения, которая уменьшается по мере продвижения к центру, где расположены задания средней трудности, и увеличивается на концах распределения. В критериально-ориентированных тестах основную массу составляют достаточно легкие задания, которые выполняют верно не менее 80–90% испытуемых, чтобы обеспечить достаточно низкий процент не аттестованных студентов, не прошедших по результатам тестирования за критериальный балл. Оценка правдоподобности дистракторов основана на подсчете долей испытуемых, выбравших каждый неправильный ответ. Анализ правдоподобности дистракторов, проведенный для результатов выполнения 39 заданий теста выборкой из 100 испытуемых, показан в табл. 6.6. В первом столбце таблицы помещены номера заданий теста. Второй столбец указывает на число испытуемых, выполнявших каждое из заданий. Все последующие столбцы содержат число и процент тестируемых, выбравших каждый из ответов к заданиям теста. Звездочкой отмечен процент, соответствующий правильному ответу к заданиям. Таблица 6.6 Анализ правдоподобности дистракторов 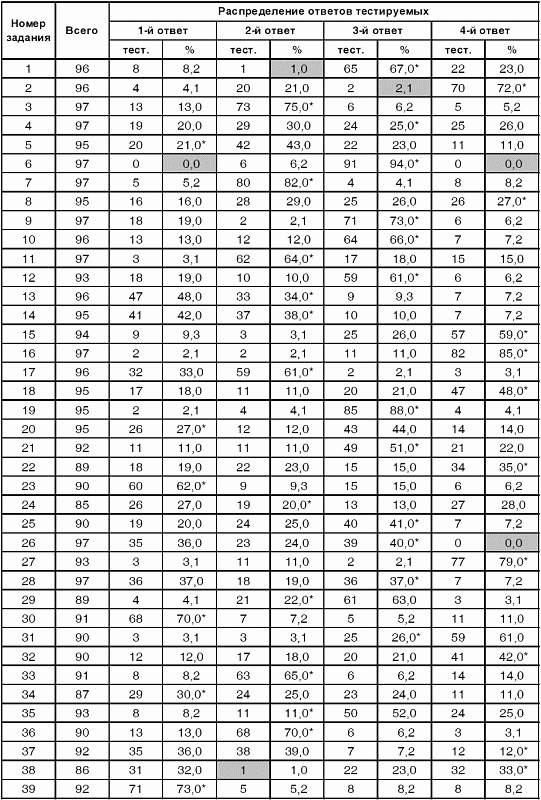 Анализ строк таблицы позволяет собрать полезную информацию о качестве дистракторов. Например, в первом задании правильным является 3-й ответ, и поэтому число P1 =? 67% в столбце, соответствующем 3-му ответу, указывает на трудность. Из 96 испытуемых, выполнявших задание, 65 справились с ним успешно, а остальные (96 – 65 = 31) распределились между дистракторами следующим образом: 8 тестируемых выбрали 1-й дистрактор, 1 тестируемый выбрал 2-й дистрактор и 22 испытуемых остановились при выполнении задания на 4-м, неправильном ответе, который, по-видимому, очень похож на правильный и поэтому оказался таким привлекательным для незнающих учеников. Таким образом, второй ответ функцию дистрактора не выполняет, поэтому подлежит изменению либо удалению из теста. Несомненно, нуждаются в переработке 1-й и 4-й ответы из задания 6, поскольку их не выбрал ни один человек из шести (97 – 91 = 6), неправильно выполнивших это задание теста и т.д. Таким образом, дистракторы, которые выбирают менее 5% неверно ответивших испытуемых, следует удалять из теста. Углубленный вариант дистракторного анализа построен на подсчете значения точечно-бисериального коэффициента корреляции для каждого дистрактора в заданиях теста. Отрицательные значения коэффициента корреляции указывают на ситуацию, когда хорошо выполнившие тест испытуемые не будут выбирать данный дистрактор в качестве правильного ответа. Значения коэффициента точечно-бисериальной корреляции для примера из табл. 6.6 приводятся в табл. 6.7 (как и ранее, звездочка соответствует правильному ответу). Таблица 6.7 Значения коэффициента точечно-бисериальной корреляции для дистракторов 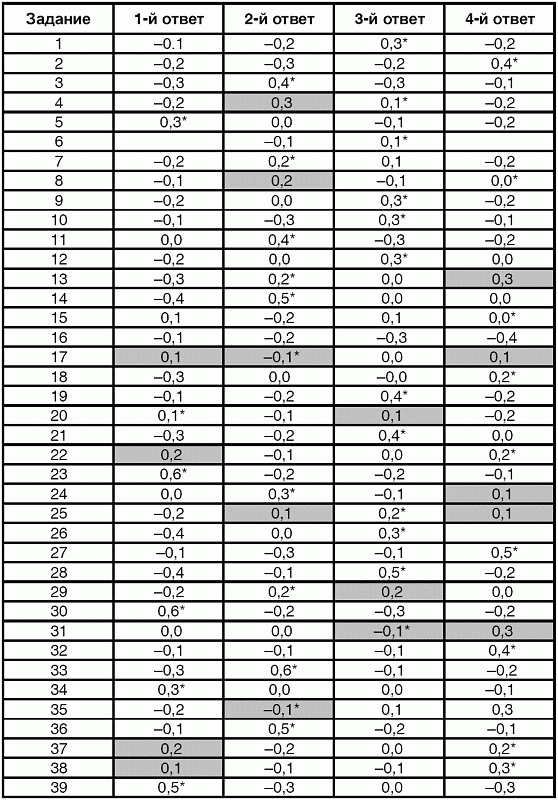 Выделенные положительные значения коэффициента точечно-бисериальной корреляции для дистракторов (например 2-й ответ в задании 4, 2-й ответ в задании 8, 4-й в 13 и т. д.) указывают на то, что эти неверные ответы выбирают в качестве правильных сильные студенты, что недопустимо в хороших заданиях теста. При правильном положении вещей значения коэффициента точечно-бисериальной корреляции для дистракторов должны быть отрицательными и превышающими по модулю 0,2. Положительные или близкие к нулю значения коэффициента для дистракторов говорят о необходимости их исключения либо переделки неправильных ответов. Правильные ответы, наоборот, должны выбирать сильные студенты, поэтому в хороших заданиях значения коэффициента точечно-бисериальной корреляции на месте ответов со звездочкой бывают только положительными и превышающими 0,5. Для случая, когда правильный ответ не выбирают сильные студенты (например, в задании 31 или в заданиях 17, 35 из табл. 6.7), коэффициент корреляции бывает близким к нулю или даже меньше нуля. Отрицательная или нулевая корреляция для верного ответа может отражать случайный характер ответов студентов, наличие систематических проблем в усвоении проверяемого материала, вызванных дефектами преподавания либо некорректной формулировкой задания теста. Дискриминативностью (discriminatory power) называется способность задания дифференцировать студентов на лучших и худших. Высокая дискриминативность – важная характеристика удачного тестового задания, она определяет меру валидности задания, его адекватность целям создания теста. Поэтому хороший нормативно-ориентированный тест должен быть составлен из заданий с высокой дискриминативной способностью. Для критериально-ориентированных тестов дискриминативность не является решающим фактором при отборе заданий в тест, но в любом случае невалидные задания должны быть удалены из теста. Для оценки дискриминативности задания применяются различные формулы. Наиболее простым является расчет по формуле rдисj= p1j – p0j, где rдисj – индекс дискриминативности для j-го задания теста; p1j – доля студентов, правильно выполнивших j-е задание в подгруппе из 27% лучших студентов по результатам выполнения теста; p0j – доля студентов, правильно выполнивших j-е задание в подгруппе из 27% худших студентов по результатам выполнения теста. Значения индекса rдис для заданий теста обычно представляют собой десятичную дробь, принадлежащую интервалу [–1; 1]. Максимального значения 1,00 rдис достигнет в том случае, когда все студенты из подгруппы лучших верно выполнят j-е задание теста, а из подгруппы худших это задание не выполнит верно ни один студент. Тогда задание будет обладать максимальным дифференцирующим эффектом. Нулевого значения rдис достигнет в том случае, когда в обеих подгруппах будут равны доли студентов, правильно выполнивших j-е задание теста. И наконец, минимальное значение rдис = –1 будет в ситуации, когда данное задание теста все сильные студенты сделали неверно, а все слабые – верно. Естественно, что задания второго и третьего типа с rдис = 0 или rдис < 0 из теста следует удалить. Более точное представление о дискриминативной способности задания можно составить, подсчитав точечный бисериальный коэффициент (rpbis) корреляции, процесс вычисления значений которого подробно рассмотрен выше в этом же разделе. Помимо приведенной формулы для rpbis, можно использовать другие, дающие близкие значения: 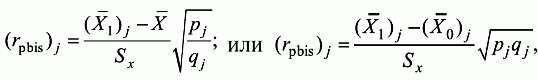 где (rpbis)j – точечно-бисериальный коэффициент корреляции для j-го задания; (X?1)j — среднее значение индивидуальных баллов студентов, выполнивших верно j-е задание; (X?0)j — среднее значение индивидуальных баллов учеников, выполнивших j-е задание неверно; X? — среднее значение баллов по всей выборке студентов; Sx — стандартное отклонение по множеству индивидуальных баллов. По мнению многих специалистов (Крокер, Алгина, Клайна и др. ), в качестве критического числа следует выбрать значение 0,2, потому все задания со значением rpbis < 0,2 необходимо удалить из теста. Интересна взаимосвязь показателей трудности и дискриминативности заданий теста. Задания с высокой дискриминативностью обычно имеют среднюю трудность, поскольку именно для них характерен высокий дифференцирующий эффект. Однако обратное заключение, вообще говоря, неверно. Задания с p =? 0,5 могут иметь как высокий, так и низкий дифференцирующий эффект. При подсчете статистик по тесту всегда проводится проверка значимости значений дисперсии, асимметрии, эксцесса и т.д. Для этого к данным, собранным по тесту, необходимо добавить информацию о принимаемом уровне риска допустить ошибку в статистическом выводе. Наиболее приемлемым для педагогических измерений является уровень в 5%, который допускает ошибку в пяти случаях из ста. После выбора степени риска проверка значимости проводится одним из описанных в литературе методов. При конструировании теста необходимо иметь четкое представление о содержании заданий, которые предполагается включить в окончательную версию теста. При одномерных измерениях содержание заданий должно отвечать свойству гомогенности, указывающему на степень его однородности с точки зрения оцениваемого параметра подготовленности ученика. Таким образом, гомогенность (однородность) – это характеристика задания, отражающая степень соответствия его содержания измеряемому свойству ученика. Степень гомогенности содержания обычно оценивают с помощью факторного анализа. Для вывода о приемлемой степени гомогенности достаточно лишь того, чтобы доминирующий фактор, в основном определяющий результаты выполнения задания, был ориентирован на измеряемую переменную. Представление о степени гомогенности задания как составляющей системы заданий в тесте можно получить с помощью анализа парных корреляций (см. выше в данном разделе). Если какое-либо задание отрицательно коррелирует с остальными, то есть веские основания для сомнений в его гомогенности. Наоборот, значимые, высокие оценки корреляции указывают на высокую степень однородности содержания заданий теста. При увеличении интеркорреляции заданий сужается содержательная область, отраженная в тесте, что желательно в тематических, но недопустимо в итоговых тестах для оценки уровня подготовки по предмету. Поэтому при создании итоговых нормативно-ориентированных тестов стараются отобрать задания с положительными, но невысокими значениями коэффициентов парной корреляции в пределах интервала (0; 0,3). Показанные в разделе простейшие случаи подсчета статистических характеристик теста входят в состав так называемой дескриптивной статистики по тесту. В общем случае статистика включает также факторный анализ для оценки полученных результатов тестирования соответствия измеряемой переменной. 6.3. Оценивание надежности и валидности педагогических тестов Общие представления о надежности и валидности были введены ранее. Оценка надежности нормативно-ориентированных тестов проводится различными методами, которые по способу осуществления можно условно разделить на две группы [28, 36]. Первая группа методов базируется на двукратном тестировании, проводимом с помощью одного и того же теста либо с помощью двух параллельных форм теста. Вторая группа предполагает однократное тестирование при оценке надежности теста. На практике стараются использовать вторую группу методов, поскольку организация повторного тестирования, как и разработка параллельных форм, всегда сопряжена с определенными трудностями и дополнительными затратами со стороны создателей тестов. Обычно вне зависимости от метода оценка надежности строится на подсчете корреляции между двумя наборами данных. Логика рассуждений при этом довольно проста: чем выше корреляция, тем надежнее тест. Для маленькой выборки корреляцию можно оценить визуально, как в приведенном далее примере (табл. 6.8). В рассматриваемом гипотетическом примере три теста А, В и С из 10 заданий дважды выполняла одна и та же выборка из 10 студентов. Тест А обладает оптимальной надежностью, так как результаты 10 студентов остались прежними: баллы и места учеников не изменились после повторного выполнения теста. Подсчет корреляции результатов первого и второго тестирования даст коэффициент корреляции, равный единице. Тест В абсолютно ненадежен: те, кто имел самые высокие баллы в первом тестировании, получают самые низкие во втором после повторного применения этого же теста. Полное отсутствие воспроизводимости баллов испытуемых указывает на минимальную надежность теста, поэтому (rн)в = –1. Тест С обеспечивает хаотичное изменение результатов, хотя баллы отдельных студентов (3-го и 9-го) будут воспроизведены при повторном выполнении теста. Скорее всего, надежность 3-го теста близка к нулю. Естественно, что рассмотренные гипотетические ситуации не встречаются на практике. Обычно коэффициент надежности принимает положительные значения, но никогда не бывает равен единице даже для существующих десятилетиями, получивших всеобщее признание очень хороших тестов. Таблица 6.8 Результаты двукратного выполнения трех тестов 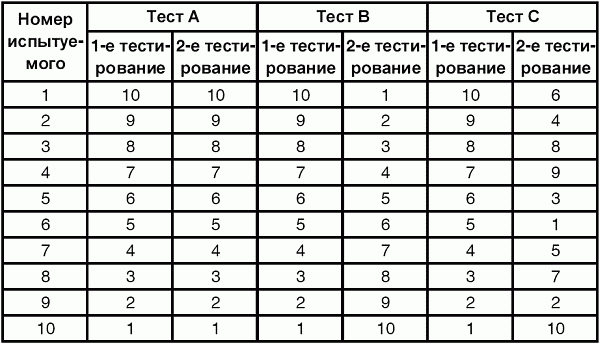 Ретестовый метод оценки надежности (test-retest reliability) основан на подсчете корреляции индивидуальных баллов испытуемых, полученных в результате двукратного выполнения ими одного и того же теста. Обычно повторное тестирование проводится через 1–2 недели, когда испытуемые еще не успели забыть учебный материал и незначительно продвинулись в усвоении новых знаний. При таких условиях повторного предъявления теста низкая корреляция между результатами тестирования будет следствием не изменения состояния испытуемых, а применения ненадежного теста. Для подсчета коэффициента надежности по методу повторного тестирования используется формула (6.9) 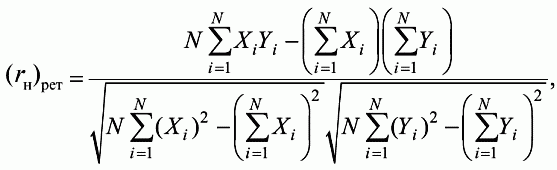 где (rн)рет — коэффициент надежности теста по ретестовому методу, Xi — индивидуальный балл i-го испытуемого в первом тестировании, Yi — индивидуальный балл i-го испытуемого во втором тестировании (i = . 1, 2, …, N). Для удобства вычисления коэффициента надежности по ретестовому методу данные можно заносить в табл. 6.9. Пример подсчета по табл. 6.9 можно привести для исходной матрицы. Выбирая ее данные в качестве результатов первого тестирования и добавляя результаты произвольные второго тестирования можно подсчитать коэффициент надежности ретестовым методом (табл. 6.10). После подстановки чисел из нижней строчки таблицы в формулу (6.9) коэффициент надежности будет 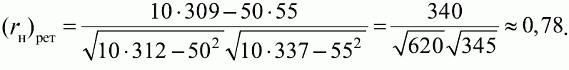 Значение rн =? 0,78 указывает на невысокую надежность теста. Применение ретестового метода может привести к ошибочным оценкам надежности в тех случаях, когда проводится слишком близкое по времени повторное применение теста. Студенты запоминают ответы к заданиям и при повторном тестировании значительно повышают свои результаты, что искажает оценку надежности теста. Таблица 6.9 Сводная таблица для оценки надежности (ретестовый метод) 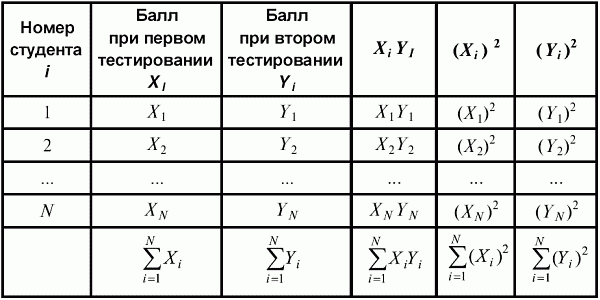 Таблица 6.10 Пример подсчета надежности ретестовым методом 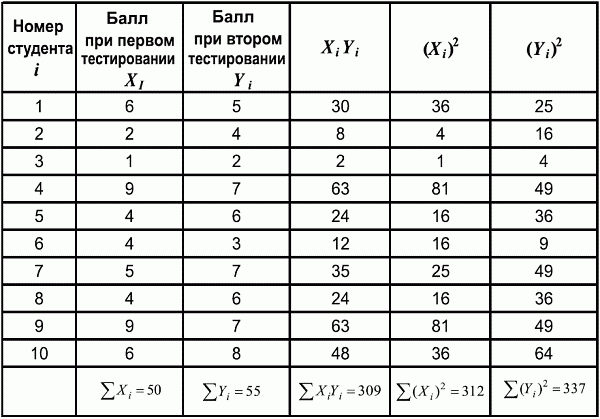 Другой метод параллельных форм (parallel-form reliability) основан на однократном применении двух параллельных вариантов теста. Он непригоден в тех случаях, когда при тестировании используется один вариант теста. В некоторых странах, например в США, благодаря соблюдению всех требований к проведению тестирования, применение единственного варианта не снижает необходимый уровень информационной безопасности, зато обеспечивает высокую сопоставимость результатов выполнения теста. Таким образом, если тест только один, то для оценки надежности методом параллельных форм приходится создавать параллельный вариант теста, затем с затратами сил, средств и времени на апробацию доказывать правомерность гипотезы о параллельности и только потом оценивать надежность исходного теста. В другой ситуации, когда изначально разрабатываются параллельные варианты теста, как в ЕГЭ, оценка надежности методом параллельных форм также требует значительных трудозатрат. Необходима тщательная ротация вариантов в группе испытуемых для обеспечения сходных выборок учащихся на параллельных вариантах теста. Даже при стратификации выборки испытуемых и ротации вариантов достоверность оценок надежности снижается из-за того, что параллельные формы – это, скорее, теория, чем реальность, поскольку на практике, несмотря на все усилия авторов, как правило, обнаруживаются статистически значимые отличия в характеристиках параллельных вариантов. Для оценки надежности методом параллельных форм используется формула (6.9). В ней Xi (i = 1, 2, …, N) – индивидуальные баллы испытуемых в первой форме, а Yi (i = 1, 2,…, N) – во второй. А далее все вычисления с точностью повторяют подробно рассмотренный пример. Метод оценивания надежности, основанный на расщеплении результатов по тесту на две части (split-half method), наиболее распространен из-за своего удобства. Он позволяет вычислить коэффициент надежности при однократном выполнении испытуемыми теста. Для оценки надежности результаты тестирования делят на две части: в одну включают данные студентов по четным, а в другую – по нечетным заданиям, считая при этом, что получены сходные по содержанию части теста. Правда, деление на две части не единственный способ, возможны и другие варианты, когда выделяют большее число частей при оценке надежности теста. Для оценивания надежности методом расщепления результаты студентов заносят в табл. 6.11. Таблица 6.11 Сводная таблица для оценки надежности (метод расщепления)  Далее для таблицы данных используют формулу (6.9), в которой роль результатов в первом тестировании выполняют данные по четным заданиям, а во втором – по нечетным. Пример подсчета по данным исходной матрицы приведен в табл. 6.2. Результаты испытуемых по четным и нечетным заданиям приводятся в табл. 6.12. После подстановки чисел из табл. 6.12 в формулу (6.9) получается 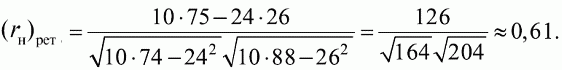 По сравнению с прежним значением 0,78 надежность получилась намного меньше, что можно было предвидеть, поскольку тест укоротился в два раза (после расщепления подсчет надежности был по пяти заданиям вместо десяти). Таблица 6.12 Пример подсчета надежности методом расщепления 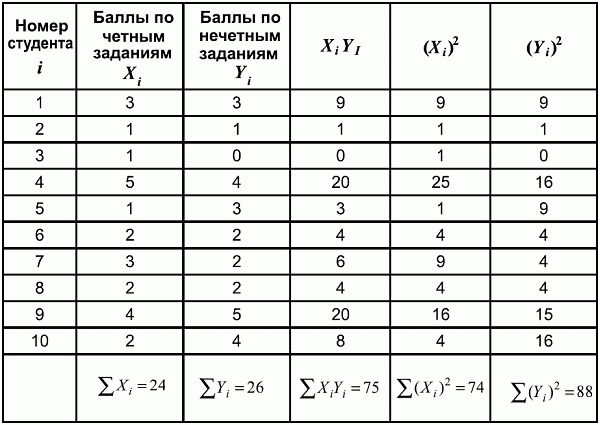 Для коррекции оценки надежности в соответствии с длиной исходного теста используется формула Спирмена–Брауна 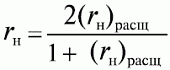 где в числителе и знаменателе дроби стоит коэффициент надежности для половины заданий теста, а слева скорректированный коэффициент надежности с учетом всех заданий теста. Тогда для рассматриваемого примера коэффициент надежности теста из десяти заданий будет 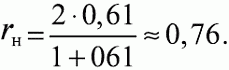 После коррекции коэффициент надежности получился приблизительно такой же, как и в предыдущем случае подсчета ретестовым методом (rн = 0,78). Применение формулы Спирмена–Брауна подтверждает высказанное ранее предположение: увеличение длины повышает надежность теста. Приведенный метод оценивания надежности имеет свои ограничения в применении. Он основан на допущении параллельности двух половин теста, что не всегда и не в полной мере может оказаться верным. Корреляция двух половин возрастает по мере роста гомогенности теста. В этой связи метод расщепления нередко называют методом оценки внутренней состоятельности (согласованности) теста (Internal-Consistency Method). 6.4. Метод Кьюдера-Ричардсона для дихотомических оценок Метод Кьюдера-Ричардсона для оценки надежности также основан на однократном тестировании, но в отличие от предыдущего подхода не зависит от искусственных допущений о полной параллельности двух частей теста. Однако и он имеет свою ограниченную сферу применения, поскольку годится исключительно при использовании дихотомических оценок по результатам выполнения заданий гомогенных тестов. Формула Кьюдера-Ричардсона (F. Kuder, M. Richardson-20, или KR-20) имеет вид [28, 36] (6.10) 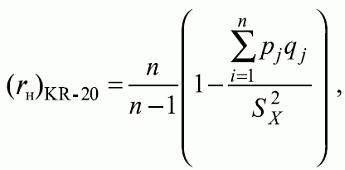 где рj – доля правильных ответов на j-е задание; qj — доля неправильных ответов, qj = 1 – рj; SX2 — дисперсия по распределению наблюдаемых баллов; n — число заданий теста. Для исходной матрицы данных подсчитанная ранее исправленная дисперсия SX2 = 6,89 , а доли правильных ответов получаются делением чисел Rj в последней строке матрицы на 10. Тогда сумма произведений долей правильных и неправильных ответов будет 0,9 · 0,1 + 0,8 · 0,2 + 0,7 · 0,3 + 0,6 · 0,4 + 0,5 · 0,5+ 0,5 · 0,5 + 0,3 · 0,7 + 0,4 · 0,6 + 0,2 · 0,8 + 0,1 · 0,9 = 1,9 и коэффициент надежности 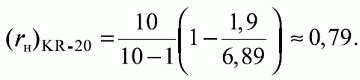 При оценке надежности нельзя полагаться лишь на один показатель, поскольку каждый из них имеет свои ограничения, смещающие оценки надежности теста в сторону завышения или занижения. Для достоверной проверки качества теста следует учитывать несколько показателей надежности, подсчитанных по разным формулам, лишь небольшая часть которых приведена в данном тексте. В качестве нижнего предела допустимых значений надежности обычно выбирают 0,7. При более низком значении использование теста вряд ли целесообразно в силу большой погрешности измерения. Если тест разрабатывают профессионалы, то к нему предъявляют более жесткие требования. Как правило, тесты с надежностью менее 0,8 считаются непригодными в профессионально организованных службах и центрах тестирования. Значения коэффициента надежности, превышающие 0,9, говорят о высоком качестве теста. Они крайне желательны, но редко встречаются. Обычно в тестологической практике надежность тестов колеблется в интервале (0,8; 0,9). Коэффициент надежности, подсчитываемый по матрице тестовых результатов, всегда зависит от свойств выборки испытуемых. Поэтому при каждом очередном использовании теста приходится оценивать его надежность, а уж потом говорить о возможности интерпретации результатов выполнения теста. 6.5. Надежность и стандартная ошибка измерения Один из аспектов применения коэффициента надежности связан с определением стандартной ошибки измерения. Для установления связи между стандартной ошибкой измерения и надежностью теста необходимо преобразовать формулу 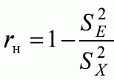 и выделить в левой части SЕ2. После преобразования формулы относительно SЕ2 получится выражение SЕ2 = SX2 (1 – rн), или 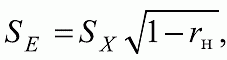 где SX — стандартное отклонение по распределению индивидуальных баллов; rн – коэффициент надежности теста; SE — стандартная ошибка измерения. Это выражение обычно используется для вычисления SE по известным величинам rн и SX Что касается сущностного смысла, то SE (standard error of measurement) трактуется как стандартное отклонение результатов испытуемого от его истинного балла, полученное при выполнении им большого числа параллельных форм теста. Для лучшего уяснения смысла показателя SE можно представить другую гипотетическую ситуацию, когда i-и испытуемый выполнял много раз один и тот же тест. Если предположить, что эффект запоминания отсутствует, то результаты тестирования образуют нормальное распределение вокруг истинного балла Тi со стандартным отклонением SE. На практике SE рассматривается как статистическая величина, отражающая степень точности отдельных измерений, поэтому величину SE используют для определения границ доверительного интервала, внутри которого должен находиться истинный балл оцениваемого ученика группы. Построение доверительного интервала. Общераспространен подход, когда доверительный интервал выстраивается как две симметричные окрестности (левая и правая) вокруг наблюдаемого показателя ученика, хотя это не совсем верно, поскольку речь должна идти об окрестностях, расположенных слева и справа от истинного балла. Тем не менее этот факт вынуждено игнорируется в прикладных исследованиях в силу отсутствия истинного балла, и доверительный интервал при заданном риске допустить ошибку t =? 0,05, т.е. в пяти случаях из ста, принимается равным (Xi – 1,96SE; Xi + 1,96SE), где ?i — наблюдаемый балл i-го испытуемого; 1,96 – константа, табличное число, используемое при t ? 0,05. Для рассматриваемого ранее примера матрицы тестовых результатов (см. табл. 6.11), коэффициента надежности rн =? 0,78 и стандартного отклонения SX =? 2,62, вычисленного ранее для матрицы, SE будет равно  Тогда доверительный интервал для истинного балла первого ученика со значением Хi = 6 будет (6 – 1,23; 6 + 1,23) или (4,77; 7,23). Истинный балл первого ученика может находиться в любой точке этого интервала. Интересна геометрическая интерпретация доверительного интервала на оси наблюдаемых баллов, приведенная для балла i-го учащегося. Очевидно, что с ростом SE границы доверительного интервала будут раздвигаться, и вместе с тем будут увеличиваться возможные пределы отклонения истинного балла от наблюдаемых результатов измерения (более правильная с точки зрения теории трактовка: пределы отклонения наблюдаемых баллов от истинной компоненты измерения). 6.6. Валидность гомогенных тестов Валидность – это характеристика способности теста служить поставленной цели измерения. Как правило, постановка целей создания теста носит комплексный характер, поэтому часто стараются проверить валидность с разных позиций сообразно различным направлениям использования теста. Например, нормативно-ориентированный тест для приема абитуриентов в вузы должен служить цели дифференциации испытуемых и прогностическим целям, так как мало выделить лучших абитуриентов в момент приема, нужно также спрогнозировать успешность дальнейшего обучения зачисленных в вузы абитуриентов. Оценивание валидности всегда проводится путем соотнесения характеристик результатов измерения с внешними критериями [ 1,28, 36]. В качестве таких критериев могут выступать оценки экспертов при анализе содержания теста и его адекватности целям измерения (содержательная валидность), результатов по другим тестам (конструктная валидность), успешности дальнейшего обучения (прогностическая валидность). Высокая корреляция между анализируемыми результатами испытуемых и внешними критериями подтверждает высокую валидность теста. Основная трудность при такой валидизации носит не практический, а методологический характер, поскольку она состоит в выборе значимого внешнего критерия. При разработке аттестационных тестов, конечно, на первом плане находится содержательная валидность, которая определяется как характеристика репрезентативности содержания теста по отношению к запланированным для проверки знаниям, умениям и требованиям ФГОС. Если тест позволяет проверить все то, что задумано авторами в спецификации и заложено в ФГОС, то он считается валидным относительно контролируемого содержания дисциплины и целей создания аттестационного теста. Представление о содержательной валидности не следует связывать только с полнотой отображения в тесте содержания требований ФГОС, необходимо также заботиться о правильности пропорций содержания теста. Если тест отображает второстепенные элементы содержания дисциплины вместо значимых разделов, то нельзя говорить о его высокой содержательной валидности. Конечно, во всех случаях справедлив общий вывод – чем глубже и полнее отображение, тем выше уверенность в содержательной валидности теста. Однако при нормативно-ориентированном подходе есть свои особенности. Тест валиден по содержанию, если он обеспечивает высокую дифференциацию результатов испытуемых и в нем отображено все то главное, без чего нельзя говорить о знании курса. При этом отдельные содержательные разделы могут быть представлены фрагментарно, а другие и вовсе отсутствовать в тесте. Для повышения содержательной валидности в тест лучше включать задания, содержание которых не связано каким-либо заметным образом, и потому они не могут замещаться при проверке. При прочих равных условиях эта тенденция приведет к повышению полноты охвата содержания и, следовательно, к росту содержательной валидности теста. Таким образом, если речь идет о валидности, то конструктор заинтересован в выборе заданий с малыми коэффициентами интеркорреляции. К противоположному выводу легко прийти, если стараться повысить надежность теста. Отбирая задания с большими коэффициентами интеркорреляции, можно обеспечить высокую однородность содержания и надежность теста. Это противоречие, отмеченное впервые Ф. Лордом [38], дает основание для возникновения серьезных проблем при конструировании теста. В частности, легко представить ситуацию разработки итогового теста по алгебре. Если включить в него только задания на решение уравнений одного вида, то можно достичь высокой надежности, близкой к 0,90. Однако, и это понятно без всяких объяснений, маловероятно, чтобы такой итоговый тест обладал приемлемой содержательной валидностью. Таким образом, при конструировании гомогенного теста следует стремиться к повышению его надежности в разумных пределах, чтобы не снизить существенным образом содержательную валидность теста. Поэтому при отборе заданий в тест необходимо иметь четкое представление об их содержании и о множестве других факторов, а не просто отдавать предпочтение тем, которые высоко коррелируют друг с другом и обеспечивают хорошую надежность теста. Правда, по рассматриваемой выше проблеме есть другая точка зрения, принадлежащая Гилфорду и Ньюнелли [36]. Они полагают, что внутренняя согласованность теста является непременным условием его высокой содержательной валидности, и потому высокая надежность служит предпосылкой оптимальной валидности теста. Кточке зрения Ф. Лорда присоединяются Кэттелл и Клайн [17]. По их мнению, максимум валидности может быть получен тогда, когда все задания слабо, но положительно коррелируют друг с другом, при этом каждое из них имеет высокую корреляцию с критерием по тесту. Поэтому повышению валидности способствует включение заданий, для которых характерны большие коэффициенты бисериальной корреляции с суммой баллов по тесту. При количественных оценках валидности для педагогических тестов в качестве критерия обычно берутся оценки экспертов, выставленные ими при традиционной проверке знаний учеников без использования тестов. Процесс валидизации осложняется необходимостью установления меры согласованности оценок экспертов, которых обычно бывает не менее трех. Если мера согласованности достаточно высока, то для оценки валидности используется формула 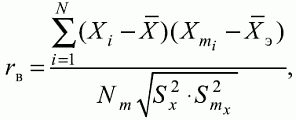 где Хi – Х? – отклонение тестового балла i-го ученика от среднего балла по тесту; Хтi – Х?э — отклонение балла i-го ученика у экспертов от Х?э — среднего арифметического экспертных оценок; SX2 — дисперсия баллов учеников по тесту; Smx2 — дисперсия баллов экспертов; m — число экспертов. Бывают случаи, когда педагог заинтересован в оценке прогностической валидности, например, указывающей меру вероятности прогноза успешности профессиональной деятельности выпускника вуза по результатам выполнения теста. В этом случае результаты по тесту коррелируют с результатами аттестации молодых специалистов, проводимой на предприятиях и организациях в течение нескольких первых лет работы. Высокая корреляция означает, что разработанные тесты прогностичны для отбора лучших выпускников вуза, обладающих сформированными профессиональными компетенциями. Выводы В отличие от традиционных средств контроля тесты проходят процесс научного обоснования качества, предполагающий оценку соответствия характеристик тестов двум важнейшим критериям: надежности и валидности. Разработка тестов для принятия административно-управленческих решений в образовании требует длительного исследовательского периода, охватывающего в циклическом режиме все этапы создания теста. Анализ эмпирических данных тестирования начинается с построения матрицы, отражающей взаимодействие испытуемых и заданий в процессе выполнения теста. Обработка данных матрицы в классической теории тестов основывается на дескриптивной статистике, анализ результатов обработки позволяет оценить качество тестовых заданий и всего теста. Наибольшую трудность при создании теста представляет интерпретация результатов обработки эмпирических результатов тестирования, но только благодаря ей может быть достигнуто высокое качество теста. Полная стандартизация процедуры предъявления теста способствует повышению точности и созданию качественных тестов. Для разработки аттестационных тестов в вузе рекомендуется использовать традиционную теорию тестов. Практические задания и вопросы для обсуждения В таблице приведены ответы 30 испытуемых на одно задание теста. Всех испытуемых можно разбить на две подгруппы, одна из которых содержит 15 испытуемых высокого уровня подготовленности, а другая – 15 человек низкого уровня подготовленности (сильная и слабая группа). По данным таблицы вычислите: 1 ) среднее значение тестовых баллов по сильной и по слабой группе, сравните их; 2) дисперсию баллов по всей группе (30 испытуемых); 3 ) долю правильных ответов на задание по сильной группе ( 15 испытуемых); 4) долю правильных ответов на задание по слабой группе (15 испытуемых); 5 ) корреляцию между ответами испытуемых на задание и суммой баллов по тесту для сильной группы; 6 ) корреляцию между ответами испытуемых на задание и суммой баллов по тесту для слабой группы. 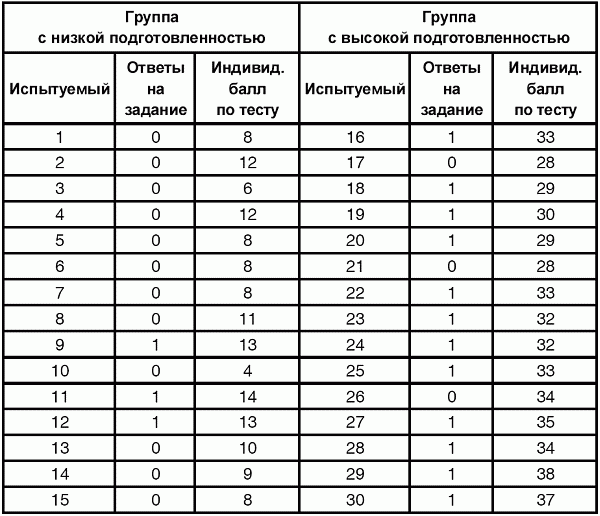 |
|
||
|
Главная | Контакты | Нашёл ошибку | Прислать материал | Добавить в избранное |
||||
|
|
||||